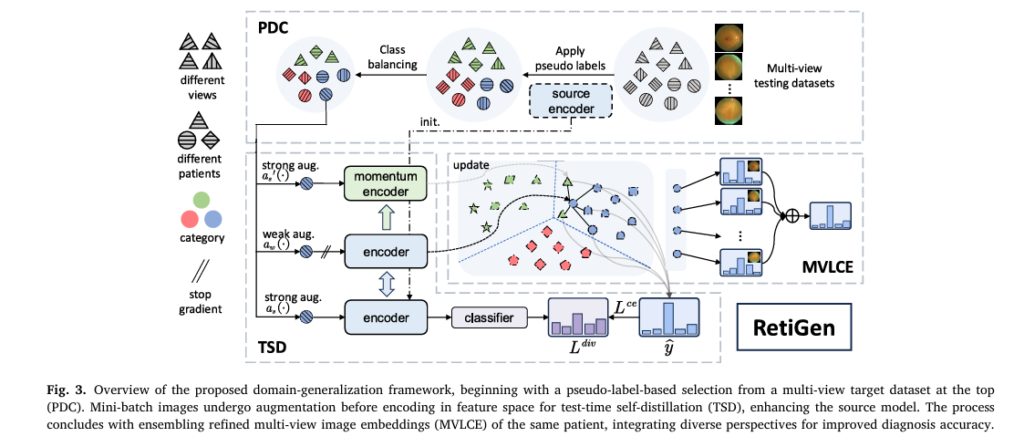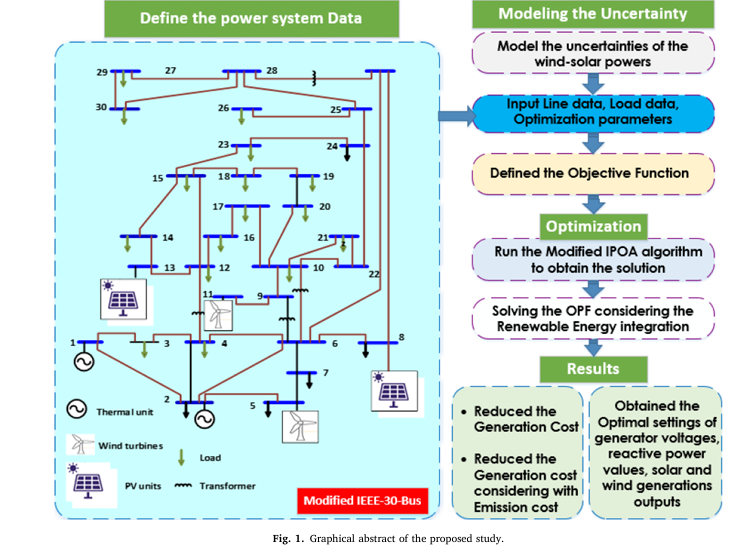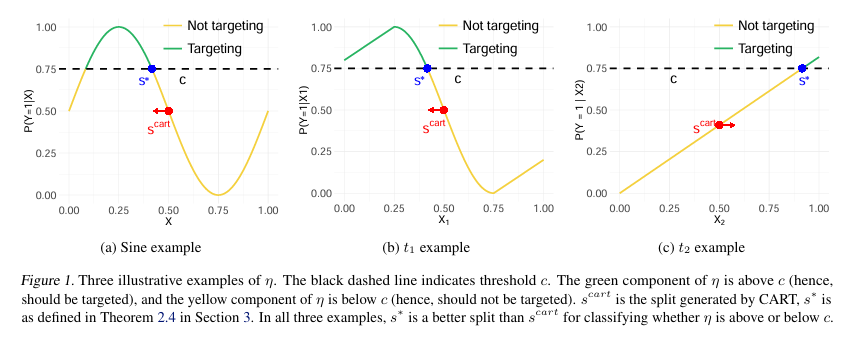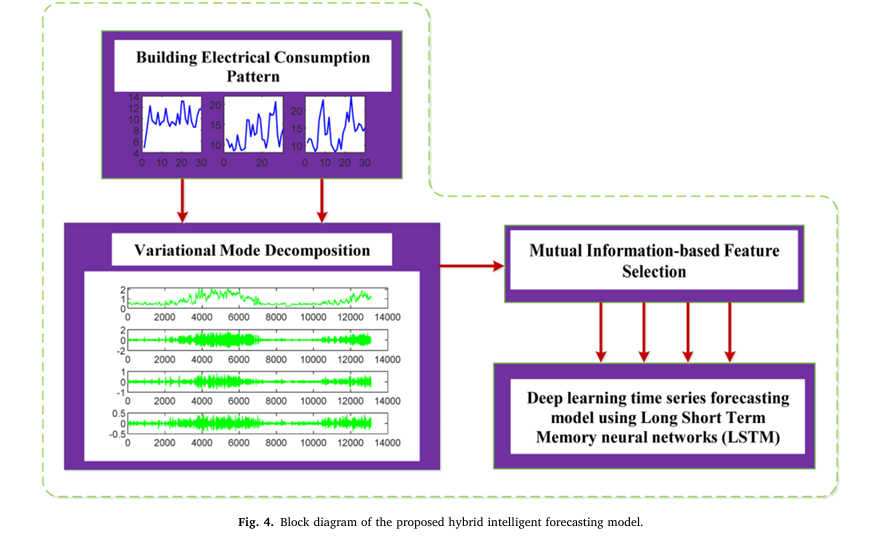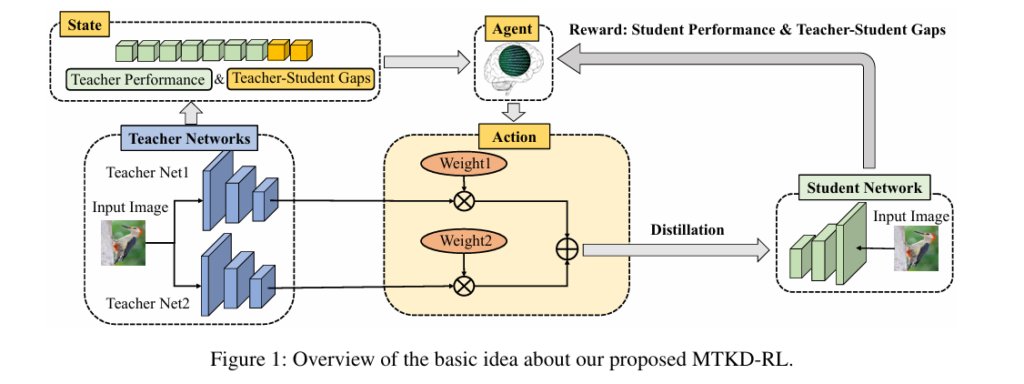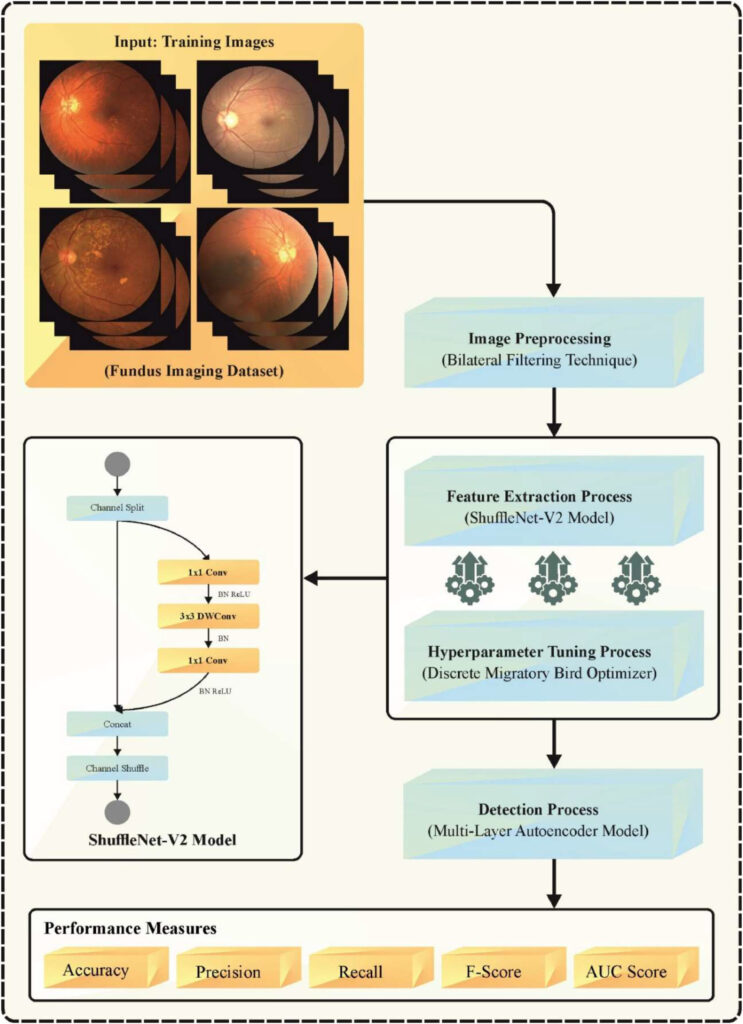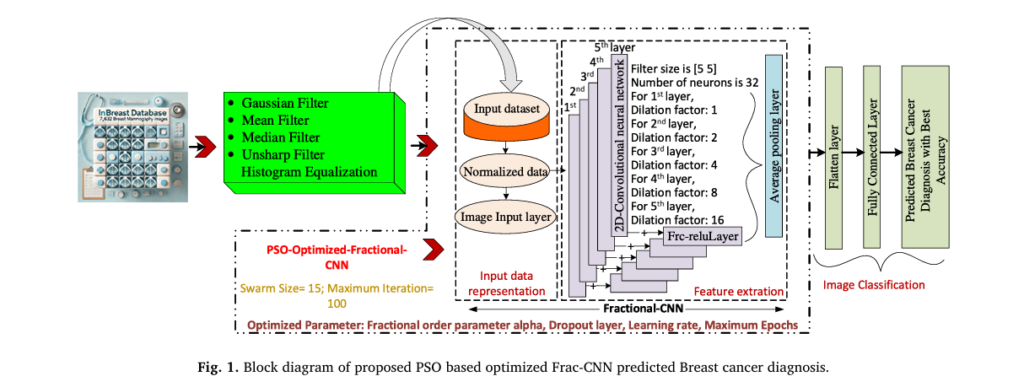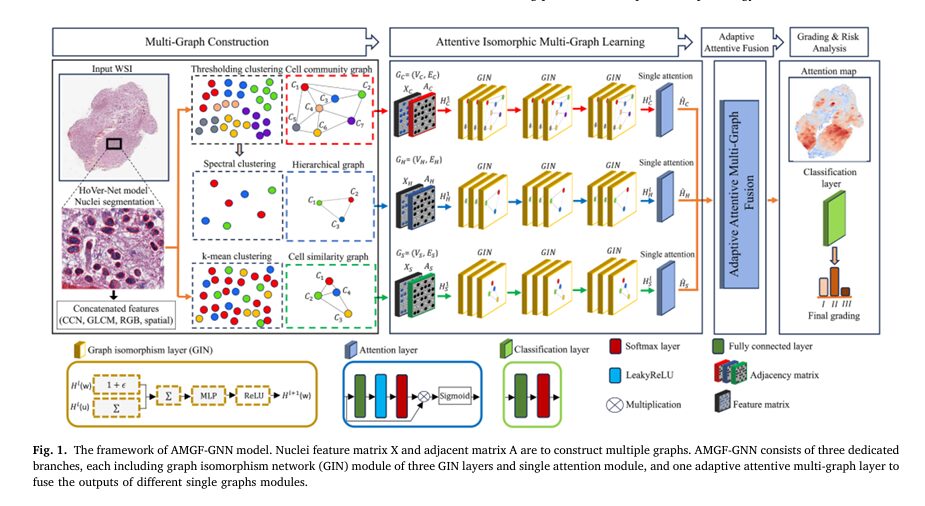
Pixel-Level Concrete Crack Quantification: A Breakthrough in Structural Health Monitoring
Concrete cracks are more than just surface imperfections—they’re early warning signs of structural degradation that can compromise the safety and longevity of buildings, bridges, roads, and other critical infrastructure. Traditional inspection methods often rely on manual assessments, which are time-consuming, subjective, and prone to human error. However, recent advancements in computer vision and deep learning […]