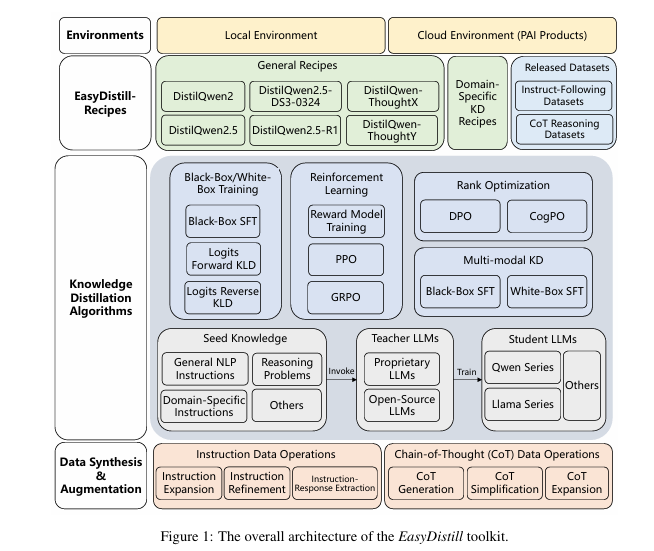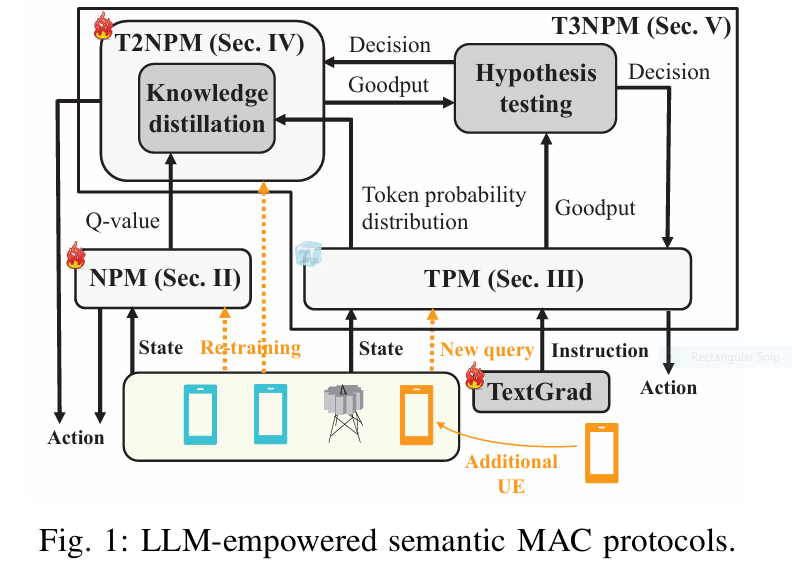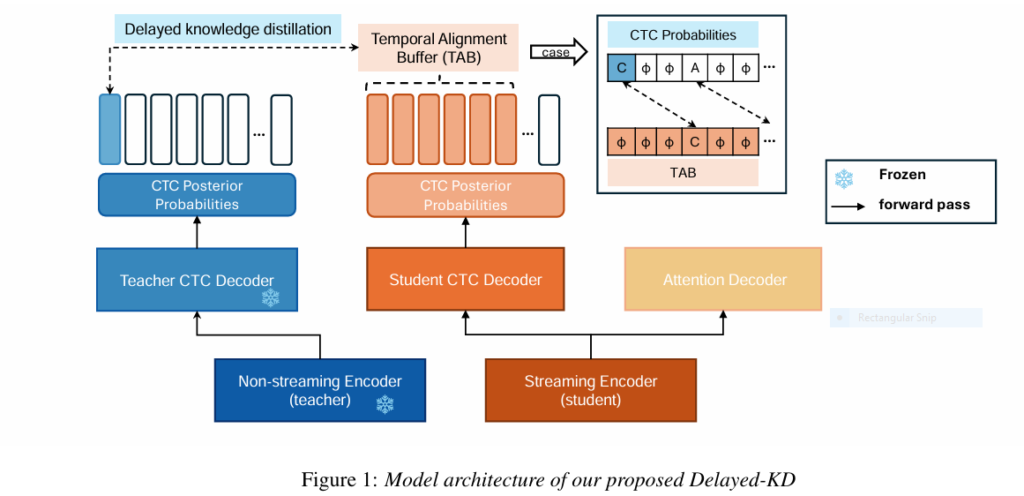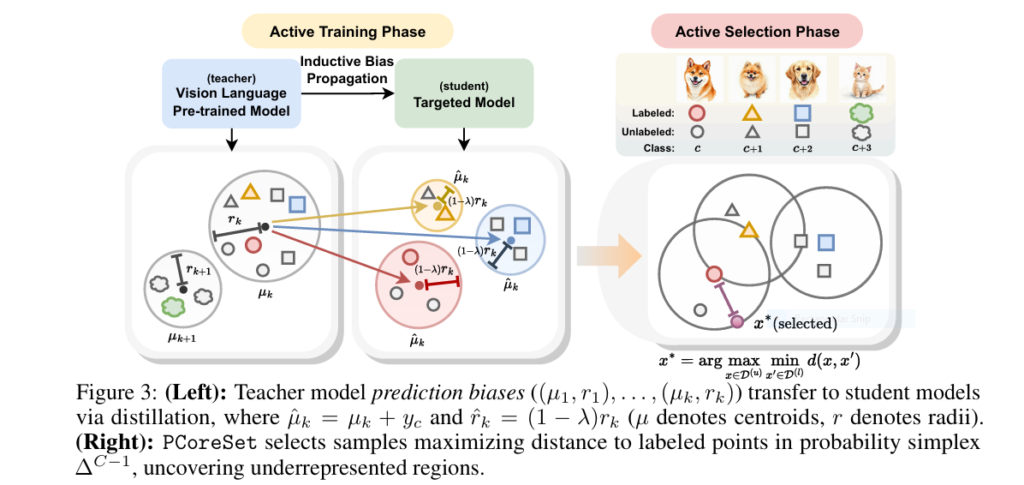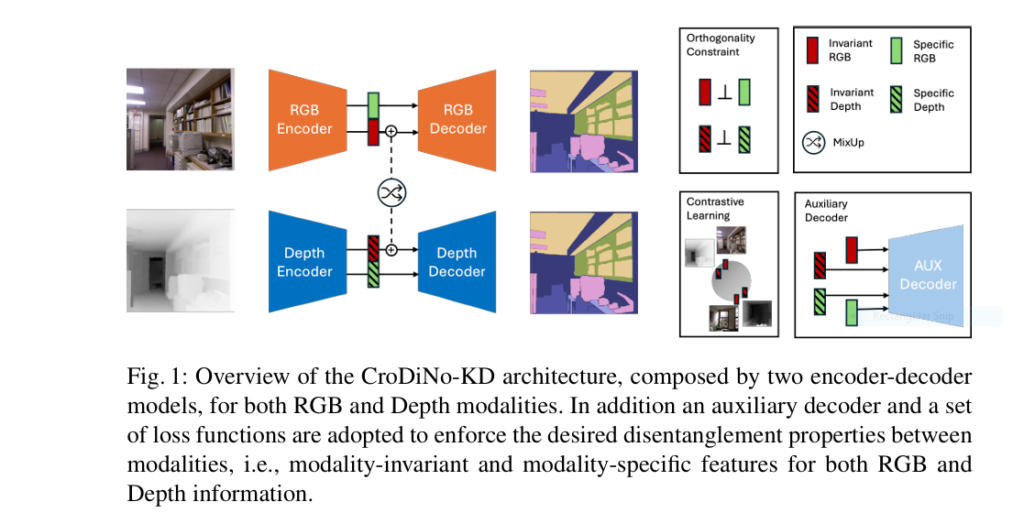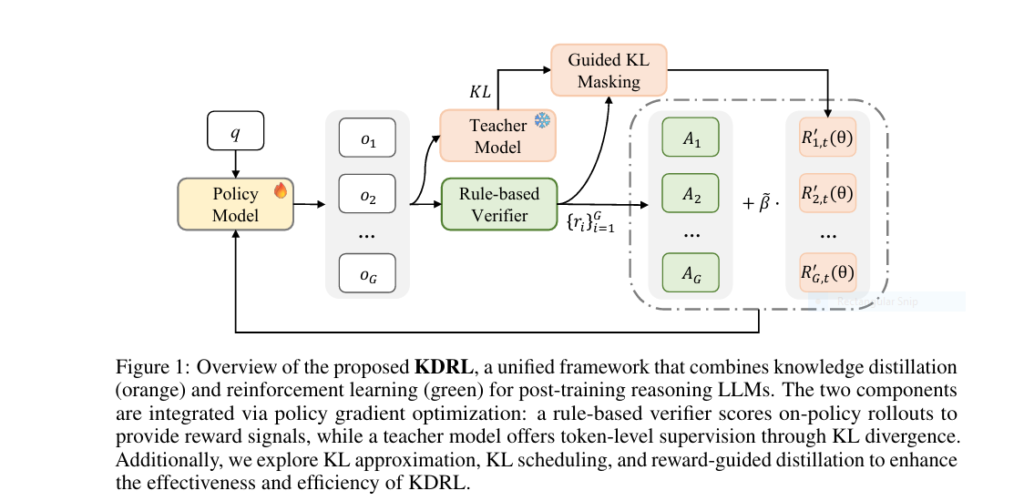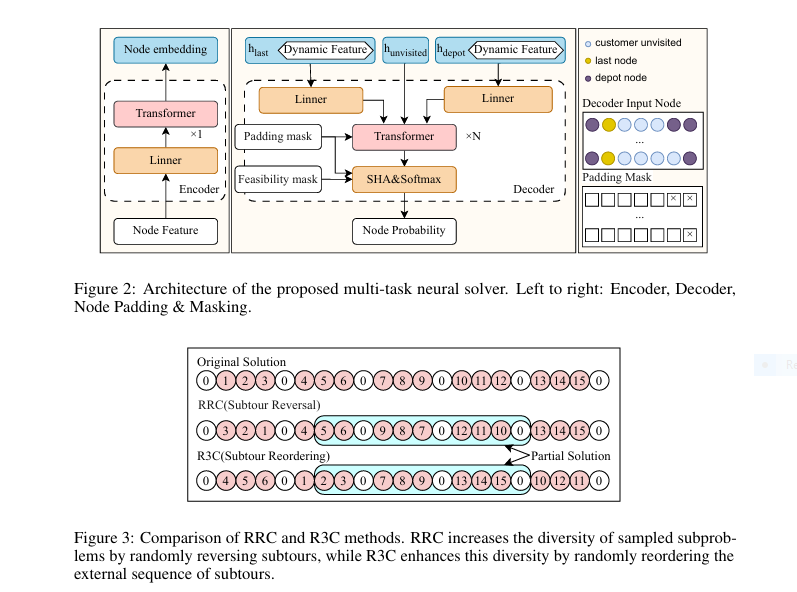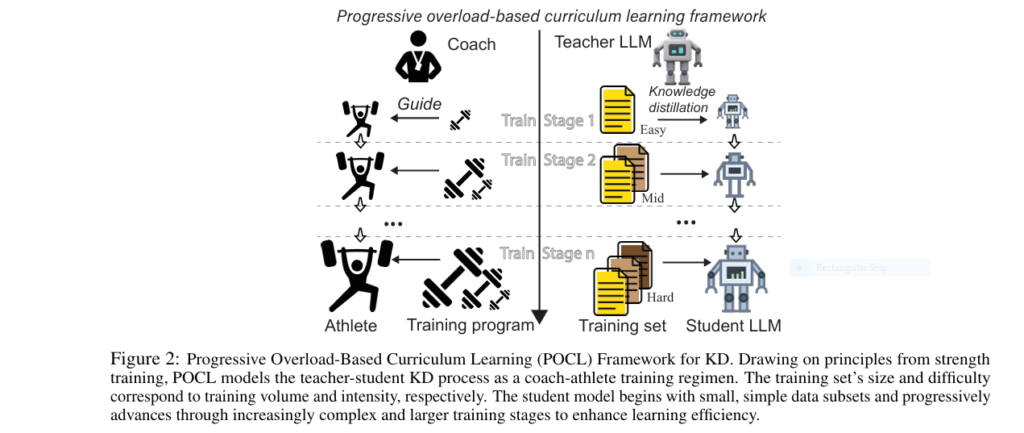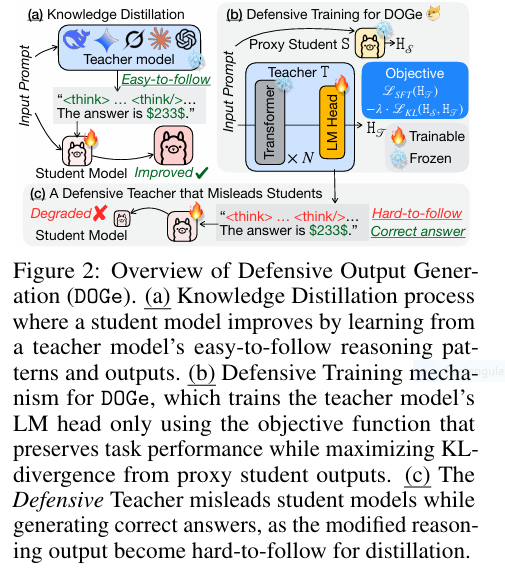
7 Revolutionary Ways DOGe Is Transforming LARGE LANGUAGE MODEL (LLM) Security (And What You’re Missing!)
In the ever-evolving world of artificial intelligence, Large Language Models (LLMs) have become the backbone of innovation. From chatbots to content generation tools, these models power some of the most sophisticated applications in use today. However, with great power comes great vulnerability — especially when it comes to model imitation via knowledge distillation (KD) . […]