Why Meta-Learning Suddenly Gets Smarter the More Tasks You Throw at It
A research team from three leading institutions has proven something nobody expected: when learning a prior across many tasks using the Gibbs algorithm, fast convergence rates are always guaranteed at the meta level — even when individual tasks refuse to cooperate. This changes how we think about the mathematics of learning-to-learn.
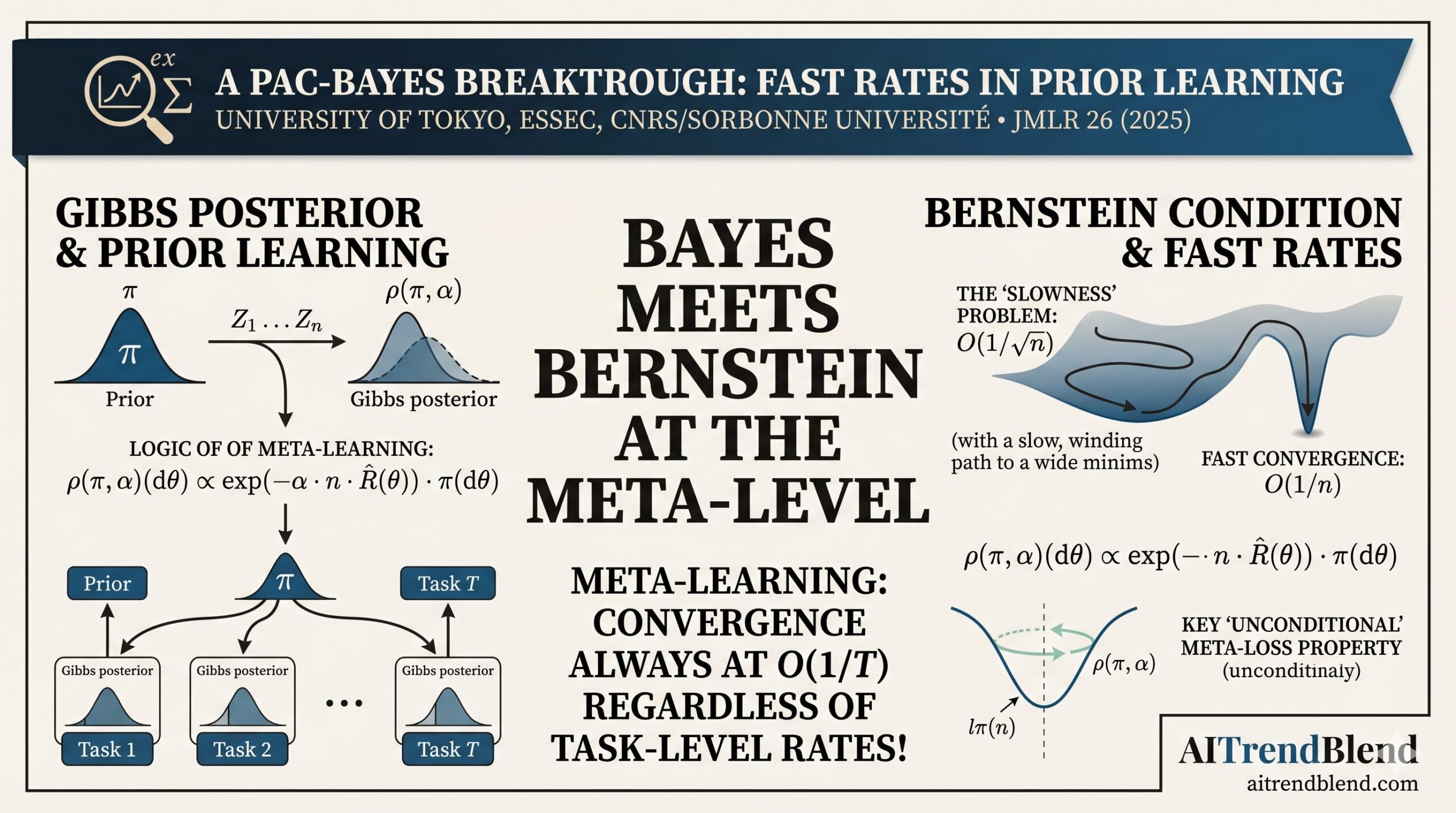
Imagine teaching a student not by showing them answers, but by giving them a mindset that makes every future lesson click faster. That is meta-learning in a nutshell. But for years, researchers have struggled to prove that this mindset can be learned efficiently from past experience. A new paper from the University of Tokyo, ESSEC Business School, and CNRS finally delivers that proof — with a surprising twist. The faster learning you want at the task level is not even required as a starting assumption. The mathematics conjures it automatically at the meta level.
The Slowness Problem That Has Haunted Meta-Learning Theory
Meta-learning is built on a beautiful idea. Instead of training a model from scratch on every new problem, you use experience from a large collection of related tasks to build a head start — an initial configuration or a prior distribution — that lets you solve new tasks with far less data. This idea powers popular methods like MAML, Reptile, and Prototypical Networks, and it is why meta-learning has found real traction in everything from drug discovery to robot locomotion to few-shot image classification.
But the theoretical story behind meta-learning has been frustratingly incomplete in one important area: the rate at which learning improves as you accumulate more tasks. In standard, single-task learning, there is a well-known phenomenon called fast rates. Under a condition called Bernstein’s condition — which captures the idea that there is a well-separated best answer and the loss function behaves nicely near it — the error of a good algorithm shrinks at a rate proportional to 1/n, where n is the number of data points. Without this condition, the best you can generally prove is a slower 1/√n rate.
When researchers moved to the meta-learning setting, a natural worry arose. You are now learning across T tasks, each with n observations. The quality of your learned prior depends on both n and T. In the best case, you would hope for an error that shrinks as 1/T as you accumulate tasks — but the theoretical machinery available suggested that achieving this fast rate might require the same strict Bernstein’s condition to hold for every individual task in the collection. That is a demanding assumption. Many real-world learning problems do not satisfy it, and requiring it across an entire distribution of tasks feels even more fragile.
Before this work, fast convergence rates in the number of tasks T required assuming that Bernstein’s condition held at the within-task level. This paper proves that when using Gibbs posteriors and a PAC-Bayes framework, Bernstein’s condition always holds at the meta level — unconditionally. The result holds whether or not individual tasks satisfy any fast-rate assumption whatsoever. Learning more tasks always pays off faster than anyone had previously proven.
What Bernstein’s Condition Actually Means — In Plain Language
The mathematical statement of Bernstein’s condition can look intimidating, but the intuition behind it is accessible. Picture a loss landscape for a single learning problem. The best possible predictor sits at some bottom point. Bernstein’s condition essentially says that moving away from that bottom point costs you proportionally — the worse a predictor is at expected risk, the more variable its loss tends to be across data points. This link between excess risk and variance is the engine that drives fast learning rates.
When Bernstein’s condition holds for a task, the Gibbs posterior — which weighs predictors exponentially according to their empirical performance — zooms in on the good region at speed 1/n rather than 1/√n. The practical difference between these two rates is enormous. For n equal to ten thousand observations, the difference between converging at 1/10000 versus 1/100 is the difference between a usable model and a model that needs ten times as much data to reach the same quality.
The formal condition requires that the variance of the loss difference between any predictor and the optimal predictor is bounded by a constant multiple of the excess risk itself. This is satisfied, for example, when the minimum achievable risk is zero, when the loss function is smooth and strongly convex, or when certain margin conditions hold in classification. But it is far from universal, and in many practical scenarios it is simply not reasonable to assume it holds.
where R(θ) is the prediction risk, R* is the optimal risk, and c > 0 is a constant.
What makes the paper’s main result so striking is that this same structural condition, which may or may not hold for individual tasks, always holds at the meta level when you frame the problem correctly. The authors show that the loss at the meta level — measuring how well a prior serves a future task — satisfies a Bernstein-like condition unconditionally, with no assumptions on the tasks themselves beyond the basic boundedness of the loss function.
The Gibbs Posterior — A Bayesian Engine for Learning
At the heart of the analysis is the Gibbs posterior, also known as exponentially weighted aggregation in the frequentist literature or as a generalized posterior in the Bayesian literature. The idea is clean and elegant. Given a prior distribution π over model parameters, the Gibbs posterior is formed by reweighting the prior according to how well each parameter value performs on the observed data. Parameters with low empirical loss receive exponentially higher weight, while poor performers are suppressed.
Formally, for a task with n observations and a temperature parameter α, the Gibbs posterior takes the form:
where R̂(θ) is the empirical risk and π is the prior distribution over parameters.
The reason this object is so useful in PAC-Bayes theory is that it minimizes a natural bound on the prediction risk. Specifically, it is the unique minimizer of the penalized empirical risk that adds a Kullback-Leibler divergence term between the posterior and prior, scaled by the inverse temperature. This variational characterization connects the Gibbs posterior directly to information-theoretic bounds on generalization, which is precisely the language PAC-Bayes theory speaks.
In the meta-learning setting, the Gibbs posterior is used at two levels. At the within-task level, each individual task is solved using the Gibbs posterior with a shared prior π. At the meta level, the prior π itself is treated as a random object drawn from a hyper-distribution Π, and a second application of the Gibbs principle learns this hyper-distribution from the collection of observed tasks. The paper calls this the meta-learning Gibbs algorithm, and it is the object for which the fast-rate guarantees are derived.
The Surprise: Bernstein’s Condition Appears for Free at the Meta Level
The central theorem of the paper — Theorem 3 in the original — is the one that makes everything else possible, and it is worth understanding why it is surprising. The authors prove that the meta-level loss, which measures how good a prior π is for solving a randomly drawn future task, always satisfies a Bernstein-like variance bound relative to the optimal prior. No matter how difficult the individual tasks are, no matter whether fast rates hold at the within-task level, the meta-level loss behaves as if Bernstein’s condition is in force.
The proof is elegant and uses two key ingredients. The first is a classical representation of the Gibbs posterior’s log-partition function as a negative-log-expectation, combined with the strong convexity of the negative log function on a bounded interval. The second is the definition of the optimal prior as the minimizer of expected meta-level loss, which provides a reference point around which the variance bound can be established through a midpoint convexity argument.
“The prior π can be learned with fast rates regardless of the rate within tasks. In other words, the meta-learning Gibbs algorithm achieves an excess risk of O(1/T) at the meta level, even when individual tasks only permit the slow O(1/√n) rate.” — Riou, Alquier & Chérief-Abdellatif · JMLR 26 (2025)
To put it differently: collecting more tasks is always worth it, and it is worth it at a rate that is qualitatively better than what naive reasoning would suggest. The cost of learning the prior decreases as 1/T rather than 1/√T, which in the regime where the number of tasks T is much larger than the per-task sample size n — the setting that motivates meta-learning in the first place — represents an enormous practical difference.
The Main Bound — What the Theorem Actually Says
The core result, Theorem 5, bounds the excess meta-risk of the learned prior against the best prior in the considered class. The full bound has a clean decomposition that separates within-task error from meta-level error. On the within-task side, you pay whatever rate your tasks support — either 1/n under Bernstein’s condition, or 1/√n without it. On the meta-level side, you always pay an additional term of order 1/T, reflecting the cost of learning the prior from T tasks.
Under standard assumptions with bounded loss, the meta-learning Gibbs algorithm achieves an excess meta-risk bounded by:
Error ≤ [best within-task error with optimal prior] + O(1/T)
The O(1/T) term reflects the cost of meta-learning the prior from T tasks. This term is always O(1/T) — never O(1/√T) — regardless of whether Bernstein’s condition holds within tasks. When Bernstein’s condition does hold within tasks, the within-task error is also O(1/n), giving an overall rate of O(1/n + 1/T). Without it, the within-task component degrades to O(1/√n), but the meta-level term remains O(1/T).
This decomposition has an important practical implication. In the regime where T is much larger than n — think of a recommender system with millions of users, each with only a handful of ratings — the 1/T term is negligible compared to the 1/n or 1/√n within-task term. Meta-learning the prior adds essentially no extra cost in this regime, while potentially dramatically reducing the within-task error by finding a better prior. The paper makes this quantitative through three concrete applications.
Three Applications That Make the Abstract Concrete
The paper does not stop at the general theorem. It works through three progressively richer settings to show what the fast meta-level rate means in practice.
The first setting considers a finite parameter space where there are M candidate values and a small subset of m* values that are actually optimal for tasks drawn from the environment. If you learn in isolation — ignoring all other tasks — you pay a within-task complexity term proportional to log(M)/n. But if you use meta-learning to learn which subset of parameters is actually useful, the within-task complexity drops to log(m*)/n. Since m* can be much smaller than M, this can be a dramatic improvement. The meta-learning cost is O(m* log(M/m*)/T), which vanishes when T grows large.
The second setting considers Gaussian priors over continuous parameter spaces, where the goal is to learn a good mean and variance for the prior distribution. Here the improvement depends on how concentrated the optimal parameters are across tasks. If the optimal parameter varies little across tasks — measured by a quantity the paper calls Σ(P) — then meta-learning can achieve a convergence rate of O(d/T) rather than O(d log n / n), where d is the parameter dimension. In the favorable low-variance regime, the gain from meta-learning can be enormous.
The third and most flexible setting considers mixtures of Gaussian priors, which can represent task environments where there are multiple clusters of related tasks. The bound naturally decomposes into three pieces: a term for identifying the right cluster (analogous to the finite case), a term for learning the within-cluster Gaussian (analogous to the single-Gaussian case), and a small meta-level penalty. The paper also handles the case where the number of mixture components is unknown and must be estimated from the data, showing that the additional cost is only O(log T / T) — a small price to pay for not needing to specify the model structure in advance.
Learning in Isolation
Each task is solved independently with a fixed prior. The error depends on the prior quality, and there is no mechanism to improve the prior from experience. In the Gaussian setting, the within-task error is O(d log n / n) and cannot be reduced by observing more tasks.
Meta-Learning with Gibbs
The prior is learned from T previous tasks. The within-task error can shrink to O(d/T) in favorable regimes — a rate that improves with the number of tasks rather than the per-task sample size. The meta-learning overhead is always O(1/T), making the total cost provably smaller when T is large.
Why This Result Matters for Real Machine Learning Systems
The gap between theory and practice in meta-learning has always been an uncomfortable one. Practitioners using MAML and its variants have seen compelling empirical results, but the theoretical guarantees available have often lagged behind, requiring assumptions that are difficult to verify in real-world settings. This paper tightens that gap in a meaningful way.
The key insight — that fast convergence at the meta level is automatic, requiring no special structure from individual tasks — validates the intuition that drives the field. When you have a large collection of tasks, learning from them collectively is genuinely more efficient than treating each one in isolation, and the efficiency improvement is quantifiably fast. This is not a trivial observation. It is a theorem that required novel mathematical tools to establish, building on the strong convexity of the log function and a careful use of the variational structure of the Gibbs posterior.
For practitioners thinking about when to use meta-learning, the result provides a clear heuristic. The regime where meta-learning pays off the most is when T is much larger than n — when you have many tasks but limited data per task. This covers a surprisingly wide range of real applications: personalized medicine where each patient is a task with few observations, natural language processing where each domain or language is a task with limited labeled data, and robotics where each environment configuration is a task requiring rapid adaptation.
If you are working in a setting where the number of tasks T substantially exceeds the per-task sample size n, the mathematics says you should use meta-learning and expect fast improvement as T grows. The rate of improvement in the prior quality is O(1/T) — always, without any fine print about the difficulty of individual tasks. Every additional task you observe makes the prior better at a guaranteed rate. This is not just an encouraging story; it is a proven bound.
An Open Door — Extending the Results to Variational Inference
One of the refreshingly honest aspects of this paper is the open question it raises at the end. The results apply to the exact Gibbs posterior, which is theoretically clean but computationally challenging to work with directly. In practice, meta-learning systems typically use variational approximations — replacing the exact Gibbs posterior with a tractable parametric family optimized to approximate it. Methods like variational autoencoders, normalizing flows, and mean-field approximations all fall into this category.
The authors conjecture that similar fast-rate guarantees should hold for variational approximations of the Gibbs posterior, but they leave this as an explicitly open problem. The difficulty is that variational approximations introduce an additional approximation error on top of the statistical error that the paper’s bounds control. Extending the analysis to handle this additional layer requires new tools, and the authors acknowledge this honestly rather than sweeping the issue under the rug.
This open question is significant precisely because it is what practitioners actually compute. A theoretical result that extends to variational methods would immediately translate into stronger guarantees for a wide range of deployed systems. The paper’s contribution is to establish the result in the exact case and make the gap to the variational case visible and well-defined, which is often how progress in theoretical machine learning works — establishing the right question is half the battle.
How This Relates to Prior Work — And Why It Goes Further
The results in this paper sit in a rich landscape of prior work on meta-learning theory. The PAC-Bayes approach to meta-learning was first proposed by Pentina and Lampert, who established that learning a hyper-posterior over priors could yield tighter generalization bounds than learning in isolation. Subsequent work by Amit and Meir, Rothfuss and collaborators, and others refined these bounds and extended them to unbounded losses and practical computational settings.
What distinguishes this paper is its focus on rates of convergence — specifically, the rate at which excess risk decays as T and n grow — rather than just the existence of generalization bounds. Earlier works provided empirical PAC-Bayes bounds that could be minimized to obtain practical algorithms with numerical certificates on generalization, but they did not characterize the speed at which these bounds improve with more data. The question of whether meta-learning achieves O(1/T) versus O(1/√T) convergence in the number of tasks had not been settled without restrictive assumptions.
The closest prior work to address this is Guan et al. (2022), which achieved fast rates in T under a Polyak-Łojasiewicz condition — a form of strong convexity that limits applicability. The current paper requires no such condition, instead exploiting the intrinsic structure of the Gibbs posterior and its log-partition representation to derive Bernstein’s condition at the meta level unconditionally. This is a genuine conceptual advance, not just an incremental improvement in constants or scope.
For any bounded loss function with constant C, any α ∈ (0, 1/C), and any prior π:
E[(L̂(π) − L̂(π*))²] ≤ 8eC · E[L̂(π) − L̂(π*)]
where L̂(π) is the empirical meta-level loss of prior π, and π* is the optimal prior. This bound holds unconditionally — it requires no Bernstein’s condition within tasks, no convexity assumptions, and no margin conditions. The coefficient 8eC is an absolute constant depending only on the loss bound.
What This Paper Changes for Anyone Working in Few-Shot Learning
For researchers and practitioners in few-shot learning — the setting where you need to generalize from just one, five, or ten examples per class — this paper provides theoretical backing for something that was previously a well-supported intuition: the more diverse tasks your meta-learner has seen, the better it performs on new tasks, and this improvement happens at a concrete, provable rate.
In image classification, this means that a meta-learned initialization trained on thousands of diverse visual categories will have a prior quality that improves provably with the number of training categories, at a 1/T rate, regardless of how easy or hard each category was to learn. In natural language processing, a meta-learned prior for domain adaptation will similarly improve with the number of source domains seen during meta-training. In medical machine learning, where each patient or disease cohort constitutes a task with limited data, the O(1/T) rate provides a quantitative argument for investing in large collections of related tasks even when per-task data is scarce.
The result also clarifies when learning in isolation is competitive with meta-learning. When T is small — say, fewer than a handful of tasks — the O(1/T) meta-level term is not particularly small, and the overhead of meta-learning may not be worthwhile. But as T grows into the hundreds or thousands, which is typical in modern large-scale meta-learning benchmarks, the meta-level rate dominates and the benefit of meta-learning is provably, not just empirically, real.
Read the Full Paper
Published open-access in the Journal of Machine Learning Research, Volume 26 (2025). Full proofs, all theorem statements, and appendix derivations are freely available through JMLR.
Charles Riou, Pierre Alquier, Badr-Eddine Chérief-Abdellatif. Bayes Meets Bernstein at the Meta Level: an Analysis of Fast Rates in Meta-Learning with PAC-Bayes. Journal of Machine Learning Research, 26 (2025) 1–60. http://jmlr.org/papers/v26/23-0259.html
This article is an independent editorial analysis of a peer-reviewed paper. Mathematical statements paraphrase the original results; for complete proofs and precise formulations, please consult the published paper. The paper was submitted March 2023, revised April 2024, and published January 2025.
References
- [1] P. Alquier. User-friendly Introduction to PAC-Bayes Bounds. Foundations and Trends in Machine Learning, 17(2):174–303, 2024.
- [2] P. Alquier, J. Ridgway, and N. Chopin. On the properties of variational approximations of Gibbs posteriors. Journal of Machine Learning Research, 17(239):1–41, 2016.
- [3] R. Amit and R. Meir. Meta-learning by adjusting priors based on extended PAC-Bayes theory. ICML, 2018.
- [4] P. L. Bartlett and S. Mendelson. Empirical minimization. Probability Theory and Related Fields, 135(3):311–334, 2006.
- [5] J. Baxter. A model of inductive bias learning. Journal of Artificial Intelligence Research, 12:149–198, 2000.
- [6] O. Catoni. PAC-Bayesian Supervised Classification: the Thermodynamics of Statistical Learning. IMS Lecture Notes – Monograph Series, 56, 2007.
- [7] G. Denevi, C. Ciliberto, R. Grazzi, and M. Pontil. Learning-to-learn stochastic gradient descent with biased regularization. ICML, 2019.
- [8] C. Finn, P. Abbeel, and S. Levine. Model-agnostic meta-learning for fast adaptation of deep networks. ICML, 2017.
- [9] J. Guan and Z. Lu. Fast-rate PAC-Bayesian generalization bounds for meta-learning. ICML, 2022.
- [10] E. Mammen and A. B. Tsybakov. Smooth discrimination analysis. The Annals of Statistics, 27(6):1808–1829, 1999.
- [11] A. Nichol, J. Achiam, and J. Schulman. On first-order meta-learning algorithms. arXiv:1803.02999, 2018.
- [12] A. Pentina and C. Lampert. A PAC-Bayesian bound for lifelong learning. ICML, 2014.
- [13] J. Rothfuss, V. Fortuin, M. Josifoski, and A. Krause. PACOH: Bayes-optimal meta-learning with PAC-guarantees. ICML, 2021.