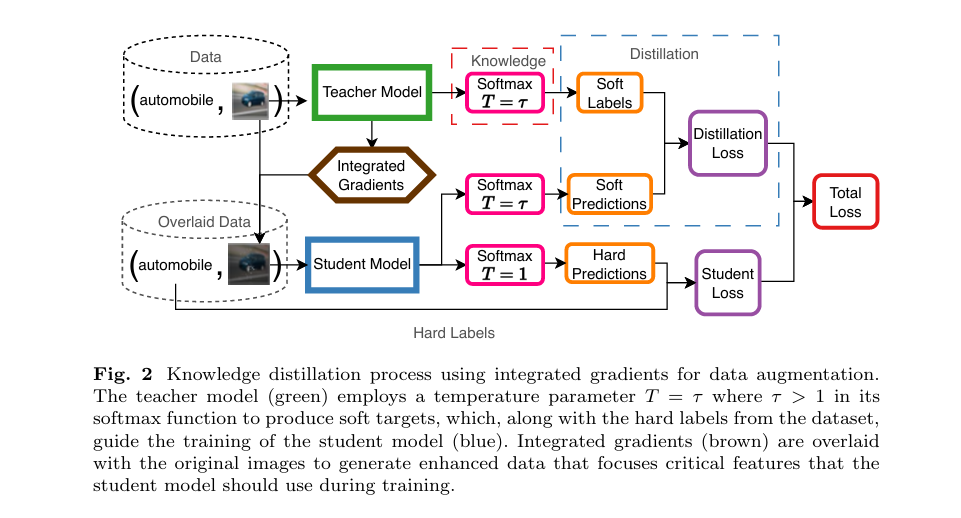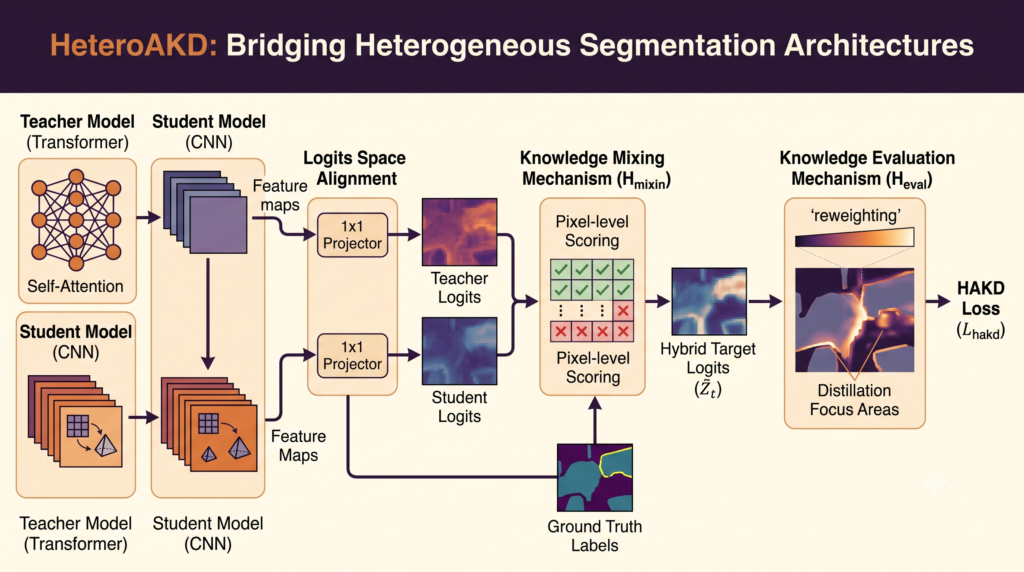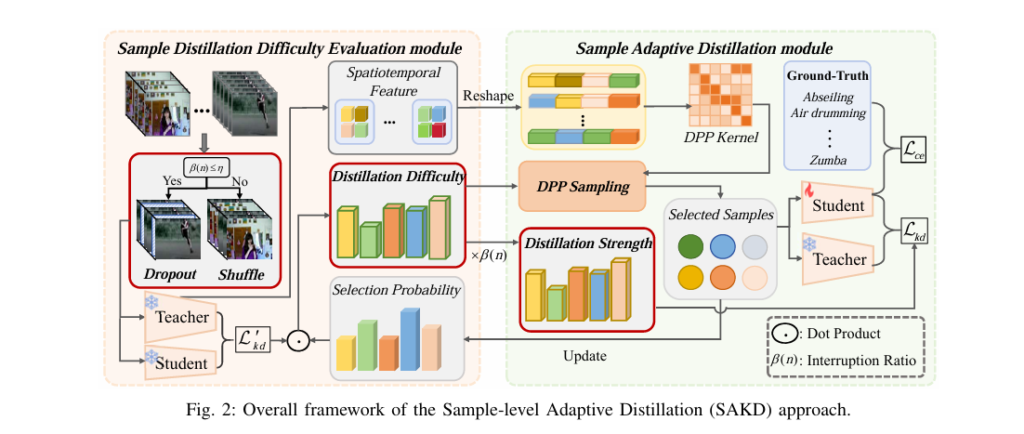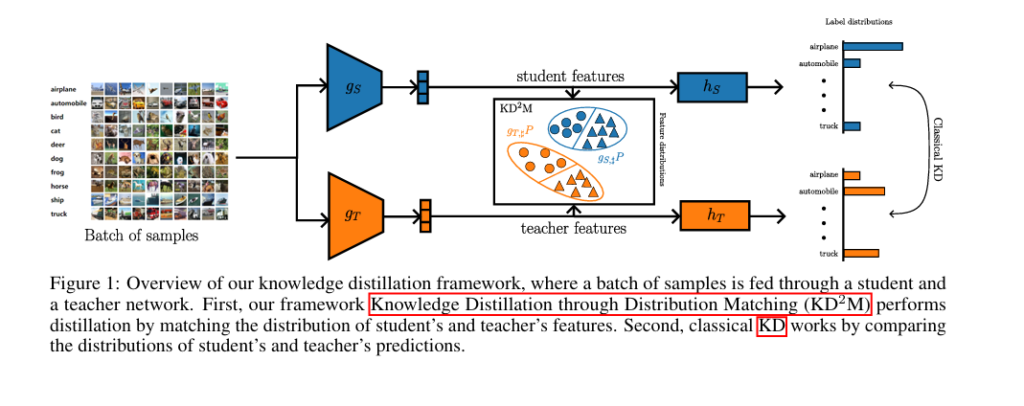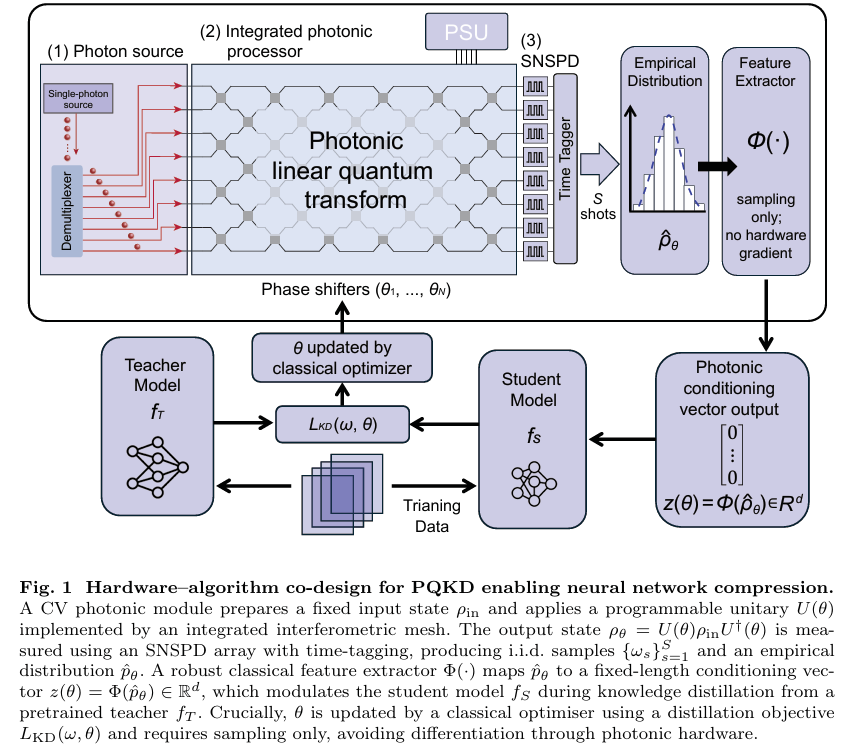
PQKD: How a Beam of Light Is Teaching AI to Learn Smarter — Photonic Quantum-Enhanced Knowledge Distillation Explained
PQKD: How a Beam of Light Is Teaching AI to Learn Smarter — Photonic Quantum-Enhanced Knowledge Distillation Explained | AI Systems Research Quantum Machine Learning · arXiv:2603.14898v1 [quant-ph] · Imperial College London · 18 min read PQKD: How a Beam of Light Is Teaching AI to Learn Smarter — Photonic Quantum-Enhanced Knowledge Distillation Explained A […]