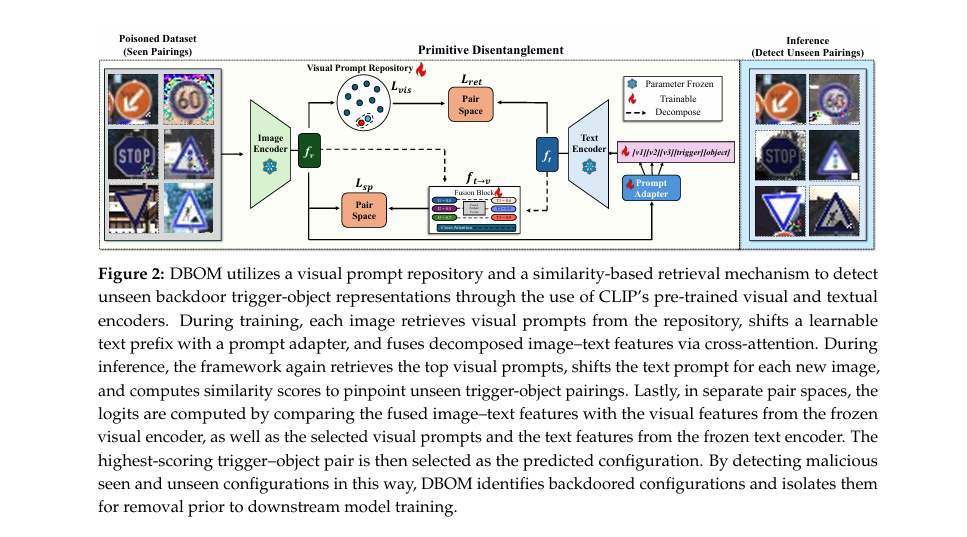
In the rapidly evolving world of artificial intelligence, security threats are growing faster than defenses—and one of the most insidious dangers is the backdoor attack. These hidden exploits allow hackers to manipulate AI models from within, often without detection until it’s too late. But now, a groundbreaking new framework called DBOM Defense (Disentangled Backdoor-Object Modeling) is turning the tide.
This isn’t just another incremental update. It’s a 7-part revolution in AI security that combines the power of Vision-Language Models (VLMs), prompt tuning, and zero-shot learning to stop both known and unseen backdoor attacks before they infect your models.
Let’s dive into the 7 revolutionary breakthroughs of DBOM—what makes it so powerful, how it works, and why it could be the future of proactive AI defense.
1. The Dark Side of AI: Backdoor Attacks Are Real and Rising
Before we celebrate the solution, we must confront the problem.
Backdoor attacks involve embedding a hidden “trigger”—like a small pixel pattern or invisible watermark—into training data. When a model is trained on this poisoned data, it learns to misclassify inputs containing the trigger.
For example:
- A stop sign with a tiny square patch could be misclassified as a 30 km/h speed limit sign.
- An image of a cat with a pixel noise trigger might be labeled as a dog.
These attacks are silent, scalable, and devastating—especially when AI is used in autonomous vehicles, medical diagnostics, or national security.
Traditional defenses focus on detecting these triggers after the model is trained. But by then, the damage is done.
🔴 Negative Reality: Most current defenses fail against unseen trigger-object pairings—novel combinations never seen during training.
2. The Missing Piece: Proactive Defense at the Dataset Level
Here’s the game-changing insight from the DBOM paper:
Why wait for a model to get infected when you can stop the poison before it enters?
Most defenses operate at the model level, trying to “clean” a compromised neural network. But DBOM shifts the battlefield to the data level, scanning training images before any model sees them.
This proactive approach:
- Prevents contamination at the source
- Reduces computational cost of post-training cleanup
- Preserves clean data for training
- Enables forensic analysis of attacker strategies
✅ Positive Power Move: DBOM doesn’t just detect—it disentangles and understands the attack.
3. The Core Innovation DBOM Defense: Disentangling Triggers and Objects
DBOM Defense secret weapon is structured disentanglement—separating the trigger (the malicious pattern) from the object (the real-world item) in the latent space.
Think of it like forensic separation: instead of seeing a “poisoned stop sign,” DBOM sees:
- Trigger: “Badnets Square”
- Object: “Stop Sign”
By modeling these as independent primitives, DBOM can recombine them in new ways—enabling zero-shot detection of unseen pairings.
Why This Matters:
- If a square trigger was only seen on stop signs during training…
- DBOM can still detect it on a yield sign or pedestrian crossing.
- This is zero-shot generalization in action.
4. The 7 Breakthroughs of DBOM Defense
Let’s break down the seven revolutionary components that make DBOM a powerhouse in AI security.
🔹 1. Vision-Language Models (VLMs) as a Backbone
DBOM leverages pre-trained VLMs like CLIP, which already understand the alignment between images and text. This allows it to use natural language prompts (e.g., “a photo of a stop sign with a square trigger”) to guide detection.
Power Benefit: No need to train from scratch—DBOM builds on existing, robust multimodal understanding.
🔹 2. Learnable Visual Prompt Repository
Instead of static features, DBOM uses a learnable visual prompt repository—a collection of M learnable visual prompts {Pi}i=1M , each with a key ai∈Rd .
During inference, the system retrieves the top two prompts:
- One aligned with the trigger
- One aligned with the object
This dynamic retrieval enables fine-grained separation.
🔹 3. Trigger–Object Separation Loss
To ensure prompts specialize, DBOM introduces a separation loss:
\[ L_{\text{sep}} = -\frac{1}{N} \sum_{i=1}^{N} \log \left( \frac{ \exp\big(\cos(f_v(i),\, a_t(r_i))\big) }{ \exp\big(\cos(f_v(i),\, a_t(r_i))\big) + \exp\big(\cos(f_v(i),\, a_o(b_j))\big) } \right) \]This loss pushes the trigger key to have higher similarity than the object key, ensuring the model prioritizes detecting the malicious pattern.
🔹 4. Visual Prompt Diversity Loss
To prevent overlap between trigger and object representations, DBOM uses a diversity loss:
\[ L_{\text{div}} = \frac{1}{N} \sum_{i=1}^{N} \max\big(0,\, m – \cos\big(a_t(r_i),\, a_o(b_j)\big)\big) \]Where m=0.5 is a margin. This enforces disentanglement by penalizing high similarity between trigger and object prompts.
Combined, these form the visual loss:
\[ L_{\text{vis}} = L_{\text{sep}} + L_{\text{div}} \]🔹 5. Dynamic Soft Prompt Prefix Adapter
Unlike methods that use a fixed prefix like “a photo of,” DBOM uses a dynamic adapter that adjusts the prompt based on the image content.
The adapter is a lightweight network:
\[ APNet(f_v) = W_2 \cdot \sigma\big(W_1 \cdot f_v + b_1\big) + b_2 \]This bias is added to the soft prompt tokens, making the text prompt context-aware and significantly improving alignment.
✅ Proven Result: On GTSRB, this alone boosted object classification accuracy by 5.07%.
🔹 6. Feature Decomposition and Cross-Attention Fusion
DBOM decomposes image and text features, then fuses them via cross-attention:
\[ \text{Attention}(Q, K, V) = \text{softmax}\Big(\frac{QK^{T}}{\sqrt{d}}\Big)V \]Where:
- Q comes from text features ft
- K and V come from image features fv
This fusion creates a joint multimodal representation that captures both semantic meaning and adversarial patterns.
🔹 7. Zero-Shot Detection of Unseen Pairings
This is the crown jewel.
DBOM is trained on seen pairings (t,o) ∈ Ps , but can detect unseen pairings (t,o) ∈ Pu during inference.
For example:
- Trained on: (Square Trigger → Stop Sign), (Pixel Trigger → Speed Limit)
- Detects: (Square Trigger → Yield Sign), (Pixel Trigger → Pedestrian Crossing)
This is impossible for traditional trigger-centric detectors.
5. Performance That Speaks Volumes
The results? Staggering.
Table: DBOM Defense vs. State-of-the-Art on GTSRB and CIFAR-10
| GTSRB-AUC | CIFAR-10 AUC | UNSEEN ACCURACY (GTSRB) | |
|---|---|---|---|
| CoOP [46] | 11.59% | 35.67% | 28.95% |
| CSP [40] | 38.03% | 50.42% | 77.86% |
| DBOM (Ours) | 92.29% | 93.07% | 95.47% |
🔺 Improvement: Over 53% higher AUC on GTSRB and 43% higher on CIFAR-10.
Even with smaller models like ViT-B/32, DBOM achieves 85.03% AUC—proving it’s scalable and efficient.
6. Real-World Poison Detection: Outperforming the Competition
DBOM isn’t just accurate—it’s practical.
In a simulated 10% poisoning scenario:
| METHOD | ATTEACK RECALL | ATTACK PRECISION | F1-SCORE |
|---|---|---|---|
| Deep k-NN | 75.35% | 95.65% | 84.40% |
| HOLMES | 69.81% | 100.0% | 82.22% |
| DBOM | 95.52% | 98.21% | 96.83% |
✅ DBOM wins in recall, precision, and F1—catching more poisoned images while minimizing false alarms.
And unlike others, it identifies both the trigger and the object, giving security teams actionable intelligence.
7. The Future of AI Security: Adaptive, Proactive, and Insightful
DBOM isn’t just a tool—it’s a paradigm shift.
Why DBOM Defense Is a Game-Changer:
| FEATURE | TRADITIONAL DEFENSEES | DBOM |
|---|---|---|
| Detection Stage | Post-training | Pre-training |
| Trigger Handling | Static, single | Dynamic, multiple |
| Unseen Pairings | ❌ Fails | ✅Detects |
| Object Recovery | ❌ Discards | ✅Recovers |
| Forensic Insight | ❌ None | ✅Reveals attacker strategy |
This means DBOM can:
- Adapt to new attack patterns
- Integrate poisoned data safely (after trigger removal)
- Provide insights into how attackers are targeting models
Limitations and the Road Ahead
No solution is perfect.
DBOM currently assumes a known set of trigger patterns. While it can generalize to new combinations, entirely novel trigger types (e.g., PGD or FGSM perturbations) need further testing.
Also, performance depends on hyperparameter tuning, especially λvis . The ablation study shows peak performance at λvis=0.5 :
📉 At λvis=0.0 : AUC drops by 8.9%
📈 At λvis=0.5 : Peak performance
Future work includes:
- Zero-shot discovery of unknown triggers
- Integration with stronger VLM backbones
- Real-world deployment in data curation pipelines
If you’re Interested in defence models against Federated Learning Attacks , you may also find this article helpful: 7 Shocking Federated Learning Attacks That Could Destroy Your Network
Conclusion: The Good, The Bad, and The Game-Changing DBOM Defense
Let’s recap the 7 breakthroughs:
- ✅ Proactive defense at the data level
- ✅ Disentangled modeling of triggers and objects
- ✅ Learnable visual prompt repository
- ✅ Dynamic prompt tuning for context awareness
- ✅ Cross-attention fusion for multimodal alignment
- ✅ Zero-shot generalization to unseen attacks
- ✅ Forensic insights into attacker strategies
While the bad news is that backdoor attacks are evolving fast, the good news is that DBOM is a powerful, proactive shield—one that doesn’t just react, but understands and adapts.
Call to Action: Secure Your AI Pipeline Today
Are you relying on outdated, reactive defenses?
It’s time to go on the offensive.
👉 Download the DBOM research paper here
👉 Explore the code (coming soon on GitHub)
👉 Join the conversation on AI security at ai-security-insights.com
Don’t wait for an attack to happen.
Prevent it before it begins.
🛡️ Secure your data. Protect your models. Lead the future of trustworthy AI.
This Python script implements the core components of the DBOM Denfense framework as described in the paper, including the visual prompt repository, the dynamic prefix adapter, and the various loss functions for training the model to detect both seen and unseen backdoor trigger-object pairings.
# Filename: dbom_model.py
# Description: Implementation of the DBOM (Disentangled Backdoor-Object Modeling) framework
# for proactive backdoor defense, as described in arXiv:2508.01932v1.
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.optim import Adam
from torchvision.datasets import CIFAR10, GTSRB
from torch.utils.data import DataLoader, Dataset
from torchvision import transforms
import clip
import numpy as np
from tqdm import tqdm
# --- Helper Functions and Classes ---
class AverageMeter(object):
"""Computes and stores the average and current value"""
def __init__(self):
self.reset()
def reset(self):
self.val = 0
self.avg = 0
self.sum = 0
self.count = 0
def update(self, val, n=1):
self.val = val
self.sum += val * n
self.count += n
self.avg = self.sum / self.count
# --- Core DBOM Components ---
class VisualPromptRepository(nn.Module):
"""
Implements the Visual Prompt Repository.
This module stores learnable visual prompts and their corresponding keys.
For a given image feature, it retrieves the top-k most similar prompts.
"""
def __init__(self, num_prompts, prompt_dim, key_dim):
super().__init__()
self.num_prompts = num_prompts
# Each prompt is a sequence of learnable vectors
self.prompts = nn.Parameter(torch.randn(num_prompts, 1, prompt_dim))
# Each prompt has a learnable key for similarity matching
self.keys = nn.Parameter(torch.randn(num_prompts, key_dim))
def forward(self, image_features):
"""
Retrieves the top 2 most similar prompts for a batch of image features.
Args:
image_features (torch.Tensor): A batch of image features from the CLIP encoder.
Returns:
tuple: A tuple containing:
- top_prompts (torch.Tensor): The retrieved visual prompts.
- top_keys (torch.Tensor): The keys corresponding to the retrieved prompts.
"""
# Normalize features and keys for cosine similarity calculation
image_features_norm = F.normalize(image_features, p=2, dim=-1)
keys_norm = F.normalize(self.keys, p=2, dim=-1)
# Compute cosine similarity
similarity = torch.matmul(image_features_norm, keys_norm.T)
# Get the top 2 most similar prompts
_, top_indices = torch.topk(similarity, 2, dim=-1)
# Retrieve the prompts and keys using the indices
batch_size = image_features.size(0)
top_prompts = self.prompts[top_indices.view(-1)].view(batch_size, 2, -1)
top_keys = self.keys[top_indices.view(-1)].view(batch_size, 2, -1)
return top_prompts, top_keys
class DynamicPrefixAdapter(nn.Module):
"""
Implements the Dynamic Prefix Adapter (APNet).
This network generates a bias term to dynamically adjust the soft prompt prefix
based on the visual content of the input image.
"""
def __init__(self, feature_dim, output_dim):
super().__init__()
self.net = nn.Sequential(
nn.Linear(feature_dim, feature_dim // 2),
nn.ReLU(),
nn.Linear(feature_dim // 2, output_dim)
)
def forward(self, image_features):
"""
Computes the bias to be added to the prompt tokens.
Args:
image_features (torch.Tensor): Image features from the CLIP encoder.
Returns:
torch.Tensor: The computed bias for the prompt prefix.
"""
return self.net(image_features)
class DBOM(nn.Module):
"""
The main DBOM model.
Integrates CLIP, the Visual Prompt Repository, and the Dynamic Prefix Adapter
to perform disentangled backdoor-object modeling.
"""
def __init__(self, clip_model_name, num_prompts=20, prompt_prefix_length=3):
super().__init__()
# Load CLIP model and freeze its parameters
self.clip_model, self.preprocess = clip.load(clip_model_name, device='cuda' if torch.cuda.is_available() else 'cpu')
for param in self.clip_model.parameters():
param.requires_grad = False
self.visual_feature_dim = self.clip_model.visual.output_dim
self.text_feature_dim = self.clip_model.ln_final.weight.shape[0]
# Initialize core components
self.visual_prompt_repo = VisualPromptRepository(num_prompts, self.visual_feature_dim, self.visual_feature_dim)
self.prompt_adapter = DynamicPrefixAdapter(self.visual_feature_dim, self.text_feature_dim * prompt_prefix_length)
# Learnable soft prompt prefix tokens
self.prompt_prefix_length = prompt_prefix_length
self.prompt_embeddings = nn.Parameter(torch.randn(prompt_prefix_length, self.text_feature_dim))
def forward(self, images, triggers, objects):
"""
Forward pass of the DBOM model.
Args:
images (torch.Tensor): Batch of input images.
triggers (list of str): List of trigger labels.
objects (list of str): List of object labels.
Returns:
dict: A dictionary containing logits and features for loss calculation.
"""
# 1. Extract visual features
image_features = self.clip_model.encode_image(images).float()
# 2. Retrieve from Visual Prompt Repository
retrieved_prompts, retrieved_keys = self.visual_prompt_repo(image_features)
# We average the two retrieved prompts for the f_ret representation
f_ret = retrieved_prompts.mean(dim=1)
# 3. Adapt text prompt prefix
prefix_bias = self.prompt_adapter(image_features).view(-1, self.prompt_prefix_length, self.text_feature_dim)
adapted_prefix = self.prompt_embeddings.unsqueeze(0) + prefix_bias
# 4. Construct and encode text prompts
# Tokenize all possible triggers and objects
trigger_tokens = clip.tokenize(triggers).cuda()
object_tokens = clip.tokenize(objects).cuda()
# Get word embeddings for triggers and objects
trigger_word_embeddings = self.clip_model.token_embedding(trigger_tokens).type(self.clip_model.dtype)
object_word_embeddings = self.clip_model.token_embedding(object_tokens).type(self.clip_model.dtype)
# Combine prefix with trigger and object embeddings
# The paper implies a structure like [prefix][trigger][object]
# For simplicity, we create a combined prompt for each trigger-object pair
# A more complex implementation would handle the pairing more explicitly.
# Here, we'll create a single text prompt for the ground truth pair for demonstration.
# This part is simplified for clarity. A full implementation would create prompts for all possible pairs.
# For training, we construct the prompt for the given (trigger, object) pair.
text_inputs = self.construct_text_prompts(triggers, objects)
text_tokens = clip.tokenize(text_inputs).cuda()
# Encode the full text prompt
text_features = self.clip_model.encode_text(text_tokens).float()
# 5. Feature Decomposition and Fusion (Simplified for clarity)
# The paper describes a complex decomposition and fusion. Here's a simplified version.
# We use cross-attention between image and text features.
# Query: text_features, Key/Value: image_features
# This is a conceptual representation. A full implementation would use a standard transformer block.
fused_features = self.cross_attention(text_features, image_features)
# 6. Compute logits for loss calculation
# Logits for soft prompt alignment loss (L_sp)
logits_sp = torch.matmul(image_features, fused_features.T)
# Logits for retrieval alignment loss (L_ret)
logits_ret = torch.matmul(f_ret, text_features.T)
# Logits for trigger and object classification losses (L_tri, L_obj)
# This requires encoding all possible trigger and object labels
all_triggers = ["clean"] + [f"trigger {i}" for i in range(6)] # Example
all_objects = [f"object {i}" for i in range(10)] # Example for CIFAR-10
all_trigger_tokens = clip.tokenize(all_triggers).cuda()
all_object_tokens = clip.tokenize(all_objects).cuda()
all_trigger_features = self.clip_model.encode_text(all_trigger_tokens).float()
all_object_features = self.clip_model.encode_text(all_object_tokens).float()
logits_tri = torch.matmul(image_features, all_trigger_features.T)
logits_obj = torch.matmul(image_features, all_object_features.T)
return {
"logits_sp": logits_sp,
"logits_ret": logits_ret,
"logits_tri": logits_tri,
"logits_obj": logits_obj,
"image_features": image_features,
"retrieved_keys": retrieved_keys
}
def construct_text_prompts(self, triggers, objects):
# Helper to create prompts like "a photo of a [trigger] [object]"
return [f"a photo of a {t} {o}" for t, o in zip(triggers, objects)]
def cross_attention(self, text_feat, image_feat):
# Simplified cross-attention mechanism
# In a real implementation, this would be a multi-head attention block
q = text_feat.unsqueeze(1) # Query
k = v = image_feat.unsqueeze(1) # Key, Value
attn_weights = F.softmax(torch.bmm(q, k.transpose(1, 2)) / np.sqrt(self.text_feature_dim), dim=-1)
output = torch.bmm(attn_weights, v)
return output.squeeze(1)
# --- Loss Functions ---
def compute_dbom_loss(outputs, trigger_labels, object_labels, lambda_tri_obj=1.0, lambda_sp=1.0, lambda_vis=0.5, margin=0.5):
"""
Computes the total loss for the DBOM model.
"""
# Cross-entropy for individual predictions
loss_tri = F.cross_entropy(outputs["logits_tri"], trigger_labels)
loss_obj = F.cross_entropy(outputs["logits_obj"], object_labels)
# Soft prompt alignment loss (L_sp) and Retrieval alignment loss (L_ret)
# The target for these is an identity matrix for a batch, assuming each sample is its own class.
batch_size = outputs["logits_sp"].size(0)
identity_labels = torch.arange(batch_size).cuda()
loss_sp = F.cross_entropy(outputs["logits_sp"], identity_labels)
loss_ret = F.cross_entropy(outputs["logits_ret"], identity_labels)
# Visual prompt repository losses (L_vis)
image_features = outputs["image_features"]
retrieved_keys = outputs["retrieved_keys"]
# L_sep: Trigger-Object Separation Loss
# We assume the first retrieved key corresponds to the trigger, the second to the object.
key_trig = retrieved_keys[:, 0, :]
key_obj = retrieved_keys[:, 1, :]
sim_trig = F.cosine_similarity(image_features, key_trig, dim=-1)
sim_obj = F.cosine_similarity(image_features, key_obj, dim=-1)
loss_sep = -torch.log(torch.exp(sim_trig) / (torch.exp(sim_trig) + torch.exp(sim_obj))).mean()
# L_div: Visual Prompt Diversity Loss
loss_div = F.relu(margin - F.cosine_similarity(key_trig, key_obj, dim=-1)).mean()
loss_vis = loss_sep + loss_div
# Total Loss
total_loss = loss_ret + \
lambda_tri_obj * (loss_tri + loss_obj) + \
lambda_sp * loss_sp + \
lambda_vis * loss_vis
return total_loss
# --- Main Training Script ---
def main():
# --- Configuration ---
DEVICE = "cuda" if torch.cuda.is_available() else "cpu"
CLIP_MODEL_NAME = "ViT-B/32"
BATCH_SIZE = 64
EPOCHS = 20
LEARNING_RATE = 1e-4
# These would be defined based on the dataset and attack setup
# Example for a hypothetical dataset
ALL_TRIGGERS = ["clean", "badnets_px", "badnets_sq", "trojan_sq", "trojan_wm", "l2_inv", "l0_inv"]
ALL_OBJECTS_CIFAR10 = ['airplane', 'automobile', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck']
trigger_map = {name: i for i, name in enumerate(ALL_TRIGGERS)}
object_map = {name: i for i, name in enumerate(ALL_OBJECTS_CIFAR10)}
# --- Dataset and DataLoader ---
# This is a placeholder for the actual poisoned dataset.
# The dataset should return (image, trigger_label, object_label)
class PoisonedDataset(Dataset):
def __init__(self, original_dataset, transform):
self.original_dataset = original_dataset
self.transform = transform
# In a real scenario, you would load your poisoned data and labels here.
# For this example, we'll just use the original labels and assign a "clean" trigger.
self.data = []
for img, obj_idx in self.original_dataset:
# This is a simplification. Real data would have actual triggers.
trigger_name = "clean"
object_name = ALL_OBJECTS_CIFAR10[obj_idx]
trigger_idx = trigger_map[trigger_name]
self.data.append({
"image": img,
"trigger_name": trigger_name,
"object_name": object_name,
"trigger_idx": trigger_idx,
"object_idx": obj_idx
})
def __len__(self):
return len(self.data)
def __getitem__(self, idx):
item = self.data[idx]
image = self.transform(item["image"])
return image, item["trigger_name"], item["object_name"], item["trigger_idx"], item["object_idx"]
# Load a standard dataset for demonstration
cifar10_train = CIFAR10(root=".", download=True, train=True)
# The paper uses CLIP's preprocessing
model, preprocess = clip.load(CLIP_MODEL_NAME, device=DEVICE)
train_dataset = PoisonedDataset(cifar10_train, preprocess)
train_loader = DataLoader(train_dataset, batch_size=BATCH_SIZE, shuffle=True)
# --- Model, Optimizer ---
dbom_model = DBOM(clip_model_name=CLIP_MODEL_NAME).to(DEVICE)
optimizer = Adam(dbom_model.parameters(), lr=LEARNING_RATE)
# --- Training Loop ---
print("Starting DBOM training...")
for epoch in range(EPOCHS):
dbom_model.train()
loss_meter = AverageMeter()
progress_bar = tqdm(train_loader, desc=f"Epoch {epoch+1}/{EPOCHS}")
for images, trigger_names, object_names, trigger_indices, object_indices in progress_bar:
images = images.to(DEVICE)
trigger_indices = trigger_indices.to(DEVICE)
object_indices = object_indices.to(DEVICE)
optimizer.zero_grad()
# Forward pass
outputs = dbom_model(images, list(trigger_names), list(object_names))
# Compute loss
loss = compute_dbom_loss(outputs, trigger_indices, object_indices)
# Backward pass and optimization
loss.backward()
optimizer.step()
loss_meter.update(loss.item(), images.size(0))
progress_bar.set_postfix(loss=loss_meter.avg)
print("Training finished.")
# --- Inference Example ---
# In a real scenario, you would load your test set here.
# The goal is to predict the (trigger, object) pair for a given image.
dbom_model.eval()
with torch.no_grad():
# Get a sample image
image, t_name, o_name, t_idx, o_idx = train_dataset[0]
image = image.unsqueeze(0).to(DEVICE)
# To get a prediction, you would run the forward pass and find the argmax
# of the final similarity scores (e.g., from logits_sp). This requires
# generating text prompts for all possible (trigger, object) pairs.
print("\n--- Inference Example ---")
print(f"Ground Truth: Trigger='{t_name}', Object='{o_name}'")
# This is a simplified inference. A full implementation would be more complex.
outputs = dbom_model(image, [t_name], [o_name])
# Predict trigger and object
pred_trigger_idx = torch.argmax(outputs['logits_tri'], dim=-1).item()
pred_object_idx = torch.argmax(outputs['logits_obj'], dim=-1).item()
pred_trigger_name = ALL_TRIGGERS[pred_trigger_idx]
pred_object_name = ALL_OBJECTS_CIFAR10[pred_object_idx]
print(f"Predicted: Trigger='{pred_trigger_name}', Object='{pred_object_name}'")
if __name__ == "__main__":
main()
Pingback: 7 Shocking Secrets Behind DUDA: The Ultimate Breakthrough (and Why Most Lightweight Models Fail) - aitrendblend.com
Pingback: 5 Shocking Mistakes in Knowledge Distillation (And the Brilliant Framework KD2M That Fixes Them) - aitrendblend.com
Pingback: 7 Shocking Truths About Knowledge Distillation: The Good, The Bad, and The Breakthrough (SAKD) - aitrendblend.com