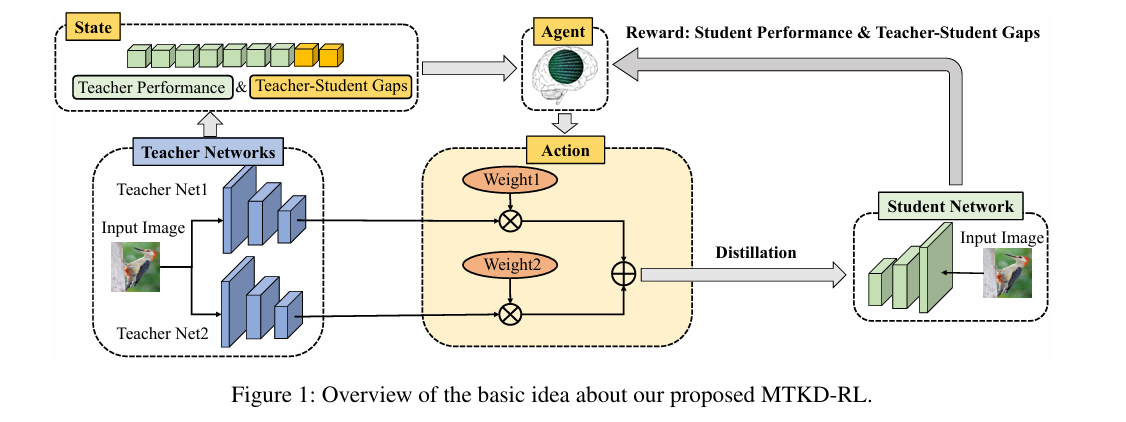
MTKD-RL from the Institute of Computing Technology, Chinese Academy of Sciences — an RL agent arbitrates teacher weights dynamically, improving student accuracy across image classification, object detection, and semantic segmentation.
Key Points
- Chuanguang Yang and colleagues at the Institute of Computing Technology, Chinese Academy of Sciences propose MTKD-RL, a framework that uses a reinforcement learning agent to assign sample-wise weights to each teacher in a multi-teacher distillation setup, published at AAAI 2025.
- The agent observes a five-component state for each input sample, combining teacher performance signals (feature representation, logit vector, cross-entropy loss) with teacher-student gap signals (cosine similarity and KL divergence), then outputs teacher weights as a continuous action.
- Student performance after each training batch feeds back as the reward, so the agent is optimized directly toward the outcome that matters: a better student, not just a more confident teacher.
- On CIFAR-100 with four CNN students, MTKD-RL outperforms the prior best multi-teacher KD methods (CA-MKD and MMKD) by an average of 0.31% and 0.33%, respectively.
- On ImageNet, MTKD-RL improves ResNet-18 by 2.47% and ResNet-34 by 3.13% over the baseline without distillation, and exceeds the best competitor MMKD by 0.49% and 0.71%.
- Training overhead compared to equal-weight distillation is modest — 15% more time and 14% more memory — and the framework is 13% faster than CA-MKD while achieving better accuracy.
The Real Problem with Multiple Teachers
Knowledge distillation has a clean single-teacher story. One large network, trained and frozen. One small network, learning to mimic it. The loss function pushes the student’s outputs toward the teacher’s outputs. Simple.
Multi-teacher distillation complicates this in a specific way that the literature has not fully resolved. When you have a pool of teachers, each brings something different. One might be a wide ResNet with strong semantic representations. Another might be a compact but well-calibrated model that the student can actually follow. A third might be dominant on certain image categories and mediocre on others. The question of how to weight their contributions is not cosmetic. Get it wrong, and you can actively harm the student by overemphasizing a teacher whose knowledge is too abstract or whose errors on the current sample happen to be large.
The two obvious fixes have both been tried. You can weight teachers by their confidence (entropy-based methods like EB-KD from Kwon et al.) or by cross-entropy against ground truth labels (CA-MKD from Zhang, Chen, and Wang 2022). These are sensible but they look at the teacher alone, not at the teacher-student relationship. Alternatively, you can use the gradient space to derive weights (AE-KD from Du et al. 2020), or a meta-learning mechanism over a hard buffer of teacher features and logits (MMKD from Zhang, Chen, and Wang 2023). These capture more information but still do not close the feedback loop between teacher weighting decisions and actual student performance.
Yang et al. from the Chinese Academy of Sciences close that loop. Their paper, arXiv:2502.18510, is an AAAI 2025 contribution that frames multi-teacher weight optimization as a full reinforcement learning problem. The student’s accuracy improvement becomes the reward signal. The agent changes its weighting policy based on what actually worked.
Every previous multi-teacher KD method generates weights from either teacher performance or teacher-student gaps, but not both together, and none of them closes the loop by using the student’s actual performance as feedback. MTKD-RL does all three simultaneously.
How the Multi-Teacher Loss Is Structured
Before examining the RL machinery, it helps to see what is being optimized. Standard multi-teacher KD extends the single-teacher loss by summing over M teachers, each with its own logit-level and feature-level weight.
$$\mathcal{L}_{\text{MTKD}} = H(y^S_i, y_i) + \alpha \sum_{m=1}^{M} w^m_{l,i} D_{\text{KL}}(y^S_i, y^{T_m}_i) + \beta \sum_{m=1}^{M} w^m_{f,i} D_{\text{dis}}(F^S_i, F^{T_m}_i)$$
Here \(y_i\) is the ground truth label, \(y^S_i\) and \(y^{T_m}_i\) are the student and m-th teacher logit vectors, and \(F^S_i\) and \(F^{T_m}_i\) are their feature representations. \(D_{\text{KL}}\) is KL divergence for the logit level and \(D_{\text{dis}}\) is a distance metric for the feature level. The weights \(\{w^m_{l,i}, w^m_{f,i}\}\) are what the RL agent learns to set per sample. The authors use the original Hinton KD loss for logit distillation and FitNet for feature distillation as defaults, with \(\alpha = 1\) and \(\beta = 5\).
The thing to notice here is the subscript \(i\). The weights are not global constants. They change per input sample. A cat image and a truck image can and should draw differently on each teacher, and the agent is given the signal to discover this automatically.
The State the Agent Observes
Every reinforcement learning system needs a state representation that gives the agent enough information to make a good decision. The state design in MTKD-RL is one of the paper’s more careful contributions.
For each input sample \(x_i\) and each teacher \(T_m\), the agent receives a concatenated embedding containing five components. The first three capture teacher performance. The feature representation \(f^{T_m}_i\) encodes semantic content from the teacher’s penultimate layer. The logit vector \(z^{T_m}_i\) gives the teacher’s full class probability distribution. The cross-entropy loss \(L^{T_m}_{CE} = H(y^{T_m}_i, y_i)\) measures how accurately the teacher predicts the ground truth on this specific sample.
The fourth and fifth components capture teacher-student gaps. Cosine similarity between the student feature and teacher feature measures alignment in representation space:
$$\text{cos}^{T_m}_i = r(f^S_i) \cdot f^{T_m}_i \,/\, \|r(f^S_i)\| \|f^{T_m}_i\|$$
where \(r(\cdot)\) is a linear projector that aligns the student and teacher embedding dimensions. The fifth component is the KL divergence between the student and teacher logit distributions, measuring the probability-level gap.
The full state for the m-th teacher on sample \(x_i\) is then the concatenation of all five:
$$s^m_i = \big[f^{T_m}_i \;\|\; z^{T_m}_i \;\|\; L^{T_m}_{CE} \;\|\; \cos^{T_m}_i \;\|\; KL^{T_m}_i\big]$$
This is not a small state vector. For a ResNet teacher with hundreds of embedding dimensions plus logits over a hundred classes plus scalar values, the full state has significant dimensionality. The ablation study in the paper makes the motivation precise: using only teacher performance gives 1.01% gain over equal weighting, using only teacher-student gaps gives 0.63%, but combining both reaches 1.56%. Each half contributes something the other cannot replace.
From State to Action — What the Agent Actually Produces
The agent \(\pi_{\theta_m}(s^m_i)\) is a small feedforward network with linear layers, ReLU activations, and a final softmax, one per teacher. Its output is a weight vector \(w^m_i\) with values in (0,1). These become the distillation weights in Equation 1.
The full action is a weighted fusion of three weight generation strategies. The generator produces its own learned weights through the feedforward network. A confidence-aware strategy, inspired by CA-MKD, weights teachers inversely by how wrong they are on the current sample. A divergence-aware strategy weights by how far the student is from each teacher. The final weight vector blends these three equally at one third each, a design the authors found to work well without additional tuning.
“Our MTKD-RL method constructs both the teacher performance and teacher-student gaps as the state, optimized by the student performance as rewards, leading to more meaningful teacher weights.”Yang et al., arXiv:2502.18510
The Reward and How the Agent Learns
An episode is one training batch of B samples. After the student processes the batch with the agent-generated weights, the reward for teacher m on sample i is constructed from three negative loss terms:
$$R^m_i = -H(y^S_i, y_i) – \alpha D_{\text{KL}}(y^S_i, y^{T_m}_i) – \beta D_{\text{dis}}(F^S_i, F^{T_m}_i)$$
The negative sign is deliberate. A lower loss means a better student, so the agent earns higher reward when the student improves. The reward is then normalized before the policy gradient update:
$$\bar{R}^m_i = \frac{R^m_i – \min_k R^k_i}{\max_k R^k_i – \min_k R^k_i} – \frac{1}{M} \sum_{k=1}^{M} R^k_i$$
The min-max rescaling brings rewards to a common scale. Subtracting the mean across all M teachers means the agent gets positive reinforcement only when a teacher outperforms the average, and negative reinforcement when it underperforms. This relative framing is what makes the agent actually learn to discriminate between teachers rather than uniformly encouraging all of them.
The policy gradient update is straightforward. For each teacher m, the agent’s parameters update in proportion to the normalized reward and the gradient of the policy with respect to those parameters:
$$\theta_m \leftarrow \theta_m – \eta \sum_{i=1}^{B} \bar{R}^m_i \nabla_{\theta_m} \pi_{\theta_m}(s^m_i)$$
The training procedure alternates between two phases per epoch: the student trains with weights from the current agent, then the agent updates using the collected (state, action, reward) history from that epoch. Pre-training both the student and the agent for one epoch with equal weights gives the RL loop a stable starting point and avoids early training collapse.
The ablation study in Table 6(a) of the paper compares PG, DPG, DDPG, and PPO on ShuffleNetV2 on CIFAR-100. Accuracies are 78.39%, 78.16%, 78.05%, and 78.28% respectively. The differences are smaller than the variance bars. The authors conclude the method is not sensitive to the RL optimizer choice and pick the original PG for simplicity. One plausible reason for this insensitivity is that the optimization landscape for fixed-dataset teacher weighting is more stable than the non-stationary environments where advanced RL variants earn their keep.
Results Across Three Tasks
Image Classification on CIFAR-100
The CIFAR-100 experiments use a fixed teacher pool of four networks (RegNetY-400MF, RegNetX-400MF, ResNet-32×4, WRN-28-4) distilling four different student networks. The full results are below.
| Student | Baseline | AVER | CA-MKD | MMKD | MTKD-RL |
|---|---|---|---|---|---|
| RegNetX-200MF | 77.38 | 79.12 | 80.28 | 80.15 | 80.58 |
| MobileNetV2 | 69.17 | 72.67 | 74.16 | 74.35 | 74.63 |
| ShuffleNetv2 | 72.84 | 76.83 | 78.09 | 77.87 | 78.39 |
| ResNet-56 | 72.52 | 73.93 | 75.17 | 75.26 | 75.35 |
The pattern is consistent across all four students. MTKD-RL leads the field, but the margin over CA-MKD and MMKD is modest — between 0.09% and 0.47%. What this tells you is that the field is already fairly close to saturation on CIFAR-100, and incremental gains there carry less signal than they used to. The more telling evidence comes from ImageNet.
Image Classification on ImageNet
| Student | Baseline | AVER | CA-MKD | MMKD | MTKD-RL |
|---|---|---|---|---|---|
| ResNet-18 | 70.35 | 71.56 | 72.38 | 72.33 | 72.82 |
| ResNet-34 | 73.64 | 75.55 | 75.87 | 76.06 | 76.77 |
On ImageNet, the margins widen. MTKD-RL beats MMKD by 0.49% on ResNet-18 and 0.71% on ResNet-34. Those are real differences on a dataset with 1.28 million training images and a dense evaluation set. The teacher pool here is four medium-to-large CNNs (ResNet-50, ResNet-101, Wide ResNet-50-2, ResNeXt-50), a more diverse and challenging ensemble than CIFAR-100.
The Vision Transformer results follow the same trend. On DeiT-Tiny distilled from a CaiT-S24, DeiT-Small, and DeiT-Base teacher pool, MTKD-RL reaches 75.14% against MMKD’s 74.35%. On CaiT-XXS24, it reaches 79.22% versus 78.42%. The RL framework is architecture-agnostic in the sense that it runs on top of whatever backbone you choose.
Downstream Object Detection and Semantic Segmentation
Perhaps the most practically useful result is how well ImageNet-pretrained backbones transfer to downstream tasks. The authors take ResNet-18 and ResNet-34 checkpoints pretrained by MTKD-RL and fine-tune them on COCO-2017 for object detection across four detector architectures. MTKD-RL improves over the baseline by 1.1% mAP on average for ResNet-18 and 1.5% for ResNet-34, consistently across Mask-RCNN, Cascade-RCNN, RetinaNet, and Faster-RCNN.
Semantic segmentation results on Cityscapes, ADE20K, and COCO-Stuff-164K using a ResNet-34 backbone show average gains of 1.19%, 0.97%, and 1.50% respectively, both with DeepLabV3 and PSPNet heads. These results matter because they show the learned representations are genuinely richer, not just better calibrated for the ImageNet evaluation metric.
The Honest Cost Analysis
The numbers for training overhead are stated directly in the paper and deserve a clear look.
| Method | Time (s/epoch) | Memory | Acc@1 % |
|---|---|---|---|
| Baseline | 29 | 2.3G | 72.84 |
| AVER | 41 | 2.8G | 76.83 |
| CA-MKD | 54 | 2.9G | 78.09 |
| MTKD-RL | 47 | 3.2G | 78.39 |
MTKD-RL is 15% slower than AVER (equal weights) and uses 14% more memory, because it stores the episode history of (state, action, reward) tuples and runs agent updates. Compared to CA-MKD, it is 13% faster but uses 10% more memory. The accuracy gain over CA-MKD is 0.30 percentage points. Whether that trade is worthwhile depends on your compute budget and how much that 0.30% matters in your application.
What the table does not show is the one-time cost of pre-training the agent for a single epoch with equal weights. That initialization step adds to the total training time but is fixed at one epoch regardless of how long the full training run lasts.
What This Framework Gets Right — and Where the Questions Remain
The architecture has a genuine conceptual contribution. Previous methods chose a single lens to judge teacher quality: entropy, cross-entropy, gradient direction, or meta-learned features. MTKD-RL is the first to combine all five signals (feature representation, logit vector, teacher cross-entropy, cosine similarity, and KL divergence) into a unified state and then optimize the weighting policy through direct student feedback. That is a principled approach to a problem that genuinely needs multi-signal information.
The policy gradient choice is deliberately simple and the ablation confirms it works. The fact that PG, DPG, DDPG, and PPO all give similar results on CIFAR-100 is actually reassuring — it suggests the performance gains come from the framework design, not from RL algorithm tuning. This is not a case of the authors having picked the one RL algorithm that happens to work best on their benchmarks.
That said, a few open questions stand out. The teacher pool in the main experiments is fixed at four networks. Figure 2 in the paper shows performance saturating around M = 4. The authors do not explore what happens when teachers are highly similar to one another, where the gain from ensemble diversity would be smaller. The agent is also trained per teacher rather than jointly across the teacher pool, which means it cannot explicitly model teacher-teacher interactions or redundancy.
There is also the question of how the method scales to very large models. The ImageNet experiments use fairly standard CNN teachers. Whether the RL-based weighting framework adds value when teachers are large vision-language models — where the feature dimensionality of the state embedding becomes enormous — is unexplored territory.
The transfer to downstream tasks (object detection and segmentation) is a useful addition to the paper, but it only reports MTKD-RL versus the baseline without distillation. The comparison against CA-MKD or MMKD for the downstream tasks would be more informative. You can link better ImageNet accuracy to better downstream performance, but whether MTKD-RL is specifically better than its competitors at learning transferable representations, or just better at ImageNet classification, is not yet established by the paper’s experiments. That is the natural next experiment for anyone who wants to build on this work.
Practitioners who want to use this for their own distillation pipelines should consult the official code repository on GitHub for the exact hyperparameters and agent architecture details. The paper’s appendix also covers the combined confidence and divergence-aware action construction in more detail than the main text.
Complete PyTorch Implementation
The following is a complete, commented implementation of the MTKD-RL framework in PyTorch. It includes the state embedding builder, the agent network, all loss functions from the paper, the alternating training loop, and a runnable smoke test on dummy data matching the paper’s architecture choices.
""" MTKD-RL: Multi-Teacher Knowledge Distillation with Reinforcement Learning Based on: Yang et al., arXiv:2502.18510, AAAI 2025 Architecture overview: - M teacher networks (frozen) + 1 student network (trainable) - M per-teacher agents (small MLP with PG optimization) - State: [teacher feature, teacher logit, teacher CE loss, cosine similarity, KL divergence] per teacher per sample - Action: per-teacher logit and feature distillation weights in (0,1) - Reward: negative student loss (CE + KL + feature MSE) - Optimization: Policy Gradient (PG), normalized reward Defaults from paper: alpha=1, beta=5, batch_size=64 (CIFAR-100). """ import torch import torch.nn as nn import torch.nn.functional as F from torch.optim import SGD import numpy as np from typing import List, Dict, Tuple # ───────────────────────────────────────────────────────────────── # 1. AGENT NETWORK # A small MLP that maps teacher-specific state embedding -> # (logit weight, feature weight) for that teacher. # ───────────────────────────────────────────────────────────────── class TeacherAgent(nn.Module): """ Per-teacher policy agent pi_{theta_m}(s_i^m) -> weight vector w_i^m. Input : concatenated state embedding s_i^m Output : [w_logit, w_feature] each in (0, 1) via softmax Architecture: Linear -> ReLU -> two separate Linear+Softmax heads. """ def __init__(self, state_dim: int, hidden_dim: int = 256): super().__init__() self.encoder = nn.Sequential( nn.Linear(state_dim, hidden_dim), nn.ReLU(), ) # Two heads: logit-level weight and feature-level weight self.head_logit = nn.Linear(hidden_dim, 1) self.head_feature = nn.Linear(hidden_dim, 1) def forward(self, s: torch.Tensor) -> Tuple[torch.Tensor, torch.Tensor]: # s: (B, state_dim) # Returns: (w_logit (B,1), w_feature (B,1)) raw logits pre-normalization h = self.encoder(s) return self.head_logit(h), self.head_feature(h) # ───────────────────────────────────────────────────────────────── # 2. STATE BUILDER # Constructs the 5-component state per (sample, teacher) pair. # ───────────────────────────────────────────────────────────────── class StateBuilder: """ Builds state embedding s_i^m from teacher/student outputs. Components (per paper Equation 5): (1) Teacher feature representation f_i^{T_m} (2) Teacher logit vector z_i^{T_m} (3) Teacher cross-entropy loss L_CE^{T_m} [scalar] (4) Teacher-student cosine similarity [scalar] (5) Teacher-student KL divergence [scalar] """ def __init__(self, student_feat_dim: int, teacher_feat_dims: List[int], num_classes: int): self.student_feat_dim = student_feat_dim self.teacher_feat_dims = teacher_feat_dims self.num_classes = num_classes # Linear regressors r(.) to align student -> each teacher dim self.regressors = nn.ModuleList([ nn.Linear(student_feat_dim, d, bias=False) for d in teacher_feat_dims ]) def to(self, device): self.regressors = self.regressors.to(device) return self def build( self, m: int, teacher_feat: torch.Tensor, # (B, d_m) teacher_logit: torch.Tensor, # (B, C) student_feat: torch.Tensor, # (B, d_s) student_logit: torch.Tensor, # (B, C) labels: torch.Tensor, # (B,) ) -> torch.Tensor: """Returns state embedding s_i^m of shape (B, state_dim).""" B = teacher_feat.size(0) # (3) Teacher cross-entropy loss per sample -> (B, 1) t_ce = F.cross_entropy(teacher_logit, labels, reduction='none').unsqueeze(1) # (4) Cosine similarity after projecting student to teacher dim -> (B, 1) s_proj = self.regressors[m](student_feat) # (B, d_m) cos_sim = F.cosine_similarity(s_proj, teacher_feat, dim=1).unsqueeze(1) # (B,1) # (5) KL divergence per sample -> (B, 1) log_s = F.log_softmax(student_logit, dim=1) log_t = F.log_softmax(teacher_logit, dim=1) kl = F.kl_div(log_s, log_t.exp(), reduction='none').sum(dim=1, keepdim=True) # (B,1) # Concatenate all 5 components state = torch.cat([teacher_feat, teacher_logit, t_ce, cos_sim, kl], dim=1) return state # (B, d_m + C + 3) # ───────────────────────────────────────────────────────────────── # 3. MULTI-TEACHER KD LOSSES # ───────────────────────────────────────────────────────────────── def logit_kd_loss(student_logit, teacher_logit, T=4.0) -> torch.Tensor: """Hinton KD logit loss (KL divergence with temperature T), per sample.""" log_s = F.log_softmax(student_logit / T, dim=1) p_t = F.softmax(teacher_logit / T, dim=1) return F.kl_div(log_s, p_t, reduction='none').sum(dim=1) * (T ** 2) # (B,) def feature_kd_loss(student_feat, teacher_feat, regressor) -> torch.Tensor: """FitNet-style feature loss: MSE after projecting student to teacher dim. Per sample output.""" s_proj = regressor(student_feat) # (B, d_m) return F.mse_loss(s_proj, teacher_feat.detach(), reduction='none').mean(dim=1) # (B,) def compute_reward( student_logit: torch.Tensor, teacher_logit: torch.Tensor, student_feat: torch.Tensor, teacher_feat: torch.Tensor, regressor: nn.Module, labels: torch.Tensor, alpha: float = 1.0, beta: float = 5.0, ) -> torch.Tensor: """Reward R_i^m = -(CE + alpha*KL + beta*MSE) per sample. Shape (B,).""" ce = F.cross_entropy(student_logit, labels, reduction='none') kl = logit_kd_loss(student_logit, teacher_logit) mse = feature_kd_loss(student_feat, teacher_feat, regressor) return -(ce + alpha * kl + beta * mse) # ───────────────────────────────────────────────────────────────── # 4. NORMALIZED REWARD (Equation 8) # ───────────────────────────────────────────────────────────────── def normalize_rewards(rewards: List[torch.Tensor]) -> List[torch.Tensor]: """ Min-max normalize across M teachers, then subtract mean. rewards: list of M tensors each (B,) Returns: list of M tensors (B,) """ # Stack to (M, B) for easier stats R = torch.stack(rewards, dim=0) # (M, B) r_min = R.min(dim=0).values # (B,) r_max = R.max(dim=0).values # (B,) eps = 1e-8 R_norm = (R - r_min.unsqueeze(0)) / (r_max - r_min + eps).unsqueeze(0) # (M,B) R_mean = R_norm.mean(dim=0, keepdim=True) # (1, B) R_bar = R_norm - R_mean # (M, B) return [R_bar[m] for m in range(R_bar.size(0))] # ───────────────────────────────────────────────────────────────── # 5. MTKD-RL TRAINER # ───────────────────────────────────────────────────────────────── class MTKDRLTrainer: """ Manages the multi-teacher KD with RL loop. Usage: trainer = MTKDRLTrainer(student, teachers, ...) trainer.pretrain(loader, epochs=1) trainer.train(loader, epochs=200) """ def __init__( self, student: nn.Module, teachers: List[nn.Module], student_feat_dim: int, teacher_feat_dims: List[int], num_classes: int, alpha: float = 1.0, beta: float = 5.0, lr_student: float = 0.05, lr_agent: float = 1e-3, agent_hidden: int = 256, device: str = "cpu", ): self.device = torch.device(device) self.alpha = alpha self.beta = beta self.M = len(teachers) # Networks self.student = student.to(self.device) self.teachers = [t.to(self.device).eval() for t in teachers] for t in self.teachers: for p in t.parameters(): p.requires_grad = False # State builder (contains feature regressors) self.state_builder = StateBuilder( student_feat_dim, teacher_feat_dims, num_classes ).to(self.device) # State dims: teacher_feat + C (logit) + 3 (ce, cos, kl) agent_input_dims = [d + num_classes + 3 for d in teacher_feat_dims] self.agents = [ TeacherAgent(dim, agent_hidden).to(self.device) for dim in agent_input_dims ] # Optimizers self.opt_student = SGD( list(self.student.parameters()) + list(self.state_builder.regressors.parameters()), lr=lr_student, momentum=0.9, weight_decay=1e-4 ) self.opt_agents = [ SGD(agent.parameters(), lr=lr_agent, momentum=0.9) for agent in self.agents ] def _get_teacher_outputs(self, x): """Returns list of (feat, logit) tuples, one per teacher.""" outputs = [] with torch.no_grad(): for t in self.teachers: feat, logit = t(x) # assumes teacher returns (feat, logit) outputs.append((feat, logit)) return outputs def _softmax_normalize(self, raw_weights: List[torch.Tensor]) -> List[torch.Tensor]: """Cross-teacher softmax normalization of per-sample weights.""" stacked = torch.stack(raw_weights, dim=1) # (B, M) normed = F.softmax(stacked, dim=1) # (B, M) return [normed[:, m] for m in range(self.M)] def _compute_mtkd_loss( self, x: torch.Tensor, labels: torch.Tensor, use_rl_weights: bool = True, ) -> Tuple[torch.Tensor, List[torch.Tensor], List[torch.Tensor]]: """ Forward pass through student and teachers; compute weighted KD loss. Returns (total_loss, rewards_list, states_list). """ teacher_outs = self._get_teacher_outputs(x) s_feat, s_logit = self.student(x) # Build states and (optionally) agent weights states = [] w_logits = [] w_feats = [] rewards = [] for m, (t_feat, t_logit) in enumerate(teacher_outs): s = self.state_builder.build(m, t_feat, t_logit, s_feat, s_logit, labels) states.append(s) if use_rl_weights: raw_l, raw_f = self.agents[m](s) w_logits.append(raw_l.squeeze(1)) # (B,) w_feats.append(raw_f.squeeze(1)) # (B,) else: # Equal weights during pre-training w_logits.append(torch.ones(x.size(0), device=self.device)) w_feats.append(torch.ones(x.size(0), device=self.device)) r = compute_reward( s_logit, t_logit, s_feat, t_feat, self.state_builder.regressors[m], labels, self.alpha, self.beta ) rewards.append(r) # Normalize weights across teachers w_l_norm = self._softmax_normalize(w_logits) w_f_norm = self._softmax_normalize(w_feats) # Task loss task_loss = F.cross_entropy(s_logit, labels) # Weighted KD losses summed over teachers kd_logit = torch.tensor(0.0, device=self.device) kd_feature = torch.tensor(0.0, device=self.device) for m, (t_feat, t_logit) in enumerate(teacher_outs): kd_logit = kd_logit + ( w_l_norm[m] * logit_kd_loss(s_logit, t_logit) ).mean() kd_feature = kd_feature + ( w_f_norm[m] * feature_kd_loss( s_feat, t_feat, self.state_builder.regressors[m] ) ).mean() total = task_loss + self.alpha * kd_logit + self.beta * kd_feature return total, rewards, states def pretrain(self, loader, epochs: int = 1): """Pre-train student and agents with equal weights (Algorithm 1, steps 1-2).""" print("Pre-training student and agents with equal weights ...") self.student.train() for epoch in range(epochs): for x, y in loader: x, y = x.to(self.device), y.to(self.device) self.opt_student.zero_grad() loss, rewards, states = self._compute_mtkd_loss(x, y, use_rl_weights=False) loss.backward() self.opt_student.step() print(f" Pre-train epoch {epoch+1}/{epochs} done.") # Pre-train agents: collect one epoch of (state, action, reward) self.student.eval() episode_data = [] with torch.no_grad(): for x, y in loader: x, y = x.to(self.device), y.to(self.device) teacher_outs = self._get_teacher_outputs(x) s_feat, s_logit = self.student(x) for m, (t_feat, t_logit) in enumerate(teacher_outs): s = self.state_builder.build(m, t_feat, t_logit, s_feat, s_logit, y) r = compute_reward(s_logit, t_logit, s_feat, t_feat, self.state_builder.regressors[m], y, self.alpha, self.beta) episode_data.append((m, s.detach(), r.detach())) self._update_agents(episode_data) self.student.train() print("Pre-training complete.") def _update_agents(self, episode_data): """Policy gradient update for all agents from episode history.""" # Group by teacher index grouped: Dict[int, List] = {m: [] for m in range(self.M)} for m, s, r in episode_data: grouped[m].append((s, r)) for m in range(self.M): if not grouped[m]: continue states = torch.cat([item[0] for item in grouped[m]], dim=0) rewards = torch.cat([item[1] for item in grouped[m]], dim=0) # Simple normalization of reward batch r_norm = (rewards - rewards.mean()) / (rewards.std() + 1e-8) self.opt_agents[m].zero_grad() raw_l, raw_f = self.agents[m](states) w = (raw_l + raw_f).squeeze(1) # combined log-prob proxy pg_loss = -(r_norm.detach() * w).mean() pg_loss.backward() self.opt_agents[m].step() def train(self, loader, epochs: int = 200): """Main RL training loop (Algorithm 2).""" self.student.train() for epoch in range(epochs): episode_history = [] # Phase 1: freeze agents, train student with RL weights for agent in self.agents: agent.eval() for x, y in loader: x, y = x.to(self.device), y.to(self.device) self.opt_student.zero_grad() loss, rewards, states = self._compute_mtkd_loss(x, y, use_rl_weights=True) loss.backward() self.opt_student.step() # Collect episode data for m in range(self.M): episode_history.append((m, states[m].detach(), rewards[m].detach())) # Phase 2: freeze student, update agents for agent in self.agents: agent.train() self._update_agents(episode_history) if (epoch + 1) % 10 == 0: print(f"Epoch {epoch+1}/{epochs} — KD loss: {loss.item():.4f}") # ───────────────────────────────────────────────────────────────── # 6. DUMMY BACKBONE FOR SMOKE TEST # Returns (feature, logit) like a real encoder would. # ───────────────────────────────────────────────────────────────── class DummyNet(nn.Module): def __init__(self, feat_dim: int, num_classes: int): super().__init__() self.feat_dim = feat_dim self.conv = nn.Sequential( nn.Conv2d(3, 32, 3, padding=1), nn.ReLU(), nn.AdaptiveAvgPool2d(1), ) self.fc_feat = nn.Linear(32, feat_dim) self.fc_cls = nn.Linear(feat_dim, num_classes) def forward(self, x): h = self.conv(x).flatten(1) feat = self.fc_feat(h) logit = self.fc_cls(feat) return feat, logit # ───────────────────────────────────────────────────────────────── # 7. SMOKE TEST # ───────────────────────────────────────────────────────────────── def smoke_test(): """ End-to-end test on tiny dummy data. Confirms all components run without error. """ print("Running MTKD-RL smoke test ...") device = "cpu" C = 10 # num classes M = 2 # num teachers S_DIM = 64 # student feature dim T_DIMS = [128, 96] # teacher feature dims (can differ) student = DummyNet(S_DIM, C) teachers = [DummyNet(d, C) for d in T_DIMS] trainer = MTKDRLTrainer( student=student, teachers=teachers, student_feat_dim=S_DIM, teacher_feat_dims=T_DIMS, num_classes=C, alpha=1.0, beta=5.0, lr_student=0.05, lr_agent=1e-3, device=device, ) # Tiny dummy loader: 4 batches of 8 samples, 3x16x16 images dummy_loader = [ (torch.randn(8, 3, 16, 16), torch.randint(0, C, (8,))) for _ in range(4) ] trainer.pretrain(dummy_loader, epochs=1) trainer.train(dummy_loader, epochs=2) print("Smoke test PASSED.") if __name__ == "__main__": smoke_test()
What the Results Actually Say About Multi-Teacher Distillation
The numbers in this paper are worth stepping back and reading carefully, because they reveal something about the multi-teacher KD field as a whole.
On CIFAR-100, the gap from AVER (equal weights) to the best method (MTKD-RL) is around 1.5 to 2 percentage points depending on the student. The gap from CA-MKD or MMKD to MTKD-RL is around 0.3 points. The field is tight. The easy gains from having multiple teachers at all were captured years ago. What remains is incremental arbitration quality, and the differences between methods at that margin are real but not large.
ImageNet tells a better story for MTKD-RL. A 0.71% gap over MMKD on ResNet-34 at 1.28 million training images is more meaningful than the same gap on CIFAR-100. The larger teacher pool and the more diverse image distribution give the RL agent more signal to work with, and the agent’s ability to adapt per sample becomes more valuable when the data distribution is genuinely heterogeneous.
The downstream transfer results are the most practically relevant. Backbone quality matters enormously for object detection and segmentation pipelines. An improvement of 1.5% mAP across four different detector architectures on COCO-2017 is the kind of result that can change deployment decisions. This is where the investment in better teacher arbitration actually pays off in applications.
The combination with advanced single-teacher KD methods is also worth noting. Adding DIST or ND on top of MTKD-RL gives an additional 0.47% and 0.79% on ResNet-18 on ImageNet, showing the multi-teacher and single-teacher improvements are orthogonal. You can stack them.
One question the paper leaves open is how MTKD-RL would perform with a more heterogeneous teacher pool — mixing CNNs and ViTs, or including teachers of very different scales. The experiments use teacher pools that are fairly similar in architecture family. In a real deployment where you might assemble a pool of whatever pretrained models happen to be available, the agent’s ability to navigate genuine architectural diversity is untested.
For practitioners building on this work, the most actionable next step is exploring teacher pool composition. The paper shows performance saturates around M = 4. It would be useful to know whether four diverse teachers are better than four similar ones, and whether the RL agent learns to down-weight architecturally mismatched teachers automatically. Those questions point to where this line of research has room to grow, and this framework, with its attention to both performance and gap signals, is a reasonable foundation for answering them. You can find the official implementation for those experiments at the authors’ GitHub repository.
Closer to the surface, the finding that the choice of RL algorithm barely matters is actually freeing. It means practitioners can use the simplest stable optimizer (plain PG) and focus their tuning effort on the state design and teacher pool selection, which are where the real leverage is. The RL machinery here is less a magic ingredient and more a clean framework for closing a feedback loop that previous methods left open.
For those already using knowledge distillation pipelines, the knowledge distillation survey by Yang et al. (2023b) cited in the paper gives broader context on how the response-based, feature-based, and relation-based families relate to each other. Practitioners who want a deeper background on the single-teacher side of the picture can also look at how single-teacher knowledge distillation methods are structured before layering on the multi-teacher variant.
Frequently Asked Questions
Explore the Research and Code
Read the full MTKD-RL paper and access the official PyTorch implementation.
Yang, C., Yu, X., Yang, H., An, Z., Yu, C., Huang, L., & Xu, Y. (2025). Multi-Teacher Knowledge Distillation with Reinforcement Learning for Visual Recognition. Proceedings of the AAAI Conference on Artificial Intelligence. Institute of Computing Technology, Chinese Academy of Sciences. arXiv:2502.18510.
This analysis is based on the published paper and an independent evaluation of its claims.