When RGB-T Trackers Lose Track: How TPMRI Learned to Remember Through Time
TPMRI introduces a three-stage progressive fusion framework that fixes RGB-T tracking’s most frustrating failures — temporal blindness and modality misalignment — through temporal modality reweighting, cross-modality semantic interaction, and adaptive global fusion.
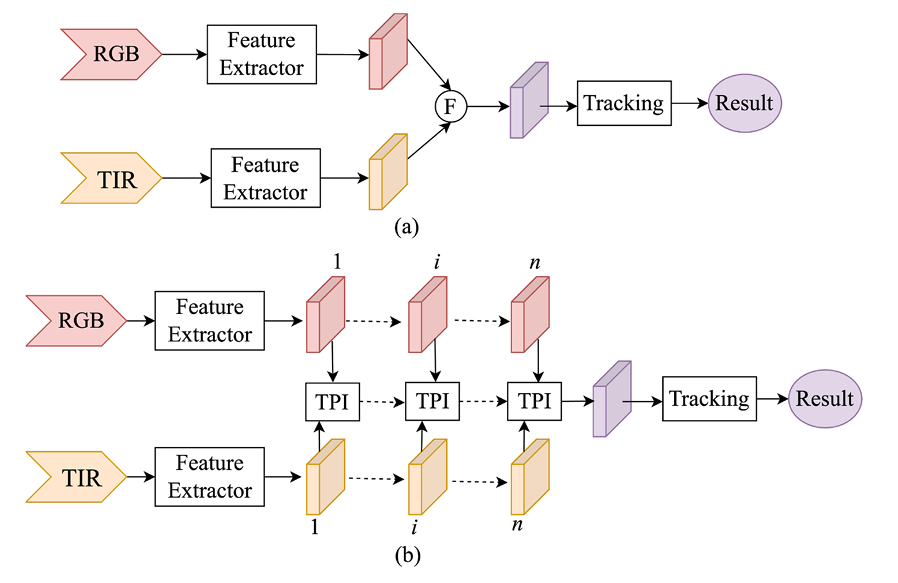
Ask an RGB-T tracker to follow a pedestrian through a dark parking garage transitioning to bright daylight, and you’ll likely see it drift or lose the target entirely. The thermal modality excels in darkness but becomes unreliable in thermal crossover scenarios; the RGB camera captures rich textures but fails completely in low light. Most existing trackers treat each frame as an independent decision, ignoring how modality reliability evolves over time.
The first issue is temporal blindness — the tracker fails to recognize that modality effectiveness fluctuates across the sequence. The second is semantic misalignment — RGB and thermal features exist in different distributions, making fine-grained fusion difficult. For years, researchers have treated these as spatial fusion problems, designing modality-aware filters or global weighting strategies. But these approaches lacked temporal awareness, leading to unstable performance when visibility conditions change.
A team from Yanshan University and the University of Exeter has taken a fundamentally different approach. Their insight, published in Knowledge-Based Systems in 2026, identifies three distinct stages where fusion can fail in RGB-T tracking. Their solution — the Three-stage Progressive Modality Reweighting and Interaction (TPMRI) framework — addresses each stage with surgical precision through a unified Three-stage Progressive Interaction (TPI) structure. The framework progressively models temporal dynamics, establishes fine-grained semantic alignment, and performs adaptive global aggregation, turning a collection of single-frame decisions into a temporally coherent tracking system.
Three Stages: Why RGB-T Tracking Fails Without Temporal Awareness
To understand TPMRI, we need to see RGB-T tracking as the researchers do — not as a static feature extraction problem, but as a temporal process where modality reliability evolves continuously. The team identified three critical failure points that previous work either missed or addressed incompletely.
First, the temporal dynamics problem. Most existing RGB-T trackers adopt static modality weighting strategies, treating each frame independently. When the RGB modality degrades due to low illumination or the thermal modality becomes unreliable during thermal crossover, these trackers cannot adapt their fusion strategy based on historical context. The result is abrupt tracking failures when conditions change.
Second, the semantic alignment problem. Even with temporal awareness, simply weighting modalities doesn’t address the fundamental distribution gap between RGB and thermal features. RGB captures texture and color; thermal captures heat signatures. These are fundamentally different semantic spaces, and naive fusion can lead to feature entanglement where complementary information is lost rather than combined.
Third, the global consistency problem. Frame-level semantic alignment alone cannot prevent temporal bias accumulation. In long-term tracking sequences, early-frame drift can propagate through the temporal modeling mechanism, causing the tracker to persistently favor the wrong modality. Without a global consistency check, temporal modeling can amplify errors rather than correct them.
These three bottlenecks explain why previous spatial-only or memory-based methods fell short. They were treating symptoms while ignoring the temporal evolution of modality reliability. TPMRI’s three-component architecture maps directly onto these three stages: Temporal Modality Reweighting (TMR) captures short-term temporal variations, Cross-Modality Interaction (CMI) establishes fine-grained semantic alignment, and Modality-Aware Fusion (MAF) performs adaptive global aggregation.
TPMRI addresses three distinct failure modes in RGB-T tracking: temporal blindness (lack of awareness of modality reliability evolution), semantic misalignment (distribution gap between RGB and thermal features), and temporal bias accumulation (error propagation in long-term sequences). Each requires a different intervention within the progressive fusion pipeline.
TMR: Teaching the Tracker to Remember Modality Reliability
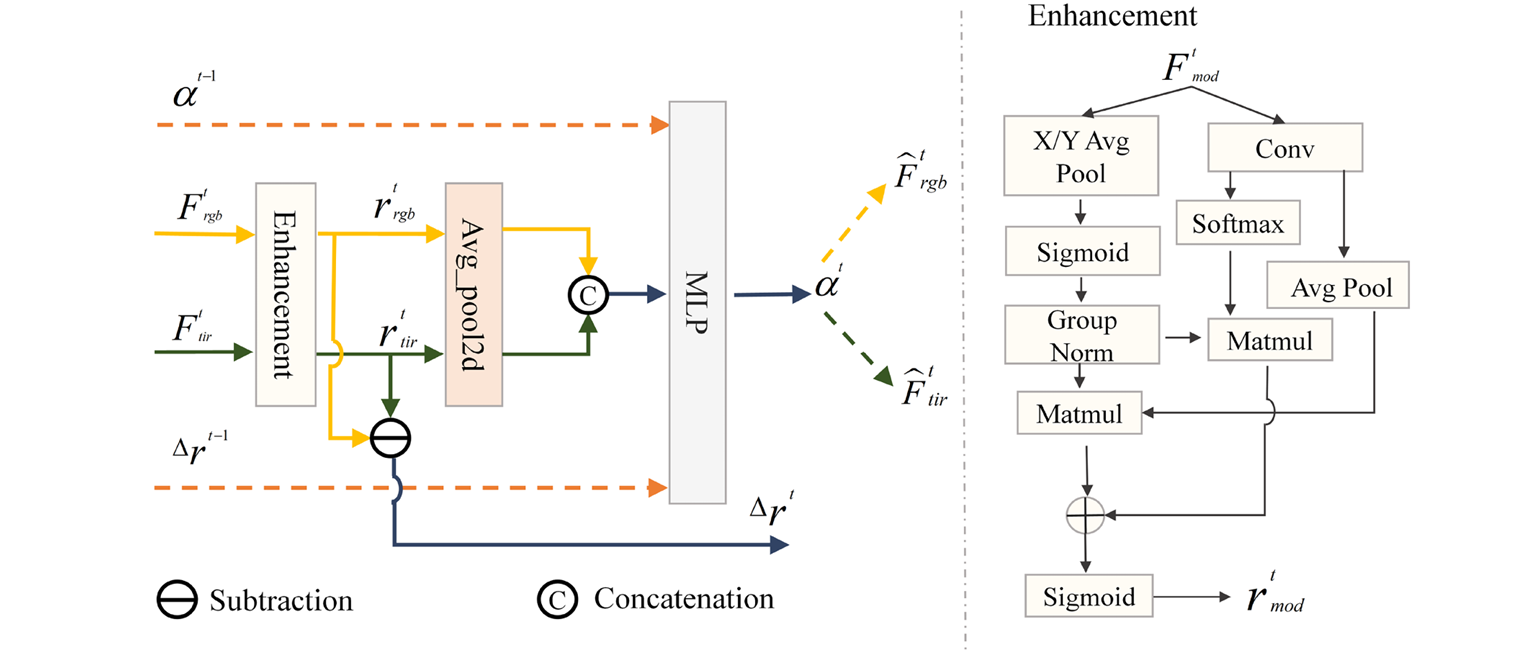
The first insight is almost embarrassingly simple once you see it: if modality effectiveness changes over time, why not track that change explicitly? But of course, we need to do this without knowing ground truth modality quality at test time. The TMR solution is elegant — propagate modality preference from previous frames while incorporating current frame evidence.
Here’s how it works. At each time step \(t\), TMR takes RGB features \(F_{rgb}^t\) and thermal features \(F_{tir}^t\), applies an Efficient Multi-scale Attention (EMA) enhancement module to emphasize salient regions, then computes modality response strengths through global average pooling:
The key innovation is the temporal context vector \(z^t\), which concatenates not just current responses but historical signals — the previous modality preference \(\alpha^{t-1}\) and response discrepancy \(\Delta r^{t-1}\):
This unified vector feeds into a lightweight MLP that outputs the current modality preference \(\alpha^t \in (0,1)\) through a sigmoid activation. The refined features become:
The effect is dramatic. By explicitly modeling the temporal evolution of modality reliability, TMR enables the tracker to smoothly transition between modalities as conditions change — favoring thermal in darkness, RGB in good lighting, and finding optimal balances in between. The closed-loop feedback of \(\alpha^t\) to the next frame creates a propagation mechanism that maintains temporal consistency.
CMI: Aligning Semantics Across Modalities
With temporally-weighted features in place, TPMRI turns to the semantic alignment problem. But rather than simple concatenation or element-wise fusion, the researchers developed a cross-attention mechanism that enables fine-grained information compensation from thermal to RGB.
The CMI module employs an asymmetric design: RGB features serve as queries (Q) while thermal features provide keys (K) and values (V). This design enables RGB features to selectively attend to informative regions in the thermal domain, facilitating adaptive extraction of semantically enriched cues.
Formally, given the temporally-weighted RGB features \(\hat{F}_{rgb}^t\) and thermal features \(\hat{F}_{tir}^t\), CMI first applies convolutional projections:
After reshaping to sequence format, the cross-attention mechanism computes:
A residual connection preserves the original RGB structure while allowing feature refinement:
This asymmetric interaction is crucial. Thermal images are typically more robust to illumination changes, making them reliable guides for refining texture-rich RGB features. The bidirectional alternative (allowing thermal to also attend to RGB) actually degrades performance — bidirectional interaction introduces feature redundancy and conflicting gradients without accuracy gains.
“Thermal images, which are typically more robust to illumination changes, can effectively serve as reliable guides to refine the texture-rich RGB features.” — Li, Liang, Kong & Zhang, Knowledge-Based Systems, 2026
MAF: Global Consistency as a Safety Net
Here’s where TPMRI gets truly innovative. Even with temporal weighting and semantic alignment, the tracker can still suffer from temporal bias accumulation in long sequences. The researchers’ solution draws on a quality gatekeeping principle: evaluate the TMR output against the spatially aligned CMI features and dynamically suppress unreliable temporal cues.
MAF first applies global average pooling to both the TMR output and CMI-enhanced features to obtain global semantic representations:
These are concatenated and fed through a lightweight two-layer perceptron to compute fusion weights:
The final fused representation combines both pathways:
The result is that MAF acts as a stabilizer, smoothing temporal fluctuations and preventing early prediction errors from propagating into future updates. It breaks the vicious cycle of drift by providing global-level adaptive aggregation that complements the frame-level processing of TMR and CMI.
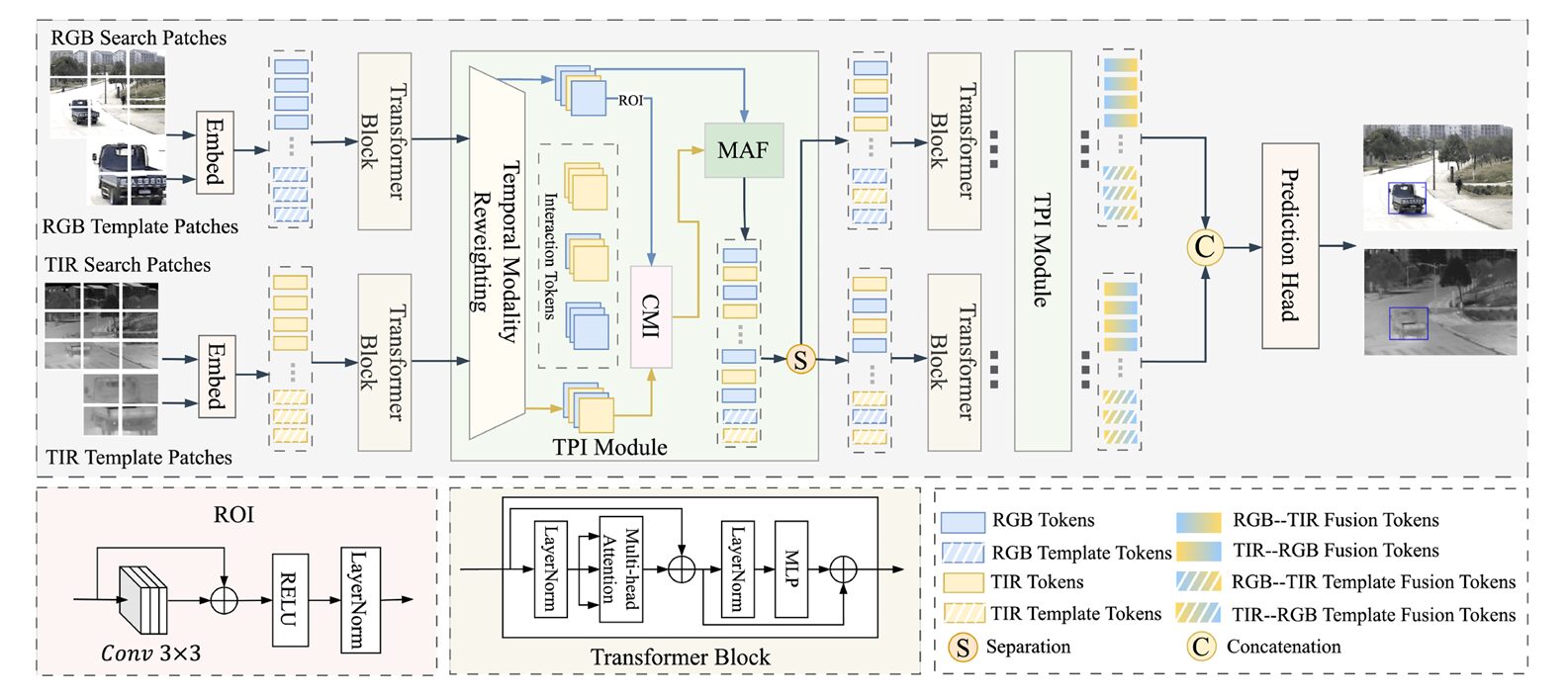
The Progressive Pipeline: From Perception to Decision
TPMRI integrates the three modules into a unified Three-stage Progressive Interaction (TPI) structure. The progressive paradigm evolves from reliability perception to semantic interaction and ultimately to adaptive fusion decision-making.
Stage 1: TMR as the Foundation. By perceiving modality reliability through temporal reweighting, TMR establishes a stable foundation for subsequent processing. It answers the question: “Which modality should I trust right now, based on what I know from the past?”
Stage 2: CMI as the Corrector. By establishing fine-grained semantic alignment via thermal-guided interaction, CMI corrects potential temporal bias and ensures information enhancement. It answers the question: “How can I use the reliable modality to improve the other?”
Stage 3: MAF as the Stabilizer. By performing global adaptive fusion, MAF smooths temporal fluctuations and reduces the accumulation of local preference errors. It answers the question: “How do I combine everything into a robust, consistent representation?”
This closed-loop mechanism balances temporal adaptability, semantic interaction, and global consistency. The progressive design ensures that each stage builds upon the previous, creating a synergistic whole greater than the sum of its parts.
Performance: State-of-the-Art on Three Benchmarks
TPMRI’s effectiveness is best appreciated through its quantitative results. On the LasHeR dataset — the largest RGB-T tracking benchmark with 245 test sequences — TPMRI achieves 66.0% Precision Rate (PR), 62.5% Normalized Precision Rate (NPR), and 53.0% Success Rate (SR).
These results represent substantial improvements over existing methods. Compared to CMD (59.0%/54.6%/46.4%) and IPL (61.7%/56.8%/49.4%), TPMRI improves PR by 7.0% and 4.3%, and SR by 6.6% and 3.6% respectively. Even against recent strong performers like ViPT (65.1%/52.5%) and M³Track (64.0%/51.1%), TPMRI maintains competitive or superior performance.
On RGBT234 — featuring 234 video pairs with sequences up to 4000 frames — TPMRI achieves 81.6% PR and 60.2% SR, outperforming MANet++ (80.0%/55.4%), ADRNet (80.9%/57.1%), and VLCTrack (81.5%/56.1%). The 60.2% SR is particularly notable as it represents a 3%+ improvement over most competitors, indicating superior robustness in long-term tracking.
On the smaller but challenging GTOT dataset, TPMRI achieves 89.7% PR and 74.7% SR, surpassing CSMMA (89.5%/73.0%), CMD (89.2%/73.4%), and BAT (88.5%/73.3%). The consistent gains across all three benchmarks demonstrate strong generalization capability.
| Method | GTOT PR↑ | GTOT SR↑ | RGBT234 PR↑ | RGBT234 SR↑ | LasHeR PR↑ | LasHeR SR↑ |
|---|---|---|---|---|---|---|
| MANet++ | — | — | 80.0 | 55.4 | — | — |
| ADRNet | — | — | 80.9 | 57.1 | — | — |
| CMD | 89.2 | 73.4 | — | — | 59.0 | 46.4 |
| ViPT | — | — | — | — | 65.1 | 52.5 |
| M³Track | — | — | — | — | 64.0 | 51.1 |
| TPMRI (Ours) | 89.7 | 74.7 | 81.6 | 60.2 | 66.0 | 53.0 |
Performance comparison on three RGB-T tracking benchmarks. TPMRI achieves state-of-the-art results across GTOT, RGBT234, and LasHeR datasets. PR = Precision Rate, SR = Success Rate. Data from Tables 2-4, Li et al., 2026.
Beyond overall metrics, TPMRI excels on challenging attributes. On LasHeR’s 19 attribute categories, it achieves leading performance on Thermal Crossover (TC), Total Occlusion (TO), and Deformation (DEF) — scenarios where spatial or temporal reliability is severely compromised. The progressive fusion framework effectively mitigates modality conflict and adapts to dynamic appearance changes.
What the Ablations Reveal
The researchers conducted extensive ablation studies to validate each component’s contribution. The results tell a clear story: all three stages matter, and they work synergistically.
Removing TMR (w/o TMR) causes the most significant performance drop — from 89.7%/74.7% to 80.2%/66.5% on GTOT. Without temporal modeling, the tracker cannot adapt to changing modality reliability, leading to suboptimal fusion in dynamic scenarios. This confirms that temporal awareness is foundational to robust RGB-T tracking.
Removing CMI (w/o CMI) also degrades performance significantly — to 85.4%/70.7% on GTOT. Without fine-grained semantic alignment, the interaction between modalities becomes less precise, hampering the ability to dynamically correct inconsistencies caused by early-frame drift.
Removing MAF (w/o MAF) results in 86.0%/71.6% on GTOT. Without global adaptive fusion, temporal bias accumulates over extended tracking periods, causing unstable modality selection in long sequences.
Perhaps most interesting is the interaction between components. TMR alone provides temporal adaptability but can accumulate bias; CMI alone provides semantic alignment but lacks temporal context; MAF alone provides global consistency but misses temporal dynamics. Only the full three-stage pipeline achieves optimal performance, demonstrating that the progressive design is essential.
Additional ablations validate key design choices: incorporating historical cues (\(\alpha^{t-1}\) and \(\Delta r^{t-1}\)) in TMR improves RGBT234 performance from 78.6%/58.4% to 81.6%/60.2%; the TIR→RGB direction in CMI outperforms bidirectional interaction; and global average pooling in MAF outperforms spatial attention variants by capturing modality unreliability at the global level.
Efficiency: Performance Without Prohibitive Cost
Beyond accuracy, TPMRI maintains competitive efficiency. The proposed modules introduce negligible computational overhead compared to the baseline. Specifically, TMR adds only 0.2028M parameters and 0.3407G FLOPs; CMI adds 0.0017M parameters; and MAF adds merely 0.0005M parameters.
The total parameter count of the full framework is 93.5669M with 23.0765G FLOPs — a marginal increase over the baseline’s 93.3619M/22.7247G. This demonstrates that significant performance improvements are achieved through efficient architectural design and effective feature interaction, rather than simply increasing model size.
TPMRI achieves 15.7 FPS on an NVIDIA RTX 4090, outperforming comparable methods like ViPT (14.1 FPS), SDSTrack (10.4 FPS), and UnTrack (12.7 FPS). This confirms that the three-stage progressive design does not compromise real-time performance.
Limitations and the Path Forward
The authors are candid about TPMRI’s current limitations. First, the method assumes relatively stable temporal dynamics — abrupt, extreme changes in both modalities simultaneously remain challenging. While TMR handles gradual transitions well, catastrophic failure in both RGB and thermal at once exceeds the framework’s recovery capability.
Second, the cross-modality interaction is currently asymmetric (TIR→RGB only). While this design choice improves performance over bidirectional alternatives, it assumes thermal is generally more reliable. In scenarios where RGB is consistently superior (rare but possible in certain artificial lighting conditions), this asymmetry could be suboptimal.
Third, the framework’s effectiveness depends on the quality of the backbone features. TPMRI is designed to enhance fusion, not compensate for severely deficient single-modality representations. If one modality is completely uninformative (not just degraded), the progressive fusion cannot create information from nothing.
Finally, TPMRI doesn’t explicitly model spatial relationships between the target and background. While MAF provides global consistency, fine-grained spatial discrimination in cluttered backgrounds with similar thermal signatures remains an area for improvement.
The Broader Implications for Multi-Modal Tracking
TPMRI represents a paradigm shift in how we think about multi-modal tracking fusion. The dominant approaches have been either static fusion (treating each frame independently) or memory-based template updating (maintaining appearance consistency). TPMRI shows that explicitly modeling the continuous evolution of modality reliability — not just appearance — is key to robust performance.
This has practical significance. RGB-T trackers are deployed in critical applications from autonomous driving to surveillance to search and rescue. These are exactly the scenarios where lighting conditions change unpredictably — tunnels, dawn/dusk transitions, indoor/outdoor movement. TPMRI’s temporal awareness makes it particularly suited for these real-world deployment conditions.
Philosophically, TPMRI suggests that the “knowledge” in multi-modal trackers is more structured than we assumed. The fact that temporal preference propagation, semantic alignment, and global consistency can be separated into distinct stages — each addressable with targeted mechanisms — implies that fusion is not a monolithic black box but a decomposable pipeline.
Looking ahead, TPMRI’s three-pronged approach — temporal modeling, semantic interaction, global stabilization — could generalize beyond RGB-T tracking. Other multi-modal fusion problems, such as RGB-D tracking or audio-visual tracking, face similar challenges of modality reliability variation and distribution misalignment. The specific mechanisms would differ, but the principles of progressive fusion could transfer.
For now, TPMRI sets a new standard for robust RGB-T tracking. It demonstrates that the gap between what multi-modal trackers can achieve and what they do achieve can be bridged through careful analysis of temporal dynamics and surgical architectural interventions. The tracker that remembers modality reliability through time, aligns semantics across modalities, and maintains global consistency — that is the tracker that succeeds when conditions get tough.
PyTorch Implementation: TPMRI Core Components
The implementation below captures the essential mechanisms of TPMRI: temporal modality reweighting with historical signal propagation, cross-modality attention for semantic alignment, and adaptive global fusion for consistency. The code demonstrates how these components integrate into a unified three-stage progressive interaction framework.
# ─────────────────────────────────────────────────────────────────────────────
# TPMRI: Three-stage Progressive Modality Reweighting and Interaction
# Li, Liang, Kong & Zhang · Knowledge-Based Systems 2026
# Core implementation: TMR, CMI, and MAF modules for RGB-T tracking
# ─────────────────────────────────────────────────────────────────────────────
import torch
import torch.nn as nn
import torch.nn.functional as F
from typing import Tuple, Optional
import math
# ─── Section 1: Temporal Modality Reweighting (TMR) ──────────────────────────
class EMA(nn.Module):
"""
Efficient Multi-scale Attention module for feature enhancement.
Used within TMR to emphasize salient regions before response computation.
"""
def __init__(self, channels: int, factor: int = 8):
super().__init__()
self.avg_pool_x = nn.AdaptiveAvgPool2d((None, 1))
self.avg_pool_y = nn.AdaptiveAvgPool2d((1, None))
self.conv1x1 = nn.Conv2d(channels, channels // factor, kernel_size=1, bias=False)
self.group_norm = nn.GroupNorm(32, channels // factor)
self.sigmoid = nn.Sigmoid()
def forward(self, x: torch.Tensor) -> torch.Tensor:
b, c, h, w = x.size()
# X and Y average pooling
x_avg = self.avg_pool_x(x).expand(-1, -1, h, w)
y_avg = self.avg_pool_y(x).expand(-1, -1, h, w)
# Convolution path
conv_out = self.conv1x1(x)
conv_out = self.sigmoid(conv_out)
# Attention computation
attn = self.sigmoid(self.group_norm(x_avg + y_avg))
out = x * attn * conv_out
return self.sigmoid(out)
class TMRModule(nn.Module):
"""
Temporal Modality Reweighting module.
Dynamically models modality reliability over time by incorporating
historical modality preference and response discrepancy.
"""
def __init__(self, channels: int = 768, hidden_dim: int = 64):
super().__init__()
self.ema_rgb = EMA(channels)
self.ema_tir = EMA(channels)
# MLP for modality preference estimation: R^4 -> R^1
self.mlp = nn.Sequential(
nn.Linear(4, hidden_dim),
nn.ReLU(inplace=True),
nn.Linear(hidden_dim, 1),
nn.Sigmoid()
)
# Initialize historical states
self.alpha_prev = None # Previous modality preference
self.delta_r_prev = None # Previous response discrepancy
def compute_response(self, feat: torch.Tensor) -> torch.Tensor:
"""Compute modality response strength via global average pooling."""
return feat.mean(dim=[1, 2, 3], keepdim=True) # [B, 1, 1, 1]
def forward(
self,
F_rgb: torch.Tensor, # [B, C, H, W]
F_tir: torch.Tensor, # [B, C, H, W]
reset_history: bool = False
) -> Tuple[torch.Tensor, torch.Tensor, torch.Tensor]:
"""
Temporal modality reweighting with historical signal propagation.
Args:
F_rgb: RGB features at current timestep
F_tir: Thermal features at current timestep
reset_history: Whether to reset temporal state (new sequence)
Returns:
F_rgb_weighted: Weighted RGB features
F_tir_weighted: Weighted thermal features
alpha: Current modality preference [0, 1]
"""
b = F_rgb.size(0)
# Reset history for new sequences
if reset_history or self.alpha_prev is None:
self.alpha_prev = torch.ones(b, 1, device=F_rgb.device) * 0.5
self.delta_r_prev = torch.zeros(b, 1, device=F_rgb.device)
# Step 1: Feature enhancement via EMA
F_rgb_enh = self.ema_rgb(F_rgb)
F_tir_enh = self.ema_tir(F_tir)
# Step 2: Compute current response strengths
r_rgb = self.compute_response(F_rgb_enh).squeeze()
r_tir = self.compute_response(F_tir_enh).squeeze()
# Step 3: Compute response discrepancy
delta_r = r_rgb - r_tir
# Step 4: Construct temporal context vector z^t
# z^t = [r_rgb^t, r_tir^t, delta_r^{t-1}, alpha^{t-1}]
z = torch.stack([
r_rgb,
r_tir,
self.delta_r_prev.squeeze(),
self.alpha_prev.squeeze()
], dim=1) # [B, 4]
# Step 5: Estimate modality preference via MLP
alpha = self.mlp(z) # [B, 1], in (0, 1)
# Step 6: Apply modality reweighting
# F_hat_rgb = alpha * F_rgb, F_hat_tir = (1-alpha) * F_tir
alpha_expanded = alpha.view(b, 1, 1, 1)
F_rgb_weighted = alpha_expanded * F_rgb
F_tir_weighted = (1 - alpha_expanded) * F_tir
# Step 7: Update historical states for next timestep
self.alpha_prev = alpha.detach()
self.delta_r_prev = delta_r.detach().unsqueeze(1)
return F_rgb_weighted, F_tir_weighted, alpha
# ─── Section 2: Cross-Modality Interaction (CMI) ─────────────────────────────
class CrossModalityAttention(nn.Module):
"""
Cross-modality attention mechanism for CMI module.
RGB features as Query, TIR features as Key and Value.
"""
def __init__(self, dim: int, num_heads: int = 8, qkv_bias: bool = False):
super().__init__()
self.num_heads = num_heads
self.head_dim = dim // num_heads
self.scale = self.head_dim ** -0.5
# Separate projections for asymmetric interaction
self.q_proj = nn.Conv2d(dim, dim // 2, kernel_size=1, bias=qkv_bias) # RGB -> Q
self.k_proj = nn.Conv2d(dim, dim // 2, kernel_size=1, bias=qkv_bias) # TIR -> K
self.v_proj = nn.Conv2d(dim, dim, kernel_size=1, bias=qkv_bias) # TIR -> V
self.proj = nn.Conv2d(dim, dim, kernel_size=1)
def forward(self, rgb_feat: torch.Tensor, tir_feat: torch.Tensor) -> torch.Tensor:
"""
Cross-modality attention: RGB queries attend to TIR keys/values.
Args:
rgb_feat: RGB features [B, C, H, W]
tir_feat: Thermal features [B, C, H, W]
Returns:
enhanced_rgb: RGB features enhanced with TIR information
"""
b, c, h, w = rgb_feat.shape
# Generate Q from RGB, K and V from TIR
Q = self.q_proj(rgb_feat) # [B, C/2, H, W]
K = self.k_proj(tir_feat) # [B, C/2, H, W]
V = self.v_proj(tir_feat) # [B, C, H, W]
# Reshape to 2D format: [B, H*W, C]
Q = Q.flatten(2).transpose(1, 2) # [B, HW, C/2]
K = K.flatten(2).transpose(1, 2) # [B, HW, C/2]
V = V.flatten(2).transpose(1, 2) # [B, HW, C]
# Compute attention: A = Softmax(Q'K')
attn = torch.bmm(Q, K.transpose(1, 2)) * self.scale # [B, HW, HW]
attn = F.softmax(attn, dim=-1)
# Apply attention to values
enhanced = torch.bmm(attn, V) # [B, HW, C]
# Reshape back to spatial format
enhanced = enhanced.transpose(1, 2).view(b, c, h, w)
enhanced = self.proj(enhanced)
# Residual connection
output = enhanced + rgb_feat
return output
class CMIModule(nn.Module):
"""
Cross-Modality Interaction module.
Establishes fine-grained semantic alignment between RGB and TIR
through asymmetric cross-attention (TIR guides RGB).
"""
def __init__(self, dim: int = 768):
super().__init__()
self.cross_attn = CrossModalityAttention(dim)
def forward(
self,
F_rgb: torch.Tensor, # [B, C, H, W] from TMR
F_tir: torch.Tensor # [B, C, H, W] from TMR
) -> torch.Tensor:
"""
Perform cross-modality interaction.
Returns:
F_cmi: Enhanced RGB features with TIR guidance [B, C, H, W]
"""
F_cmi = self.cross_attn(F_rgb, F_tir)
return F_cmi
# ─── Section 3: Modality-Aware Fusion (MAF) ──────────────────────────────────
class MAFModule(nn.Module):
"""
Modality-Aware Fusion module.
Performs adaptive global aggregation to smooth temporal fluctuations
and prevent bias accumulation.
"""
def __init__(self, dim: int = 768, reduction: int = 4):
super().__init__()
self.gap = nn.AdaptiveAvgPool2d(1)
# Two-layer perceptron for fusion weight generation
self.fc = nn.Sequential(
nn.Linear(dim * 2, dim // reduction),
nn.ReLU(inplace=True),
nn.Linear(dim // reduction, 2), # Output 2 weights
nn.Softmax(dim=1) # Ensure alpha + beta = 1
)
def forward(
self,
F_rgb: torch.Tensor, # [B, C, H, W] from TMR
F_cmi: torch.Tensor # [B, C, H, W] from CMI
) -> torch.Tensor:
"""
Adaptive global fusion of TMR output and CMI-enhanced features.
Args:
F_rgb: TMR-weighted RGB features
F_cmi: CMI-enhanced features (RGB with TIR guidance)
Returns:
F_fused: Globally fused features [B, C, H, W]
"""
# Step 1: Global information aggregation
f_rgb = self.gap(F_rgb).flatten(1) # [B, C]
f_cmi = self.gap(F_cmi).flatten(1) # [B, C]
# Step 2: Joint representation
f_cat = torch.cat([f_rgb, f_cmi], dim=1) # [B, 2C]
# Step 3: Adaptive weight generation
weights = self.fc(f_cat) # [B, 2], weights sum to 1
alpha = weights[:, 0].view(-1, 1, 1, 1) # Weight for F_rgb
beta = weights[:, 1].view(-1, 1, 1,1) # Step 4: Weighted fusion
F_fused = alpha * F_rgb + beta * F_cmi
return F_fused
# ─── Section 4: Three-stage Progressive Interaction (TPI) Module ─────────────
class TPIModule(nn.Module):
"""
Three-stage Progressive Interaction (TPI) module.
Unifies TMR, CMI, and MAF into a single progressive fusion pipeline
that evolves from temporal modeling to semantic interaction to
adaptive fusion decision-making.
"""
def __init__(self, dim: int = 768):
super().__init__()
self.tmr = TMRModule(dim)
self.cmi = CMIModule(dim)
self.maf = MAFModule(dim)
def forward(
self,
F_rgb: torch.Tensor,
F_tir: torch.Tensor,
reset_history: bool = False
) -> Tuple[torch.Tensor, torch.Tensor]:
"""
Three-stage progressive fusion.
Stage 1 (TMR): Temporal modality reweighting - perceives reliability
Stage 2 (CMI): Cross-modality interaction - establishes semantic alignment
Stage 3 (MAF): Modality-aware fusion - performs adaptive global aggregation
Returns:
F_fused: Final fused features
alpha: Modality preference from TMR (for monitoring)
"""
# Stage 1: TMR - Temporal Modality Reweighting
F_rgb_tmr, F_tir_tmr, alpha = self.tmr(F_rgb, F_tir, reset_history)
# Stage 2: CMI - Cross-Modality Interaction (TIR guides RGB)
F_cmi = self.cmi(F_rgb_tmr, F_tir_tmr)
# Stage 3: MAF - Modality-Aware Fusion (global aggregation)
F_fused = self.maf(F_rgb_tmr, F_cmi)
return F_fused, alpha
# ─── Section 5: Complete TPMRI Tracker Integration ───────────────────────────
class TPMRI(nn.Module):
"""
Complete TPMRI tracker with Transformer backbone and TPI modules.
Integrates TPI modules after each Transformer block for progressive
multi-modal fusion throughout the feature hierarchy.
"""
def __init__(
self,
backbone_dim: int = 768,
num_tpi_layers: int = 12,
pretrained_backbone: Optional[str] = None
):
super().__init__()
# Transformer backbone (e.g., ViT-Base)
self.backbone = self._build_backbone(backbone_dim, pretrained_backbone)
# TPI modules integrated after each Transformer block
self.tpi_modules = nn.ModuleList([
TPIModule(backbone_dim) for _ in range(num_tpi_layers)
])
# Prediction head (center-based from OSTrack)
self.head = self._build_head(backbone_dim)
def _build_backbone(self, dim: int, pretrained: Optional[str]) -> nn.Module:
"""Build Transformer backbone for feature extraction."""
# Implementation would load ViT-Base or similar
# Returns backbone that processes both RGB and TIR patches
pass
def _build_head(self, dim: int) -> nn.Module:
"""
Build center-based prediction head.
Three branches: classification, center offset, and size regression.
"""
return nn.ModuleDict({
'cls': nn.Sequential(
nn.Conv2d(dim, dim, 3, padding=1),
nn.BatchNorm2d(dim),
nn.ReLU(inplace=True),
nn.Conv2d(dim, 1, 1) # Classification score
),
'offset': nn.Sequential(
nn.Conv2d(dim, dim, 3, padding=1),
nn.BatchNorm2d(dim),
nn.ReLU(inplace=True),
nn.Conv2d(dim, 2, 1) # Center offset (x, y)
),
'size': nn.Sequential(
nn.Conv2d(dim, dim, 3, padding=1),
nn.BatchNorm2d(dim),
nn.ReLU(inplace=True),
nn.Conv2d(dim, 2, 1) # Size (w, h)
)
})
def forward(
self,
rgb_template: torch.Tensor,
rgb_search: torch.Tensor,
tir_template: torch.Tensor,
tir_search: torch.Tensor,
reset_history: bool = False
) -> Dict[str, torch.Tensor]:
"""
Forward pass of TPMRI tracker.
Args:
rgb_template: Template RGB patches [B, 3, H, W]
rgb_search: Search RGB patches [B, 3, H, W]
tir_template: Template thermal patches [B, 3, H, W]
tir_search: Search thermal patches [B, 3, H, W]
reset_history: Reset TMR temporal state (new sequence)
Returns:
outputs: Dict with 'cls' (classification), 'offset', 'size'
"""
# Extract features from both modalities via backbone
# Returns list of features at each layer for both template and search
rgb_features, tir_features = self.backbone(
rgb_template, rgb_search, tir_template, tir_search
)
# Progressive fusion through TPI modules at each layer
fused_features = []
for i, (rgb_feat, tir_feat, tpi) in enumerate(
zip(rgb_features, tir_features, self.tpi_modules)
):
# Apply TPI: TMR -> CMI -> MAF
fused, alpha = tpi(rgb_feat, tir_feat, reset_history=(reset_history and i == 0))
fused_features.append(fused)
# Final fused features from last layer
final_features = fused_features[-1]
# Prediction head
outputs = {
'cls': self.head['cls'](final_features),
'offset': self.head['offset'](final_features),
'size': self.head['size'](final_features)
}
return outputs
# ─── Section 6: Loss Functions ───────────────────────────────────────────────
class TPMRILoss(nn.Module):
"""
Composite loss for TPMRI training.
Combines focal loss for classification with GIoU and L1 losses
for bounding box regression.
"""
def __init__(self, lambda_giou: float = 2.0, lambda_l1: float = 5.0):
super().__init__()
self.lambda_giou = lambda_giou
self.lambda_l1 = lambda_l1
self.focal_loss = self._focal_loss
def _focal_loss(self, pred: torch.Tensor, target: torch.Tensor, alpha: float = 0.25, gamma: float = 2.0) -> torch.Tensor:
"""Focal loss for classification."""
bce = F.binary_cross_entropy_with_logits(pred, target, reduction='none')
pt = torch.exp(-bce)
focal = alpha * (1 - pt) ** gamma * bce
return focal.mean()
def giou_loss(self, pred_boxes: torch.Tensor, target_boxes: torch.Tensor) -> torch.Tensor:
"""Generalized IoU loss for bounding box regression."""
# Implementation of GIoU calculation
# ...
pass
def forward(
self,
outputs: Dict[str, torch.Tensor],
targets: Dict[str, torch.Tensor]
) -> torch.Tensor:
"""
Compute total loss.
L_total = L_cls + lambda_giou * L_GIoU + lambda_l1 * L_L1
"""
loss_cls = self.focal_loss(outputs['cls'], targets['cls'])
loss_giou = self.giou_loss(outputs['boxes'], targets['boxes'])
loss_l1 = F.l1_loss(outputs['boxes'], targets['boxes'])
total_loss = loss_cls + self.lambda_giou * loss_giou + self.lambda_l1 * loss_l1
return total_loss
# ─── Section 7: Usage Example ────────────────────────────────────────────────
if __name__ == "__main__":
"""
Example: Initialize TPMRI tracker and perform tracking inference.
"""
# Initialize TPMRI with ViT-Base backbone
model = TPMRI(
backbone_dim=768,
num_tpi_layers=12,
pretrained_backbone='vit_base_patch16_224'
).cuda()
# Example input tensors (batch_size=1)
rgb_template = torch.randn(1, 3, 128, 128).cuda()
rgb_search = torch.randn(1, 3, 256, 256).cuda()
tir_template = torch.randn(1, 3, 128, 128).cuda()
tir_search = torch.randn(1, 3, 256, 256).cuda()
# First frame: reset temporal history
outputs = model(
rgb_template, rgb_search,
tir_template, tir_search,
reset_history=True
)
print(f"Classification map shape: {outputs['cls'].shape}")
print(f"Offset map shape: {outputs['offset'].shape}")
print(f"Size map shape: {outputs['size'].shape}")
print("✓ TPMRI forward pass complete — temporal fusion enabled")
# Subsequent frames: temporal state propagates automatically
# outputs = model(rgb_template, rgb_search, tir_template, tir_search)
Access the Full Paper
The complete TPMRI methodology, theoretical analysis, and extensive experimental validation are available in the Knowledge-Based Systems publication. The paper includes detailed ablation studies, comparisons with state-of-the-art methods on GTOT, RGBT234, and LasHeR benchmarks, and analysis of attribute-based performance.
Li, H., Liang, J., Kong, W., & Zhang, X. (2026). Three-stage progressive modality reweighting and interaction framework for robust RGB-T tracking. Knowledge-Based Systems, 339, 115453. https://doi.org/10.1016/j.knosys.2026.115453
This article is an independent editorial analysis of publicly available peer-reviewed research. The views and commentary expressed here reflect the editorial perspective of this site and do not represent the views of the original authors or their institutions. Code implementations are provided for educational purposes. Always refer to the original paper and official documentation for authoritative details.
Explore More on MedAI Research
If this analysis sparked your interest, here is more of what we cover across the site — from foundational tutorials to the latest research breakdowns in machine learning and AI systems.