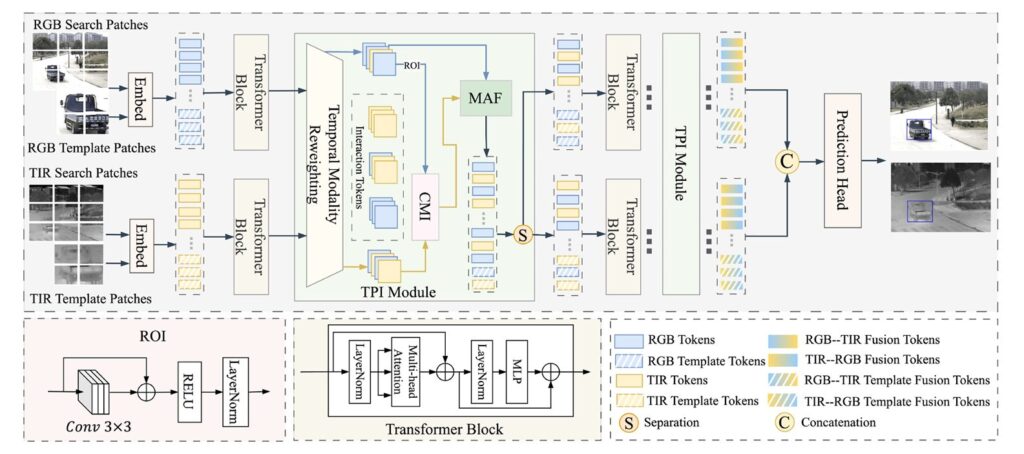
TPMRI: How Three-Stage Progressive Fusion Is Solving RGB-T Tracking’s Temporal Blindness
TPMRI: How Three-Stage Progressive Fusion Is Solving RGB-T Tracking’s Temporal Blindness | MedAI Research MedAI Research Machine Learning About Computer Vision · Knowledge-Based Systems, 2026 · 14 min read When RGB-T Trackers Lose Track: How TPMRI Learned to Remember Through Time TPMRI introduces a three-stage progressive fusion framework that fixes RGB-T tracking’s most frustrating failures […]
TPMRI: How Three-Stage Progressive Fusion Is Solving RGB-T Tracking’s Temporal Blindness Read More »