Bregman Proximal Gradient for Nonconvex Optimization: When SGD Does Not Have a Valid Proof
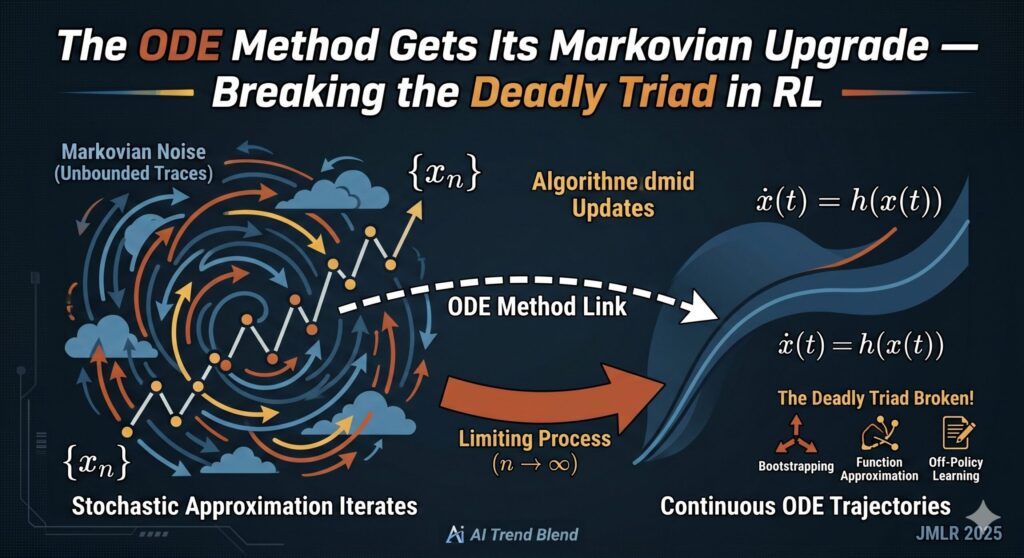
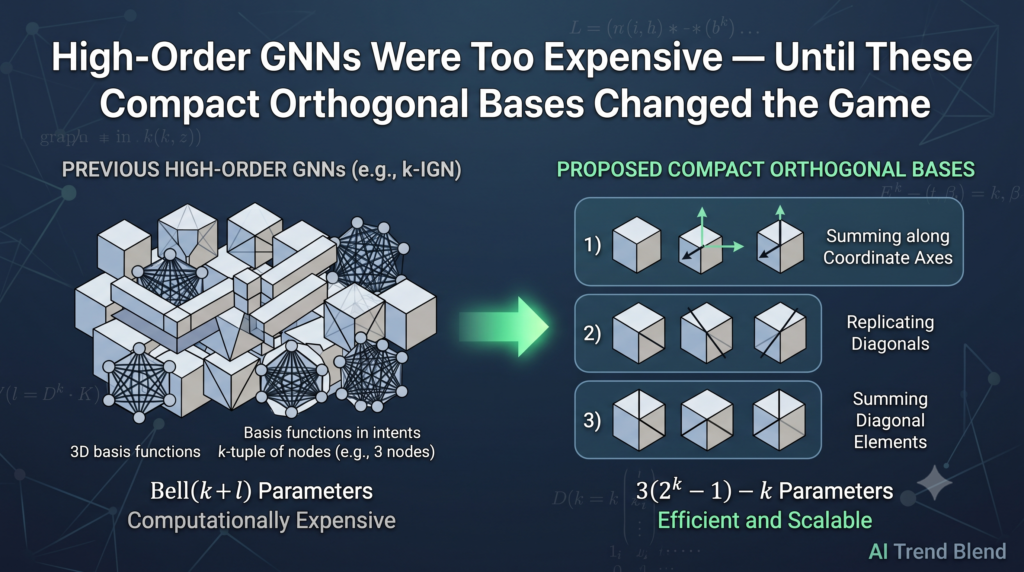
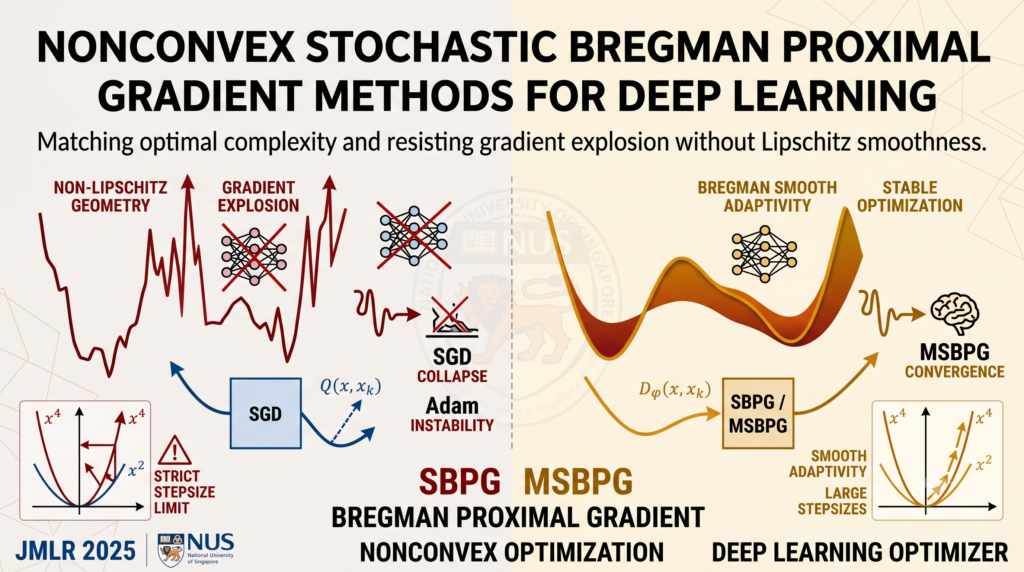
Stochastic Bregman proximal gradient methods drop the Lipschitz assumption behind SGD’s convergence proofs, match optimal sample complexity, and resist gradient explosion where standard optimizers collapse.