Introduction
In the world of deep learning, especially in computer vision, knowledge distillation (KD) has been a go-to method to compress large models and improve performance. But the classic approach heavily relies on teacher-student architectures, which come with high memory, computational costs, and training complexity.
The new research paper “Intra-class Patch Swap for Self-Distillation” proposes a teacher-free distillation method that disrupts these norms. With just a single student model and a clever augmentation strategy, it delivers surprisingly powerful results—without needing any teacher networks.
Let’s dive into the 7 surprising strengths and limitations of this breakthrough technique, and what it means for the future of AI model training.
1. ✅ Goodbye, Teachers: A True Self-Distillation Revolution
Most knowledge distillation methods depend on pre-trained teacher models to guide student networks. But these teachers are:
- Expensive to train
- Hard to choose
- Storage-heavy
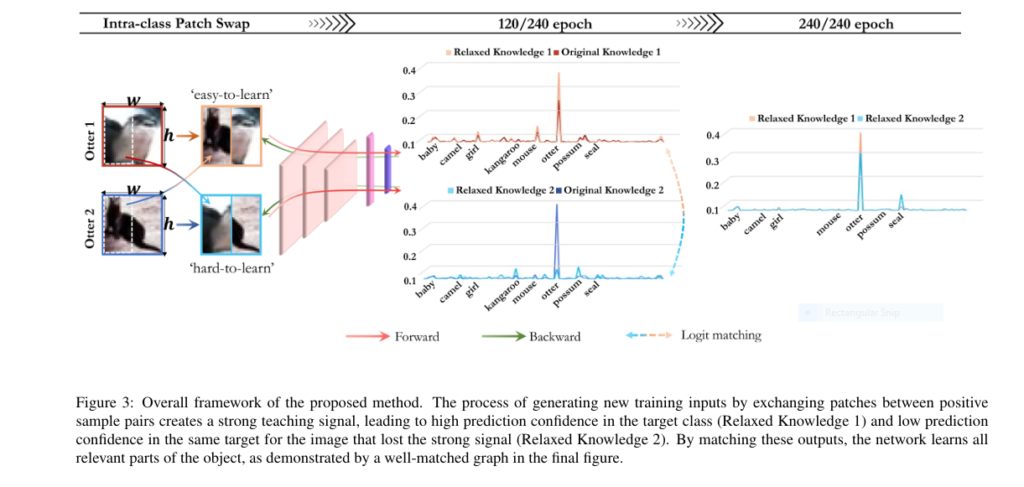
The proposed Intra-class Patch Swap (IPS) eliminates the need for teachers. Instead, it uses patch-level data augmentation between samples of the same class to simulate a teacher-student interaction—within the same model.
Keywords: self-distillation without teacher, teacher-free knowledge distillation
2. 🔄 Patch Swap Magic: Simulating Difficulty Inside a Class
The IPS method introduces random patch swaps between intra-class images. This creates two new images:
- One with strong features (e.g., head of a dog)
- One with weaker features (e.g., body or background)
These serve as pseudo-teacher and pseudo-student pairs. The model then learns by aligning their predictive distributions via KL-divergence.
This not only helps the model focus on different parts of the object but also increases the training signal diversity—resulting in more generalizable features.
3. 📊 Better Than the Real Thing? Outperforming Teacher-Based KD
Yes, you read that right.
On ImageNet:
- IPS achieved 77.85% top-1 accuracy with ResNet50 (2×2 patch swap)
- That’s +1.55% higher than the baseline and even better than ResNet152 used as a teacher!
On CIFAR-100:
- ResNet18 baseline: 77.92%
- ResNet18 + IPS: 80.53% (+2.61%)
And the trend holds across multiple architectures—ResNet, VGG, ShuffleNet, even MViTv2 transformers!
Keywords: outperforming teacher-based knowledge distillation, Intra-class Patch Swap accuracy
4. 🚀 Multi-Domain Superpowers: Classification, Segmentation, Detection
IPS isn’t just for classification. It generalizes beautifully to semantic segmentation and object detection:
- On VOC2012 segmentation, mIoU improved from 72.46% to 75.25%
- On PASCAL VOC detection, mAP increased significantly across 14 of 20 classes
- On fine-grained datasets like CUB-200 and Stanford Dogs, accuracy jumped up to +12.18%
This shows that IPS enhances representation learning, making models smarter and more context-aware.
5. 🧠 No Extra Parameters. No Network Changes. Just Results.
A huge benefit? Simplicity.
IPS requires:
- No architectural changes
- No auxiliary classifiers
- No additional parameters
All it needs is a single augmentation function. That makes it easy to integrate into existing training pipelines.
Here’s the kicker: the full implementation fits in under 20 lines of PyTorch code.
Keywords: plug-and-play data augmentation, model-agnostic self-distillation
6. 🛡️ Built-In Robustness: Handles Noisy Labels, Adversaries & Corruptions
The study extensively tested IPS under adversarial attacks, label noise, and corruptions:
| Metric | Baseline | IPS |
|---|---|---|
| FGSM (ε=0.01) | 45.9% | 57.5% |
| Label noise (80%) | 29.1% | 31.9% |
| CIFAR100-C (corruptions) | 55.4% | 59.3% |
These gains aren’t just academic. They mean more reliable AI in real-world, unpredictable environments—like autonomous driving, medical imaging, and surveillance.
Keywords: robust knowledge distillation, resilient deep learning models
7. ⚠️ Pitfall: Too Much Swapping Can Hurt
The authors caution against overdoing the patch swaps. Using too many swapped pairs (high pr values) can distort the image integrity, leading to logit over-smoothing and accuracy drops.
The sweet spot? A swap probability (pr) around 0.5 seems to work best across datasets.
Still, the method outperforms CutMix, MixUp, and CutOut even when used together, making it a strong primary augmentation for future pipelines.
The Equation That Powers It All
At the heart of the IPS method is a loss function that combines:
- Two cross-entropy losses (for swapped images)
- Two KL-divergence terms (between strong and weak samples)
\[ \mathcal{L} = \frac{1}{2} \gamma (\mathcal{L}_{\mathrm{CE1}} + \mathcal{L}_{\mathrm{CE2}}) + \frac{1}{2} \alpha (\mathcal{L}_{\mathrm{KD1}} + \mathcal{L}_{\mathrm{KD2}}) \]
Where γ and α are tuning weights (usually both set to 1), and T is the temperature for softening logits.
This simple but effective formulation enables relaxed supervision—key to self-distillation success.
If you’re Interested in deep learning based Enter Multi-Frame Deconvolution model, you may also find this article helpful: 7 Game-Changing Wins & Pitfalls of Multi-Frame Deconvolution in Super-Resolution Ultrasound (SRUS)
Final Verdict: Should You Use It?
If you’re training models for:
✅ Image classification
✅ Semantic segmentation
✅ Object detection
✅ Fine-grained classification
✅ On-device or edge deployment
Then YES.
Intra-class Patch Swap is a no-teacher, no-hassle, high-performance self-distillation method that is:
- Easy to implement
- Resource-light
- Architecturally neutral
- And—most importantly—state-of-the-art in multiple domains
💥 Call to Action: Try IPS in Your Next Vision Project!
Ready to say goodbye to bulky teacher models and hello to smarter training?
🔗 Get the Code Now: Intra-class Patch Swap GitHub
📊 Benchmark it on your dataset
🤖 Integrate it with your favorite models—ResNet, VGG, MobileNet, even Transformers!
🤖 Paper link: https://arxiv.org/abs/2505.14124
Want help customizing it for your use case? Drop us a message—we’re here to help you optimize, scale, and ship robust AI models faster.
FAQ
❓Is this better than MixUp or CutMix?
Yes, especially in terms of preserving class relationships and improving robustness. It can even complement them when used correctly.
❓Can it be used for NLP or audio models?
Currently designed for image-based tasks, but the principle of intra-class difficulty modeling could inspire adaptations in other domains.
❓What’s the catch?
Overuse of patch swaps (pr too high) can degrade performance. Stick to a balanced pr = 0.5.
Here’s the complete implementation of the proposed intra-class patch swap for self-distillation:
import torch
import torch.nn as nn
import torch.nn.functional as F
import numpy as np
import random
class IntraClassPatchSwap:
def __init__(self, patch_size=4, swap_prob=0.5):
self.patch_size = patch_size
self.swap_prob = swap_prob
def __call__(self, batch_a, batch_b):
"""
Perform intra-class patch swapping between two batches of images
Args:
batch_a: Tensor of shape [B, C, H, W]
batch_b: Tensor of shape [B, C, H, W]
Returns:
swapped_a, swapped_b: Augmented images with same shape as inputs
"""
B, C, H, W = batch_a.shape
device = batch_a.device
# Calculate total patches
total_patches = (H // self.patch_size) * (W // self.patch_size)
# Unfold images into patches
patches_a = F.unfold(batch_a, kernel_size=self.patch_size,
stride=self.patch_size, padding=0) # [B, C*S*S, L]
patches_b = F.unfold(batch_b, kernel_size=self.patch_size,
stride=self.patch_size, padding=0) # [B, C*S*S, L]
# Process each image pair in the batch
for i in range(B):
if random.random() < self.swap_prob:
# Randomly select number of patches to swap (1 to total_patches-1)
k = random.randint(1, total_patches - 1)
# Randomly select patch indices
idx = torch.randperm(total_patches)[:k].to(device)
# Swap patches between images
temp = patches_a[i, :, idx].clone()
patches_a[i, :, idx] = patches_b[i, :, idx]
patches_b[i, :, idx] = temp
# Fold patches back into images
swapped_a = F.fold(patches_a, output_size=(H, W),
kernel_size=self.patch_size,
stride=self.patch_size, padding=0)
swapped_b = F.fold(patches_b, output_size=(H, W),
kernel_size=self.patch_size,
stride=self.patch_size, padding=0)
return swapped_a, swapped_b
class SelfDistillationLoss(nn.Module):
def __init__(self, temperature=4.0, alpha=1.0, gamma=1.0):
super().__init__()
self.temperature = temperature
self.alpha = alpha # Weight for KD loss
self.gamma = gamma # Weight for CE loss
def forward(self, logits_a, logits_b, labels):
"""
Compute self-distillation loss
Args:
logits_a: Logits from first augmented image [B, num_classes]
logits_b: Logits from second augmented image [B, num_classes]
labels: Ground truth labels [B]
Returns:
Combined loss value
"""
# Cross-entropy losses
ce_loss1 = F.cross_entropy(logits_a, labels)
ce_loss2 = F.cross_entropy(logits_b, labels)
ce_loss = (ce_loss1 + ce_loss2) / 2
# Soften logits with temperature
soft_a = F.log_softmax(logits_a / self.temperature, dim=1)
soft_b = F.softmax(logits_b / self.temperature, dim=1)
# KL divergence losses (symmetric)
kl_loss1 = F.kl_div(soft_a, soft_b, reduction='batchmean')
kl_loss2 = F.kl_div(soft_b, soft_a, reduction='batchmean')
kl_loss = (kl_loss1 + kl_loss2) / 2
# Combine losses
total_loss = self.gamma * ce_loss + self.alpha * kl_loss
return total_loss
# Example usage in training loop
def train_model(model, train_loader, optimizer, device, epochs=100):
patch_swap = IntraClassPatchSwap(patch_size=4, swap_prob=0.5)
criterion = SelfDistillationLoss(temperature=4.0, alpha=1.0, gamma=1.0)
model.train()
for epoch in range(epochs):
for batch_a, batch_b, labels in train_loader:
batch_a, batch_b, labels = batch_a.to(device), batch_b.to(device), labels.to(device)
# Apply intra-class patch swap
swapped_a, swapped_b = patch_swap(batch_a, batch_b)
# Forward pass
logits_a = model(swapped_a)
logits_b = model(swapped_b)
# Compute loss
loss = criterion(logits_a, logits_b, labels)
# Backward pass
optimizer.zero_grad()
loss.backward()
optimizer.step()
# Custom dataset for same-class pairs (required for training)
class SameClassPairDataset(torch.utils.data.Dataset):
def __init__(self, original_dataset):
self.dataset = original_dataset
self.class_indices = self._build_class_indices()
def _build_class_indices(self):
class_indices = {}
for idx, (_, label) in enumerate(self.dataset):
if label not in class_indices:
class_indices[label] = []
class_indices[label].append(idx)
return class_indices
def __len__(self):
return len(self.dataset)
def __getitem__(self, index):
img1, label1 = self.dataset[index]
same_class_indices = self.class_indices[label1]
# Select a different image from same class
if len(same_class_indices) > 1:
other_idx = random.choice([i for i in same_class_indices if i != index])
else:
other_idx = index # Fallback if only one image
img2, label2 = self.dataset[other_idx]
return img1, img2, label1
# Example dataset setup for CIFAR-100
if __name__ == "__main__":
from torchvision.datasets import CIFAR100
from torchvision.transforms import ToTensor
from torch.utils.data import DataLoader
# Prepare datasets
base_dataset = CIFAR100(root='./data', train=True, download=True, transform=ToTensor())
pair_dataset = SameClassPairDataset(base_dataset)
train_loader = DataLoader(pair_dataset, batch_size=64, shuffle=True)
# Initialize model and optimizer (example)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = ResNet18(num_classes=100).to(device) # Replace with actual model
optimizer = torch.optim.SGD(model.parameters(), lr=0.05, momentum=0.9, weight_decay=5e-4)
# Start training
train_model(model, train_loader, optimizer, device, epochs=240)
Pingback: 7 Shocking Truths About Trace-Based Knowledge Distillation That Can Hurt AI Trust - aitrendblend.com