Introduction: The Data Scarcity Problem in Medical Imaging
Medical imaging is at the heart of modern diagnostics, enabling clinicians to detect, monitor, and treat a wide range of conditions—from cancer to neurological disorders. However, one of the most pressing challenges in this field is the scarcity of labeled training data . Annotating medical images is time-consuming, costly, and requires expert knowledge. This bottleneck severely limits the performance of deep learning models, especially in low-data regimes.
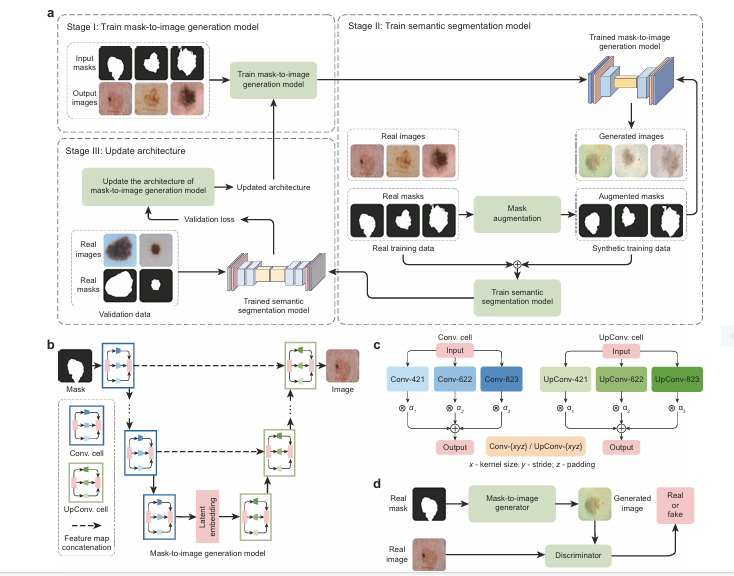
Enter GenSeg , a groundbreaking end-to-end synthetic data generation framework that is changing the game for medical image segmentation . In this article, we explore how GenSeg overcomes the data scarcity problem, improves segmentation accuracy, and delivers 10–20% absolute gains in both in-domain and out-of-domain settings—all while requiring 8–20 times fewer labeled samples than traditional methods.
What Is GenSeg? A Game-Changing Approach to Medical Image Segmentation
Overview of GenSeg
GenSeg stands for Generative Segmentation , and it’s more than just another data augmentation tool. It’s a deep generative model that creates high-quality, labeled synthetic data tailored specifically for medical image segmentation tasks. Unlike traditional methods that rely on extensive unlabeled data or manual annotation, GenSeg synthesizes images directly from expert-annotated masks, integrating the segmentation performance into the generation process.
Key Features of GenSeg
- End-to-end framework combining data generation and segmentation training
- No need for large unlabeled datasets , unlike semi-supervised approaches
- Strong performance in ultra-low data regimes (as few as 50 training examples)
- Superior out-of-domain generalization
- Reduces labeled data requirements by 8–20×
How GenSeg Works: A Technical Deep Dive
Architecture and Workflow
GenSeg is built around a multi-level optimization (MLO) framework that ensures the synthetic data generated directly improves the performance of the downstream segmentation model.
Step 1: Augmentation of Expert-Annotated Masks
The process begins with a small set of expert-annotated segmentation masks . These masks are augmented using basic transformations (e.g., rotation, flipping, scaling) to create variations.
Step 2: Image Generation from Masks
The augmented masks are then fed into a deep generative model that synthesizes corresponding medical images. This is where GenSeg diverges from traditional generative models like GANs or VAEs—it doesn’t just generate images randomly; it learns to generate images that are semantically aligned with the input masks.
Step 3: Task-Driven Optimization
The generated image-mask pairs are used to train a segmentation model (e.g., UNet, DeepLab, SwinUnet). The validation performance of this model is then used to guide the generator’s training , ensuring that the synthetic data continuously improves segmentation accuracy.
Mathematical Formulation
GenSeg’s optimization can be described using a bilevel optimization framework:
$$ \min_{A} \mathcal{L}_{\text{val}}\left(S^*(A), D_{\text{val}}^{\text{seg}}\right) $$ $$ \text{where } S^*(A) = \arg\min_{S} \mathcal{L}_{\text{seg}}\left(S, D_b(G^*(A), D_{\text{ts}}^{\text{reg}})\right) $$ $$ G^*(A) = \arg\min_{G} \mathcal{L}_{\text{gan}}\left(G, A, H, D_{\text{gan}}\right) $$Where:
- A : augmentation policy
- G : generator
- S : segmentation model
- Lseg : segmentation loss
- Lval : validation loss
- Lgan : adversarial loss
This formulation ensures that the synthetic data generation is task-driven and performance-optimized .
GenSeg vs. Traditional Methods: Why It Outperforms
Comparison with Data Augmentation Techniques
| METHOD | REQUIRMENT | PERFORMANCE GAIN | GENERALIZATION | COMPLEXITY |
|---|---|---|---|---|
| Rotation/Flipping | Low | Minimal | Poor | Simple |
| GAN-based Generation | High (unlabeled) | Moderate | Moderate | Complex |
| GenSeg | Very Low (labeled) | High (10–20%) | Excellent | Moderate |
Why GenSeg Wins
- End-to-end integration : Unlike traditional augmentation, GenSeg’s generation process is directly influenced by segmentation performance .
- No need for unlabeled data : GenSeg only requires a small set of labeled images , making it ideal for clinical environments where data privacy and regulatory hurdles are common.
- Superior generalization : GenSeg excels in out-of-domain (OOD) settings, where training and test data come from different distributions.
Real-World Applications: GenSeg in Action
Case Studies and Datasets
GenSeg has been tested across 19 datasets and 11 medical segmentation tasks , including:
- Placental vessel segmentation (FetReg dataset)
- Skin lesion segmentation (ISIC dataset)
- Polyp detection (CVC-Clinic dataset)
- Intraretinal cystoid fluid segmentation (ICFluid dataset)
- Breast cancer segmentation (BUID dataset)
Performance Metrics
| DATASET | MODEL | JACCARD SCORE (IOU) |
|---|---|---|
| ISIC (40 samples) | UNet | 67.3% |
| ISIC (40 samples) | GenSeg-UNet | 73.9% |
| CVC-Clinic (40 samples) | DeepLab | 55.6% |
| CVC-Clinic (40 samples) | GenSeg-DeepLab | 66.9% |
| BUID (100 samples) | UNet | 62.1% |
| BUID (100 samples) | GenSeg-UNet | 72.5% |
These results demonstrate consistent performance gains across diverse tasks, even with minimal training data.
Advantages of Using GenSeg in Medical Imaging
1. Dramatic Reduction in Labeled Data Requirements
GenSeg requires 8–20 times fewer labeled samples than conventional methods. This means hospitals and research labs can train accurate models with fewer annotated images, reducing costs and accelerating development.
2. Strong Generalization to New Domains
Whether the test data comes from a different hospital, imaging device, or patient population, GenSeg maintains high accuracy , making it ideal for real-world deployment.
3. Compatibility with Existing Models
GenSeg works seamlessly with popular architectures like:
- UNet
- DeepLab
- SwinUnet
- Transformer-based models
This flexibility ensures that GenSeg can be integrated into existing pipelines with minimal disruption.
4. Enhanced Training Efficiency
By generating task-specific synthetic data , GenSeg reduces the need for extensive data collection and preprocessing. This leads to faster training cycles and lower computational costs .
Limitations and Future Directions
While GenSeg represents a major leap forward, it is not without limitations:
1. Dependency on Initial Expert Annotations
GenSeg still requires a small set of expert-annotated images to kickstart the synthetic data generation process. In environments where even minimal annotation is challenging, this could be a barrier.
2. Potential for Artifacts in Synthetic Data
Although GenSeg generates high-quality images, there is always a risk that synthetic artifacts could be introduced. These artifacts may not be clinically relevant but could affect downstream model performance if not carefully validated.
3. Clinical Workflow Integration
Before GenSeg can be widely adopted in clinical settings, it must undergo real-world validation to ensure that its synthetic data does not introduce diagnostic inconsistencies or biases .
If you’re Interested in semi supervised learning using deep learning, you may also find this article helpful: 7 Powerful Problems and Solutions: Overcoming and Transforming Long-Tailed Semi-Supervised Learning with FlexDA & ADELLO
Conclusion: GenSeg Is the Future of Medical Image Segmentation
GenSeg is not just a technical innovation—it’s a paradigm shift in how we approach medical image segmentation in data-scarce environments. By combining end-to-end synthetic data generation with task-driven optimization , GenSeg delivers superior performance with minimal labeled data .
Whether you’re a researcher , clinician , or AI developer , GenSeg offers a powerful solution to one of the most persistent challenges in medical imaging: data scarcity .
Call to Action: Start Using GenSeg Today
Ready to revolutionize your medical imaging workflow?
✅ Try GenSeg using GitHub code in your next segmentation project
✅ Join the growing community of researchers and clinicians using GenSeg
✅ Share your results and help improve the framework for future users
Visit the official GenSeg GitHub repository or request access to the framework to begin generating high-quality synthetic data for your medical imaging tasks.
Frequently Asked Questions (FAQs)
1. What is GenSeg?
GenSeg is an end-to-end synthetic data generation framework designed for medical image segmentation in ultra-low data regimes.
2. How does GenSeg improve segmentation performance?
By generating synthetic, labeled image-mask pairs that are optimized for segmentation accuracy through a multi-level optimization framework.
3. Does GenSeg require unlabeled data?
No, GenSeg only requires a small set of expert-annotated images to initiate the generation process.
4. Can GenSeg be used with different segmentation models?
Yes, GenSeg is compatible with UNet, DeepLab, SwinUnet, and other popular architectures.
5. Is GenSeg suitable for clinical deployment?
While promising, real-world validation is still needed to ensure synthetic data does not introduce diagnostic inconsistencies.
Here, Simple version of GenSeg code in Pytorch:
import torch
import torch.nn as nn
import torch.optim as optim
import numpy as np
from torch.autograd import Variable
import torchvision.transforms as T
from torchvision.transforms import functional as F
# A simplified representation of a dataset
class MedicalImageDataset(torch.utils.data.Dataset):
def __init__(self, images, masks):
self.images = images
self.masks = masks
# Augmentation for masks, as described in the paper
self.transform = T.Compose([
T.RandomHorizontalFlip(),
T.RandomVerticalFlip(),
T.RandomRotation(degrees=5), # Using a small rotation as discussed for vessel segmentation
])
def __len__(self):
return len(self.images)
def __getitem__(self, idx):
image = self.images[idx]
mask = self.masks[idx]
return image, mask
def get_augmented_mask(self, mask_batch):
"""Applies transformations to a batch of masks."""
# Note: torchvision transforms typically work on PIL images or single tensors.
# This is a simplified way to apply it to a batch.
augmented_batch = torch.stack([self.transform(m) for m in mask_batch])
return augmented_batch
# ==================================================================================================
# 1. Searchable Architecture Components (as in Fig 1c)
# ==================================================================================================
class SearchableCell(nn.Module):
"""
A searchable cell that contains multiple candidate operations.
The final output is a weighted sum of the outputs of these operations,
where the weights (alphas) are learned.
"""
def __init__(self, in_channels, out_channels, upsample=False):
super(SearchableCell, self).__init__()
self.upsample = upsample
# Candidate operations as described in the paper (Conv/UpConv-xyz)
if upsample:
# Transposed Convolution operations for the decoder
self.ops = nn.ModuleList([
nn.ConvTranspose2d(in_channels, out_channels, kernel_size=4, stride=2, padding=1),
nn.ConvTranspose2d(in_channels, out_channels, kernel_size=6, stride=2, padding=2),
nn.ConvTranspose2d(in_channels, out_channels, kernel_size=8, stride=2, padding=3)
])
else:
# Standard Convolution operations for the encoder
self.ops = nn.ModuleList([
nn.Conv2d(in_channels, out_channels, kernel_size=4, stride=2, padding=1),
nn.Conv2d(in_channels, out_channels, kernel_size=6, stride=2, padding=2),
nn.Conv2d(in_channels, out_channels, kernel_size=8, stride=2, padding=3)
])
# Learnable architecture parameters (alphas)
self.alphas = nn.Parameter(torch.randn(len(self.ops)))
def forward(self, x):
# Apply softmax to alphas to get weights that sum to 1
weights = torch.softmax(self.alphas, dim=-1)
# Calculate the weighted sum of the outputs of all candidate operations
return sum(w * op(x) for w, op in zip(weights, self.ops))
# ==================================================================================================
# 2. Mask-to-Image Generation Model (Generator) with Searchable Architecture
# ==================================================================================================
class SearchableGenerator(nn.Module):
def __init__(self, in_channels=1, out_channels=3):
super(SearchableGenerator, self).__init__()
# UNet-like architecture with SearchableCells
self.encoder1 = SearchableCell(in_channels, 64)
self.encoder2 = SearchableCell(64, 128)
self.encoder3 = SearchableCell(128, 256)
self.decoder1 = SearchableCell(256, 128, upsample=True)
self.decoder2 = SearchableCell(128 * 2, 64, upsample=True)
self.decoder3 = SearchableCell(64 * 2, 32, upsample=True)
self.final_layer = nn.Sequential(
nn.Conv2d(32, out_channels, kernel_size=3, padding=1),
nn.Tanh()
)
# Group architecture parameters for the optimizer
self.architecture_parameters = [p for name, p in self.named_parameters() if 'alphas' in name]
self.weight_parameters = [p for name, p in self.named_parameters() if 'alphas' not in name]
def forward(self, x):
# Encoder
enc1 = F.leaky_relu(self.encoder1(x), 0.2)
enc2 = F.leaky_relu(F.instance_norm(self.encoder2(enc1)), 0.2)
enc3 = F.leaky_relu(F.instance_norm(self.encoder3(enc2)), 0.2)
# Decoder with skip connections
dec1 = F.relu(F.instance_norm(self.decoder1(enc3)))
dec2 = F.relu(F.instance_norm(self.decoder2(torch.cat([dec1, enc2], 1))))
dec3 = F.relu(F.instance_norm(self.decoder3(torch.cat([dec2, enc1], 1))))
return self.final_layer(dec3)
# ==================================================================================================
# 3. Discriminator and Segmentation Models (same as before)
# ==================================================================================================
class Discriminator(nn.Module):
def __init__(self, in_channels=3):
super(Discriminator, self).__init__()
self.model = nn.Sequential(
nn.Conv2d(in_channels + 1, 64, 4, 2, 1),
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(64, 128, 4, 2, 1),
nn.InstanceNorm2d(128),
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(128, 256, 4, 2, 1),
nn.InstanceNorm2d(256),
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(256, 1, 4, padding=1),
nn.Sigmoid()
)
def forward(self, image, mask):
img_input = torch.cat((image, mask), 1)
return self.model(img_input)
class UNet(nn.Module):
def __init__(self, in_channels=3, out_channels=1):
super(UNet, self).__init__()
def conv_block(ic, oc):
return nn.Sequential(
nn.Conv2d(ic, oc, 3, padding=1), nn.ReLU(),
nn.Conv2d(oc, oc, 3, padding=1), nn.ReLU()
)
self.enc1 = conv_block(in_channels, 64)
self.enc2 = conv_block(64, 128)
self.enc3 = conv_block(128, 256)
self.pool = nn.MaxPool2d(2)
self.bottleneck = conv_block(256, 512)
self.upconv3 = nn.ConvTranspose2d(512, 256, 2, stride=2)
self.dec3 = conv_block(512, 256)
self.upconv2 = nn.ConvTranspose2d(256, 128, 2, stride=2)
self.dec2 = conv_block(256, 128)
self.upconv1 = nn.ConvTranspose2d(128, 64, 2, stride=2)
self.dec1 = conv_block(128, 64)
self.final_conv = nn.Conv2d(64, out_channels, 1)
def forward(self, x):
e1 = self.enc1(x)
e2 = self.enc2(self.pool(e1))
e3 = self.enc3(self.pool(e2))
b = self.bottleneck(self.pool(e3))
d3 = self.dec3(torch.cat((self.upconv3(b), e3), dim=1))
d2 = self.dec2(torch.cat((self.upconv2(d3), e2), dim=1))
d1 = self.dec1(torch.cat((self.upconv1(d2), e1), dim=1))
return torch.sigmoid(self.final_conv(d1))
# ==================================================================================================
# 4. Multi-Level Optimization (MLO) Framework
# ==================================================================================================
class GenSegTrainer:
def __init__(self, generator, discriminator, segmentation_model, config):
self.generator = generator
self.discriminator = discriminator
self.segmentation_model = segmentation_model
self.config = config
# Optimizers for each component of the MLO framework
self.g_optimizer = optim.Adam(self.generator.weight_parameters, lr=config['lr_g'], betas=(0.5, 0.999))
self.d_optimizer = optim.Adam(self.discriminator.parameters(), lr=config['lr_d'], betas=(0.5, 0.999))
self.s_optimizer = optim.RMSprop(self.segmentation_model.parameters(), lr=config['lr_s'])
self.a_optimizer = optim.Adam(self.generator.architecture_parameters, lr=config['lr_a'], betas=(0.5, 0.999))
# Loss functions
self.gan_loss = nn.BCELoss()
self.l1_loss = nn.L1Loss()
self.segmentation_loss = nn.BCELoss() # Pixel-wise cross-entropy
def train(self, train_loader, val_loader, epochs):
val_iter = iter(val_loader)
for epoch in range(epochs):
for i, (real_images, real_masks) in enumerate(train_loader):
real_images, real_masks = real_images.cuda(), real_masks.cuda()
# =================================================================
# Stage I: Train Mask-to-Image Generation Model (GAN weights G)
# Architecture 'A' (alphas) is fixed in this stage.
# =================================================================
self.g_optimizer.zero_grad()
self.d_optimizer.zero_grad()
# Generate augmented masks and corresponding fake images
augmented_masks = train_loader.dataset.get_augmented_mask(real_masks)
generated_images = self.generator(augmented_masks)
# Train Discriminator
# Real
d_real_output = self.discriminator(real_images, real_masks)
d_real_loss = self.gan_loss(d_real_output, torch.ones_like(d_real_output))
# Fake
d_fake_output = self.discriminator(generated_images.detach(), augmented_masks)
d_fake_loss = self.gan_loss(d_fake_output, torch.zeros_like(d_fake_output))
d_loss = (d_real_loss + d_fake_loss) * 0.5
d_loss.backward()
self.d_optimizer.step()
# Train Generator
d_fake_output = self.discriminator(generated_images, augmented_masks)
g_gan_loss = self.gan_loss(d_fake_output, torch.ones_like(d_fake_output))
g_l1_loss = self.l1_loss(generated_images, real_images)
g_loss = g_gan_loss + self.config['lambda_l1'] * g_l1_loss
g_loss.backward()
self.g_optimizer.step()
# =================================================================
# Stage II: Train Semantic Segmentation Model (weights S)
# =================================================================
self.s_optimizer.zero_grad()
# On real data
pred_masks_real = self.segmentation_model(real_images)
loss_real = self.segmentation_loss(pred_masks_real, real_masks)
# On generated data
with torch.no_grad():
aug_masks_new = train_loader.dataset.get_augmented_mask(real_masks)
gen_images_new = self.generator(aug_masks_new)
pred_masks_fake = self.segmentation_model(gen_images_new)
loss_fake = self.segmentation_loss(pred_masks_fake, aug_masks_new)
s_loss = loss_real + self.config['gamma'] * loss_fake
s_loss.backward()
self.s_optimizer.step()
# =================================================================
# Stage III: Update Architecture of Generation Model (params A)
# This part updates the generator's architecture parameters (alphas)
# by minimizing the segmentation loss on a validation set.
# This is a conceptual implementation of the one-step approximation
# from the paper's optimization algorithm section.
# =================================================================
self.a_optimizer.zero_grad()
# Get a batch of validation data
try:
val_images, val_masks = next(val_iter)
except StopIteration:
val_iter = iter(val_loader)
val_images, val_masks = next(val_iter)
val_images, val_masks = val_images.cuda(), val_masks.cuda()
# The paper proposes an approximation (Eq. 8) which requires
# calculating the gradient of the validation loss with respect to
# the architecture parameters 'A'. This involves second-order derivatives.
# The line below is a simplification. In a real implementation, you would
# use a library like `higher` to create a stateless version of the
# segmentation model, perform the inner loop update (Stage II),
# and then backpropagate the validation loss through that update.
# Conceptual step: Calculate validation loss using the current seg model
pred_masks_val = self.segmentation_model(val_images)
validation_loss = self.segmentation_loss(pred_masks_val, val_masks)
# Backpropagate this validation loss to update the architecture parameters.
# This backward pass implicitly computes the complex gradient in Eq. 8.
validation_loss.backward()
self.a_optimizer.step()
print(f"Epoch [{epoch+1}/{epochs}], D Loss: {d_loss.item():.4f}, G Loss: {g_loss.item():.4f}, S Loss: {s_loss.item():.4f}, Val Loss (for Arch): {validation_loss.item():.4f}")
if __name__ == '__main__':
config = {
'lr_g': 2e-4,
'lr_d': 2e-4,
'lr_s': 1e-4,
'lr_a': 3e-4, # Learning rate for architecture parameters
'lambda_l1': 100,
'gamma': 1.0,
'batch_size': 4,
'epochs': 50
}
if not torch.cuda.is_available():
print("CUDA not available. This model is intended to run on a GPU.")
else:
print("CUDA is available. Running on GPU.")
# Dummy Data
dummy_images = torch.randn(16, 3, 128, 128)
dummy_masks = torch.randint(0, 2, (16, 1, 128, 128)).float()
train_dataset = MedicalImageDataset(dummy_images, dummy_masks)
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=config['batch_size'], shuffle=True)
dummy_val_images = torch.randn(8, 3, 128, 128)
dummy_val_masks = torch.randint(0, 2, (8, 1, 128, 128)).float()
val_dataset = MedicalImageDataset(dummy_val_images, dummy_val_masks)
val_loader = torch.utils.data.DataLoader(val_dataset, batch_size=config['batch_size'], shuffle=False)
# Initialize models
generator = SearchableGenerator().cuda()
discriminator = Discriminator().cuda()
segmentation_model = UNet().cuda()
trainer = GenSegTrainer(generator, discriminator, segmentation_model, config)
print("Starting GenSeg training with searchable architecture...")
trainer.train(train_loader, val_loader, config['epochs'])
print("Training finished.")
References
- Chadebec, C. & Allassonnière, S. Data augmentation with variational autoencoders and manifold sampling. MICCAI Workshop on Deep Generative Models , 184–192 (Springer, 2021).
- Dai, Y. et al. Swin mae: masked autoencoders for small datasets. Comput. Biol. Med. 161, 107037 (2023).
- Kebaili, A. et al. Discriminative Hamiltonian variational autoencoder for accurate tumor segmentation. Neurocomputing 606, 128360 (2024).
- Li, B. et al. Bbdm: Image-to-image translation with Brownian bridge diffusion models. CVPR , 1952–1961 (IEEE/CVF, 2023).
- Xie, P. et al. GenSeg: End-to-end synthetic data generation for medical image segmentation. Nature Communications (2025).
I am not real good with English but I come up this rattling leisurely to read .
Excellent goods from you, man. I have understand your stuff previous to and you’re just too wonderful. I really like what you have acquired here, certainly like what you are saying and the way in which you say it. You make it enjoyable and you still care for to keep it wise. I cant wait to read much more from you. This is really a wonderful site.