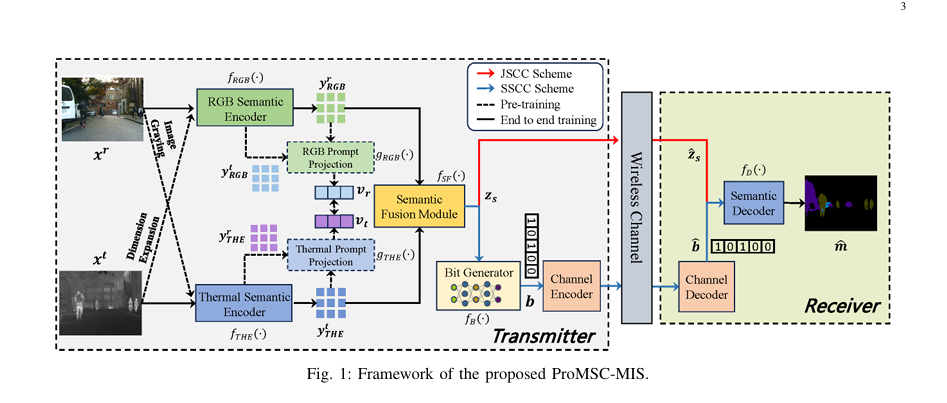
In the rapidly evolving landscape of artificial intelligence and wireless communication, a groundbreaking new framework—ProMSC-MIS (Prompt-based Multimodal Semantic Communication for Multi-Spectral Image Segmentation)—is setting a new benchmark in task-driven data transmission. Developed by Haoshuo Zhang, Yufei Bo, and Meixia Tao from Shanghai Jiao Tong University, this innovative system redefines how multimodal data is processed, transmitted, and utilized for high-impact applications like autonomous driving and nighttime surveillance.
This article dives deep into the architecture, training methodology, and performance advantages of ProMSC-MIS, offering a comprehensive overview for researchers, engineers, and AI enthusiasts interested in semantic communication, multimodal learning, and efficient image segmentation.
What Is ProMSC-MIS?
ProMSC-MIS stands at the intersection of deep learning, multimodal fusion, and semantic-aware transmission. Unlike traditional communication systems that focus on pixel-accurate image reconstruction, ProMSC-MIS prioritizes the transmission of task-relevant semantic information. This means only the most meaningful features needed for image segmentation are extracted, compressed, and sent over bandwidth-limited channels.
The framework is specifically designed for multi-spectral image segmentation, where spatially aligned RGB and thermal images are processed together to enhance scene understanding under diverse lighting conditions.
🔍 Primary Keywords: ProMSC-MIS, multimodal semantic communication, multi-spectral image segmentation, prompt learning, semantic fusion
Why ProMSC-MIS Matters: The Problem with Traditional Methods
Conventional image transmission pipelines follow a source-channel separation principle: images are compressed (e.g., using JPEG2000 or BPG), transmitted, reconstructed, and then fed into a segmentation model. This approach has critical drawbacks:
- High bandwidth consumption due to full-image transmission.
- Poor performance in low-light or extreme conditions.
- Redundant data transmission, including visually irrelevant pixels.
- Decoupled processing between communication and task execution.
Semantic communication addresses these issues by integrating task awareness into the transmission pipeline. However, most existing systems are unimodal or lack intelligent fusion strategies.
ProMSC-MIS fills this gap with a prompt-guided, contrastive pre-training mechanism and an advanced cross-attention + SE network fusion module, enabling superior performance at 50–70% lower bandwidth.
How ProMSC-MIS Works: A Step-by-Step Breakdown
1. Input: RGB and Thermal Image Pair
Let the input images be:
- xr ∈ RH×W×3 : RGB image
- xt ∈ RH×W×1 : Thermal image
Both are spatially aligned and captured from the same viewpoint.
2. Unimodal Semantic Encoders with Prompt Learning
ProMSC-MIS employs two parallel encoders:
- fRGB(⋅) : Extracts RGB semantic features yRGBr
- fTHE(⋅) : Extracts thermal semantic features yTHEt
But here’s the innovation: during pre-training, each modality is used as a prompt for the other.
🔄 Prompt Learning in Action
\[ x_r’ = \text{ConvertRGBtoGray}(x_r) \] \[ x_t’ = \text{ExpandTo3Channels}(x_t) \] \[ y_t^{\text{RGB}} = f_{\text{RGB}}(x_t’; \theta_r) \] \[ y_r^{\text{THE}} = f_{\text{THE}}(x_r’; \theta_t) \]These cross-modal outputs serve as “semantic hints” or prompts, guiding the encoders to learn complementary features rather than redundant ones.
🧠 Contrastive Learning Objective
To ensure diversity in learned features, a contrastive loss minimizes the cosine similarity between projected features:
\[ L_v(v_r, v_t) = \frac{\| v_r \|_2 \cdot \| v_t \|_2}{\| v_r \cdot v_t \|} \]where:
\[ v_r = g_{\text{RGB}}\Big( \text{concat}(y_{r}^{\text{RGB}}, \, y_{t}^{\text{RGB}}); \, \phi_r \Big) \] \[ v_t = g_{\text{THE}}\Big( \text{concat}(y_{t}^{\text{THE}}, \, y_{r}^{\text{THE}}); \, \phi_t \Big) \]Minimizing Lv pushes the embeddings apart, encouraging the model to capture distinct, modality-specific semantics.
3. Semantic Fusion Module: Cross-Attention + SE Networks
After encoding, features are fused using a hybrid architecture:
✅ Cross-Attention Transformer Block
- Self-Attention: Enhances intra-modal features
- Cross-Attention: Fuses information across modalities
For RGB features Fr ∈ RLr×D and thermal Ft ∈ RLt×D :
- Query from RGB:
- Key & Value from thermal:
Multi-Head Cross-Attention (MHCA):
\[ CA_h(Fr_s) = \text{softmax}\!\left( \frac{D_m}{H} \, Q_{r,h_c}(K_{t,h_c})^{T} \right) V_{t,h_c} \] \[ MHCA(Fr_s) = \Big[ \text{concat}_{h=1}^{H} \; CA_h(Fr_s) \Big] W_{rc} \]
A learnable matrix Mr dynamically adjusts cross-modal contribution:
\[ \alpha_{r} = F_{rc} \odot M_{r} + F_{rc} \]
Same process applies to thermal → RGB direction.
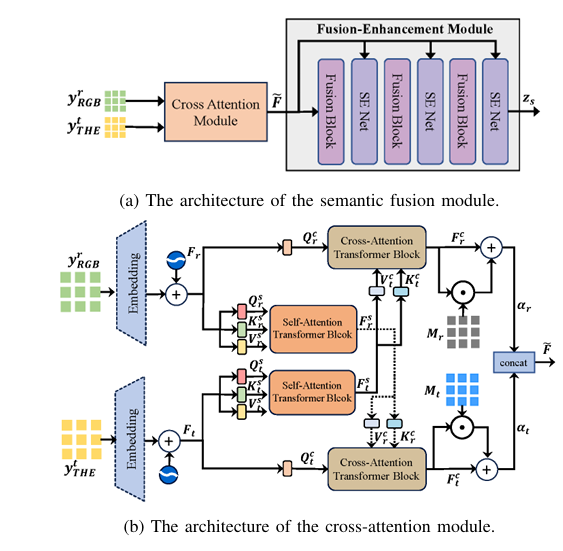
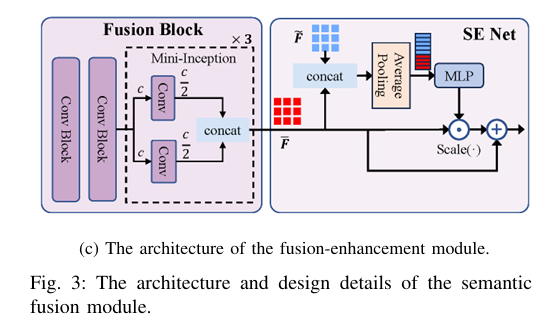
✅ Fusion-Enhancement with Squeeze-and-Excitation (SE)
The concatenated outputs F~=[αr ; αt] pass through:
- Fusion Blocks: Mini-Inception modules for multi-scale feature capture
- SE Networks: Channel-wise attention to recalibrate feature importance
After three stages, the final fused semantic vector zs ∈ RLs is generated.
4. Bit Generation & Transmission (SSCC)
To ensure compatibility with existing digital systems, ProMSC-MIS uses Separate Source-Channel Coding (SSCC):
- Bit Generator fB(⋅) : A learnable probabilistic layer maps zs to a probability table ps ∈ RLb×2
- Gumbel-Softmax Sampling: Enables differentiable discrete bit generation:bℓ=one_hot(argmax(logps,ℓ+g)),g ∼ Gumbel(0,1)
- Transmission: Bit sequence b is sent over a Binary Symmetric Channel (BSC) with bit-flip probability p
- Reception: Received b is decoded back to zs
5. Semantic Decoding for Segmentation
The receiver uses a decoder fD(⋅) —built with transpose convolutions—to upsample zs or b into the final segmentation map m ∈ RH×W×N , where N is the number of classes.
Training uses a composite loss:
\[ L_{e}(\hat{m}, m) = \lambda \cdot L_{\text{Dice}} + (1 – \lambda) \cdot L_{\text{SoftCE}} \]Where:
- Dice Loss (LDice ) improves class overlap
- Soft Cross-Entropy (LSoftCE ) smooths label distribution
Performance: Why ProMSC-MIS Outperforms the Competition
📊 Benchmarking Setup
- Dataset: MFNet (1,569 RGB-T image pairs, 8 object classes + background)
- Metrics: mIoU (mean Intersection over Union), mAcc (mean Accuracy)
- Compression Rate: Bits per pixel (bpp)
🔍 Comparison with Traditional Pipelines (JPEG2000/BPG + Segmentation)
| METHOD | MIOU (%) | MACC (%) | BP | NOTES |
|---|---|---|---|---|
| BPG-FEANet | ~42 | ~65 | 0.2 | High bandwidth |
| ProMSC-MIS | 42 | 65 | 0.06–0.09 | 50–70% less bandwidth |
Key Findings:
- Achieves same segmentation quality at 1/20 the bandwidth of BPG-FEANet
- Works in extreme low-bitrate regimes (0.0039–0.015625 bpp), where traditional codecs fail
- More robust to channel fluctuations due to end-to-end optimization
💡 At 0.09375 bpp, ProMSC-MIS delivers 3–4× higher mIoU than JPEG2000-based methods and 45% improvement over BPG-FEANet.
🔍 Comparison with DeepSC Variants
| MODEL | MIOU (%) | MACC (%) | BPP | NOTES |
|---|---|---|---|---|
| Multimodal DeepSC (no pre-train) | ~38 | ~58 | 0.07 | Baseline |
| RGB-DeepSC | ~34 | ~52 | 0.07 | Unimodal |
| Thermal-DeepSC | ~32 | ~50 | 0.07 | Unimodal |
| ProMSC-MIS | 41.5 | 63.8 | 0.07 | +9% mIoU gain |
Insights:
- Pre-training significantly boosts performance, especially at low bpp
- Multimodal > Unimodal: RGB + thermal consistently outperforms single-modality models
- RGB dominates in daylight, thermal excels at night—ProMSC-MIS adapts via fusion
Model Efficiency: Lower Complexity, Higher Performance
| MODEL | PARAMS (M) | FLOPS (G) | LATENCY (MS) |
|---|---|---|---|
| ProMSC-MIS (avg) | 186.99 | 212.34 | 46.95 |
| MFNet | 0.74 | 8.42 | 4.60 |
| RTFNet | 254.51 | 337.46 | 51.87 |
| FEANet | 255.21 | 337.47 | 65.89 |
Despite higher parameter count than MFNet, ProMSC-MIS achieves 26% lower storage overhead and 37% less computational complexity than RTFNet/FEANet when considering the entire pipeline (including source coding).
⚡ Even with full semantic processing, ProMSC-MIS is faster than FEANet and more efficient than all high-performance benchmarks.
Real-World Applications
🚗 Autonomous Driving
- Combines RGB detail and thermal night vision
- Enables 24/7 object detection (pedestrians, bikes, cones)
- Reduces data load on vehicle-to-infrastructure (V2I) links
🌙 Nighttime Surveillance
- Thermal data compensates for poor lighting
- Sharp segmentation of humans and vehicles in darkness
- Operates under ultra-low bandwidth (e.g., remote drones)
🛰️ Satellite & UAV Imaging
- Efficient transmission of multi-spectral Earth observation data
- Ideal for bandwidth-constrained satellite downlinks
Ablation Studies: What Makes ProMSC-MIS Work?
The paper validates two core innovations:
| CONFIGURATION | MIOU (%) | FROM FULL MODEL |
|---|---|---|
| Full ProMSC-MIS | 41.5 | — |
| w/o Pre-training | 38.0 | -3.5 |
| w/o Cross-Attention | 39.2 | -2.3 |
| w/o SE Networks | 40.1 | -1.4 |
| w/o Prompt Guidance | 37.8 | -3.7 |
Conclusion: Both prompt-based pre-training and advanced fusion are critical for peak performance.
Future Directions
- Integration with generative AI for missing modality synthesis
- Extension to video for semantic video communication
- Adaptive bit allocation based on scene complexity
- Hardware acceleration for real-time deployment
Conclusion: The Future of Task-Oriented Communication
ProMSC-MIS represents a paradigm shift in how we think about data transmission. By combining prompt learning, contrastive pre-training, and intelligent semantic fusion, it delivers:
✅ 50–70% bandwidth reduction
✅ Superior segmentation accuracy in low-light and low-bitrate conditions
✅ Lower computational and storage costs
✅ End-to-end task optimization from sensor to decision
This framework is not just a technical advancement—it’s a blueprint for next-generation AI-driven communication systems in autonomous vehicles, smart cities, and beyond.
Want to Dive Deeper?
👉 Download the full paper: ProMSC-MIS: Prompt-based Multimodal Semantic Communication for Multi-Spectral Image Segmentation
👉 Explore the MFNet dataset: MFNet: Multi-Spectral Semantic Segmentation
👉 Try the code: Implementation coming soon on GitHub (linked in the paper)
💬 Call to Action
Are you working on semantic communication, multimodal AI, or edge-based vision systems? Join the conversation!
- 📧 Subscribe to our AI & Communications newsletter
- 💬 Comment below with your thoughts on ProMSC-MIS
- 🔗 Share this article with your network to spread the word on this breakthrough
Together, we’re building the future of intelligent, efficient, and task-driven communication.
Here is the Python implementation of the ProMSC-MIS model, structured to be a single, self-contained file.
import torch
import torch.nn as nn
import torch.nn.functional as F
import torchvision.models as models
import math
# ==============================================================================
# Helper Modules (Attention, SE Net, etc.)
# ==============================================================================
class ChannelAttention(nn.Module):
"""
Channel-wise attention module as described in the paper.
Recalibrates channel importance.
"""
def __init__(self, in_planes, ratio=16):
super(ChannelAttention, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.max_pool = nn.AdaptiveMaxPool2d(1)
self.fc = nn.Sequential(
nn.Conv2d(in_planes, in_planes // ratio, 1, bias=False),
nn.ReLU(),
nn.Conv2d(in_planes // ratio, in_planes, 1, bias=False)
)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avg_out = self.fc(self.avg_pool(x))
max_out = self.fc(self.max_pool(x))
out = avg_out + max_out
return self.sigmoid(out)
class SpatialAttention(nn.Module):
"""
Spatial attention module as described in the paper.
Emphasizes significant spatial regions.
"""
def __init__(self, kernel_size=7):
super(SpatialAttention, self).__init__()
self.conv1 = nn.Conv2d(2, 1, kernel_size, padding=kernel_size // 2, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avg_out = torch.mean(x, dim=1, keepdim=True)
max_out, _ = torch.max(x, dim=1, keepdim=True)
x_cat = torch.cat([avg_out, max_out], dim=1)
x_att = self.conv1(x_cat)
return self.sigmoid(x_att)
class SENet(nn.Module):
"""
Squeeze-and-Excitation Network as shown in Figure 3(c).
"""
def __init__(self, in_channels, reduction=16):
super(SENet, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool1d(1)
self.fc = nn.Sequential(
nn.Linear(in_channels, in_channels // reduction, bias=False),
nn.ReLU(inplace=True),
nn.Linear(in_channels // reduction, in_channels, bias=False),
nn.Sigmoid()
)
def forward(self, x):
# x shape: (batch, channels, length)
b, c, _ = x.size()
y = self.avg_pool(x).view(b, c)
y = self.fc(y).view(b, c, 1)
return x * y.expand_as(x)
# ==============================================================================
# Core Architectural Components (Encoder, Decoder, Fusion)
# ==============================================================================
class SemanticEncoder(nn.Module):
"""
Semantic Encoder module based on ResNet-152 with attention. (Figure 2(a))
Used for both RGB and Thermal modalities.
"""
def __init__(self):
super(SemanticEncoder, self).__init__()
resnet = models.resnet152(weights=models.ResNet152_Weights.IMAGENET1K_V1)
self.layer0 = nn.Sequential(resnet.conv1, resnet.bn1, resnet.relu, resnet.maxpool)
self.layer1 = resnet.layer1
self.layer2 = resnet.layer2
self.layer3 = resnet.layer3
# Adding attention modules as per Figure 2(a)
self.ca1 = ChannelAttention(256)
self.sa1 = SpatialAttention()
self.ca2 = ChannelAttention(512)
self.sa2 = SpatialAttention()
self.ca3 = ChannelAttention(1024)
self.sa3 = SpatialAttention()
def forward(self, x):
x = self.layer0(x)
# Block 1
x1 = self.layer1(x)
x1_att = self.ca1(x1) * x1
x1_att = self.sa1(x1_att) * x1_att
x1 = x1 + x1_att
# Block 2
x2 = self.layer2(x1)
x2_att = self.ca2(x2) * x2
x2_att = self.sa2(x2_att) * x2_att
x2 = x2 + x2_att
# Block 3
x3 = self.layer3(x2)
x3_att = self.ca3(x3) * x3
x3_att = self.sa3(x3_att) * x3_att
x3 = x3 + x3_att
return x3 # Output feature map
class TransformerBlock(nn.Module):
""" A single Transformer block for self-attention or cross-attention. """
def __init__(self, embed_dim, num_heads, ff_dim, dropout=0.1):
super().__init__()
self.att = nn.MultiheadAttention(embed_dim, num_heads, dropout=dropout, batch_first=True)
self.ffn = nn.Sequential(
nn.Linear(embed_dim, ff_dim),
nn.ReLU(),
nn.Linear(ff_dim, embed_dim)
)
self.norm1 = nn.LayerNorm(embed_dim)
self.norm2 = nn.LayerNorm(embed_dim)
self.dropout = nn.Dropout(dropout)
def forward(self, x, context=None):
# If context is None, it's self-attention. Otherwise, it's cross-attention.
if context is None:
context = x
# Attention
attn_output, _ = self.att(x, context, context)
x = x + self.dropout(attn_output)
x = self.norm1(x)
# Feed Forward
ffn_output = self.ffn(x)
x = x + self.dropout(ffn_output)
x = self.norm2(x)
return x
class CrossAttentionModule(nn.Module):
"""
Cross-Attention Module to fuse features from two modalities. (Figure 3(b))
"""
def __init__(self, feature_dim=1024, embed_dim=256, num_heads=8, ff_dim=512):
super().__init__()
self.embed_dim = embed_dim
# Initial projection to embedding dimension
self.rgb_embed = nn.Conv2d(feature_dim, embed_dim, kernel_size=1)
self.the_embed = nn.Conv2d(feature_dim, embed_dim, kernel_size=1)
# Positional encoding
self.pos_encoder = nn.Parameter(torch.randn(1, 28*28, embed_dim)) # Assuming 28x28 feature map size
# Transformer blocks
self.self_att_rgb = TransformerBlock(embed_dim, num_heads, ff_dim)
self.self_att_the = TransformerBlock(embed_dim, num_heads, ff_dim)
self.cross_att_rgb = TransformerBlock(embed_dim, num_heads, ff_dim)
self.cross_att_the = TransformerBlock(embed_dim, num_heads, ff_dim)
# Learnable contribution matrices
self.M_r = nn.Parameter(torch.ones(1, 28*28, embed_dim))
self.M_t = nn.Parameter(torch.ones(1, 28*28, embed_dim))
def forward(self, y_rgb, y_the):
bs, c, h, w = y_rgb.shape
F_r = self.rgb_embed(y_rgb).flatten(2).permute(0, 2, 1) # (bs, h*w, embed_dim)
F_t = self.the_embed(y_the).flatten(2).permute(0, 2, 1) # (bs, h*w, embed_dim)
# Add positional encoding
F_r = F_r + self.pos_encoder[:, :h*w, :]
F_t = F_t + self.pos_encoder[:, :h*w, :]
# Self-attention
F_r_s = self.self_att_rgb(F_r)
F_t_s = self.self_att_the(F_t)
# Cross-attention
F_r_c = self.cross_att_rgb(F_r_s, context=F_t_s)
F_t_c = self.cross_att_the(F_t_s, context=F_r_s)
# Apply learnable matrices (Eq. 10)
alpha_r = F_r_c * self.M_r[:, :h*w, :] + F_r_c
alpha_t = F_t_c * self.M_t[:, :h*w, :] + F_t_c
# Concatenate and return
F_tilde = torch.cat([alpha_r, alpha_t], dim=2) # (bs, h*w, 2*embed_dim)
return F_tilde
class FusionBlock(nn.Module):
""" Fusion Block with Mini-Inception as shown in Figure 3(c). """
def __init__(self, in_channels):
super(FusionBlock, self).__init__()
self.conv_block1 = nn.Conv1d(in_channels, in_channels, kernel_size=3, padding=1)
self.conv_block2 = nn.Conv1d(in_channels, in_channels, kernel_size=3, padding=1)
# Mini-Inception module
self.inception_conv1 = nn.Conv1d(in_channels // 2, in_channels // 2, kernel_size=1)
self.inception_conv2 = nn.Conv1d(in_channels // 2, in_channels // 2, kernel_size=3, padding=1)
def forward(self, x):
x = F.relu(self.conv_block1(x))
x = F.relu(self.conv_block2(x))
# Mini-Inception
x1, x2 = torch.split(x, x.size(1) // 2, dim=1)
x1 = self.inception_conv1(x1)
x2 = self.inception_conv2(x2)
x = torch.cat([x1, x2], dim=1)
return x
class FusionEnhancementModule(nn.Module):
""" Fusion-Enhancement Module. (Figure 3(c)) """
def __init__(self, in_channels, num_blocks=3):
super(FusionEnhancementModule, self).__init__()
self.fusion_blocks = nn.ModuleList([FusionBlock(in_channels) for _ in range(num_blocks)])
self.se_nets = nn.ModuleList([SENet(in_channels) for _ in range(num_blocks)])
def forward(self, F_tilde):
# F_tilde shape: (bs, seq_len, channels) -> (bs, channels, seq_len) for Conv1d
x = F_tilde.permute(0, 2, 1)
for i in range(len(self.fusion_blocks)):
x_res = x
x = self.fusion_blocks[i](x)
x = self.se_nets[i](x)
x = x + x_res
return x.flatten(1) # Flatten to get the final zs vector
class SemanticFusionModule(nn.Module):
"""
Complete Semantic Fusion Module. (Figure 3(a))
"""
def __init__(self, feature_dim=1024, embed_dim=256, seq_len=28*28):
super().__init__()
self.cross_attention = CrossAttentionModule(feature_dim, embed_dim)
self.fusion_enhancement = FusionEnhancementModule(in_channels=2*embed_dim)
def forward(self, y_rgb, y_the):
F_tilde = self.cross_attention(y_rgb, y_the)
z_s = self.fusion_enhancement(F_tilde)
return z_s
class BitGenerator(nn.Module):
"""
Learnable Bit Generator using Gumbel-Softmax.
"""
def __init__(self, input_dim, output_len):
super().__init__()
self.fc = nn.Linear(input_dim, output_len * 2)
self.output_len = output_len
def forward(self, z_s, training=True):
logits = self.fc(z_s).view(-1, self.output_len, 2)
# Gumbel-Softmax trick for differentiable sampling
p_s = F.gumbel_softmax(logits, tau=1, hard=True, dim=-1)
# Get the discrete bits (0s and 1s)
b = p_s[:, :, 1] # Probability of being 1 gives the bit value
return b
class SemanticDecoder(nn.Module):
"""
Semantic Decoder to produce the final segmentation map. (Figure 2(b))
"""
def __init__(self, input_dim, num_classes=9):
super().__init__()
# This part needs to reconstruct spatial dimensions from the flat vector
self.initial_upsample = nn.Linear(input_dim, 1024 * 7 * 7) # Example size
self.layers = nn.ModuleList()
# Upsampling blocks
# from 7x7 -> 14x14 -> 28x28 -> 56x56 -> 112x112 -> 224x224 -> 448x480 (approx)
channels = [1024, 512, 256, 128, 64, 32]
for i in range(len(channels) - 1):
self.layers.append(self._make_upsample_block(channels[i], channels[i+1]))
self.final_conv = nn.ConvTranspose2d(channels[-1], num_classes, kernel_size=4, stride=2, padding=1)
# Adjust final size to 480x640 if needed with a final Conv or interpolation
def _make_upsample_block(self, in_channels, out_channels):
return nn.Sequential(
nn.ConvTranspose2d(in_channels, out_channels, kernel_size=4, stride=2, padding=1),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True),
nn.Conv2d(out_channels, out_channels, kernel_size=3, padding=1),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True),
)
def forward(self, x):
x = self.initial_upsample(x)
x = x.view(-1, 1024, 7, 7)
for layer in self.layers:
x = layer(x)
x = self.final_conv(x)
# Upsample to final image size (e.g., 480x640)
x = F.interpolate(x, size=(480, 640), mode='bilinear', align_corners=False)
return x
class PromptProjection(nn.Module):
""" Prompt projection module g() from Section III-D-1. """
def __init__(self, in_channels=1024, out_dim=256):
super().__init__()
self.conv_layers = nn.Sequential(
nn.Conv2d(in_channels * 2, in_channels, kernel_size=3, padding=1),
nn.ReLU(),
nn.Conv2d(in_channels, in_channels // 2, kernel_size=3, padding=1),
nn.ReLU()
)
self.pool = nn.AdaptiveAvgPool2d(1)
self.mlp = nn.Linear(in_channels // 2, out_dim)
def forward(self, y1, y2):
x = torch.cat([y1, y2], dim=1)
x = self.conv_layers(x)
x = self.pool(x).flatten(1)
v = self.mlp(x)
return v
# ==============================================================================
# The Complete ProMSC-MIS Model
# ==============================================================================
class ProMSC_MIS(nn.Module):
""" The complete ProMSC-MIS framework. """
def __init__(self, L_b=30720, num_classes=9, projection_dim=256):
super().__init__()
self.f_RGB = SemanticEncoder()
self.f_THE = SemanticEncoder()
self.f_SF = SemanticFusionModule()
# The input dim to the bit generator is the flattened output of fusion module
fusion_output_dim = 512 * 28 * 28
self.f_B = BitGenerator(fusion_output_dim, L_b)
self.f_D = SemanticDecoder(L_b, num_classes)
# Modules for pre-training
self.g_RGB = PromptProjection(out_dim=projection_dim)
self.g_THE = PromptProjection(out_dim=projection_dim)
def forward(self, x_r, x_t, training=True):
# End-to-end forward pass (Phase 2)
y_RGB_r = self.f_RGB(x_r)
y_THE_t = self.f_THE(x_t)
z_s = self.f_SF(y_RGB_r, y_THE_t)
b = self.f_B(z_s, training)
# Simulate BSC channel (in a real scenario, this happens outside the model)
# Here we assume an ideal channel for simplicity in the forward pass.
# Noise can be added during the training loop.
b_hat = b
m_hat = self.f_D(b_hat)
return m_hat
def pretrain_forward(self, x_r, x_t, x_r_prime, x_t_prime):
# Pre-training forward pass (Phase 1)
y_RGB_r = self.f_RGB(x_r)
y_THE_t = self.f_THE(x_t)
y_RGB_t = self.f_RGB(x_t_prime)
y_THE_r = self.f_THE(x_r_prime)
v_r = self.g_RGB(y_RGB_r, y_RGB_t)
v_t = self.g_THE(y_THE_t, y_THE_r)
return v_r, v_t
# ==============================================================================
# Loss Functions
# ==============================================================================
def pretrain_loss_fn(v_r, v_t):
""" Cosine similarity loss for pre-training (Eq. 15). """
v_r_norm = F.normalize(v_r, p=2, dim=1)
v_t_norm = F.normalize(v_t, p=2, dim=1)
return torch.abs(torch.sum(v_r_norm * v_t_norm, dim=1)).mean()
class DiceLoss(nn.Module):
""" Dice loss for segmentation task (Eq. 17). """
def __init__(self, smooth=1.0):
super(DiceLoss, self).__init__()
self.smooth = smooth
def forward(self, pred, target):
pred_softmax = F.softmax(pred, dim=1)
intersection = torch.sum(pred_softmax * target, dim=(2, 3))
union = torch.sum(pred_softmax, dim=(2, 3)) + torch.sum(target, dim=(2, 3))
dice = (2. * intersection + self.smooth) / (union + self.smooth)
return 1 - dice.mean()
class SoftCrossEntropyLoss(nn.Module):
""" Soft Cross-Entropy loss for segmentation task (Eq. 18). """
def __init__(self, num_classes, epsilon=0.1):
super(SoftCrossEntropyLoss, self).__init__()
self.num_classes = num_classes
self.epsilon = epsilon
def forward(self, pred, target):
# Target is one-hot encoded
log_probs = F.log_softmax(pred, dim=1)
soft_target = (1 - self.epsilon) * target + self.epsilon / self.num_classes
return -torch.sum(soft_target * log_probs, dim=1).mean()
def end_to_end_loss_fn(pred, target, num_classes, lambda_dice=0.5):
""" Combined loss for end-to-end training (Eq. 16). """
dice_loss = DiceLoss()(pred, target)
soft_ce_loss = SoftCrossEntropyLoss(num_classes)(pred, target)
return lambda_dice * dice_loss + (1 - lambda_dice) * soft_ce_loss
# ==============================================================================
# Training Simulation (Algorithm 1)
# ==============================================================================
def simulate_bsc_channel(b, flip_probability=0.01):
""" Simulates a Binary Symmetric Channel. """
noise = torch.rand_like(b) < flip_probability
b_hat = b.clone()
b_hat[noise] = 1 - b_hat[noise]
return b_hat
if __name__ == '__main__':
# --- Configuration ---
BATCH_SIZE = 2
IMG_HEIGHT = 480
IMG_WIDTH = 640
NUM_CLASSES = 9
BPP = 0.0703
L_b = int(BPP * IMG_HEIGHT * IMG_WIDTH) # Length of bit sequence
DEVICE = "cuda" if torch.cuda.is_available() else "cpu"
print(f"Using device: {DEVICE}")
print(f"Bit sequence length (L_b): {L_b}")
# --- Model Initialization ---
model = ProMSC_MIS(L_b=L_b, num_classes=NUM_CLASSES).to(DEVICE)
# --- Dummy Data ---
# RGB image (3 channels)
dummy_x_r = torch.randn(BATCH_SIZE, 3, IMG_HEIGHT, IMG_WIDTH).to(DEVICE)
# Thermal image (1 channel)
dummy_x_t = torch.randn(BATCH_SIZE, 1, IMG_HEIGHT, IMG_WIDTH).to(DEVICE)
# Ground truth segmentation map (one-hot encoded)
dummy_m = F.one_hot(torch.randint(0, NUM_CLASSES, (BATCH_SIZE, IMG_HEIGHT, IMG_WIDTH)), num_classes=NUM_CLASSES).permute(0, 3, 1, 2).float().to(DEVICE)
# Pre-processed images for pre-training prompts
dummy_x_r_prime = dummy_x_r.mean(dim=1, keepdim=True) # Grayscale
dummy_x_t_prime = dummy_x_t.repeat(1, 3, 1, 1) # 3-channel thermal
print("\n" + "="*50)
print("PHASE 1: PRE-TRAINING SIMULATION")
print("="*50)
# --- Phase 1: Pre-training ---
pretrain_params = (
list(model.f_RGB.parameters()) + list(model.f_THE.parameters()) +
list(model.g_RGB.parameters()) + list(model.g_THE.parameters())
)
optimizer_pretrain = torch.optim.Adam(pretrain_params, lr=1e-4)
optimizer_pretrain.zero_grad()
v_r, v_t = model.pretrain_forward(dummy_x_r, dummy_x_t, dummy_x_r_prime, dummy_x_t_prime)
loss_pretrain = pretrain_loss_fn(v_r, v_t)
loss_pretrain.backward()
optimizer_pretrain.step()
print(f"Pre-training forward pass successful.")
print(f" - v_r shape: {v_r.shape}")
print(f" - v_t shape: {v_t.shape}")
print(f" - Calculated Pre-training Loss: {loss_pretrain.item():.4f}")
print("\n" + "="*50)
print("PHASE 2: END-TO-END TRAINING SIMULATION")
print("="*50)
# --- Phase 2: End-to-end training ---
# In a real scenario, you would load the pre-trained f_RGB and f_THE weights here.
end_to_end_params = model.parameters() # Train all parameters
optimizer_e2e = torch.optim.Adam(end_to_end_params, lr=1e-4)
optimizer_e2e.zero_grad()
# Forward pass to get semantic features and bits
y_RGB_r = model.f_RGB(dummy_x_r)
y_THE_t = model.f_THE(dummy_x_t)
z_s = model.f_SF(y_RGB_r, y_THE_t)
b = model.f_B(z_s)
# Simulate channel
b_hat = simulate_bsc_channel(b, flip_probability=0.01)
# Decoder
m_hat = model.f_D(b_hat)
loss_e2e = end_to_end_loss_fn(m_hat, dummy_m, NUM_CLASSES)
loss_e2e.backward()
optimizer_e2e.step()
print(f"End-to-end forward pass successful.")
print(f" - z_s (fused features) shape: {z_s.shape}")
print(f" - b (bit sequence) shape: {b.shape}")
print(f" - m_hat (output segmentation) shape: {m_hat.shape}")
print(f" - Calculated End-to-End Loss: {loss_e2e.item():.4f}")
Related posts, You May like to read
- 7 Shocking Truths About Knowledge Distillation: The Good, The Bad, and The Breakthrough (SAKD)
- 7 Revolutionary Breakthroughs in Medical Image Translation (And 1 Fatal Flaw That Could Derail Your AI Model)
- DeepSPV: Revolutionizing 3D Spleen Volume Estimation from 2D Ultrasound with AI
- ACAM-KD: Adaptive and Cooperative Attention Masking for Knowledge Distillation
- GeoSAM2 3D Part Segmentation — Prompt-Controllable, Geometry-Aware Masks for Precision 3D Editing
- Probabilistic Smooth Attention for Deep Multiple Instance Learning in Medical Imaging
- A Knowledge Distillation-Based Approach to Enhance Transparency of Classifier Models
- Towards Trustworthy Breast Tumor Segmentation in Ultrasound Using AI Uncertainty