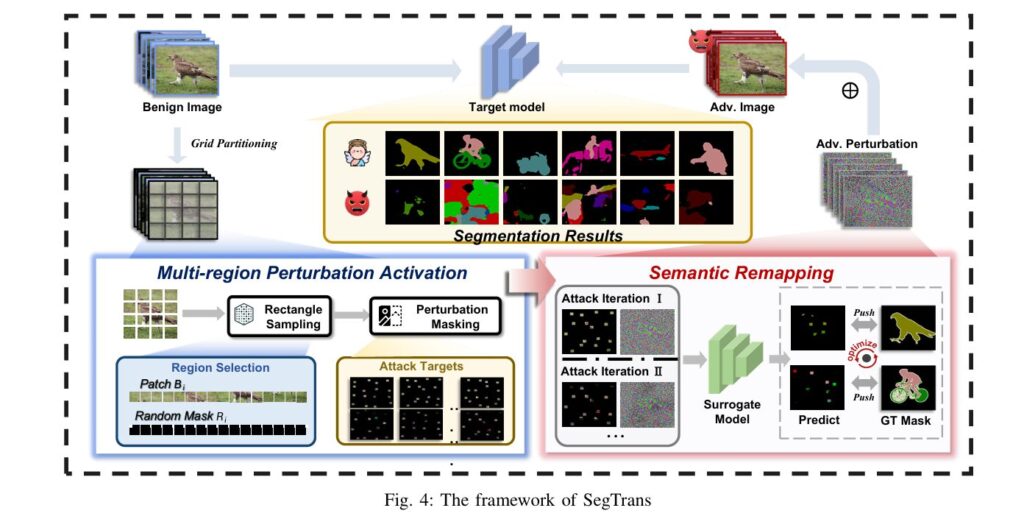
SegTrans: The Breakthrough Framework That Makes AI Segmentation Models Vulnerable to Transfer Attacks
In the high-stakes world of autonomous driving, medical diagnostics, and satellite imagery analysis, semantic segmentation models are the unsung heroes. These sophisticated AI systems perform pixel-level classification, allowing them to precisely identify and outline objects like pedestrians, tumors, or road markings within complex images. Their accuracy is critical for safety and reliability. However, a groundbreaking […]