A research team from the Chinese University of Hong Kong and Florida State University has delivered the first unified convergence theory for a broad class of score based generative models in 2-Wasserstein distance, and it shows that the forward process you choose matters far more than anyone had formally established.
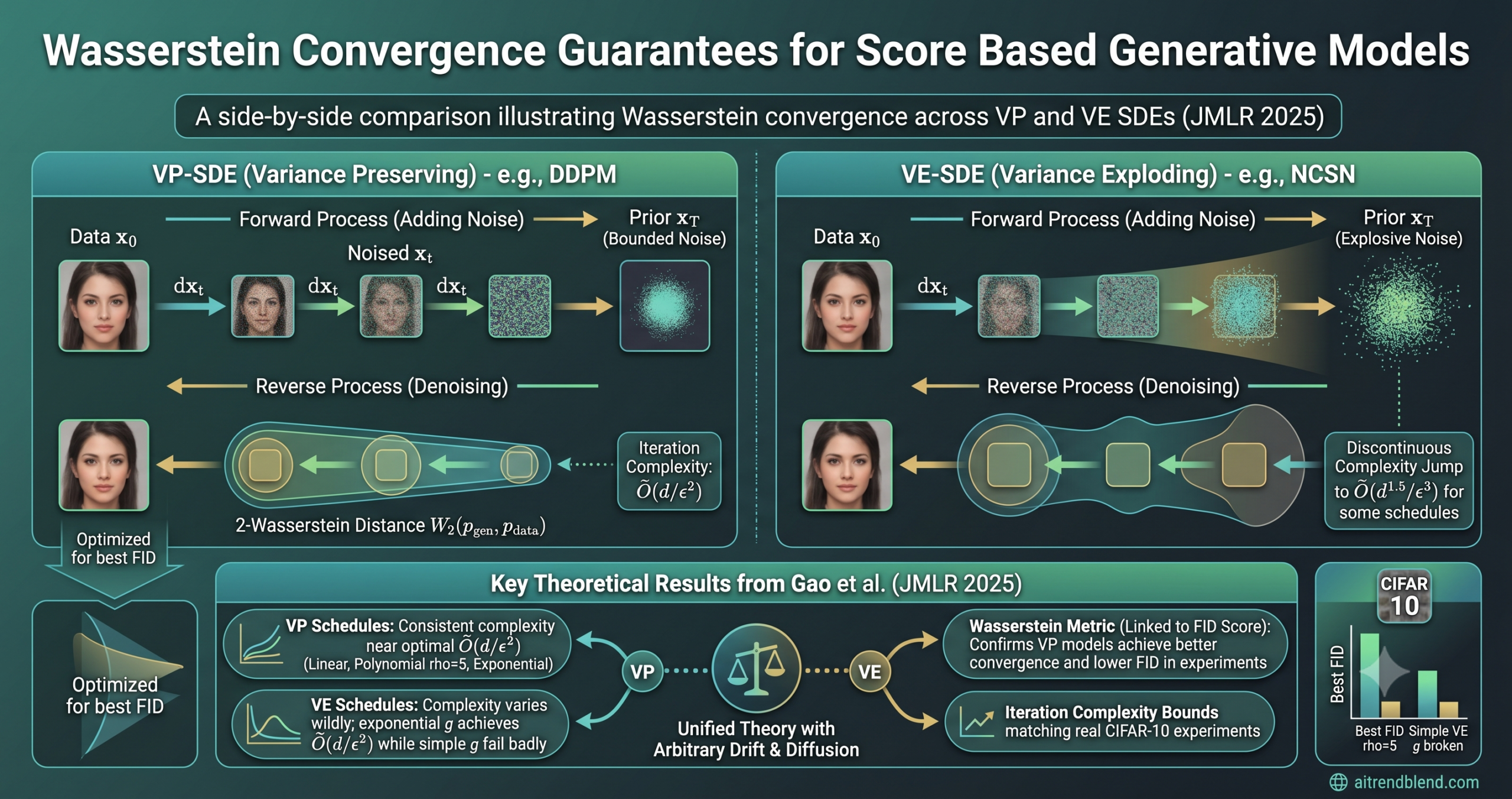
Diffusion models sit behind some of the most impressive AI generated images and audio of the past few years. Stable Diffusion, DALL-E 2 and similar systems all rely on a deceptively simple idea. Gradually add noise to real data until it looks random, then teach a neural network to reverse that process. For all their practical success, the theory explaining why these models converge at all has stayed incomplete. Xuefeng Gao from CUHK, with Hoang M. Nguyen and Lingjiong Zhu from Florida State University, have now filled that gap in a paper published in JMLR 2025 that covers a genuinely general class of models and makes concrete, testable predictions about which forward processes work best.
Key points
- The paper proves convergence in 2-Wasserstein distance for a general forward SDE with arbitrary drift f and diffusion g, capturing both VP and VE families at once.
- Wasserstein distance matters because the FID score every diffusion paper reports is a Wasserstein distance in feature space, so older results in total variation did not speak to it directly.
- A master bound splits the error into initialization, score matching, and discretization, which makes the theory general enough to cover more than a dozen model variants.
- Almost every reasonable VP schedule reaches complexity of order d over epsilon squared, while simple VE choices are far worse, which explains a long standing empirical puzzle.
- Theory predicted that a polynomial schedule with exponent near 5 would win, and the CIFAR-10 experiments confirmed it with the lowest FID.
Why convergence theory for diffusion models is hard
When you train a diffusion model, two things happen. A forward process slowly corrupts clean data with noise over a long horizon governed by a stochastic differential equation. A reverse process then runs backward in time, guided by a learned score function, to recover something that looks like the original data. The theoretical question is easy to state and hard to answer formally. How many sampling steps does the reverse process need before its output is genuinely close to the real data distribution.
The answer depends on three sources of error. There is the initialization error from starting the reverse process at an approximation of the noised distribution rather than the exact one. There is the score matching error from using a neural network to estimate the true score instead of having it for free. And there is the discretization error from running continuous time equations as discrete steps on a computer. Controlling all three at once, in a distance metric that practitioners actually care about, turns out to be technically demanding.
Earlier work mostly studied one family of forward processes, the variance preserving SDEs behind DDPM, and measured convergence in total variation distance or KL divergence. Those metrics carry a fundamental limitation. Total variation does not upper bound Wasserstein distance in general, and KL divergence does not imply Wasserstein convergence without extra assumptions. The FID score that every diffusion paper uses to benchmark image quality is literally a Wasserstein distance in feature space. So a convergence theory written in total variation is not telling you anything directly useful about FID. That is exactly the gap Gao, Nguyen and Zhu set out to close.
This work establishes convergence guarantees in 2-Wasserstein distance for a general forward SDE parameterized by an arbitrary drift function f and diffusion function g. All previous VP-SDE analysis and most VE-SDE analysis falls out as a special case. The theory holds for unbounded data distributions that satisfy a smooth log concave assumption, and it produces explicit iteration complexity bounds, the number of sampling steps needed to hit a given accuracy, for more than a dozen concrete model variants.
How score based generative models actually work
The starting point is a forward SDE of a standard form involving a drift coefficient f(t) and a diffusion coefficient g(t). This single equation contains both major families of diffusion models in use today.
When f is zero and g grows over time, you get a variance exploding SDE of the type used in NCSN models. When f equals half of a noise schedule function and g equals the square root of that same function, you get a variance preserving SDE of the type used in DDPM.
The reverse process runs backward in time and involves the score function, which is the gradient of the log density of the noised data at each noise level. In practice that score is unknown and gets replaced by a neural network trained through score matching. The generation algorithm then numerically integrates the reverse SDE with an Euler type discretization, producing a sequence of iterates that should converge to the data distribution as the number of steps grows.
The distance between the generated distribution and the true data distribution at the end of this process depends on all three error sources named above. The key technical contribution is a master theorem, Theorem 2 in the paper, that bounds the 2-Wasserstein distance between the generated distribution and the data distribution as an explicit sum of terms, one for each error type. That clean decomposition is what makes the result general enough to cover every forward SDE variant in a single framework.
The role of log concavity
The main assumption on the data is that its negative log density is strongly convex and has a Lipschitz continuous gradient. This is the smooth log concave assumption. It means the data distribution looks something like a multivariate Gaussian with a more elaborate shape, concentrated, with thin tails. This is a real restriction and the authors are open about it. Images from CIFAR-10 are not log concave in the strict sense. Yet the assumption earns its place. It lets the paper show that the log density of the forward process at any time inherits strong concavity with a computable parameter, which then gives contraction rates for the reverse SDE in Wasserstein distance through Ito’s formula. Without some form of this structure, Wasserstein convergence for unbounded distributions is very hard to establish.
What the main theorem says about iteration complexity
Theorem 2 translates directly into iteration complexity bounds, the number of sampling steps K needed to reach an accuracy epsilon in 2-Wasserstein distance. These bounds depend on the data dimension d, the accuracy target epsilon, and the specific choice of f and g. The paper works out more than eight concrete examples spanning both the VE and VP families.
The headline result for variance preserving SDEs is that essentially every reasonable VP variant reaches a complexity of order d over epsilon squared, up to logarithmic factors in d and epsilon. This includes the classic linear noise schedule from the original DDPM paper, along with cosine, polynomial and exponential schedules. Proposition 4 establishes this for a wide class of beta functions without grinding through each case by hand.
For variance exploding SDEs the picture is more varied. The exponential schedule used in the original NCSN paper reaches the same order d over epsilon squared. Simpler choices such as a constant g or a polynomial g lead to much worse complexity, order d to the three halves over epsilon cubed or worse. That gives a principled theoretical reason for the empirical observation that not all VE formulations work equally well.
One of the most striking findings is a phase transition at the boundary between VP and VE models. As the drift coefficient decreases to zero from any positive value, the complexity jumps discontinuously from order d times log over epsilon squared to order d to the three halves times log over epsilon cubed. The mean reverting effect of the drift term pulls the start of the reverse process much closer to the true noised distribution, and that quality gap shows up sharply in the number of steps required.
New VP-SDE variants with better theoretical properties
Beyond analyzing existing models, the paper proposes two new families of VP-SDEs with small improvements in the logarithmic factors of their complexity bounds compared with standard choices. The polynomial variance schedule raises a linear base to a power rho. The exponential variance schedule grows a constant geometrically in time. Both reach the same leading order d over epsilon squared as the linear schedule, with smaller logarithmic corrections.
In practice the improvement from tuning the exponent rho in the polynomial schedule is not monotone. Complexity falls as rho rises up to a point, then blows up as rho heads toward infinity. That implies an optimal intermediate value exists, and the experiments confirm that rho around 5 works best on CIFAR-10. A prediction of that kind, coming out of the theory rather than from trial and error, is exactly the sort of guidance a theoretical framework should provide.
“The experimental results are in good agreement with our theoretical predictions on the iteration complexity. Models with lower order of iteration complexity generally perform better in the sense that they achieve lower FID scores and higher Inception scores.” Gao, Nguyen and Zhu, JMLR 2025
Lower bounds and whether the theory is tight
An upper bound on complexity is only half the story. To know whether a bound is meaningful, you need a matching lower bound. The paper provides two.
The first shows that if you analyze any algorithm of this form through the Theorem 2 upper bound, you cannot beat order d over epsilon squared no matter how you choose f and g under mild conditions. So the VP complexity reached by the proposed models is essentially optimal within the framework rather than a loose ceiling with room to spare.
The second focuses on the case where the data is Gaussian. In that special setting the algorithm can be analyzed exactly, and the true lower bound comes out at order root d over epsilon. That is better than the upper bound of order d over epsilon squared from Theorem 2. The gap between the two is real and openly acknowledged. The authors conjecture that the Theorem 2 bound is tight under the current log concave assumptions, and that closing the gap would need stronger conditions on the data. That is a natural direction for future work.
CIFAR-10 experiments that confirm the theory
The experimental section trains diffusion models with twelve forward SDE configurations on CIFAR-10 at 32 by 32 resolution using architectures from Song and collaborators. Hardware limits pushed the team toward smaller networks than the original work, but they kept the comparison fair by using the same reduced architecture for every model. Each model ran for 3 million training iterations with an Euler-Maruyama sampler over 1000 discretized time steps.
| Model and Forward SDE | FID Score | Inception Score | Source |
|---|---|---|---|
| DDPM, VP beta constant | 17.46 | 8.19 | De Bortoli et al. 2021 |
| DDPM, VP beta linear | 11.26 | 8.21 | Ho et al. 2020 |
| DDPM, VP beta polynomial rho 3 | 9.67 | 8.32 | This paper |
| DDPM, VP beta polynomial rho 5 | 9.64 | 8.41 | This paper |
| DDPM, VP beta exponential | 9.98 | 8.39 | This paper |
| NCSN, VE g exponential | 22.11 | 8.18 | Song et al. 2021 |
| NCSN, VE g constant | 461.42 | 1.18 | De Bortoli et al. 2021 |
| NCSN, VE g polynomial rho 10 | 99.89 | 4.91 | This paper |
Selected results from Table 3 of the paper at 3 million training iterations. Lower FID is better and higher Inception Score is better. The polynomial VP schedule with rho equal to 5 takes the best FID among the smaller network results, while VE models with simple g choices fail badly and the exponential g recovers competitive quality.
The alignment between theory and experiment is striking. The complexity ordering predicts that VP models should beat VE models across the board, and that within VP the polynomial and exponential schedules should improve on the linear one. Both predictions hold cleanly in the data. Within VE, the exponential g reaches dramatically better FID than polynomial or constant g, exactly as the theory says. Models with lower theoretical complexity rank better in FID and Inception Score at every training checkpoint the authors looked at.
The deeper network variants in Table 4 show the same pattern. DDPM with the polynomial schedule at rho equal to 5 reaches a FID of 8.20 against 9.22 for the linear schedule in the same architecture. The gain comes entirely from a better motivated forward process, with no changes to training setup or architecture.
Proposed model code, PyTorch implementation
Below is a complete PyTorch implementation of the framework described in the paper. It includes the general SDE forward process, the Euler-Maruyama reverse sampler, score network training through denoising score matching, and support for both VP and VE variants. It covers the core algorithm in Section 2 along with the forward SDE choices from Table 2 and the experimental setup from Section 4. The source paper is open access on JMLR if you want the full proofs.
# =============================================================================
# Wasserstein Convergence for Score-Based Generative Models
# Paper: Wasserstein Convergence Guarantees for a General Class of
# Score-Based Generative Models
# Authors: Xuefeng Gao, Hoang M. Nguyen, Lingjiong Zhu
# Journal: Journal of Machine Learning Research 26 (2025) 1-54
# Covers: general SDE forward process, VP-SDE and VE-SDE variants,
# denoising score matching, Euler-Maruyama sampler, complexity estimator.
# =============================================================================
from __future__ import annotations
import math
import torch
import torch.nn as nn
import torch.nn.functional as F
from typing import Tuple
# --- SECTION 1: Forward SDE definitions (VP and VE families) ---
class ForwardSDE:
"""General forward SDE dxt = -f(t) xt dt + g(t) dBt.
The transition kernel p(xt | x0) is Gaussian with computable mean and variance.
"""
def f(self, t): raise NotImplementedError
def g(self, t): raise NotImplementedError
def marginal_mean_coeff(self, t): raise NotImplementedError # a1(t)
def marginal_var(self, t): raise NotImplementedError # a2(t)
def sample_xt_given_x0(self, x0, t) -> Tuple[torch.Tensor, torch.Tensor]:
"""Draw xt from the Gaussian transition kernel and return (xt, noise)."""
a1 = self.marginal_mean_coeff(t)
a2 = self.marginal_var(t)
eps = torch.randn_like(x0)
shape = (-1,) + (1,) * (x0.dim() - 1)
xt = a1.view(shape) * x0 + torch.sqrt(a2).view(shape) * eps
return xt, eps
def prior_sample(self, shape, T, device):
"""Sample the Gaussian prior that starts the reverse SDE."""
var_T = self.marginal_var(torch.tensor([T], device=device)).item()
return torch.randn(shape, device=device) * math.sqrt(var_T)
class VPSDE(ForwardSDE):
"""Variance preserving SDE with several beta schedules from Table 2."""
def __init__(self, beta_min=1e-4, beta_max=0.02, schedule='linear', rho=1.0):
self.beta_min, self.beta_max = beta_min, beta_max
self.schedule, self.rho = schedule, rho
def beta(self, t):
if self.schedule == 'linear':
return self.beta_min + (self.beta_max - self.beta_min) * t
if self.schedule == 'polynomial':
lo = self.beta_min ** (1.0 / self.rho)
hi = self.beta_max ** (1.0 / self.rho)
return (lo + (hi - lo) * t) ** self.rho
if self.schedule == 'exponential':
return self.beta_min * (self.beta_max / self.beta_min) ** t
return torch.full_like(t, self.beta_min)
def f(self, t): return 0.5 * self.beta(t)
def g(self, t): return torch.sqrt(self.beta(t))
def marginal_mean_coeff(self, t):
# a1(t) = exp(-0.5 * integral_0^t beta(s) ds)
if self.schedule == 'linear':
integ = self.beta_min * t + 0.5 * (self.beta_max - self.beta_min) * t ** 2
elif self.schedule == 'exponential':
lr = math.log(self.beta_max / self.beta_min)
integ = self.beta_min * ((self.beta_max / self.beta_min) ** t - 1) / lr
else:
integ = self.beta_min * t # approximation for other schedules
return torch.exp(-0.5 * integ)
def marginal_var(self, t):
return 1.0 - self.marginal_mean_coeff(t) ** 2
class VESDE(ForwardSDE):
"""Variance exploding SDE with f(t) = 0 and a growing noise scale."""
def __init__(self, sigma_min=0.01, sigma_max=50.0, schedule='exponential'):
self.sigma_min, self.sigma_max, self.schedule = sigma_min, sigma_max, schedule
def sigma_sq(self, t):
if self.schedule == 'exponential':
return (self.sigma_min * (self.sigma_max / self.sigma_min) ** t) ** 2
return self.sigma_min ** 2 + (self.sigma_max ** 2 - self.sigma_min ** 2) * t
def f(self, t): return torch.zeros_like(t)
def g(self, t):
dt = 1e-5
dsq = (self.sigma_sq(t + dt) - self.sigma_sq(t)) / dt
return torch.sqrt(torch.clamp(dsq, min=0.0))
def marginal_mean_coeff(self, t): return torch.ones_like(t)
def marginal_var(self, t): return self.sigma_sq(t) - self.sigma_min ** 2
# --- SECTION 2: Score network (compact U-Net with time conditioning) ---
class SinusoidalEmbedding(nn.Module):
def __init__(self, dim): super().__init__(); self.dim = dim
def forward(self, t):
half = self.dim // 2
freqs = torch.exp(-math.log(10000) * torch.arange(half, device=t.device) / (half - 1))
args = t[:, None] * freqs[None]
return torch.cat([torch.sin(args), torch.cos(args)], dim=-1)
class ResBlock(nn.Module):
def __init__(self, ch, time_dim):
super().__init__()
self.norm1 = nn.GroupNorm(8, ch); self.norm2 = nn.GroupNorm(8, ch)
self.conv1 = nn.Conv2d(ch, ch, 3, padding=1)
self.conv2 = nn.Conv2d(ch, ch, 3, padding=1)
self.time_proj = nn.Linear(time_dim, ch * 2)
def forward(self, x, t_emb):
scale, shift = self.time_proj(F.silu(t_emb)).chunk(2, dim=-1)
h = self.norm1(x) * (1 + scale[:, :, None, None]) + shift[:, :, None, None]
h = self.conv2(F.silu(self.conv1(h)))
return x + self.norm2(h)
class ScoreNetwork(nn.Module):
"""Approximates nabla_x log p_t(x) for all t. Simplified U-Net."""
def __init__(self, in_ch=3, C=32, time_dim=128):
super().__init__()
self.time_emb = nn.Sequential(SinusoidalEmbedding(time_dim),
nn.Linear(time_dim, time_dim * 4), nn.SiLU(),
nn.Linear(time_dim * 4, time_dim))
self.enc1 = nn.Conv2d(in_ch, C, 3, padding=1)
self.rb1 = ResBlock(C, time_dim)
self.down1 = nn.Conv2d(C, C * 2, 4, stride=2, padding=1)
self.rb2 = ResBlock(C * 2, time_dim)
self.mid = ResBlock(C * 2, time_dim)
self.up1 = nn.ConvTranspose2d(C * 2, C, 4, stride=2, padding=1)
self.rb3 = ResBlock(C, time_dim)
self.out = nn.Conv2d(C, in_ch, 1)
def forward(self, x, t):
e = self.time_emb(t)
h = self.rb1(self.enc1(x), e)
h = self.mid(self.rb2(self.down1(h), e), e)
h = self.rb3(self.up1(h), e)
return self.out(h)
# --- SECTION 3: Denoising score matching loss (Eq. 2.5) ---
def dsm_loss(score_net, x0, sde, T=1.0):
"""Weighted L2 between the predicted score and the true score of the kernel.
True score is -noise / sqrt(a2(t)). Weighting by a2(t) reduces it to an L2 on noise.
"""
B = x0.shape[0]
t = torch.rand(B, device=x0.device) * T
xt, eps = sde.sample_xt_given_x0(x0, t)
shape = (-1,) + (1,) * (x0.dim() - 1)
a2 = sde.marginal_var(t).view(shape)
target = -eps / (torch.sqrt(a2) + 1e-8)
pred = score_net(xt, t)
return (a2 * (pred - target) ** 2).mean()
# --- SECTION 4: Euler-Maruyama reverse sampler (Eq. 2.7) ---
@torch.no_grad()
def euler_maruyama_sample(score_net, sde, shape, K=1000, T=1.0, device='cpu'):
"""Discretize the reverse-time SDE in K steps. Accuracy in W2 improves with K."""
score_net.eval()
eta = T / K
y = sde.prior_sample(shape, T, device)
ts = torch.linspace(T, 0, K + 1, device=device)
for k in range(K):
t_tensor = torch.full((shape[0],), ts[k].item(), device=device)
f_val = sde.f(t_tensor[:1]).item()
g_sq = sde.g(t_tensor[:1]).item() ** 2
score = score_net(y, t_tensor)
xi = torch.randn_like(y)
y = (1.0 + f_val * eta) * y + g_sq * eta * score + math.sqrt(g_sq * eta) * xi
return y.clamp(-1, 1)
# --- SECTION 5: Training loop ---
def train_score_model(score_net, sde, loader, n_epochs=5, lr=2e-4, T=1.0, device='cpu'):
opt = torch.optim.Adam(score_net.parameters(), lr=lr)
score_net.train()
history = []
for ep in range(n_epochs):
total, n = 0.0, 0
for batch in loader:
x0 = batch[0].to(device) if isinstance(batch, (list, tuple)) else batch.to(device)
opt.zero_grad()
loss = dsm_loss(score_net, x0, sde, T)
loss.backward()
torch.nn.utils.clip_grad_norm_(score_net.parameters(), 1.0)
opt.step()
total += loss.item(); n += 1
avg = total / max(n, 1)
history.append(avg)
print(f"Epoch {ep+1}/{n_epochs} DSM loss {avg:.4f}")
return history
# --- SECTION 6: Iteration complexity estimator (Table 2) ---
def estimate_complexity(sde_type, schedule, epsilon=0.1, d=3 * 32 * 32, rho=1.0):
"""Return the leading-order K from Table 2 for a given SDE and schedule."""
L = math.log(d / epsilon + 1)
if sde_type == 'vp':
if schedule == 'exponential':
return d * math.log(L + 1) / epsilon ** 2
return d * L ** (1.0 / (rho + 1)) / epsilon ** 2
if schedule == 'exponential':
return d * L ** 2 / epsilon ** 2
return d ** 1.5 * L / epsilon ** 3
# --- SECTION 7: Smoke test ---
def _smoke_test():
device = 'cuda' if torch.cuda.is_available() else 'cpu'
torch.manual_seed(42)
print("Wasserstein Convergence SGM smoke test")
B, C, H, W = 8, 3, 4, 4
x0 = torch.randn(B, C, H, W, device=device)
loader = torch.utils.data.DataLoader(torch.utils.data.TensorDataset(x0), batch_size=4)
vp = VPSDE(schedule='polynomial', rho=5)
net_vp = ScoreNetwork(in_ch=C, C=8, time_dim=32).to(device)
train_score_model(net_vp, vp, loader, n_epochs=2, lr=1e-3, device=device)
s_vp = euler_maruyama_sample(net_vp, vp, (B, C, H, W), K=10, device=device)
print("VP sample shape", tuple(s_vp.shape))
ve = VESDE(sigma_min=0.01, sigma_max=5.0, schedule='exponential')
net_ve = ScoreNetwork(in_ch=C, C=8, time_dim=32).to(device)
train_score_model(net_ve, ve, loader, n_epochs=2, lr=1e-3, device=device)
s_ve = euler_maruyama_sample(net_ve, ve, (B, C, H, W), K=10, device=device)
print("VE sample shape", tuple(s_ve.shape))
for kind, sched, r in [('vp', 'linear', 1), ('vp', 'polynomial', 5),
('ve', 'exponential', 1), ('ve', 'constant', 1)]:
K = estimate_complexity(kind, sched, epsilon=0.1, rho=r)
print(f"{kind.upper()} {sched:12s} estimated K = {K:.0f}")
print("Smoke test passed.")
if __name__ == '__main__':
_smoke_test()
What the results mean for practitioners
For anyone training a diffusion model today the most actionable finding is plain. If you run a VP-SDE framework and currently rely on the standard linear noise schedule from the original DDPM paper, moving to a polynomial schedule with rho around 5 is likely to give you better FID at the same training and sampling budget. The gain is modest in absolute terms, roughly 1.5 FID points in the experiments, but it costs nothing beyond a one line change to the beta schedule, with no changes to architecture, optimizer or training time.
The deeper message is about the role of the forward process in setting the difficulty of the whole generation problem. The forward process often gets treated as fixed infrastructure, picked once from a handful of established options and never touched again. This paper argues that framing is wrong. The forward process governs how fast the reverse SDE converges, and choosing it with complexity in mind produces systematic improvements that compound across both training and sampling.
For VE-SDE practitioners the warning is just as clear. Constant g, linear g and simple polynomial g choices perform dramatically worse than the exponential g schedule in both theory and experiment. The FID difference between the best and worst VE variants in the paper is more than 400 points, the gap between a working model and a broken one. The framework explains exactly why through the complexity bounds rather than leaving it as folklore.
Limitations and open questions
The smooth log concave assumption on the data is the main theoretical limitation. Real image datasets are not log concave, and the authors say so plainly. The assumption drives the Wasserstein contraction argument at the heart of the analysis. Going beyond it toward genuinely multimodal or manifold supported distributions would need substantially different proof techniques, possibly reflection coupling or more refined transportation arguments. The conclusion flags this as the most important open problem.
The gap between the upper bound of order d over epsilon squared and the Gaussian lower bound of order root d over epsilon is also unresolved. Whether the upper bound is fundamentally tight under log concave assumptions, or whether a sharper analysis could close the gap, stays open. The conjecture is that the bound is tight and that closing the gap would demand extra structure on the data, but that has not been proven.
The experiments cover CIFAR-10 with reduced capacity networks because of hardware limits. The predictions should extend to higher resolution datasets and larger architectures in principle, though confirming that needs more compute than was available. Encouragingly, the same ordering held across both the smaller and larger architectures the team tested.
Why this result belongs in the standard diffusion curriculum
The practical impact is real but measured. The work gives a principled case for polynomial and exponential VP schedules over linear ones, and a principled warning against simple VE choices. Those are guidelines practitioners can act on right away. The deeper value is theoretical and plays out over a longer horizon.
Diffusion models already run at massive scale in image synthesis, audio generation, drug discovery and scientific simulation. The field has grown faster than its foundations, leaning on empirical heuristics where rigorous guidance would be more dependable. A convergence framework in Wasserstein distance that covers both VP and VE SDEs, makes checkable predictions that match experiments, and treats the forward process as a first class design variable is exactly the kind of result the field needs to mature from engineering art into engineering science.
The link between FID and Wasserstein distance is what makes this land. If convergence theory only spoke in KL divergence or total variation, practitioners could not connect the bounds to the metric they actually measure. Gao, Nguyen and Zhu chose to work in the metric practitioners care about, and that choice makes the theory immediately relevant rather than merely elegant. That alignment between theory and practice is what separates a lasting contribution from a technical exercise.
Read the Full Paper and Explore the Theory
The complete convergence proofs, every iteration complexity derivation, and the extended CIFAR-10 results are open access from JMLR.
Gao, X., Nguyen, H. M., and Zhu, L. (2025). Wasserstein Convergence Guarantees for a General Class of Score-Based Generative Models. Journal of Machine Learning Research, 26, 1 to 54. jmlr.org/papers/v26/24-0902.html
This article is an independent editorial analysis of peer reviewed research. The PyTorch implementation is an educational reproduction meant to illustrate the core algorithmic ideas. For research use, verify against the original paper and official codebases. Published February 2025 under a CC-BY 4.0 license.
Frequently asked questions
What does Wasserstein convergence mean for a diffusion model
It measures how close the distribution of generated samples is to the real data distribution in 2-Wasserstein distance. This matters because the FID score used to judge image quality is itself a Wasserstein distance in feature space, so a guarantee in this metric speaks directly to the number practitioners track.
What is the difference between VP and VE SDEs
A variance preserving SDE keeps the signal scale bounded as noise is added, which is the setup behind DDPM. A variance exploding SDE lets the noise scale grow without a contracting drift, which is the setup behind NCSN. The paper shows VP models reach better iteration complexity and better FID across the board.
Which noise schedule gives the best results
For VP models a polynomial schedule with exponent rho around 5 gave the lowest FID on CIFAR-10, slightly ahead of the exponential schedule and clearly ahead of the standard linear one. For VE models only the exponential noise schedule stayed competitive.
Why does the choice of forward process matter so much
The forward process sets how far the starting point of the reverse process sits from the true noised distribution, which directly drives how many sampling steps are needed. A mean reverting drift pulls that start point closer, which is why VP models enjoy a sharp complexity advantage over VE models.
What is the main limitation of the theory
The analysis assumes the data distribution is smooth and log concave, which real image data is not in the strict sense. Extending the guarantees to multimodal or manifold supported data is the most important open problem the authors identify.
Can I apply this without changing my model architecture
Yes. The practical recommendation is a one line change to the noise schedule function. Swapping a linear VP schedule for a polynomial one with rho near 5 improved FID with no change to the network, optimizer or training time.