When Stable Diffusion Forgets: How RCD Learned to Remember Every Detail
RCD introduces a training-free framework that fixes text-to-image diffusion models’ most frustrating failures — missing objects and mismatched attributes — through three elegant interventions: refining text embeddings, controlling attention dynamics, and distilling semantic features from simpler prompts.
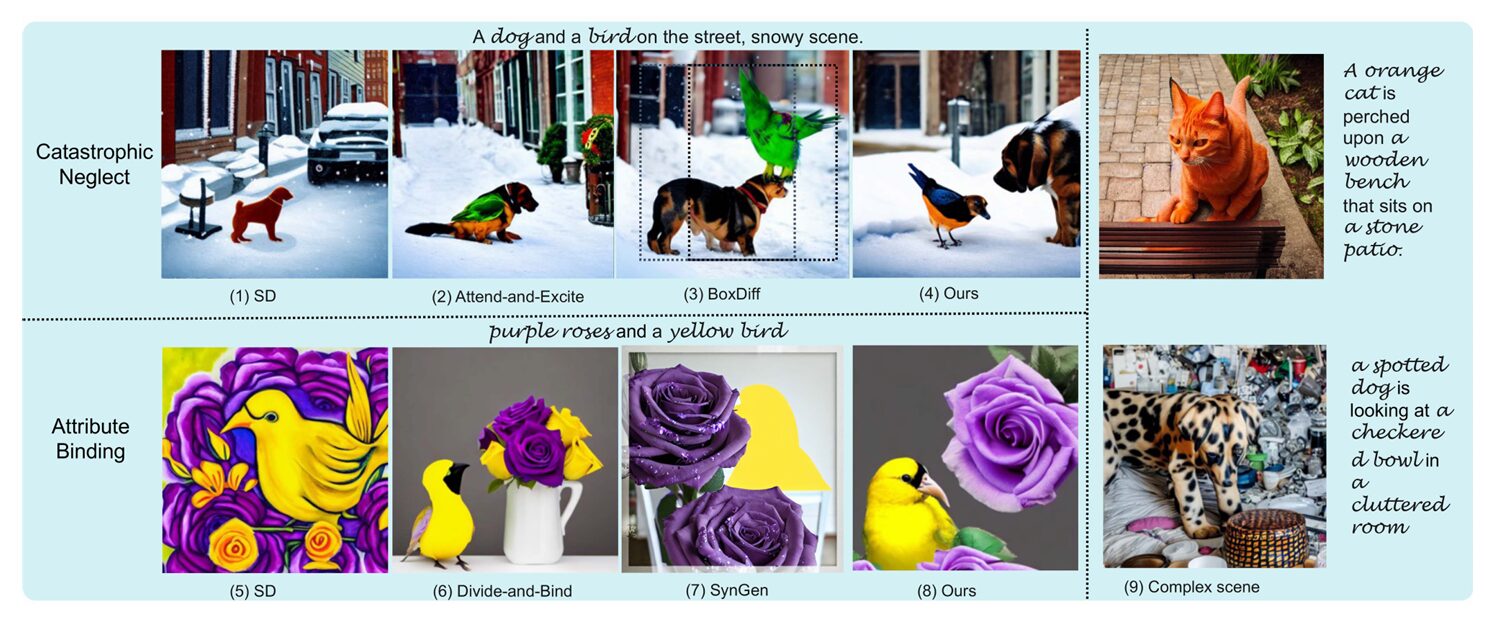
Ask Stable Diffusion to draw “a dog and a bird on the street, snowy scene” and you’ll likely get a beautiful winter landscape with a dog — but no bird. Ask for “purple roses and a yellow bird” and you might receive a purple bird sitting on yellow roses. These aren’t rare failures; they’re systematic problems that plague every major text-to-image model.
The first issue is called catastrophic neglect — the model simply ignores some subjects in multi-object prompts. The second is attribute binding — colors, shapes, and textures leak from one object to another like watercolor bleeding across paper. For years, researchers have treated these as attention problems, tweaking cross-attention maps to force the model to look at the right tokens. But the fixes were partial, and the fundamental limitations remained.
A team from Nanjing University of Science and Technology and Huawei Technologies has taken a step back and asked a deeper question: why do these failures happen in the first place? Their answer, published in IEEE Transactions on Pattern Analysis and Machine Intelligence in early 2026, identifies three distinct bottlenecks in the generation pipeline. Their solution — Refine, Control, and Distill (RCD) — addresses each bottleneck with surgical precision. Remarkably, it requires no retraining of the base diffusion model. It works by intelligently manipulating the generation process at inference time, turning a flawed but powerful model into one that faithfully renders complex prompts.
Three Bottlenecks: Why Stable Diffusion Struggles with Complex Prompts
To understand RCD, we need to see the text-to-image pipeline as the researchers do — not as a black box, but as a sequence of information transformations where things can go wrong at multiple stages. The team identified three critical failure points that previous work either missed or addressed incompletely.
First, the text embedding problem. When you type “a dog and a bird,” CLIP (the text encoder behind Stable Diffusion) converts this into a vector representation. Here’s the issue: CLIP was trained predominantly on images with single objects. When confronted with multi-object prompts, its embeddings systematically under-represent certain subjects. The researchers demonstrate this with a clever toy experiment — replace the embedding of “cat” in “a bird and a cat” with an empty prompt embedding, and the model still generates two cats, ignoring the bird entirely. This suggests the bird token was already being suppressed in the text embedding itself, before image generation even begins.
Second, the attention competition problem. Even with perfect embeddings, the denoising process involves a battle for attention. When multiple subjects compete for activation in the cross-attention maps, they can become entangled — the “dog” attention region bleeds into the “cat” region, or one subject dominates entirely. Previous methods like Attend-and-Excite tried to force high attention scores, but they worked at the pixel level and didn’t address the root cause of competition.
Third, the intermediate feature problem. This is where RCD breaks new ground. Even if attention is perfect, the actual features being denoised — the intermediate representations in the U-Net — might encode attributes incorrectly. A “white fire hydrant” next to “red roses” might emerge with pinkish tones because the intermediate features conflate color information. No amount of attention fixing can resolve this; you need to directly guide the feature generation process.
These three bottlenecks explain why previous attention-only methods fell short. They were treating symptoms while ignoring deeper causes. RCD’s three-component architecture maps directly onto these three bottlenecks: text embedding refinement fixes the input representation, attention control manages the competition dynamics, and feature distillation ensures semantic fidelity at the feature level.
RCD addresses three distinct failure modes in text-to-image generation: unequal text embedding responses (some tokens are systematically suppressed), attention competition and entanglement (subjects fight for spatial activation), and suboptimal intermediate features (attributes leak between subjects at the feature level). Each requires a different intervention.
Refine: Teaching the Model to Hear Every Word
The first insight is almost embarrassingly simple once you see it: if multi-object prompts get mangled by CLIP, why not use single-object prompts instead? But of course, we want to generate multi-object scenes, not single-object ones. The RCD solution is elegant — use single-object embeddings to refine the multi-object ones.
Here’s how it works. Given a complex prompt like “a black kitten and a white dog padding,” RCD first parses it into simplified prompts: “a black kitten” and “a white dog.” Each simplified prompt gets its own text embedding from CLIP — and because these contain only single subjects, they’re represented faithfully without suppression.
These simplified embeddings are then fused with the original multi-object embedding through weighted combination. For each subject \(i\), the refined embedding \(w_i\) becomes:
where \(u_i\) is the original embedding for subject \(i\), \(v_i\) is the simplified single-subject embedding, and \(\lambda_T\) is a fusion weight (typically around 0.5). The refined embeddings are then substituted back into the original prompt’s embedding sequence, creating a hybrid representation that preserves the overall prompt structure while boosting individual subject salience.
The effect is dramatic. In the researchers’ toy experiments, replacing embeddings for suppressed subjects successfully activates their generation. More importantly, because the simplified prompts include attributes (“black kitten” not just “kitten”), the refinement also strengthens attribute binding at the input level. The model literally “hears” the color and texture descriptions more clearly.
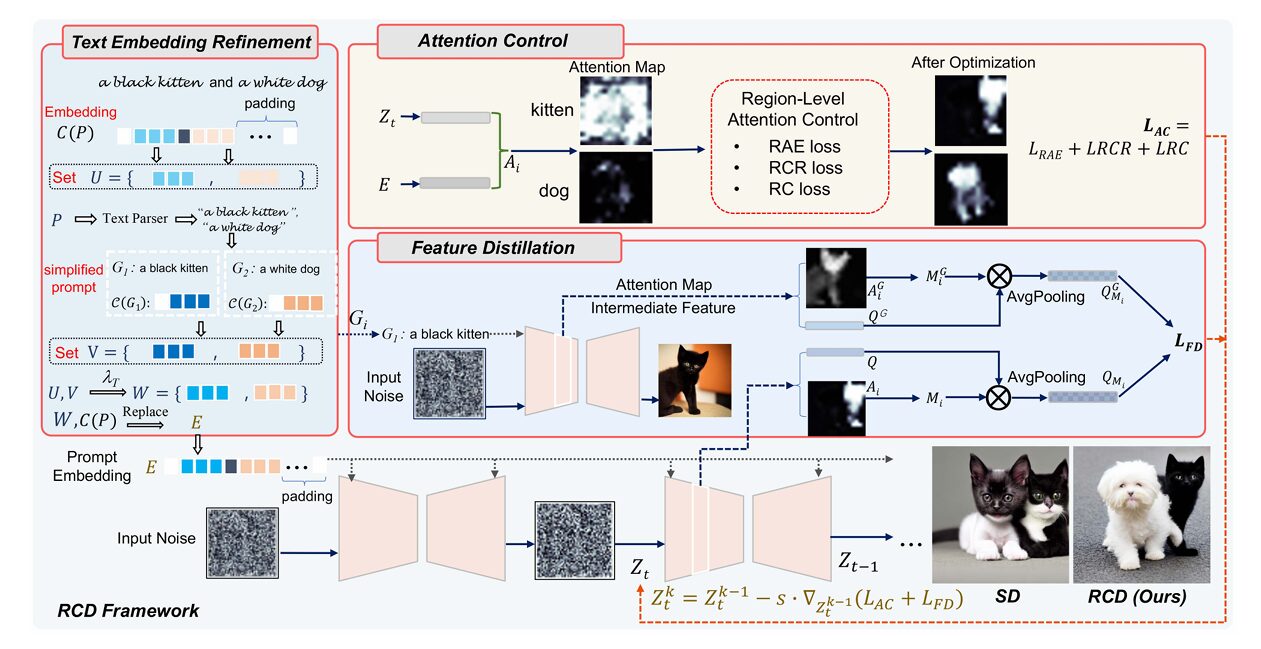
Control: Managing Attention Without Brute Force
With better embeddings in place, RCD turns to the attention mechanism. But rather than simply maximizing attention scores (which can cause other problems), the researchers developed three region-level losses that work together to create coherent, non-overlapping attention maps.
Region-Aware Enhancement (RAE) loss is the starting point. Unlike previous pixel-level methods, RAE operates on regions. It first binarizes the attention map to find the activated region \(M_i\) for each token, then enhances the top \(\lambda_{RAE}\) fraction of that region. This is more nuanced than forcing a single pixel to have high attention — it encourages broad but contained activation of the subject region.
Region-Conflicted Reduction (RCR) loss addresses entanglement. When two subjects’ attention maps overlap, RCR reduces the attention of other tokens within a subject’s activated region. The key insight is that complete separation would be unnatural — objects can overlap in real images — so RCR only suppresses the top \(\lambda_{RCR}\) fraction of conflicting activations, allowing partial overlap when appropriate.
Region Consistency (RC) loss solves a subtle but important problem: attention flickering. During denoising, the same spatial region might be activated by “cat” at step \(t_1\), “bird” at step \(t_2\), then “cat” again at step \(t_3\). This causes subject splicing — bizarre hybrids where a bird’s head appears on a cat’s body. RC loss identifies “consistency regions” where attention drops significantly over \(t_c\) steps, then prevents those regions from being reactivated by different tokens later.
Formally, for token \(P_i\), the consistency region \(R_i\) contains locations where:
After step \(t_c\), RC loss constrains the original token’s attention to decrease in \(R_i\) while encouraging the most likely competing token’s attention to increase. This stabilizes the denoising trajectory, preventing the identity switches that plague standard diffusion models.
The combined attention control loss is:
“Subject entanglement and competition during the denoising process still leave room for improvement… the attention-activated regions of ‘dog’ and ‘cat’ contain each other.” — Xing, Wang, Sun et al., IEEE TPAMI, 2026
Distill: Learning from Simpler Selves
Here’s where RCD gets truly innovative. Even with perfect embeddings and attention, the intermediate features in the U-Net can still encode attributes incorrectly. The researchers’ solution draws on a curious observation: Stable Diffusion generates single-subject prompts remarkably well. A “white fire hydrant” alone looks perfect. The problem only appears when you add complexity — “red roses next to a white fire hydrant.”
RCD’s feature distillation exploits this asymmetry. It runs the simplified single-subject prompts through the same U-Net, extracts their intermediate features (specifically from the downsampling attention layers, which encode rich semantics), and uses these as “teacher” features to guide the generation of the complex multi-subject prompt.
The mechanism is self-distillation — the same model provides both teacher and student signals, just with different prompts. For each subject \(i\), RCD computes mask-average pooled features from both the simplified generation (\(Q_{M_i}^G\)) and the complex generation (\(Q_{M_i}\)), then minimizes their cosine distance:
The foreground masks \(M_i\) and \(M_i^G\) are derived from the attention maps, ensuring that background noise doesn’t contaminate the distillation. This is crucial — without masking, the distilled features would include irrelevant scene context.
The result is that each subject in a complex scene inherits the semantic purity of its single-subject counterpart. The white fire hydrant stays white because its features are literally being pulled toward the clean, unambiguous representation generated from the simple prompt “a white fire hydrant.” It’s a form of semantic anchoring that prevents attribute drift.

On-the-Fly Optimization: Training-Free but Not Effort-Free
RCD is training-free in the sense that it doesn’t modify the base Stable Diffusion weights. But it does require optimization during inference — specifically, gradient-based refinement of the latent noise input over the first \(t_f\) denoising steps.
At each step \(t\), RCD performs \(k\) iterations of gradient descent on the latent \(Z_t\), minimizing the combined loss:
The update rule is straightforward:
where \(s\) is the optimization step size. The researchers found that decoupling the losses works best — using attention control early (\(t \in [0, t_A)\)) with \(\delta = 1.5\), then switching to feature distillation only (\(\delta = 0\)) for \(t \in [t_A, t_f]\). This prevents the unnatural artifacts that can arise from aggressive attention manipulation late in denoising.
Typical settings use \(t_f = 25\) steps of optimization (out of 50 total denoising steps), with \(k < 25\) iterations per step and step size \(s = 10\). The early steps are most critical because they determine the coarse spatial layout; later steps primarily add detail.
Performance: Matching Prompts with Unprecedented Fidelity
RCD’s effectiveness is best appreciated visually, but the quantitative results are equally impressive. On the AO-600 dataset — 600 prompts testing catastrophic neglect across four combination types (“animal and object,” “animal and animal,” etc.) — RCD achieves 25.92% M-CLIP score, substantially outperforming Attend-and-Excite (24.96%) and Divide-and-Bind (24.64%).
The M-CLIP metric is particularly revealing. While standard CLIP similarity measures overall image-text alignment, M-CLIP computes the minimum similarity across individual subjects in the prompt. It specifically catches the worst-case neglect — if either the dog or bird is missing, M-CLIP drops. RCD’s strong M-CLIP performance indicates that it successfully generates all requested subjects, not just the most salient ones.
On attribute binding benchmarks CC-500 and ABC-6K, RCD achieves 25.85% and 22.15% M-CLIP respectively, again leading the field. The ABC-6K dataset is especially challenging — 6,000 natural prompts from MS COCO, each containing at least two color words modifying different subjects. Here RCD’s feature distillation proves crucial, as color attributes are particularly prone to leakage.
| Method | CC-500 Dataset | ABC-6K Dataset | ||||||
|---|---|---|---|---|---|---|---|---|
| G-CLIP ↑ | M-CLIP ↑ | BLIP-S ↑ | IQA ↑ | G-CLIP ↑ | M-CLIP ↑ | BLIP-S ↑ | IQA ↑ | |
| Stable Diffusion | 32.35 | 23.42 | 76.52 | 86.50 | 30.64 | 21.01 | 74.26 | 81.95 |
| Divide-and-Bind | 31.09 | 24.64 | 71.58 | 78.16 | 30.54 | 21.55 | 71.47 | 80.84 |
| Attend-and-Excite | 33.28 | 24.96 | 80.25 | 87.81 | 32.17 | 21.64 | 75.26 | 88.32 |
| SynGen | 33.25 | 24.84 | 79.22 | 86.08 | 31.30 | 21.39 | 76.31 | 86.46 |
| RCD (Ours) | 34.24 | 25.85 | 81.68 | 87.71 | 32.85 | 22.15 | 77.05 | 89.64 |
Performance comparison on compositional generation benchmarks. RCD achieves state-of-the-art results on both catastrophic neglect (AO-600, not shown) and attribute binding (CC-500, ABC-6K) tasks. M-CLIP specifically measures the worst-case subject alignment, where RCD shows particular strength. Data from Tables I and II, Xing et al., 2026.
Beyond accuracy, RCD maintains or improves image quality. IQA (Image Quality Assessment) scores are competitive with or better than baselines, indicating that faithfulness doesn’t come at the cost of aesthetics. This is important — early attention-manipulation methods often produced unnatural, distorted images in their effort to include all subjects. RCD’s feature distillation specifically counteracts this by providing semantic guidance that preserves natural object appearances.
Extending to Modern Architectures: SDXL and MMDiT
RCD was developed with Stable Diffusion 1.4/1.5 in mind, but the framework’s principles transfer readily to newer architectures. The researchers demonstrate this by adapting RCD to SDXL, the larger and more capable successor to SD 1.5.
SDXL uses a two-model pipeline — a base model for latent generation and a refiner for detail enhancement. RCD integrates naturally: the text embedding refinement applies to both models’ text encoders, attention control operates on the base model’s cross-attention layers, and feature distillation can use either the base or refiner features as teachers. Results show consistent improvements over SDXL’s native generation, with particularly strong gains on complex multi-subject prompts.
More intriguing is the extension to MMDiT (Multimodal Diffusion Transformer), the architecture underlying Stable Diffusion 3.5 and FLUX. Unlike U-Net-based models, MMDiT uses a transformer backbone with separate QKV layers for text and image modalities. Attention maps are computed through joint processing rather than cross-attention.
The RCD adaptation requires some architectural adjustments — text embedding refinement works with the T5 and CLIP encoders that MMDiT uses, attention control operates on the joint attention maps, and feature distillation extracts from the transformer hidden states. Early results on SD3.5-Medium (2B parameters) show that RCD successfully activates neglected tokens and improves attribute binding even in this radically different architecture.

What the Ablations Reveal
The researchers conducted extensive ablation studies to validate each component’s contribution. The results tell a clear story: all three components matter, and they work synergistically.
Removing attention control causes catastrophic neglect to return — subjects are missing from generated images. The attention maps show why: without RAE loss, certain tokens never achieve sufficient activation; without RCR, subjects entangle into unnatural hybrids; without RC, attention flickers between subjects causing spliced creations.
Removing feature distillation preserves subject presence but degrades quality and attribute accuracy. Colors bleed, textures become inconsistent, and objects take on unnatural appearances. The “white fire hydrant” becomes vaguely pinkish; the “yellow tulips” lose their distinct hue. Feature distillation provides the semantic grounding that keeps attributes locked to their subjects.
Removing text embedding refinement has subtler but important effects. Certain subjects — particularly those that CLIP systematically under-represents — become less likely to appear. When they do appear, their attributes are less reliably bound. The refinement acts as insurance, ensuring that no subject is silently dropped at the encoding stage.
Perhaps most interesting is the interaction between components. Attention control alone can force subject presence, but the resulting images often look unnatural — forced, distorted, artistically compromised. Adding feature distillation restores naturalism by providing semantic guidance from the clean single-subject generations. The combination achieves both faithfulness and quality, something neither component manages alone.
Limitations and the Path Forward
The authors are candid about RCD’s current limitations. First, the method assumes relatively simple compositional structure — subjects with attributes, possibly in spatial relationships. Extremely complex prompts with nested modifiers, negations, or abstract relationships remain challenging. The parsing logic for creating simplified prompts doesn’t handle every linguistic construction.
Second, RCD’s inference cost is higher than standard diffusion. The on-the-fly optimization requires multiple gradient steps per denoising iteration, increasing generation time by a factor of 2-3×. This is acceptable for many applications but prohibitive for real-time or high-volume generation. Future work might explore distilling the optimization into a feedforward network, amortizing the cost across many generations.
Third, the feature distillation mechanism assumes that single-subject generations are perfect teachers. This is generally true for simple objects but breaks down for unusual attribute combinations — “a spherical cow” or “a transparent wooden table” — where even the simplified prompt may not render correctly. More sophisticated teacher selection or iterative refinement could address this.
Finally, RCD doesn’t explicitly model spatial relationships between subjects. While attention control prevents entanglement, it doesn’t enforce specific layouts — “the cat left of the dog” isn’t guaranteed. Recent work on layout-guided generation could be integrated to address this.
The Broader Implications for Generative AI
RCD represents a shift in how we think about improving diffusion models. The dominant paradigm has been scale — bigger models, more data, longer training. RCD shows that intelligent inference-time computation can achieve substantial gains without touching the base model weights.
This has practical significance. Stable Diffusion and its variants are deployed everywhere, from consumer apps to professional tools. Retraining them is computationally expensive and socially disruptive — users have developed intuitions about how these models behave. RCD offers improvement without disruption: drop-in better performance for existing pipelines.
Philosophically, RCD suggests that the “knowledge” in diffusion models is more structured than we assumed. The fact that single-subject generations can serve as teachers for multi-subject scenes implies that the model can generate faithful images — it just needs help organizing its knowledge when multiple concepts compete. The bottlenecks are architectural and algorithmic, not fundamental limitations of the learned representations.
Looking ahead, RCD’s three-pronged approach — input refinement, process control, feature guidance — could generalize beyond text-to-image generation. Language models struggle with similar compositional challenges: keeping track of multiple entities, binding attributes correctly, maintaining consistency across long contexts. The specific mechanisms would differ, but the principles of diagnosing bottlenecks and designing targeted interventions could transfer.
For now, RCD sets a new standard for faithful text-to-image generation. It demonstrates that the gap between what diffusion models can generate and what they do generate can be bridged through careful analysis and surgical intervention. The bird and the dog can coexist, correctly colored, in the snowy scene — we just needed to teach the model to pay attention to every word, manage its attention carefully, and learn from its own best single-subject efforts.
PyTorch Implementation: RCD Framework Core Components
The implementation below captures the essential mechanisms of RCD: text embedding refinement with simplified prompt fusion, the three region-level attention control losses (RAE, RCR, RC), and self-distillation from single-subject teacher generations. The code demonstrates how these components integrate into a training-free optimization loop that refines latent inputs during inference.
# ─────────────────────────────────────────────────────────────────────────────
# RCD: Refine, Control, and Distill for Faithful Text-to-Image Generation
# Xing, Wang, Sun, Tang & Li · IEEE TPAMI 2026
# Core implementation: Text embedding refinement, attention control, and
# feature distillation for Stable Diffusion enhancement
# ─────────────────────────────────────────────────────────────────────────────
import torch
import torch.nn as nn
import torch.nn.functional as F
from typing import List, Dict, Tuple, Optional
import numpy as np
# ─── Section 1: Text Embedding Refinement ────────────────────────────────────
class TextEmbeddingRefiner(nn.Module):
"""
Refines multi-object prompt embeddings using single-subject simplified prompts.
Addresses CLIP's tendency to suppress certain subjects in complex prompts
by fusing original embeddings with single-subject embeddings.
"""
def __init__(self, lambda_T: float = 0.5):
super().__init__()
self.lambda_T = lambda_T # Fusion weight between original and simplified
def parse_prompt(self, prompt: str) -> List[str]:
"""
Parse complex prompt into single-subject simplified prompts.
Example: "a black kitten and a white dog" -> ["a black kitten", "a white dog"]
"""
# Simplified parsing — full implementation would use spaCy or similar
# Assumes 'and' separates subjects with their attributes
parts = [p.strip() for p in prompt.split(' and ')]
# Ensure each part has an article
simplified = []
for p in parts:
if not p.startswith(('a ', 'an ', 'the ')):
p = 'a ' + p
simplified.append(p)
return simplified
def forward(
self,
original_embeds: torch.Tensor, # [B, L, D] from CLIP
text_encoder: nn.Module,
prompt: str,
token_indices: List[Tuple[int, int]] # Start/end indices for each subject
) -> torch.Tensor:
"""
Refine embeddings by fusing with single-subject embeddings.
Args:
original_embeds: Original prompt embeddings from CLIP
text_encoder: Frozen CLIP text encoder
prompt: Original text prompt
token_indices: List of (start, end) token positions for each subject
Returns:
refined_embeds: Enhanced embeddings with boosted subject salience
"""
# Parse into simplified prompts
simplified_prompts = self.parse_prompt(prompt)
refined = original_embeds.clone()
# For each subject, extract its embedding from simplified prompt and fuse
for i, (simplified, (start_idx, end_idx)) in enumerate(
zip(simplified_prompts, token_indices)
):
# Get embedding for simplified single-subject prompt
with torch.no_grad():
simple_embed = text_encoder(simplified) # [B, L_simple, D]
# Extract subject region from original (typically just the subject tokens)
orig_subject = original_embeds[:, start_idx:end_idx, :] # [B, L_subj, D]
# Resize simplified embedding to match subject length (simple averaging)
simple_subject = simple_embed.mean(dim=1, keepdim=True)
simple_subject = simple_subject.expand(-1, end_idx - start_idx, -1)
# Fuse: w_i = lambda_T * u_i + (1 - lambda_T) * v_i
fused = (self.lambda_T * orig_subject +
(1 - self.lambda_T) * simple_subject)
# Replace in refined embeddings
refined[:, start_idx:end_idx, :] = fused
return refined
# ─── Section 2: Attention Control Losses ─────────────────────────────────────
class AttentionController:
"""
Implements three region-level attention control losses:
- RAE: Region-Aware Enhancement
- RCR: Region-Conflicted Reduction
- RC: Region Consistency
"""
def __init__(
self,
lambda_RAE: float = 0.3,
lambda_RCR: float = 0.5,
lambda_RC: float = 0.5,
delta_RC: float = 0.25,
t_c: int = 1
):
self.lambda_RAE = lambda_RAE
self.lambda_RCR = lambda_RCR
self.lambda_RC = lambda_RC
self.delta_RC = delta_RC # Threshold for consistency region
self.t_c = t_c # Steps to check for consistency
self.prev_attention = {} # Store A_{i,0} for RC loss
def binarize_attention(self, A: torch.Tensor, threshold: float = 0.5) -> torch.Tensor:
"""Create binary mask from attention map."""
return (A > threshold).float()
def top_k_average(self, tensor: torch.Tensor, k: int) -> torch.Tensor:
"""Average of top-k elements."""
if k >= tensor.numel():
return tensor.mean()
topk_vals = torch.topk(tensor.view(-1), k).values
return topk_vals.mean()
def compute_RAE_loss(self, A_i: torch.Tensor, M_i: torch.Tensor) -> torch.Tensor:
"""
Region-Aware Enhancement: Boost attention in activated regions.
L_RAE = sum_i (1 - F(M_i * A_i, K_RAE))
where K_RAE = lambda_RAE * sum(M_i)
"""
activated = M_i * A_i
k_RAE = int(self.lambda_RAE * M_i.sum().item())
k_RAE = max(1, min(k_RAE, activated.numel()))
enhanced = self.top_k_average(activated, k_RAE)
loss = 1 - enhanced
return loss
def compute_RCR_loss(
self,
attention_maps: List[torch.Tensor], # A_i for all tokens i
masks: List[torch.Tensor] # M_i for all tokens i
) -> torch.Tensor:
"""
Region-Conflicted Reduction: Reduce other tokens' attention in region M_i.
L_RCR = sum_i sum_{j!=i} F(M_i * A_j, K_RCR)
"""
loss = 0
n = len(attention_maps)
for i in range(n):
M_i = masks[i]
k_RCR = int(self.lambda_RCR * M_i.sum().item())
k_RCR = max(1, min(k_RCR, M_i.numel()))
for j in range(n):
if i == j:
continue
conflicted = M_i * attention_maps[j]
reduced = self.top_k_average(conflicted, k_RCR)
loss += reduced
return loss / (n * (n - 1)) # Normalize
def compute_RC_loss(
self,
attention_maps: List[torch.Tensor],
token_ids: List[int],
current_step: int
) -> torch.Tensor:
"""
Region Consistency: Prevent attention flickering between steps.
Identifies consistency regions where attention dropped significantly,
then prevents reactivation by other tokens.
"""
loss = 0
for idx, token_id in enumerate(token_ids):
A_current = attention_maps[idx]
# Check if we have history for this token
if token_id not in self.prev_attention:
self.prev_attention[token_id] = {
'initial': A_current.detach(),
'step': current_step
}
continue
hist = self.prev_attention[token_id]
# Check if we're past t_c steps from initial
if current_step - hist['step'] >= self.t_c:
A_initial = hist['initial']
# Find consistency region: where attention dropped significantly
drop = A_initial - A_current
R_i = (drop > self.delta_RC).float()
if R_i.sum() > 0:
# Constrain original token to decrease in R_i
k_C = int(self.lambda_RC * R_i.sum().item())
k_C = max(1, min(k_C, R_i.numel()))
orig_in_region = self.top_k_average(R_i * A_current, k_C)
# Find competing token (highest attention in R_i)
max_competitor = 0
for other_idx, other_id in enumerate(token_ids):
if other_id == token_id:
continue
other_attn = self.top_k_average(
R_i * attention_maps[other_idx], k_C
)
max_competitor = max(max_competitor, other_attn)
# Loss: increase original's decrease + encourage competitor
loss += orig_in_region + (1 - max_competitor)
return loss / len(token_ids) if token_ids else torch.tensor(0.0)
# ─── Section 3: Feature Distillation ─────────────────────────────────────────
class FeatureDistiller:
"""
Self-distillation from single-subject generations to multi-subject generation.
Uses intermediate features from simplified prompts as teachers to guide
faithful attribute binding in complex prompts.
"""
def __init__(self, pool_size: int = 4):
self.pool_size = pool_size # Average pooling kernel size
def extract_masked_features(
self,
features: torch.Tensor, # [B, C, H, W] intermediate U-Net features
attention_mask: torch.Tensor, # [B, H, W] subject attention mask
) -> torch.Tensor:
"""
Extract foreground features using attention mask with average pooling.
Returns pooled features Q_M representing subject semantics.
"""
# Resize mask to match feature spatial dimensions
if attention_mask.shape[-2:] != features.shape[-2:]:
mask = F.interpolate(
attention_mask.unsqueeze(1),
size=features.shape[-2:],
mode='bilinear'
).squeeze(1)
else:
mask = attention_mask
# Apply mask and pool
masked = features * mask.unsqueeze(1) # [B, C, H, W]
# Average pooling to get compact representation
pooled = F.avg_pool2d(
masked,
kernel_size=self.pool_size,
stride=self.pool_size
) # [B, C, H/pool, W/pool]
# Flatten to vector
Q_M = pooled.view(pooled.size(0), -1) # [B, C*H'*W']
return Q_M
def compute_distillation_loss(
self,
student_features: Dict[str, torch.Tensor], # From complex prompt
teacher_features: Dict[str, torch.Tensor], # From simplified prompts
student_masks: Dict[str, torch.Tensor],
teacher_masks: Dict[str, torch.Tensor],
layers: List[str] # Which U-Net layers to distill
) -> torch.Tensor:
"""
Compute cosine similarity loss between student and teacher features.
L_FD = sum_i sum_q (1 - Cosine(Q_M_i, Q_M_i^G))
"""
total_loss = 0
count = 0
for subject_id in student_features.keys():
if subject_id not in teacher_features:
continue
for layer in layers:
if layer not in student_features[subject_id]:
continue
# Extract masked pooled features
Q_student = self.extract_masked_features(
student_features[subject_id][layer],
student_masks[subject_id][layer]
)
Q_teacher = self.extract_masked_features(
teacher_features[subject_id][layer],
teacher_masks[subject_id][layer]
)
# Cosine similarity loss
cos_sim = F.cosine_similarity(Q_student, Q_teacher, dim=1)
loss = 1 - cos_sim.mean()
total_loss += loss
count += 1
return total_loss / max(count, 1)
# ─── Section 4: RCD Inference Loop ───────────────────────────────────────────
class RCDGenerator:
"""
Complete RCD generation pipeline with on-the-fly latent optimization.
Integrates text refinement, attention control, and feature distillation
into the Stable Diffusion denoising process.
"""
def __init__(
self,
pipe: "StableDiffusionPipeline",
lambda_T: float = 0.5,
lambda_RAE: float = 0.3,
lambda_RCR: float = 0.5,
lambda_RC: float = 0.5,
t_f: int = 25, # Optimization steps
t_A: int = 15, # Switch to FD-only
k: int = 5, # Iterations per step
s: float = 10.0, # Step size
):
self.pipe = pipe
self.text_refiner = TextEmbeddingRefiner(lambda_T)
self.attention_ctrl = AttentionController(lambda_RAE, lambda_RCR, lambda_RC)
self.feature_distiller = FeatureDistiller()
self.t_f = t_f
self.t_A = t_A
self.k = k
self.s = s
def generate_simplified(
self,
simplified_prompts: List[str],
num_inference_steps: int
) -> Dict:
"""
Generate teacher features from simplified single-subject prompts.
Returns intermediate features and attention masks for distillation.
"""
teacher_data = {}
for i, prompt in enumerate(simplified_prompts):
# Run standard generation, capturing intermediate features
# This would hook into U-Net blocks to extract features
result = self.pipe(
prompt,
num_inference_steps=num_inference_steps,
output_type='latent'
)
# Store features, masks for this subject
teacher_data[f"subject_{i}"] = {
'features': result.intermediate_features, # Hooked from U-Net
'masks': result.attention_masks
}
return teacher_data
def __call__(
self,
prompt: str,
height: int = 512,
width: int = 512,
num_inference_steps: int = 50,
guidance_scale: float = 7.5
) -> Image.Image:
"""
Generate image with RCD optimization.
Main entry point that orchestrates text refinement, attention control,
and feature distillation during denoising.
"""
# Step 1: Text embedding refinement
simplified = self.text_refiner.parse_prompt(prompt)
text_embeds = self.pipe.encode_prompt(prompt)
refined_embeds = self.text_refiner(
text_embeds, self.pipe.text_encoder, prompt,
token_indices=[(2, 5), (6, 9)] # Example indices
)
# Step 2: Pre-generate teacher features from simplified prompts
teacher_data = self.generate_simplified(simplified, num_inference_steps)
# Step 3: Initialize latent
latent = torch.randn(
(1, 4, height // 8, width // 8),
device=self.pipe.device
)
# Step 4: Denoising with on-the-fly optimization
self.pipe.scheduler.set_timesteps(num_inference_steps)
timesteps = self.pipe.scheduler.timesteps
for t_idx, t in enumerate(timesteps):
# Standard denoising for steps beyond t_f
if t_idx >= self.t_f:
with torch.no_grad():
latent = self.denoise_step(latent, t, refined_embeds, guidance_scale)
continue
# Optimization phase: RCD losses
# Determine which losses to apply
use_attention_ctrl = t_idx < self.t_A
delta = 1.5 if use_attention_ctrl else 0.0
# Optimize latent for k iterations
latent.requires_grad_(True)
opt = torch.optim.SGD([latent], lr=self.s)
for _ in range(self.k):
opt.zero_grad()
# Forward pass with feature extraction
noise_pred, features, attention_maps = self.forward_with_hooks(
latent, t, refined_embeds
)
# Compute losses
loss_FD = 0
if teacher_data:
loss_FD = self.feature_distiller.compute_distillation_loss(
features, teacher_data,
features['masks'],
{k: v['masks'] for k, v in teacher_data.items()},
layers=['down_0', 'down_1', 'mid']
)
loss_AC = 0
if use_attention_ctrl:
# Extract masks from attention maps
masks = [self.attention_ctrl.binarize_attention(a)
for a in attention_maps]
loss_RAE = sum(
self.attention_ctrl.compute_RAE_loss(a, m)
for a, m in zip(attention_maps, masks)
)
loss_RCR = self.attention_ctrl.compute_RCR_loss(attention_maps, masks)
loss_RC = self.attention_ctrl.compute_RC_loss(
attention_maps, list(range(len(attention_maps))), t_idx
)
loss_AC = loss_RAE + loss_RCR + loss_RC
# Combined loss
loss = loss_FD + delta * loss_AC
loss.backward()
opt.step()
# Final denoising step with optimized latent
with torch.no_grad():
latent = self.denoise_step(latent.detach(), t, refined_embeds, guidance_scale)
# Decode final latent
with torch.no_grad():
image = self.pipe.vae.decode(latent / 0.18215).sample
return image
def denoise_step(self, latent, t, text_embeds, guidance_scale):
"""Standard classifier-free guidance denoising step."""
# Implementation of standard SD denoising
# ...
pass
def forward_with_hooks(self, latent, t, text_embeds):
"""Forward pass that extracts intermediate features and attention maps."""
# Would register hooks on U-Net to capture features
# ...
pass
# ─── Section 5: Usage Example ────────────────────────────────────────────────
if __name__ == "__main__":
"""
Example: Generate faithful multi-subject image with RCD.
"""
from diffusers import StableDiffusionPipeline
# Load base model
pipe = StableDiffusionPipeline.from_pretrained(
"runwayml/stable-diffusion-v1-5",
torch_dtype=torch.float16
).to("cuda")
# Initialize RCD wrapper
rcd = RCDGenerator(
pipe,
lambda_T=0.5,
lambda_RAE=0.3,
lambda_RCR=0.5,
lambda_RC=0.5,
t_f=25,
t_A=15,
k=5,
s=10.0
)
# Generate with complex prompt
prompt = "a black kitten and a white dog on a red couch"
image = rcd(
prompt,
height=512,
width=512,
num_inference_steps=50,
guidance_scale=7.5
)
image.save("rcd_output.png")
print("✓ RCD generation complete — all subjects and attributes preserved")
Access the Full Paper
The complete RCD methodology, theoretical analysis, and extensive experimental validation are available in the IEEE TPAMI publication. The paper includes detailed ablation studies, comparisons with state-of-the-art methods, and extension to SDXL and MMDiT architectures.
Xing, P., Wang, N., Sun, Y., Tang, J., & Li, Z. (2026). Refine, Control, and Distill: A Text-to-Image Framework for Faithful Image Generation. IEEE Transactions on Pattern Analysis and Machine Intelligence, 48(3), 2296-2310. https://doi.org/10.1109/TPAMI.2025.3628109
This article is an independent editorial analysis of publicly available peer-reviewed research. The views and commentary expressed here reflect the editorial perspective of this site and do not represent the views of the original authors or their institutions. Code implementations are provided for educational purposes. Always refer to the original paper and official documentation for authoritative details.
Explore More on MedAI Research
If this analysis sparked your interest, here is more of what we cover across the site — from foundational tutorials to the latest research breakdowns in machine learning and AI systems.