Introduction: The Challenge of Understanding Complex Surgical Videos
Modern surgical procedures generate vast amounts of video data that hold immense potential for training, quality assessment, and AI-assisted decision-making. Yet, one persistent challenge has plagued computer vision researchers: how can machines automatically identify and track surgical instruments and anatomical structures without human-labeled data?
Traditional supervised learning approaches require thousands of painstakingly annotated frames—a process that is prohibitively expensive, time-consuming, and requires specialized medical expertise. Meanwhile, existing self-supervised methods struggle with the unique complexities of surgical environments: instruments move at varying speeds, tissues deform unpredictably, and objects frequently enter and exit the field of view.
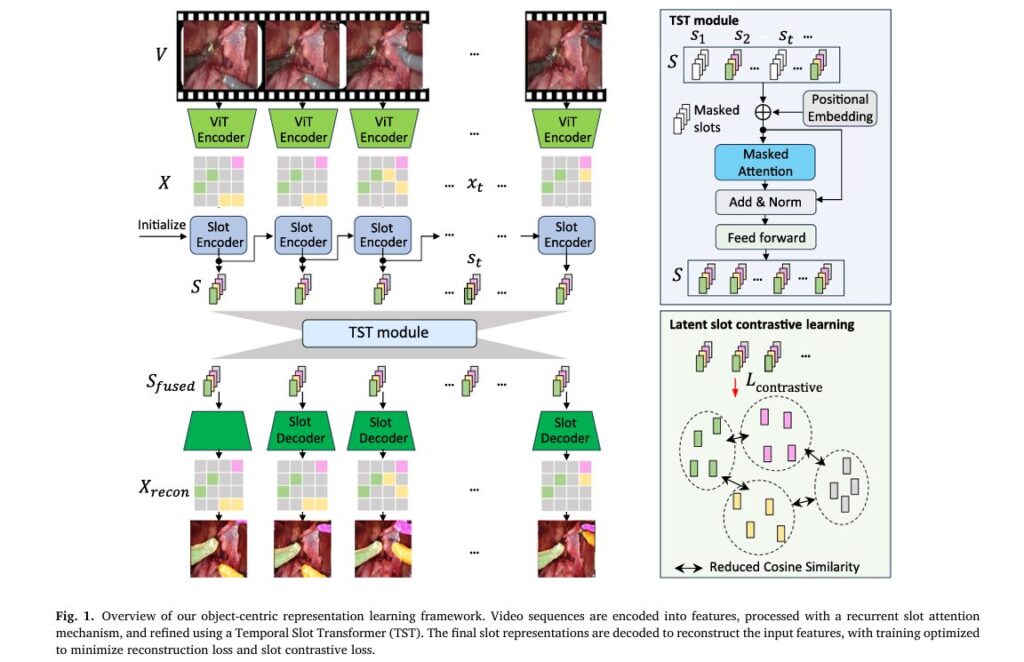
Enter Slot-BERT, a groundbreaking architecture developed by researchers at the University of Pennsylvania and University Health Network Toronto. Published in Medical Image Analysis (2026), this innovative framework represents a paradigm shift in how AI systems perceive and reason about dynamic surgical scenes. By adapting the renowned BERT transformer architecture from natural language processing to process visual “slots” representing objects, Slot-BERT achieves state-of-the-art performance across multiple surgical specialties while requiring no manual annotations during training.
Key Innovation: Slot-BERT treats object-centric slot representations as analogous to word embeddings in language models, enabling bidirectional temporal reasoning that captures long-range dependencies in surgical videos.
What Is Object-Centric Learning and Why Does It Matter?
The Cognitive Foundation of Object-Centric AI
Human perception operates through object-specific grouping and association—a cognitive process where we naturally bind features to individual entities and track them over time. This mechanism, described by cognitive scientists as “object files” (Kahneman et al., 1992), allows humans to efficiently reason about complex scenes without becoming overwhelmed by pixel-level details.
Object-centric learning aims to replicate this biological advantage in artificial neural networks. Rather than processing images as unstructured grids of pixels, these systems learn to decompose scenes into discrete, compositional entities called “slots.” Each slot encapsulates all relevant information about a specific object—its appearance, position, and temporal dynamics.
The Slot Attention Mechanism
At the heart of Slot-BERT lies the Slot Attention (SA) mechanism, originally proposed by Locatello et al. (2020). This iterative attention process transforms unstructured feature maps into a fixed set of slot vectors through competitive binding:
Given input features x ∈ RN×Dfeature and current slot representations si ∈ RK×dslot , the slot update follows:
\[ q = W_q s_i \quad (\text{queries}) \] \[ k = W_k x \quad (\text{keys}) \] \[ v = W_v x \quad (\text{values}) \] \[ A = \operatorname{softmax} \left( \frac{q k^{\top}}{\sqrt{d}} \right) \in \mathbb{R}^{K \times N} \] \[ \hat{A}_{mn} = \sum_{l=1}^{N} A_{ml} A_{ln} \quad (\text{normalized attention}) \] \[ s_{i+1} = \hat{A} \, v \quad (\text{slot update}) \]Where:
- N = number of spatial patches (typically N=784 for a 28×28 patch grid)
- K = number of slots (typically K =7 for surgical scenes)
- dslot = slot dimension
- m ∈ {1,…,K} indexes slots
- n ∈ {1,…,N} indexes spatial features
Why this matters: Slot attention is dramatically more efficient than full self-attention because K≪N, reducing computational complexity from O(N2) to O(KN).
The Slot-BERT Architecture: Technical Deep Dive
1. Temporal Slot Transformer (TST): Bidirectional Video Reasoning
Previous video object-centric methods relied on recurrent neural network (RNN) architectures that process frames sequentially. While intuitive, this approach suffers from:
- Vanishing gradients in long sequences
- Unidirectional bias—unable to leverage future context for current predictions
- Instability when training on sequences longer than a few seconds
Slot-BERT revolutionizes this paradigm by introducing the Temporal Slot Transformer (TST) module. Inspired by BERT’s success in NLP, the TST processes slot sequences using bidirectional masked self-attention:
\[ S_{\text{pos}} = S + P_{\text{temporal}} \] \[ S_{\text{masked}} = S_{\text{pos}} \odot M_{\text{slot}}, \quad M_{\text{slot}} \in \{0,1\}^{1 \times K \times T} \] \[ S_{\text{fused}} = \operatorname{TransformerEncoder} \!\left( S_{\text{masked}},\, M_{\text{slot}} \right) \]Where Ptemporal ∈ R1×dslot×T represents learnable temporal positional embeddings, and γ (masking ratio) determines what fraction of frames are masked during training.
Critical distinction: Unlike autoregressive models that can only attend to past frames, TST’s non-causal self-attention enables each slot to attend to both past and future frames simultaneously. This mirrors how human surgeons anticipate instrument movements based on procedural context.
2. Slot Contrastive Loss: Enforcing Representation Diversity
A persistent challenge in slot-based models is slot collapse—when multiple slots encode similar information, effectively reducing the model’s capacity to represent distinct objects. Slot-BERT addresses this through a novel slot contrastive loss based on cosine similarity.
For slot vectors ui, uj ∈ R1×dslot within the same frame:
\[ \operatorname{sim}(u_i, u_j) = \frac{u_i \cdot u_j} {\|u_i\| \, \|u_j\|} \] \[ C_{ij} = \operatorname{sim}(u_i, u_j) – \delta_{ij} \] \[ L_{\text{contrast}} = \frac{1}{T K^{2}} \sum_{t=1}^{T} \sum_{i=1}^{K} \sum_{j=1}^{K} \left[ – \log \left( \frac{ \exp\!\left(-C_{ij}/\tau\right) }{ \sum_{k=1}^{K} \exp\!\left(-C_{ik}/\tau\right) } \right) \right] \]Where τ > 0 is a temperature parameter and δij is the Kronecker delta (excluding self-similarity).
The effect: This loss pushes slot vectors toward quasi-orthogonal directions on the unit hypersphere, ensuring each slot captures distinct, non-redundant information about different scene entities.
3. Complete Training Objective
The final loss combines reconstruction fidelity with slot diversity:
\[ L_{\text{final}} = L_{\text{recon}} + \alpha L_{\text{contrast}} \] \[ L_{\text{recon}} = \left\lVert X_{\text{recon}} – X \right\rVert_{2}^{2} \]Where α is a balancing hyperparameter (empirically optimized to α = 0.01 with τ = 0.5 ).
Performance Benchmarks: How Slot-BERT Dominates the Field
Quantitative Results Across Surgical Domains
The research team evaluated Slot-BERT on four challenging surgical datasets spanning three specialties:
| Dataset | Surgery Type | Clips | Key Challenge |
|---|---|---|---|
| MICCAI | Abdominal/Phantom | 24,642 | Large-scale, diverse instruments |
| Cholec80 | Cholecystectomy | 5,296 | Frequent instrument disappearance/reappearance |
| EndoVis | Abdominal (Robotic) | 480 | Complex multi-instrument interactions |
| Thoracic | Lung (RUL) | 264 | Sparse annotation, domain shift |
Table 1: Dataset characteristics and specific challenges for evaluating object-centric learning.
Unsupervised Training Results
When trained from scratch without any labels, Slot-BERT achieves superior performance across all metrics:
| Method | mBO-V (%) | mBO-F (%) | FG-ARI (%) | CorLoc (%) |
|---|---|---|---|---|
| DINO-Saur | 38.2 | 42.9 | 48.4 | 45.8 |
| SAVi | 29.4 | 33.2 | 36.6 | 40.0 |
| STEVE | 27.9 | 31.5 | 34.3 | 17.0 |
| Slot-Diffusion | 37.5 | 42.2 | 46.3 | 42.0 |
| Video-Saur | 46.3 | 50.1 | 55.1 | 60.1 |
| Slot-BERT (Ours) | 48.9 | 52.8 | 58.2 | 70.7 |
Table 2: Performance comparison on MICCAI dataset. Bold indicates best results. mBO-V = video mean best overlap, mBO-F = frame mean best overlap, FG-ARI = foreground adjusted Rand index, CorLoc = correct localization.
Key takeaways:
- +2.6% improvement in video-level segmentation (mBO-V) over previous SOTA
- +10.6% improvement in object localization (CorLoc)
- Significant reduction in boundary error (mBHD: 44.2 vs. 53.9 for Video-Saur)
Zero-Shot Domain Generalization
Perhaps most impressively, Slot-BERT exhibits remarkable zero-shot transfer capability. When trained only on MICCAI data and tested directly on unseen surgical domains:
| Target Dataset | Method | mBO-V (%) | mBO-F (%) |
|---|---|---|---|
| EndoVis | Video-Saur | 42.7 | 46.7 |
| Slot-BERT | 43.5 | 47.6 | |
| Thoracic | Video-Saur | 36.7 | 48.9 |
| Slot-BERT | 37.7 | 51.1 | |
| Cholec | Video-Saur | 27.0 | 26.1 |
| Slot-BERT | 29.2 | 27.9 |
Table 3: Zero-shot performance—models trained on MICCAI, tested on new surgical specialties without fine-tuning.
This cross-specialty generalization is unprecedented in surgical video analysis and demonstrates that Slot-BERT learns fundamental visual concepts transferable across anatomical contexts.
Long-Range Temporal Coherence: Handling Extended Surgical Procedures
Scaling to 30-Second Sequences
Surgical actions often extend far beyond the short clips used in typical video analysis research. Slot-BERT uniquely handles 30-second sequences (30 frames at 1 FPS) through:
- Sliding window inference with online recurrent processing
- Future slot prediction for initialization beyond training context
- Bidirectional attention that maintains consistency across the entire sequence
| Sequence Length | Method | mBO-V (%) | FG-ARI (%) |
|---|---|---|---|
| 7 frames | Video-Saur | 46.7 | 56.1 |
| Slot-BERT | 48.0 | 57.5 | |
| Slot-BERT + Future Pred | 48.5 | 58.0 | |
| 11 frames | Video-Saur | 44.4 | 55.2 |
| Slot-BERT | 46.2 | 56.8 | |
| Slot-BERT + Future Pred | 46.9 | 57.3 | |
| 30 frames | Video-Saur | 42.3 | 56.8 |
| Slot-BERT | 44.4 | 61.7 |
Table 4: Performance across varying sequence lengths demonstrates Slot-BERT’s superior temporal consistency.
Critical insight: While competing methods show degradation with longer sequences, Slot-BERT maintains robust performance, with the full 30-frame model actually improving FG-ARI by nearly 5 points over shorter sequences.
Identity-Aware Tracking Metrics
Under challenging conditions with frequent instrument entry/exit and occlusion:
- IDF1 improvement: +9.4% over RNN baseline
- Temporal Identity Persistence (T-IDP): +8.9% improvement
- CorLoc: +8.8% better localization accuracy
These metrics confirm that Slot-BERT doesn’t just segment objects accurately—it maintains consistent identity tracking across time, a crucial capability for surgical workflow analysis.
Computational Efficiency: Practical Deployment
Real-Time Performance Benchmarks
Despite its sophisticated architecture, Slot-BERT achieves competitive inference speeds:
| Method | Time/Frame (ms) | GFLOPs | Memory (MB) |
|---|---|---|---|
| SAVi | 3.3 | 430.7 | — |
| STEVE | 8.2 | 540.7 | — |
| Slot-Diffusion | 5.7 | 334.2 | — |
| Video-Saur | 1.2 | 411.7 | 369.3 |
| Slot-BERT | 1.7 | 453.5 | 371.0* |
*With 5-frame context window; 373.1 MB with 30-frame window
Table 5: Computational efficiency comparison. Slot-BERT adds only 1.69 MB memory overhead for 5-frame temporal context.
Why this matters: The minimal overhead (0.5 ms vs. Video-Saur) is more than justified by substantial accuracy gains, making Slot-BERT suitable for real-time surgical applications on affordable hardware (NVIDIA RTX 6000 Ada Generation).
Ablation Studies: Validating Design Choices
Component Contribution Analysis
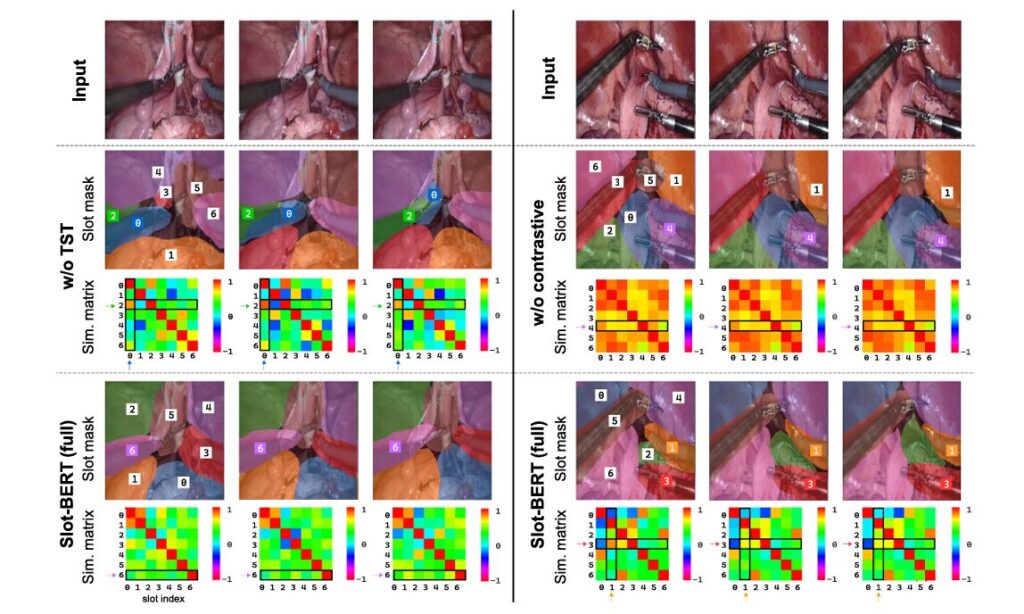
Systematic ablation reveals the complementary roles of TST and contrastive learning:
| Configuration | MICCAI (11 frames) | Cholec (11 frames) | ||
|---|---|---|---|---|
| mBO-V | IDF1 | mBO-V | IDF1 | |
| Baseline (no TST, no contrast) | 41.9 | 76.2 | 29.6 | 51.8 |
| + Contrastive only | 45.5 | 79.1 | 33.2 | 59.4 |
| + TST only | 47.0 | 80.8 | 33.8 | 60.2 |
| Full Slot-BERT | 48.6 | 82.4 | 35.2 | 63.7 |
Table 6: Ablation study showing synergistic effects of TST module and contrastive loss.
Statistical significance: All improvements exceed Cohen’s d>0.8 (large effect size) with p<0.0167 (Bonferroni-corrected).
Visualizing Slot Behavior
The paper presents visualization matrices showing cosine similarity between slot vectors across frames. Without TST, slot identities fluctuate wildly—an instrument tracked by slot 0 suddenly jumps to slot 2, while tissue fragments across multiple slots. With full Slot-BERT, similarity matrices show stable diagonal patterns indicating consistent object-to-slot assignment. The contrastive loss visibly pushes off-diagonal similarities toward zero, confirming slot orthogonality.
Limitations and Future Directions
Current Constraints
While groundbreaking, Slot-BERT has acknowledged limitations:
- Patch-resolution boundaries: Segmentation masks are limited by the 14×14 or 16×16 patch grid of the ViT encoder, leading to imprecise object boundaries particularly around thin instruments
- Fixed slot allocation: The number of slots K must be specified in advance (typically K=7 ); dynamic allocation remains an open challenge
- Object re-identification: When objects exit and re-enter the field of view, slot reassignment isn’t guaranteed without additional memory mechanisms
Promising Research Trajectories
The authors outline several high-impact extensions:
- High-resolution adaptation: Leveraging DINOv3’s high-resolution capabilities or using Slot-BERT as guidance for optical flow refinement
- Weakly supervised enhancement: Incorporating video-level class labels through set prediction frameworks
- Interactive annotation: Allowing clinicians to specify which slot represents a target instrument, reducing annotation burden by 90%+
- Cross-modal extension: Integrating audio or kinematic data for richer surgical scene understanding
Clinical Impact and Broader Applications
Transforming Surgical Education
Slot-BERT’s zero-shot capabilities enable immediate deployment across surgical specialties without costly retraining:
- Training curriculum development: Automatic identification of instrument-tissue interactions for skill assessment
- Quality assurance: Objective measurement of procedural steps and instrument handling
- Predictive assistance: Anticipating next instruments based on procedural context
Beyond Surgery: General Video Understanding
The architectural innovations—particularly bidirectional slot transformers and latent-space contrastive learning—transfer to:
- Autonomous driving: Long-range pedestrian and vehicle tracking
- Robotics: Object manipulation in cluttered environments
- Scientific imaging: Cell tracking in microscopy and organ segmentation in MRI
Conclusion: A New Paradigm for Medical AI
Slot-BERT represents a fundamental advance in self-supervised video understanding, specifically engineered for the demanding requirements of surgical analysis. By bridging the gap between natural language processing transformers and computer vision, it achieves:
✅ State-of-the-art segmentation without manual annotations
✅ Zero-shot generalization across surgical specialties
✅ Long-range temporal coherence for extended procedures
✅ Computational efficiency suitable for real-time deployment
✅ Interpretable representations through explicit object slots
The research demonstrates that bidirectional reasoning in latent space—rather than expensive pixel-level processing—is the key to scalable, robust medical video AI.
Engage With the Research
How do you see object-centric AI transforming your field? Whether you’re a surgeon interested in AI-assisted training, a computer vision researcher pushing the boundaries of self-supervised learning, or a medical device developer seeking practical deployment strategies, we’d love to hear your perspective.
Drop your thoughts in the comments below:
- What surgical applications would benefit most from automatic instrument tracking?
- How can we address the boundary precision limitations of patch-based methods?
- Should medical AI prioritize interpretability (slot-based) or raw performance (end-to-end)?
Subscribe to our newsletter for deep dives into cutting-edge medical AI research, and share this article with colleagues working at the intersection of healthcare and artificial intelligence.
This analysis is based on “Slot-BERT: Self-supervised object discovery in surgical video” by Liao et al., published in Medical Image Analysis 110 (2026) 103972. The original research and supplementary materials are available through the journal’s open access repository.
Here is a comprehensive, end-to-end implementation of Slot-BERT based on the paper. This will be a complete PyTorch implementation with all components described in the research.
"""
Slot-BERT: Self-supervised Object Discovery in Surgical Video
Complete End-to-End Implementation
Based on: Liao et al., Medical Image Analysis 110 (2026) 103972
"""
import torch
import torch.nn as nn
import torch.nn.functional as F
import math
from typing import Optional, Tuple, Dict, List
from einops import rearrange, repeat
import timm # For pretrained vision encoders
# =============================================================================
# CONFIGURATION
# =============================================================================
class SlotBERTConfig:
"""Configuration for Slot-BERT model."""
# Image/Video parameters
img_size: int = 224
patch_size: int = 14 # DINO typically uses 14x14 patches
num_frames: int = 5 # Training sequence length (T)
# Slot attention parameters
num_slots: int = 7 # Number of object slots (K)
slot_dim: int = 256 # Slot dimension (d_slot)
num_iterations: int = 3 # Slot attention iterations
# Transformer parameters
transformer_layers: int = 3
transformer_heads: int = 8
transformer_dim_feedforward: int = 1024 # 4 * slot_dim
transformer_dropout: float = 0.1
# Training parameters
mask_ratio: float = 0.5 # Ratio of frames to mask during training
contrastive_weight: float = 0.01 # Alpha for contrastive loss
contrastive_temperature: float = 0.5 # Tau for contrastive loss
# Feature encoder
encoder_model: str = "vit_base_patch14_dinov2" # DINOv2 backbone
feature_dim: int = 768 # DINOv2 base feature dimension
def __init__(self, **kwargs):
for k, v in kwargs.items():
setattr(self, k, v)
# Derived parameters
self.num_patches = (self.img_size // self.patch_size) ** 2
self.transformer_dim_feedforward = 4 * self.slot_dim
# =============================================================================
# SLOT ATTENTION MODULE
# =============================================================================
class SlotAttention(nn.Module):
"""
Iterative attention mechanism that binds features to slots.
Based on Locatello et al. (2020) with modifications for video.
"""
def __init__(self, config: SlotBERTConfig):
super().__init__()
self.config = config
self.num_iterations = config.num_iterations
self.num_slots = config.num_slots
self.slot_dim = config.slot_dim
self.feature_dim = config.feature_dim
# Learnable slot initialization parameters
self.slots_mu = nn.Parameter(torch.randn(1, 1, config.slot_dim))
self.slots_log_sigma = nn.Parameter(torch.randn(1, 1, config.slot_dim))
# Linear transformations for attention
self.to_q = nn.Linear(config.slot_dim, config.slot_dim, bias=False)
self.to_k = nn.Linear(config.feature_dim, config.slot_dim, bias=False)
self.to_v = nn.Linear(config.feature_dim, config.slot_dim, bias=False)
# Slot update MLP (GRU-style update)
self.gru = nn.GRUCell(config.slot_dim, config.slot_dim)
# Feed-forward network for slot refinement
self.mlp = nn.Sequential(
nn.Linear(config.slot_dim, config.slot_dim),
nn.ReLU(inplace=True),
nn.Linear(config.slot_dim, config.slot_dim)
)
self.norm_inputs = nn.LayerNorm(config.feature_dim)
self.norm_slots = nn.LayerNorm(config.slot_dim)
self.norm_mlp = nn.LayerNorm(config.slot_dim)
def forward(
self,
features: torch.Tensor,
slots_init: Optional[torch.Tensor] = None
) -> Tuple[torch.Tensor, torch.Tensor]:
"""
Args:
features: [B, N, D_feature] patch features
slots_init: [B, K, D_slot] initial slots (for temporal propagation)
Returns:
slots: [B, K, D_slot] final slot representations
attention_maps: [B, K, N] final attention weights (for segmentation)
"""
B, N, D = features.shape
# Initialize slots
if slots_init is None:
# Sample from Gaussian with learned parameters
mu = self.slots_mu.expand(B, self.num_slots, -1)
sigma = self.slots_log_sigma.exp().expand(B, self.num_slots, -1)
slots = mu + sigma * torch.randn_like(mu)
else:
slots = slots_init
# Normalize inputs
inputs = self.norm_inputs(features)
k = self.to_k(inputs) # [B, N, D_slot]
v = self.to_v(inputs) # [B, N, D_slot]
# Iterative refinement
for _ in range(self.num_iterations):
slots_prev = slots
slots = self.norm_slots(slots)
# Compute attention
q = self.to_q(slots) # [B, K, D_slot]
# Scaled dot-product attention
attn_logits = torch.einsum('bqd,bkd->bqk', q, k) / math.sqrt(self.slot_dim)
attn = F.softmax(attn_logits, dim=-1) # [B, K, N]
# Normalize attention across slots (competitive binding)
attn = attn / (attn.sum(dim=1, keepdim=True) + 1e-8)
# Weighted aggregation
updates = torch.einsum('bqk,bkd->bqd', attn, v) # [B, K, D_slot]
# GRU update
slots = self.gru(
updates.reshape(-1, self.slot_dim),
slots_prev.reshape(-1, self.slot_dim)
).reshape(B, self.num_slots, self.slot_dim)
# MLP refinement
slots = slots + self.mlp(self.norm_mlp(slots))
# Final attention maps for decoding
with torch.no_grad():
q = self.to_q(self.norm_slots(slots))
attn_logits = torch.einsum('bqd,bkd->bqk', q, k) / math.sqrt(self.slot_dim)
attention_maps = F.softmax(attn_logits, dim=-1)
attention_maps = attention_maps / (attention_maps.sum(dim=1, keepdim=True) + 1e-8)
return slots, attention_maps
# =============================================================================
# TEMPORAL SLOT TRANSFORMER (TST)
# =============================================================================
class TemporalSlotTransformer(nn.Module):
"""
Bidirectional transformer for temporal slot reasoning.
Inspired by BERT's masked language modeling applied to slots.
"""
def __init__(self, config: SlotBERTConfig):
super().__init__()
self.config = config
self.slot_dim = config.slot_dim
# Temporal positional embeddings
self.temporal_pos_embed = nn.Parameter(
torch.randn(1, config.num_slots, config.slot_dim, config.num_frames)
)
# Transformer encoder
encoder_layer = nn.TransformerEncoderLayer(
d_model=config.slot_dim,
nhead=config.transformer_heads,
dim_feedforward=config.transformer_dim_feedforward,
dropout=config.transformer_dropout,
batch_first=True,
norm_first=True # Pre-norm for stability
)
self.transformer = nn.TransformerEncoder(
encoder_layer,
num_layers=config.transformer_layers
)
self.norm = nn.LayerNorm(config.slot_dim)
def forward(
self,
slots: torch.Tensor,
mask: Optional[torch.Tensor] = None,
return_attention: bool = False
) -> torch.Tensor:
"""
Args:
slots: [B, K, D, T] slot sequence
mask: [B, T] boolean mask (True = keep, False = mask out)
return_attention: whether to return attention weights
Returns:
fused_slots: [B, K, D, T] temporally fused slots
"""
B, K, D, T = slots.shape
# Add temporal positional embeddings
pos_embed = self.temporal_pos_embed[:, :, :, :T]
slots_pos = slots + pos_embed # Broadcast addition
# Prepare for transformer: [B, T, K, D] -> [B, T*K, D]
slots_seq = rearrange(slots_pos, 'b k d t -> b (t k) d')
# Create attention mask for slots if frame-level mask provided
if mask is not None:
# Expand frame mask to slot level: [B, T] -> [B, T*K]
slot_mask = repeat(mask, 'b t -> b (t k)', k=K)
# Invert for transformer (True = mask out)
attn_mask = ~slot_mask # [B, T*K]
else:
attn_mask = None
# Bidirectional transformer encoding
if return_attention:
# Hook to capture attention
attention_weights = []
def hook_fn(module, input, output):
attention_weights.append(output[1] if isinstance(output, tuple) else None)
handles = []
for layer in self.transformer.layers:
handles.append(layer.self_attn.register_forward_hook(hook_fn))
fused = self.transformer(slots_seq, src_key_padding_mask=attn_mask)
for h in handles:
h.remove()
else:
fused = self.transformer(slots_seq, src_key_padding_mask=attn_mask)
# Reshape back: [B, T*K, D] -> [B, K, D, T]
fused_slots = rearrange(fused, 'b (t k) d -> b k d t', k=K, t=T)
fused_slots = self.norm(fused_slots)
if return_attention:
return fused_slots, attention_weights
return fused_slots
# =============================================================================
# SLOT CONTRASTIVE LOSS
# =============================================================================
class SlotContrastiveLoss(nn.Module):
"""
Contrastive loss to enforce orthogonality between slots.
Pushes different slots to have low cosine similarity.
"""
def __init__(self, temperature: float = 0.5):
super().__init__()
self.temperature = temperature
def forward(self, slots: torch.Tensor) -> torch.Tensor:
"""
Args:
slots: [B, K, D, T] slot representations
Returns:
loss: scalar contrastive loss
"""
B, K, D, T = slots.shape
# Normalize slots for cosine similarity
slots_norm = F.normalize(slots, dim=2) # [B, K, D, T]
total_loss = 0.0
for t in range(T):
# Slots at time t: [B, K, D]
s = slots_norm[:, :, :, t]
# Compute cosine similarity matrix: [B, K, K]
sim_matrix = torch.einsum('bkd,bld->bkl', s, s)
# Remove self-similarity
mask = torch.eye(K, device=slots.device).bool().unsqueeze(0) # [1, K, K]
sim_matrix = sim_matrix.masked_fill(mask, float('-inf'))
# Contrastive loss: push similarities toward -inf (orthogonal)
# For each slot i, all other slots j are "negatives"
logits = -sim_matrix / self.temperature # [B, K, K]
# Cross-entropy: each slot should be dissimilar to all others
# Labels are arbitrary since we want uniform distribution over negatives
# Use InfoNCE-style loss
logits_max, _ = logits.max(dim=-1, keepdim=True)
logits_stable = logits - logits_max.detach()
exp_logits = torch.exp(logits_stable)
# Loss for each slot pair
loss_t = -torch.log(exp_logits / exp_logits.sum(dim=-1, keepdim=True))
loss_t = loss_t.masked_fill(mask, 0).sum() / (B * K * (K - 1))
total_loss += loss_t
return total_loss / T
# =============================================================================
# DECODERS
# =============================================================================
class MLPBroadcastDecoder(nn.Module):
"""
Simple MLP decoder that broadcasts slots to spatial positions.
Produces segmentation masks directly from attention.
"""
def __init__(self, config: SlotBERTConfig):
super().__init__()
self.config = config
self.num_patches = config.num_patches
self.slot_dim = config.slot_dim
self.feature_dim = config.feature_dim
# Positional encoding for spatial positions
self.pos_embed = nn.Parameter(
torch.randn(1, config.num_patches, config.slot_dim)
)
# Shared MLP for decoding
self.mlp = nn.Sequential(
nn.Linear(config.slot_dim, config.slot_dim),
nn.ReLU(inplace=True),
nn.Linear(config.slot_dim, config.slot_dim),
nn.ReLU(inplace=True),
)
# Output heads
self.to_features = nn.Linear(config.slot_dim, config.feature_dim)
self.to_alpha = nn.Linear(config.slot_dim, 1) # Attention mask
def forward(
self,
slots: torch.Tensor,
attention_maps: Optional[torch.Tensor] = None
) -> Tuple[torch.Tensor, torch.Tensor]:
"""
Args:
slots: [B, K, D] slots for a single frame
attention_maps: [B, K, N] pre-computed attention from slot attention
Returns:
reconstructed: [B, N, D_feature] reconstructed features
masks: [B, K, N] slot segmentation masks
"""
B, K, D = slots.shape
N = self.num_patches
# Broadcast slots to all spatial positions
slots_broadcast = repeat(slots, 'b k d -> b k n d', n=N) # [B, K, N, D]
# Add spatial positional encoding
pos = repeat(self.pos_embed, '1 n d -> b k n d', b=B, k=K)
slots_pos = slots_broadcast + pos # [B, K, N, D]
# Apply shared MLP
decoded = self.mlp(slots_pos) # [B, K, N, D]
# Predict features and alpha masks
features_k = self.to_features(decoded) # [B, K, N, D_feature]
alpha_k = self.to_alpha(decoded).squeeze(-1) # [B, K, N]
# Softmax over slots to get mixing weights
masks = F.softmax(alpha_k, dim=1) # [B, K, N]
# Weighted combination of slot features
reconstructed = torch.einsum('bkn,bknd->bnd', masks, features_k)
return reconstructed, masks
class SlotMixerDecoder(nn.Module):
"""
SlotMixer decoder with cross-attention between slots and positions.
More efficient for larger numbers of slots.
Based on Sajjadi et al. (2022).
"""
def __init__(self, config: SlotBERTConfig):
super().__init__()
self.config = config
self.num_patches = config.num_patches
# Learnable queries for spatial positions
self.spatial_queries = nn.Parameter(
torch.randn(1, config.num_patches, config.slot_dim)
)
# Allocation: cross-attention from spatial positions to slots
self.alloc_attn = nn.MultiheadAttention(
embed_dim=config.slot_dim,
num_heads=8,
batch_first=True
)
# Mixing: single-head attention
self.mix_norm = nn.LayerNorm(config.slot_dim)
# Rendering MLP
self.render_mlp = nn.Sequential(
nn.Linear(config.slot_dim, config.slot_dim * 2),
nn.GELU(),
nn.Linear(config.slot_dim * 2, config.feature_dim)
)
self.norm = nn.LayerNorm(config.slot_dim)
def forward(
self,
slots: torch.Tensor,
attention_maps: Optional[torch.Tensor] = None
) -> Tuple[torch.Tensor, torch.Tensor]:
"""
Args:
slots: [B, K, D] slots for a single frame
Returns:
reconstructed: [B, N, D_feature] reconstructed features
masks: [B, K, N] slot segmentation masks
"""
B, K, D = slots.shape
N = self.num_patches
# Allocation: slots attend to spatial queries
queries = repeat(self.spatial_queries, '1 n d -> b n d', b=B)
# Cross-attention: positions query slots
f, _ = self.alloc_attn(
queries, slots, slots
) # [B, N, D]
# Mixing: compute attention from positions to slots
f_norm = self.mix_norm(f)
slots_norm = self.norm(slots)
# Single-head attention for mixing weights
mix_logits = torch.einsum('bnd,bkd->bnk', f_norm, slots_norm) / math.sqrt(D)
mix_attn = F.softmax(mix_logits, dim=-1) # [B, N, K]
# Mix slots according to attention
m = torch.einsum('bnk,bkd->bnd', mix_attn, slots) # [B, N, D]
# Rendering
reconstructed = self.render_mlp(m) # [B, N, D_feature]
# Transpose masks for consistency with MLP decoder
masks = rearrange(mix_attn, 'b n k -> b k n')
return reconstructed, masks
# =============================================================================
# FEATURE ENCODER (DINOv2)
# =============================================================================
class DINOv2Encoder(nn.Module):
"""
Wrapper for DINOv2 pretrained vision transformer.
Extracts patch-level features for slot attention.
"""
def __init__(self, config: SlotBERTConfig):
super().__init__()
self.config = config
# Load pretrained DINOv2
self.encoder = torch.hub.load('facebookresearch/dinov2', config.encoder_model)
# Freeze encoder (standard practice for slot-based methods)
for param in self.encoder.parameters():
param.requires_grad = False
self.feature_dim = config.feature_dim
def forward(self, x: torch.Tensor) -> torch.Tensor:
"""
Args:
x: [B, 3, H, W] input images
Returns:
features: [B, N, D_feature] patch features
"""
B = x.shape[0]
# Get patch tokens from DINOv2
with torch.no_grad():
features_dict = self.encoder.forward_features(x)
# Extract patch tokens (exclude CLS token)
patch_tokens = features_dict['x_norm_patchtokens'] # [B, N, D]
return patch_tokens
# =============================================================================
# COMPLETE SLOT-BERT MODEL
# =============================================================================
class SlotBERT(nn.Module):
"""
Complete Slot-BERT model for self-supervised object discovery in video.
"""
def __init__(
self,
config: SlotBERTConfig,
decoder_type: str = "mlp" # "mlp" or "mixermixer"
):
super().__init__()
self.config = config
# Components
self.encoder = DINOv2Encoder(config)
self.slot_attention = SlotAttention(config)
self.temporal_transformer = TemporalSlotTransformer(config)
# Decoder
if decoder_type == "mlp":
self.decoder = MLPBroadcastDecoder(config)
elif decoder_type == "mixer":
self.decoder = SlotMixerDecoder(config)
else:
raise ValueError(f"Unknown decoder type: {decoder_type}")
# Loss functions
self.contrastive_loss = SlotContrastiveLoss(config.contrastive_temperature)
# Future slot prediction head (for inference)
self.future_predictor = nn.Linear(config.slot_dim, config.slot_dim)
def encode_frames(self, video: torch.Tensor) -> torch.Tensor:
"""
Encode video frames to patch features.
Args:
video: [B, T, 3, H, W] video frames
Returns:
features: [B, T, N, D_feature] frame features
"""
B, T = video.shape[:2]
# Flatten batch and time
frames_flat = rearrange(video, 'b t c h w -> (b t) c h w')
features_flat = self.encoder(frames_flat) # [B*T, N, D]
# Reshape back
features = rearrange(
features_flat,
'(b t) n d -> b t n d',
b=B, t=T
)
return features
def apply_slot_attention(
self,
features: torch.Tensor,
slots_init: Optional[torch.Tensor] = None
) -> Tuple[torch.Tensor, torch.Tensor, List[torch.Tensor]]:
"""
Apply slot attention with temporal recurrence.
Args:
features: [B, T, N, D_feature]
slots_init: Optional initial slots for first frame
Returns:
slots: [B, K, D, T] slot sequence
attention_maps: [B, T, K, N] attention for decoding
slot_inits: List of initial slots for each frame
"""
B, T, N, D = features.shape
K = self.config.num_slots
slots_list = []
attention_list = []
slot_inits = []
prev_slots = slots_init
for t in range(T):
# Apply slot attention to frame t
slots_t, attn_t = self.slot_attention(features[:, t], prev_slots)
slots_list.append(slots_t) # [B, K, D]
attention_list.append(attn_t) # [B, K, N]
slot_inits.append(prev_slots if prev_slots is not None else slots_t.detach())
# Use as initialization for next frame (RNN-style)
prev_slots = slots_t
# Stack: [B, T, K, D] -> [B, K, D, T]
slots = torch.stack(slots_list, dim=1)
slots = rearrange(slots, 'b t k d -> b k d t')
# Stack attention: [B, T, K, N]
attention_maps = torch.stack(attention_list, dim=1)
return slots, attention_maps, slot_inits
def apply_temporal_transformer(
self,
slots: torch.Tensor,
mask_ratio: Optional[float] = None
) -> Tuple[torch.Tensor, torch.Tensor]:
"""
Apply masked temporal transformer.
Args:
slots: [B, K, D, T] input slots
mask_ratio: ratio of frames to mask (None = no masking)
Returns:
fused_slots: [B, K, D, T] temporally fused slots
mask: [B, T] which frames were masked
"""
B, K, D, T = slots.shape
if mask_ratio is not None and self.training:
# Random masking for training
mask = torch.rand(B, T, device=slots.device) > mask_ratio
else:
# No masking during inference
mask = torch.ones(B, T, dtype=torch.bool, device=slots.device)
fused_slots = self.temporal_transformer(slots, mask)
return fused_slots, mask
def decode_frame(
self,
slots: torch.Tensor,
attention_map: Optional[torch.Tensor] = None
) -> Tuple[torch.Tensor, torch.Tensor]:
"""
Decode slots to reconstructed features for a single frame.
Args:
slots: [B, K, D] slots for one frame
attention_map: [B, K, N] optional pre-computed attention
Returns:
reconstructed: [B, N, D_feature]
masks: [B, K, N] segmentation masks
"""
return self.decoder(slots, attention_map)
def forward(
self,
video: torch.Tensor,
return_all: bool = False
) -> Dict[str, torch.Tensor]:
"""
Forward pass for training.
Args:
video: [B, T, 3, H, W] input video
return_all: whether to return intermediate outputs
Returns:
Dictionary containing losses and optional intermediates
"""
B, T = video.shape[:2]
# 1. Encode frames
features = self.encode_frames(video) # [B, T, N, D_feature]
# 2. Slot attention with temporal recurrence
slots_initial, attention_maps, _ = self.apply_slot_attention(features)
# slots_initial: [B, K, D, T]
# 3. Temporal transformer with masking
slots_fused, mask = self.apply_temporal_transformer(
slots_initial,
mask_ratio=self.config.mask_ratio if self.training else None
)
# 4. Decode each frame
reconstructions = []
decoded_masks = []
for t in range(T):
slots_t = slots_fused[:, :, :, t] # [B, K, D]
attn_t = attention_maps[:, t] # [B, K, N]
recon_t, masks_t = self.decode_frame(slots_t, attn_t)
reconstructions.append(recon_t)
decoded_masks.append(masks_t)
# Stack: [B, T, N, D_feature]
reconstructed = torch.stack(reconstructions, dim=1)
masks = torch.stack(decoded_masks, dim=1) # [B, T, K, N]
# 5. Compute losses
# Reconstruction loss (MSE on masked frames only)
if self.training and self.config.mask_ratio > 0:
# Only compute loss on masked frames
loss_recon = F.mse_loss(
reconstructed * ~mask[:, :, None, None],
features * ~mask[:, :, None, None]
)
else:
loss_recon = F.mse_loss(reconstructed, features)
# Contrastive loss on fused slots
loss_contrast = self.contrastive_loss(slots_fused)
# Total loss
loss = loss_recon + self.config.contrastive_weight * loss_contrast
outputs = {
'loss': loss,
'loss_recon': loss_recon,
'loss_contrast': loss_contrast,
'reconstructed': reconstructed,
'slots_initial': slots_initial,
'slots_fused': slots_fused,
'masks': masks,
'features': features,
}
if return_all:
outputs['attention_maps'] = attention_maps
return outputs
@torch.no_grad()
def predict_future_slots(
self,
slots_past: torch.Tensor,
num_future: int = 1
) -> torch.Tensor:
"""
Predict future slot initialization using TST.
Used for inference on sequences longer than training length.
Args:
slots_past: [B, K, D, T_past] past slots
num_future: number of future slots to predict
Returns:
future_slots: [B, K, D, num_future] predicted slots
"""
B, K, D, T = slots_past.shape
# Create empty slots for future positions
future_empty = torch.zeros(B, K, D, num_future, device=slots_past.device)
# Concatenate: [B, K, D, T + num_future]
slots_extended = torch.cat([slots_past, future_empty], dim=-1)
# Apply transformer (no masking)
slots_extended = rearrange(slots_extended, 'b k d t -> b t k d')
slots_extended = rearrange(slots_extended, 'b t k d -> b (t k) d')
# Simple forward pass
encoded = self.temporal_transformer.transformer(slots_extended)
# Reshape and extract future slots
encoded = rearrange(encoded, 'b (t k) d -> b t k d', k=K)
encoded = rearrange(encoded, 'b t k d -> b k d t')
future_slots = encoded[:, :, :, -num_future:]
return future_slots
@torch.no_grad()
def segment_video(
self,
video: torch.Tensor,
use_future_prediction: bool = False
) -> Dict[str, torch.Tensor]:
"""
Inference: segment video into object masks.
Args:
video: [B, T, 3, H, W] input video
use_future_prediction: whether to use future slot prediction
Returns:
Dictionary with segmentation masks and slot assignments
"""
self.eval()
T = video.shape[1]
train_T = self.config.num_frames
if T <= train_T or not use_future_prediction:
# Standard forward pass
outputs = self.forward(video, return_all=True)
# Reshape masks to image space
masks = outputs['masks'] # [B, T, K, N]
B, T, K, N = masks.shape
H = W = int(math.sqrt(N))
masks_spatial = rearrange(
masks,
'b t k (h w) -> b t k h w',
h=H, w=W
)
# Upsample to original resolution
masks_upsampled = F.interpolate(
rearrange(masks_spatial, 'b t k h w -> (b t) k h w'),
size=(self.config.img_size, self.config.img_size),
mode='bilinear',
align_corners=False
)
masks_upsampled = rearrange(
masks_upsampled,
'(b t) k h w -> b t k h w',
b=B, t=T
)
return {
'masks': masks_upsampled,
'slots': outputs['slots_fused'],
'reconstructed': outputs['reconstructed']
}
else:
# Sliding window with future prediction
return self._sliding_window_inference(video)
def _sliding_window_inference(
self,
video: torch.Tensor
) -> Dict[str, torch.Tensor]:
"""
Process long videos using sliding window with future prediction.
"""
B, T_total, C, H, W = video.shape
train_T = self.config.num_frames
all_masks = []
all_slots = []
# Initial window
t = 0
while t < T_total:
end_t = min(t + train_T, T_total)
window = video[:, t:end_t]
# Pad if necessary
if end_t - t < train_T:
pad_T = train_T - (end_t - t)
pad_frames = video[:, -1:].expand(B, pad_T, C, H, W)
window = torch.cat([window, pad_frames], dim=1)
# Process window
outputs = self.forward(window, return_all=True)
# Store results (only valid frames)
valid_frames = end_t - t
all_masks.append(outputs['masks'][:, :valid_frames])
all_slots.append(outputs['slots_fused'][:, :, :, :valid_frames])
# Predict future slots for next window initialization
if end_t < T_total:
future_slots = self.predict_future_slots(
outputs['slots_fused'][:, :, :, :valid_frames],
num_future=1
)
# Use for next window (implementation would continue)
t = end_t
# Concatenate all windows
masks = torch.cat(all_masks, dim=1)
slots = torch.cat(all_slots, dim=-1)
return {
'masks': masks,
'slots': slots
}
# =============================================================================
# TRAINING SCRIPT
# =============================================================================
def create_trainer(config: SlotBERTConfig):
"""
Create training components for Slot-BERT.
"""
model = SlotBERT(config)
# Only train slot-related parameters (encoder is frozen)
trainable_params = []
for name, param in model.named_parameters():
if 'encoder' not in name and param.requires_grad:
trainable_params.append(param)
optimizer = torch.optim.AdamW(
trainable_params,
lr=1e-4,
weight_decay=1e-5
)
# Learning rate scheduler with warmup
def lr_lambda(epoch):
warmup_epochs = 5
if epoch < warmup_epochs:
return epoch / warmup_epochs
return 0.5 ** ((epoch - warmup_epochs) // 20)
scheduler = torch.optim.lr_scheduler.LambdaLR(optimizer, lr_lambda)
return model, optimizer, scheduler
def train_step(
model: SlotBERT,
batch: torch.Tensor,
optimizer: torch.optim.Optimizer,
device: torch.device
) -> Dict[str, float]:
"""
Single training step.
Args:
model: SlotBERT model
batch: [B, T, 3, H, W] video batch
optimizer: Optimizer
device: Computation device
Returns:
Dictionary of loss values
"""
model.train()
batch = batch.to(device)
optimizer.zero_grad()
outputs = model(batch)
loss = outputs['loss']
loss.backward()
# Gradient clipping
torch.nn.utils.clip_grad_norm_(model.parameters(), max_norm=1.0)
optimizer.step()
return {
'total_loss': loss.item(),
'recon_loss': outputs['loss_recon'].item(),
'contrast_loss': outputs['loss_contrast'].item()
}
# =============================================================================
# EXAMPLE USAGE
# =============================================================================
def demo():
"""Demonstrate Slot-BERT with dummy data."""
# Configuration
config = SlotBERTConfig(
img_size=224,
patch_size=14,
num_frames=5,
num_slots=7,
slot_dim=256,
batch_size=2
)
# Create model
model = SlotBERT(config, decoder_type="mlp")
# Dummy video batch: [B, T, 3, H, W]
batch_size = 2
video = torch.randn(batch_size, config.num_frames, 3, 224, 224)
print(f"Input video shape: {video.shape}")
print(f"Model parameters: {sum(p.numel() for p in model.parameters()):,}")
print(f"Trainable parameters: {sum(p.numel() for p in model.parameters() if p.requires_grad):,}")
# Forward pass
outputs = model(video, return_all=True)
print(f"\nOutput shapes:")
print(f" Reconstructed: {outputs['reconstructed'].shape}")
print(f" Slots initial: {outputs['slots_initial'].shape}")
print(f" Slots fused: {outputs['slots_fused'].shape}")
print(f" Masks: {outputs['masks'].shape}")
print(f"\nLosses:")
print(f" Total: {outputs['loss'].item():.4f}")
print(f" Reconstruction: {outputs['loss_recon'].item():.4f}")
print(f" Contrastive: {outputs['loss_contrast'].item():.4f}")
# Inference
print("\n--- Inference ---")
with torch.no_grad():
seg_results = model.segment_video(video)
print(f"Segmentation masks: {seg_results['masks'].shape}")
print("\nSlot-BERT demo completed successfully!")
if __name__ == "__main__":
demo()Related posts, You May like to read
- 7 Shocking Truths About Knowledge Distillation: The Good, The Bad, and The Breakthrough (SAKD)
- TransXV2S-Net: Revolutionary AI Architecture Achieves 95.26% Accuracy in Skin Cancer Detection
- TimeDistill: Revolutionizing Time Series Forecasting with Cross-Architecture Knowledge Distillation
- HiPerformer: A New Benchmark in Medical Image Segmentation with Modular Hierarchical Fusion
- GeoSAM2 3D Part Segmentation — Prompt-Controllable, Geometry-Aware Masks for Precision 3D Editing
- DGRM: How Advanced AI is Learning to Detect Machine-Generated Text Across Different Domains
- A Knowledge Distillation-Based Approach to Enhance Transparency of Classifier Models
- Towards Trustworthy Breast Tumor Segmentation in Ultrasound Using AI Uncertainty
- IB-D2GAT: How Information Bottleneck Theory Revolutionizes Dynamic Graph Learning Under Distribution Shifts
- How AI Combines Medical Images and Patient Data to Detect Skin Cancer More Accurately: A Deep Dive into Multimodal Deep Learning