Introduction: A Critical Need for Advanced Skin Cancer Detection
Skin cancer is one of the most common and deadly forms of cancer worldwide. According to the Skin Cancer Foundation , 1 in 5 Americans will develop skin cancer in their lifetime , and melanoma alone accounts for more deaths than all other skin cancers combined . The urgency for early, accurate diagnosis has never been greater.
Traditional diagnostic methods rely heavily on dermatologists’ visual assessments, which can be time-consuming and prone to human error—especially when distinguishing between benign and malignant lesions with subtle differences. Enter artificial intelligence (AI) and deep learning, which have revolutionized medical diagnostics by enabling faster, more precise detection of diseases like skin cancer.
In this article, we explore how a groundbreaking convolutional neural network called SPCB-Net is setting new benchmarks in skin cancer image classification using multi-scale feature fusion , self-interactive attention pyramids , and cross-layer bilinear-trilinear pooling .
The Challenge: Why Traditional Methods Fall Short
Despite advancements in AI-assisted diagnostics, existing models face several limitations:
- Small inter-class feature differences : Many skin lesions look visually similar, making it hard for even advanced CNNs to distinguish between them.
- Large intra-class variations : Lesions from the same category can vary significantly in appearance due to lighting, texture, or patient-specific factors.
- Loss of detail in deeper layers : As networks go deeper, they lose spatial resolution, reducing their ability to detect fine-grained features.
These issues result in suboptimal classification performance and limit the generalization of models across different datasets.
Enter SPCB-Net: A Multi-Scale Revolution in Skin Cancer Detection
A recent research paper titled “SPCB-Net: A Multi-Scale Skin Cancer Image Identification Network Using Self-Interactive Attention Pyramid and Cross-Layer Bilinear-Trilinear Pooling” presents a novel deep learning architecture designed specifically to address these challenges.
✅ Key Features of SPCB-Net:
- Self-Interactive Attention Pyramid (SAP) – Enhances multi-scale feature extraction.
- Cross-Layer Bilinear-Trilinear Pooling – Captures high-order interactions across layers.
- SK Feature Pyramid (SK-FP) – Dynamically adjusts receptive fields for better detail preservation.
- Global Average Algorithm (GAA) – Ensures robust final classification results.
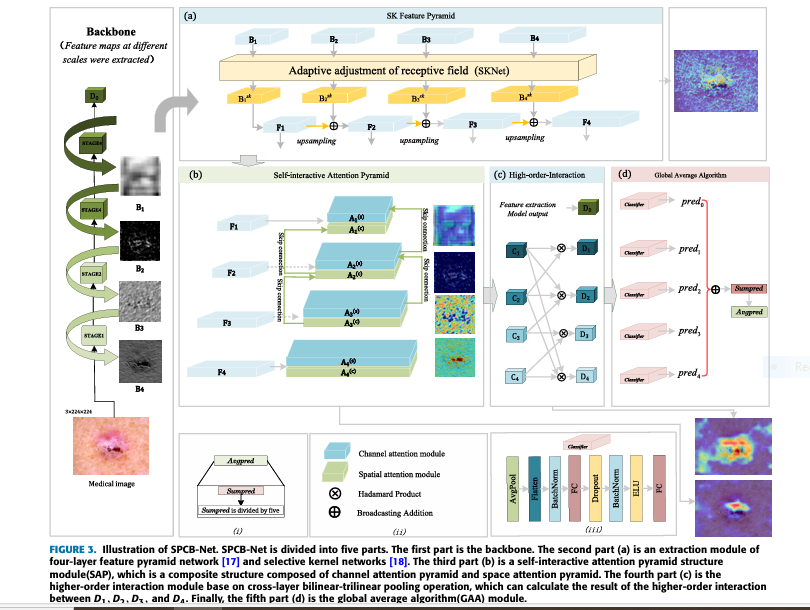
How SPCB-Net Works: Breaking Down the Architecture
Let’s dive into the core components of the SPCB-Net model and understand how each contributes to its superior performance.
1. SK Feature Pyramid (SK-FP): Dynamic Receptive Field Adjustment
Traditional feature pyramids use uniform convolution kernels across scales, often leading to loss of important details. SPCB-Net introduces the Selective Kernel Feature Pyramid (SK-FP) , which dynamically adjusts the receptive field size based on input characteristics.
This allows the model to:
- Preserve spatial resolution at lower levels.
- Capture rich semantic information at higher levels.
- Avoid over-smoothing and retain critical lesion boundaries.
Equation 1: SK Module Output
$$B_{sik} = \text{SK}(B_i)$$
Where:
- Bi : Input feature map at scale i
- Bsik : Adjusted feature map after applying SK module
2. Self-Interactive Attention Pyramid (SAP): Focusing on What Matters
To improve feature reliability and reduce background noise, SPCB-Net employs the Self-Interactive Attention Pyramid (SAP) . This module combines:
- Spatial Attention Pyramid
- Channel Attention Pyramid
- Skip Connections from low-level to high-level features
By integrating both spatial and channel-wise attention mechanisms, SAP enables the model to focus on key lesion areas while suppressing irrelevant background regions.
Equation 2: Spatial Attention Mask
$$A_n^{(s)} = \sigma(f_{3\times3}(S_c))$$
Equation 3: Channel Attention Mask
$$A_n^{(c)} = \sigma(W_2\cdot\text{ReLU}(W_1\cdot\text{AvgPool}(F_n)))$$
Where:
- σ : Sigmoid activation function
- f3×3 : Convolution operation
- W1,W2 : Learnable weights
3. Cross-Layer Bilinear-Trilinear Pooling: Capturing Long-Range Dependencies
High-order feature interactions are crucial for distinguishing subtle differences between skin lesions. SPCB-Net introduces a hybrid pooling mechanism that combines:
- Bilinear pooling – for second-order feature interactions
- Trilinear pooling – for third-order feature interactions
This cross-layer approach enhances the model’s ability to learn complex, non-linear relationships between features extracted from different layers.
Equation 4: Bilinear Pooling Operation
$$
D_p = \text{AvgPool}(C_a \otimes C_b)
$$
Equation 5: Trilinear Pooling Operation
$$
D_q = \text{AvgPool}(C_c \otimes C_d \otimes C_e)
$$
Where:
- ⊗ : Hadamard product
- Ca,Cb,Cc,Cd,Ce : Feature maps from different layers
4. Global Average Algorithm (GAA): Final Classification Refinement
Finally, the Global Average Algorithm (GAA) aggregates predictions from multiple classifiers to produce the final output. This ensemble-like method improves robustness and reduces overfitting.
$$\text{Avgpred} = \frac{\sum_{k=0}^{4} \text{pred}_k}{5}$$
Where:
- predk : Prediction from the k -th classifier
Performance Evaluation: How SPCB-Net Stacks Up
SPCB-Net was evaluated on two widely-used skin cancer datasets:
- HAM10000 – Contains 10,015 dermoscopy images across 7 skin disease categories.
- NCT-CRC-HE-100K – Contains 100,000 histopathology images across 9 tissue types.
📊 Results Summary:
| DATASET | MODEL | ACCURACY |
|---|---|---|
| HAM10000 | State-of-the-Art | 96.7% |
| HAM10000 | SPCB-Net (ResNet101) | 97.1%✅ |
| NCT-CRC-HE-100K | State-of-the-Art | 99.47% |
| NCT-CRC-HE-100K | SPCB-Net (ResNet101) | 99.87%✅ |
SPCB-Net achieves state-of-the-art performance , outperforming existing models by +0.4% accuracy on both datasets.
Why SPCB-Net Is a Game-Changer
Here are the top reasons why SPCB-Net represents a significant leap forward in skin cancer detection:
- Improved Feature Discrimination – Through SAP and SK-FP, the model learns discriminative features at multiple scales.
- Enhanced Generalization – Demonstrated strong performance on both dermatoscopic and histopathological images.
- Efficient Computation – Hybrid bilinear-trilinear pooling balances accuracy and computational cost.
- Robust Final Classification – GAA ensures reliable decision-making through multi-classifier consensus.
Real-World Applications and Future Potential
Beyond skin cancer detection, SPCB-Net holds promise in broader medical imaging tasks such as:
- Breast cancer detection
- Diabetic retinopathy screening
- Lung nodule classification
- Colorectal tumor analysis
Its modular design also makes it adaptable for integration into hospital PACS systems and telemedicine platforms.
If you’re Interested in deep learning based Knowledge distillation model, you may also find this article helpful: 7 Breakthrough Lessons from EmoVLM-KD: How Combining AI Models Can Dramatically Boost Emotion Recognition AI Accuracy
Conclusion: The Future of Medical Imaging is Here
SPCB-Net represents a major milestone in the application of AI to dermatology and pathology. By combining multi-scale feature fusion , attention-based interaction , and advanced pooling techniques , it delivers unparalleled accuracy in skin cancer image classification.
For healthcare providers, researchers, and tech developers, adopting and refining such models can lead to:
- Faster, more accurate diagnoses
- Reduced burden on dermatologists
- Early intervention and improved patient outcomes
🔥 Call-to-Action: Ready to Join the AI Healthcare Revolution?
Whether you’re a researcher, clinician, or tech enthusiast, the future of skin cancer detection is being rewritten by innovations like SPCB-Net. Stay ahead of the curve by exploring how AI can transform your practice or project.
👉 Download the full research paper here
👉 Explore code implementations of SPCB-Net Below
👉 Join our community of AI-driven healthcare innovators here
Together, we can make early, accurate diagnosis the norm—not the exception.
🧠 Bonus: Frequently Asked Questions (FAQ)
Q: Can SPCB-Net work with other types of cancer?
A: Yes! While trained on skin cancer data, SPCB-Net’s architecture is highly adaptable and shows promising results in colorectal and breast cancer classification.
Q: Is SPCB-Net available for public use?
A: Research code and pre-trained models are expected to be released by the authors shortly.
Q: How does SPCB-Net compare to ResNet or DenseNet?
A: SPCB-Net outperforms both ResNet and DenseNet variants by incorporating attention mechanisms and hybrid pooling strategies tailored for medical imaging.
Q: Does SPCB-Net require specialized hardware?
A: It runs efficiently on standard GPUs and can be deployed in cloud-based diagnostic systems without requiring expensive infrastructure.
📌 Final Thoughts
In an era where early diagnosis can mean the difference between life and death, tools like SPCB-Net are not just technological marvels—they are lifesavers. As AI continues to evolve, so too will our ability to detect and treat diseases like skin cancer with unprecedented precision.
Stay tuned for more breakthroughs in AI-powered healthcare—and don’t forget to share this post if you found it valuable!
Here’s the PyTorch implementation of SPCB-Net based on the paper:
import torch
import torch.nn as nn
import torch.nn.functional as F
from torchvision import models
from collections import OrderedDict
# ==========================================================================================
# Backward-Compatible Feature Extractors (Replaces torchvision.models.feature_extraction)
# ==========================================================================================
class ResNetFeatureExtractor(nn.Module):
"""A wrapper to extract intermediate features from a ResNet model."""
def __init__(self, backbone, return_nodes):
super().__init__()
# Retain the original backbone model
self.backbone = backbone
self.return_nodes = return_nodes
def forward(self, x):
"""Manually run the forward pass of ResNet to capture intermediate layers."""
out = OrderedDict()
# Initial layers
x = self.backbone.conv1(x)
x = self.backbone.bn1(x)
x = self.backbone.relu(x)
x = self.backbone.maxpool(x)
# Stage 1
x = self.backbone.layer1(x)
if 'layer1' in self.return_nodes:
out[self.return_nodes['layer1']] = x
# Stage 2
x = self.backbone.layer2(x)
if 'layer2' in self.return_nodes:
out[self.return_nodes['layer2']] = x
# Stage 3
x = self.backbone.layer3(x)
if 'layer3' in self.return_nodes:
out[self.return_nodes['layer3']] = x
# Stage 4
x = self.backbone.layer4(x)
if 'layer4' in self.return_nodes:
out[self.return_nodes['layer4']] = x
return out
class VGGFeatureExtractor(nn.Module):
"""A wrapper to extract intermediate features from a VGG model."""
def __init__(self, backbone, return_nodes):
super().__init__()
# We only need the 'features' part of the VGG model
self.features = backbone.features
self.return_nodes = return_nodes
def forward(self, x):
"""Iterate through the VGG features and capture specified layers."""
out = OrderedDict()
for name, module in self.features.named_children():
x = module(x)
if name in self.return_nodes:
out[self.return_nodes[name]] = x
return out
# ==========================================================================================
# Helper Modules (Classifier)
# ==========================================================================================
class ClassifierBlock(nn.Module):
"""
Classifier block as described in Figure 3(iii) of the paper.
It consists of Global Average Pooling, BatchNorm, Dropout, ELU, and a final FC layer.
"""
def __init__(self, in_features, num_classes):
super(ClassifierBlock, self).__init__()
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.flatten = nn.Flatten()
self.bn1 = nn.BatchNorm1d(in_features)
self.dropout = nn.Dropout(0.5)
self.bn2 = nn.BatchNorm1d(in_features)
self.elu = nn.ELU()
self.fc = nn.Linear(in_features, num_classes)
def forward(self, x):
x = self.avgpool(x)
x = self.flatten(x)
x = self.bn1(x)
x = self.dropout(x)
x = self.bn2(x)
x = self.elu(x)
x = self.fc(x)
return x
# ==========================================================================================
# Part 1: SK Feature Pyramid (SK-FP) - Section III-A
# ==========================================================================================
class SKConv(nn.Module):
"""
Selective Kernel Convolution (SKConv) block from the SKNet paper.
This is the core component for the SK Feature Pyramid.
"""
def __init__(self, in_channels, out_channels, stride=1, M=2, r=16, L=32):
super(SKConv, self).__init__()
d = max(in_channels // r, L)
self.M = M
self.out_channels = out_channels
self.convs = nn.ModuleList()
for i in range(M):
# Correctly calculate padding to preserve spatial dimensions
kernel_size = 3 + i * 2
dilation = 1 + i
padding = ((kernel_size - 1) * dilation) // 2
self.convs.append(
nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size=kernel_size, stride=stride, padding=padding, dilation=dilation),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True)
)
)
self.gap = nn.AdaptiveAvgPool2d((1, 1))
self.fc = nn.Linear(out_channels, d)
self.fcs = nn.ModuleList([nn.Linear(d, out_channels) for _ in range(M)])
self.softmax = nn.Softmax(dim=1)
def forward(self, x):
feats = [conv(x) for conv in self.convs]
# All tensors in 'feats' should now have the same size
feats_sum = torch.stack(feats, dim=1).sum(dim=1)
z = self.gap(feats_sum).view(x.size(0), -1)
s = self.fc(z)
attention_vectors = torch.stack([fc(s) for fc in self.fcs], dim=1)
attention_vectors = self.softmax(attention_vectors).unsqueeze(-1).unsqueeze(-1)
feats_weighted = torch.stack(feats, dim=1) * attention_vectors
return feats_weighted.sum(dim=1)
class SKFeaturePyramid(nn.Module):
"""
SK Feature Pyramid (SK-FP) as described in Figure 3(a).
"""
def __init__(self, backbone_channels, pyramid_channels=256):
super(SKFeaturePyramid, self).__init__()
self.pyramid_channels = pyramid_channels
self.sk_layers = nn.ModuleList([SKConv(c, pyramid_channels) for c in backbone_channels])
def forward(self, backbone_features):
"""
Args:
backbone_features (list): [C4, C3, C2, C1] from deep to shallow.
Returns:
list: [F1, F2, F3, F4] from shallow to deep.
"""
sk_features = [sk(feat) for sk, feat in zip(self.sk_layers, backbone_features)]
pyramid_features = []
prev_feat = sk_features[0]
pyramid_features.append(prev_feat)
for i in range(1, len(sk_features)):
upsampled_feat = F.interpolate(prev_feat, scale_factor=2, mode='nearest')
current_feat = sk_features[i]
prev_feat = upsampled_feat + current_feat
pyramid_features.append(prev_feat)
return pyramid_features[::-1]
# ==========================================================================================
# Part 2: Self-interactive Attention Pyramid (SAP) - Section III-B
# ==========================================================================================
class SpatialAttention(nn.Module):
"""Spatial Attention Module as described in Figure 4(a)."""
def __init__(self, kernel_size=3):
super(SpatialAttention, self).__init__()
self.conv = nn.Conv2d(2, 1, kernel_size=kernel_size, padding=(kernel_size - 1) // 2, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avg_out = torch.mean(x, dim=1, keepdim=True)
max_out, _ = torch.max(x, dim=1, keepdim=True)
x_cat = torch.cat([avg_out, max_out], dim=1)
return self.sigmoid(self.conv(x_cat))
class ChannelAttention(nn.Module):
"""Channel Attention Module as described in Figure 4(b)."""
def __init__(self, in_channels, reduction_ratio=16):
super(ChannelAttention, self).__init__()
self.fc = nn.Sequential(
nn.Conv2d(in_channels, in_channels // reduction_ratio, 1, bias=False),
nn.ReLU(),
nn.Conv2d(in_channels // reduction_ratio, in_channels, 1, bias=False)
)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
y = F.adaptive_avg_pool2d(x, 1)
y = self.fc(y)
return self.sigmoid(y)
class SelfInteractiveAttentionPyramid(nn.Module):
"""Self-interactive Attention Pyramid (SAP) from Figure 3(b)."""
def __init__(self, in_channels_list):
super(SelfInteractiveAttentionPyramid, self).__init__()
self.num_levels = len(in_channels_list)
self.spatial_attentions = nn.ModuleList([SpatialAttention() for _ in in_channels_list])
self.channel_attentions = nn.ModuleList([ChannelAttention(c) for c in in_channels_list])
def forward(self, feature_pyramid):
"""
Args:
feature_pyramid (list): [F1, F2, F3, F4].
Returns:
list: [Fa1, Fa2, Fa3, Fa4].
"""
spatial_maps = [sa(f) for sa, f in zip(self.spatial_attentions, feature_pyramid)]
channel_maps = [ca(f) for ca, f in zip(self.channel_attentions, feature_pyramid)]
# Apply bottom-up skip connections for n=1, 2 (indices 0, 1)
for i in range(self.num_levels - 2):
s_map_upsampled = F.interpolate(spatial_maps[i], size=spatial_maps[i+1].shape[2:], mode='nearest')
c_map_upsampled = F.interpolate(channel_maps[i], size=channel_maps[i+1].shape[2:], mode='nearest')
spatial_maps[i+1] = (spatial_maps[i+1] + s_map_upsampled) / 2.0
channel_maps[i+1] = (channel_maps[i+1] + c_map_upsampled) / 2.0
output_features = []
for i in range(self.num_levels):
combined_attention = spatial_maps[i] + channel_maps[i]
output_features.append(feature_pyramid[i] * combined_attention)
return output_features
# ==========================================================================================
# Part 3: Cross-layer Bilinear-Trilinear Pooling (High-Order-Interaction) - Section III-C
# ==========================================================================================
class HighOrderInteraction(nn.Module):
"""High-Order-Interaction module from Figure 3(c)."""
def __init__(self):
super(HighOrderInteraction, self).__init__()
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
def forward(self, attention_features):
C1, C2, C3, C4 = attention_features
target_size = C1.shape[2:] # Get spatial size of the largest feature map
# FIX: Upsample all features to the same size before multiplication
C2_up = F.interpolate(C2, size=target_size, mode='bilinear', align_corners=False)
C3_up = F.interpolate(C3, size=target_size, mode='bilinear', align_corners=False)
C4_up = F.interpolate(C4, size=target_size, mode='bilinear', align_corners=False)
D1 = self.avgpool(C1 * C2_up)
D2 = self.avgpool(C3_up * C4_up)
D3 = self.avgpool(C1 * C2_up * C3_up)
D4 = self.avgpool(C2_up * C3_up * C4_up)
return [D1, D2, D3, D4]
# ==========================================================================================
# Part 4: The Complete SPCB-Net Model - Section III
# ==========================================================================================
class SPCBNet(nn.Module):
"""The complete SPCB-Net model, integrating all components."""
def __init__(self, backbone_name='resnet101', num_classes=7, pretrained=True):
super(SPCBNet, self).__init__()
self.num_classes = num_classes
if backbone_name == 'resnet101':
backbone = models.resnet101(weights=models.ResNet101_Weights.DEFAULT if pretrained else None)
return_nodes = {'layer1': 'p1', 'layer2': 'p2', 'layer3': 'p3', 'layer4': 'p4'}
self.feature_extractor = ResNetFeatureExtractor(backbone, return_nodes)
backbone_channels = [256, 512, 1024, 2048] # Shallow to deep
elif backbone_name == 'vgg19':
backbone = models.vgg19_bn(weights=models.VGG19_BN_Weights.DEFAULT if pretrained else None)
return_nodes = {'12': 'p1', '25': 'p2', '38': 'p3', '51': 'p4'}
self.feature_extractor = VGGFeatureExtractor(backbone, return_nodes)
backbone_channels = [128, 256, 512, 512] # Shallow to deep
else:
raise NotImplementedError(f"Backbone {backbone_name} not supported.")
pyramid_channels = 256
# Reverse the channel list to match the deep-to-shallow feature order
self.sk_fp = SKFeaturePyramid(backbone_channels[::-1], pyramid_channels)
self.sap = SelfInteractiveAttentionPyramid([pyramid_channels] * 4)
self.hoi = HighOrderInteraction()
self.classifier_d0 = ClassifierBlock(backbone_channels[-1], num_classes)
self.classifier_d1 = ClassifierBlock(pyramid_channels, num_classes)
self.classifier_d2 = ClassifierBlock(pyramid_channels, num_classes)
self.classifier_d3 = ClassifierBlock(pyramid_channels, num_classes)
self.classifier_d4 = ClassifierBlock(pyramid_channels, num_classes)
def forward(self, x):
# Extract features, returns a dict
backbone_feats_dict = self.feature_extractor(x)
# Convert to list and reverse to get deep-to-shallow order [p4, p3, p2, p1]
backbone_feats_list = list(backbone_feats_dict.values())[::-1]
# Pass deep-to-shallow features to SK-FP
pyramid_features = self.sk_fp(backbone_feats_list)
# Pass shallow-to-deep pyramid features to SAP
attention_features = self.sap(pyramid_features)
# Perform high-order interaction
hoi_features = self.hoi(attention_features)
D1, D2, D3, D4 = hoi_features
# D0 is the deepest feature map from the backbone
D0 = backbone_feats_list[0]
# Get predictions from all 5 branches
pred0 = self.classifier_d0(D0)
pred1 = self.classifier_d1(D1)
pred2 = self.classifier_d2(D2)
pred3 = self.classifier_d3(D3)
pred4 = self.classifier_d4(D4)
if self.training:
return pred0, pred1, pred2, pred3, pred4
# During evaluation, return the averaged prediction
return (pred0 + pred1 + pred2 + pred3 + pred4) / 5.0
# ==========================================================================================
# Example Usage
# ==========================================================================================
if __name__ == '__main__':
NUM_CLASSES = 7
BATCH_SIZE = 4
IMG_SIZE = 224
print("Instantiating SPCB-Net with ResNet101 backbone...")
model = SPCBNet(backbone_name='resnet101', num_classes=NUM_CLASSES, pretrained=False)
dummy_input = torch.randn(BATCH_SIZE, 3, IMG_SIZE, IMG_SIZE)
model.train()
print("\n--- Testing in Training Mode ---")
preds_train = model(dummy_input)
print(f"Number of output prediction tensors: {len(preds_train)}")
for i, p in enumerate(preds_train):
print(f"Shape of pred{i}: {p.shape}")
model.eval()
print("\n--- Testing in Evaluation Mode ---")
with torch.no_grad():
final_pred = model(dummy_input)
print(f"Shape of final averaged prediction: {final_pred.shape}")
print("\n--- Example Loss Calculation ---")
criterion = nn.CrossEntropyLoss()
labels = torch.randint(0, NUM_CLASSES, (BATCH_SIZE,))
p0, p1, p2, p3, p4 = preds_train
total_loss = sum([criterion(p, labels) for p in [p0, p1, p2, p3, p4]]) / 5.0
print(f"Example total loss: {total_loss.item():.4f}")
Pingback: 7 Revolutionary Insights from Hierarchical Vision Transformers in Prostate Biopsy Grading (And Why They Matter) - aitrendblend.com