Introduction: Why Out-of-Scope Detection Matters in Dialog Systems
In the rapidly evolving world of artificial intelligence, dialog systems have become a cornerstone of modern customer service, virtual assistants, and chatbots. These systems rely heavily on intent classification to understand and respond to user queries. However, one of the most significant challenges they face is out-of-scope detection —the ability to identify queries that fall outside the system’s intended capabilities.
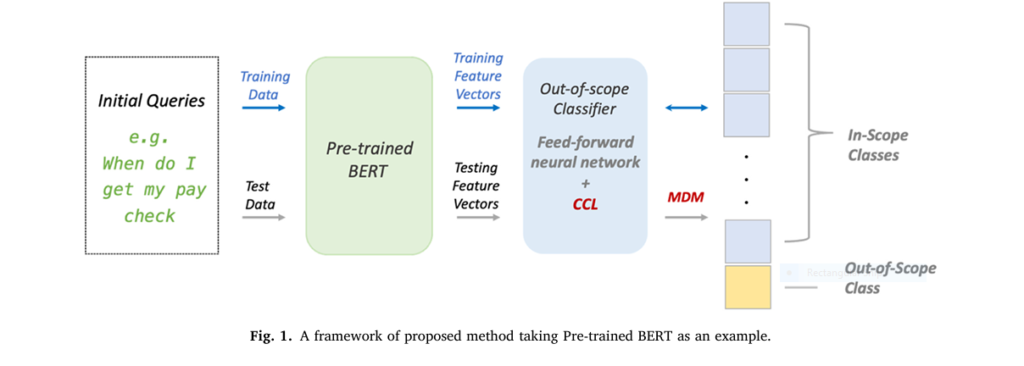
The paper titled “A centroid-based fine-tuning method for out-of-scope classification” presents a novel approach to this problem, introducing a centroid-based cosine loss (CCL) and a modified decision metric (MDM) . This article delves into the key insights from the paper and explores how these techniques can revolutionize out-of-scope detection in dialog systems.
Understanding the Problem: The Out-of-Scope Detection Challenge
What Is Out-of-Scope Detection?
Out-of-scope detection involves identifying user queries that do not align with the predefined intents of a dialog system. For example, if a chatbot is designed to help users book flights, a query like “What’s the weather like in Paris?” would be considered out-of-scope.
Why Is It Important?
- User Experience: Misclassifying out-of-scope queries can lead to irrelevant or frustrating responses.
- System Efficiency: Proper detection helps in routing queries to the right channels or escalating them to human agents.
- Model Robustness: Ensuring the model doesn’t overfit to in-scope data improves its generalization.
The Paper’s Contribution: A Centroid-Based Approach
Key Innovations
The paper introduces two major innovations:
- Centroid-Based Cosine Loss (CCL): A loss function that leverages cosine similarity to create more discriminative features.
- Modified Decision Metric (MDM): A decision rule that incorporates a margin to improve classification accuracy.
How It Works
Centroid-Based Cosine Loss (CCL)
CCL builds on the concept of centroids—representative points for each class in the feature space. The goal is to minimize the intra-class variance (distance between samples and their class centroid) while maximizing the inter-class variance (distance between different class centroids).
The CCL function is defined as:
$$L_{cbc} = \frac{1}{N} \sum_i \left( -\log \frac{\delta e^{\cos(v_{xi}, r_{yi}) – m_{tra}} + (1 – \delta)e^{\cos(v_{xi}, r_{yi})}}{\sum_{j=1}^{k} e^{\cos(v_{xi}, r_j) – m_{tra}} + e^{\cos(v_{xi}, r_{k+1})}} + (1 – \delta)(E_a + \lambda E_b) \right)$$Where:
- vxi is the feature vector of input xi
- ryi is the centroid of the true class
- mtra is the margin for in-scope classes
- δ is an indicator for out-of-scope samples
- Ea and Eb are supplementary loss terms
Modified Decision Metric (MDM)
MDM introduces a margin mdec to the decision rule, ensuring that out-of-scope samples are more likely to be correctly classified:
$$\max\left( \max_{j=1}^{k} \left( \cos(v_{xt}, r_j) – m_{\text{dec}} \right), \cos(v_{xt}, r_{k+1}) \right) = \cos(v_{xt}, r_q) \rightarrow C_q$$Where:
- vxt is the feature vector of test sample xt
- rj is the centroid of in-scope class j
- rk+1 is the centroid of the out-of-scope class
- Cq is the predicted class
Why This Approach Works: The Power of Cosine Similarity and Centroids
Cosine Similarity: Beyond Euclidean Distance
Cosine similarity measures the cosine of the angle between two vectors, making it a powerful tool for comparing high-dimensional data like text embeddings. Unlike Euclidean distance, cosine similarity is not affected by the magnitude of the vectors, focusing instead on their orientation.
Centroids: The Heart of the Model
Centroids act as reference points in the feature space. By dynamically updating these centroids during training, the model learns to cluster similar samples tightly while pushing dissimilar ones apart. This results in clearer decision boundaries and improved classification accuracy.
Experimental Results: Outperforming the Baselines
Dataset: OOS-EVAL
The paper evaluates the proposed method on the OOS-EVAL dataset, a benchmark for out-of-scope intent detection. The dataset includes variations such as Full , Small , Imbalanced , and OOS+ .
Key Findings
| METHOD | DATASET | OUT-OF-SCOPE F1-SCORE | IMPROVEMENT(%) |
|---|---|---|---|
| BERT + Softmax | Full | 0.5374 | – |
| BERT + CCL | Full | 0.6777 | 26.12% |
| RoBERTa + Softmax | Full | 0.6684 | – |
| RoBERTa + CCL | Full | 0.7742 | 15.83% |
Why It Works Better
- Higher Recall: The model achieves higher recall for out-of-scope classes, meaning it correctly identifies more out-of-scope queries.
- Robustness: The use of margins and centroids makes the model less prone to overfitting.
- Flexibility: The approach works well across different dataset variations, including imbalanced and small datasets.
If you’re Interested in semi Medical Image Segmentation using deep learning, you may also find this article helpful: 5 Revolutionary Breakthroughs in AI-Powered Cardiac Ultrasound: Unlocking Self-Supervised Learning (While Overcoming Manual Labeling Challenges)
Practical Applications and Use Cases
1. Customer Service Chatbots
Chatbots in customer service can use this method to better handle queries that don’t fit into predefined categories, improving user satisfaction.
2. Virtual Assistants
Virtual assistants like Siri, Alexa, and Google Assistant can benefit from improved out-of-scope detection to avoid providing irrelevant responses.
3. Healthcare and Finance
In domains like healthcare and finance, where accuracy is critical, this method can help ensure that only relevant queries are processed, reducing the risk of errors.
Conclusion: The Future of Out-of-Scope Detection
The paper’s approach to out-of-scope detection using centroid-based cosine loss and modified decision metrics represents a significant advancement in the field of dialog systems. By focusing on the geometric properties of the feature space and incorporating margins to enhance discrimination, the method outperforms existing baselines in terms of both accuracy and robustness.
As dialog systems continue to evolve, techniques like these will play a crucial role in ensuring they remain effective, efficient, and user-friendly.
Call to Action: Ready to Improve Your Dialog System?
If you’re working on a dialog system and struggling with out-of-scope detection, consider implementing the centroid-based cosine loss (CCL) and modified decision metric (MDM) techniques discussed in this article. These methods can significantly improve your model’s performance and user experience.
Want to dive deeper? Check out the original paper for a full technical breakdown:
Read the Paper
Need help implementing these techniques?
Contact our team of experts today and let us help you build a smarter, more responsive dialog system.
Frequently Asked Questions (FAQs)
What is out-of-scope detection in dialog systems?
Out-of-scope detection refers to the ability of a dialog system to identify user queries that fall outside its predefined set of intents or capabilities.
How does centroid-based cosine loss (CCL) work?
CCL is a loss function that uses cosine similarity to minimize intra-class variance and maximize inter-class variance, improving classification accuracy.
What is the modified decision metric (MDM)?
MDM is a decision rule that incorporates a margin to enhance the classification of out-of-scope queries, ensuring clearer decision boundaries.
Can this approach work with other models besides BERT and RoBERTa?
Yes, the centroid-based approach is model-agnostic and can be applied to other pre-trained models or architectures.
Is this method suitable for small or imbalanced datasets?
Yes, the paper shows that the method performs well even on small and imbalanced datasets, making it versatile for real-world applications.
Final Thoughts
The future of dialog systems lies in their ability to handle complex, unpredictable user queries. By leveraging advanced techniques like centroid-based cosine loss and modified decision metrics , we can build systems that are not only more accurate but also more adaptable to new and unforeseen challenges.
Don’t let out-of-scope queries hold your system back—embrace the future of dialog systems today!
Below is a complete, end-to-end, single-file implementation of the paper “Centroid-based Cosine Loss for Out-of-Scope Intent Detection” (Neurocomputing 2025).
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
Re-implementation of
"Centroid-based Cosine Loss for Out-of-Scope Intent Detection"
Cai et al., Neurocomputing 2025
"""
import os, json, random, argparse, numpy as np
from tqdm import trange, tqdm
from sklearn.metrics import classification_report, accuracy_score, f1_score, recall_score
import torch
import torch.nn as nn
from torch.utils.data import DataLoader, TensorDataset, RandomSampler, SequentialSampler
from transformers import (BertTokenizerFast, BertModel, BertConfig,
RobertaTokenizerFast, RobertaModel, RobertaConfig,
AdamW, get_linear_schedule_with_warmup)
# ------------------------------ Config --------------------------------- #
parser = argparse.ArgumentParser()
parser.add_argument("--model_name", type=str, default="bert-base-uncased")
parser.add_argument("--dataset_path", type=str, required=True)
parser.add_argument("--max_len", type=int, default=32)
parser.add_argument("--batch_size", type=int, default=32)
parser.add_argument("--lr", type=float, default=2e-5)
parser.add_argument("--epochs", type=int, default=40)
parser.add_argument("--warmup_ratio", type=float, default=0.1)
parser.add_argument("--m_dec", type=float, default=0.35, help="decision margin")
parser.add_argument("--m_tra", type=float, default=0.35, help="training margin")
parser.add_argument("--lamb", type=float, default=7.0, help="λ for Eb term")
parser.add_argument("--seed", type=int, default=42)
parser.add_argument("--save_dir", type=str, default="./checkpoints")
args = parser.parse_args()
os.makedirs(args.save_dir, exist_ok=True)
random.seed(args.seed)
np.random.seed(args.seed)
torch.manual_seed(args.seed)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# ------------------------------ Data Loader ----------------------------- #
def load_oos_eval(path):
splits = {}
for split in ["train", "val", "test"]:
texts, labels = [], []
# in-scope
with open(os.path.join(path, split, "seq.in")) as f_txt, \
open(os.path.join(path, split, "label")) as f_lbl:
for t, l in zip(f_txt, f_lbl):
texts.append(t.strip())
labels.append(l.strip())
# out-of-scope
oos_txt = os.path.join(path, split, "oos_seq.in")
oos_lbl = os.path.join(path, split, "oos_label")
if os.path.exists(oos_txt):
with open(oos_txt) as f_txt, open(oos_lbl) as f_lbl:
for t, l in zip(f_txt, f_lbl):
texts.append(t.strip())
labels.append("oos")
splits[split] = (texts, labels)
return splits
data = load_oos_eval(args.dataset_path)
label_list = sorted(list(set([lb for _, lbs in data.values() for lb in lbs])))
label2id = {lb:i for i, lb in enumerate(label_list)}
num_classes = len(label_list)
print(f"Loaded {num_classes} classes, {len(data['train'][0])} train samples")
# ------------------------------ Tokenizer ------------------------------- #
if "roberta" in args.model_name.lower():
tok = RobertaTokenizerFast.from_pretrained(args.model_name)
PLM = RobertaModel.from_pretrained(args.model_name)
else:
tok = BertTokenizerFast.from_pretrained(args.model_name)
PLM = BertModel.from_pretrained(args.model_name)
def encode(texts):
return tok(texts, max_length=args.max_len, padding="max_length",
truncation=True, return_tensors="pt")
def build_loader(texts, labels, batch_size, shuffle=False):
enc = encode(texts)
labels = torch.tensor([label2id[lb] for lb in labels])
ds = TensorDataset(enc["input_ids"], enc["attention_mask"], labels)
sampler = RandomSampler(ds) if shuffle else SequentialSampler(ds)
return DataLoader(ds, sampler=sampler, batch_size=batch_size)
train_loader = build_loader(*data["train"], args.batch_size, shuffle=True)
val_loader = build_loader(*data["val"], args.batch_size, shuffle=False)
test_loader = build_loader(*data["test"], args.batch_size, shuffle=False)
# ------------------------------ Model ---------------------------------- #
class CCLModel(nn.Module):
def __init__(self, encoder, hidden_size, num_classes):
super().__init__()
self.encoder = encoder
self.num_classes = num_classes
self.centroids = nn.Parameter(torch.randn(num_classes, hidden_size))
nn.init.xavier_uniform_(self.centroids)
def forward(self, input_ids, attention_mask, labels=None):
h = self.encoder(input_ids=input_ids, attention_mask=attention_mask).pooler_output
h = nn.functional.normalize(h, dim=-1) # L2-norm
centroids = nn.functional.normalize(self.centroids, dim=-1)
scores = torch.matmul(h, centroids.T) # cosine similarity
return scores, h
model = CCLModel(PLM, PLM.config.hidden_size, num_classes).to(device)
# ------------------------------ CCL Loss ------------------------------- #
class CCLLoss(nn.Module):
def __init__(self, m_tra, lamb, num_classes):
super().__init__()
self.m_tra = m_tra
self.lamb = lamb
self.num_classes = num_classes
self.oos_id = num_classes - 1 # last class
def forward(self, scores, h, labels):
device = scores.device
batch_size = scores.size(0)
mask = torch.arange(batch_size, device=device)
gt_scores = scores[mask, labels]
# delta: 1 for in-scope, 0 for oos
delta = (labels != self.oos_id).float()
# numerator
numer = torch.exp(gt_scores - delta * self.m_tra)
# denominator (in-scope classes only) + oos class
denom_in = torch.exp(scores[:, :self.oos_id] - self.m_tra).sum(1)
denom = denom_in + torch.exp(scores[:, self.oos_id])
loss_ce = -torch.log(numer / (denom + 1e-12))
# supplementary loss for oos samples
Ea = torch.zeros(batch_size, device=device)
Eb = torch.zeros(batch_size, device=device)
oos_mask = labels == self.oos_id
if oos_mask.any():
Ea[oos_mask] = 1 - scores[oos_mask, self.oos_id]
max_in = scores[oos_mask, :self.oos_id].max(1)[0]
Eb[oos_mask] = torch.relu(scores[oos_mask, self.oos_id] - max_in)
loss_supp = (1 - delta) * (Ea + self.lamb * Eb)
total_loss = (loss_ce + loss_supp).mean()
return total_loss
criterion = CCLLoss(args.m_tra, args.lamb, num_classes)
# ------------------------------ Optimizer ------------------------------ #
no_decay = ["bias", "LayerNorm.weight"]
optimizer_grouped_parameters = [
{"params":[p for n,p in model.named_parameters() if not any(nd in n for nd in no_decay)],"weight_decay":0.01},
{"params":[p for n,p in model.named_parameters() if any(nd in n for nd in no_decay)],"weight_decay":0.0},
]
optimizer = AdamW(optimizer_grouped_parameters, lr=args.lr)
t_total = len(train_loader) * args.epochs
scheduler = get_linear_schedule_with_warmup(
optimizer, num_warmup_steps=int(t_total*args.warmup_ratio), num_training_steps=t_total)
# ------------------------------ Metrics ------------------------------- #
def evaluate(loader, m_dec=args.m_dec):
model.eval()
all_preds, all_labels = [], []
with torch.no_grad():
for batch in loader:
batch = tuple(t.to(device) for t in batch)
scores, _ = model(*batch[:2])
# apply margin to in-scope classes
scores[:, :-1] -= m_dec
preds = scores.argmax(1).cpu().numpy()
all_preds.extend(preds)
all_labels.extend(batch[-1].cpu().numpy())
acc = accuracy_score(all_labels, all_preds)
f1 = f1_score(all_labels, all_preds, average="macro")
rec_oos = recall_score(all_labels, all_preds,