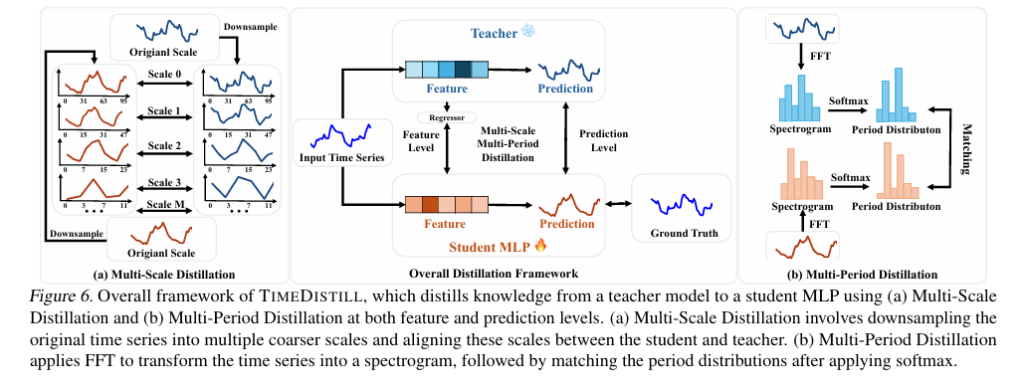
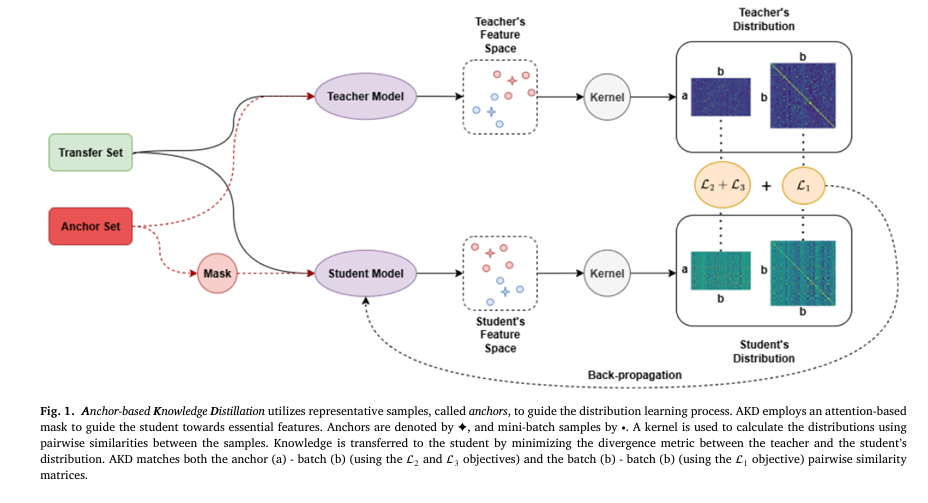
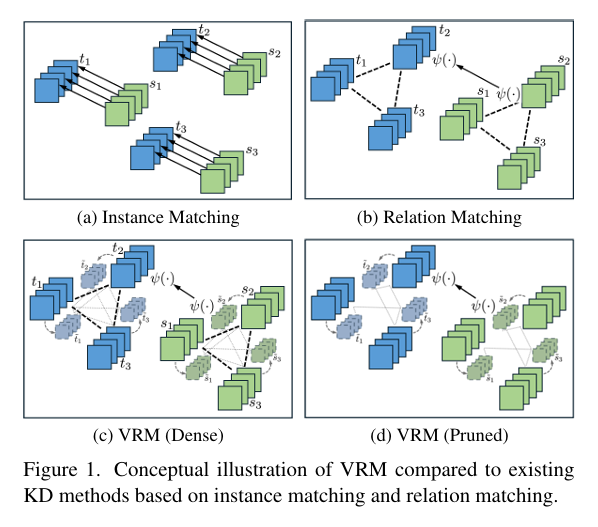
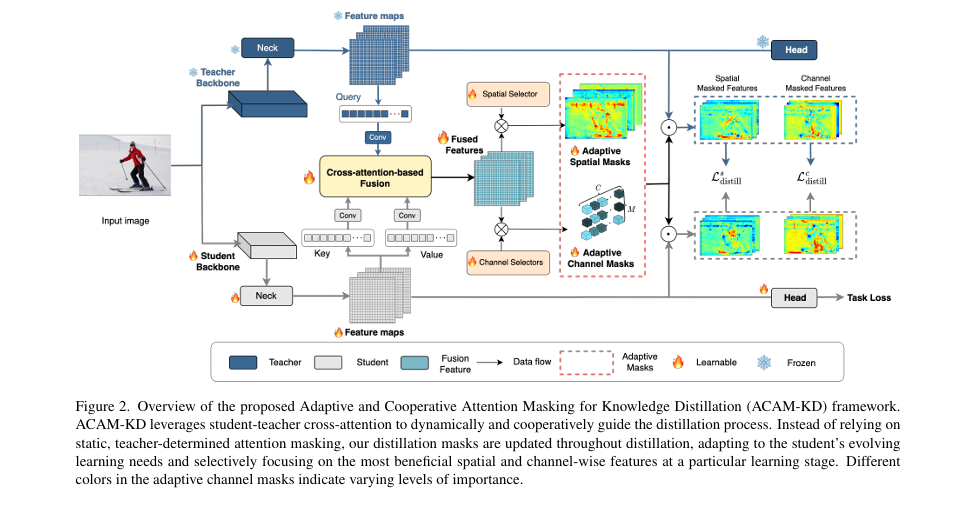
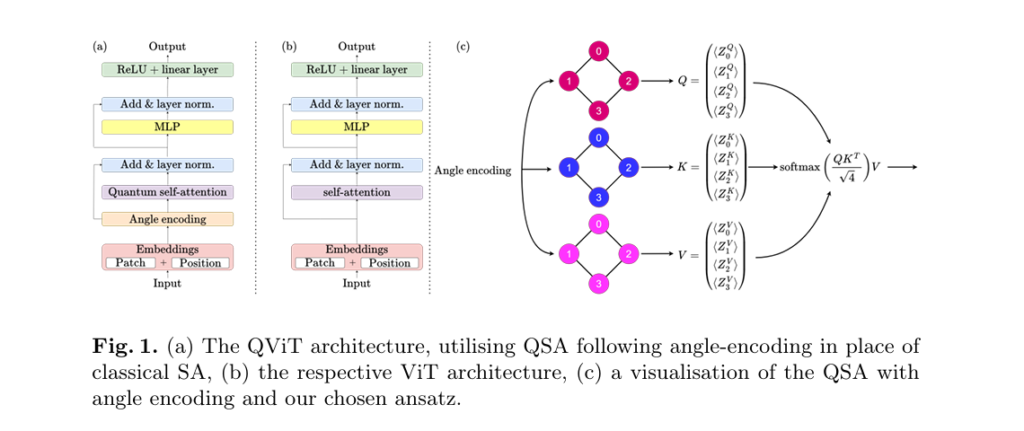
DSKD: How Sense Dictionaries Are Finally Making Decoder LLMs Smarter Without Slowing Them Down
DSKD: How Sense Dictionaries Are Finally Making Decoder LLMs Smarter Without Slowing Them Down | AI Research AITrendBlend Machine Learning About Natural Language Processing · arXiv:2602.22351v1 [cs.CL] · 15 min read DSKD: The Lexical Knowledge Injection That Finally Works for Decoder Language Models How researchers at RPI and IBM Research taught generative LLMs to understand […]