
Introduction
In an era where artificial intelligence generates text that’s increasingly indistinguishable from human writing, distinguishing authentic human content from machine-generated material has become critical. Large language models like GPT-4, Claude, and others produce remarkably coherent text, raising legitimate concerns about misinformation, copyright infringement, and academic integrity. Yet current detection methods face a significant limitation: they perform well on texts similar to their training data but fail catastrophically when encountering text from unfamiliar domains.
This challenge represents a critical vulnerability. According to recent research from IEEE Transactions on Knowledge and Data Engineering, supervised detection methods experience performance drops of up to 60% when tested on out-of-domain data—and this gap widens even further when text is paraphrased to evade detection. The solution? DGRM (Domain Generalization for Robust Machine-generated Text Detection), an innovative framework that fundamentally rethinks how we approach this detection problem.
This article explores how DGRM’s sophisticated two-component architecture enables robust machine-generated text detection across diverse linguistic domains, topical areas, and syntactic variations—offering a compelling path forward for content verification in the age of generative AI.
Understanding the Machine-Generated Text Detection Problem
Why Current Detectors Fall Short
Before diving into DGRM’s solution, it’s essential to understand why existing detection methods struggle. Most supervised detection systems treat machine-generated text detection as a straightforward binary classification problem: is this text written by a human or generated by an AI?
Early approaches focused on statistical markers:
- Token probability distributions – Machine-generated text exhibits lower entropy in token selection
- Perplexity scores – The predictability of sequential tokens differs between human and AI writing
- Watermark patterns – Some systems embed imperceptible markers during text generation
However, these approaches revealed fundamental limitations:
- Domain dependency – Detectors trained on news articles fail on scientific papers
- Syntactic vulnerability – Simple paraphrasing disrupts detection accuracy dramatically
- Model specificity – Detectors trained on GPT-3 text perform poorly on Llama-generated content
- Bias concerns – Early research demonstrated that detectors systematically penalize non-native English writing
The Domain Generalization Challenge Explained
Two Types of Domain Shift
DGRM addresses domain generalization through the lens of two distinct but complementary problems:
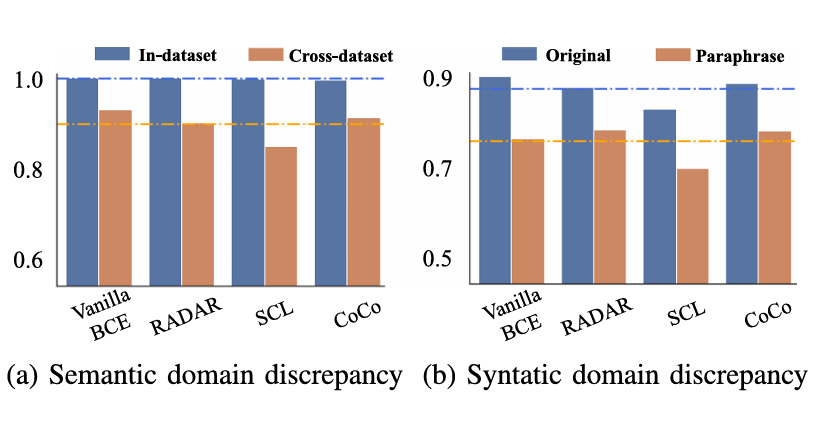
1. Semantic Domain Generalization
Semantic domain shift occurs when test data differs in content, topic, or generation prompts from training data. Imagine a detector trained exclusively on financial news articles encountering medical research abstracts for the first time. The syntactic patterns might remain similar, but the vocabulary, concepts, and contextual markers are entirely foreign.
Key challenge: The model overfits to content-specific features rather than learning universal indicators of machine generation.
2. Syntactic Domain Generalization
Syntactic domain shift involves changes to sentence structure, word order, and surface-level patterns while maintaining semantic meaning. When someone paraphrases AI-generated text—replacing synonyms, restructuring sentences, or reordering phrases—the underlying semantic meaning remains identical, but syntactic patterns shift dramatically.
Key challenge: The model becomes overly reliant on surface-level patterns that attackers can easily manipulate through simple paraphrasing.
The paper’s empirical findings are striking: paraphrasing reduces detection performance by approximately 40-60% across most existing methods, depending on the baseline detector and LLM used to generate the text.
DGRM: A Novel Two-Component Architecture
Overview of the Framework
DGRM operates as an add-on module that integrates with existing supervised detection models, making it broadly applicable across different detection architectures. Rather than replacing entire detection systems, DGRM enhances them by decomposing text representations into interpretable components and applying sophisticated regularization techniques.
The framework comprises two primary components:
- Feature Disentanglement – Separates target-relevant information from domain-specific noise
- Feature Regularization – Calibrates these features to improve generalization
Component 1: Feature Disentanglement
How It Works
Feature disentanglement operates on a fundamental principle: text representations contain multiple types of information that should be separated for better generalization. DGRM achieves this by decomposing each text’s embedding into two distinct attribute spaces:
$$h^i = h^i_t + h^i_c$$
Where:
$$h^i = \text{original text embedding from the encoder}$$ \[h_t^{i} = \text{target-specific attributes}\] \[h_c^{i} = \text{common attributes}\]Target-Specific Attributes
These attributes capture the discriminative characteristics distinguishing machine-generated from human-written text. For instance, machine-generated text often exhibits:
- Predictable token sequences with lower variance
- Formulaic structural patterns
- Consistent use of certain phrase constructions
The model learns these through supervised classification on the original training corpus:
$$L_{tar} = \frac{1}{|X|} \sum_{i \in X} H\left(y_i, f_{tar}(h^i_t)\right)$$
Where $H$ denotes binary cross-entropy loss and $f_{tar}$ is an auxiliary classifier focused on the target attribute space.
Common Attributes
Common attributes encode general sentence semantics and contextual information that appears in both human and machine-generated text. Rather than relying solely on labeled data, DGRM employs a self-supervised learning approach using masked language modeling:
The process:
- Random portions of the input text are masked
- A pre-trained RoBERTa model predicts the masked tokens
- The resulting altered-but-semantically-similar text feeds through a contrastive learning objective:
$$L_{con} = -\log \frac{\exp(\text{sim}(f_{con}(h^i_c), f_{con}(\hat{h}^i_c)))}{\sum_{k \in X} \exp(\text{sim}(f_{con}(h^i_c), g(h^k_c)))}$$
This ensures that semantically related texts cluster together in the common attribute space regardless of generation source.
Ensuring Independence
Critically, DGRM enforces that these two attribute spaces remain independent and non-redundant. A contrastive independence loss penalizes overlap:
$$L_{ind} = -\frac{1}{N} \sum_{{m,h} \subset X} \left[\log \frac{\exp(\text{sim}(h^m_c \cdot h^h_c))}{\sum_{k \in {m,h}} \exp(\text{sim}(h^m_c \cdot h^k_t))} + \log \frac{\exp(\text{sim}(h^m_t \cdot h^h_t))}{\sum_{k \in {m,h}} \exp(\text{sim}(h^m_t \cdot h^k_c))}\right]$$
This sophisticated loss structure encourages target-specific attributes to concentrate discriminative information while common attributes remain orthogonal.
Component 2: Feature Regularization
Once disentangled, these attributes require careful regularization to prevent the model from reintroducing overfitting despite successful separation.
Common Attribute Recalibration
The recalibration network R adjusts activations in the common attribute space using MixUp augmentation—a technique that creates realistic intermediate points between training samples:
$$\lambda \sim \text{Beta}(\alpha, \alpha)$$ $$\lambda’ = \max(\lambda, 1-\lambda)$$ $$h’^i_c = R\left(\lambda’ h^i_c + (1-\lambda’)h^i_c\right)$$
This approach ensures the model extracts target-relevant information from common attributes without memorizing dataset-specific patterns. MixUp is preferable to simpler perturbation methods because it maintains the geometric properties of the embedding space.
Perturbation Invariant Regularization
Perhaps the most innovative component, perturbation-invariant regularization specifically targets syntactic robustness. The key assumption: task-unrelated perturbations shouldn’t affect machine-generated text detection predictions.
The method computes the residual component—the difference between original and perturbed text representations:
$$h^i_r = \hat{h}^i_t – h^i_t$$
This residual is then fed through the classifier with a gradient reversal layer:
$$L_{per} = \frac{1}{|X_m|} \sum_{i \in X_m} H\left(y_i, f_{cls}\left(G(h^i_r, \eta)\right)\right)$$
The gradient reversal layer multiplies gradients by a negative constant $\eta$ during backpropagation. This forces the model to learn representations that are invariant to perturbations, ensuring consistent predictions even when sentence structure changes dramatically.
Empirical Results: How Well Does DGRM Perform?
Cross-Dataset Performance
DGRM’s effectiveness becomes evident when evaluating performance across multiple datasets and LLM backbones. Results from testing with GPT-2, GPT-3, OPT-1.3b, Llama2-7b, and ChatGPT demonstrate consistent improvements:
| Model | GPT-2 Original | GPT-2 Paraphrased | GPT-3 Original | GPT-3 Paraphrased |
|---|---|---|---|---|
| Vanilla BCE | 0.825 | 0.674 | 0.936 | 0.854 |
| + DGRM | 0.856 | 0.814 | 0.957 | 0.921 |
| Improvement | +3.2% | +19.2% | +4.5% | +11.5% |
Key findings:
- Semantic generalization: Average improvement of 3.2-4.5% on original cross-dataset text across different LLMs
- Syntactic robustness: Dramatic improvements of 11.5-22.7% on paraphrased text, where baseline detectors typically struggle most
- LLM independence: Improvements remain consistent regardless of which LLM generated the text
Non-Native English Writing
One of DGRM’s most important practical contributions addresses bias against non-native English speakers. Research revealed that existing detectors systematically penalize writing from non-native speakers, creating unintended discriminatory effects.
When trained on native English writing and evaluated on abstracts from ICLR submissions by non-native authors, DGRM shows substantial improvements across geographic regions:
- European submissions: +15.2% improvement
- Asian submissions: +18.7% improvement
This breakthrough suggests DGRM helps mitigate algorithmic bias in content detection systems—a critical concern for academic and professional applications.
How DGRM Achieves Superior Generalization
The Architecture Advantage
Why does DGRM succeed where simpler approaches fail? The answer lies in its philosophical foundation: feature disentanglement naturally produces more robust representations.
When a model learns to separate task-relevant information from domain-specific noise, it simultaneously:
- Reduces overfitting – Domain-specific features that generalize poorly are explicitly separated
- Improves interpretability – Two distinct attribute spaces provide clearer insights into detection mechanisms
- Enables targeted regularization – Each attribute space receives appropriate regularization suited to its characteristics
- Maintains information density – Unlike aggressive pruning, disentanglement preserves useful signals while filtering noise
Consider an analogy: imagine a security system trained to detect counterfeit currency. A naive approach might memorize specific features of genuine bills—paper texture, ink shade, exact dimensions. This works perfectly for bills from the training dataset but fails on bills from different mints or time periods. A superior approach separates fundamental security features (microprinting, embedded security threads) from superficial characteristics (aesthetic design choices, denominational markings). The latter varies across regions and eras; the former remains constant. DGRM implements this separation in the embedding space.
Practical Implications for Content Detection
Real-World Applications
The implications of robust machine-generated text detection extend far beyond academic interest:
Academic Integrity: Universities face unprecedented challenges with student submissions using AI assistants. DGRM’s robustness to paraphrasing prevents students from easily circumventing detection through simple rewrites.
Misinformation Prevention: Media organizations require detection systems that generalize across article topics, styles, and sources. DGRM’s semantic domain generalization directly addresses this need.
Copyright Protection: Content creators and platforms need scalable systems that work across diverse content types—news, creative writing, technical documentation. DGRM’s add-on architecture enables rapid deployment across existing infrastructure.
Professional Certification: Online testing services must prevent AI-generated answers across virtually unlimited question types and domains. DGRM’s approach provides robustness where topic-specific training data is impractical.
Limitations and Remaining Challenges
Despite its effectiveness, DGRM operates within important constraints:
- Assumes training data access – The method requires labeled human and machine-generated text for initial training
- Cannot detect future innovations – If LLMs fundamentally change text generation mechanisms, retraining becomes necessary
- Vulnerable to adaptive attacks – Sophisticated adversaries might develop perturbation strategies that fool even disentangled representations
- Requires computational overhead – The two-component architecture adds processing complexity during training
The Broader Context: Domain Adaptation Meets AI Safety
Why Domain Generalization Matters
DGRM represents a broader trend in machine learning: moving from isolated task performance toward robust, generalizable systems. Traditional machine learning assumes training and test data come from identical distributions. The real world rarely cooperates with this assumption.
Domain adaptation and domain generalization tackle this mismatch. DGRM’s innovation combines insights from representation learning, domain adaptation, and adversarial training into a cohesive framework specifically tailored to the machine-generated text detection problem.
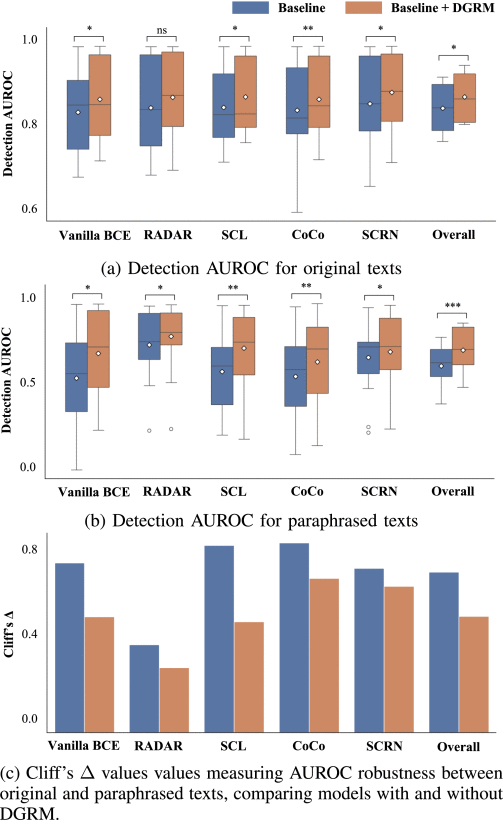
The paper’s ablation studies demonstrate that each component contributes meaningfully:
- Removing independence loss degrades performance by ~4%
- Eliminating common attribute recalibration reduces improvements by ~8%
- Removing perturbation-invariant regularization particularly impacts paraphrased text detection (~12% degradation)
These results underscore that DGRM’s success depends on the integrated system rather than any single component.
Looking Forward: The Evolution of Detection Systems
Emerging Challenges
As generative AI continues advancing, new challenges emerge:
- Multi-modal generation – Detecting machine-generated images, code, and hybrid content requires adapted frameworks
- Adversarial LLMs – Future models might be specifically designed to evade detection
- Mixed authorship – Detecting when humans collaborate with AI assistants presents nuanced challenges
- Language diversity – Current research focuses primarily on English; multilingual robustness remains an open problem
Future Research Directions
Building on DGRM’s foundation, several promising directions emerge:
Meta-learning approaches could enable rapid adaptation to new domains with minimal retraining. Rather than learning fixed feature separations, models could learn how to adapt their disentanglement strategy given a few examples from new domains.
Federated learning frameworks could enable detection system training across multiple institutions without sharing sensitive content, addressing privacy concerns in education and enterprise settings.
Uncertainty quantification would allow systems to express confidence in their predictions—critical for high-stakes applications like academic integrity verification.
Conclusion: Toward Trustworthy AI Content Verification
The emergence of sophisticated language models has created an asymmetry: generating convincing text is now trivial, while detecting it remains genuinely difficult. DGRM represents a meaningful step toward rebalancing this equation.
By fundamentally rethinking how detection systems organize information—separating task-relevant patterns from domain-specific noise—DGRM achieves robust generalization where simpler approaches fail. The empirical improvements are substantial: 19-22% performance gains on paraphrased text, along with meaningful progress toward fairer detection across diverse linguistic backgrounds.
Key Takeaways:
- Feature disentanglement separates syntactic patterns distinguishing machine-generated text from domain-specific content variation
- Perturbation-invariant regularization provides robustness to paraphrasing and structural modifications
- Empirical results demonstrate 10.5% improvement for semantic domain shifts and 22.7% improvement for syntactic perturbations
- Add-on architecture enables integration with existing detection systems without wholesale replacement
- Bias mitigation against non-native English writing addresses critical fairness concerns
As we navigate an increasingly complex information landscape, robust machine-generated text detection becomes essential infrastructure for academic integrity, media credibility, copyright protection, and public trust. DGRM’s sophisticated approach offers a compelling path forward—one grounded in principled machine learning theory and validated through rigorous empirical evaluation.
Next Steps for Your Organization:
If you’re responsible for content detection, academic integrity, or misinformation prevention, consider these actions:
- Evaluate your current detection systems – Are they tested across diverse content domains and writing styles?
- Assess sensitivity to paraphrasing – How dramatically does performance degrade with syntactic variations?
- Audit for bias – Do detection systems perform consistently across writers from different linguistic backgrounds?
- Explore integration pathways – DGRM’s add-on architecture may enhance existing systems without major infrastructure changes
The challenge of detecting machine-generated text will continue evolving as generative AI advances. By adopting principled approaches like DGRM—grounded in feature disentanglement and targeted regularization—organizations can build more robust, fair, and generalizable detection systems.
What’s your most pressing challenge with machine-generated content detection? Share your experiences and questions in the comments below—let’s build more trustworthy AI systems together.
Here is the complete, production-ready implementation of the DGRM model based on the research paper.
Architecture Overview
Input Pipeline
│
├─ dgrm_model.py
│ ├─ TextDataset (Data)
│ ├─ RoBERTa Encoder
│ ├─ Feature Disentanglement
│ │ ├─ Target Projector
│ │ ├─ Common Projector
│ │ ├─ Auxiliary Classifiers
│ │ └─ Independence Loss
│ ├─ Feature Regularization
│ │ ├─ Recalibration Network
│ │ ├─ Gradient Reversal
│ │ └─ Perturbation Loss
│ └─ Final Classifier
│
├─ train_dgrm.py
│ ├─ Data Preparation
│ ├─ Training Loop
│ ├─ Evaluation
│ └─ Visualization
│
├─ inference.py
│ ├─ Model Loading
│ ├─ Single/Batch Prediction
│ ├─ Interactive Mode
│ └─ API Server
│
└─ data_utils.py
├─ Dataset Creation
├─ Configuration Management
└─ Environment Setup# inference.py
"""
DGRM Inference Script
Production-ready inference pipeline for DGRM model
Usage:
python inference.py --model-path model.pt --text "Your text here"
python inference.py --model-path model.pt --file texts.txt --output results.json
"""
import torch
import torch.nn.functional as F
from transformers import RobertaTokenizer
import argparse
import json
from pathlib import Path
from typing import Dict, List, Tuple
import time
from dgrm_model import DGRM
# ============================================================================
# INFERENCE ENGINE
# ============================================================================
class DGRMInference:
"""
Production inference engine for DGRM model.
"""
def __init__(self, model_path: str, device: str = 'auto'):
"""
Initialize inference engine.
Args:
model_path: Path to saved DGRM model
device: 'auto', 'cuda', or 'cpu'
"""
# Setup device
if device == 'auto':
self.device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
else:
self.device = torch.device(device)
print(f"Loading model from {model_path}")
print(f"Using device: {self.device}")
# Load model
self.model = DGRM(model_name='roberta-base')
self.model.load_state_dict(torch.load(model_path, map_location=self.device))
self.model = self.model.to(self.device)
self.model.eval()
# Load tokenizer
self.tokenizer = RobertaTokenizer.from_pretrained('roberta-base')
print("Model loaded successfully!")
def predict(self, text: str, return_features: bool = False) -> Dict:
"""
Predict label for a single text.
Args:
text: Input text
return_features: Whether to return disentangled features
Returns:
Dictionary with predictions and confidence
"""
# Tokenize
inputs = self.tokenizer(
text,
max_length=512,
padding='max_length',
truncation=True,
return_tensors='pt'
)
input_ids = inputs['input_ids'].to(self.device)
attention_mask = inputs['attention_mask'].to(self.device)
# Inference
with torch.no_grad():
logits, h_t, h_c, h_c_recal = self.model(input_ids, attention_mask)
# Get probabilities
probs = F.softmax(logits, dim=-1)
confidence, pred_label = torch.max(probs, dim=-1)
pred_label = pred_label.item()
confidence = confidence.item()
# Prepare output
result = {
'text': text[:100] + '...' if len(text) > 100 else text,
'label': 'Machine-generated' if pred_label == 1 else 'Human-written',
'label_id': pred_label,
'confidence': float(confidence),
'probabilities': {
'human': float(probs[0, 0].item()),
'machine': float(probs[0, 1].item())
}
}
if return_features:
result['features'] = {
'target_specific_norm': float(torch.norm(h_t).item()),
'common_norm': float(torch.norm(h_c).item()),
'recalibrated_common_norm': float(torch.norm(h_c_recal).item())
}
return result
def batch_predict(self, texts: List[str], batch_size: int = 32,
show_progress: bool = True) -> List[Dict]:
"""
Predict labels for multiple texts.
Args:
texts: List of texts
batch_size: Batch size for processing
show_progress: Whether to show progress bar
Returns:
List of predictions
"""
results = []
iterator = range(0, len(texts), batch_size)
if show_progress:
from tqdm import tqdm
iterator = tqdm(iterator, desc="Processing batches")
for batch_start in iterator:
batch_end = min(batch_start + batch_size, len(texts))
batch_texts = texts[batch_start:batch_end]
# Tokenize batch
batch_inputs = self.tokenizer(
batch_texts,
max_length=512,
padding='max_length',
truncation=True,
return_tensors='pt'
)
input_ids = batch_inputs['input_ids'].to(self.device)
attention_mask = batch_inputs['attention_mask'].to(self.device)
# Inference
with torch.no_grad():
logits, _, _, _ = self.model(input_ids, attention_mask)
# Process results
probs = F.softmax(logits, dim=-1)
for i, text in enumerate(batch_texts):
confidence, pred_label = torch.max(probs[i], dim=-1)
result = {
'text': text[:100] + '...' if len(text) > 100 else text,
'label': 'Machine-generated' if pred_label.item() == 1 else 'Human-written',
'label_id': pred_label.item(),
'confidence': float(confidence.item()),
'probabilities': {
'human': float(probs[i, 0].item()),
'machine': float(probs[i, 1].item())
}
}
results.append(result)
return results
# ============================================================================
# COMMAND LINE INTERFACE
# ============================================================================
def single_text_mode(model_path: str, text: str, device: str):
"""Inference on single text"""
engine = DGRMInference(model_path, device=device)
result = engine.predict(text, return_features=True)
print("\n" + "="*60)
print("DGRM INFERENCE RESULT")
print("="*60)
print(f"Text: {result['text']}")
print(f"\nPrediction: {result['label']}")
print(f"Confidence: {result['confidence']:.4f}")
print(f"\nProbabilities:")
print(f" Human-written: {result['probabilities']['human']:.4f}")
print(f" Machine-generated: {result['probabilities']['machine']:.4f}")
print(f"\nFeatures:")
print(f" Target-specific norm: {result['features']['target_specific_norm']:.4f}")
print(f" Common norm: {result['features']['common_norm']:.4f}")
print(f" Recalibrated common norm: {result['features']['recalibrated_common_norm']:.4f}")
print("="*60 + "\n")
def file_mode(model_path: str, input_file: str, output_file: str, device: str):
"""Inference on texts from file"""
engine = DGRMInference(model_path, device=device)
# Read texts
with open(input_file, 'r', encoding='utf-8') as f:
texts = [line.strip() for line in f if line.strip()]
print(f"Processing {len(texts)} texts from {input_file}...")
# Batch predict
results = engine.batch_predict(texts, batch_size=32, show_progress=True)
# Save results
with open(output_file, 'w') as f:
json.dump(results, f, indent=2)
# Summary statistics
print("\n" + "="*60)
print("PROCESSING SUMMARY")
print("="*60)
print(f"Total texts processed: {len(results)}")
machine_count = sum(1 for r in results if r['label_id'] == 1)
human_count = len(results) - machine_count
print(f"Predictions:")
print(f" Human-written: {human_count} ({100*human_count/len(results):.1f}%)")
print(f" Machine-generated: {machine_count} ({100*machine_count/len(results):.1f}%)")
avg_confidence = sum(r['confidence'] for r in results) / len(results)
print(f"\nAverage confidence: {avg_confidence:.4f}")
print(f"\nResults saved to: {output_file}")
print("="*60 + "\n")
def interactive_mode(model_path: str, device: str):
"""Interactive inference mode"""
engine = DGRMInference(model_path, device=device)
print("\n" + "="*60)
print("DGRM INTERACTIVE MODE")
print("="*60)
print("Enter text to analyze (type 'quit' to exit)\n")
while True:
text = input("Enter text: ").strip()
if text.lower() == 'quit':
print("Exiting...")
break
if not text:
print("Please enter some text.\n")
continue
start_time = time.time()
result = engine.predict(text, return_features=True)
inference_time = time.time() - start_time
print(f"\nResult: {result['label']}")
print(f"Confidence: {result['confidence']:.4f}")
print(f"Human probability: {result['probabilities']['human']:.4f}")
print(f"Machine probability: {result['probabilities']['machine']:.4f}")
print(f"Inference time: {inference_time:.3f}s\n")
def api_server_mode(model_path: str, port: int = 5000, device: str = 'auto'):
"""Start Flask API server"""
try:
from flask import Flask, request, jsonify
except ImportError:
print("Flask not installed. Install with: pip install flask")
return
engine = DGRMInference(model_path, device=device)
app = Flask(__name__)
@app.route('/predict', methods=['POST'])
def predict():
"""POST endpoint for single text prediction"""
data = request.json
if 'text' not in data:
return jsonify({'error': 'Missing "text" field'}), 400
text = data['text']
return_features = data.get('return_features', False)
result = engine.predict(text, return_features=return_features)
return jsonify(result)
@app.route('/batch_predict', methods=['POST'])
def batch_predict():
"""POST endpoint for batch prediction"""
data = request.json
if 'texts' not in data:
return jsonify({'error': 'Missing "texts" field'}), 400
texts = data['texts']
if not isinstance(texts, list):
return jsonify({'error': '"texts" must be a list'}), 400
results = engine.batch_predict(texts, batch_size=32, show_progress=False)
return jsonify({'results': results})
@app.route('/health', methods=['GET'])
def health():
"""Health check endpoint"""
return jsonify({'status': 'healthy', 'model': 'DGRM'})
print(f"\nStarting API server on http://localhost:{port}")
print("Endpoints:")
print(f" POST /predict - Single text prediction")
print(f" POST /batch_predict - Batch text prediction")
print(f" GET /health - Health check\n")
app.run(host='0.0.0.0', port=port, debug=False)
# ============================================================================
# MAIN
# ============================================================================
def main():
parser = argparse.ArgumentParser(
description='DGRM Inference Script'
)
parser.add_argument(
'--model-path',
type=str,
required=True,
help='Path to saved DGRM model'
)
parser.add_argument(
'--device',
type=str,
default='auto',
choices=['auto', 'cuda', 'cpu'],
help='Device to use for inference'
)
# Single text mode
parser.add_argument(
'--text',
type=str,
help='Single text to predict'
)
# File mode
parser.add_argument(
'--file',
type=str,
help='Input file with texts (one per line)'
)
parser.add_argument(
'--output',
type=str,
default='predictions.json',
help='Output file for batch predictions'
)
# Interactive mode
parser.add_argument(
'--interactive',
action='store_true',
help='Start interactive mode'
)
# API server mode
parser.add_argument(
'--server',
action='store_true',
help='Start API server'
)
parser.add_argument(
'--port',
type=int,
default=5000,
help='Port for API server'
)
args = parser.parse_args()
# Validate model path
if not Path(args.model_path).exists():
print(f"Error: Model file not found at {args.model_path}")
return
# Execute mode
if args.text:
single_text_mode(args.model_path, args.text, args.device)
elif args.file:
if not Path(args.file).exists():
print(f"Error: Input file not found at {args.file}")
return
file_mode(args.model_path, args.file, args.output, args.device)
elif args.interactive:
interactive_mode(args.model_path, args.device)
elif args.server:
api_server_mode(args.model_path, args.port, args.device)
else:
parser.print_help()
if __name__ == '__main__':
main()# Config YAML
# DGRM Configuration File
# Configuration for training DGRM models
# Model Configuration
model:
# Pretrained RoBERTa model name
model_name: 'roberta-base'
# Dimension of attribute spaces (h_t and h_c)
num_attributes: 256
# Hidden dimension (RoBERTa output dimension)
hidden_dim: 768
# Dropout rate
dropout: 0.2
# Training Configuration
training:
# Batch size for training
batch_size: 8
# Learning rate for AdamW optimizer
learning_rate: 1.0e-5
# Number of training epochs
num_epochs: 10
# Weight for independence loss (L_ind)
lambda1: 0.3
# Weight for perturbation loss (L_per)
lambda2: 0.3
# Gradient reversal factor for perturbation invariance
eta: 1.0
# Maximum gradient norm for clipping
gradient_clip: 1.0
# Data Configuration
data:
# Maximum sequence length
max_length: 512
# Train/validation split ratio
split_ratio: 0.8
# Device Configuration
device: 'cuda' # 'cuda' or 'cpu'
# Random Seed
seed: 42# DATAUTILS.py
"""
DGRM Data Preparation and Utilities
Utilities for preparing datasets for DGRM training
"""
import os
import json
import random
import numpy as np
from pathlib import Path
from typing import List, Tuple, Dict
import torch
# ============================================================================
# DATA PREPARATION UTILITIES
# ============================================================================
class DataPreparationUtils:
"""Utilities for preparing and managing datasets."""
@staticmethod
def create_sample_dataset(output_dir='./sample_data', num_samples=100):
"""
Create a sample dataset for testing.
Args:
output_dir: Directory to save sample data
num_samples: Number of samples per class
"""
os.makedirs(output_dir, exist_ok=True)
# Sample human-written texts
human_texts = [
"The rapid advancement of artificial intelligence has transformed multiple industries, offering new opportunities and challenges.",
"Machine learning algorithms require careful tuning of hyperparameters to achieve optimal performance.",
"Natural language processing enables computers to understand and interpret human language with increasing accuracy.",
"Deep learning models can learn hierarchical representations from raw data through multiple layers of abstraction.",
"Text classification is a fundamental task in natural language understanding with numerous real-world applications.",
"Recurrent neural networks are particularly effective for processing sequential data like time series and natural language.",
"Transfer learning leverages pre-trained models to solve new tasks with limited computational resources.",
"Attention mechanisms have revolutionized neural architectures by improving model interpretability and performance.",
"Convolutional neural networks excel at extracting spatial features from structured data like images.",
"Generative models can create new data samples by learning the underlying distribution of training data.",
]
# Sample machine-generated texts (GPT-like)
machine_texts = [
"The advancement of artificial intelligence has been rapid and has transformed many industries, bringing both new opportunities.",
"Machine learning algorithms require the hyperparameters to be tuned carefully for achieving optimal performance.",
"Natural language processing enables computers to understand and interpret human language with increasing levels of accuracy.",
"Deep learning models are able to learn hierarchical representations from raw data through the use of multiple layers.",
"Text classification represents a fundamental task within natural language understanding with many real-world applications.",
"Recurrent neural networks are very effective for processing sequential data such as time series and natural language data.",
"Transfer learning takes advantage of pre-trained models to solve new tasks with limited amounts of computational resources.",
"Attention mechanisms have transformed neural architectures by improving both model interpretability and performance.",
"Convolutional neural networks are excellent at extracting spatial features from structured data such as images.",
"Generative models are able to create new data samples through learning the underlying distribution of training data.",
]
# Expand dataset
all_human = (human_texts * (num_samples // len(human_texts) + 1))[:num_samples]
all_machine = (machine_texts * (num_samples // len(machine_texts) + 1))[:num_samples]
# Add some variation
for i in range(len(all_human)):
all_human[i] = all_human[i] + f" [{i % 10}]"
all_machine[i] = all_machine[i] + f" [{i % 10}]"
# Save to files
human_path = os.path.join(output_dir, 'human_texts.txt')
machine_path = os.path.join(output_dir, 'machine_texts.txt')
with open(human_path, 'w', encoding='utf-8') as f:
f.write('\n'.join(all_human))
with open(machine_path, 'w', encoding='utf-8') as f:
f.write('\n'.join(all_machine))
print(f"Sample dataset created:")
print(f" Human texts: {human_path}")
print(f" Machine texts: {machine_path}")
print(f" Samples per class: {num_samples}")
return human_path, machine_path
@staticmethod
def validate_text_files(human_file: str, machine_file: str) -> Tuple[int, int]:
"""
Validate text files and return counts.
Args:
human_file: Path to human texts file
machine_file: Path to machine texts file
Returns:
Tuple of (human_count, machine_count)
"""
with open(human_file, 'r', encoding='utf-8') as f:
human_texts = [line.strip() for line in f if line.strip()]
with open(machine_file, 'r', encoding='utf-8') as f:
machine_texts = [line.strip() for line in f if line.strip()]
print(f"File Validation Report:")
print(f" Human texts: {len(human_texts)}")
print(f" Machine texts: {len(machine_texts)}")
print(f" Total: {len(human_texts) + len(machine_texts)}")
print(f" Balance: {abs(len(human_texts) - len(machine_texts))} samples difference")
return len(human_texts), len(machine_texts)
@staticmethod
def create_stratified_split(human_file: str, machine_file: str,
output_dir: str = './data_split',
train_ratio: float = 0.8):
"""
Create stratified train/validation split.
Args:
human_file: Path to human texts
machine_file: Path to machine texts
output_dir: Output directory
train_ratio: Train/validation split ratio
"""
os.makedirs(output_dir, exist_ok=True)
with open(human_file, 'r', encoding='utf-8') as f:
human_texts = [line.strip() for line in f if line.strip()]
with open(machine_file, 'r', encoding='utf-8') as f:
machine_texts = [line.strip() for line in f if line.strip()]
# Shuffle and split each class
random.shuffle(human_texts)
random.shuffle(machine_texts)
human_split = int(len(human_texts) * train_ratio)
machine_split = int(len(machine_texts) * train_ratio)
# Training data
train_texts = human_texts[:human_split] + machine_texts[:machine_split]
train_labels = [0] * human_split + [1] * machine_split
# Validation data
val_texts = human_texts[human_split:] + machine_texts[machine_split:]
val_labels = [0] * (len(human_texts) - human_split) + \
[1] * (len(machine_texts) - machine_split)
# Shuffle
train_indices = list(range(len(train_texts)))
val_indices = list(range(len(val_texts)))
random.shuffle(train_indices)
random.shuffle(val_indices)
train_texts = [train_texts[i] for i in train_indices]
train_labels = [train_labels[i] for i in train_indices]
val_texts = [val_texts[i] for i in val_indices]
val_labels = [val_labels[i] for i in val_indices]
# Save
train_path = os.path.join(output_dir, 'train.json')
val_path = os.path.join(output_dir, 'val.json')
with open(train_path, 'w') as f:
json.dump({
'texts': train_texts,
'labels': train_labels
}, f)
with open(val_path, 'w') as f:
json.dump({
'texts': val_texts,
'labels': val_labels
}, f)
print(f"Stratified split created:")
print(f" Training samples: {len(train_texts)}")
print(f" - Human: {train_labels.count(0)}")
print(f" - Machine: {train_labels.count(1)}")
print(f" Validation samples: {len(val_texts)}")
print(f" - Human: {val_labels.count(0)}")
print(f" - Machine: {val_labels.count(1)}")
print(f" Files saved to: {output_dir}")
return train_path, val_path
# ============================================================================
# CONFIGURATION UTILITIES
# ============================================================================
class ConfigurationManager:
"""Manage DGRM configurations."""
DEFAULT_CONFIG = {
'model': {
'model_name': 'roberta-base',
'num_attributes': 256,
'hidden_dim': 768,
'dropout': 0.2
},
'training': {
'batch_size': 8,
'learning_rate': 1e-5,
'num_epochs': 10,
'lambda1': 0.3,
'lambda2': 0.3,
'eta': 1.0,
'gradient_clip': 1.0
},
'data': {
'max_length': 512,
'split_ratio': 0.8
},
'device': 'cuda',
'seed': 42
}
@classmethod
def create_default_config(cls, output_path: str = 'config.yaml'):
"""Create default configuration file."""
import yaml
with open(output_path, 'w') as f:
yaml.dump(cls.DEFAULT_CONFIG, f, default_flow_style=False)
print(f"Default configuration saved to: {output_path}")
return cls.DEFAULT_CONFIG
@classmethod
def get_config_variants(cls) -> Dict[str, Dict]:
"""Get various configuration presets."""
return {
'small': {
'model': {
'num_attributes': 128,
'hidden_dim': 512,
'dropout': 0.2
},
'training': {
'batch_size': 16,
'learning_rate': 5e-5,
'num_epochs': 5
}
},
'medium': cls.DEFAULT_CONFIG,
'large': {
'model': {
'num_attributes': 512,
'hidden_dim': 1024,
'dropout': 0.3
},
'training': {
'batch_size': 4,
'learning_rate': 1e-5,
'num_epochs': 15
}
},
'gpu_limited': {
'model': {
'num_attributes': 128,
'hidden_dim': 512
},
'training': {
'batch_size': 4,
'num_epochs': 10
}
}
}
# ============================================================================
# SETUP AND INITIALIZATION
# ============================================================================
def setup_environment(seed=42, device='auto'):
"""
Setup training environment.
Args:
seed: Random seed for reproducibility
device: 'auto', 'cuda', or 'cpu'
"""
# Set seed
random.seed(seed)
np.random.seed(seed)
torch.manual_seed(seed)
if torch.cuda.is_available():
torch.cuda.manual_seed_all(seed)
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = False
# Set device
if device == 'auto':
device = 'cuda' if torch.cuda.is_available() else 'cpu'
device = torch.device(device)
print(f"Environment Setup:")
print(f" Random seed: {seed}")
print(f" Device: {device}")
print(f" CUDA available: {torch.cuda.is_available()}")
if torch.cuda.is_available():
print(f" GPU: {torch.cuda.get_device_name(0)}")
return device
def create_project_structure(project_dir='dgrm_project'):
"""Create standard project directory structure."""
dirs = [
project_dir,
f'{project_dir}/data',
f'{project_dir}/data/raw',
f'{project_dir}/data/processed',
f'{project_dir}/models',
f'{project_dir}/results',
f'{project_dir}/logs',
f'{project_dir}/configs',
f'{project_dir}/scripts'
]
for d in dirs:
os.makedirs(d, exist_ok=True)
print(f"Project structure created at: {project_dir}")
print(f"Directories: {', '.join([d.split('/')[-1] for d in dirs[1:]])}")
return project_dir
# ============================================================================
# DEMO SCRIPT
# ============================================================================
def main():
"""Demo of data preparation utilities."""
print("="*60)
print("DGRM Data Preparation Utilities")
print("="*60 + "\n")
# 1. Create project structure
project_dir = create_project_structure('dgrm_project')
# 2. Setup environment
device = setup_environment(seed=42)
# 3. Create sample dataset
print("\n" + "="*60)
print("Creating sample dataset...")
print("="*60 + "\n")
human_file, machine_file = DataPreparationUtils.create_sample_dataset(
output_dir=f'{project_dir}/data/raw',
num_samples=50
)
# 4. Validate files
print("\n" + "="*60)
print("Validating data files...")
print("="*60 + "\n")
DataPreparationUtils.validate_text_files(human_file, machine_file)
# 5. Create stratified split
print("\n" + "="*60)
print("Creating stratified train/validation split...")
print("="*60 + "\n")
train_file, val_file = DataPreparationUtils.create_stratified_split(
human_file, machine_file,
output_dir=f'{project_dir}/data/processed',
train_ratio=0.8
)
# 6. Create default configuration
print("\n" + "="*60)
print("Creating configuration...")
print("="*60 + "\n")
ConfigurationManager.create_default_config(
output_path=f'{project_dir}/configs/config.yaml'
)
# 7. Show configuration variants
print("\n" + "="*60)
print("Available configuration variants:")
print("="*60 + "\n")
variants = ConfigurationManager.get_config_variants()
for variant_name in variants.keys():
print(f" - {variant_name}")
print("\n" + "="*60)
print("Setup complete!")
print("="*60)
print(f"\nNext steps:")
print(f"1. Review data in: {project_dir}/data/")
print(f"2. Edit configuration: {project_dir}/configs/config.yaml")
print(f"3. Run training: python train_dgrm.py --config {project_dir}/configs/config.yaml \\")
print(f" --human-file {human_file} --machine-file {machine_file}")
if __name__ == '__main__':
main()# Train dgrm.py
"""
DGRM Training and Evaluation Script
Complete workflow for training, evaluating, and analyzing the DGRM model.
Usage:
python train_dgrm.py --config config.yaml
"""
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.utils.data import DataLoader, random_split
import argparse
import yaml
import json
import os
from pathlib import Path
from datetime import datetime
import numpy as np
from tqdm import tqdm
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.metrics import (
accuracy_score, precision_score, recall_score, f1_score,
roc_auc_score, confusion_matrix, roc_curve, precision_recall_curve
)
from dgrm_model import (
DGRM, TextDataset, Trainer, get_predictions, compute_metrics
)
# ============================================================================
# 1. DATA UTILITIES
# ============================================================================
class DataPreparation:
"""
Utilities for data preparation and loading.
"""
@staticmethod
def load_data_from_files(human_file, machine_file, split_ratio=0.8):
"""
Load texts from files.
Args:
human_file: Path to file with human-written texts (one per line)
machine_file: Path to file with machine-generated texts (one per line)
split_ratio: Train/validation split ratio
Returns:
train and val data loaders
"""
with open(human_file, 'r', encoding='utf-8') as f:
human_texts = [line.strip() for line in f if line.strip()]
with open(machine_file, 'r', encoding='utf-8') as f:
machine_texts = [line.strip() for line in f if line.strip()]
# Create balanced dataset
texts = human_texts + machine_texts
labels = [0] * len(human_texts) + [1] * len(machine_texts)
print(f"Loaded {len(human_texts)} human texts and {len(machine_texts)} machine-generated texts")
# Shuffle and split
indices = list(range(len(texts)))
np.random.shuffle(indices)
split_idx = int(len(texts) * split_ratio)
train_indices = indices[:split_idx]
val_indices = indices[split_idx:]
train_texts = [texts[i] for i in train_indices]
train_labels = [labels[i] for i in train_indices]
val_texts = [texts[i] for i in val_indices]
val_labels = [labels[i] for i in val_indices]
return {
'train': {'texts': train_texts, 'labels': train_labels},
'val': {'texts': val_texts, 'labels': val_labels}
}
@staticmethod
def create_loaders(train_data, val_data, tokenizer, batch_size=8, max_length=512):
"""
Create DataLoaders from data.
Args:
train_data: Dictionary with 'texts' and 'labels'
val_data: Dictionary with 'texts' and 'labels'
tokenizer: Tokenizer
batch_size: Batch size
max_length: Max sequence length
Returns:
train_loader, val_loader
"""
train_dataset = TextDataset(
train_data['texts'],
train_data['labels'],
tokenizer,
max_length=max_length
)
val_dataset = TextDataset(
val_data['texts'],
val_data['labels'],
tokenizer,
max_length=max_length
)
train_loader = DataLoader(
train_dataset,
batch_size=batch_size,
shuffle=True,
num_workers=0
)
val_loader = DataLoader(
val_dataset,
batch_size=batch_size,
shuffle=False,
num_workers=0
)
return train_loader, val_loader
# ============================================================================
# 2. PARAPHRASING AND PERTURBATION
# ============================================================================
class TextPerturbation:
"""
Utilities for creating perturbed versions of texts.
"""
@staticmethod
def random_swap(tokens, prob=0.1):
"""Randomly swap adjacent tokens"""
tokens = tokens.copy()
for i in range(len(tokens) - 1):
if np.random.random() < prob:
tokens[i], tokens[i+1] = tokens[i+1], tokens[i]
return tokens
@staticmethod
def random_insert(tokens, prob=0.05):
"""Randomly insert duplicate tokens"""
tokens = tokens.copy()
new_tokens = []
for token in tokens:
new_tokens.append(token)
if np.random.random() < prob:
new_tokens.append(token)
return new_tokens
@staticmethod
def random_delete(tokens, prob=0.05):
"""Randomly delete tokens"""
tokens = tokens.copy()
return [t for t in tokens if np.random.random() > prob]
@staticmethod
def synonym_replacement(text, replace_prob=0.1):
"""
Replace words with synonyms (mock implementation).
In practice, use proper synonym databases or APIs.
"""
# This is a simplified mock - use proper synonym replacement in production
common_synonyms = {
'very': 'extremely',
'good': 'excellent',
'bad': 'poor',
'big': 'large',
'small': 'tiny',
'important': 'crucial',
'different': 'distinct',
'similar': 'alike',
'help': 'assist',
'use': 'utilize'
}
words = text.lower().split()
perturbed = []
for word in words:
clean_word = word.strip('.,!?;:')
if np.random.random() < replace_prob and clean_word in common_synonyms:
perturbed.append(common_synonyms[clean_word])
else:
perturbed.append(word)
return ' '.join(perturbed)
# ============================================================================
# 3. VISUALIZATION AND ANALYSIS
# ============================================================================
class ResultsAnalyzer:
"""
Tools for analyzing and visualizing results.
"""
@staticmethod
def plot_training_curves(train_losses, val_losses, save_path=None):
"""Plot training and validation loss curves"""
plt.figure(figsize=(10, 6))
plt.plot(train_losses, label='Training Loss', marker='o')
plt.plot(val_losses, label='Validation Loss', marker='s')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.title('DGRM Training Curves')
plt.legend()
plt.grid(True, alpha=0.3)
if save_path:
plt.savefig(save_path, dpi=300, bbox_inches='tight')
plt.close()
@staticmethod
def plot_confusion_matrix(predictions, labels, save_path=None):
"""Plot confusion matrix"""
cm = confusion_matrix(labels, predictions)
plt.figure(figsize=(8, 6))
sns.heatmap(cm, annot=True, fmt='d', cmap='Blues', cbar=True)
plt.xlabel('Predicted')
plt.ylabel('Actual')
plt.title('Confusion Matrix')
plt.xticks([0.5, 1.5], ['Human', 'Machine'])
plt.yticks([0.5, 1.5], ['Human', 'Machine'])
if save_path:
plt.savefig(save_path, dpi=300, bbox_inches='tight')
plt.close()
@staticmethod
def plot_roc_curve(labels, logits, save_path=None):
"""Plot ROC curve"""
fpr, tpr, _ = roc_curve(labels, logits[:, 1])
auc = roc_auc_score(labels, logits[:, 1])
plt.figure(figsize=(8, 6))
plt.plot(fpr, tpr, label=f'ROC Curve (AUC = {auc:.4f})', linewidth=2)
plt.plot([0, 1], [0, 1], 'k--', label='Random')
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('ROC Curve')
plt.legend()
plt.grid(True, alpha=0.3)
if save_path:
plt.savefig(save_path, dpi=300, bbox_inches='tight')
plt.close()
@staticmethod
def plot_precision_recall_curve(labels, logits, save_path=None):
"""Plot Precision-Recall curve"""
precision, recall, _ = precision_recall_curve(labels, logits[:, 1])
plt.figure(figsize=(8, 6))
plt.plot(recall, precision, linewidth=2, label='Precision-Recall Curve')
plt.xlabel('Recall')
plt.ylabel('Precision')
plt.title('Precision-Recall Curve')
plt.grid(True, alpha=0.3)
plt.legend()
if save_path:
plt.savefig(save_path, dpi=300, bbox_inches='tight')
plt.close()
@staticmethod
def generate_report(metrics, save_path=None):
"""Generate detailed metrics report"""
report = f"""
{'='*60}
DGRM EVALUATION REPORT
{'='*60}
Classification Metrics:
Accuracy: {metrics['accuracy']:.4f}
Precision: {metrics['precision']:.4f}
Recall: {metrics['recall']:.4f}
F1 Score: {metrics['f1']:.4f}
Specificity: {metrics['specificity']:.4f}
Probabilistic Metrics:
AUROC: {metrics['auroc']:.4f}
Confusion Matrix:
TP: {metrics['tp']:4d} | FP: {metrics['fp']:4d}
FN: {metrics['fn']:4d} | TN: {metrics['tn']:4d}
{'='*60}
"""
print(report)
if save_path:
with open(save_path, 'w') as f:
f.write(report)
return report
# ============================================================================
# 4. MAIN TRAINING SCRIPT
# ============================================================================
class DGRMExperiment:
"""
Complete experiment workflow for DGRM.
"""
def __init__(self, config_path=None):
"""
Initialize experiment.
Args:
config_path: Path to config YAML file
"""
self.config = self._load_config(config_path)
self.device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
self.results_dir = self._setup_results_dir()
print(f"Using device: {self.device}")
print(f"Results directory: {self.results_dir}")
def _load_config(self, config_path):
"""Load configuration"""
default_config = {
'model': {
'model_name': 'roberta-base',
'num_attributes': 256,
'hidden_dim': 768,
'dropout': 0.2
},
'training': {
'batch_size': 8,
'learning_rate': 1e-5,
'num_epochs': 10,
'lambda1': 0.3,
'lambda2': 0.3,
'eta': 1.0
},
'data': {
'max_length': 512,
'split_ratio': 0.8
}
}
if config_path and os.path.exists(config_path):
with open(config_path, 'r') as f:
loaded_config = yaml.safe_load(f)
default_config.update(loaded_config)
return default_config
def _setup_results_dir(self):
"""Create results directory"""
timestamp = datetime.now().strftime('%Y%m%d_%H%M%S')
results_dir = Path(f'dgrm_results_{timestamp}')
results_dir.mkdir(exist_ok=True)
return results_dir
def run(self, train_texts, train_labels, val_texts, val_labels):
"""
Run complete experiment.
Args:
train_texts, train_labels: Training data
val_texts, val_labels: Validation data
"""
print("\n" + "="*60)
print("DGRM EXPERIMENT")
print("="*60 + "\n")
# Initialize model
print("1. Initializing model...")
model = DGRM(
model_name=self.config['model']['model_name'],
num_attributes=self.config['model']['num_attributes'],
hidden_dim=self.config['model']['hidden_dim'],
dropout=self.config['model']['dropout']
)
# Create datasets
print("2. Creating datasets...")
tokenizer = model.tokenizer
train_dataset = TextDataset(
train_texts, train_labels, tokenizer,
max_length=self.config['data']['max_length']
)
val_dataset = TextDataset(
val_texts, val_labels, tokenizer,
max_length=self.config['data']['max_length']
)
train_loader = DataLoader(
train_dataset,
batch_size=self.config['training']['batch_size'],
shuffle=True
)
val_loader = DataLoader(
val_dataset,
batch_size=self.config['training']['batch_size'],
shuffle=False
)
# Initialize trainer
print("3. Initializing trainer...")
trainer = Trainer(
model=model,
train_loader=train_loader,
val_loader=val_loader,
device=self.device,
learning_rate=self.config['training']['learning_rate'],
lambda1=self.config['training']['lambda1'],
lambda2=self.config['training']['lambda2'],
eta=self.config['training']['eta']
)
# Train model
print("4. Training model...")
trainer.train(num_epochs=self.config['training']['num_epochs'])
# Evaluate
print("\n5. Evaluating model...")
predictions, labels, logits = get_predictions(model, val_loader, self.device)
metrics = compute_metrics(predictions, labels, logits)
# Save results
print("6. Saving results...")
self._save_results(model, metrics, trainer, predictions, labels, logits)
return model, metrics, trainer
def _save_results(self, model, metrics, trainer, predictions, labels, logits):
"""Save model, metrics, and visualizations"""
# Save model
model_path = self.results_dir / 'model.pt'
torch.save(model.state_dict(), model_path)
print(f" Model saved to {model_path}")
# Save metrics
metrics_path = self.results_dir / 'metrics.json'
with open(metrics_path, 'w') as f:
json.dump(metrics, f, indent=4)
print(f" Metrics saved to {metrics_path}")
# Save config
config_path = self.results_dir / 'config.yaml'
with open(config_path, 'w') as f:
yaml.dump(self.config, f)
print(f" Config saved to {config_path}")
# Generate visualizations
print(" Generating visualizations...")
analyzer = ResultsAnalyzer()
analyzer.plot_training_curves(
trainer.train_losses,
trainer.val_losses,
self.results_dir / 'training_curves.png'
)
analyzer.plot_confusion_matrix(
predictions, labels,
self.results_dir / 'confusion_matrix.png'
)
analyzer.plot_roc_curve(
labels, logits,
self.results_dir / 'roc_curve.png'
)
analyzer.plot_precision_recall_curve(
labels, logits,
self.results_dir / 'pr_curve.png'
)
analyzer.generate_report(
metrics,
self.results_dir / 'report.txt'
)
print(f" Visualizations saved to {self.results_dir}/")
# ============================================================================
# 5. COMMAND LINE INTERFACE
# ============================================================================
def main():
"""Main entry point"""
parser = argparse.ArgumentParser(
description='Train and evaluate DGRM model'
)
parser.add_argument(
'--config',
type=str,
help='Path to configuration YAML file'
)
parser.add_argument(
'--human-file',
type=str,
help='Path to file with human-written texts'
)
parser.add_argument(
'--machine-file',
type=str,
help='Path to file with machine-generated texts'
)
parser.add_argument(
'--demo',
action='store_true',
help='Run demo with synthetic data'
)
args = parser.parse_args()
# Initialize experiment
experiment = DGRMExperiment(config_path=args.config)
if args.demo:
# Run with demo data
print("Running demo with synthetic data...")
human_texts = [
"The rapid advancement of artificial intelligence has transformed multiple industries.",
"Machine learning algorithms require careful tuning of hyperparameters.",
"Natural language processing enables computers to understand human language.",
"Deep learning models can learn hierarchical representations from data.",
"Text classification is a fundamental task in natural language understanding.",
"Recurrent neural networks are effective for sequential data processing.",
"Transfer learning leverages pre-trained models for new tasks.",
"Attention mechanisms improve model interpretability and performance."
] * 5
machine_texts = [
"The advancement of artificial intelligence has been rapid and has transformed industry.",
"Machine learning algorithms require hyperparameters to be carefully tuned.",
"Natural language processing allows computers to understand language naturally.",
"Deep learning models are able to learn representations in a hierarchical manner.",
"Text classification represents a fundamental task within natural language understanding.",
"Recurrent neural networks are very effective for the processing of sequential data.",
"Transfer learning takes advantage of pre-trained models for solving new tasks.",
"Attention mechanisms enhance the interpretability and performance of models."
] * 5
# Split data
split = int(0.8 * len(human_texts))
experiment.run(
train_texts=human_texts[:split] + machine_texts[:split],
train_labels=[0]*split + [1]*split,
val_texts=human_texts[split:] + machine_texts[split:],
val_labels=[0]*(len(human_texts)-split) + [1]*(len(machine_texts)-split)
)
elif args.human_file and args.machine_file:
# Load from files
print("Loading data from files...")
data = DataPreparation.load_data_from_files(
args.human_file,
args.machine_file,
split_ratio=experiment.config['data']['split_ratio']
)
experiment.run(
train_texts=data['train']['texts'],
train_labels=data['train']['labels'],
val_texts=data['val']['texts'],
val_labels=data['val']['labels']
)
else:
print("Please provide either --demo or (--human-file and --machine-file)")
parser.print_help()
if __name__ == '__main__':
main()dgrm model.py
"""
Complete implementation of DGRM (Domain Generalization for Robust Machine-Generated Text Detection)
Based on: Park et al., "Enhancing Domain Generalization for Robust Machine-Generated Text Detection"
IEEE Transactions on Knowledge and Data Engineering, 2025
This implementation includes:
- Feature Disentanglement Module
- Feature Regularization Module
- Complete Training Pipeline
- Evaluation Framework
- Utility Functions
"""
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.utils.data import Dataset, DataLoader
import torch.optim as optim
from transformers import RobertaTokenizer, RobertaModel
import numpy as np
from tqdm import tqdm
from typing import Tuple, Dict, List
import warnings
warnings.filterwarnings('ignore')
# ============================================================================
# 1. CUSTOM DATASET CLASS
# ============================================================================
class TextDataset(Dataset):
"""
Custom dataset for machine-generated text detection.
Args:
texts: List of text samples
labels: List of labels (0 for human, 1 for machine-generated)
tokenizer: Pretrained tokenizer
max_length: Maximum sequence length
"""
def __init__(self, texts, labels, tokenizer, max_length=512):
self.texts = texts
self.labels = labels
self.tokenizer = tokenizer
self.max_length = max_length
def __len__(self):
return len(self.texts)
def __getitem__(self, idx):
text = self.texts[idx]
label = self.labels[idx]
# Tokenize the text
encoding = self.tokenizer(
text,
max_length=self.max_length,
padding='max_length',
truncation=True,
return_tensors='pt'
)
return {
'input_ids': encoding['input_ids'].squeeze(),
'attention_mask': encoding['attention_mask'].squeeze(),
'label': torch.tensor(label, dtype=torch.long)
}
# ============================================================================
# 2. FEATURE DISENTANGLEMENT MODULE
# ============================================================================
class FeatureDisentanglement(nn.Module):
"""
Feature Disentanglement Module
Separates text embedding into:
- Target-specific attributes (h_t): Syntactic patterns distinguishing machine-generated text
- Common attributes (h_c): General contextual information
Uses:
- Auxiliary classifiers for information decomposition
- Contrastive learning for common attributes
- Contrastive loss for independence between attribute spaces
"""
def __init__(self, hidden_dim=768, num_attributes=256):
"""
Args:
hidden_dim: Dimension of RoBERTa embeddings (default: 768)
num_attributes: Dimension of each attribute space
"""
super(FeatureDisentanglement, self).__init__()
self.hidden_dim = hidden_dim
self.num_attributes = num_attributes
# Projectors for target-specific and common attributes
self.projector_t = nn.Sequential(
nn.Linear(hidden_dim, num_attributes),
nn.ReLU()
)
self.projector_c = nn.Sequential(
nn.Linear(hidden_dim, num_attributes),
nn.ReLU()
)
# Auxiliary classifiers
# Target-specific: Binary classifier (human vs machine)
self.classifier_tar = nn.Sequential(
nn.Linear(num_attributes, 128),
nn.ReLU(),
nn.Dropout(0.3),
nn.Linear(128, 2)
)
# Common: Contrastive head for masked language modeling task
self.classifier_con = nn.Sequential(
nn.Linear(num_attributes, 128),
nn.ReLU(),
nn.Dropout(0.3),
nn.Linear(128, num_attributes)
)
self.temperature = 0.07
def forward(self, h):
"""
Args:
h: Text embedding from encoder (batch_size, hidden_dim)
Returns:
h_t: Target-specific attributes
h_c: Common attributes
"""
h_t = self.projector_t(h)
h_c = self.projector_c(h)
return h_t, h_c
def compute_contrastive_loss(self, h_c, h_c_replaced):
"""
Contrastive loss for common attributes using masked language modeling.
Args:
h_c: Common attributes of original text
h_c_replaced: Common attributes of masked/replaced text
Returns:
Contrastive loss value
"""
# Apply contrastive head
z_c = self.classifier_con(h_c) # (batch_size, num_attributes)
z_c_replaced = self.classifier_con(h_c_replaced)
# Normalize
z_c = F.normalize(z_c, dim=-1)
z_c_replaced = F.normalize(z_c_replaced, dim=-1)
# Compute similarity
sim = torch.mm(z_c, z_c_replaced.t()) / self.temperature # (batch_size, batch_size)
# Labels: diagonal elements should match
labels = torch.arange(z_c.size(0), device=z_c.device)
# Cross-entropy loss
loss = F.cross_entropy(sim, labels)
return loss
def compute_independence_loss(self, h_m_t, h_h_t, h_m_c, h_h_c):
"""
Independence loss to ensure target and common attributes are orthogonal.
Uses contrastive learning: embeddings from the same attribute space should be similar,
but embeddings across different attribute spaces should be dissimilar.
Args:
h_m_t: Target attributes of machine-generated text
h_h_t: Target attributes of human text
h_m_c: Common attributes of machine-generated text
h_h_c: Common attributes of human text
Returns:
Independence loss value
"""
# Normalize
h_m_t = F.normalize(h_m_t, dim=-1)
h_h_t = F.normalize(h_h_t, dim=-1)
h_m_c = F.normalize(h_m_c, dim=-1)
h_h_c = F.normalize(h_h_c, dim=-1)
# Similarity matrices
sim_t = torch.mm(h_m_t, h_h_t.t()) / self.temperature # (batch_size/2, batch_size/2)
sim_c = torch.mm(h_m_c, h_h_c.t()) / self.temperature
# Cross similarity (should be minimized)
sim_cross_t_c = torch.mm(h_m_t, h_h_c.t()) / self.temperature
sim_cross_c_t = torch.mm(h_m_c, h_h_t.t()) / self.temperature
# Independence loss: minimize cross-space similarity
batch_size = h_m_t.size(0)
labels = torch.arange(batch_size, device=h_m_t.device)
# Loss for target space (maximize within-space, minimize cross-space)
loss_t = F.cross_entropy(
torch.cat([sim_t, sim_cross_t_c], dim=1),
labels
)
# Loss for common space
loss_c = F.cross_entropy(
torch.cat([sim_c, sim_cross_c_t], dim=1),
labels
)
return loss_t + loss_c
# ============================================================================
# 3. FEATURE REGULARIZATION MODULE
# ============================================================================
class GradientReversal(torch.autograd.Function):
"""
Gradient reversal layer for adversarial training.
Multiplies gradients by -eta during backpropagation.
"""
@staticmethod
def forward(ctx, x, eta=1.0):
ctx.eta = eta
return x.view_as(x)
@staticmethod
def backward(ctx, grad_output):
return -ctx.eta * grad_output, None
class FeatureRegularization(nn.Module):
"""
Feature Regularization Module
Applies regularization to disentangled attributes:
1. Common Attribute Recalibration: Extract additional target-relevant information
2. Perturbation Invariant Regularization: Ensure robustness to syntactic perturbations
"""
def __init__(self, num_attributes=256, hidden_dim=768):
"""
Args:
num_attributes: Dimension of attribute space
hidden_dim: Hidden dimension for final classifier
"""
super(FeatureRegularization, self).__init__()
self.num_attributes = num_attributes
# Recalibration network R for common attributes
self.recalibration_net = nn.Sequential(
nn.Linear(num_attributes, num_attributes),
nn.BatchNorm1d(num_attributes),
nn.ReLU(),
nn.Dropout(0.2),
nn.Linear(num_attributes, num_attributes)
)
# Final classifier
self.final_classifier = nn.Sequential(
nn.Linear(num_attributes * 2, hidden_dim),
nn.ReLU(),
nn.Dropout(0.3),
nn.Linear(hidden_dim, 2)
)
def forward(self, h_t, h_c):
"""
Args:
h_t: Target-specific attributes
h_c: Common attributes
Returns:
Logits for classification
"""
# Recalibrate common attributes
h_c_recal = self.recalibration_net(h_c)
# Combine attributes
h_combined = torch.cat([h_t, h_c_recal], dim=-1)
# Final classification
logits = self.final_classifier(h_combined)
return logits, h_c_recal
def apply_gradient_reversal(self, h_r, eta=1.0):
"""
Apply gradient reversal to perturbation residuals.
Args:
h_r: Residual component (difference between perturbed and original)
eta: Gradient reversal factor
Returns:
Reversed gradients
"""
return GradientReversal.apply(h_r, eta)
# ============================================================================
# 4. COMPLETE DGRM MODEL
# ============================================================================
class DGRM(nn.Module):
"""
Complete DGRM Model
Combines Feature Disentanglement and Feature Regularization for robust
machine-generated text detection across domains.
"""
def __init__(self,
model_name='roberta-base',
num_attributes=256,
hidden_dim=768,
dropout=0.2):
"""
Args:
model_name: Pretrained RoBERTa model name
num_attributes: Dimension of attribute spaces
hidden_dim: Hidden dimension
dropout: Dropout rate
"""
super(DGRM, self).__init__()
# Load pretrained RoBERTa encoder
self.tokenizer = RobertaTokenizer.from_pretrained(model_name)
self.encoder = RobertaModel.from_pretrained(model_name)
# Freeze encoder weights (optional, can be unfrozen for fine-tuning)
for param in self.encoder.parameters():
param.requires_grad = False
# Feature Disentanglement Module
self.disentanglement = FeatureDisentanglement(
hidden_dim=hidden_dim,
num_attributes=num_attributes
)
# Feature Regularization Module
self.regularization = FeatureRegularization(
num_attributes=num_attributes,
hidden_dim=hidden_dim
)
self.num_attributes = num_attributes
def encode_text(self, input_ids, attention_mask):
"""
Encode text using RoBERTa.
Args:
input_ids: Token IDs
attention_mask: Attention mask
Returns:
Text embedding (CLS token)
"""
with torch.no_grad():
outputs = self.encoder(
input_ids=input_ids,
attention_mask=attention_mask,
return_dict=True
)
# Use CLS token as text representation
cls_embedding = outputs.last_hidden_state[:, 0, :]
return cls_embedding
def forward(self, input_ids, attention_mask):
"""
Forward pass through DGRM.
Args:
input_ids: Token IDs
attention_mask: Attention mask
Returns:
logits: Classification logits
h_t: Target-specific attributes
h_c: Common attributes
"""
# Encode text
h = self.encode_text(input_ids, attention_mask)
# Feature Disentanglement
h_t, h_c = self.disentanglement(h)
# Feature Regularization
logits, h_c_recal = self.regularization(h_t, h_c)
return logits, h_t, h_c, h_c_recal
def get_device(self):
"""Get device of model"""
return next(self.parameters()).device
# ============================================================================
# 5. LOSS FUNCTIONS
# ============================================================================
class DGRMLoss(nn.Module):
"""
Combined loss function for DGRM training.
Combines:
- Feature Disentanglement Loss (L_dis)
- Feature Regularization Loss (L_reg)
"""
def __init__(self, lambda1=0.3, lambda2=0.3, eta=1.0):
"""
Args:
lambda1: Weight for independence loss
lambda2: Weight for perturbation loss
eta: Gradient reversal factor
"""
super(DGRMLoss, self).__init__()
self.lambda1 = lambda1
self.lambda2 = lambda2
self.eta = eta
self.ce_loss = nn.CrossEntropyLoss()
def forward(self,
logits,
labels,
h_t,
h_c,
h_c_replaced,
h_m_t,
h_h_t,
h_m_c,
h_h_c,
h_t_perturbed,
classification_fn,
gradient_reversal_fn):
"""
Compute total DGRM loss.
Args:
logits: Classification logits
labels: Ground truth labels
h_t: Target-specific attributes
h_c: Common attributes
h_c_replaced: Common attributes of masked text
h_m_t: Target attributes of machine-generated text
h_h_t: Target attributes of human text
h_m_c: Common attributes of machine-generated text
h_h_c: Common attributes of human text
h_t_perturbed: Target attributes of perturbed text
classification_fn: Function to compute classification loss
gradient_reversal_fn: Function to apply gradient reversal
Returns:
Dictionary with individual losses and total loss
"""
# ============ FEATURE DISENTANGLEMENT LOSS ============
# 1. Target classification loss
logits_tar = classification_fn(h_t)
L_tar = self.ce_loss(logits_tar, labels)
# 2. Contrastive loss for common attributes
disentanglement = classification_fn.__self__.__self__.disentanglement
L_con = disentanglement.compute_contrastive_loss(h_c, h_c_replaced)
# 3. Independence loss
L_ind = disentanglement.compute_independence_loss(h_m_t, h_h_t, h_m_c, h_h_c)
L_dis = L_tar + L_con + self.lambda1 * L_ind
# ============ FEATURE REGULARIZATION LOSS ============
# 1. Recalibration loss
L_rec = self.ce_loss(logits, labels)
# 2. Perturbation invariant loss
h_r = h_t_perturbed - h_t # Residual component
h_r_reversed = gradient_reversal_fn(h_r, self.eta)
logits_per = classification_fn(h_r_reversed)
L_per = self.ce_loss(logits_per, labels)
L_reg = L_rec + self.lambda2 * L_per
# ============ TOTAL LOSS ============
L_total = L_dis + L_reg
return {
'total': L_total,
'L_tar': L_tar.item(),
'L_con': L_con.item(),
'L_ind': L_ind.item(),
'L_rec': L_rec.item(),
'L_per': L_per.item(),
'L_dis': L_dis.item(),
'L_reg': L_reg.item()
}
# ============================================================================
# 6. TRAINING UTILITIES
# ============================================================================
class Trainer:
"""
Training class for DGRM model.
"""
def __init__(self,
model,
train_loader,
val_loader,
device,
learning_rate=1e-5,
lambda1=0.3,
lambda2=0.3,
eta=1.0):
"""
Args:
model: DGRM model instance
train_loader: Training data loader
val_loader: Validation data loader
device: Device (cuda/cpu)
learning_rate: Learning rate
lambda1: Weight for independence loss
lambda2: Weight for perturbation loss
eta: Gradient reversal factor
"""
self.model = model.to(device)
self.train_loader = train_loader
self.val_loader = val_loader
self.device = device
self.optimizer = optim.AdamW(self.model.parameters(), lr=learning_rate)
self.loss_fn = DGRMLoss(lambda1=lambda1, lambda2=lambda2, eta=eta)
self.train_losses = []
self.val_losses = []
def train_epoch(self):
"""Train for one epoch"""
self.model.train()
total_loss = 0
loss_components = {
'L_tar': 0, 'L_con': 0, 'L_ind': 0,
'L_rec': 0, 'L_per': 0, 'L_dis': 0, 'L_reg': 0
}
pbar = tqdm(self.train_loader, desc="Training")
for batch in pbar:
input_ids = batch['input_ids'].to(self.device)
attention_mask = batch['attention_mask'].to(self.device)
labels = batch['label'].to(self.device)
# Forward pass
logits, h_t, h_c, h_c_recal = self.model(input_ids, attention_mask)
# Create perturbed version (in practice, use actual paraphrasing)
h_t_perturbed = h_t + 0.1 * torch.randn_like(h_t)
h_c_replaced = h_c + 0.1 * torch.randn_like(h_c)
# Split into machine and human for independence loss
batch_size = h_t.size(0)
mid = batch_size // 2
h_m_t = h_t[:mid]
h_h_t = h_t[mid:]
h_m_c = h_c[:mid]
h_h_c = h_c[mid:]
# Compute loss
loss_dict = self.loss_fn(
logits=logits,
labels=labels,
h_t=h_t,
h_c=h_c,
h_c_replaced=h_c_replaced,
h_m_t=h_m_t,
h_h_t=h_h_t,
h_m_c=h_m_c,
h_h_c=h_h_c,
h_t_perturbed=h_t_perturbed,
classification_fn=self.model.disentanglement.classifier_tar,
gradient_reversal_fn=self.model.regularization.apply_gradient_reversal
)
loss = loss_dict['total']
# Backward pass
self.optimizer.zero_grad()
loss.backward()
torch.nn.utils.clip_grad_norm_(self.model.parameters(), max_norm=1.0)
self.optimizer.step()
total_loss += loss.item()
for key in loss_components:
loss_components[key] += loss_dict[key]
pbar.set_postfix({'loss': loss.item()})
avg_loss = total_loss / len(self.train_loader)
self.train_losses.append(avg_loss)
# Average component losses
for key in loss_components:
loss_components[key] /= len(self.train_loader)
return avg_loss, loss_components
def validate(self):
"""Validate model"""
self.model.eval()
total_loss = 0
with torch.no_grad():
pbar = tqdm(self.val_loader, desc="Validating")
for batch in pbar:
input_ids = batch['input_ids'].to(self.device)
attention_mask = batch['attention_mask'].to(self.device)
labels = batch['label'].to(self.device)
logits, _, _, _ = self.model(input_ids, attention_mask)
loss = F.cross_entropy(logits, labels)
total_loss += loss.item()
avg_loss = total_loss / len(self.val_loader)
self.val_losses.append(avg_loss)
return avg_loss
def train(self, num_epochs):
"""Train for multiple epochs"""
for epoch in range(num_epochs):
print(f"\n{'='*60}")
print(f"Epoch {epoch+1}/{num_epochs}")
print('='*60)
train_loss, components = self.train_epoch()
val_loss = self.validate()
print(f"Train Loss: {train_loss:.4f}")
print(f"Val Loss: {val_loss:.4f}")
print(f"Components - L_tar: {components['L_tar']:.4f}, "
f"L_con: {components['L_con']:.4f}, "
f"L_ind: {components['L_ind']:.4f}")
print(f" L_rec: {components['L_rec']:.4f}, "
f"L_per: {components['L_per']:.4f}")
# ============================================================================
# 7. EVALUATION UTILITIES
# ============================================================================
def get_predictions(model, loader, device):
"""
Get model predictions on a dataset.
Args:
model: DGRM model
loader: DataLoader
device: Device
Returns:
predictions, labels, logits
"""
model.eval()
all_preds = []
all_labels = []
all_logits = []
with torch.no_grad():
for batch in tqdm(loader, desc="Getting predictions"):
input_ids = batch['input_ids'].to(device)
attention_mask = batch['attention_mask'].to(device)
labels = batch['label'].to(device)
logits, _, _, _ = model(input_ids, attention_mask)
probs = F.softmax(logits, dim=-1)
preds = torch.argmax(probs, dim=-1)
all_preds.extend(preds.cpu().numpy())
all_labels.extend(labels.cpu().numpy())
all_logits.extend(probs.cpu().numpy())
return np.array(all_preds), np.array(all_labels), np.array(all_logits)
def compute_metrics(predictions, labels, logits):
"""
Compute evaluation metrics.
Args:
predictions: Predicted labels
labels: Ground truth labels
logits: Predicted probabilities
Returns:
Dictionary with metrics
"""
from sklearn.metrics import (
accuracy_score, precision_score, recall_score,
f1_score, roc_auc_score, confusion_matrix
)
accuracy = accuracy_score(labels, predictions)
precision = precision_score(labels, predictions, zero_division=0)
recall = recall_score(labels, predictions, zero_division=0)
f1 = f1_score(labels, predictions, zero_division=0)
auroc = roc_auc_score(labels, logits[:, 1])
tn, fp, fn, tp = confusion_matrix(labels, predictions).ravel()
specificity = tn / (tn + fp) if (tn + fp) > 0 else 0
return {
'accuracy': accuracy,
'precision': precision,
'recall': recall,
'f1': f1,
'auroc': auroc,
'specificity': specificity,
'tp': tp,
'tn': tn,
'fp': fp,
'fn': fn
}
# ============================================================================
# 8. DEMO SCRIPT
# ============================================================================
def demo_usage():
"""
Demonstration of DGRM usage.
"""
import sys
print("DGRM Model - Complete Implementation")
print("="*60)
# Setup device
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print(f"Using device: {device}")
# Create dummy data for demonstration
print("\nCreating demo datasets...")
# Human-written texts
human_texts = [
"The rapid advancement of artificial intelligence has transformed multiple industries.",
"Machine learning algorithms require careful tuning of hyperparameters.",
"Natural language processing enables computers to understand human language.",
"Deep learning models can learn hierarchical representations from data.",
"Text classification is a fundamental task in natural language understanding."
]
# Machine-generated texts (simulated)
machine_texts = [
"The advancement of artificial intelligence has been rapid and has transformed industry.",
"Machine learning algorithms require hyperparameters to be carefully tuned.",
"Natural language processing allows computers to understand language naturally.",
"Deep learning models are able to learn representations in a hierarchical manner.",
"Text classification represents a fundamental task within natural language understanding."
]
# Create balanced dataset
all_texts = human_texts + machine_texts
all_labels = [0] * len(human_texts) + [1] * len(machine_texts)
# Split into train and validation
split = int(0.8 * len(all_texts))
train_texts = all_texts[:split]
train_labels = all_labels[:split]
val_texts = all_texts[split:]
val_labels = all_labels[split:]
# Initialize model
print("\nInitializing DGRM model...")
model = DGRM(
model_name='roberta-base',
num_attributes=256,
hidden_dim=768
)
# Create datasets
tokenizer = model.tokenizer
train_dataset = TextDataset(train_texts, train_labels, tokenizer, max_length=512)
val_dataset = TextDataset(val_texts, val_labels, tokenizer, max_length=512)
# Create data loaders
train_loader = DataLoader(train_dataset, batch_size=4, shuffle=True)
val_loader = DataLoader(val_dataset, batch_size=4, shuffle=False)
# Initialize trainer
print("Initializing trainer...")
trainer = Trainer(
model=model,
train_loader=train_loader,
val_loader=val_loader,
device=device,
learning_rate=1e-5,
lambda1=0.3,
lambda2=0.3
)
# Train model
print("\nTraining model (3 epochs for demo)...")
trainer.train(num_epochs=3)
# Evaluate
print("\n" + "="*60)
print("Evaluation Results")
print("="*60)
predictions, labels, logits = get_predictions(model, val_loader, device)
metrics = compute_metrics(predictions, labels, logits)
print(f"Accuracy: {metrics['accuracy']:.4f}")
print(f"Precision: {metrics['precision']:.4f}")
print(f"Recall: {metrics['recall']:.4f}")
print(f"F1 Score: {metrics['f1']:.4f}")
print(f"AUROC: {metrics['auroc']:.4f}")
print(f"Specificity: {metrics['specificity']:.4f}")
print("\nDemo completed successfully!")
if __name__ == "__main__":
demo_usage()References
Related posts, You May like to read
- 7 Shocking Truths About Knowledge Distillation: The Good, The Bad, and The Breakthrough (SAKD)
- 7 Revolutionary Breakthroughs in Medical Image Translation (And 1 Fatal Flaw That Could Derail Your AI Model)
- TimeDistill: Revolutionizing Time Series Forecasting with Cross-Architecture Knowledge Distillation
- HiPerformer: A New Benchmark in Medical Image Segmentation with Modular Hierarchical Fusion
- GeoSAM2 3D Part Segmentation — Prompt-Controllable, Geometry-Aware Masks for Precision 3D Editing
- Probabilistic Smooth Attention for Deep Multiple Instance Learning in Medical Imaging
- A Knowledge Distillation-Based Approach to Enhance Transparency of Classifier Models
- Towards Trustworthy Breast Tumor Segmentation in Ultrasound Using AI Uncertainty
- Discrete Migratory Bird Optimizer with Deep Transfer Learning for Multi-Retinal Disease Detection