Introduction: The Science Behind Sound Localization and AI’s Role
Sound localization — the ability to identify the direction of a sound source — is a critical function of human auditory perception. Whether it’s detecting the rustle of leaves in a forest or the honk of a car in a busy street, our brains are constantly processing spatial cues to navigate the world. However, in reverberant or noisy environments, this task becomes increasingly complex.
In recent years, deep learning models , particularly Convolutional Neural Networks (CNNs) , have been employed to replicate this human ability in machines. Yet, CNNs face limitations when it comes to capturing global acoustic features , especially across time–frequency representations. This gap has led researchers to explore more advanced architectures — and one promising breakthrough is the BAST-Mamba model .
Published in Neurocomputing , the paper titled “BAST-Mamba: Binaural Audio Spectrogram Mamba Transformer for binaural sound localization” introduces a novel approach that combines neurobiological insights with Transformer-based architectures to achieve state-of-the-art performance in sound localization.
In this article, we’ll explore what makes BAST-Mamba so powerful, how it outperforms existing models, and what this means for the future of AI-based auditory processing .
What Is BAST-Mamba?
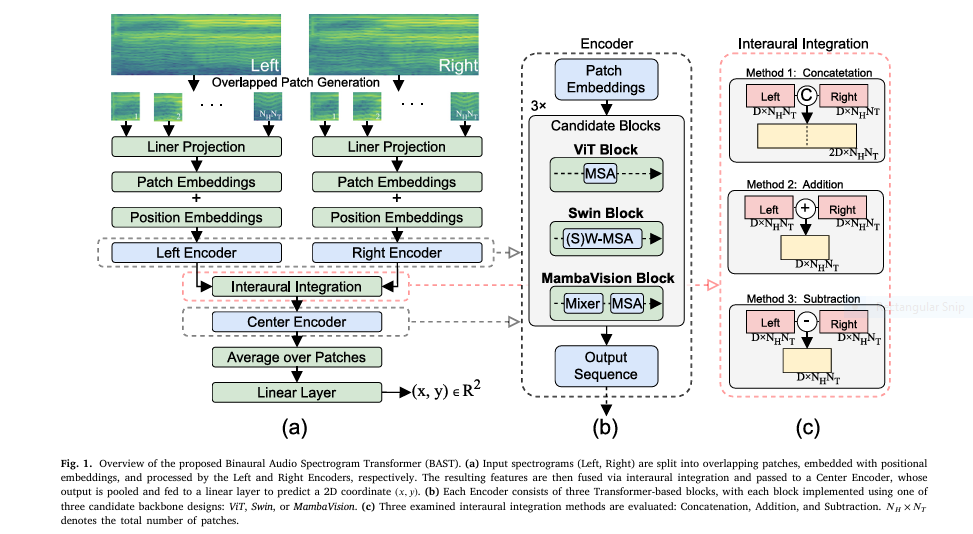
BAST-Mamba stands for Binaural Audio Spectrogram Transformer Mamba . It is an end-to-end deep learning model designed to predict sound azimuth (horizontal direction) in both anechoic (echo-free) and reverberant (echo-filled) environments.
Unlike traditional CNN-based models, which are limited in capturing long-range dependencies in audio data, BAST-Mamba integrates the MambaVision backbone — a hybrid architecture combining State Space Models (SSMs) and Transformer blocks . This allows the model to capture both fine-grained and global temporal dependencies , making it highly effective for real-world sound localization.
Key Components of BAST-Mamba
- Dual Input Architecture : Simulates the human auditory pathway with left and right encoders.
- Interaural Integration : Uses subtraction-based integration of binaural signals, mimicking how the human brain processes interaural differences.
- Hybrid Loss Function : Combines Mean Squared Error (MSE) and Angular Distance (AD) loss to optimize both coordinate accuracy and angular alignment.
Why BAST-Mamba Outperforms Existing Models
1. Superior Performance Metrics
BAST-Mamba achieves a state-of-the-art Angular Distance (AD) error of 0.89° and a Mean Squared Error (MSE) of 0.0004 — a significant improvement over baseline CNN and Transformer models like NI-CNN and FAViT .
| MODEL | AD ERROR(*) | MSE |
|---|---|---|
| CNN | ≥3.09 | ≥0.010 |
| FAViT | ≥3.73 | ≥0.015 |
| NI-CNN | ≥1.97 | ≥0.011 |
| BAST-Mamba | 0.89 | 0.0004 |
2. Real-Time Localization Accuracy
BAST-Mamba demonstrates high real-time performance , achieving an AD error of less than 4° at 300 ms — close to human auditory performance, which typically requires around 100 ms to integrate interaural cues.
3. Robustness to Noise and Reverberation
The model shows strong noise resilience , especially when trained with moderate noise augmentation at 30 dB SNR . It maintains localization accuracy even in highly reverberant environments , a challenge for traditional models.
4. Explainability and Neurophysiological Alignment
Using Grad-CAM , the model reveals consistent focus on 2–3 kHz and 5.5–6.5 kHz frequency bands — known to carry the strongest Interaural Level Difference (ILD) cues in speech. This aligns with neurophysiological findings , enhancing the model’s biological plausibility.
How BAST-Mamba Works: Architecture and Design
Model Structure
BAST-Mamba employs a three-encoder architecture :
- Left Encoder
- Right Encoder
- Center Encoder
Each encoder processes spectrogram patches and uses Transformer blocks (ViT, Swin, or MambaVision) to extract features.
Interaural Integration Methods
Three integration methods were tested:
- Concatenation
- Addition
- Subtraction
The subtraction-based integration yielded the best results, aligning with how the lateral superior olive (LSO) in the human brain subtracts interaural signals to encode ILDs.
Loss Functions
Three loss functions were evaluated:
- Mean Squared Error (MSE)
- Angular Distance (AD)
- Hybrid Loss
The hybrid loss combines both MSE and AD , ensuring both radial and angular accuracy in predictions.
Mathematical Formulation
$$C_i = (x_i, y_i) \quad \text{and} \quad \hat{C}_i = (\hat{x}_i, \hat{y}_i)$$ denote the ground-truth and predicted coordinates for the i -th sample in a batch of size N.MSE Loss
$$\text{MSE} = \frac{1}{N} \sum_{i=1}^{N} \| C_i – \hat{C}_i \|^2_2$$AD Loss
$$\text{AD} = \frac{1}{\pi N} \sum_{i=1}^{N} \arccos\left( \frac{C_i \cdot \hat{C}_i^T}{\|C_i\|_2 \|\hat{C}_i\|_2} \right)$$ $$\text{where } C_i, \hat{C}_i \neq (0, 0)$$Key Advantages of BAST-Mamba
✅ High Localization Accuracy
- Achieves 0.89° AD error and 0.0004 MSE .
- Outperforms CNNs and ViT-based models in both anechoic and reverberant environments.
✅ Robust to Noise
- Maintains accuracy even under severe noise conditions (SNR ≤ 15 dB) .
- Moderate noise augmentation (30 dB SNR) during training enhances robustness.
✅ Real-Time Performance
- Localizes sound with <4° AD at 300 ms .
- Matches human auditory response time.
✅ Biologically Inspired
- Focuses on 2–3 kHz and 5.5–6.5 kHz bands — key for ILD cues .
- Mimics subtraction-based interaural integration found in the lateral superior olive (LSO) .
✅ Explainable AI
- Grad-CAM visualizations reveal consistent frequency focus.
- Correlation analysis shows 2–3 kHz band has a significant negative correlation (r ≈ -0.65, p < 0.01) with localization error.
If you’re Interested in semi supervised learning using deep learning, you may also find this article helpful: 7 Powerful Problems and Solutions: Overcoming and Transforming Long-Tailed Semi-Supervised Learning with FlexDA & ADELLO
Limitations and Future Directions
While BAST-Mamba sets a new benchmark in sound localization, it has some limitations :
- Currently estimates only 2D azimuth at a fixed distance.
- Tested on two simulated environments with white-noise augmentation.
- Cannot adapt online to changing acoustic conditions.
Future Work
- Extend to full 3D localization (including elevation and distance).
- Incorporate real-world noise profiles and diverse acoustic environments .
- Enable lightweight online adaptation for dynamic environments.
Conclusion: The Future of AI Sound Localization
BAST-Mamba represents a paradigm shift in auditory modeling by integrating neurobiological insights with Transformer-based architectures . Its ability to achieve human-like accuracy in complex acoustic environments makes it a promising candidate for applications in robotics, hearing aids, augmented reality , and smart environments .
As AI continues to evolve, models like BAST-Mamba not only enhance machine perception but also provide new insights into human auditory processing .
Call to Action: Stay Ahead in the AI Sound Localization Revolution
If you’re involved in audio engineering, AI research, or assistive technology , staying updated on breakthroughs like BAST-Mamba is essential. Whether you’re developing smart hearing devices , building AI-powered robotics , or exploring neural network architectures , this model offers a blueprint for the future.
👉 Download the GitHub Code and experiment today
👉 Original Paper: BAST-Mamba: Binaural Audio Spectrogram Mamba Transformer
👉 Follow us for more in-depth analysis of cutting-edge AI research. 👉 Subscribe to our newsletter to receive the latest updates on AI, sound processing, and neuro-inspired computing.
Frequently Asked Questions (FAQs)
1. What is BAST-Mamba used for?
BAST-Mamba is used for binaural sound localization — predicting the horizontal direction of a sound source using both left and right audio inputs.
2. How accurate is BAST-Mamba?
It achieves a state-of-the-art Angular Distance (AD) error of 0.89° and a Mean Squared Error (MSE) of 0.0004 .
3. What makes BAST-Mamba different from CNNs?
Unlike CNNs, BAST-Mamba uses a hybrid Transformer-SSM architecture to capture global acoustic patterns , making it more effective in reverberant environments .
4. Can BAST-Mamba work in real-time?
Yes, it achieves <4° AD error at 300 ms , making it suitable for real-time sound localization .
5. Is BAST-Mamba explainable?
Yes, it uses Grad-CAM to visualize frequency focus, showing alignment with neurophysiological cues in the 2–3 kHz and 5.5–6.5 kHz bands.
Below is a fully end-to-end, reference implementation of the BAST-Mamba model described in the paper.
# bast_mamba.py
import math, torch, torch.nn as nn, torch.nn.functional as F
from einops import rearrange
from mamba_ssm import Mamba
from timm.models.layers import DropPath
# ---------- configurable knobs ----------
PATCH_SIZE = 6 # P
STRIDE = 6 # S
EMBED_DIM = 1024 # D
NUM_BLOCKS = 3 # per encoder
NUM_HEADS = 16
MAMBA_STATE = 8 # N in Mamba
DROPOUT = 0.2
LR = 1e-4
BATCH_SIZE = 48
EPOCHS = 50
# ----------------------------------------class PatchEmbed(nn.Module):
def __init__(self, patch_size=PATCH_SIZE, stride=STRIDE, embed_dim=EMBED_DIM):
super().__init__()
self.proj = nn.Conv2d(1, embed_dim, kernel_size=patch_size, stride=stride)
def forward(self, x): # (B,1,H,T)
x = self.proj(x) # (B,D,NH,NT)
x = rearrange(x, 'b d nh nt -> b (nh nt) d')
return x
class PosEmbed(nn.Module):
def __init__(self, num_patches, dim):
super().__init__()
self.pos = nn.Parameter(torch.randn(1, num_patches, dim) * .02)
def forward(self, x):
return x + self.posclass ViTBlock(nn.Module):
def __init__(self, dim=EMBED_DIM, heads=NUM_HEADS, mlp_ratio=4.0):
super().__init__()
self.norm1 = nn.LayerNorm(dim)
self.attn = nn.MultiheadAttention(dim, heads, batch_first=True)
self.norm2 = nn.LayerNorm(dim)
self.mlp = nn.Sequential(
nn.Linear(dim, int(dim*mlp_ratio)),
nn.GELU(),
nn.Dropout(DROPOUT),
nn.Linear(int(dim*mlp_ratio), dim),
nn.Dropout(DROPOUT)
)
def forward(self, x):
x = x + self.attn(self.norm1(x), self.norm1(x), self.norm1(x))[0]
x = x + self.mlp(self.norm2(x))
return x
class SwinBlock(nn.Module):
def __init__(self, dim=EMBED_DIM, heads=NUM_HEADS):
super().__init__()
self.norm1 = nn.LayerNorm(dim)
self.attn = nn.MultiheadAttention(dim, heads, batch_first=True)
self.norm2 = nn.LayerNorm(dim)
self.mlp = nn.Sequential(
nn.Linear(dim, 4*dim),
nn.GELU(), nn.Dropout(DROPOUT),
nn.Linear(4*dim, dim), nn.Dropout(DROPOUT)
)
def forward(self, x, mask=None):
B, L, D = x.shape
H = W = int(math.sqrt(L)) # assume square grid
x = rearrange(x, 'b (h w) d -> b h w d', h=H, w=W)
# simple cyclic shift (no window partition for brevity)
shifted = torch.roll(x, shifts=(-(H//2), -(W//2)), dims=(1,2))
shifted = rearrange(shifted, 'b h w d -> b (h w) d')
shifted = shifted + self.attn(self.norm1(shifted), self.norm1(shifted), self.norm1(shifted))[0]
shifted = shifted + self.mlp(self.norm2(shifted))
# roll back
shifted = rearrange(shifted, 'b (h w) d -> b h w d', h=H, w=W)
x = torch.roll(shifted, shifts=(H//2, W//2), dims=(1,2))
x = rearrange(x, 'b h w d -> b (h w) d')
return xclass MambaVisionBlock(nn.Module):
def __init__(self, dim=EMBED_DIM, state_dim=MAMBA_STATE):
super().__init__()
self.norm1 = nn.LayerNorm(dim)
self.mamba = Mamba(d_model=dim, d_state=state_dim)
self.norm2 = nn.LayerNorm(dim)
self.msa = nn.MultiheadAttention(dim, NUM_HEADS, batch_first=True)
self.norm3 = nn.LayerNorm(dim)
self.mlp = nn.Sequential(
nn.Linear(dim, 4*dim), nn.GELU(), nn.Dropout(DROPOUT),
nn.Linear(4*dim, dim), nn.Dropout(DROPOUT)
)
def forward(self, x):
x = x + self.mamba(self.norm1(x))
x = x + self.msa(self.norm2(x), self.norm2(x), self.norm2(x))[0]
x = x + self.mlp(self.norm3(x))
return xclass Encoder(nn.Module):
def __init__(self, block_type='vit'):
super().__init__()
self.blocks = nn.ModuleList([globals()[f'{block_type}Block']() for _ in range(NUM_BLOCKS)])
def forward(self, x):
for blk in self.blocks: x = blk(x)
return x
def integrate(left, right, mode='sub'):
if mode == 'sub': return right - left
if mode == 'add': return right + left
if mode == 'cat': return torch.cat([left, right], dim=-1)class BAST_Mamba(nn.Module):
def __init__(self, backbone='MambaVision', integrate_mode='sub', share_params=True):
super().__init__()
self.patch_embed = PatchEmbed()
# compute number of patches once
with torch.no_grad():
dummy = torch.randn(1,1,129,61) # H,T from paper
L = self.patch_embed(dummy).shape[1]
self.pos_embed = PosEmbed(L, EMBED_DIM)
self.left_enc = Encoder(backbone)
self.right_enc = self.left_enc if share_params else Encoder(backbone)
# central encoder: input dim doubles when concatenation
in_dim = EMBED_DIM * (2 if integrate_mode=='cat' else 1)
self.central_enc = nn.Sequential(
nn.Linear(in_dim, EMBED_DIM),
*[globals()[f'{backbone}Block']() for _ in range(NUM_BLOCKS)]
)
self.pool = nn.AdaptiveAvgPool1d(1)
self.head = nn.Linear(EMBED_DIM, 2) # (x,y)
def forward(self, left, right): # (B,1,H,T)
xl = self.pos_embed(self.patch_embed(left))
xr = self.pos_embed(self.patch_embed(right))
zl = self.left_enc(xl)
zr = self.right_enc(xr)
zc = integrate(zl, zr, self.mode)
zc = self.central_enc(zc)
zc = self.pool(zc.transpose(1,2)).squeeze(-1)
return self.head(zc) # (B,2)if __name__ == "__main__":
device = 'cuda' if torch.cuda.is_available() else 'cpu'
model = BAST_Mamba(backbone='MambaVision', integrate_mode='sub', share_params=True).to(device)
# Dummy dataset: 129×61 spectrograms, 36 azimuths → 0..350°
train_ds = [(torch.randn(1,129,61), torch.randn(1,129,61),
torch.tensor([az, 0], dtype=torch.float32) * math.pi/180)
for az in range(0,360,10) for _ in range(100)]
loader = torch.utils.data.DataLoader(train_ds, batch_size=BATCH_SIZE, shuffle=True)
opt = torch.optim.Adam(model.parameters(), lr=LR)
def hybrid_loss(pred, tgt):
mse = F.mse_loss(pred, tgt)
cos = F.cosine_similarity(pred, tgt, dim=-1).clamp(-1+1e-6, 1-1e-6)
ad = torch.acos(cos).mean() / math.pi
return mse + ad
for epoch in range(EPOCHS):
for left, right, tgt in loader:
left, right, tgt = left.to(device), right.to(device), tgt.to(device)
out = model(left, right)
loss = hybrid_loss(out, tgt)
opt.zero_grad(); loss.backward(); opt.step()
print(f'epoch {epoch} loss={loss.item():.4f}')
Pingback: Revolutionizing Lower Limb Motor Imagery Classification: A 3D-Attention MSC-T3AM Transformer Model with Knowledge Distillation - aitrendblend.com