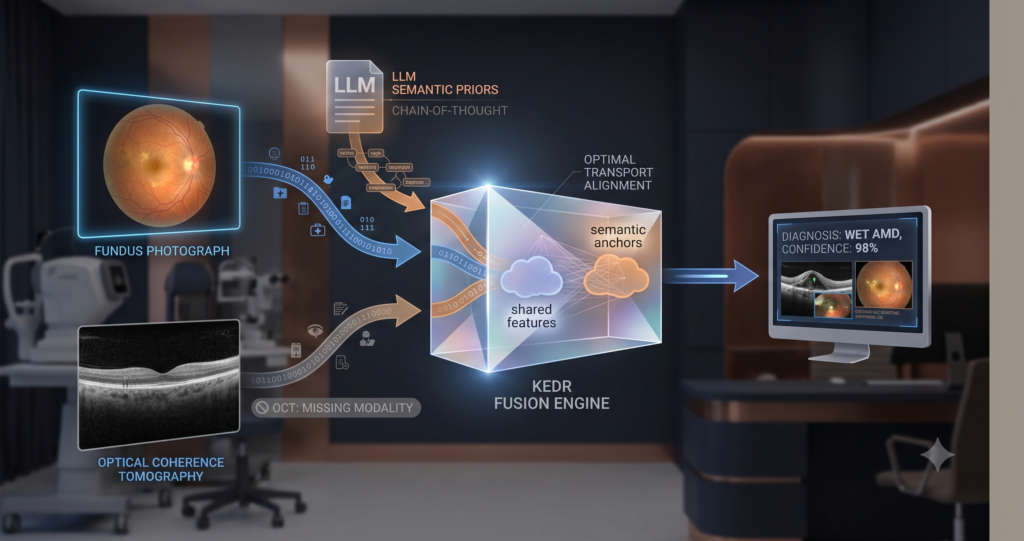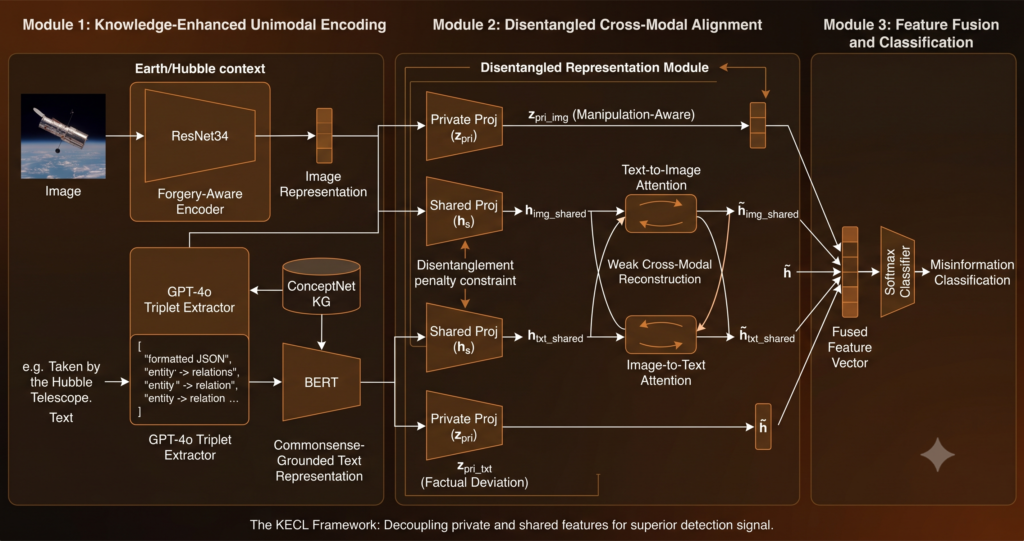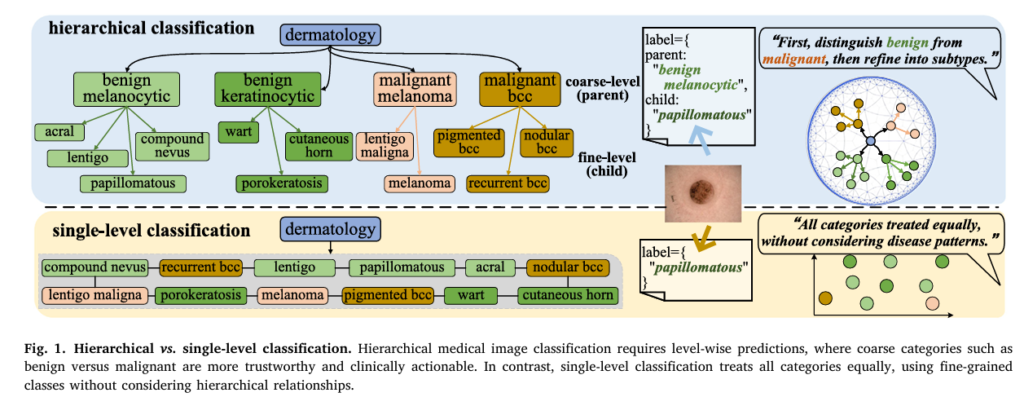
Teaching AI to Say “I Don’t Know”: HCEP and the Open-Set Emotion Recognition Problem
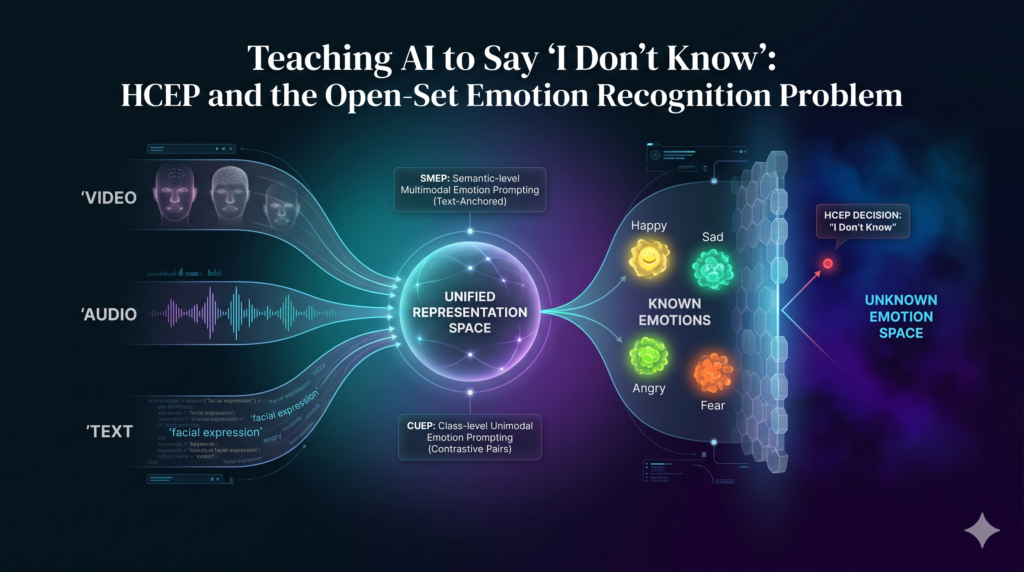
HCEP tackles open-set emotion recognition: teaching multimodal AI to admit when an expression matches no known category instead of forcing a wrong label.
Teaching AI to Say “I Don’t Know”: HCEP and the Open-Set Emotion Recognition Problem Read More »