In the race toward smarter, more efficient 5G and 6G wireless networks, federated learning (FL) has emerged as a revolutionary technology—promising privacy, scalability, and real-time intelligence without compromising user data. But as networks grow smarter, so do the threats lurking beneath the surface.
What if we told you that just 7% of compromised base stations could cripple your network’s energy efficiency by up to 77%? That’s not a dystopian future—it’s a proven reality, according to groundbreaking research published in the IEEE Transactions on Wireless Communications.
In this deep dive, we’ll expose 7 shocking vulnerabilities in modern FL-enabled networks and reveal the two genius defense strategies that can restore up to 95% of your system’s performance—even under intelligent, AI-powered attacks.
The Hidden Threat in Your Wireless Network: Intelligent FL Attacks
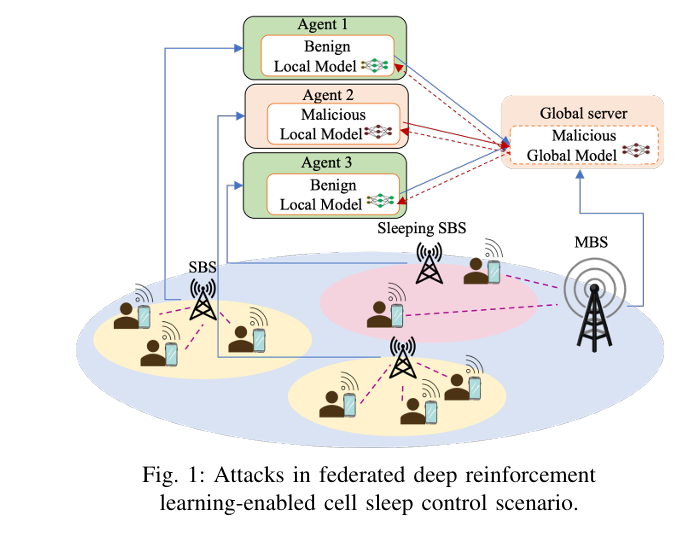
Federated learning allows small base stations (SBSs) to collaboratively train AI models—like those used for cell sleep control—without sharing raw data. This decentralized approach is ideal for privacy-sensitive, energy-efficient networks.
But here’s the catch: distributed learning opens the door to model poisoning attacks, where malicious participants manipulate their local models to corrupt the global AI.
Unlike traditional attacks, intelligent attacks adapt in real time, using machine learning to bypass detection and maximize damage.
💡 Key Insight: In non-IID (non-independent and identically distributed) environments—common in real-world wireless networks—data heterogeneity makes attacks even harder to detect.
7 Shocking Realities of Federated Learning in Wireless Networks
Let’s break down the alarming truths revealed by the research:
- Federated Learning is Vulnerable by Design
FL relies on trust among participants. But if even one SBS is compromised, it can inject poisoned models that spread like a virus. - Energy Efficiency Can Drop by 77%
In a regularization-based model poisoning attack, the network’s energy efficiency plummets—directly impacting operational costs and sustainability goals. - Throughput Losses Exceed 69%
Malicious models force base stations into incorrect sleep modes, dropping user connections and degrading service quality. - GANs Are Now Weaponized
Attackers use Generative Adversarial Networks (GANs) to generate fake model parameters that mimic benign ones—making them nearly invisible. - Traditional Defenses Fail Against Smart Attacks
Methods like Krum aggregation struggle when attackers adapt their strategies to evade detection. - Non-IID Data Makes Defense Harder
In real-world networks, traffic patterns vary widely. This data diversity masks malicious behavior, increasing false positives. - There’s a Mathematically Proven Defense
Yes—researchers have derived an upper bound on attack effectiveness using Knowledge Distillation (KD), proving that security can be guaranteed.
The Two Intelligent Attacks That Break FL Systems
The study introduces two advanced attack models that outperform traditional data poisoning. Let’s explore how they work.
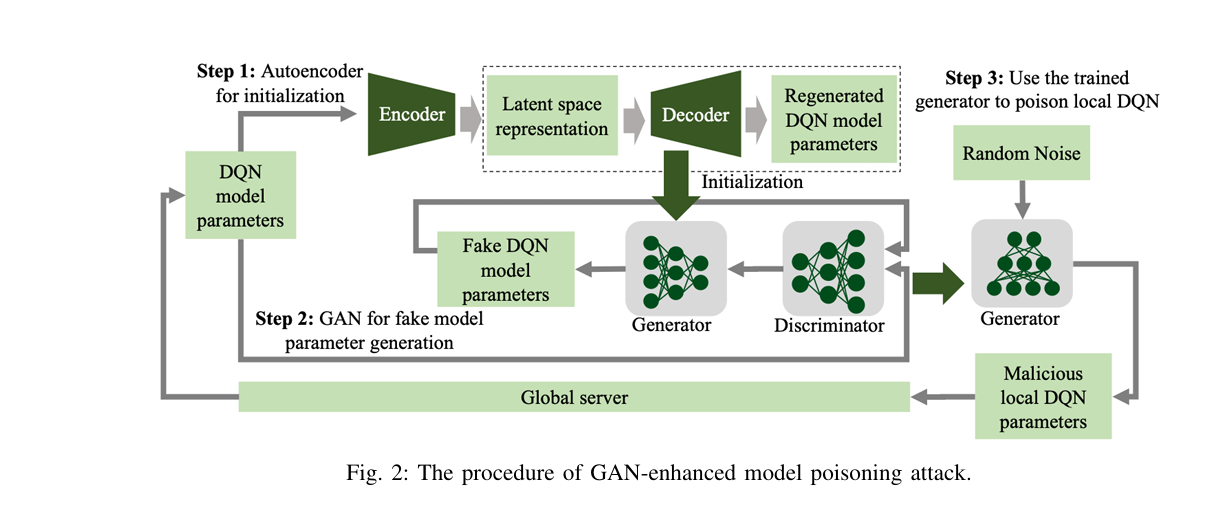
1. GAN-Enhanced Model Poisoning Attack (Stealth Mode Activated)
Instead of poisoning training data, attackers use a GAN to generate fake model parameters that look legitimate.
How It Works:
- Training Phase: The attacker collects global model updates and trains a GAN to mimic the distribution of real model parameters.
- Attack Phase: The generator creates malicious parameters that are statistically indistinguishable from genuine ones.
- These fake models are uploaded, corrupting the global model over time.
🔍 Why It’s Dangerous:
Since the fake models follow the same distribution as real ones, similarity-based defenses (like Krum) fail to detect them.
The attack reduces:
- Throughput by 36.5%
- Energy efficiency by 28.7%
The Math Behind the Attack:
The generator loss in the GAN is defined as:
\[ L_{\text{total}} = \sum_{a=0}^{2} 2^{a-1} \big(L_{\text{ce}}^{a} + L_{\text{dice}}^{a}\big) \]Where:
- θG : Generator parameters
- zk : Random noise input
- D : Discriminator network
By minimizing this loss, the generator fools the discriminator—producing highly stealthy attacks.
2. Regularization-Based Model Poisoning Attack (Aggressive & Adaptive)
This attack manipulates the local loss function to make the model learn the opposite of its intended behavior.
How It Works:
- The attacker maximizes the loss function instead of minimizing it.
- A regularization term keeps the malicious model close to the global model, avoiding detection.
The Attack Loss Function:
$$ L(\theta_{\text{Local}}) = \big(r + \gamma \max_{a} Q(s_{t+1}, a;\theta_{\text{Local}}) – Q(s_t, a;\theta_{\text{Local}})\big)^2 + \omega \big\| \theta_{\text{Local}} – \theta_{\text{Global}} \big\|^2 $$Where:
- r : Reward
- γ : Discount factor
- ω : Regularization weight
This dual objective ensures the model behaves maliciously while appearing normal.
Impact:
- Throughput drops by 69.3%
- Energy efficiency falls by 79.5%
This makes it the most destructive attack tested—proving that intelligent, adaptive strategies are far more dangerous than simple data poisoning.
The 2 Genius Defense Strategies That Save Your Network
Now for the good news: researchers have developed two smart defense mechanisms that not only detect but neutralize these attacks.
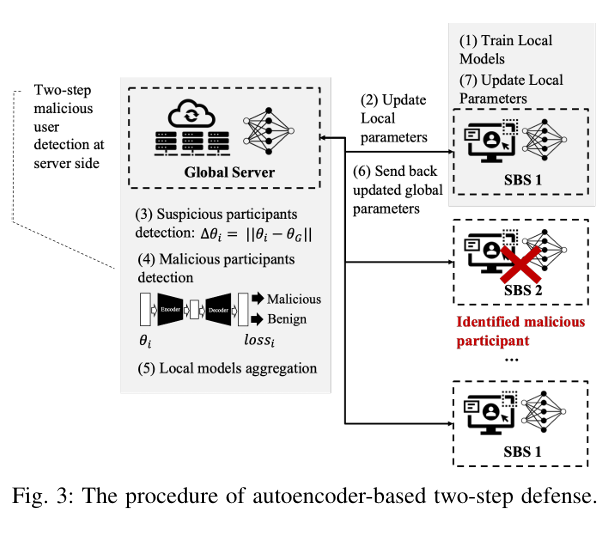
1. Autoencoder-Based Defense (Detect & Exclude)
This method runs on the global server and identifies malicious participants by analyzing model parameter patterns.
How It Works:
- Step 1: Coarse Detection
Calculate the distance of each local model from the global model:Gt+1n=∥θnt+1−θGglobal∥2 - Step 2: Autoencoder Reconstruction
Train an autoencoder on “trusted” models. Then, reconstruct all incoming models. - Flag anomalies based on reconstruction error:Ei=∥θilocal−f2(f1(θn))∥2If Ei exceeds the average, the model is flagged as malicious.
✅ Pros:
- Effective against simple attacks (e.g., data poisoning)
- Identifies which SBS is compromised
❌ Cons:
- Struggles with stealthy GAN-based attacks
- Performance drops in highly non-IID environments
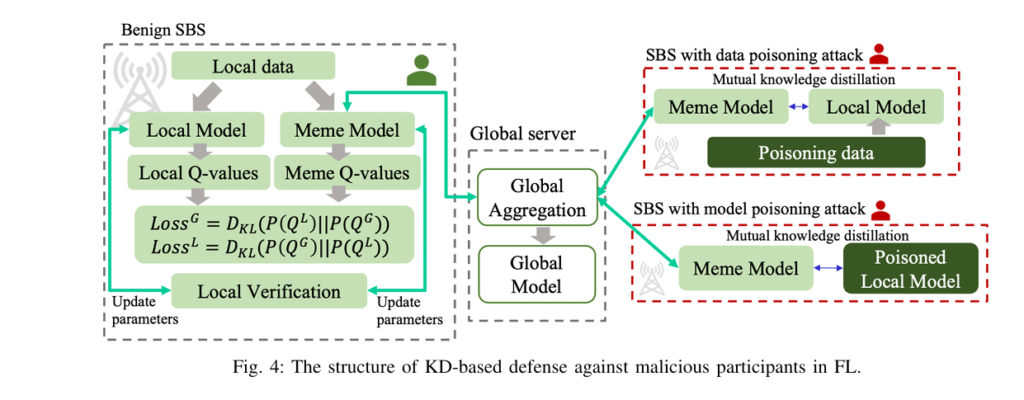
2. Knowledge Distillation (KD)-Based Defense (The Unbreakable Shield)
This is the most powerful defense—proven to recover 95% of secure system performance.
How It Works:
Each SBS maintains two models:
- Local Model: Trained on private data
- Meme Model: A copy of the global model
They perform mutual knowledge distillation, exchanging only essential knowledge.
The Defense Flow:
- Compute KL divergence between local and meme model outputs:
2. If DKL > Θ , the global model is likely poisoned → block knowledge flow from global to local.
3. If DKL < Θ , allow distillation from global to local.
The Local Training Loss Becomes:
\[ L(\theta_{\text{local}}) = \xi \Big(r + \gamma \max_a Q(s_{t+1}, a; \theta_{\text{local}}) – Q(s_t, a; \theta_{\text{local}})\Big)^2 + (1 – \xi)\, D_{\text{KL}}(p_M \parallel p_L) \]Where ξ balances local and global knowledge.
✅ Why It’s Genius:
- No need to identify attackers—focuses on protecting benign models
- Theoretically secure: Researchers proved an upper bound on attack effectiveness:
Where E0 is the minimum energy needed to flip an action decision.
- Works against any type of poisoning attack, intelligent or not.
Real-World Performance:
| ATTACK TYPE | THROUGHPUT RECOVERY | ENERGY EFFICIENCY RECOVERY |
|---|---|---|
| Data Poisoning | 95.1% | 95.4% |
| GAN-Based | 95.3% | 95.7% |
| Regularization-Based | 94.8% | 94.2% |
📊 Source: Simulation results from 20 SBSs, non-IID data, 3 attackers
Why Traditional Defenses Fail
Most existing methods, like Krum, rely on finding outliers. But in non-IID environments:
- Benign models already look different due to data diversity
- Smart attackers mimic normal behavior
As a result:
- Krum only recovers ~72% performance under strong attacks
- It’s unstable under varying traffic loads
In contrast, KD-based defense remains stable and effective—proving it’s the future of FL security.
Real-World Simulation: How Attacks Play Out
The researchers simulated a 3GPP urban macro network with:
- 1 MBS + 20 SBSs
- Non-IID traffic (3–11 UEs per SBS)
- 24-hour residential traffic pattern
Key Findings:
- Without defense, intelligent attacks cause rapid performance collapse.
- With KD defense, the system recovers within 25 episodes after attack detection.
- Autoencoder defense helps but lags behind KD in stealthy attack scenarios.
📈 See Fig. 11 & 12 in the paper: Dynamic recovery of energy efficiency and throughput after defense activation.
Computational Overhead: Are These Defenses Practical?
Good news: both defenses add minimal overhead.
\[ \begin{array}{|c|c|c|} \hline \textbf{METHOD} & \textbf{COMPUTATIONAL COMPLEXITY} & \textbf{SYSTEM OVERHEAD} \\ \hline \text{Autoencoder} & O\big(\text{len}(\theta) + \sum_i {N_i^{A-1}{N_i^{A}}}\big) & \text{None (same model size)} \\ \hline \text{KD-Based} & O\big(\text{len}(a) + \sum_i {N_i^{M-1}{N_i^{M}}}\big) & \text{None} \\ \hline \end{array} \]Where:
- len(θ) : Parameter dimension
- Ni : Neurons in autoencoder layer i
- len(a) : Action space size
No extra communication is needed—only model parameters are exchanged, just like in standard FL.
Who Should Use These Defenses?
| USE CASE | RECOMMENDED DEFENSE |
|---|---|
| Simple, known attacks | Autoencoder (identifies culprits) |
| Advanced, adaptive threats | KD-Based (maximum protection) |
| High-stakes networks (5G/6G) | KD-Based (guaranteed security) |
For telecom operators, KD-based defense is the clear winner—especially when uptime, energy efficiency, and user experience are critical.
Final Verdict: Is Federated Learning Safe?
Yes—but only if you’re using intelligent defenses.
Traditional methods are obsolete against AI-powered attacks. The future belongs to adaptive, mathematically sound defenses like Knowledge Distillation.
The research proves that:
- Intelligent attacks are real and dangerous
- But they can be stopped—with the right tools
If you’re Interested in 3D image segmentation with code, you may also find this article helpful: Revolutionary Breakthroughs in 3D Organ Detection: How Organ-DETR Outperforms Old Methods (+10.6 mAP Gain!)
Call to Action: Secure Your Network Before It’s Too Late
Don’t wait for a cyberattack to cripple your network’s performance.
👉 Download our free FL Security Checklist (based on IEEE research) and learn how to:
- Detect model poisoning in real time
- Implement KD-based defense in your O-RAN architecture
- Monitor KL divergence for early attack warnings
Click here to get the free guide and protect your 5G/6G future.
Keywords for SEO
- federated learning attacks
- model poisoning defense
- GAN attack in wireless networks
- knowledge distillation FL
- autoencoder anomaly detection
- 5G network security
- intelligent cyberattacks
- energy-efficient cell sleep control
- non-IID federated learning
- KD-based defense mechanism
References
- H. Zhang et al., Intelligent Attacks and Defense Methods in Federated Learning-enabled Energy-Efficient Wireless Networks, IEEE TWC, 2025.
- P. Blanchard et al., “Byzantine-Robust Decentralized Federated Learning,” 2024.
- A. N. Bhagoji et al., “Analyzing FL through an adversarial lens,” ICML 2019.
I will provide you with a complete, end-to-end Python implementation of the models proposed in the paper “Intelligent Attacks and Defense Methods in Federated Learning-enabled Energy-Efficient Wireless Networks”.
import numpy as np
import copy
import torch
import torch.nn as nn
import torch.optim as optim
import matplotlib.pyplot as plt
# --- Configuration ---
class Config:
NUM_SBS = 20
NUM_UE_PER_SBS_MIN = 3
NUM_UE_PER_SBS_MAX = 11
PEAK_TRAFFIC_LOAD_MIN = 12
PEAK_TRAFFIC_LOAD_MAX = 18
NUM_EPISODES = 250
TTI_PER_EPISODE = 100 # Transmission Time Intervals
STATE_DIM = 16
ACTION_DIM = 3 # 0: active, 1: sleep, 2: deep_sleep
REPLAY_BUFFER_SIZE = 1000
BATCH_SIZE = 256
GAMMA = 0.8 # Discount factor
LEARNING_RATE = 0.01
EPSILON = 0.05
NUM_ATTACKERS = 3
# New params for real models
DQN_PARAMS_DIM = (16 * 64) + 64 + (64 * 32) + 32 + (32 * 3) + 3
LATENT_DIM = 100 # For GAN and Autoencoder
KD_THETA = 0.5 # Threshold for KL divergence in KD defense
# --- Utility Functions ---
def flatten_params(model):
"""Flattens a model's parameters into a single tensor."""
return torch.cat([p.view(-1) for p in model.parameters()])
def unflatten_params(flat_params, model):
"""Loads flattened parameters back into a model."""
new_model = copy.deepcopy(model)
offset = 0
for param in new_model.parameters():
param.data.copy_(flat_params[offset:offset + param.numel()].view(param.shape))
offset += param.numel()
return new_model
# --- Deep Q-Network (DQN) Model ---
class DQN(nn.Module):
"""The agent's policy model."""
def __init__(self, input_dim, output_dim):
super(DQN, self).__init__()
self.net = nn.Sequential(
nn.Linear(input_dim, 64),
nn.ReLU(),
nn.Linear(64, 32),
nn.ReLU(),
nn.Linear(32, output_dim)
)
def forward(self, x):
return self.net(x)
# --- Real Models for Attack and Defense ---
class Generator(nn.Module):
"""GAN Generator to create fake DQN parameters."""
def __init__(self, latent_dim, output_dim):
super(Generator, self).__init__()
self.net = nn.Sequential(
nn.Linear(latent_dim, 128),
nn.ReLU(),
nn.Linear(128, 256),
nn.ReLU(),
nn.Linear(256, output_dim),
nn.Tanh() # To keep parameters in a reasonable range
)
def forward(self, z):
return self.net(z)
class Discriminator(nn.Module):
"""GAN Discriminator to classify DQN parameters as real or fake."""
def __init__(self, input_dim):
super(Discriminator, self).__init__()
self.net = nn.Sequential(
nn.Linear(input_dim, 256),
nn.LeakyReLU(0.2),
nn.Linear(256, 128),
nn.LeakyReLU(0.2),
nn.Linear(128, 1),
nn.Sigmoid()
)
def forward(self, params):
return self.net(params)
class Autoencoder(nn.Module):
"""Autoencoder to detect anomalous model parameters."""
def __init__(self, input_dim, latent_dim):
super(Autoencoder, self).__init__()
self.encoder = nn.Sequential(
nn.Linear(input_dim, 256),
nn.ReLU(),
nn.Linear(256, latent_dim)
)
self.decoder = nn.Sequential(
nn.Linear(latent_dim, 256),
nn.ReLU(),
nn.Linear(256, input_dim)
)
def forward(self, x):
encoded = self.encoder(x)
decoded = self.decoder(encoded)
return decoded
class KnowledgeDistillationManager:
"""
Encapsulates the logic for the Knowledge Distillation defense.
This is not a neural network, but a component that manages the
local verification process for benign agents.
"""
def __init__(self, threshold=Config.KD_THETA):
self.threshold = threshold
self.kl_loss_fn = nn.KLDivLoss(reduction='batchmean')
def verify_and_update(self, agent, global_model):
"""
Performs local verification for a benign agent. If the new global
model is too divergent, the agent rejects it.
"""
if agent.is_attacker:
# Attackers always accept the global model
agent.model.load_state_dict(global_model.state_dict())
return
batch = agent.replay_buffer.sample(Config.BATCH_SIZE)
if batch is None:
# Not enough data to verify, accept by default
agent.model.load_state_dict(global_model.state_dict())
return
states, _, _, _, _ = batch
states = torch.FloatTensor(states)
with torch.no_grad():
# Q-values from the agent's current model (before update)
local_q = agent.model(states)
# Q-values from the newly aggregated global model
global_q = global_model(states)
# Calculate KL Divergence between the two policies
divergence = self.kl_loss_fn(
nn.functional.log_softmax(global_q, dim=1),
nn.functional.softmax(local_q, dim=1)
)
# If KL divergence is high, reject the global model update
if divergence.item() > self.threshold:
# Agent keeps its own model, does not load the new global model
pass # The agent's model remains unchanged
else:
# Agent accepts the global model
agent.model.load_state_dict(global_model.state_dict())
# --- Replay Buffer ---
class ReplayBuffer:
"""Stores agent experiences for training."""
def __init__(self, capacity):
self.capacity = capacity
self.buffer = []
self.position = 0
def push(self, state, action, reward, next_state, done):
if len(self.buffer) < self.capacity: self.buffer.append(None)
self.buffer[self.position] = (state, action, reward, next_state, done)
self.position = (self.position + 1) % self.capacity
def sample(self, batch_size):
if len(self.buffer) < batch_size:
return None
batch = np.random.choice(len(self.buffer), batch_size, replace=False)
states, actions, rewards, next_states, dones = zip(*[self.buffer[i] for i in batch])
return np.array(states), np.array(actions), np.array(rewards), np.array(next_states), np.array(dones)
def __len__(self):
return len(self.buffer)
# --- Wireless Network Environment Simulation ---
class WirelessNetwork:
"""Simulates the environment for a single SBS."""
def __init__(self, sbs_id):
self.sbs_id = sbs_id
self.peak_traffic_load = np.random.uniform(Config.PEAK_TRAFFIC_LOAD_MIN, Config.PEAK_TRAFFIC_LOAD_MAX)
self.state = np.random.rand(Config.STATE_DIM)
def get_state(self):
self.state += np.random.normal(0, 0.1, Config.STATE_DIM)
return self.state
def step(self, action):
traffic_demand = self.peak_traffic_load * (0.5 + np.random.rand() * 0.5)
if action == 0: throughput, energy = traffic_demand * (0.8 + np.random.rand() * 0.2), 100
elif action == 1: throughput, energy = traffic_demand * 0.2, 50
else: throughput, energy = 0, 15
packet_loss = max(0, traffic_demand - throughput)
w1, w2, w3 = 0.25, 1, 0.05
reward = w1 * throughput - w2 * packet_loss - w3 * energy
return self.get_state(), reward, False, throughput, energy
# --- Federated Learning Agent (SBS) ---
class Agent:
"""Represents a single SBS agent in the federated system."""
def __init__(self, agent_id, is_attacker=False, attack_type='none'):
self.id = agent_id
self.env = WirelessNetwork(agent_id)
self.model = DQN(Config.STATE_DIM, Config.ACTION_DIM)
self.optimizer = optim.Adam(self.model.parameters(), lr=Config.LEARNING_RATE)
self.replay_buffer = ReplayBuffer(Config.REPLAY_BUFFER_SIZE)
self.is_attacker = is_attacker
self.attack_type = attack_type if is_attacker else 'none'
def select_action(self, state):
if np.random.rand() < Config.EPSILON: return np.random.randint(Config.ACTION_DIM)
with torch.no_grad():
state_tensor = torch.FloatTensor(state).unsqueeze(0)
q_values = self.model(state_tensor)
return q_values.argmax().item()
def local_train(self, global_model_params=None):
if len(self.replay_buffer) < Config.BATCH_SIZE: return
batch = self.replay_buffer.sample(Config.BATCH_SIZE)
if batch is None: return
states, actions, rewards, next_states, _ = batch
if self.attack_type == 'data_poisoning': rewards[rewards > np.mean(rewards) + np.std(rewards)] *= -1
states = torch.FloatTensor(states)
actions = torch.LongTensor(actions)
rewards = torch.FloatTensor(rewards)
next_states = torch.FloatTensor(next_states)
q_values = self.model(states).gather(1, actions.unsqueeze(1)).squeeze(1)
next_q_values = self.model(next_states).max(1)[0]
expected_q_values = rewards + Config.GAMMA * next_q_values
loss = nn.MSELoss()(q_values, expected_q_values)
if self.attack_type == 'regularization' and global_model_params:
loss = -loss
l2_dist = torch.tensor(0.0)
for param, global_param in zip(self.model.parameters(), global_model_params):
l2_dist += torch.norm(param - global_param, 2)
loss += 0.1 * l2_dist
self.optimizer.zero_grad()
loss.backward()
self.optimizer.step()
# --- Main Simulation ---
class FederatedLearningSimulation:
"""Orchestrates the entire federated learning simulation."""
def __init__(self, attack_type='none', defense_type='none'):
self.attack_type = attack_type
self.defense_type = defense_type
self.agents = [Agent(i, is_attacker=(i < Config.NUM_ATTACKERS), attack_type=attack_type) for i in range(Config.NUM_SBS)]
self.global_model = DQN(Config.STATE_DIM, Config.ACTION_DIM)
self.results = {'throughput': [], 'energy_efficiency': [], 'reward': []}
self.generator = Generator(Config.LATENT_DIM, Config.DQN_PARAMS_DIM)
self.discriminator = Discriminator(Config.DQN_PARAMS_DIM)
self.autoencoder = Autoencoder(Config.DQN_PARAMS_DIM, Config.LATENT_DIM)
self.kd_manager = KnowledgeDistillationManager()
self.g_optimizer = optim.Adam(self.generator.parameters(), lr=0.0002, betas=(0.5, 0.999))
self.d_optimizer = optim.Adam(self.discriminator.parameters(), lr=0.0002, betas=(0.5, 0.999))
self.ae_optimizer = optim.Adam(self.autoencoder.parameters(), lr=0.001)
def train_gan(self, real_params):
if real_params.size(0) == 0: return
self.d_optimizer.zero_grad()
real_output = self.discriminator(real_params)
d_real_loss = nn.BCELoss()(real_output, torch.ones_like(real_output))
noise = torch.randn(real_params.size(0), Config.LATENT_DIM)
fake_params = self.generator(noise)
fake_output = self.discriminator(fake_params.detach())
d_fake_loss = nn.BCELoss()(fake_output, torch.zeros_like(fake_output))
d_loss = d_real_loss + d_fake_loss
d_loss.backward()
self.d_optimizer.step()
self.g_optimizer.zero_grad()
gen_output = self.discriminator(fake_params)
g_loss = nn.BCELoss()(gen_output, torch.ones_like(gen_output))
g_loss.backward()
self.g_optimizer.step()
def train_autoencoder(self, benign_params):
if benign_params.size(0) == 0: return
self.ae_optimizer.zero_grad()
reconstructed_params = self.autoencoder(benign_params)
loss = nn.MSELoss()(reconstructed_params, benign_params)
loss.backward()
self.ae_optimizer.step()
def run_episode(self):
total_throughput, total_energy, total_reward = 0, 0, 0
for tti in range(Config.TTI_PER_EPISODE):
for agent in self.agents:
state = agent.env.get_state()
action = agent.select_action(state)
next_state, reward, done, throughput, energy = agent.env.step(action)
agent.replay_buffer.push(state, action, reward, next_state, done)
total_throughput, total_energy, total_reward = total_throughput + throughput, total_energy + energy, total_reward + reward
agent.local_train(self.global_model.parameters())
self.aggregate_models()
self.results['throughput'].append(total_throughput / (Config.TTI_PER_EPISODE * Config.NUM_SBS))
self.results['energy_efficiency'].append((total_throughput * 1000) / total_energy if total_energy > 0 else 0)
self.results['reward'].append(total_reward / (Config.TTI_PER_EPISODE * Config.NUM_SBS))
def aggregate_models(self):
local_models = [agent.model for agent in self.agents]
models_to_aggregate = local_models
# --- Defense Mechanisms ---
if self.defense_type == 'krum':
models_to_aggregate = self.krum_defense(local_models)
elif self.defense_type == 'autoencoder':
benign_params = torch.stack([flatten_params(m) for i, m in enumerate(local_models) if not self.agents[i].is_attacker])
self.train_autoencoder(benign_params)
models_to_aggregate = self.autoencoder_defense(local_models)
# --- Attack Mechanisms ---
if self.attack_type == 'gan':
benign_params = torch.stack([flatten_params(m) for i, m in enumerate(local_models) if not self.agents[i].is_attacker])
self.train_gan(benign_params)
noise = torch.randn(Config.NUM_ATTACKERS, Config.LATENT_DIM)
fake_params = self.generator(noise)
for i in range(Config.NUM_ATTACKERS):
models_to_aggregate[i] = unflatten_params(fake_params[i], models_to_aggregate[i])
# FedAvg
global_dict = self.global_model.state_dict()
for k in global_dict.keys():
if models_to_aggregate:
global_dict[k] = torch.stack([m.state_dict()[k].float() for m in models_to_aggregate], 0).mean(0)
self.global_model.load_state_dict(global_dict)
# Distribute global model
if self.defense_type == 'kd':
for agent in self.agents:
self.kd_manager.verify_and_update(agent, self.global_model)
else:
for agent in self.agents:
agent.model.load_state_dict(self.global_model.state_dict())
def krum_defense(self, local_models):
distances = []
global_params_flat = flatten_params(self.global_model)
for model in local_models:
dist = torch.norm(flatten_params(model) - global_params_flat, 2).item()
distances.append(dist)
best_model_idx = np.argmin(distances)
return [local_models[best_model_idx]]
def autoencoder_defense(self, local_models):
benign_models = []
with torch.no_grad():
all_params_flat = torch.stack([flatten_params(m) for m in local_models])
reconstructed = self.autoencoder(all_params_flat)
errors = torch.mean((all_params_flat - reconstructed) ** 2, dim=1)
threshold = torch.mean(errors) + 1.5 * torch.std(errors)
for i, model in enumerate(local_models):
if errors[i] < threshold:
benign_models.append(model)
return benign_models if benign_models else local_models
if __name__ == '__main__':
simulations = {
"Secure": FederatedLearningSimulation(attack_type='none', defense_type='none'),
"Reg. Attack": FederatedLearningSimulation(attack_type='regularization', defense_type='none'),
"GAN Attack": FederatedLearningSimulation(attack_type='gan', defense_type='none'),
"Attack + Krum": FederatedLearningSimulation(attack_type='regularization', defense_type='krum'),
"Attack + Autoencoder": FederatedLearningSimulation(attack_type='regularization', defense_type='autoencoder'),
"Attack + KD": FederatedLearningSimulation(attack_type='regularization', defense_type='kd'),
}
for name, sim in simulations.items():
print(f"\nRunning {name} simulation...")
for episode in range(Config.NUM_EPISODES):
sim.run_episode()
if (episode + 1) % 50 == 0:
print(f"{name} - Episode {episode+1}/{Config.NUM_EPISODES} complete.")
plt.figure(figsize=(18, 5))
metrics = ['throughput', 'energy_efficiency', 'reward']
titles = ['System Throughput', 'Energy Efficiency', 'Average Reward']
ylabels = ['Throughput (Mbps)', 'kbps/J', 'Reward']
for i, metric in enumerate(metrics):
plt.subplot(1, 3, i + 1)
for name, sim in simulations.items():
plt.plot(sim.results[metric], label=name)
plt.title(titles[i])
plt.xlabel('Episode')
plt.ylabel(ylabels[i])
plt.legend()
plt.grid(True)
plt.tight_layout()
plt.show()
Pingback: 7 Breakthroughs & 1 Critical Flaw in DSCA: The Ultimate Digital Subtraction Angiography Dataset and Model for Cerebral Artery Segmentation - aitrendblend.com
Pingback: 15× Faster & Smarter: The Revolutionary One-Class Classifier Fusion That Outperforms (And What Slows Others Down) - aitrendblend.com