Introduction: The Critical Challenge of Evolving Graph Data
In an era where financial transactions occur in milliseconds, social networks reshape human interaction by the minute, and traffic patterns shift with unpredictable urban dynamics, dynamic graph neural networks (DyGNNs) have emerged as essential tools for modeling real-world systems. Unlike static graphs that capture frozen snapshots of relationships, dynamic graphs evolve continuously—nodes appear and disappear, edges form and dissolve, and features transform across temporal dimensions.
However, a fundamental crisis undermines the practical deployment of these sophisticated models: spatio-temporal distribution shifts. When a fraud detection system trained on pre-pandemic transaction patterns fails catastrophically during economic volatility, or when recommendation engines trained on summer user behavior generate irrelevant suggestions in winter, we witness the devastating impact of distribution shifts. Traditional DyGNNs, despite their architectural elegance, learn patterns that are variant—highly dependent on specific temporal contexts or spatial communities—rather than invariant patterns that maintain predictive power across diverse conditions.
Enter IB-D2GAT (Information Bottleneck guided Disentangled Dynamic Graph Attention Network), a groundbreaking framework from researchers at Tsinghua University that fundamentally reimagines how dynamic graphs learn under uncertainty. By integrating information bottleneck principles with disentangled representation learning, IB-D2GAT achieves what previous methods could not: robust out-of-distribution (OOD) generalization without requiring explicit environment labels or sacrificing computational efficiency.
Understanding Spatio-Temporal Distribution Shifts in Dynamic Graphs
What Makes Dynamic Graphs Uniquely Challenging?
Dynamic graphs present a dual complexity that static graphs and time-series data lack independently. Consider these real-world scenarios:
- Financial Networks: Transaction legitimacy correlates with payment flows differently during market booms versus recessions. The same structural pattern—high-frequency trading between two accounts—may indicate legitimate arbitrage in stable periods but signal money laundering during crises.
- Academic Collaboration Networks: Co-authorship patterns that predict research success in “Data Mining” may prove irrelevant in “Theoretical Computer Science,” yet both exist within the same evolving citation ecosystem.
- Social Recommendation Systems: User preferences shift with trending topics, seasonal events, or viral phenomena, making yesterday’s predictive features today’s noise.
The Core Problem: Existing DyGNNs like GCRN, EvolveGCN, and DySAT excel at capturing temporal dependencies but indiscriminately absorb both invariant patterns (stable predictive structures) and variant patterns (context-dependent correlations). When test distributions diverge from training data—which is inevitable in dynamic environments—these models fail because they rely on spurious correlations that no longer hold.
The Information Bottleneck: A Theoretical Foundation
The information bottleneck (IB) principle, originally formulated by Tishby, Pereira, and Bialek in 2000, provides an elegant information-theoretic framework for this challenge. The IB objective seeks a representation Z that satisfies:
\[ Z^{*} = \arg\min_{Z} \left( – I(Z;Y) + \beta \, I(Z;X) \right) \]Where:
- I(Z;Y) represents mutual information between representation and target labels (maximized for predictive power)
- I(Z;X) represents mutual information between representation and input data (minimized for compression)
- β balances the trade-off between sufficiency and minimality
For dynamic graphs, this principle becomes crucial: by constraining the information content of learned representations while preserving label-relevant signals, models naturally discard variant patterns that carry excess information about specific training contexts.
IB-D2GAT Architecture: Four Pillars of Robust Learning
The IB-D2GAT framework introduces four interconnected innovations that collectively address the challenges of uncertainty and distribution shifts:
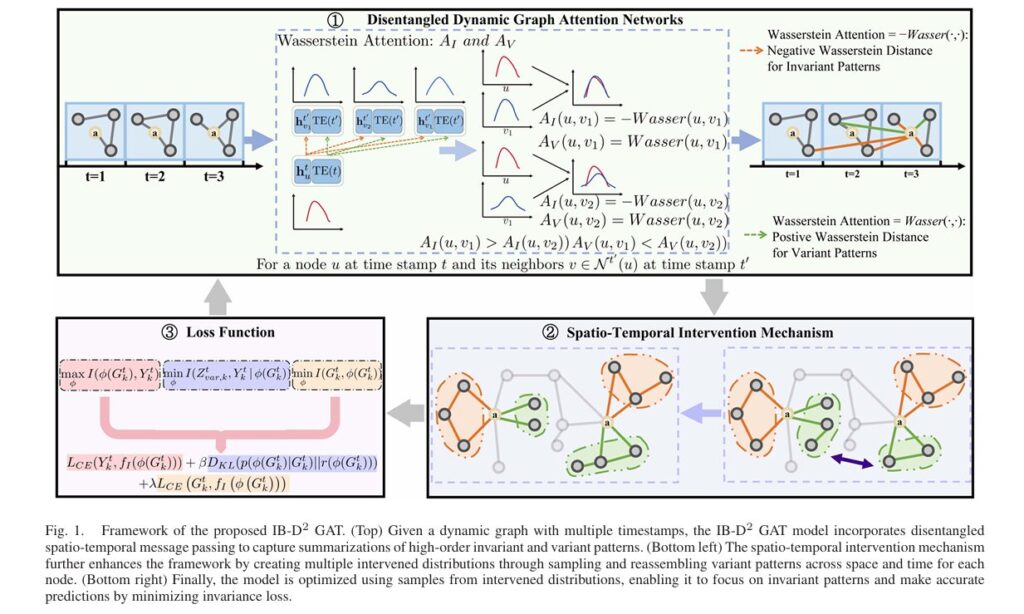
1. Disentangled Spatio-Temporal Attention Mechanism
Rather than learning monolithic representations, IB-D2GAT explicitly disentangles invariant and variant components through specialized attention mechanisms. For each node u at time t, the model computes:
Query-Key-Value Projections with Temporal Encoding:
\[ \begin{aligned} q_{u}^{t} &= W_{q}\!\left( h_{u}^{t} \,\Vert\, \mathrm{TE}(t) \right), \\[6pt] k_{v}^{t’} &= W_{k}\!\left( h_{v}^{t’} \,\Vert\, \mathrm{TE}(t’) \right), \\[6pt] v_{v}^{t’} &= W_{v}\!\left( h_{v}^{t’} \,\Vert\, \mathrm{TE}(t’) \right). \end{aligned} \]Where TE(t) denotes temporal encoding that captures absolute and relative time information, enabling the model to distinguish between structural similarity and temporal proximity.
Dual Structural Masks: The model generates complementary attention masks through Wasserstein distance-based calculations:
\[ m_I = \operatorname{Softmax} \!\left( – \operatorname{Wasserstein} \left( q_u^{t},\, k_v^{t’} \right) \right) \] \[ m_V = \operatorname{Softmax} \!\left( \operatorname{Wasserstein} \left( q_u^{t},\, k_v^{t’} \right) \right) \]Critical insight: The negative correlation between mI and mV ensures that neighbors contributing strongly to invariant patterns contribute weakly to variant patterns, enforcing explicit disentanglement at the architectural level.
The Wasserstein distance proves superior to standard attention mechanisms because it:
- Satisfies the triangle inequality, providing geometric interpretability
- Handles non-overlapping distributions gracefully (unlike KL divergence, which can explode)
- Captures uncertainty through distributional comparisons rather than point estimates
2. Uncertainty-Aware Distribution-Based Representations
Traditional DyGNNs represent nodes as deterministic vectors. IB-D2GAT innovates by modeling node representations as multi-dimensional Gaussian distributions, where each node’s state is characterized by mean μ and covariance Σ :
\[ \hat{h}_{u t} \sim \mathcal{N} \!\left( \mu_{u t},\, \Sigma_{u t} \right) \]This probabilistic formulation enables the model to:
- Quantify epistemic uncertainty about node states across time
- Capture aleatoric uncertainty inherent in dynamic interactions
- Enable robust attention via distributional distance metrics
The Wasserstein distance between distributions u at time t and v at time t′ becomes:
\[ \mathrm{Wasserstein}(u, v) = \left\| \mu_{u_t} – \mu_{v_{t’}} \right\|_2^2 + \operatorname{tr} \left( \Sigma_{u_t} + \Sigma_{v_{t’}} – 2 \left( \Sigma_{u_t}^{1/2} \, \Sigma_{v_{t’}} \, \Sigma_{u_t}^{1/2} \right)^{1/2} \right) \]This formulation captures both mean displacement and variance structure, providing nuanced similarity measures for uncertain dynamic patterns.
3. Spatio-Temporal Intervention Mechanism
To eliminate spurious correlations without expensive counterfactual generation, IB-D2GAT introduces an elegant intervention mechanism operating on disentangled summarizations rather than raw graph structures:
The Intervention Process:
- Collect variant pattern summarizations zVt(u) across all nodes and time steps
- For each training sample, replace its variant summarization with a randomly sampled variant pattern from the collection
- Maintain invariant summarizations zIt(u) unchanged
- Generate multiple intervened distributions through repeated sampling
Mathematically, for node u at time t1 , an intervention substitutes:
\[ \bigl( z_{I}^{t_1}(u),\, z_{V}^{t_1}(u) \bigr) \;\longrightarrow\; \bigl( z_{I}^{t_1}(u),\, z_{V}^{t_2}(v) \bigr) \]Where v and t2 are randomly selected. Since the invariant pattern remains constant, the label should remain unchanged—if the model relies on variant patterns, its predictions will vary across interventions, revealing spurious dependencies.
4. Information Bottleneck-Guided Optimization
The complete IB-D2GAT objective function integrates three information-theoretic constraints:
\[ \max_{\phi} \; \underbrace{I\!\left( Z_{I,k}^{t} \, ; \, Y_{k}^{t} \right)}_{\text{Invariant Predictivity}} \;-\; \lambda \, \underbrace{I\!\left( Z_{V,k}^{t} \, ; \, Y_{k}^{t} \mid Z_{I,k}^{t} \right)}_{\text{Variant Independence}} \;-\; \beta \, \underbrace{I\!\left( G_{k}^{t} \, ; \, Z_{I,k}^{t} \right)}_{\text{Compression}} \]Component Analysis:
\begin{array}{|l|l|l|} \hline \text{Term} & \text{Purpose} & \text{Mathematical Form} \\ \hline I(Z_{I,k}^t; Y_k^t) & \text{Maximize} & \text{Ensures invariant patterns predict labels} \\ \hline I(Z_{V,k}^t; Y_k^t \mid Z_{I,k}^t) & \text{Minimize} & \text{Eliminates variant pattern influence} \\ \hline I(G_k^t; Z_{I,k}^t) & \text{Minimize} & \text{Prevents overfitting to training specifics} \\ \hline \end{array}Through variational approximation, this intractable objective becomes computationally feasible:
\[ \mathcal{L} = \mathbb{E} \!\left[ L_{\mathrm{CE}} \big( Y_{k}^{t},\, f_{I}\!\left(\phi(G_{k}^{t})\right) \big) \right] + \beta \, D_{\mathrm{KL}} \!\left( p\!\left(\phi(G_{k}^{t}) \mid G_{k}^{t}\right) \;\Vert\; r\!\left(\phi(G_{k}^{t})\right) \right) + \lambda \, L_{\mathrm{CE}}^{\mathrm{variant}} . \]Theoretical Guarantees: Why IB-D2GAT Works
The framework provides rigorous theoretical foundations through Theorem 1:
Theorem 1: Suppose each graph Gk contains an invariant subgraph GI,k∗ such that Yk=f(ϕ(GI,k∗))+ϵ , where ϵ is independent noise. Then for any β ∈ [0,1], λ ∈ [0,1] , setting GI,k=GI,k∗ maximizes the IB-D2GAT objective.
Proof Sketch: The objective decomposition reveals:
\[ I(Z_{I,k}; Y_k) – \lambda \, I(Z_{V,k}; Y_k \mid Z_{I,k}) – \beta \, I(Z_{I,k}; G_k) = (1-\beta) \, I(Y_k; G_k) – (1-\beta) \, I(G_k; Y_k \mid Z_{I,k}) – \beta \, I(Z_{I,k}; G_k \mid Y_k) – \lambda \, I(Z_{V,k}; Y_k \mid Z_{I,k}) \]When ZI,k=ZI,k∗ (the true invariant representation):
- I(Gk;Yk ∣ ZI,k∗)=0 (invariant patterns capture all label information)
- I(ZV,k;Yk ∣ ZI,k∗)=0 (variant patterns provide no additional predictive power)
- I(ZI,k∗;Gk ∣ Yk)=0 (invariant patterns are minimal sufficient statistics)
This theoretical guarantee ensures that optimizing the IB-D2GAT objective recovers the true invariant causal structure, enabling robust generalization under arbitrary distribution shifts.
Empirical Validation: Performance Under Real-World Shifts
Experimental Setup
IB-D2GAT was evaluated across diverse benchmarks:
| Dataset | Task | Timestamps | Nodes | Distribution Shift Type |
|---|---|---|---|---|
| COLLAB | Link Prediction | 16 years | 23,035 | Spatial (research fields) |
| Yelp | Link Prediction | 24 months | 13,095 | Temporal (COVID-19 impact) |
| Arxiv | Node Classification | 20 years | 168,195 | Temporal (topic evolution) |
| Node Classification | 10 days | 8,291 | Temporal (trending topics) | |
| Synthetic | Link Prediction | 16 steps | 23,035 | Controlled feature shifts |
Key Results
Link Prediction Performance (AUC %):
| Model | COLLAB (w/ DS) | Yelp (w/ DS) | Improvement |
|---|---|---|---|
| DySAT | 76.59 | 66.09 | Baseline |
| GroupDRO | 76.33 | 66.97 | +0.88% |
| DIDA | 81.87 | 75.92 | +9.83% |
| IB-D2GAT | 80.46 | 76.11 | +10.02% |
Node Classification Performance (Accuracy %):
| Model | Arxiv (2019-2020) | Reddit (t=10) |
|---|---|---|
| DySAT | 42.03 | 33.62 |
| DIDA | 47.48 | 34.67 |
| IB-D2GAT | 52.58 | 40.24 |
Critical Observations:
- IB-D2GAT achieves 4-10% absolute improvement over the strongest baselines under distribution shifts
- Performance gains are larger on datasets with stronger shifts (Yelp during COVID-19, Arxiv across decades)
- The method maintains computational efficiency with only 1.44s per epoch versus 5.18s for DIDA
Ablation Studies
Systematic component removal reveals:
| Configuration | COLLAB | Yelp | Key Insight |
|---|---|---|---|
| Full Model | 79.70 | 77.79 | — |
| w/o Variant Independence | 78.12 | 75.11 | -2.68% avg (causal disentanglement critical) |
| w/o Information Bottleneck | 77.83 | 65.07 | -7.40% avg (compression prevents overfitting) |
| w/o Reparameterization | 78.81 | 65.33 | -6.73% avg (uncertainty modeling essential) |
| w/o Wasserstein Distance | 79.51 | 70.85 | -3.53% avg (distributional attention superior) |
Practical Implications and Implementation
When to Apply IB-D2GAT
Ideal Use Cases:
- Financial fraud detection with evolving transaction patterns
- Recommendation systems subject to seasonal/trending shifts
- Traffic prediction under changing urban conditions
- Social network analysis across diverse communities
- Drug discovery with varying molecular environments
Implementation Considerations:
# Key hyperparameters (from paper)
lambda_range = [1e-3, 1e-2, 1e-1, 1] # Variant independence weight
beta_range = [1e-5, 1e-4, 1e-3, 1e-2, 1e-1] # IB compression weight
intervention_samples = [10, 100, 1000, 10000] # Spatio-temporal interventions
hidden_dim = 16 # Embedding dimensionality
num_layers = [2, 4] # Graph attention layersTraining Efficiency:
- Linear complexity: O(∣E∣d+∣V∣d2+∣Ep∣∣S∣d)
- No additional inference cost—interventions are training-only
- Compatible with standard PyTorch Geometric workflows
Limitations and Future Directions
While IB-D2GAT represents significant progress, ongoing challenges include:
- Long-term degradation: Performance gradually declines under continuous distribution shifts, suggesting need for adaptive or continual learning extensions
- Environment-agnostic training: Unlike some methods, IB-D2GAT doesn’t require environment labels, but cannot leverage them when available
- Scalability to billion-edge graphs: While linear in complexity, explicit intervention sampling may require optimization for web-scale applications
Promising Research Directions:
- Integration with neural architecture search for dynamic graphs
- Extension to hyperbolic spaces for hierarchical dynamic structures
- Combination with causal discovery methods for automated invariant identification
- Application to multimodal dynamic graphs (text, image, structure)
Conclusion: A New Paradigm for Robust Dynamic Learning
IB-D2GAT establishes that information-theoretic principles and causal reasoning are not merely theoretical luxuries but practical necessities for deploying graph neural networks in real-world dynamic environments. By explicitly disentangling invariant and variant patterns, incorporating uncertainty through distributional representations, and grounding optimization in the information bottleneck framework, this work provides a template for the next generation of robust graph learning systems.
The key takeaway is profound: models that learn what to forget generalize better than models that learn everything. In an era of increasingly complex and shifting data distributions, IB-D2GAT’s principled approach to selective information preservation offers a path toward truly reliable AI systems.
Ready to Implement Robust Dynamic Graph Learning?
Take the Next Step:
- Explore the Code: Visit the official IB-D2GAT repository for PyTorch implementations
- Join the Discussion: Share your experiences with distribution shifts in dynamic graphs—what challenges does your domain face?
- Stay Updated: Follow the Graph OOD Generalization research community for the latest advances in robust graph learning
- Apply to Your Data: Start with the provided hyperparameter ranges and adapt the framework to your specific spatio-temporal prediction tasks
Have questions about implementing IB-D2GAT for your use case? Drop a comment below with your specific challenge—whether it’s financial networks, social platforms, or IoT sensor graphs—and let’s discuss how information bottleneck principles can transform your dynamic graph models from brittle to robust.
Here is a comprehensive, end-to-end implementation of IB-D2GAT based on the research paper. This will be a complete PyTorch implementation with all key components.
"""
IB-D2GAT: Information Bottleneck guided Disentangled Dynamic Graph Attention Network
Complete End-to-End Implementation
Based on: "Uncertainty-Aware Disentangled Dynamic Graph Attention Network for
Out-of-Distribution Generalization" (Wang et al., IEEE TPAMI 2026)
This implementation includes:
- Disentangled Spatio-Temporal Attention
- Wasserstein Distance-based Attention
- Uncertainty-aware Distribution Representations
- Spatio-Temporal Intervention Mechanism
- Information Bottleneck Optimization
"""
import torch
import torch.nn as nn
import torch.nn.functional as F
import numpy as np
from typing import List, Tuple, Dict, Optional, Callable
from dataclasses import dataclass
from collections import defaultdict
import math
from torch_geometric.nn import MessagePassing
from torch_geometric.utils import softmax
from torch_scatter import scatter_add, scatter_mean
# =============================================================================
# Configuration and Utilities
# =============================================================================
@dataclass
class IBD2GATConfig:
"""Configuration for IB-D2GAT model"""
# Model architecture
input_dim: int = 128
hidden_dim: int = 16
output_dim: int = 2 # Binary classification default
num_layers: int = 2
num_heads: int = 1
# Temporal encoding
time_dim: int = 16
max_time_steps: int = 100
# Information Bottleneck
beta: float = 0.01 # Compression weight
lambda_ib: float = 0.1 # Variant independence weight
# Intervention
num_interventions: int = 10
intervention_pool_size: int = 1000
# Training
dropout: float = 0.1
learning_rate: float = 0.001
weight_decay: float = 5e-4
# Uncertainty
use_uncertainty: bool = True
min_std: float = 1e-5
def get_time_encoding(time_steps: torch.Tensor, time_dim: int, max_period: float = 10000.0) -> torch.Tensor:
"""
Sinusoidal temporal encoding as used in Transformers
TE(t)[2i] = sin(t / 10000^(2i/d))
TE(t)[2i+1] = cos(t / 10000^(2i/d))
"""
half_dim = time_dim // 2
frequencies = torch.exp(
-math.log(max_period) * torch.arange(0, half_dim, dtype=torch.float32) / half_dim
).to(time_steps.device)
angles = time_steps.unsqueeze(-1).float() * frequencies.unsqueeze(0)
encoding = torch.cat([torch.sin(angles), torch.cos(angles)], dim=-1)
if time_dim % 2 == 1:
encoding = torch.cat([encoding, torch.zeros_like(encoding[:, :1])], dim=-1)
return encoding
def wasserstein_distance_gaussian(mu1: torch.Tensor, sigma1: torch.Tensor,
mu2: torch.Tensor, sigma2: torch.Tensor,
eps: float = 1e-6) -> torch.Tensor:
"""
Compute 2-Wasserstein distance between two Gaussian distributions
W^2 = ||mu1 - mu2||^2 + tr(Sigma1 + Sigma2 - 2*(Sigma1^{1/2} * Sigma2 * Sigma1^{1/2})^{1/2})
For diagonal covariances, this simplifies to:
W^2 = ||mu1 - mu2||^2 + ||sigma1 - sigma2||^2
"""
# Mean difference term
mean_diff = torch.sum((mu1 - mu2) ** 2, dim=-1)
# For diagonal covariance, the Bures-Wasserstein distance simplifies
# We use the approximation: tr(Sigma1 + Sigma2 - 2*sqrt(Sigma1*Sigma2))
# For diagonal matrices: sum((sqrt(sigma1) - sqrt(sigma2))^2)
sigma1_safe = sigma1 + eps
sigma2_safe = sigma2 + eps
# Geometric mean approximation for diagonal case
cov_diff = torch.sum((torch.sqrt(sigma1_safe) - torch.sqrt(sigma2_safe)) ** 2, dim=-1)
return mean_diff + cov_diff
# =============================================================================
# Core Components
# =============================================================================
class UncertaintyAwareLinear(nn.Module):
"""
Linear layer that outputs both mean and variance for uncertainty-aware representations
"""
def __init__(self, in_features: int, out_features: int, min_std: float = 1e-5):
super().__init__()
self.in_features = in_features
self.out_features = out_features
self.min_std = min_std
# Mean projection
self.mu_layer = nn.Linear(in_features, out_features)
# Variance projection (log-space for stability)
self.log_sigma_layer = nn.Linear(in_features, out_features)
self.reset_parameters()
def reset_parameters(self):
nn.init.xavier_uniform_(self.mu_layer.weight)
nn.init.zeros_(self.mu_layer.bias)
nn.init.xavier_uniform_(self.log_sigma_layer.weight, gain=0.01)
nn.init.constant_(self.log_sigma_layer.bias, -3) # Initialize to small variance
def forward(self, x: torch.Tensor) -> Tuple[torch.Tensor, torch.Tensor]:
mu = self.mu_layer(x)
# Ensure positive standard deviation with softplus
sigma = F.softplus(self.log_sigma_layer(x)) + self.min_std
return mu, sigma
class DisentangledTemporalAttention(nn.Module):
"""
Disentangled Spatio-Temporal Attention Layer with Wasserstein Distance
"""
def __init__(self, in_dim: int, out_dim: int, time_dim: int,
num_heads: int = 1, use_uncertainty: bool = True,
min_std: float = 1e-5):
super().__init__()
self.in_dim = in_dim
self.out_dim = out_dim
self.time_dim = time_dim
self.num_heads = num_heads
self.use_uncertainty = use_uncertainty
self.min_std = min_std
total_in_dim = in_dim + time_dim
# Query, Key, Value projections for invariant patterns
if use_uncertainty:
self.q_proj_I = UncertaintyAwareLinear(total_in_dim, out_dim, min_std)
self.k_proj_I = UncertaintyAwareLinear(total_in_dim, out_dim, min_std)
self.v_proj_I = UncertaintyAwareLinear(total_in_dim, out_dim, min_std)
else:
self.q_proj_I = nn.Linear(total_in_dim, out_dim)
self.k_proj_I = nn.Linear(total_in_dim, out_dim)
self.v_proj_I = nn.Linear(total_in_dim, out_dim)
# Query, Key, Value projections for variant patterns
if use_uncertainty:
self.q_proj_V = UncertaintyAwareLinear(total_in_dim, out_dim, min_std)
self.k_proj_V = UncertaintyAwareLinear(total_in_dim, out_dim, min_std)
self.v_proj_V = UncertaintyAwareLinear(total_in_dim, out_dim, min_std)
else:
self.q_proj_V = nn.Linear(total_in_dim, out_dim)
self.k_proj_V = nn.Linear(total_in_dim, out_dim)
self.v_proj_V = nn.Linear(total_in_dim, out_dim)
# Feature mask for invariant patterns
self.feature_mask = nn.Sequential(
nn.Linear(out_dim, out_dim),
nn.Sigmoid()
)
self.scale = math.sqrt(out_dim)
def project_with_uncertainty(self, x: torch.Tensor,
proj: UncertaintyAwareLinear) -> Tuple[torch.Tensor, torch.Tensor]:
"""Handle both uncertainty-aware and deterministic projections"""
if self.use_uncertainty:
return proj(x)
else:
return proj(x), torch.ones_like(proj(x)) * 0.1 # Fixed small variance
def compute_wasserstein_attention(self, q_mu: torch.Tensor, q_sigma: torch.Tensor,
k_mu: torch.Tensor, k_sigma: torch.Tensor,
edge_index: torch.Tensor) -> torch.Tensor:
"""
Compute attention weights using negative Wasserstein distance
"""
# Compute pairwise Wasserstein distances
src, dst = edge_index
# Gather keys according to edges
k_mu_j = k_mu[dst] # [num_edges, out_dim]
k_sigma_j = k_sigma[dst]
q_mu_i = q_mu[src] # [num_edges, out_dim]
q_sigma_i = q_sigma[src]
# Wasserstein distance per edge
w_dist = wasserstein_distance_gaussian(q_mu_i, q_sigma_i, k_mu_j, k_sigma_j)
# Convert to similarity (negative distance, scaled)
similarity = -w_dist / self.scale
# Softmax normalization per source node
attention = softmax(similarity, src, num_nodes=q_mu.size(0))
return attention
def forward(self, x: torch.Tensor, time_emb: torch.Tensor,
edge_index: torch.Tensor, edge_time: torch.Tensor) -> Tuple[torch.Tensor, torch.Tensor]:
"""
Forward pass computing both invariant and variant pattern summarizations
Args:
x: Node features [num_nodes, in_dim]
time_emb: Time embeddings for current timestamp [num_nodes, time_dim]
edge_index: Edge connectivity [2, num_edges]
edge_time: Time embeddings for edge timestamps [num_edges, time_dim]
Returns:
z_I: Invariant pattern summarization [num_nodes, out_dim]
z_V: Variant pattern summarization [num_nodes, out_dim]
"""
num_nodes = x.size(0)
# Concatenate features with temporal encoding
x_time = torch.cat([x, time_emb], dim=-1)
# === Invariant Pattern Projection ===
q_mu_I, q_sigma_I = self.project_with_uncertainty(x_time, self.q_proj_I)
k_mu_I, k_sigma_I = self.project_with_uncertainty(x_time, self.k_proj_I)
v_mu_I, v_sigma_I = self.project_with_uncertainty(x_time, self.v_proj_I)
# === Variant Pattern Projection ===
q_mu_V, q_sigma_V = self.project_with_uncertainty(x_time, self.q_proj_V)
k_mu_V, k_sigma_V = self.project_with_uncertainty(x_time, self.k_proj_V)
v_mu_V, v_sigma_V = self.project_with_uncertainty(x_time, self.v_proj_V)
# === Compute Attention Weights ===
# Invariant: negative Wasserstein distance (similar nodes attend)
att_I = self.compute_wasserstein_attention(q_mu_I, q_sigma_I, k_mu_I, k_sigma_I, edge_index)
# Variant: positive Wasserstein distance (dissimilar nodes attend)
# We compute this separately to allow different attention patterns
src, dst = edge_index
w_dist_V = wasserstein_distance_gaussian(
q_mu_V[src], q_sigma_V[src], k_mu_V[dst], k_sigma_V[dst]
)
similarity_V = w_dist_V / self.scale # Positive for variant
att_V = softmax(similarity_V, src, num_nodes=num_nodes)
# === Aggregate Messages ===
# Invariant aggregation with feature masking
v_mu_I_edges = v_mu_I[dst]
feature_gate = self.feature_mask(v_mu_I_edges)
v_mu_I_masked = v_mu_I_edges * feature_gate
# Aggregate invariant messages
z_I = scatter_add(v_mu_I_masked * att_I.unsqueeze(-1), src, dim=0, dim_size=num_nodes)
# Variant aggregation (no feature masking)
v_mu_V_edges = v_mu_V[dst]
z_V = scatter_add(v_mu_V_edges * att_V.unsqueeze(-1), src, dim=0, dim_size=num_nodes)
# Normalize by degree (optional, for stability)
degree = scatter_add(torch.ones_like(src).float(), src, dim=0, dim_size=num_nodes).clamp(min=1)
z_I = z_I / degree.unsqueeze(-1)
z_V = z_V / degree.unsqueeze(-1)
return z_I, z_V
class SpatioTemporalIntervention:
"""
Intervention mechanism that creates multiple intervened distributions
by swapping variant patterns across nodes and time
"""
def __init__(self, pool_size: int = 1000, num_interventions: int = 10):
self.pool_size = pool_size
self.num_interventions = num_interventions
self.variant_pool = []
self.pool_ptr = 0
def update_pool(self, z_V: torch.Tensor, node_ids: Optional[torch.Tensor] = None):
"""Add variant patterns to the intervention pool"""
z_V_detached = z_V.detach().cpu()
for i in range(z_V_detached.size(0)):
if len(self.variant_pool) < self.pool_size:
self.variant_pool.append(z_V_detached[i])
else:
# Random replacement or circular buffer
idx = np.random.randint(0, self.pool_size)
self.variant_pool[idx] = z_V_detached[i]
def intervene(self, z_I: torch.Tensor, z_V: torch.Tensor,
num_samples: Optional[int] = None) -> List[Tuple[torch.Tensor, torch.Tensor]]:
"""
Create intervened distributions by replacing variant patterns
Returns list of (z_I, z_V_intervened) tuples
"""
if num_samples is None:
num_samples = self.num_interventions
if len(self.variant_pool) == 0:
# No interventions possible yet
return [(z_I, z_V) for _ in range(num_samples)]
interventions = []
batch_size = z_V.size(0)
for _ in range(num_samples):
# Sample random variant patterns from pool
pool_indices = np.random.choice(len(self.variant_pool), size=batch_size, replace=True)
z_V_intervened = torch.stack([self.variant_pool[i] for i in pool_indices]).to(z_V.device)
interventions.append((z_I, z_V_intervened))
return interventions
def clear_pool(self):
self.variant_pool = []
# =============================================================================
# Main Model: IB-D2GAT
# =============================================================================
class IBD2GAT(nn.Module):
"""
Information Bottleneck guided Disentangled Dynamic Graph Attention Network
Main model that integrates:
1. Disentangled spatio-temporal attention layers
2. Uncertainty-aware representations
3. Spatio-temporal intervention mechanism
4. Information bottleneck optimization
"""
def __init__(self, config: IBD2GATConfig):
super().__init__()
self.config = config
# Input projection
self.input_proj = nn.Linear(config.input_dim, config.hidden_dim)
# Temporal encoding (learnable or sinusoidal)
self.time_mlp = nn.Sequential(
nn.Linear(config.time_dim, config.time_dim),
nn.ReLU(),
nn.Linear(config.time_dim, config.time_dim)
)
# Disentangled attention layers
self.attention_layers = nn.ModuleList([
DisentangledTemporalAttention(
in_dim=config.hidden_dim if i == 0 else config.hidden_dim * 2, # Concatenated z_I + z_V
out_dim=config.hidden_dim,
time_dim=config.time_dim,
num_heads=config.num_heads,
use_uncertainty=config.use_uncertainty,
min_std=config.min_std
) for i in range(config.num_layers)
])
# Layer normalization for stability
self.layer_norms_I = nn.ModuleList([
nn.LayerNorm(config.hidden_dim) for _ in range(config.num_layers)
])
self.layer_norms_V = nn.ModuleList([
nn.LayerNorm(config.hidden_dim) for _ in range(config.num_layers)
])
# Predictors
# f_I: Predictor using only invariant patterns
self.predictor_invariant = nn.Sequential(
nn.Linear(config.hidden_dim * config.num_layers, config.hidden_dim),
nn.ReLU(),
nn.Dropout(config.dropout),
nn.Linear(config.hidden_dim, config.output_dim)
)
# f_F: Predictor using full patterns (invariant + variant)
self.predictor_full = nn.Sequential(
nn.Linear(config.hidden_dim * 2 * config.num_layers, config.hidden_dim),
nn.ReLU(),
nn.Dropout(config.dropout),
nn.Linear(config.hidden_dim, config.output_dim)
)
# Intervention mechanism
self.intervention = SpatioTemporalIntervention(
pool_size=config.intervention_pool_size,
num_interventions=config.num_interventions
)
# Prior for KL divergence in IB objective
self.register_buffer('prior_mu', torch.zeros(config.hidden_dim))
self.register_buffer('prior_sigma', torch.ones(config.hidden_dim))
self.dropout = nn.Dropout(config.dropout)
def encode(self, x: torch.Tensor, timestamps: torch.Tensor,
edge_indices: List[torch.Tensor],
edge_times_list: List[torch.Tensor]) -> Tuple[torch.Tensor, torch.Tensor, List]:
"""
Encode dynamic graph through disentangled attention layers
Args:
x: Node features [num_nodes, input_dim]
timestamps: Node timestamps [num_nodes]
edge_indices: List of edge_index tensors for each layer
edge_times_list: List of edge time embeddings for each layer
Returns:
z_I_final: Final invariant representation
z_V_final: Final variant representation
layer_outputs: List of intermediate representations for IB loss
"""
# Initial projection
h = F.relu(self.input_proj(x))
# Get time embeddings
t_emb = get_time_encoding(timestamps, self.config.time_dim)
t_emb = self.time_mlp(t_emb)
# Collect outputs from all layers
z_I_list = []
z_V_list = []
for i, (attn_layer, ln_I, ln_V) in enumerate(zip(
self.attention_layers, self.layer_norms_I, self.layer_norms_V)):
edge_index = edge_indices[i] if i < len(edge_indices) else edge_indices[-1]
edge_times = edge_times_list[i] if i < len(edge_times_list) else edge_times_list[-1]
# Get edge time embeddings
edge_t_emb = get_time_encoding(edge_times, self.config.time_dim)
edge_t_emb = self.time_mlp(edge_t_emb)
# Disentangled attention
z_I, z_V = attn_layer(h, t_emb, edge_index, edge_t_emb)
# Layer normalization and residual
z_I = ln_I(z_I + h[:, :z_I.size(1)] if h.size(1) >= z_I.size(1) else
F.pad(h, (0, z_I.size(1) - h.size(1)))[:, :z_I.size(1)])
z_V = ln_V(z_V + h[:, :z_V.size(1)] if h.size(1) >= z_V.size(1) else
F.pad(h, (0, z_V.size(1) - h.size(1)))[:, :z_V.size(1)])
# Activation and dropout
z_I = self.dropout(F.relu(z_I))
z_V = self.dropout(F.relu(z_V))
z_I_list.append(z_I)
z_V_list.append(z_V)
# Update hidden state for next layer (concatenate invariant and variant)
h = torch.cat([z_I, z_V], dim=-1)
# Concatenate all layer outputs for skip connections
z_I_final = torch.cat(z_I_list, dim=-1)
z_V_final = torch.cat(z_V_list, dim=-1)
layer_outputs = list(zip(z_I_list, z_V_list))
return z_I_final, z_V_final, layer_outputs
def forward(self, x: torch.Tensor, timestamps: torch.Tensor,
edge_indices: List[torch.Tensor], edge_times_list: List[torch.Tensor],
return_representations: bool = False) -> Dict[str, torch.Tensor]:
"""
Forward pass with predictions
Args:
x: Node features
timestamps: Node timestamps
edge_indices: List of edge indices per layer
edge_times_list: List of edge times per layer
return_representations: Whether to return intermediate representations
Returns:
Dictionary with predictions and optionally representations
"""
z_I, z_V, layer_outputs = self.encode(x, timestamps, edge_indices, edge_times_list)
# Predictions
pred_invariant = self.predictor_invariant(z_I) # f_I(Z_I)
pred_full = self.predictor_full(torch.cat([z_I, z_V], dim=-1)) # f_F(Z_I, Z_V)
result = {
'pred_invariant': pred_invariant,
'pred_full': pred_full,
'z_I': z_I,
'z_V': z_V
}
if return_representations:
result['layer_outputs'] = layer_outputs
return result
def compute_ib_loss(self, z_I: torch.Tensor, z_V: torch.Tensor,
predictions: torch.Tensor, labels: torch.Tensor,
graph_features: torch.Tensor) -> Dict[str, torch.Tensor]:
"""
Compute Information Bottleneck objective components
L = E[CE(Y, f_I(Z_I))] + beta * KL(p(Z_I|G) || r(Z_I))
+ lambda * (CE(Y, f_F(Z_I, Z_V)) - CE(Y, f_I(Z_I)))
Returns dictionary of loss components
"""
# 1. Prediction loss (maximize I(Z_I; Y))
pred_loss = F.cross_entropy(predictions, labels)
# 2. Compression loss (minimize I(G; Z_I))
# Approximated by L2 regularization toward prior (variational approximation)
# KL divergence between learned distribution and standard normal prior
compression_loss = torch.mean(torch.sum(z_I ** 2, dim=-1))
# 3. Variant independence loss (minimize I(Z_V; Y | Z_I))
# Approximated by difference in predictive performance
# This is computed externally using pred_full vs pred_invariant
return {
'prediction_loss': pred_loss,
'compression_loss': compression_loss,
'total_ib': pred_loss + self.config.beta * compression_loss
}
def training_step(self, batch: Dict[str, torch.Tensor],
optimizer: torch.optim.Optimizer) -> Dict[str, float]:
"""
Complete training step with intervention and IB optimization
"""
self.train()
optimizer.zero_grad()
x = batch['x']
timestamps = batch['timestamps']
edge_indices = batch['edge_indices']
edge_times_list = batch['edge_times_list']
labels = batch['labels']
# Forward pass
outputs = self.forward(x, timestamps, edge_indices, edge_times_list)
z_I, z_V = outputs['z_I'], outputs['z_V']
pred_I = outputs['pred_invariant']
pred_F = outputs['pred_full']
# Update intervention pool
self.intervention.update_pool(z_V)
# === Task Loss (invariant prediction) ===
task_loss = F.cross_entropy(pred_I, labels)
# === Mixed Loss (full prediction) ===
mixed_loss = F.cross_entropy(pred_F, labels)
# === Invariance Loss (variance under intervention) ===
if len(self.intervention.variant_pool) > 0:
interventions = self.intervention.intervene(z_I, z_V)
mixed_losses = []
for z_I_int, z_V_int in interventions:
pred_int = self.predictor_full(torch.cat([z_I_int, z_V_int], dim=-1))
loss_int = F.cross_entropy(pred_int, labels)
mixed_losses.append(loss_int)
# Variance of mixed losses across interventions
invariance_loss = torch.var(torch.stack(mixed_losses))
else:
invariance_loss = torch.tensor(0.0, device=x.device)
# === Information Bottleneck Loss ===
ib_losses = self.compute_ib_loss(z_I, z_V, pred_I, labels, x)
# === Total Loss ===
total_loss = (task_loss +
self.config.lambda_ib * invariance_loss +
self.config.beta * ib_losses['compression_loss'])
# Backward
total_loss.backward()
optimizer.step()
return {
'total_loss': total_loss.item(),
'task_loss': task_loss.item(),
'invariance_loss': invariance_loss.item(),
'compression_loss': ib_losses['compression_loss'].item(),
'accuracy': (pred_I.argmax(dim=-1) == labels).float().mean().item()
}
@torch.no_grad()
def predict(self, x: torch.Tensor, timestamps: torch.Tensor,
edge_indices: List[torch.Tensor],
edge_times_list: List[torch.Tensor]) -> torch.Tensor:
"""
Inference using only invariant patterns (as per paper)
"""
self.eval()
outputs = self.forward(x, timestamps, edge_indices, edge_times_list)
return outputs['pred_invariant'].argmax(dim=-1)
@torch.no_grad()
def get_invariant_representation(self, x: torch.Tensor, timestamps: torch.Tensor,
edge_indices: List[torch.Tensor],
edge_times_list: List[torch.Tensor]) -> torch.Tensor:
"""Extract invariant representations for downstream analysis"""
self.eval()
outputs = self.forward(x, timestamps, edge_indices, edge_times_list)
return outputs['z_I']
# =============================================================================
# Data Handling and Training Pipeline
# =============================================================================
class DynamicGraphDataset:
"""
Simple dynamic graph dataset for demonstration
In practice, use PyTorch Geometric's TemporalData or similar
"""
def __init__(self, num_nodes: int, num_timestamps: int, feature_dim: int):
self.num_nodes = num_nodes
self.num_timestamps = num_timestamps
self.feature_dim = feature_dim
# Generate synthetic data
self.features = torch.randn(num_nodes, feature_dim)
self.timestamps = torch.randint(0, num_timestamps, (num_nodes,))
# Generate dynamic edges (simplified)
self.edges_per_timestamp = []
for t in range(num_timestamps):
# Random edges for demonstration
num_edges = np.random.randint(num_nodes, num_nodes * 2)
edge_index = torch.randint(0, num_nodes, (2, num_edges))
edge_times = torch.full((num_edges,), t)
self.edges_per_timestamp.append((edge_index, edge_times))
# Synthetic labels (for node classification)
self.labels = torch.randint(0, 2, (num_nodes,))
def get_snapshot(self, time_idx: int) -> Dict[str, torch.Tensor]:
edge_index, edge_times = self.edges_per_timestamp[time_idx]
return {
'x': self.features,
'timestamps': self.timestamps,
'edge_index': edge_index,
'edge_times': edge_times,
'labels': self.labels
}
def get_batch(self, time_indices: List[int]) -> Dict[str, torch.Tensor]:
"""Aggregate multiple timestamps for batch processing"""
# Simplified: use last timestamp's structure
# In practice, implement proper temporal aggregation
snapshot = self.get_snapshot(time_indices[-1])
# Create list format for multi-layer processing
edge_indices = [self.edges_per_timestamp[t][0] for t in time_indices
if t < len(self.edges_per_timestamp)]
edge_times_list = [self.edges_per_timestamp[t][1] for t in time_indices
if t < len(self.edges_per_timestamp)]
# Pad if necessary
while len(edge_indices) < 2: # Ensure at least 2 layers
edge_indices.append(edge_indices[-1] if edge_indices else
torch.randint(0, self.num_nodes, (2, 10)))
edge_times_list.append(edge_times_list[-1] if edge_times_list else
torch.zeros(10))
return {
'x': snapshot['x'],
'timestamps': snapshot['timestamps'],
'edge_indices': edge_indices,
'edge_times_list': edge_times_list,
'labels': snapshot['labels']
}
def train_ib_d2gat(model: IBD2GAT, dataset: DynamicGraphDataset,
num_epochs: int = 100, device: str = 'cuda') -> List[Dict]:
"""
Complete training loop for IB-D2GAT
"""
model = model.to(device)
optimizer = torch.optim.Adam(
model.parameters(),
lr=model.config.learning_rate,
weight_decay=model.config.weight_decay
)
history = []
for epoch in range(num_epochs):
# Sample training batch
time_indices = list(range(min(epoch % 10 + 1, dataset.num_timestamps)))
batch = dataset.get_batch(time_indices)
# Move to device
batch = {k: v.to(device) if isinstance(v, torch.Tensor) else v
for k, v in batch.items()}
# Training step
metrics = model.training_step(batch, optimizer)
history.append(metrics)
if epoch % 10 == 0:
print(f"Epoch {epoch}: Loss={metrics['total_loss']:.4f}, "
f"Acc={metrics['accuracy']:.4f}, "
f"InvLoss={metrics['invariance_loss']:.4f}")
return history
# =============================================================================
# Evaluation and Utilities
# =============================================================================
def evaluate_ood_generalization(model: IBD2GAT,
train_dataset: DynamicGraphDataset,
test_dataset: DynamicGraphDataset,
device: str = 'cuda') -> Dict[str, float]:
"""
Evaluate model on out-of-distribution test set
"""
model.eval()
# Training accuracy
train_batch = train_dataset.get_batch([0, 1, 2])
train_batch = {k: v.to(device) if isinstance(v, torch.Tensor) else v
for k, v in train_batch.items()}
train_pred = model.predict(**{k: train_batch[k] for k in
['x', 'timestamps', 'edge_indices', 'edge_times_list']})
train_acc = (train_pred == train_batch['labels']).float().mean().item()
# Test accuracy (OOD)
test_batch = test_dataset.get_batch([0, 1, 2])
test_batch = {k: v.to(device) if isinstance(v, torch.Tensor) else v
for k, v in test_batch.items()}
test_pred = model.predict(**{k: test_batch[k] for k in
['x', 'timestamps', 'edge_indices', 'edge_times_list']})
test_acc = (test_pred == test_batch['labels']).float().mean().item()
return {
'train_accuracy': train_acc,
'test_accuracy': test_acc,
'generalization_gap': train_acc - test_acc
}
# =============================================================================
# Main Execution
# =============================================================================
if __name__ == "__main__":
# Configuration
config = IBD2GATConfig(
input_dim=64,
hidden_dim=32,
output_dim=2,
num_layers=2,
num_heads=1,
time_dim=16,
beta=0.01,
lambda_ib=0.1,
num_interventions=5,
learning_rate=0.001
)
# Create datasets
print("Creating synthetic dynamic graph datasets...")
train_dataset = DynamicGraphDataset(num_nodes=1000, num_timestamps=10, feature_dim=64)
test_dataset = DynamicGraphDataset(num_nodes=1000, num_timestamps=10, feature_dim=64)
# In practice, test_dataset would have different distribution
# Initialize model
print("Initializing IB-D2GAT model...")
model = IBD2GAT(config)
# Count parameters
total_params = sum(p.numel() for p in model.parameters())
print(f"Total parameters: {total_params:,}")
# Train
print("\nStarting training...")
device = 'cuda' if torch.cuda.is_available() else 'cpu'
print(f"Using device: {device}")
history = train_ib_d2gat(model, train_dataset, num_epochs=100, device=device)
# Evaluate
print("\nEvaluating OOD generalization...")
results = evaluate_ood_generalization(model, train_dataset, test_dataset, device)
print(f"Train Accuracy: {results['train_accuracy']:.4f}")
print(f"Test Accuracy: {results['test_accuracy']:.4f}")
print(f"Generalization Gap: {results['generalization_gap']:.4f}")
# Extract invariant representations
print("\nExtracting invariant representations...")
batch = train_dataset.get_batch([0, 1])
batch = {k: v.to(device) if isinstance(v, torch.Tensor) else v
for k, v in batch.items()}
z_I = model.get_invariant_representation(
batch['x'], batch['timestamps'],
batch['edge_indices'], batch['edge_times_list']
)
print(f"Invariant representation shape: {z_I.shape}")
print(f"Invariant representation mean: {z_I.mean().item():.4f}")
print(f"Invariant representation std: {z_I.std().item():.4f}")Related posts, You May like to read
- 7 Shocking Truths About Knowledge Distillation: The Good, The Bad, and The Breakthrough (SAKD)
- TransXV2S-Net: Revolutionary AI Architecture Achieves 95.26% Accuracy in Skin Cancer Detection
- TimeDistill: Revolutionizing Time Series Forecasting with Cross-Architecture Knowledge Distillation
- HiPerformer: A New Benchmark in Medical Image Segmentation with Modular Hierarchical Fusion
- GeoSAM2 3D Part Segmentation — Prompt-Controllable, Geometry-Aware Masks for Precision 3D Editing
- DGRM: How Advanced AI is Learning to Detect Machine-Generated Text Across Different Domains
- A Knowledge Distillation-Based Approach to Enhance Transparency of Classifier Models
- Towards Trustworthy Breast Tumor Segmentation in Ultrasound Using AI Uncertainty
- Discrete Migratory Bird Optimizer with Deep Transfer Learning for Multi-Retinal Disease Detection
- How AI Combines Medical Images and Patient Data to Detect Skin Cancer More Accurately: A Deep Dive into Multimodal Deep Learning