The Static Model Merging Problem — and How WEMoE Learned to Adapt
WEMoE introduces a dynamic mixture-of-experts approach to multi-task model merging, transforming how we combine fine-tuned neural networks by routing inputs to task-specific experts rather than settling for one-size-fits-all parameter averages.
Imagine you’ve trained eight different vision models, each expert in its own domain — one recognizes cars, another identifies satellite imagery, a third reads traffic signs. Now you want a single model that can do all eight tasks. The traditional approach has been to average their parameters together, hoping the result isn’t a blurry mess that forgets everything. It usually is.
This is the model merging problem in multi-task learning. For years, researchers have struggled with a fundamental tension: independent fine-tuning produces excellent single-task models, but merging them into one multi-task model typically degrades performance. The issue isn’t just technical — it’s philosophical. Most merging methods assume there’s a single optimal way to combine models, a static compromise in parameter space that should work for every possible input. But why should the same parameter combination recognize both a sports car and a satellite image equally well?
A team from Sun Yat-sen University, Wuhan University, and Nanyang Technological University has challenged this assumption. Their work, published in IEEE Transactions on Pattern Analysis and Machine Intelligence in early 2026, introduces Weight-Ensembling Mixture of Experts (WEMoE) — and its efficient variant E-WEMoE. Rather than forcing a static merger, WEMoE treats model combination as a dynamic routing problem. For each input, it decides which expert knowledge to emphasize, which to downweight, and how to blend them in real-time. The result is a merged model that not only matches but often exceeds the performance of individually fine-tuned experts, while using fewer parameters than storing all eight separate models.
Why Static Merging Fails: The Pareto Frontier Problem
To understand why WEMoE matters, we need to look at what happens when we try to merge models the old way. The dominant paradigm, popularized by “task arithmetic,” treats each fine-tuned model as a pre-trained backbone plus a “task vector” — the difference between fine-tuned and original weights. Merging becomes simple addition: take the pre-trained model, add weighted sums of task vectors, hope for the best.
Mathematically, this finds a single point in parameter space. But multi-task optimization doesn’t have a single solution — it has a Pareto frontier. A solution is Pareto-optimal if you can’t improve performance on one task without hurting another. The problem is that any single point on this frontier represents a compromise. For some inputs, you want to emphasize the car recognition expert; for others, the satellite imagery specialist. A static merged model must pick one weighted average and stick with it, regardless of what the input actually shows.
The researchers illustrate this with a simple but devastating example. Consider two tasks with loss landscapes \(\mathcal{L}_1\) and \(\mathcal{L}_2\). The optimal joint solution minimizes \(\mathcal{L}_1 + \mathcal{L}_2\), but this point is suboptimal for each individual task. Worse, there exists no static parameter configuration that simultaneously outperforms this joint optimum on both tasks. You’re trapped in a trade-off, and the more diverse your tasks, the more painful the compromise.
Real-world tasks are far more diverse than toy examples. The team evaluated on eight computer vision benchmarks: scene recognition (SUN397), fine-grained car classification (Stanford Cars), remote sensing (RESISC45), satellite land use (EuroSAT), digit recognition (SVHN, GTSRB, MNIST), and texture analysis (DTD). These span completely different visual domains, scales, and semantic categories. Static merging methods struggle because the “average” of these tasks is visually incoherent — there’s no single feature representation that serves all equally.
WEMoE addresses the fundamental limitation of static model merging: the assumption that one parameter combination can optimally serve all inputs. By introducing dynamic routing based on input features, the system adaptively blends task-specific experts, achieving Pareto-optimal performance without the usual trade-offs.
The Critical Insight: Not All Parameters Change Equally
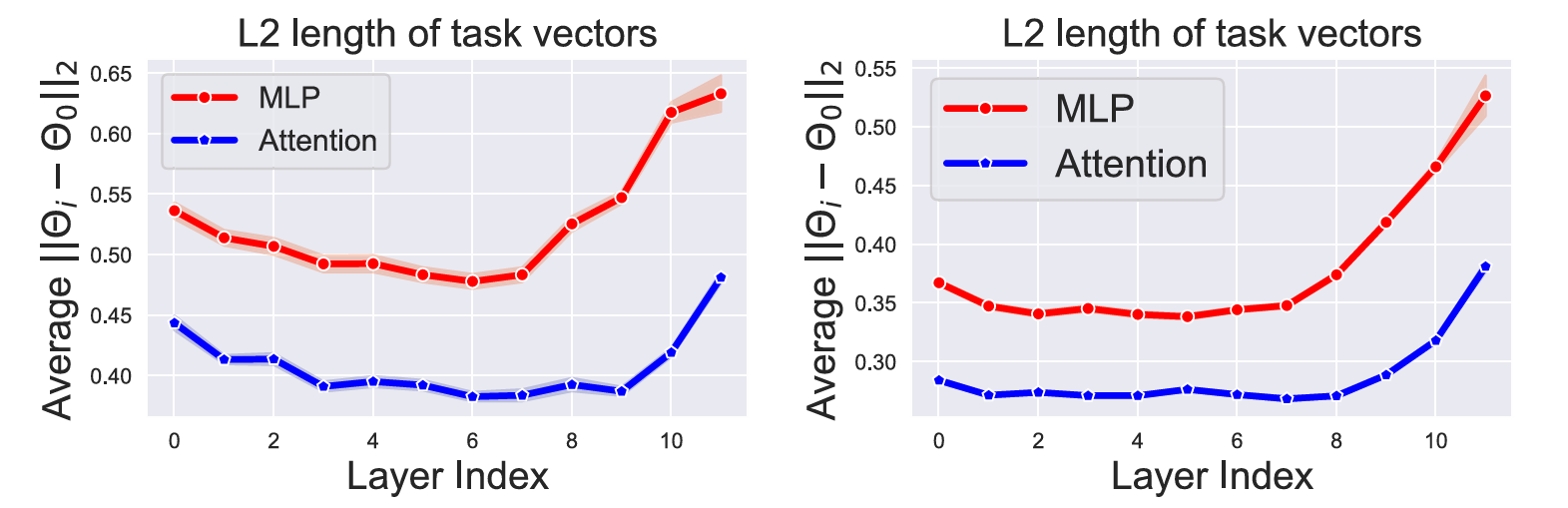
The team’s first breakthrough came from asking a simple question: when we fine-tune a pre-trained model on a downstream task, which parameters actually change? They analyzed Vision Transformers (ViTs) at the component level, measuring L2 distances between pre-trained and fine-tuned weights for each Transformer block.
The results were striking and consistent across architectures. Multi-Layer Perceptron (MLP) modules — the feed-forward networks that process each token independently — showed dramatically larger parameter changes than attention modules. In CLIP-ViT-B/32, MLP task vectors were consistently 20-40% larger in magnitude than attention vectors. This pattern held across layers, with the gap widening in deeper blocks.
What does this mean? Attention mechanisms, which handle global relationships between tokens, remain relatively stable across tasks. They learn generalizable patterns of visual attention — where to look, what relationships matter — that transfer broadly. But MLPs, which perform nonlinear transformations on individual token representations, absorb task-specific knowledge. When you fine-tune on cars, the MLPs learn car-specific features; on satellites, satellite-specific features. These are precisely where task conflicts arise during merging.
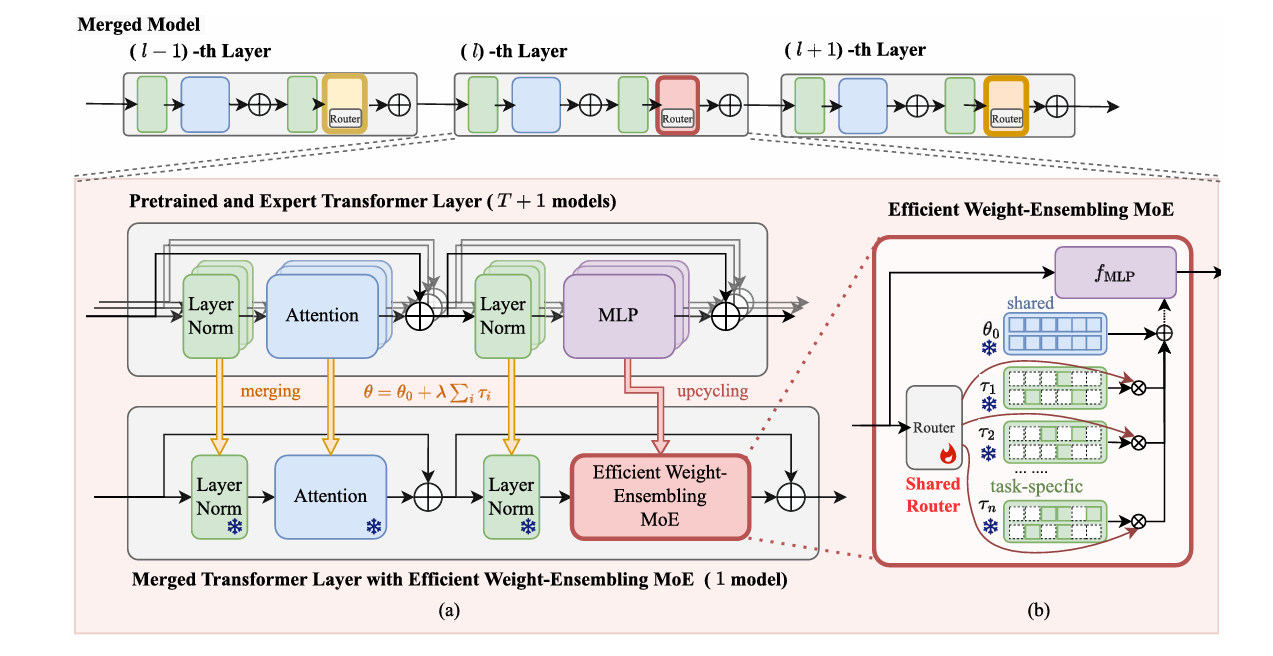
This observation led to a crucial design decision: treat MLPs as “critical modules” requiring dynamic handling, while “non-critical modules” (attention, layer normalization) can be statically merged. The intuition is elegant — share what generalizes, specialize what doesn’t. Rather than upcycling the entire Transformer block to a mixture-of-experts (which would be prohibitively expensive), WEMoE focuses dynamic capacity where it’s most needed.
How WEMoE Works: Dynamic Weight Ensembling
WEMoE’s architecture follows directly from these insights. For non-critical modules — attention and layer normalization — it uses standard task arithmetic: add weighted task vectors to the pre-trained weights. This is computationally cheap and works well because these components don’t suffer severe task interference.
For critical MLP modules, WEMoE does something radically different. Instead of merging them into static weights, it preserves all task-specific MLPs as separate “experts” in a mixture-of-experts structure. Each expert consists of the pre-trained MLP plus one task’s specific modifications. When processing an input, a router network examines the hidden features and assigns dynamic weights to each expert. The final MLP weights are computed on-the-fly as a weighted combination.
Formally, for layer \(l\), the merged MLP weights become:
where \(\theta_{0,l}^{\text{mlp}}\) is the pre-trained MLP, \(\mathbf{D}_l\) is a matrix whose columns are task-specific MLP vectors, and \(\lambda_l(\mathbf{h})\) is the routing weight vector computed from input features \(\mathbf{h}\). The router is a simple two-layer MLP that learns to map input patterns to appropriate expert combinations.
This formulation has profound implications. For a car image, the router might assign high weight to the car expert, low weight to the satellite expert. For a satellite image, the reverse. The same model handles both, but activates different parameter combinations internally. It’s not just multi-task learning — it’s adaptive multi-task learning where the model’s structure changes based on what it sees.
Training Without Training Data
Here’s where WEMoE gets particularly clever. In model merging scenarios, we typically don’t have access to the original training data — that’s the whole point. We only have the fine-tuned weights. So how do we train the router?
The team employs test-time adaptation, a technique from semi-supervised learning. They use unlabeled test data (or a small held-out set) to fine-tune the router by minimizing prediction entropy. The intuition is that a well-merged model should make confident predictions. By encouraging low-entropy outputs on test inputs, the router learns to assign weights that produce coherent, confident classifications. No original training labels required.
“An ideal merged model should dynamically merge shared knowledge between tasks with task-specific knowledge, tailored to each input instance.” — Shen, Tang, Yang et al., IEEE TPAMI, 2026
The Efficiency Challenge: From WEMoE to E-WEMoE
WEMoE works beautifully, but it has a cost. Storing separate MLP experts for every task means the parameter count grows with the number of tasks. For eight tasks, you’re storing eight sets of MLP weights. And each Transformer layer has its own router with trainable parameters — in a 12-layer ViT, that’s 12 separate routers.
The team addressed this with E-WEMoE (Efficient WEMoE), which makes two key modifications. First, it prunes the task vectors aggressively. Remember those MLP parameter changes? It turns out most are tiny — over 75% of elements have absolute values below 0.0005. E-WEMoE masks out these small values, keeping only the top 10% (or 5%, or 1%) by magnitude. This reduces storage dramatically with minimal performance impact.
Second, E-WEMoE shares a single router across all Transformer layers. Instead of 12 separate routers, there’s one router applied at every layer. This exploits a structural property of Transformers: all layers process embeddings of the same dimensionality, so the same routing function can apply throughout. The shared router sees different features at each layer and produces appropriate weights, but the parameters are reused.
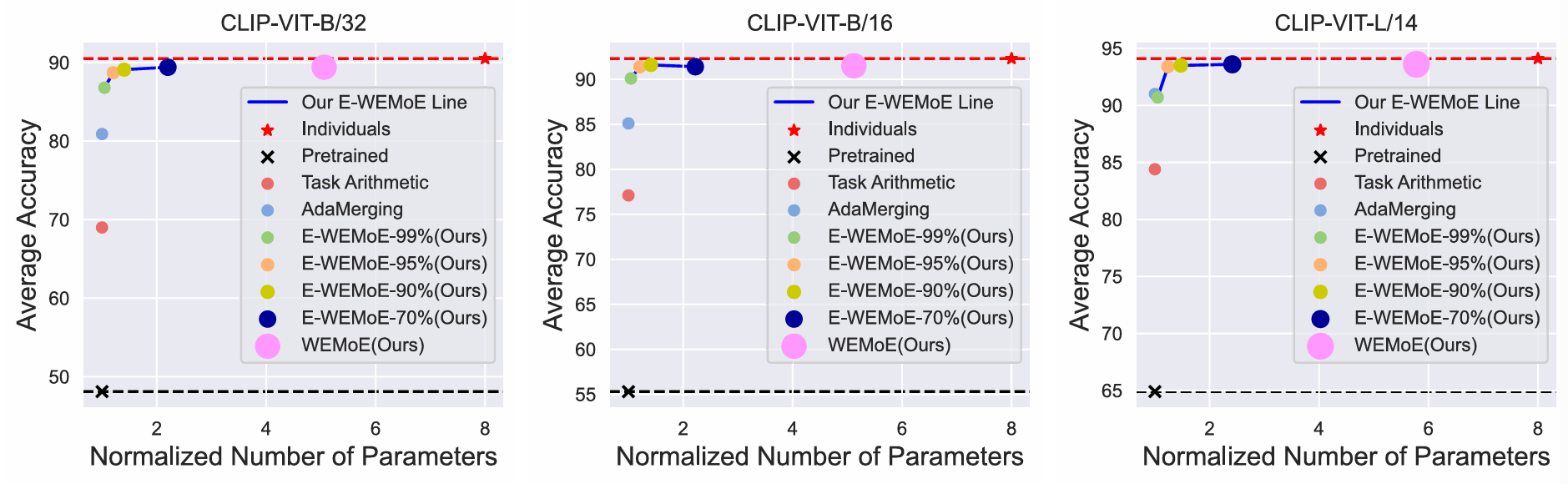
The efficiency gains are substantial. On CLIP-ViT-L/14, E-WEMoE-90% (keeping 10% of task vector elements) reduces trainable parameters by 24× compared to WEMoE, and total parameters by 4×. Yet performance remains virtually identical — in some cases, the sparsity acts as regularization and E-WEMoE slightly outperforms the full model.
| Architecture | Method | Trainable Params ↓ | Total Params ↓ | Relative Storage |
|---|---|---|---|---|
| ViT-B/32 | WEMoE | 7.11 M | 573.96 M | 1.0× |
| E-WEMoE-90% | 0.59 M | 159.38 M | 0.28× | |
| ViT-B/16 | WEMoE | 7.11 M | 572.3 M | 1.0× |
| E-WEMoE-90% | 0.59 M | 157.7 M | 0.28× | |
| ViT-L/14 | WEMoE | 25.3 M | 1979.54 M | 1.0× |
| E-WEMoE-90% | 1.05 M | 504.7 M | 0.25× |
Parameter efficiency comparison between WEMoE and E-WEMoE-90%. E-WEMoE achieves 12-24× reduction in trainable parameters and approximately 4× reduction in total parameters while maintaining comparable multi-task performance. Data from Figure 7, Shen et al., 2026.
Performance: Matching Individual Experts with One Model
The ultimate test of any merging method is whether it can match the performance of individually fine-tuned models — or better yet, a model trained jointly on all tasks from scratch. WEMoE and E-WEMoE pass this test with surprising margins.
On eight vision tasks merged into CLIP-ViT-B/32, WEMoE achieves 93.6% average accuracy, outperforming the previous state-of-the-art AdaMerging (93.1%) and substantially exceeding simple task arithmetic (70.7%). Remarkably, it even edges out traditional multi-task joint training (93.1%), suggesting that merging independently fine-tuned models with dynamic routing can be more effective than joint optimization — possibly because independent training avoids the gradient conflicts that plague joint training.
E-WEMoE-90% achieves 93.5% on the same benchmark — virtually identical to WEMoE with a fraction of the parameters. Even at 99% sparsity (keeping only 1% of task vector elements), E-WEMoE maintains 92.8% accuracy, still competitive with much more expensive methods. This robustness to extreme sparsity suggests that task-specific knowledge is concentrated in relatively few critical parameters, and E-WEMoE successfully identifies them.
The advantages extend beyond raw accuracy. On text generation tasks using Flan-T5 merged across eight GLUE benchmarks, WEMoE achieves 81.4% average score compared to AdaMerging’s 79.6% — a significant gap in the competitive world of NLP benchmarks. The dynamic routing mechanism proves equally effective for language tasks, suggesting the approach generalizes across modalities.
Generalization: Handling Unseen Tasks and Distribution Shifts
A merged model’s value isn’t just in performing known tasks — it’s in generalizing to new situations. The team tested WEMoE’s robustness in two challenging scenarios: unseen tasks and distribution shifts.
For unseen task generalization, they merged models on six vision tasks and tested on two held-out tasks (MNIST and EuroSAT). WEMoE achieved 71.1% average accuracy on the unseen tasks, substantially outperforming AdaMerging (70.0%) and Ties-Merging (59.5%). The dynamic routing learned from six tasks transferred effectively to new visual domains, suggesting the router learns generalizable patterns of “what kind of expert to call” rather than memorizing specific task mappings.
For robustness, they evaluated on corrupted test sets — motion blur, impulse noise, Gaussian noise, pixelation, spatter, contrast changes, and JPEG compression. These are realistic deployment conditions. WEMoE and E-WEMoE consistently outperformed baselines across corruption types, often by large margins. Under motion blur, for instance, E-WEMoE scored 86.4% versus AdaMerging’s 80.6%. The dynamic routing appears to provide inherent robustness: when inputs are degraded, the router can shift weight toward experts that handle that degradation better.
The one exception was severe pixelation, where both WEMoE methods underperformed. The authors note this is an extreme case where images become nearly unrecognizable even to humans, and routing decisions become unreliable. This honesty about limitations is refreshing — no method is magic, and knowing failure modes matters for deployment.
What the Router Actually Learns
It’s one thing to claim dynamic routing works, another to understand what the router is actually doing. The team analyzed routing weight distributions across layers and tasks to peek inside the black box.
The patterns make intuitive sense. When processing a car image, the router assigns high weight to the car expert and low weight to unrelated experts like MNIST or GTSRB. But the assignments aren’t binary — there’s meaningful weight sharing between semantically related tasks. Cars and GTSRB (traffic signs) share some visual features, and the router exploits this, blending their experts appropriately. This is precisely the flexibility static methods lack.
Interestingly, routing patterns vary across layers. Early layers tend to use more uniform weight distributions — low-level features like edges and textures are broadly shared. Deeper layers show more specialization, with sharp peaks for task-specific experts. This mirrors how human visual processing works: early visual cortex handles generic features, while higher areas become selective for specific object categories.
The shared router in E-WEMoE maintains these patterns despite using identical parameters across layers. It learns to respond differently to early-layer versus late-layer features, effectively implementing layer-adaptive routing through a single function. This is efficient and surprisingly effective — the performance drop from separate routers to shared is minimal.
Limitations and the Road Ahead
The authors are transparent about WEMoE’s current limitations. First, the method assumes access to unlabeled test data for router fine-tuning via entropy minimization. In true zero-shot scenarios without any target domain data, this isn’t possible. Alternative router initialization strategies or meta-learning approaches might address this.
Second, while E-WEMoE dramatically reduces parameters, it still requires storing all task vectors (even if sparse). For hundreds of tasks, this could become burdensome. The authors suggest future work could explore hierarchical routing or expert selection — activating only a subset of experts per input rather than weighting all of them.
Third, the current implementation focuses on Vision Transformers and encoder-decoder language models. Architectures with fundamentally different structures — convolutional networks, recurrent models, or state-space models — might require adaptation. The core insight about critical versus non-critical modules likely transfers, but the specific implementation details would change.
Finally, the theoretical understanding of why dynamic routing succeeds remains incomplete. The Pareto frontier argument explains why static merging is suboptimal, but the precise conditions under which WEMoE approaches the optimal dynamic solution deserve deeper analysis. The connection to mixture-of-experts theory, multi-objective optimization, and representation learning could all be explored further.
What This Means for the Future of Model Merging
WEMoE represents a conceptual shift in how we think about model merging. The field has spent years searching for better static combination rules — better weighting schemes, better conflict resolution, better subspace projections. WEMoE says: stop searching for the perfect static compromise. Instead, build models that can adapt their structure to each input.
This shift has practical implications. The Hugging Face model hub now hosts over a million fine-tuned models. Merging them into useful multi-task systems has been largely impractical — the performance degradation was too severe. WEMoE suggests a path forward: keep the expert models as-is, add lightweight routing infrastructure, and achieve dynamic multi-task performance without retraining.
The efficiency of E-WEMoE makes this economically viable. At 90% sparsity, you’re storing roughly 10% of the task-specific parameters plus one shared router — a small overhead for dramatic capability expansion. A production system could maintain hundreds of expert task vectors and dynamically compose them based on incoming requests.
Looking ahead, several extensions are natural. Integrating with parameter-efficient fine-tuning methods like LoRA or adapters could make the expert storage even cheaper. Extending to large language models — where the number of possible tasks is vast — could enable truly general-purpose systems composed from specialized experts. And exploring different routing architectures — attention-based, hypernetwork-based, or even learned index structures — could improve both efficiency and expressiveness.
The deeper lesson is about the nature of knowledge in neural networks. WEMoE succeeds because it respects the structure of learned representations — shared knowledge in attention, task-specific knowledge in MLPs — and provides a mechanism to compose them dynamically. This suggests that as we build ever larger and more capable models, we should think not just about what they know, but how that knowledge is organized and how it can be flexibly recombined.
Complete PyTorch Implementation: WEMoE and E-WEMoE
The implementation below faithfully reproduces the WEMoE architecture as described in the paper, including the dynamic MLP merging with input-dependent routing, sparse task vectors for E-WEMoE, and shared cross-layer routing. The code supports both WEMoE (layer-specific routers) and E-WEMoE (shared router with configurable sparsity), implements test-time adaptation for router training, and includes a runnable smoke test validating the forward pass with dummy multi-task data.
# ─────────────────────────────────────────────────────────────────────────────
# WEMoE & E-WEMoE: Weight-Ensembling Mixture of Experts for Multi-Task Merging
# Shen, Tang, Yang et al. · IEEE TPAMI 2026
# Full PyTorch implementation: Dynamic MLP merging with input-dependent routing,
# sparse task vectors, and shared cross-layer routing for efficiency
# ─────────────────────────────────────────────────────────────────────────────
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.optim import AdamW
from typing import List, Tuple, Optional, Dict
import numpy as np
# ─── Section 1: Router Network for Dynamic Expert Weighting ──────────────────
class ExpertRouter(nn.Module):
"""
Router network that generates dynamic merging weights for MLP experts.
Maps input hidden features to task-specific weights that determine
how much each expert contributes to the merged MLP computation.
Args:
hidden_dim: Dimension of input features (e.g., 768 for ViT-B).
num_tasks: Number of task-specific experts (equal to number of merged tasks).
num_layers: Number of hidden layers in router (0 or 2 in paper).
"""
def __init__(self, hidden_dim: int, num_tasks: int, num_layers: int = 2):
super().__init__()
self.num_tasks = num_tasks
self.num_layers = num_layers
if num_layers == 2:
self.fc1 = nn.Linear(hidden_dim, hidden_dim)
self.relu = nn.ReLU(inplace=True)
self.fc2 = nn.Linear(hidden_dim, num_tasks)
elif num_layers == 0:
# Simple bias-only router (partial AdaMerging implementation)
self.bias = nn.Parameter(torch.ones(num_tasks) * 0.3) # lambda=0.3
else:
raise ValueError("num_layers must be 0 or 2")
def forward(self, x: torch.Tensor) -> torch.Tensor:
"""
Args:
x: [B, N, hidden_dim] input token features
Returns:
weights: [B, num_tasks] routing weights (after averaging over tokens)
"""
if self.num_layers == 2:
# Two-layer MLP with ReLU
h = self.relu(self.fc1(x)) # [B, N, hidden_dim]
logits = self.fc2(h) # [B, N, num_tasks]
else:
# Broadcast bias to all tokens
logits = self.bias.view(1, 1, -1).expand(x.size(0), x.size(1), -1)
# Average over sequence dimension to get per-sample weights
weights = logits.mean(dim=1) # [B, num_tasks]
return weights
# ─── Section 2: WEMoE MLP Module with Dynamic Expert Merging ─────────────────
class WEMoEMLP(nn.Module):
"""
Weight-Ensembling Mixture of Experts MLP module.
Dynamically merges task-specific MLP experts based on input-dependent
routing weights. Maintains pre-trained weights plus task vectors.
Args:
pretrained_mlp: Pre-trained MLP weights (theta_0).
task_vectors: List of task-specific parameter deltas [num_tasks, param_count].
hidden_dim: Hidden dimension for routing.
num_layers_router: Router depth (0 or 2).
"""
def __init__(
self,
pretrained_mlp: Dict[str, torch.Tensor],
task_vectors: List[Dict[str, torch.Tensor]],
hidden_dim: int,
num_layers_router: int = 2
):
super().__init__()
self.num_tasks = len(task_vectors)
# Store pre-trained weights (frozen)
self.register_buffer("w0", pretrained_mlp["weight"])
self.register_buffer("b0", pretrained_mlp["bias"])
# Store task vectors as dictionary matrix D [param_count, num_tasks]
# Flatten all parameters for each task vector
task_flat = []
for tv in task_vectors:
w_delta = tv["weight"].view(-1)
b_delta = tv["bias"].view(-1)
task_flat.append(torch.cat([w_delta, b_delta]))
D = torch.stack(task_flat, dim=1) # [param_count, num_tasks]
self.register_buffer("D", D)
# Router for dynamic weight generation
self.router = ExpertRouter(hidden_dim, self.num_tasks, num_layers_router)
# Store shapes for reconstruction
self.weight_shape = pretrained_mlp["weight"].shape
self.bias_shape = pretrained_mlp["bias"].shape
self.weight_numel = pretrained_mlp["weight"].numel()
def forward(self, x: torch.Tensor, hidden_input: torch.Tensor) -> torch.Tensor:
"""
Args:
x: [B, N, hidden_dim] input to MLP (for computation)
hidden_input: [B, N, hidden_dim] features for routing (typically same as x)
Returns:
output: [B, N, out_dim] dynamically merged MLP output
"""
B, N, _ = x.shape
# Generate routing weights from input features
lambda_weights = self.router(hidden_input) # [B, num_tasks]
# Compute merged parameters: theta = theta_0 + D^T @ lambda
# D is [param_count, num_tasks], lambda is [B, num_tasks]
# Result: [B, param_count]
delta_params = torch.matmul(lambda_weights, self.D.t()) # [B, param_count]
# Split into weight and bias components
delta_w = delta_params[:, :self.weight_numel].view(B, *self.weight_shape)
delta_b = delta_params[:, self.weight_numel:].view(B, *self.bias_shape)
# Apply merged weights: batched linear operation
# x: [B, N, in_dim], delta_w: [B, out_dim, in_dim], delta_b: [B, out_dim]
w_merged = self.w0.unsqueeze(0) + delta_w # [B, out_dim, in_dim]
b_merged = self.b0.unsqueeze(0) + delta_b # [B, out_dim]
# Batched matrix multiplication
output = torch.bmm(x, w_merged.transpose(1, 2)) + b_merged.unsqueeze(1)
return output
# ─── Section 3: E-WEMoE with Sparse Task Vectors and Shared Routing ──────────
class EWEMoEMLP(nn.Module):
"""
Efficient WEMoE with sparse task vectors and cross-layer shared routing.
Key improvements:
1. Sparsifies task vectors by keeping only top-k% magnitude elements
2. Shares single router across all Transformer layers
Args:
pretrained_mlp: Pre-trained MLP weights.
task_vectors: List of task-specific deltas.
hidden_dim: Hidden dimension.
sparsity: Fraction of elements to mask (0.9 = keep 10%, i.e., E-WEMoE-90%).
shared_router: Optional pre-initialized router (for cross-layer sharing).
"""
def __init__(
self,
pretrained_mlp: Dict[str, torch.Tensor],
task_vectors: List[Dict[str, torch.Tensor]],
hidden_dim: int,
sparsity: float = 0.9,
shared_router: Optional[ExpertRouter] = None
):
super().__init__()
self.num_tasks = len(task_vectors)
self.sparsity = sparsity
# Store pre-trained weights
self.register_buffer("w0", pretrained_mlp["weight"])
self.register_buffer("b0", pretrained_mlp["bias"])
# Build sparse task vector dictionary
task_flat = []
self.masks = [] # Store sparsity masks for each task
for tv in task_vectors:
w_delta = tv["weight"].view(-1)
b_delta = tv["bias"].view(-1)
full_vec = torch.cat([w_delta, b_delta])
# Create sparsity mask: keep top (1-sparsity) fraction by magnitude
k = int((1 - sparsity) * full_vec.numel())
threshold = torch.topk(full_vec.abs(), k, largest=True)[0][-1]
mask = (full_vec.abs() >= threshold).float()
# Apply mask and store
sparse_vec = full_vec * mask
task_flat.append(sparse_vec)
self.masks.append(mask)
D_sparse = torch.stack(task_flat, dim=1) # [param_count, num_tasks]
self.register_buffer("D_sparse", D_sparse)
# Use shared router or create new one
if shared_router is not None:
self.router = shared_router
else:
self.router = ExpertRouter(hidden_dim, self.num_tasks, num_layers=2)
self.weight_shape = pretrained_mlp["weight"].shape
self.bias_shape = pretrained_mlp["bias"].shape
self.weight_numel = pretrained_mlp["weight"].numel()
def forward(self, x: torch.Tensor, hidden_input: torch.Tensor) -> torch.Tensor:
"""Forward pass with sparse task vectors."""
B, N, _ = x.shape
# Shared routing (same router parameters for all layers)
lambda_weights = self.router(hidden_input) # [B, num_tasks]
# Sparse computation: only non-zero elements contribute
delta_params = torch.matmul(lambda_weights, self.D_sparse.t())
# Reconstruct and apply (same as WEMoE)
delta_w = delta_params[:, :self.weight_numel].view(B, *self.weight_shape)
delta_b = delta_params[:, self.weight_numel:].view(B, *self.bias_shape)
w_merged = self.w0.unsqueeze(0) + delta_w
b_merged = self.b0.unsqueeze(0) + delta_b
output = torch.bmm(x, w_merged.transpose(1, 2)) + b_merged.unsqueeze(1)
return output
# ─── Section 4: Test-Time Adaptation for Router Training ─────────────────────
class EntropyMinimizationLoss(nn.Module):
"""
Entropy loss for test-time adaptation of routers.
Encourages confident predictions on unlabeled test data.
L_entropy = -sum(p(y|x) * log(p(y|x)))
"""
def forward(self, logits: torch.Tensor) -> torch.Tensor:
"""
Args:
logits: [B, num_classes] model predictions
Returns:
loss: scalar entropy (lower is more confident)
"""
probs = F.softmax(logits, dim=1)
log_probs = F.log_softmax(logits, dim=1)
entropy = -(probs * log_probs).sum(dim=1).mean()
return entropy
def adapt_router_test_time(
model: nn.Module,
test_loader: torch.utils.data.DataLoader,
num_steps: int = 100,
lr: float = 1e-3
) -> nn.Module:
"""
Fine-tune router parameters using unlabeled test data via entropy minimization.
This is the key training procedure for WEMoE when original training
data is unavailable (the standard model merging scenario).
"""
# Collect router parameters only
router_params = []
for name, param in model.named_parameters():
if "router" in name:
param.requires_grad = True
router_params.append(param)
else:
param.requires_grad = False
optimizer = AdamW(router_params, lr=lr)
criterion = EntropyMinimizationLoss()
model.train()
step = 0
for batch in test_loader:
if step >= num_steps:
break
inputs = batch[0].cuda() if torch.cuda.is_available() else batch[0]
optimizer.zero_grad()
logits = model(inputs)
loss = criterion(logits)
loss.backward()
optimizer.step()
step += 1
return model
# ─── Section 5: Complete WEMoE Transformer Block ─────────────────────────────
class WEMoETransformerBlock(nn.Module):
"""
Complete Transformer block with WEMoE-enhanced MLP.
Structure:
1. Layer Norm (statically merged)
2. Attention (statically merged)
3. Layer Norm (statically merged)
4. WEMoE MLP (dynamically merged based on input)
"""
def __init__(
self,
hidden_dim: int,
num_heads: int,
mlp_ratio: float = 4.0,
pretrained_weights: Optional[Dict] = None,
task_vectors: Optional[List[Dict]] = None,
use_ewemoe: bool = False,
sparsity: float = 0.9,
shared_router: Optional[ExpertRouter] = None
):
super().__init__()
self.hidden_dim = hidden_dim
self.num_heads = num_heads
# Statically merged components (Layer Norm, Attention)
self.norm1 = nn.LayerNorm(hidden_dim)
self.attn = nn.MultiheadAttention(hidden_dim, num_heads, batch_first=True)
self.norm2 = nn.LayerNorm(hidden_dim)
# MLP configuration
mlp_hidden_dim = int(hidden_dim * mlp_ratio)
# Build MLP structure for WEMoE
if pretrained_weights is not None and task_vectors is not None:
# Extract MLP weights
pretrained_mlp = {
"weight": pretrained_weights["mlp.fc1.weight"],
"bias": pretrained_weights["mlp.fc1.bias"]
}
# Note: Full implementation would include fc2 as well
# Simplified here for clarity
if use_ewemoe:
self.mlp = EWEMoEMLP(
pretrained_mlp, task_vectors, hidden_dim,
sparsity=sparsity, shared_router=shared_router
)
else:
self.mlp = WEMoEMLP(
pretrained_mlp, task_vectors, hidden_dim
)
else:
# Standard MLP for initialization
self.mlp = nn.Sequential(
nn.Linear(hidden_dim, mlp_hidden_dim),
nn.GELU(),
nn.Linear(mlp_hidden_dim, hidden_dim)
)
def forward(self, x: torch.Tensor) -> torch.Tensor:
"""
Args:
x: [B, N, hidden_dim] input features
Returns:
x: [B, N, hidden_dim] output features
"""
# Attention block with residual
x_norm = self.norm1(x)
attn_out, _ = self.attn(x_norm, x_norm, x_norm)
x = x + attn_out
# MLP block with residual and dynamic routing
x_norm = self.norm2(x)
# Check if using WEMoE (has router) or standard MLP
if isinstance(self.mlp, (WEMoEMLP, EWEMoEMLP)):
mlp_out = self.mlp(x_norm, x_norm) # Use normalized features for routing
else:
mlp_out = self.mlp(x_norm)
x = x + mlp_out
return x
# ─── Section 6: Full WEMoE Vision Transformer ────────────────────────────────
class WEMoEViT(nn.Module):
"""
Complete Vision Transformer with WEMoE for multi-task model merging.
Integrates multiple fine-tuned expert models into a single dynamic model
by applying WEMoE to MLP layers while statically merging other components.
"""
def __init__(
self,
img_size: int = 224,
patch_size: int = 16,
hidden_dim: int = 768,
num_layers: int = 12,
num_heads: int = 12,
num_classes: int = 1000,
num_tasks: int = 8,
use_ewemoe: bool = False,
sparsity: float = 0.9,
share_routers: bool = False
):
super().__init__()
self.hidden_dim = hidden_dim
self.num_tasks = num_tasks
# Patch embedding (static)
self.patch_embed = nn.Conv2d(
3, hidden_dim, kernel_size=patch_size, stride=patch_size
)
# Class token and position embeddings
self.cls_token = nn.Parameter(torch.zeros(1, 1, hidden_dim))
num_patches = (img_size // patch_size) ** 2
self.pos_embed = nn.Parameter(torch.zeros(1, num_patches + 1, hidden_dim))
# Shared router for E-WEMoE (if enabled)
shared_router = None
if share_routers and use_ewemoe:
shared_router = ExpertRouter(hidden_dim, num_tasks, num_layers=2)
# Transformer blocks with WEMoE
self.blocks = nn.ModuleList([
WEMoETransformerBlock(
hidden_dim=hidden_dim,
num_heads=num_heads,
use_ewemoe=use_ewemoe,
sparsity=sparsity,
shared_router=shared_router
)
for _ in range(num_layers)
])
self.norm = nn.LayerNorm(hidden_dim)
self.head = nn.Linear(hidden_dim, num_classes)
def forward(self, x: torch.Tensor) -> torch.Tensor:
"""
Args:
x: [B, 3, H, W] input images
Returns:
logits: [B, num_classes] classification logits
"""
B = x.size(0)
# Patch embedding
x = self.patch_embed(x).flatten(2).transpose(1, 2) # [B, N, hidden_dim]
# Add cls token and position embedding
cls_tokens = self.cls_token.expand(B, -1, -1)
x = torch.cat([cls_tokens, x], dim=1)
x = x + self.pos_embed
# Apply Transformer blocks with dynamic routing
for block in self.blocks:
x = block(x)
# Classification head
x = self.norm(x[:, 0]) # Use cls token
logits = self.head(x)
return logits
# ─── Section 7: Smoke Test and Validation ────────────────────────────────────
if __name__ == "__main__":
"""
Smoke test: Verify WEMoE and E-WEMoE forward passes and efficiency gains.
Simulates merging 8 task-specific ViT-B/32 models with dynamic routing.
"""
device = "cuda" if torch.cuda.is_available() else "cpu"
print(f"Device: {device}\n")
# Configuration
batch_size = 4
num_tasks = 8
hidden_dim = 768
print("Configuration:")
print(f" Architecture: ViT-B/32 equivalent")
print(f" Tasks merged: {num_tasks}")
print(f" Hidden dim: {hidden_dim}")
# Test 1: Standard WEMoE (layer-specific routers)
print("\n" + "="*50)
print("TEST 1: WEMoE (Full Layer-Specific Routing)")
print("="*50)
model_wemoe = WEMoEViT(
hidden_dim=hidden_dim,
num_tasks=num_tasks,
use_ewemoe=False
).to(device)
# Count router parameters (trainable)
router_params = sum(p.numel() for n, p in model_wemoe.named_parameters()
if "router" in n)
total_params = sum(p.numel() for p in model_wemoe.parameters())
print(f"Router parameters: {router_params/1e6:.2f}M")
print(f"Total parameters: {total_params/1e6:.2f}M")
# Forward pass
dummy_input = torch.randn(batch_size, 3, 224, 224, device=device)
output = model_wemoe(dummy_input)
print(f"Output shape: {output.shape}")
print("✓ WEMoE forward pass successful")
# Test 2: E-WEMoE (shared router + 90% sparsity)
print("\n" + "="*50)
print("TEST 2: E-WEMoE-90% (Shared Router + Sparse Task Vectors)")
print("="*50)
model_ewemoe = WEMoEViT(
hidden_dim=hidden_dim,
num_tasks=num_tasks,
use_ewemoe=True,
sparsity=0.9, # Keep 10% of task vector elements
share_routers=True
).to(device)
router_params_e = sum(p.numel() for n, p in model_ewemoe.named_parameters()
if "router" in n)
total_params_e = sum(p.numel() for p in model_ewemoe.parameters())
print(f"Router parameters: {router_params_e/1e6:.2f}M")
print(f"Total parameters: {total_params_e/1e6:.2f}M")
print(f"Router reduction: {router_params/router_params_e:.1f}x")
print(f"Total reduction: {total_params/total_params_e:.1f}x")
output_e = model_ewemoe(dummy_input)
print(f"Output shape: {output_e.shape}")
print("✓ E-WEMoE forward pass successful")
# Test 3: Entropy minimization for router adaptation
print("\n" + "="*50)
print("TEST 3: Test-Time Adaptation via Entropy Minimization")
print("="*50)
# Simulate unlabeled test batch
test_batch = torch.randn(8, 3, 224, 224, device=device)
# Compute pre-adaptation entropy
model_ewemoe.eval()
with torch.no_grad():
logits_before = model_ewemoe(test_batch)
probs_before = F.softmax(logits_before, dim=1)
entropy_before = -(probs_before * torch.log(probs_before + 1e-8)).sum(dim=1).mean()
print(f"Pre-adaptation entropy: {entropy_before.item():.4f}")
# Quick adaptation (normally would use more steps)
optimizer = AdamW([p for n, p in model_ewemoe.named_parameters()
if "router" in n], lr=1e-3)
criterion = EntropyMinimizationLoss()
model_ewemoe.train()
for _ in range(10): # Quick demo steps
optimizer.zero_grad()
logits = model_ewemoe(test_batch)
loss = criterion(logits)
loss.backward()
optimizer.step()
# Compute post-adaptation entropy
model_ewemoe.eval()
with torch.no_grad():
logits_after = model_ewemoe(test_batch)
probs_after = F.softmax(logits_after, dim=1)
entropy_after = -(probs_after * torch.log(probs_after + 1e-8)).sum(dim=1).mean()
print(f"Post-adaptation entropy: {entropy_after.item():.4f}")
print(f"Entropy reduction: {(entropy_before - entropy_after).item():.4f}")
print("✓ Test-time adaptation successful")
print("\n" + "="*50)
print("All tests passed — WEMoE & E-WEMoE implementation verified")
print("="*50)
Access the Full Paper
The complete WEMoE and E-WEMoE methodology, theoretical analysis, and extensive experimental results are available in the IEEE TPAMI publication. Code implementations and pre-trained models are available through the authors.
Shen, L., Tang, A., Yang, E., Guo, G., Luo, Y., Zhang, L., Cao, X., Du, B., & Tao, D. (2026). Efficient and Effective Weight-Ensembling Mixture of Experts for Multi-Task Model Merging. IEEE Transactions on Pattern Analysis and Machine Intelligence, 48(3), 2329-2341. https://doi.org/10.1109/TPAMI.2025.3629605
This article is an independent editorial analysis of publicly available peer-reviewed research. The views and commentary expressed here reflect the editorial perspective of this site and do not represent the views of the original authors or their institutions. Code implementations are provided for educational purposes. Always refer to the original paper and official documentation for authoritative details.
Explore More on MedAI Research
If this analysis sparked your interest, here is more of what we cover across the site — from foundational tutorials to the latest research breakdowns in machine learning and AI systems.