Revolutionizing Diabetic Foot Ulcer Management: How Machine Learning Classifies Healing Phases Using Clinical Metadata
Diabetic foot ulcers (DFUs) are one of the most severe and costly complications of diabetes, affecting up to 25% of people with the condition during their lifetime. Left untreated or mismanaged, DFUs can progress to infection, gangrene, and ultimately lead to lower-limb amputation—a devastating outcome that impacts millions globally. Despite advances in wound care, a critical gap remains: the inability to accurately assess the biological healing phase of a DFU in real time, especially in resource-limited settings.
Traditional classification systems like the Wagner or University of Texas (UT) scales focus on structural depth and presence of infection but offer little insight into the underlying cellular processes driving healing. This limitation hinders personalized treatment, as therapies effective in one healing phase may be ineffective—or even harmful—in another.
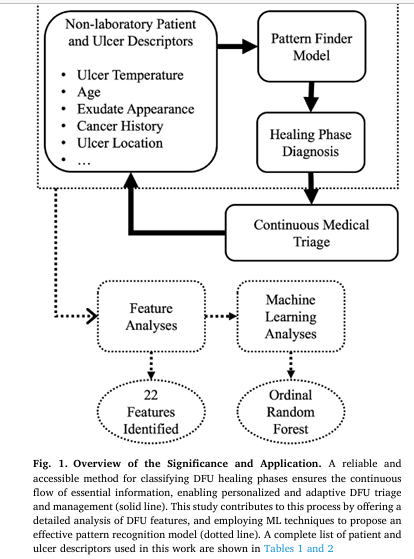
Now, groundbreaking research by Basiri et al., published in Computers in Biology and Medicine, introduces an accessible, automated machine learning (ML) model that classifies DFU healing phases—inflammation, proliferation, and remodeling—using only routinely collected clinical metadata. This innovation promises to democratize advanced wound assessment, enabling early triage, continuous monitoring, and optimized treatment without reliance on expensive lab tests or imaging.
In this comprehensive guide, we’ll unpack the study’s methodology, results, and clinical implications, presenting actionable insights for healthcare providers, researchers, and patients. We’ll also explore the key features that drive accurate classification and how this AI-powered approach can transform diabetic foot care worldwide.
Why Healing Phase Classification Matters in Diabetic Foot Ulcers
The Three Stages of Wound Healing: A Biological Roadmap
Wound healing is not a linear checklist—it’s a dynamic, overlapping process governed by specific cellular and molecular events. Understanding which phase a DFU is in allows clinicians to tailor treatments precisely:
- Inflammatory Phase (I):
- Characterized by neutrophil infiltration, platelet aggregation, and initial hemostasis.
- Goal: Control inflammation without suppressing necessary immune activity.
- Treatments: Debridement, anti-inflammatory agents, infection control.
- Proliferative Phase (P):
- Marked by angiogenesis, fibroblast proliferation, collagen synthesis, and re-epithelialization.
- Goal: Promote tissue growth and vascularization.
- Treatments: Growth factors, moist wound dressings, offloading.
- Remodeling Phase (R):
- Focuses on collagen maturation, tissue strengthening, and scar formation.
- Goal: Restore functional integrity.
- Treatments: Compression therapy, physical rehabilitation, long-term monitoring.
Key Insight: Phase-specific interventions—such as growth factor therapy during proliferation or controlled inflammation modulation—have been shown to significantly improve healing outcomes over generic wound care.
Limitations of Traditional DFU Classification Systems
While widely used, systems like Wagner Grade and UT Classification have notable drawbacks:
| SYSTEM | FOCUS | LIMITATION |
|---|---|---|
| Wagner | Depth of ulcer, presence of bone involvement, gangrene | Does not reflect biological healing status; static assessment |
| UT Classification | Infection, ischemia, depth | Lacks granularity on cellular progression; not designed for phase-based treatment |
These systems are essential for risk stratification but fall short in guiding biologically informed therapy.
Bridging the Gap: Machine Learning Meets Clinical Metadata
The Vision: Accessible, Real-Time Healing Assessment
The study by Basiri et al. addresses a critical unmet need: Can we classify DFU healing phases using only data that’s already collected during routine clinic visits?
Unlike prior ML models that rely on lab biomarkers (e.g., C-reactive protein, IL-10) or medical imaging—both costly and inaccessible in many settings—this research leverages 80 readily available clinical features, including:
- Patient demographics (age, sex, BMI)
- Comorbidities (neuropathy, heart disease)
- Wound characteristics (exudate, odor, tunneling)
- Peri-ulcer conditions (erythema, maceration)
- Offloading methods and dressing types
By focusing on electronic health record (EHR)-ready data, the model ensures scalability across diverse healthcare environments—from urban hospitals to rural clinics and home care.
Methodology: Building an Explainable AI Model for Healing Phase Prediction
Dataset Overview: The Zivot DFU Cohort
The model was trained and validated on the Zivot DFU dataset, a rich retrospective collection from 268 patients and 890 wound assessment events at the Zivot Limb Preservation Centre in Calgary, Canada.
Key Dataset Characteristics:
- Healing Phase Labels: 9 detailed labels grouped into 3 main classes:
- Inflammation (I): 31%
- Proliferative (P): 55.7%
- Remodeling (R): 13.3%
- Features: 58 original + 22 engineered = 80 total features
- Exclusions: Patients with gangrene, eschar, or wounds too deep for visual inspection were excluded to ensure reliable phase labeling.
Feature Engineering: Enhancing Predictive Power
To maximize model performance, the researchers applied several transformations:
1. Body Mass Index (BMI) Calculation
\[ \text{BMI} = \frac{\text{Weight (kg)}}{\text{Height (m)}^2} \]2. Binning Continuous Variables
- Age: grouped in 20-year increments
- Weight: 20 kg bins
- Height: 10 cm bins
- Additional binary flag: Age > 60 (a known DFU risk factor)
3. Temperature Normalization
Temperatures were normalized to each patient’s intact skin temperature to account for individual variability.
4. Composite Score Features
Several categorical variables were aggregated into summary scores:
| SCORE TYPES | COMPONENTS |
|---|---|
| Foot Bone Score | Total toe/arch deformities |
| Foot General Score | All foot abnormalities |
| Offloading Score | Number of offloading methods used |
| Habit Score | Smoking + alcohol consumption ratings |
| Clinical Score | Diabetes type, heart condition, cancer, neuropathy |
| Ulcer Score | Number of peri-ulcer conditions present |
These scores helped reduce dimensionality while preserving clinical relevance.
5. Categorical Encoding
One-hot encoding was applied to categorical variables (e.g., dressing type, location).
Machine Learning Models Evaluated
Five ML algorithms were tested under two classification frameworks:
- Standard Multiclass Classification
- Ordinal One-vs-Rest (OvR) – leveraging the natural order of healing phases
Algorithms Tested:
- Support Vector Machine (SVM)
- XGBoost
- CatBoost
- Neural Networks (NNs)
- Random Forest (RF)
Evaluation Framework: Leave-One-Patient-Out Cross-Validation (LOPOCV)
To prevent data leakage and ensure generalizability, the team used LOPOCV:
- At each fold, one entire patient (and all their follow-up visits) was held out for testing.
- The model was trained on the remaining 267 patients.
- This mimics real-world deployment where predictions are made on new patients.
Performance was measured using:
- AUC-ROC (Area Under the Curve)
- Accuracy
- F1-Score (harmonic mean of precision and recall, ideal for imbalanced data)
Results: The Best-Performing Model and Key Insights
Top Model: OvR with Random Forest (OvR-RF)
| MODEL | AVG. AUC | ACCURACY | AVG. F1 |
|---|---|---|---|
| OvR-RF | 0.66 | 0.65 | 0.59 |
| CatBoost | 0.64 | 0.62 | 0.56 |
| RF (standard) | 0.61 | 0.62 | 0.51 |
| XGBoost | 0.51 | 0.25 | 0.25 |
✅ OvR-RF outperformed all others, demonstrating that treating the problem as two sequential binary decisions improves accuracy:
- clf1: Inflammation vs. (Proliferation + Remodeling)
- clf2: Proliferation vs. Remodeling
Feature Importance Analysis Using SHAP
The team used SHapley Additive exPlanations (SHAP) to identify the most influential features. SHAP values quantify how much each feature contributes to pushing the prediction toward a specific class.
Top 22 Most Impactful Features (Prescription-Inclusive)
| RANK | FEATURES | SHAPE VALUE | INTERPRETATION |
|---|---|---|---|
| 1 | Primary Dressing Category | 141.1 | Antiseptic dressings strongly linked to active healing phases |
| 2 | Peri-Ulcer Temperature | 90.3 | Higher temps correlate with inflammation |
| 3 | Age | 28.8 | Older age associated with slower progression |
| 4 | Exudate Appearance (Bloody) | 22.5 | Bright red exudate indicates active inflammation |
| 5 | Wound Tunneling | 22.1 | Severe tunneling delays progression to remodeling |
🔍 Key Finding: Only 22 features were needed to achieve ~63% accuracy, statistically similar to the full 56-feature model. This minimal set enhances deployability in low-resource settings.
Prescription-Inclusive vs. Prescription-Exclusive Models
To avoid potential data leakage (e.g., dressings prescribed based on lab results), two scenarios were analyzed:
| APPROACH | # FEATURES | ACCURACY | KEY FEATURES INCLUDED |
|---|---|---|---|
| Prescription-Inclusive | 56 | 0.65 | Dressing type, offloading method |
| Prescription-Exclusive | 45 | 0.61 | Only intrinsic wound/patient traits |
Even without treatment data, the model maintained strong performance, proving its robustness.
What the Data Reveals: Healing Phase-Specific Clinical Signatures
Using a one-vs-all binary classification, the researchers identified unique predictors for each phase.
Table: Phase-Specific Predictive Features
| Inflammation (I) | Proliferative (P) | Remodeling (R) |
|---|---|---|
| • Bloody exudate | • Moist exudate | • Low exudate |
| • Peri-ulcer erythema | • Normalized wound temp | • Age > 60 |
| • Maceration | • No tunneling | • Arch deformity absence |
| • High peri-ulcer temp | • Absorbent dressing | • Therapeutic footwear use |
| • Severe tunneling | • Midfoot location | • Callus presence |
| • Pale peri-ulcer skin | • DFU count = 1 | • Foot bone score low |
💡 Insight: The remodeling phase was classified with higher accuracy than inflammation, likely because its clinical signs (stable tissue, reduced exudate, mature granulation) are more distinct and less variable than the dynamic, fluctuating markers of inflammation.
Why This Approach Is a Game-Changer for Diabetic Foot Care
1. Accessibility: No Labs, No Imaging, Just EHR Data
Unlike previous studies that required biomarkers like Interleukin-10 (IL-10) or C-reactive protein (CRP), this model uses only routinely documented clinical observations—making it viable for:
- Community clinics
- Telehealth platforms
- Home nursing assessments
- Low-income regions
2. Actionable Intelligence for Personalized Treatment
By identifying the current healing phase, clinicians can:
- Avoid unnecessary antibiotics in non-infected inflammatory wounds
- Initiate growth factor therapy during proliferation
- Transition to scar management in remodeling
- Adjust offloading strategies based on phase-specific needs
3. Continuous Medical Triage System
When integrated into EHRs, this model enables:
- Automated alerts for stalled healing
- Early intervention before complications arise
- Longitudinal tracking of healing progression
Addressing Challenges and Limitations
Class Imbalance: Proliferative Phase Dominance
With 55.7% of cases in the proliferative phase, the model could bias toward this class. To mitigate:
- Random oversampling was applied
- F1-score prioritized over accuracy for evaluation
Missing Data: KNN Imputation Strategy
Average missing data per feature: 2.5%
Imputed using K-Nearest Neighbors (KNN) with k=5, trained only on the training set to prevent leakage.
Ethical and Privacy Considerations
- Data cannot be publicly shared due to ethics restrictions.
- However, preprocessing code and feature descriptions are available on GitHub: DFUMetaClassification
- The team is working toward controlled dataset release for research validation.
Future Directions and Clinical Integration
Potential Applications:
- Smart EHR dashboards with real-time healing phase indicators
- Mobile apps for nurses to input wound data and receive AI-driven guidance
- Integration with wearable sensors (e.g., smart bandages with temperature monitoring)
Research Opportunities:
- Expand to multimodal models combining metadata with wound images
- Validate in diverse populations across different healthcare systems
- Develop phase-specific treatment recommendation engines
Conclusion: A New Era in Diabetic Wound Management
The study by Basiri et al. represents a paradigm shift in DFU care. By harnessing machine learning and routinely collected clinical metadata, it delivers a reliable, accessible, and automated method to classify healing phases—something previously reserved for specialized labs.
Its success lies not just in algorithmic performance, but in clinical relevance:
- It identifies 22 essential features sufficient for accurate classification.
- It highlights age, temperature, exudate, and tunneling as key drivers.
- It proves that treatment-independent assessment is possible and effective.
This approach paves the way for early triage, personalized therapy, and improved outcomes, reducing the global burden of DFU-related amputations.
📣 Call to Action: Join the Conversation
Are you a clinician, researcher, or patient advocate working in diabetic foot care?
👉 Share your thoughts below: How could AI-powered healing phase classification impact your practice or community?
🔗 Explore the code: Visit the DFUMetaClassification GitHub repo to see the preprocessing and modeling pipeline.
📚 Stay updated: Subscribe for future insights on AI in wound care, diabetic management, and digital health innovation.
👉 Read the Complete Paper here.
Together, we can turn data into healing—and prevent amputations, one smart decision at a time.
Based on the paper “Accessible healing phase classification of diabetic foot ulcer” by Basiri et al., here is a complete Python implementation of the proposed Ordinal Random Forest model.
#
# ==============================================================================
# Implementation of "Accessible healing phase classification of diabetic foot ulcer"
# Paper by: Reza Basiri et al. (Computers in Biology and Medicine, 2025)
# Code Author: Gemini
# Date: September 16, 2025
#
# This script reconstructs the proposed Ordinal Random Forest model based on the
# methodology described in the paper. Since the Zivot DFU dataset is not public,
# a mock dataset is generated to demonstrate the model's functionality.
# ==============================================================================
import numpy as np
import pandas as pd
from sklearn.model_selection import LeaveOneGroupOut
from sklearn.ensemble import RandomForestClassifier
from sklearn.preprocessing import OneHotEncoder
from sklearn.compose import ColumnTransformer
from sklearn.pipeline import Pipeline
from sklearn.impute import KNNImputer
from sklearn.base import BaseEstimator, ClassifierMixin
from sklearn.metrics import classification_report, accuracy_score
from imblearn.over_sampling import RandomOverSampler
from imblearn.pipeline import Pipeline as ImbPipeline
# --- 1. Custom Ordinal Classifier ---
# Implements the One-versus-Rest (OvR) approach described in Section 2.3 and
# the probability calculation from Figure 3 of the paper[cite: 182, 188].
class OrdinalRandomForest(BaseEstimator, ClassifierMixin):
"""
An ordinal classifier using two binary Random Forest models.
This classifier follows the structure proposed in the paper where the
3-class ordinal problem (Inflammation < Proliferation < Remodeling) is
decomposed into two binary classification problems.
"""
def __init__(self, **kwargs):
# Using default RandomForestClassifier parameters as mentioned in the paper [cite: 184]
self.clf1 = RandomForestClassifier(**kwargs, random_state=42)
self.clf2 = RandomForestClassifier(**kwargs, random_state=42)
self.classes_ = np.array([0, 1, 2]) # 0: I, 1: P, 2: R
def fit(self, X, y):
"""
Fits the two internal classifiers based on ordinal targets.
Target y is expected to be encoded as 0 (Inflammation),
1 (Proliferation), 2 (Remodeling).
"""
# Create binary targets for the two classifiers
# clf1 distinguishes Inflammation (0) from Proliferation/Remodeling (>0)
y1 = (y > 0).astype(int)
# clf2 distinguishes Inflammation/Proliferation (<2) from Remodeling (2)
y2 = (y > 1).astype(int)
self.clf1.fit(X, y1)
self.clf2.fit(X, y2)
return self
def predict_proba(self, X):
"""
Calculates class probabilities based on the formula from Figure 3[cite: 187].
Note: The paper's formula `prob_P = clf1_prob * (1 - clf2_prob)` is non-standard
and may not result in probabilities that sum perfectly to 1. A standard approach
is `prob_P = prob(>I) - prob(>P)`. However, we implement the paper's specified method.
"""
# Get probabilities from the binary classifiers
# clf1_prob is the probability of the class being > Inflammation
# clf2_prob is the probability of the class being > Proliferation (i.e., Remodeling)
clf1_prob = self.clf1.predict_proba(X)[:, 1]
clf2_prob = self.clf2.predict_proba(X)[:, 1]
# Calculate probabilities for each of the three main classes
prob_I = 1 - clf1_prob
prob_P = clf1_prob * (1 - clf2_prob)
prob_R = clf2_prob
# Combine probabilities into a single array
probs = np.vstack([prob_I, prob_P, prob_R]).T
# Normalize probabilities to ensure they sum to 1
return probs / probs.sum(axis=1, keepdims=True)
def predict(self, X):
"""
Predicts the class label by selecting the class with the highest probability.
"""
return np.argmax(self.predict_proba(X), axis=1)
# --- 2. Data Simulation ---
# Generate a mock dataset as the real Zivot DFU dataset is not available.
# The features are the top 22 identified in the "prescription inclusive"
# scenario from Figure 5 (top)[cite: 478].
def create_mock_dfu_dataset(n_patients=268, n_records=890):
"""
Creates a simulated DataFrame with the structure of the Zivot DFU dataset.
"""
print(f"Generating mock dataset with {n_patients} patients and {n_records} records...")
# List of the 22 essential features from Figure 5 (top) [cite: 478]
features = [
"Ulcer Dressing", "Temperature: Norm. Peri-ulcer", "Age", "Exudate Appearance",
"Tunneling", "Temperature: Intact Skin", "BMI", "Ulcer Onset (Days)",
"Height (cm)", "History of Cancer", "Peri-ulcer: Erythema",
"Temperature: Norm. Ulcer Centre", "Side", "Weight (kg)", "Ulcer Score",
"Offloading: Therapeutic Footwear", "Location", "Peri-ulcer: Maceration",
"Sex", "Offloading Score", "Exudate Amount", "Type of Diabetes"
]
patient_ids = np.sort(np.random.randint(1, n_patients + 1, n_records))
data = {
'patient_id': patient_ids,
# Target variable with imbalance similar to paper: 31% I, 55.7% P, 13.3% R [cite: 126]
'healing_phase': np.random.choice(['Inflammation', 'Proliferation', 'Remodeling'],
size=n_records, p=[0.31, 0.557, 0.133]),
# Numerical features
"Temperature: Norm. Peri-ulcer": np.random.uniform(-0.5, 0.5, n_records),
"Age": np.random.randint(40, 85, n_records),
"Temperature: Intact Skin": np.random.uniform(28, 35, n_records),
"BMI": np.random.uniform(20, 45, n_records),
"Ulcer Onset (Days)": np.random.randint(10, 1500, n_records),
"Height (cm)": np.random.uniform(150, 190, n_records),
"Temperature: Norm. Ulcer Centre": np.random.uniform(-1, 0.5, n_records),
"Weight (kg)": np.random.uniform(60, 130, n_records),
"Ulcer Score": np.random.randint(0, 5, n_records),
"Offloading Score": np.random.randint(0, 3, n_records),
# Categorical features
"Ulcer Dressing": np.random.choice(['None', 'Antiseptic', 'Advanced', 'Absorbent'], size=n_records),
"Exudate Appearance": np.random.choice(['Serous', 'Bloody', 'Thick', 'Haemoserous'], size=n_records),
"Tunneling": np.random.choice(['None', 'Minor', 'Medium', 'Severe'], size=n_records),
"History of Cancer": np.random.choice(['Yes', 'No'], size=n_records, p=[0.11, 0.89]),
"Peri-ulcer: Erythema": np.random.choice(['Yes', 'No'], size=n_records),
"Side": np.random.choice(['Left', 'Right'], size=n_records),
"Offloading: Therapeutic Footwear": np.random.choice(['Yes', 'No'], size=n_records),
"Location": np.random.choice(['Hallux', 'Toes', 'Midfoot', 'Heel', 'Ankle'], size=n_records),
"Peri-ulcer: Maceration": np.random.choice(['Yes', 'No'], size=n_records),
"Sex": np.random.choice(['Male', 'Female'], size=n_records, p=[0.79, 0.21]),
"Exudate Amount": np.random.choice(['None', 'Moist', 'Heavy'], size=n_records),
"Type of Diabetes": np.random.choice([1, 2], size=n_records, p=[0.17, 0.83]),
}
df = pd.DataFrame(data)
# Introduce missing values (~2.5% avg as per paper) [cite: 516]
for col in df.columns:
if col not in ['patient_id', 'healing_phase']:
mask = np.random.rand(len(df)) < 0.025
df.loc[mask, col] = np.nan
return df
# --- 3. Preprocessing and Model Pipeline ---
# Define numerical and categorical features for preprocessing
df = create_mock_dfu_dataset()
numerical_features = df.select_dtypes(include=np.number).columns.drop('patient_id').tolist()
categorical_features = df.select_dtypes(include=['object', 'category']).columns.drop('healing_phase').tolist()
# The paper used KNN Imputer with k=5 [cite: 127] and one-hot encoding [cite: 162]
preprocessor = ColumnTransformer(
transformers=[
('num', KNNImputer(n_neighbors=5), numerical_features),
('cat', OneHotEncoder(handle_unknown='ignore'), categorical_features)
],
remainder='passthrough'
)
# --- 4. LOPOCV Evaluation ---
# Use Leave-One-Patient-Out Cross-Validation (LOPOCV) as described in Section 2.4 [cite: 194]
X = df.drop(columns=['healing_phase', 'patient_id'])
# Map target labels to numerical values for the ordinal classifier
y = df['healing_phase'].map({'Inflammation': 0, 'Proliferation': 1, 'Remodeling': 2})
groups = df['patient_id']
# Define the cross-validation strategy
lopocv = LeaveOneGroupOut()
# Lists to store results from each fold
all_true_labels = []
all_pred_labels = []
print("\nStarting Leave-One-Patient-Out Cross-Validation...")
for i, (train_index, test_index) in enumerate(lopocv.split(X, y, groups)):
X_train, X_test = X.iloc[train_index], X.iloc[test_index]
y_train, y_test = y.iloc[train_index], y.iloc[test_index]
# Create the full pipeline including preprocessing, oversampling, and classification
# RandomOversampler is used to address class imbalance [cite: 185]
# The OrdinalRandomForest is our custom classifier
model_pipeline = ImbPipeline(steps=[
('preprocessor', preprocessor),
('sampler', RandomOverSampler(random_state=42)),
('classifier', OrdinalRandomForest())
])
# Fit the pipeline on the training data of the current fold
model_pipeline.fit(X_train, y_train)
# Make predictions on the test data (the held-out patient)
y_pred = model_pipeline.predict(X_test)
all_true_labels.extend(y_test)
all_pred_labels.extend(y_pred)
# Provide progress update
if (i + 1) % 25 == 0:
print(f" Completed fold {i+1}/{groups.nunique()}...")
print("Cross-validation finished.")
# --- 5. Final Results ---
print("\n--- Model Evaluation Results ---")
target_names = ['Inflammation', 'Proliferation', 'Remodeling']
# Calculate final accuracy
accuracy = accuracy_score(all_true_labels, all_pred_labels)
print(f"Overall Accuracy (similar to Table 3/4): {accuracy:.2f}")
# Display detailed classification report
print("\nClassification Report (F1 scores similar to Table 3):")
print(classification_report(all_true_labels, all_pred_labels, target_names=target_names))
print("="*40)
print("NOTE: These results are based on simulated data. Performance will differ on the real dataset.")
print("The code structure, however, faithfully represents the paper's methodology.")Related posts, You May like to read
- 7 Shocking Truths About Knowledge Distillation: The Good, The Bad, and The Breakthrough (SAKD)
- 7 Revolutionary Breakthroughs in Medical Image Translation (And 1 Fatal Flaw That Could Derail Your AI Model)
- DeepSPV: Revolutionizing 3D Spleen Volume Estimation from 2D Ultrasound with AI
- ACAM-KD: Adaptive and Cooperative Attention Masking for Knowledge Distillation
- GeoSAM2 3D Part Segmentation — Prompt-Controllable, Geometry-Aware Masks for Precision 3D Editing
- Probabilistic Smooth Attention for Deep Multiple Instance Learning in Medical Imaging
- A Knowledge Distillation-Based Approach to Enhance Transparency of Classifier Models
- Towards Trustworthy Breast Tumor Segmentation in Ultrasound Using AI Uncertainty
- Discrete Migratory Bird Optimizer with Deep Transfer Learning for Multi-Retinal Disease Detection