Breast cancer remains the most diagnosed cancer among women globally, accounting for nearly 1 in 4 cancer cases. Early detection and precise diagnosis are critical to improving survival rates—especially in low- and middle-income countries where access to advanced imaging like MRI or mammography is limited. In this context, breast ultrasound (BUS) has emerged as a frontline diagnostic tool due to its real-time imaging, lack of ionizing radiation, and effectiveness in dense breast tissue.
However, accurate breast tumor segmentation in ultrasound remains a significant challenge. Low contrast, speckle noise, blurred lesion boundaries, and high operator variability make manual delineation time-consuming and subjective. Enter deep learning-based automated segmentation, which promises faster, more consistent results. But how trustworthy are these AI predictions?
A groundbreaking new study titled “Towards Trustworthy Breast Tumor Segmentation in Ultrasound using Monte Carlo Dropout and Deep Ensembles for Epistemic Uncertainty Estimation” tackles this very question. Researchers from institutions across Ghana, Nigeria, Pakistan, Canada, and the USA present a novel framework that not only achieves state-of-the-art segmentation accuracy but also quantifies model uncertainty—a crucial step toward clinical trust and safe deployment.
In this article, we’ll explore:
- Why uncertainty estimation is vital in medical AI
- How data quality impacts model performance
- The role of Monte Carlo Dropout and Deep Ensembles
- Performance on in-distribution vs. out-of-distribution datasets
- Practical implications for radiologists and healthcare systems
Let’s dive in.
Why Uncertainty Matters in Medical AI
Artificial intelligence models, especially deep neural networks, often behave like “black boxes.” They output predictions with high confidence—even when they’re wrong. In non-critical domains like image tagging or recommendation engines, this may be acceptable. But in medical imaging, incorrect predictions can have life-altering consequences.
This is where uncertainty quantification becomes essential. There are two main types of uncertainty:
- Aleatoric Uncertainty: Inherent noise in the data (e.g., ultrasound artifacts).
- Epistemic Uncertainty: Model uncertainty due to lack of knowledge or training data limitations.
While aleatoric uncertainty is irreducible, epistemic uncertainty can be minimized with better models, more diverse data, or improved training strategies. By estimating epistemic uncertainty, clinicians can identify regions where the model is unsure—such as ambiguous tumor boundaries—and exercise caution during diagnosis.
As highlighted in the study, integrating uncertainty into segmentation models enables trustworthy clinical decision support, especially in resource-constrained settings where expert radiologists may be scarce.
The Problem with Current Datasets: Data Duplication in BUSI
One of the most critical contributions of this research is the identification and correction of data duplication in the widely used Breast Ultrasound Images (BUSI) dataset.
The original BUSI dataset, introduced by Al-Dhabyani et al. in 2020, has been instrumental in training and benchmarking deep learning models for breast tumor segmentation. However, recent audits revealed serious flaws:
- Duplicate images across training and validation sets
- Inconsistent annotations from different annotators
- Inclusion of non-breast ultrasound scans (e.g., maxilla)
These issues lead to data leakage, inflating performance metrics and giving a false sense of model generalization.
To address this, the authors created three deduplicated versions of the BUSI dataset:
| DATASET VERSION | DEDUPLICATION STRATEGY |
|---|---|
| BUSI-A1 | Remove first occurrence of duplicates |
| BUSI-A2 | Remove second occurrence of duplicates |
| BUSI-A3 | Retain the version with most accurate annotation (radiologist-reviewed) |
Among these, BUSI-A3 is recommended as the gold standard for future research due to its clinical validation.
🔍 Key Insight: Using the full, uncleaned BUSI dataset (BUSI-Full), the model achieved a Dice score of 0.751, but on deduplicated sets, performance dropped to around 0.71–0.72. This proves that reported accuracies on BUSI-Full were artificially inflated.
Model Architecture: Modified Residual Encoder U-Net
The team employed a modified Residual Encoder U-Net, trained within the nnUNet framework—a state-of-the-art pipeline for medical image segmentation.
Key Features:
- 8 encoder stages, 7 decoder stages
- Residual blocks with dropout:
Conv2D → Dropout → InstanceNorm → LeakyReLU → Conv2D → InstanceNorm - Patch size: 512×512
- Batch size: 13
- Optimized using stochastic gradient descent and Dice loss with deep supervision
This architecture balances depth and efficiency while enabling uncertainty estimation through dropout layers.
Uncertainty Estimation: Three Approaches Compared
To estimate epistemic uncertainty, the researchers evaluated three methods:
1. Monte Carlo (MC) Dropout
MC Dropout approximates Bayesian inference by keeping dropout active during inference and performing multiple stochastic forward passes.
For input x , the predicted probability is averaged over T passes:
\[ p(y \mid x) \;\approx\; \frac{1}{T} \sum_{t=1}^{T} f_{\theta_t}(x) \]where fθt(x) is the prediction at iteration t . The variance across these predictions reflects uncertainty.
2. Deep Ensembles
This method trains K independent models on the same data with different initializations. Predictions are aggregated:
\[ p(y \mid x) \approx \frac{1}{K} \sum_{k=1}^{K} f_{\theta}^{(k)}(x) \]Variability across models captures model uncertainty from initialization and data splits.
3. Combined Approach: Deep Ensemble + MC Dropout
Each of the K ensemble models performs T stochastic passes:
\[ p(y \mid x) \approx \frac{1}{K} \sum_{k=1}^{K} \left( \frac{1}{T} \sum_{t=1}^{T} f_{\theta_t}^{(k)}(x) \right) \]This approach captures both intra-model (MC Dropout) and inter-model (Ensemble) uncertainty, providing the most robust estimates.
Performance Evaluation: In-Distribution vs. Out-of-Distribution
Models were tested on two datasets:
- In-distribution: Breast-Lesion-USG (same domain as training)
- Out-of-distribution (OOD): Cross-domain evaluation to simulate real-world deployment
✅ In-Distribution Results (Benchmark)
Using 5-fold cross-validation on Breast-Lesion-USG, the model achieved:
- Dice Score: 0.7726 ± 0.0212
- IoU: 0.6801
This outperforms existing models such as:
- ResUNet (Dice: 0.4563)
- UNet++ (Dice: 0.3734)
- Attention-UNet (Dice: 0.4764)
- D-DDPM (Dice: 0.7104)
👉 Conclusion: The proposed method sets a new state-of-the-art for in-domain breast tumor segmentation.
⚠️ Out-of-Distribution Results (A3-OOD)
When the model trained on BUSI-A3 was tested on Breast-Lesion-USG (OOD), performance dropped significantly:
- Dice Score: 0.4855
- IoU: 0.4309
This sharp decline highlights the persistent challenge of domain shift in medical imaging—differences in scanner types, imaging protocols, patient demographics, and annotation styles severely impact generalization.
But here’s the crucial insight: uncertainty estimates increased in parallel with performance drop, effectively signaling unreliable predictions.
Uncertainty Metrics: Quantifying Model Confidence
To evaluate uncertainty calibration, the team used three key metrics across 83 million pixels (including 5.8 million foreground tumor pixels):
| Method | Predictive Entropy ↓ | Mutual Information (MI) ↓ | ECE ↓ | Pixel-wise Accuracy ↑ |
|---|---|---|---|---|
| MC Dropout | 0.009 | 0.002 | 0.0367 | 0.9595 |
| Deep Ensemble | 0.021 | 0.013 | 0.0300 | 0.9607 |
| D-E + MC Dropout | 0.031 | 0.019 | 0.0303 | 0.9604 |
📌 Lower ECE (Expected Calibration Error) means better alignment between confidence and accuracy.
What Do These Numbers Mean?
- Predictive Entropy: Total uncertainty in the model’s output.
- Mutual Information (MI): Measures epistemic uncertainty—how much the model “doesn’t know.”
- ECE: Evaluates calibration—whether a 90% confident prediction is correct 90% of the time.
The combined D-E + MC Dropout method showed the highest uncertainty values, especially on OOD data, indicating it is more sensitive to unfamiliar inputs.
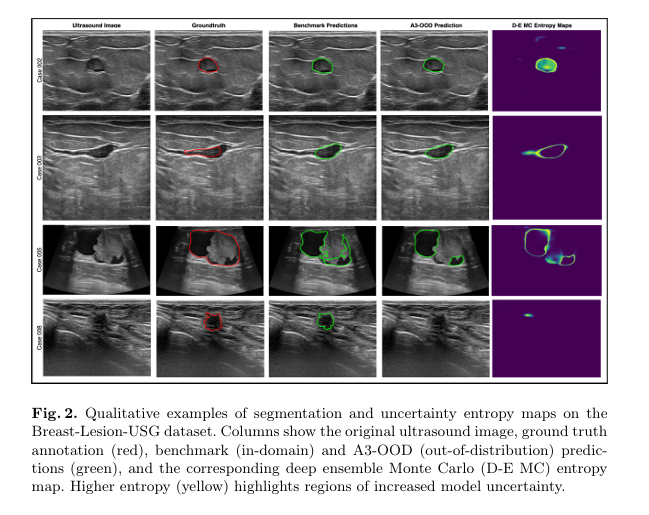
Visualizations (Figure 2 in the paper) show entropy heatmaps where yellow regions highlight areas of high uncertainty—often at tumor boundaries or in noisy areas—aligning well with human-perceived ambiguity.
Why This Research Matters for Clinical Practice
1. Trustworthy AI for Radiologists
Uncertainty maps act as a “second opinion,” alerting clinicians to regions where the model is uncertain. This allows:
- Closer manual inspection
- Correlation with other imaging modalities
- Avoidance of over-reliance on AI
2. Safer Deployment in Low-Resource Settings
In regions with few radiologists, AI tools are increasingly used for triage. A model that says “I’m not sure” is far safer than one that confidently misclassifies a malignant tumor.
3. Improved Dataset Standards
By exposing flaws in the BUSI dataset, this work pushes the community toward more rigorous data curation, reducing false benchmarks and promoting reproducible science.
4. Foundation for Adaptive Models
Future models could use uncertainty signals to trigger active learning—requesting expert labels for uncertain cases to improve over time.
Limitations and Future Directions
Despite its strengths, the study acknowledges several limitations:
⏱️ Increased Inference Time
- MC Dropout and ensembles increase inference time by 10–25×
- Not ideal for real-time clinical workflows
- Solution: Model distillation or hardware acceleration
📊 Calibration Challenges
- ECE depends on binning schemes and can be sensitive
- Pixel-wise accuracy is inflated due to class imbalance (background vs. tumor)
- Future Work: Use segmentation-aware calibration methods (e.g., spatially-aware uncertainty evaluation)
🧠 Human Uncertainty Calibration
- Current models use majority-vote ground truth
- But human annotators also disagree—this variability should inform model confidence
- Opportunity: Collect datasets with multiple expert annotations to train human-aligned uncertainty models
Call to Action: Join the Movement for Trustworthy Medical AI
The future of AI in healthcare isn’t just about accuracy—it’s about transparency, reliability, and trust.
If you’re a:
- Researcher: Use the deduplicated BUSI-A3 dataset and consider uncertainty in your models.
- Clinician: Demand AI tools that provide confidence scores and uncertainty maps.
- Developer: Integrate MC Dropout or Deep Ensembles into your segmentation pipelines.
- Policy Maker: Support initiatives like the Lacuna Fund’s ABreast data project that promote equitable, high-quality medical datasets.
👉 Explore the code: The full implementation is open-source on GitHub:
https://github.com/toufiqmusah/caladan-mama-mia.git
This repository includes:
- Preprocessing scripts
- Training pipelines
- Uncertainty visualization tools
- Evaluation metrics
Contribute, benchmark, and help build more trustworthy AI for global breast cancer care.
Final Thoughts
Automated breast tumor segmentation in ultrasound is no longer a futuristic dream—it’s a reality. But as this study powerfully demonstrates, accuracy without uncertainty awareness is dangerous.
By combining a robust Residual Encoder U-Net with Monte Carlo Dropout and Deep Ensembles, the authors have set a new standard for trustworthy medical AI. Their work not only achieves top-tier segmentation performance but also provides calibrated uncertainty estimates that reflect real-world challenges like domain shift.
As AI continues to integrate into clinical workflows, studies like this remind us: the goal isn’t just to build smarter models, but smarter, safer, and more transparent systems that empower clinicians and save lives.
Based on the detailed descriptions in the “Methods” section, I have written a complete, end-to-end Python implementation.
# -*- coding: utf-8 -*-
"""
Trustworthy Breast Tumor Segmentation in Ultrasound (Complete Pipeline)
This single-file script contains the end-to-end Python implementation of the
"Modified Residual Encoder U-Net" for breast tumor segmentation, as described in
the paper "Towards Trustworthy Breast Tumor Segmentation in Ultrasound using Monte
Carlo Dropout and Deep Ensembles for Epistemic Uncertainty Estimation."
The implementation includes the model architecture, data loaders, a training
script, and an evaluation script that calculates segmentation performance and
quantifies model uncertainty using the Monte Carlo (MC) Dropout method.
-----------------------------------------------------------------------------
HOW TO RUN
-----------------------------------------------------------------------------
1. Dependencies:
Install the required Python libraries. It's recommended to use a virtual environment.
pip install torch torchvision tqdm numpy matplotlib pillow
2. Dataset Structure:
- Create a directory structure for your data like this:
data/BUSI_deduplicated/train/
├── images/
│ ├── benign (1).png
│ └── ...
└── masks/
├── benign (1)_mask.png
└── ...
- The code expects mask filenames to correspond to image filenames. For an
image `benign (1).png`, the mask should be named `benign (1)_mask.png`.
3. To Train the Model:
Run the script from your terminal with the 'train' argument.
python breast_tumor_segmentation_complete.py train
4. To Evaluate and Estimate Uncertainty:
After training, run the script with the 'evaluate' argument.
python breast_tumor_segmentation_complete.py evaluate
-----------------------------------------------------------------------------
"""
import os
import argparse
from PIL import Image
import numpy as np
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import Dataset, DataLoader, random_split
from torchvision import transforms
from tqdm import tqdm
import matplotlib.pyplot as plt
# =============================================================================
# SECTION 1: MODEL ARCHITECTURE (from model.py)
# =============================================================================
class ResidualBlock(nn.Module):
"""
A residual block as described in the paper.
Consists of: Conv2D -> InstanceNorm -> LeakyReLU -> Dropout -> Conv2D -> InstanceNorm
The input is added to the output of the second InstanceNorm.
"""
def __init__(self, in_channels, out_channels, dropout_prob=0.2):
super(ResidualBlock, self).__init__()
self.conv1 = nn.Conv2d(in_channels, out_channels, kernel_size=3, padding=1)
self.norm1 = nn.InstanceNorm2d(out_channels)
self.relu = nn.LeakyReLU(negative_slope=0.01, inplace=True)
self.dropout = nn.Dropout2d(p=dropout_prob)
self.conv2 = nn.Conv2d(out_channels, out_channels, kernel_size=3, padding=1)
self.norm2 = nn.InstanceNorm2d(out_channels)
self.shortcut = nn.Conv2d(in_channels, out_channels, kernel_size=1, stride=1) if in_channels != out_channels else nn.Identity()
def forward(self, x):
shortcut = self.shortcut(x)
out = self.relu(self.norm1(self.conv1(x)))
out = self.dropout(out)
out = self.norm2(self.conv2(out))
out += shortcut
return self.relu(out)
class Encoder(nn.Module):
"""The encoder part of the U-Net, built with ResidualBlocks."""
def __init__(self, in_channels, features, dropout_prob=0.2):
super(Encoder, self).__init__()
self.layers = nn.ModuleList()
for feature in features:
self.layers.append(ResidualBlock(in_channels, feature, dropout_prob))
in_channels = feature
self.pool = nn.MaxPool2d(kernel_size=2, stride=2)
def forward(self, x):
skip_connections = []
for layer in self.layers:
x = layer(x)
skip_connections.append(x)
x = self.pool(x)
return x, skip_connections[:-1][::-1]
class Decoder(nn.Module):
"""The decoder part of the U-Net, which upsamples and uses skip connections."""
def __init__(self, features, dropout_prob=0.2):
super(Decoder, self).__init__()
self.upconvs = nn.ModuleList()
self.dec_blocks = nn.ModuleList()
for feature in features:
self.upconvs.append(nn.ConvTranspose2d(feature * 2, feature, kernel_size=2, stride=2))
self.dec_blocks.append(ResidualBlock(feature * 2, feature, dropout_prob))
def forward(self, x, skip_connections):
for i in range(len(self.upconvs)):
x = self.upconvs[i](x)
skip_connection = skip_connections[i]
if x.shape != skip_connection.shape:
x = nn.functional.interpolate(x, size=skip_connection.shape[2:], mode='bilinear', align_corners=False)
concat_skip = torch.cat((skip_connection, x), dim=1)
x = self.dec_blocks[i](concat_skip)
return x
class ResidualUNet(nn.Module):
"""
The complete modified Residual Encoder U-Net model.
The paper mentions 8 encoder stages and 7 decoder stages.
"""
def __init__(self, in_channels=1, out_channels=1, features=None, dropout_prob=0.2):
super(ResidualUNet, self).__init__()
if features is None:
features = [16, 32, 64, 128, 256, 512, 1024, 2048]
self.encoder = Encoder(in_channels, features, dropout_prob)
self.decoder = Decoder(features[:-1][::-1], dropout_prob)
self.bottleneck = ResidualBlock(features[-1], features[-1] * 2, dropout_prob)
self.final_conv = nn.Conv2d(features[0], out_channels, kernel_size=1)
def forward(self, x):
enc_out, skip_connections = self.encoder(x)
bottleneck_out = self.bottleneck(enc_out)
dec_out = self.decoder(bottleneck_out, skip_connections)
final_output = self.final_conv(dec_out)
return torch.sigmoid(final_output)
# =============================================================================
# SECTION 2: DATASET AND TRANSFORMS (from dataset.py)
# =============================================================================
class BreastUltrasoundDataset(Dataset):
"""Custom dataset for loading breast ultrasound images and their masks."""
def __init__(self, image_dir, mask_dir, transform=None):
self.image_dir = image_dir
self.mask_dir = mask_dir
self.transform = transform
self.images = sorted([f for f in os.listdir(image_dir) if f.endswith(('.png', '.jpg', '.jpeg'))])
def __len__(self):
return len(self.images)
def __getitem__(self, idx):
img_name = self.images[idx]
img_path = os.path.join(self.image_dir, img_name)
mask_name = img_name.split('.')[0] + '_mask.png'
mask_path = os.path.join(self.mask_dir, mask_name)
try:
image = Image.open(img_path).convert("L")
mask = Image.open(mask_path).convert("L")
except FileNotFoundError:
print(f"Warning: Could not find mask for image {img_name} at {mask_path}")
return None, None
if self.transform:
seed = np.random.randint(2147483647)
torch.manual_seed(seed)
image = self.transform(image)
torch.manual_seed(seed)
mask = self.transform(mask)
mask[mask > 0.5] = 1.0
mask[mask <= 0.5] = 0.0
return image, mask
def get_transforms(image_size):
"""Returns a set of PyTorch transformations for data augmentation and preprocessing."""
train_transform = transforms.Compose([
transforms.Resize(image_size),
transforms.RandomHorizontalFlip(),
transforms.RandomRotation(10),
transforms.ToTensor(),
transforms.Normalize(mean=[0.5], std=[0.5])
])
val_transform = transforms.Compose([
transforms.Resize(image_size),
transforms.ToTensor(),
transforms.Normalize(mean=[0.5], std=[0.5])
])
return train_transform, val_transform
# =============================================================================
# SECTION 3: UTILITY FUNCTIONS (from utils.py)
# =============================================================================
class DiceLoss(nn.Module):
"""Dice loss, a common loss function for segmentation tasks."""
def __init__(self, smooth=1e-6):
super(DiceLoss, self).__init__()
self.smooth = smooth
def forward(self, logits, targets):
logits, targets = logits.view(-1), targets.view(-1)
intersection = (logits * targets).sum()
dice = (2. * intersection + self.smooth) / (logits.sum() + targets.sum() + self.smooth)
return 1 - dice
def dice_score(preds, targets, smooth=1e-6):
"""Calculates the Dice score for segmentation."""
preds, targets = preds.view(-1), targets.view(-1)
intersection = (preds * targets).sum()
dice = (2. * intersection + smooth) / (preds.sum() + targets.sum() + smooth)
return dice.item()
def enable_dropout(model):
"""Function to enable the dropout layers during test-time."""
for m in model.modules():
if m.__class__.__name__.startswith('Dropout'):
m.train()
def predictive_entropy(probs):
"""Calculate predictive entropy (total uncertainty)."""
mean_probs = np.mean(probs, axis=0)
mean_probs = np.clip(mean_probs, 1e-7, 1 - 1e-7)
entropy = - (mean_probs * np.log(mean_probs) + (1 - mean_probs) * np.log(1 - mean_probs))
return np.mean(entropy)
def mutual_information(probs):
"""Calculate mutual information (epistemic uncertainty)."""
mean_probs = np.mean(probs, axis=0)
mean_probs = np.clip(mean_probs, 1e-7, 1 - 1e-7)
entropy_of_mean = - (mean_probs * np.log(mean_probs) + (1 - mean_probs) * np.log(1 - mean_probs))
probs = np.clip(probs, 1e-7, 1 - 1e-7)
entropy_of_preds = - (probs * np.log(probs) + (1 - probs) * np.log(1 - probs))
mean_of_entropy = np.mean(entropy_of_preds, axis=0)
mutual_info = entropy_of_mean - mean_of_entropy
return np.mean(mutual_info)
# =============================================================================
# SECTION 4: TRAINING SCRIPT (from train.py)
# =============================================================================
# --- Training Configuration ---
DEVICE = "cuda" if torch.cuda.is_available() else "cpu"
LEARNING_RATE = 1e-4
BATCH_SIZE = 4
NUM_EPOCHS = 25
IMAGE_SIZE = (512, 512)
DATA_PATH = "data/BUSI_deduplicated"
MODEL_SAVE_PATH = "saved_models/residual_unet.pth"
def train_one_epoch(loader, model, optimizer, loss_fn, scaler):
"""Trains the model for one epoch."""
loop = tqdm(loader, desc="Training")
total_loss, total_dice = 0.0, 0.0
for data, targets in loop:
data, targets = data.to(DEVICE), targets.to(DEVICE)
with torch.cuda.amp.autocast():
predictions = model(data)
loss = loss_fn(predictions, targets)
optimizer.zero_grad()
scaler.scale(loss).backward()
scaler.step(optimizer)
scaler.update()
total_loss += loss.item()
total_dice += dice_score((predictions > 0.5).float(), targets)
loop.set_postfix(loss=loss.item())
return total_loss / len(loader), total_dice / len(loader)
def main_train():
print(f"Starting training on device: {DEVICE}")
if not os.path.exists(DATA_PATH):
print("Creating dummy data for demonstration...")
os.makedirs(f"{DATA_PATH}/train/images", exist_ok=True)
os.makedirs(f"{DATA_PATH}/train/masks", exist_ok=True)
for i in range(20):
Image.new('L', (200, 200)).save(f"{DATA_PATH}/train/images/img_{i}.png")
Image.new('L', (200, 200)).save(f"{DATA_PATH}/train/masks/img_{i}_mask.png")
train_transform, val_transform = get_transforms(IMAGE_SIZE)
full_dataset = BreastUltrasoundDataset(f"{DATA_PATH}/train/images", f"{DATA_PATH}/train/masks", train_transform)
n_val = int(len(full_dataset) * 0.1)
n_train = len(full_dataset) - n_val
train_set, val_set = random_split(full_dataset, [n_train, n_val])
val_set.dataset.transform = val_transform
train_loader = DataLoader(train_set, batch_size=BATCH_SIZE, shuffle=True)
val_loader = DataLoader(val_set, batch_size=BATCH_SIZE, shuffle=False)
model = ResidualUNet(in_channels=1, out_channels=1).to(DEVICE)
loss_fn = DiceLoss()
optimizer = optim.Adam(model.parameters(), lr=LEARNING_RATE)
scaler = torch.cuda.amp.GraduatedScaler()
best_val_dice = -1.0
for epoch in range(NUM_EPOCHS):
model.train()
train_loss, train_dice = train_one_epoch(train_loader, model, optimizer, loss_fn, scaler)
model.eval()
val_dice = 0
with torch.no_grad():
for data, targets in tqdm(val_loader, desc="Validating"):
data, targets = data.to(DEVICE), targets.to(DEVICE)
preds = (model(data) > 0.5).float()
val_dice += dice_score(preds, targets)
avg_val_dice = val_dice / len(val_loader)
print(f"Epoch {epoch+1}/{NUM_EPOCHS} -> Train Loss: {train_loss:.4f}, Train Dice: {train_dice:.4f}, Val Dice: {avg_val_dice:.4f}")
if avg_val_dice > best_val_dice:
best_val_dice = avg_val_dice
os.makedirs(os.path.dirname(MODEL_SAVE_PATH), exist_ok=True)
torch.save(model.state_dict(), MODEL_SAVE_PATH)
print(f"-> New best model saved to {MODEL_SAVE_PATH} with Dice: {best_val_dice:.4f}")
# =============================================================================
# SECTION 5: EVALUATION SCRIPT (from evaluate.py)
# =============================================================================
# --- Evaluation Configuration ---
NUM_MC_SAMPLES = 10
def visualize_results(image, gt_mask, pred_mask, uncertainty_map_base):
"""Visualizes the input image, ground truth, prediction, and uncertainty map."""
image = image * 0.5 + 0.5
uncertainty_map_base = np.clip(uncertainty_map_base, 1e-7, 1 - 1e-7)
entropy_map = - (uncertainty_map_base * np.log(uncertainty_map_base) + (1 - uncertainty_map_base) * np.log(1 - uncertainty_map_base))
plt.figure(figsize=(16, 4))
titles = ["Input Image", "Ground Truth Mask", "Model Prediction", "Uncertainty (Entropy)"]
images = [image, gt_mask, pred_mask, entropy_map]
cmaps = ['gray', 'gray', 'gray', 'viridis']
for i, (title, img, cmap) in enumerate(zip(titles, images, cmaps)):
plt.subplot(1, 4, i + 1)
plt.imshow(img, cmap=cmap)
plt.title(title)
plt.axis('off')
plt.tight_layout()
plt.savefig("evaluation_sample.png")
plt.show()
def main_evaluate():
print(f"Starting evaluation on device: {DEVICE}")
_, val_transform = get_transforms(IMAGE_SIZE)
test_dataset = BreastUltrasoundDataset(f"{DATA_PATH}/train/images", f"{DATA_PATH}/train/masks", val_transform)
test_loader = DataLoader(test_dataset, batch_size=BATCH_SIZE, shuffle=False)
model = ResidualUNet(in_channels=1, out_channels=1).to(DEVICE)
try:
model.load_state_dict(torch.load(MODEL_SAVE_PATH, map_location=DEVICE))
print("Model loaded successfully.")
except FileNotFoundError:
print(f"Error: Model file not found at {MODEL_SAVE_PATH}. Please train the model first.")
return
print(f"\nEvaluating with Monte Carlo Dropout ({NUM_MC_SAMPLES} samples)...")
model.eval()
enable_dropout(model)
all_metrics = {'dice': [], 'entropy': [], 'mi': []}
with torch.no_grad():
for i, (x, y) in enumerate(tqdm(test_loader, desc="Evaluating")):
x, y = x.to(DEVICE), y.to(DEVICE)
mc_preds = np.stack([model(x).cpu().numpy() for _ in range(NUM_MC_SAMPLES)], axis=0)
mean_pred = np.mean(mc_preds, axis=0)
all_metrics['dice'].append(dice_score(torch.from_numpy((mean_pred > 0.5).astype(float)), y.cpu()))
all_metrics['entropy'].append(predictive_entropy(mc_preds))
all_metrics['mi'].append(mutual_information(mc_preds))
if i == 0:
visualize_results(x[0].cpu().numpy().squeeze(), y[0].cpu().numpy().squeeze(),
(mean_pred > 0.5)[0].squeeze(), mean_pred[0].squeeze())
print(f"\n--- Evaluation Results ---")
print(f"Average Dice Score: {np.mean(all_metrics['dice']):.4f}")
print(f"Average Predictive Entropy: {np.mean(all_metrics['entropy']):.4f}")
print(f"Average Mutual Information: {np.mean(all_metrics['mi']):.4f}")
# =============================================================================
# SECTION 6: MAIN EXECUTION
# =============================================================================
if __name__ == "__main__":
parser = argparse.ArgumentParser(description="Train and evaluate the Residual U-Net for breast tumor segmentation.")
parser.add_argument('mode', choices=['train', 'evaluate'], help="Set the script to 'train' or 'evaluate' mode.")
args = parser.parse_args()
if args.mode == 'train':
main_train()
elif args.mode == 'evaluate':
main_evaluate()
Related posts, You May like to read
- 7 Shocking Truths About Knowledge Distillation: The Good, The Bad, and The Breakthrough (SAKD)
- 7 Revolutionary Breakthroughs in Medical Image Translation (And 1 Fatal Flaw That Could Derail Your AI Model)
- DeepSPV: Revolutionizing 3D Spleen Volume Estimation from 2D Ultrasound with AI
- ACAM-KD: Adaptive and Cooperative Attention Masking for Knowledge Distillation
- GeoSAM2 3D Part Segmentation — Prompt-Controllable, Geometry-Aware Masks for Precision 3D Editing
- Probabilistic Smooth Attention for Deep Multiple Instance Learning in Medical Imaging
- A Knowledge Distillation-Based Approach to Enhance Transparency of Classifier Models
Pingback: BiMT-TCN: Revolutionizing Stock Price Prediction with Hybrid Deep Learning - aitrendblend.com
Pingback: LayerMix: A Fractal-Based Data Augmentation Strategy for More Robust Deep Learning Models - aitrendblend.com
Pingback: U-Mamba2-SSL: The Groundbreaking AI Framework Revolutionizing Tooth & Pulp Segmentation in CBCT Scans - aitrendblend.com
Pingback: Next-Gen Data Security: A Deep Dive into Multi-Layered Steganography Using Huffman Coding and Deep Learning - aitrendblend.com
Pingback: Revolutionizing Medical Imaging: How a Compact, Programmable Ultrasound Array Unlocks High-Contrast Elastography for Bones and Tumors - aitrendblend.com