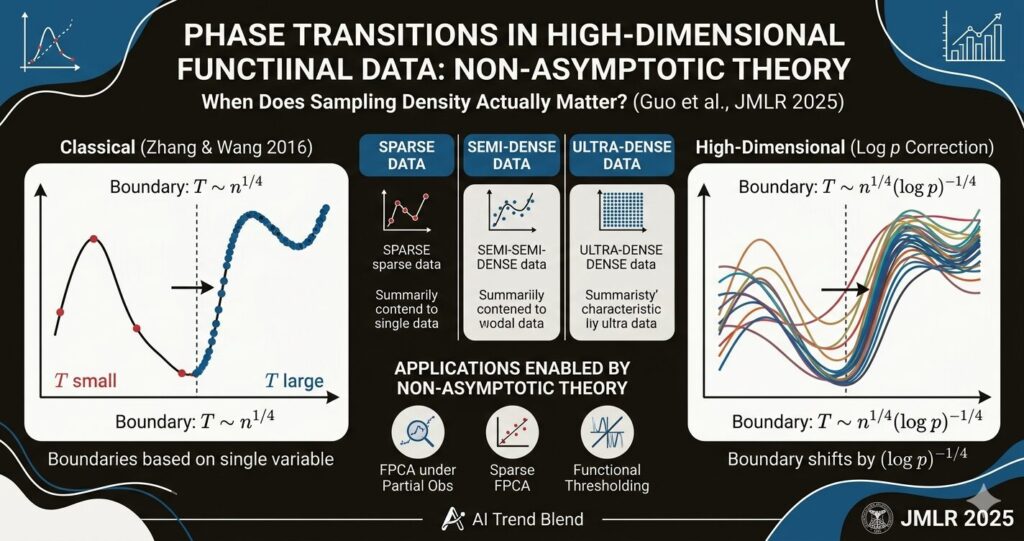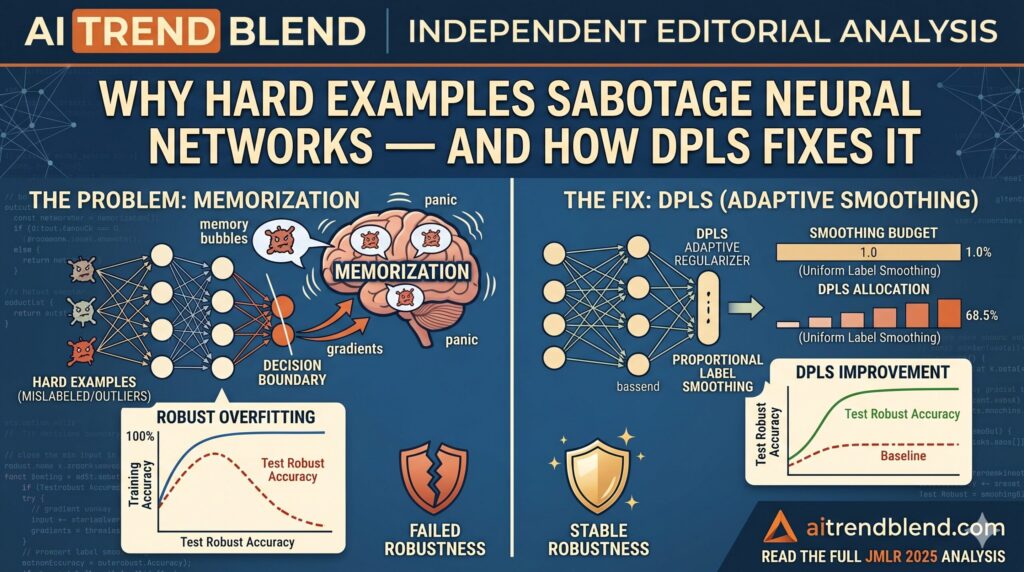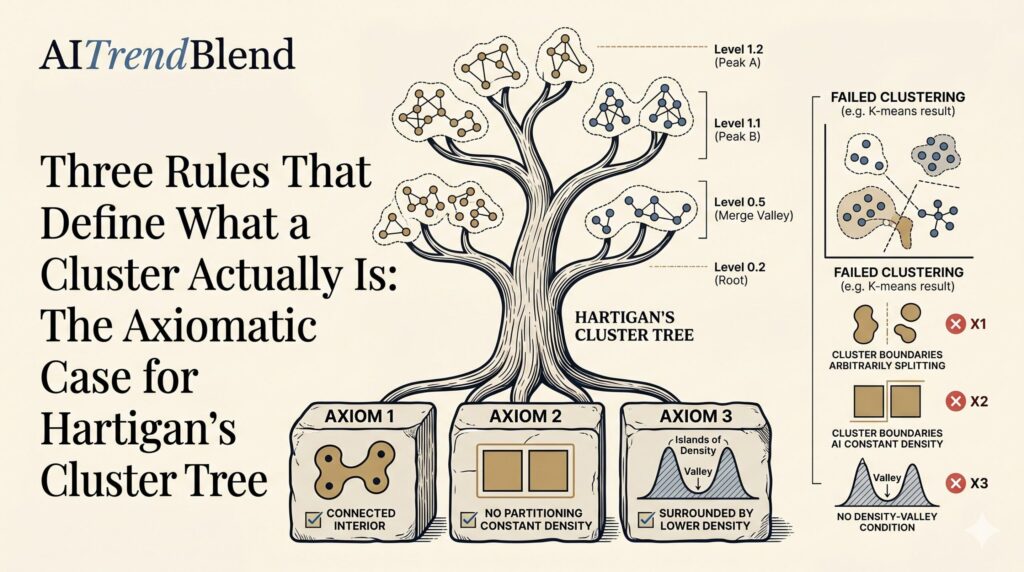
Random ReLU Neural Networks as Non-Gaussian Processes
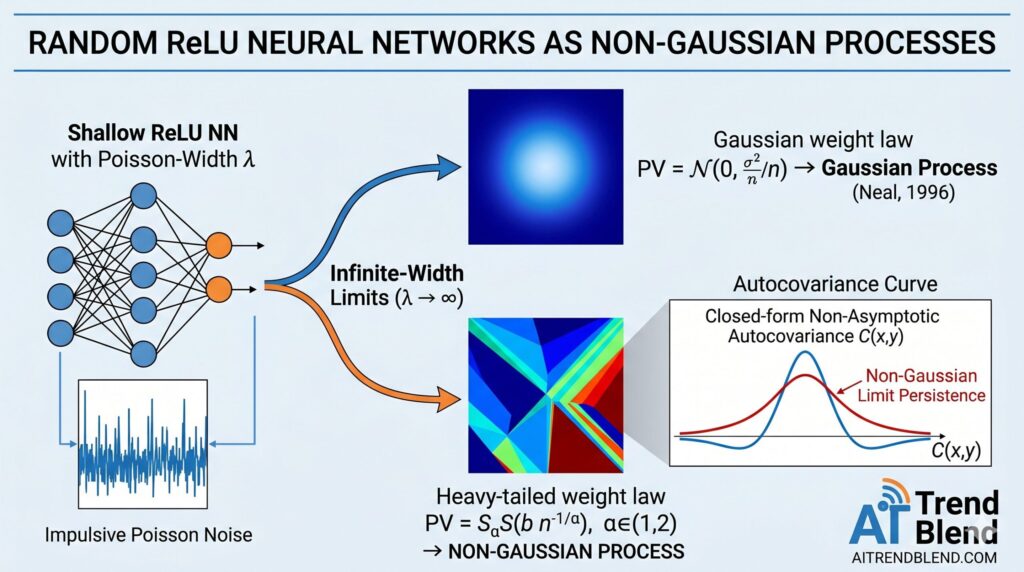
Random ReLU Neural Networks as Non-Gaussian Processes | AI Trend Blend AITrendBlend Machine Learning Computer Vision About Neural Network Theory · Journal of Machine Learning Research 26 (2025) 1–31 · 16 min read Wide Neural Networks Are Not Always Gaussian — Here’s the Proof A team from UC San Diego and EPFL’s Biomedical Imaging Group […]
Random ReLU Neural Networks as Non-Gaussian Processes Read More »