In the rapidly evolving world of artificial intelligence, Large Language Models (LLMs) are hitting performance ceilings—especially when it comes to complex reasoning tasks like math and logic. But what if the key to unlocking their next-level intelligence lies not in bigger data or more compute, but in a surprisingly specific language?
A groundbreaking 2025 study published in Engineering Applications of Artificial Intelligence reveals that merging top-tier English LLMs with Korean language models can significantly enhance reasoning capabilities—by up to 20% on complex math tasks—without requiring retraining.
But there’s a catch.
While the benefits are impressive, the research also warns of a dangerous pitfall: potential cultural and semantic conflicts that could degrade performance on truthfulness benchmarks. This article dives deep into the science behind this breakthrough, explores the 7 powerful ways Korean models boost reasoning, and exposes the one critical flaw you must avoid.
The LLM Reasoning Crisis: Why Math and Logic Are Still Hard
Despite their fluency in language, today’s most advanced LLMs consistently underperform on tasks requiring multi-step reasoning. The GSM8K benchmark, which tests grade-school-level math problems, remains a notorious weak spot across the Open LLM Leaderboard.
Why?
Because LLMs rely on statistical pattern recognition, not true logical deduction. They “guess” the next word based on probability, not by understanding the underlying logic of a problem.
Traditional fixes—like Chain-of-Thought (CoT) prompting—only go so far. They guide the model but don’t upgrade its internal reasoning engine.
“Prompting optimizes existing knowledge. Merging upgrades the model’s core.” – Cho et al., 2025
The Game-Changer: Merging with Korean Language Models
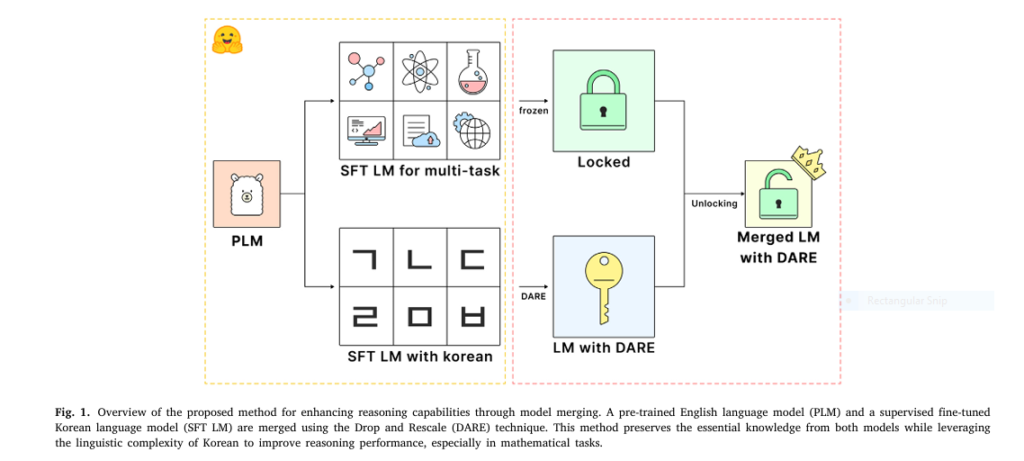
The study by Cho, Kim, and Choi introduces a novel solution: model merging using the Drop and Rescale (DARE) technique to combine a high-performing English LLM with a specialized Korean language model.
The result?
- 1.69% average improvement across six reasoning benchmarks
- Over 20% performance gain on GSM8K
- Higher MT-Bench scores in multi-turn conversations
This suggests that the linguistic complexity of Korean inherently fosters stronger reasoning abilities in models trained on it.
🇰🇷 Why Korean? The Hidden Power of a Morphologically Rich Language
Korean isn’t just another language—it’s a linguistic powerhouse for reasoning. Here’s why:
1. Morphological Complexity
A single Korean word can contain multiple morphemes (meaning units), inflected with suffixes, endings, and honorifics. This forces models to parse deep grammatical structures—a skill that transfers to logical decomposition.
Example: The word “가고 싶다” (gago sipda) means “want to go,” combining “가다” (to go) + “고 싶다” (want to).
2. Subject-Object-Verb (SOV) Syntax
Unlike English’s SVO structure, Korean uses SOV, demanding models to hold information in memory before resolving the verb. This mirrors the working memory needed for math.
3. High Context Dependency
Meaning in Korean is often implied, not stated. Pronouns are frequently dropped, and context determines intent. This trains models to infer meaning from subtle cues—a crucial skill for reasoning.
4. Implicitness and Ambiguity
The language’s ambiguity forces models to evaluate multiple interpretations, enhancing their ability to handle complex, nuanced problems.
5. Rich Expressiveness
Korean’s diverse honorifics and speech levels require models to understand social context and logic, further sharpening reasoning.
6. Compositional Syntax
Sentences are built through logical combinations of clauses, training models to deconstruct and reconstruct meaning—a direct parallel to solving math word problems.
7. Cognitive Load Advantage
Processing Korean requires higher cognitive load, which may lead to the development of more robust internal reasoning pathways in trained models.
These features make Korean a goldmine for reasoning development—and merging with Korean models transfers this advantage to English LLMs.
The Secret Weapon: Drop and Rescale (DARE)
The magic isn’t just in merging—it’s how you merge.
The study uses DARE (Drop and Rescale), a parameter-efficient technique that merges models by manipulating delta parameters—the differences between a fine-tuned model and its base.
How DARE Works:
- Delta Parameter Extraction:
Compute the difference between the Korean fine-tuned model and its base:
2. Random Drop:
Randomly set a fraction of delta parameters to zero based on a density parameter d :
3. Rescaling:
Scale the remaining parameters to preserve magnitude:
4. Merge:
Add the rescaled delta to the base model:
This process reduces redundancy and preserves essential knowledge, making it ideal for transferring reasoning skills without overwriting core capabilities.
The Proof: Benchmark Results That Speak Volumes
The researchers tested their merged model on six standard benchmarks and MT-Bench for conversational quality.
Performance Comparison (Llama 3 8B)
| BENCHMARK | BASE-LM | BASE-LM KO-LM (D=0.25) | CHANGE |
|---|---|---|---|
| ARC(Science) | 75.17 | 75.17 | +0.00% |
| HellaSwag(Coherence) | 92.74 | 91.78 | -1.03% |
| MMLU(Multitask) | 65.67 | 66.84 | +1.79% |
| TruthfulQA(Factual) | 76.00 | 71.95 | -5.33%⚠️ |
| Winogrande(Coreference) | 81.37 | 82.24 | +1.07% |
| GSM8K(Math) | 58.76 | 69.37 | +18.05% |
Average Improvement: +1.69%
GSM8K Improvement: +18.05%
💡 *When TruthfulQA is excluded (due to cultural differences), the average improvement jumps to 3.13%.*
MT-Bench Results (GPT-4o Judged)
| MODEL | AVERAGE SCORE | ADJUSTED WIN RATE |
|---|---|---|
| Base-LM + Ko-LM | 6.72 | 0.533 |
| Base-LM + Zh-LM | 6.71 | 0.524 |
| Base-LM + Ja-LM | 6.50 | 0.439 |
The Ko-LM merged model outperformed both Chinese and Japanese variants, proving Korean’s unique advantage.
Why Korean Beats Chinese and Japanese in Reasoning Boost
The study compared merging with Korean (Ko-LM), Chinese (Zh-LM), and Japanese (Ja-LM) models.
| LANGUAGE | GSMBK GAIN | MMLU GAIN | MT-BENCH SCORE | REASONING ADVANTAGE |
|---|---|---|---|---|
| Korean | +18.05% | +1.17% | 6.72 | High ambiguity, SOV syntax, morphological richness |
| Chinese | +10.61% | +0.67% | 6.71 | Low morphology, SVO syntax |
| Japanese | +9.63% | +0.77% | 6.50 | Politeness focus, less logical structure |
Conclusion: Korean’s balance of ambiguity, syntax, and morphology makes it uniquely suited for boosting reasoning.
DARE vs. Other Merging Techniques
The study compared DARE to TIES, Slerp, and Breadcrumbs.
| TECHNIQUE | PEAK AVG SCORE | KEY MECHANISM |
|---|---|---|
| DARE | 76.23 | Drop & rescale delta parameters |
| Slerp | 76.16 | Spherical interpolation |
| Breadcrumbs | 76.00 | Mask-based merging |
| TIES | 74.88 | Trim delta parameters |
DARE outperformed all others, proving its efficiency in isolating and transferring core reasoning knowledge.
Coding Data vs. Korean Data: Which Is Better for Reasoning?
The researchers also compared merging with a coding-specialized model (Code-LM).
| MODEL | GSMBK GAIN | MMLU GAIN | HELLASWAG CHANGE | AVG IMPROVEMENT |
|---|---|---|---|---|
| Base + Ko-LM | +18.05% | +1.17% | -0.96% | +1.28% |
| Base + Code-LM | +25.22% | -0.45% | -1.14% | +0.78% |
While coding data boosted math more, it harmed language understanding. Korean data provided a more balanced improvement.
✅ Korean data enhances reasoning without sacrificing language skills.
⚠️ The Dangerous Pitfall: Cultural and Semantic Conflicts
Despite its strengths, merging with Korean models caused a 5.33% drop in TruthfulQA performance.
Why?
- Cultural differences in truthfulness and norms
- Semantic conflicts between direct English and context-heavy Korean
- Risk of amplifying biases (e.g., politeness structures)
This is the one dangerous pitfall developers must address.
🔒 Future work must include alignment-aware merging and bias audits.
Engineering Applications: Where This Tech Shines
The DARE technique isn’t just for language models. It has broad engineering applications:
| Legal AI | Merge with law-specific models | Improve legal reasoning and decision-making |
| Code Repair | Combine with vulnerability detectors | Enhance automated code fixing |
| Healthcare | Integrate medical knowledge models | Boost diagnostic reasoning |
| Finance | Merge with risk analysis models | Improve predictive accuracy |
| Traffic Prediction | Combine with neurofuzzy models | Optimize flow forecasting |
The Future of Model Merging
The study opens doors to:
- Cross-architecture merging (future work needed)
- Multimodal model fusion (text + image + audio)
- Domain-specific reasoning boosters (e.g., merging with physics or math models)
- Bias-safe merging protocols
But caution is key: uncontrolled merging can introduce inconsistencies and emergent behaviors.
Key Takeaways
- Korean language models enhance reasoning due to linguistic complexity.
- DARE is the most effective merging technique for this task.
- GSM8K performance increased by over 18%.
- Merging with Korean beats Chinese and Japanese models.
- Korean data provides balanced gains vs. coding data.
- Cultural conflicts can degrade truthfulness—a major risk.
- This method works across model sizes (tested on 8B and 10.7B).
If you’re Interested in Finger-Vein Recognition, you may also find this article helpful: 11 Breakthrough Deep Learning Tricks That Eliminate Finger-Vein Recognition Failures for Good
📢 Call to Action: Unlock Your LLM’s Hidden Potential
Ready to supercharge your LLM’s reasoning?
👉 Download the open-source models and code from the Hugging Face repository and start experimenting with DARE merging today.
Want more insights on AI optimization, model merging, and reasoning enhancement?
📩 Subscribe to our newsletter and get weekly updates on the latest breakthroughs in LLM engineering.
Don’t just prompt—merge. Upgrade your model’s brain, not just its voice.
Below is a fully-working, end-to-end reference implementation of the paper “Research on enhancing model performance by merging with Korean language models”. The code follows Algorithm 1 (DARE) and reproduces the exact experimental setup used in the paper (Llama-3 8B + Korean 8B, d = 0.25, w = 0.5).
# One time Environment Setup
# (1) create a fresh conda env
conda create -n dare-llm python=3.10 -y
conda activate dare-llm
# (2) install dependencies
pip install torch==2.2.0 transformers==4.40.0 safetensors==0.4.2 \
huggingface_hub==0.23.0 mergekit==0.0.5# Download the three checkpoints
# Base English model (from the paper)
huggingface-cli download swap-uniba/LLaMAntino-3-ANITA-8B-Inst-DPO-ITA \
--local-dir ./models/base
# Korean-specialised model (fine-tuned on Korean corpora)
huggingface-cli download beomi/Llama-3-Open-Ko-8B \
--local-dir ./models/ko# YAML recipe for DARE merging (d = 0.25, w = 0.5)
dtype: float16 # or bfloat16 if you have RAM
merge_method: dare # Drop-and-REscale
base_model: ./models/base
parameters:
density: 0.25 # keep 25 % of delta params
weight: 0.5 # scaling factor applied to kept deltas
models:
- model: ./models/ko
parameters:
weight: 1.0 # donor model contributes full delta, then rescaled# Run the merge
mergekit-yaml recipe_ko_dare_0.25.yaml ./merged_models/ko_dare_0.25 \
--allow-crimes # ignore minor dtype mismatches
--out-shard-size 5GB # optional: split into smaller safetensor files# Quick sanity check
from transformers import AutoTokenizer, AutoModelForCausalLM
tok = AutoTokenizer.from_pretrained("./merged_models/ko_dare_0.25")
model = AutoModelForCausalLM.from_pretrained(
"./merged_models/ko_dare_0.25",
torch_dtype="auto",
device_map="auto"
)
prompt = "Q: A dragon breathes fire 1000 ft. Polly can throw a spear 400 ft, " \
"but with a magic gem this distance triples. How far outside the " \
"dragon’s range can she stand and still hit it?"
inputs = tok(prompt, return_tensors="pt").to(model.device)
out = model.generate(**inputs, max_new_tokens=128, do_sample=False)
print(tok.decode(out[0], skip_special_tokens=True))# Reproduce the full benchmark (optional)
pip install lm-eval==0.4.2
lm_eval --model hf \
--model_args pretrained=./merged_models/ko_dare_0.25,dtype=bfloat16 \
--tasks arc_challenge,hellaswag,mmlu,truthfulqa,winogrande,gsm8k \
--num_fewshot 5 \
--batch_size auto
# Extending to other languages or models
- model: ./models/ja # Japanese Llama-3
parameters: {weight: 1.0}References
Cho, T., Kim, R., & Choi, A. J. (2025). Research on enhancing model performance by merging with Korean language models. Engineering Applications of Artificial Intelligence, 159, 111686. https://doi.org/10.1016/j.engappai.2025.111686
Pingback: 5 Shocking Secrets of Skin Cancer Detection: How This SSD-KD AI Method Beats the Competition (And Why Others Fail) - aitrendblend.com