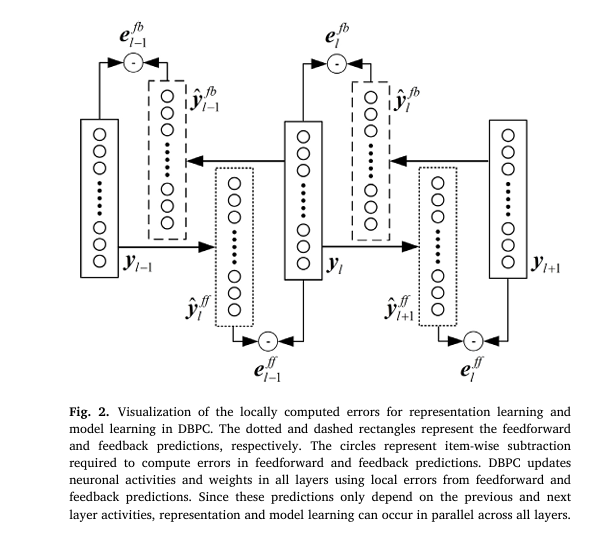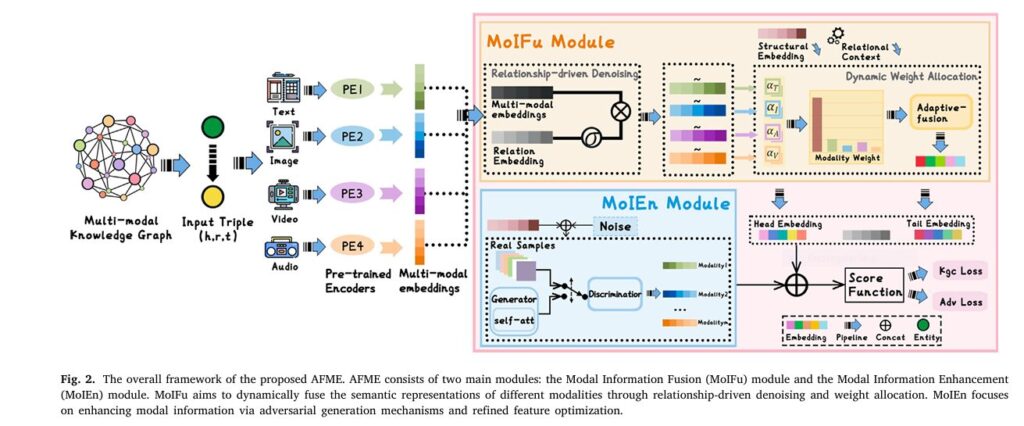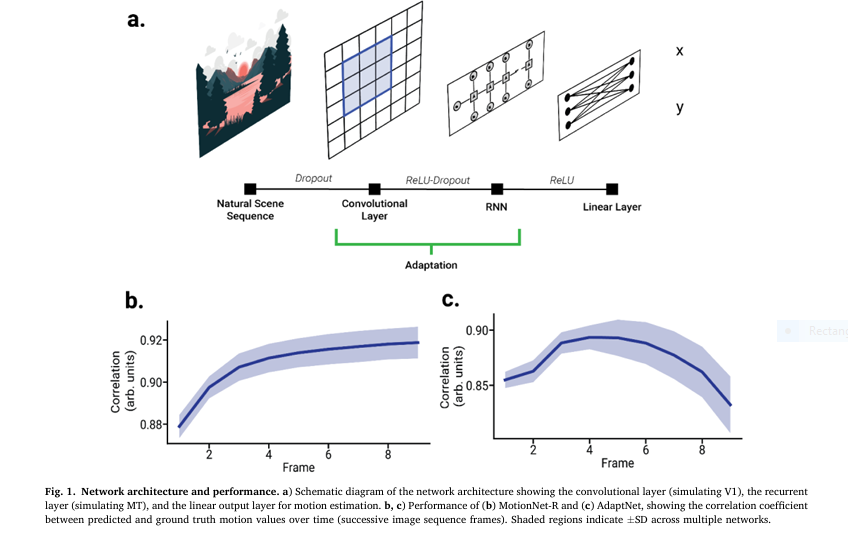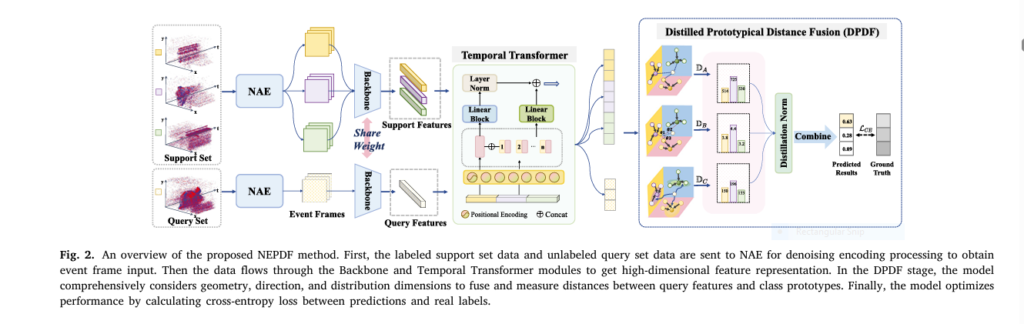
7 Revolutionary Ways to Compress BERT Models Without Losing Accuracy (With Math Behind It)
Introduction: Why BERT Compression Is a Game-Changer (And a Necessity) In the fast-evolving world of Natural Language Processing (NLP) , BERT has become a cornerstone for language understanding. However, with great power comes great computational cost. BERT’s massive size — especially in variants like BERT Base and BERT Large — poses significant challenges for deployment […]