Why Batch Size Changes What Your Neural Network Learns
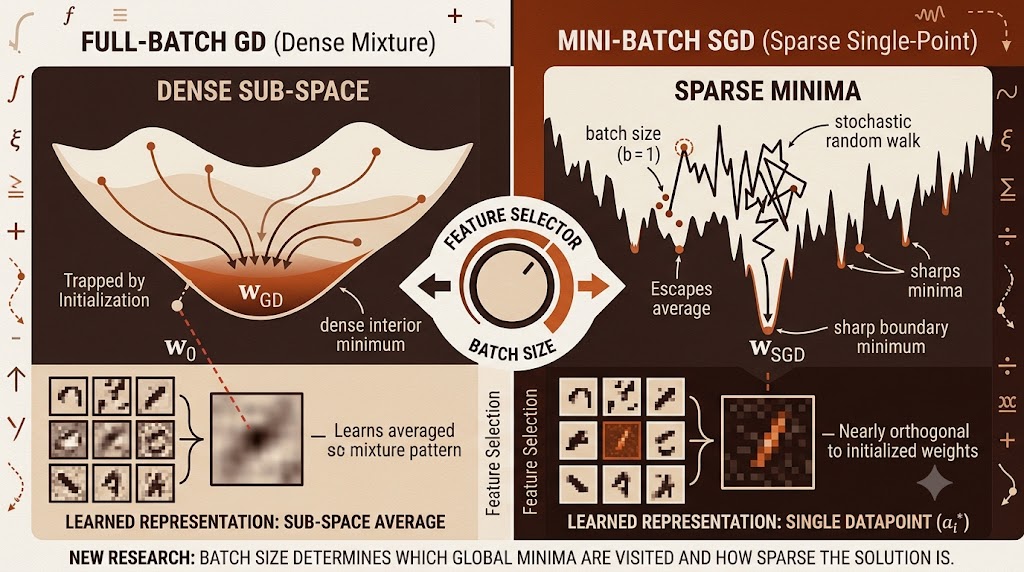
Analysis by the aitrendblend editorial team January 2025 Machine Learning Research Optimization Feature Learning GD (left) settles near a dense interior minimum; SGD with b=1 (right) escapes to a single datapoint on the boundary. From Ghosh et al., JMLR 2025. Pick any mainstream guide to training neural networks and you will read the same advice: […]
Why Batch Size Changes What Your Neural Network Learns Read More »