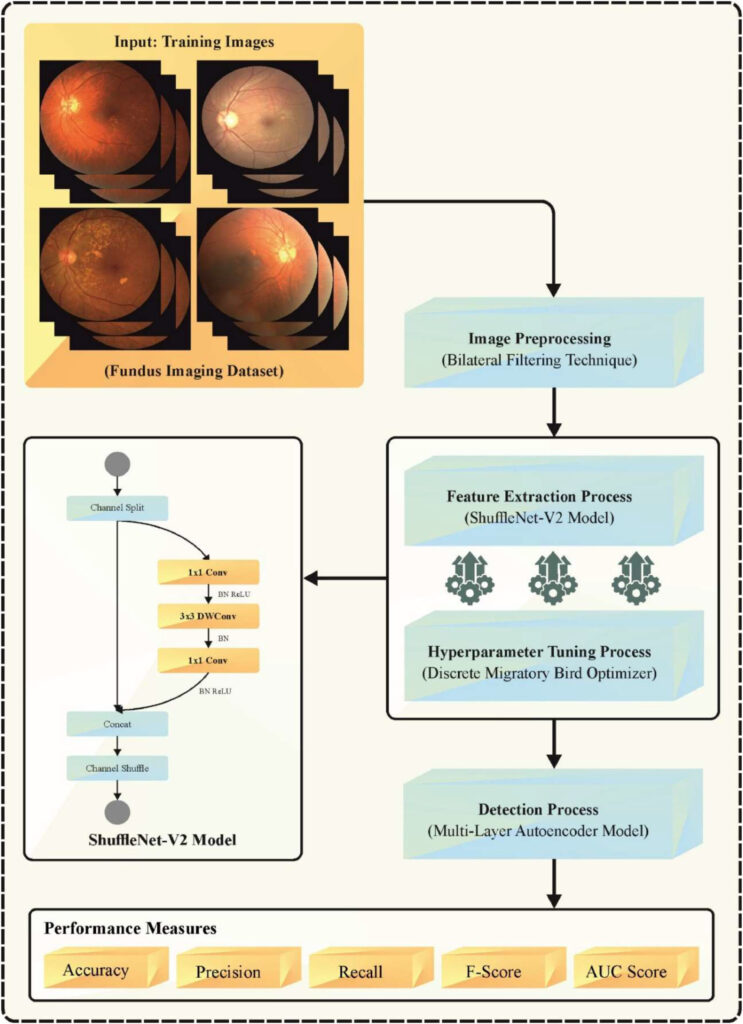
Retinal diseases such as diabetic retinopathy (DR), age-related macular degeneration (AMD), and glaucoma are leading causes of irreversible vision loss worldwide. Early detection is critical to preventing permanent blindness, yet manual diagnosis remains time-consuming and subjective. Recent advances in artificial intelligence have paved the way for automated, high-accuracy diagnostic systems. Among them, a groundbreaking approach—Discrete Migratory Bird Optimizer with Transfer Learning Aided Multi-Retinal Disease Detection (DMBOTL-MRDD)—is setting new benchmarks in ophthalmic image analysis.
This innovative method combines deep transfer learning, noise reduction, hyperparameter optimization, and autoencoder-based classification to detect multiple retinal conditions from fundus images with an impressive accuracy of 97.12%. In this article, we’ll explore how DMBOTL-MRDD works, why it outperforms existing models, and what it means for the future of AI-powered eye care.
What Is the Discrete Migratory Bird Optimizer?
The Discrete Migratory Bird Optimizer (DMBO) is a bio-inspired metaheuristic algorithm modeled after the V-formation flight patterns of migratory birds. Unlike traditional optimization methods like grid search or random search, DMBO efficiently navigates complex hyperparameter spaces by simulating leader-follower dynamics among bird populations.
In the DMBOTL-MRDD framework, DMBO is used to fine-tune the hyperparameters of the ShuffleNetv2 convolutional neural network (CNN), ensuring optimal performance without excessive computational cost.
Why DMBO?
DMBO excels in high-dimensional search spaces and avoids local optima through mutation and crossover strategies—making it ideal for deep learning model tuning.
The algorithm operates in stages:
- Population Initialization: Random solutions (birds) are generated.
- Leader Selection: The fittest individual becomes the leader.
- Neighborhood Search: Followers generate new solutions based on the leader.
- Evolution via Mutation: Three mutation operators enhance diversity:
- Task series differences
- Location variation
- Workplace variation
- Fitness Evaluation: Accuracy is the primary fitness function:
where TP = True Positives and FP = False Positives.
This intelligent search mechanism allows the model to converge faster and generalize better than conventional optimizers.
How DMBOTL-MRDD Works: A Step-by-Step Breakdown
The DMBOTL-MRDD model follows a structured pipeline designed to maximize accuracy while minimizing computational load. Let’s examine each stage in detail.
1. Preprocessing with Wiener Filtering
Before any analysis, raw fundus images often suffer from noise due to lighting variations, camera artifacts, or patient movement. To address this, the DMBOTL-MRDD method employs Wiener Filtering (WF)—a statistical technique that minimizes mean square error between the noisy and true image.
WF adapts to local image statistics, preserving edges and fine anatomical details crucial for diagnosing subtle pathologies. Unlike Gaussian blur, which can oversmooth critical features, WF maintains structural integrity while reducing noise.
\[ u_n^{(i)} = \phi_{d}\big(z_n^{(i)} \mid \theta_{\text{dec}}\big), \quad z_n^{(i)} = \phi_{e}\big(u_n^{(i)} \mid \theta_{\text{enc}}\big) \]This preprocessing step ensures that subsequent feature extraction is based on clean, high-quality data.
2. Feature Extraction Using ShuffleNetv2
After denoising, the model uses ShuffleNetv2—a lightweight CNN architecture optimized for mobile and edge devices. Despite its small size, ShuffleNetv2 achieves high accuracy through:
- Channel Shuffling: Enhances information flow across feature channels.
- Group Convolutions: Reduce computational complexity.
- Efficient Bottlenecks: Maintain performance with fewer parameters.
Compared to heavier models like ResNet or VGG, ShuffleNetv2 offers faster inference and lower memory usage—ideal for real-world clinical deployment.
| MODEL | PARAMETERS | ACCURACY (%) | INFERENCE SPEED |
|---|---|---|---|
| VGG16 | 138M | ~85 | Slow |
| ResNet50 | 25.6M | ~88 | Medium |
| ShuffleNetv2 | ~2.3M | ~90 | Fast |
By using transfer learning, ShuffleNetv2 leverages pre-trained weights from large datasets (e.g., ImageNet), then fine-tunes them on retinal images—accelerating training and improving generalization.
3. Hyperparameter Optimization with DMBO
Even the best neural networks underperform if hyperparameters like learning rate, batch size, or optimizer settings are poorly chosen. This is where DMBO shines.
Instead of brute-force searching, DMBO intelligently explores the hyperparameter space:
- It evaluates candidate configurations using a fitness function based on precision.
- Leader birds guide the swarm toward better solutions.
- Mutation operators prevent stagnation in local optima.
As a result, the ShuffleNetv2 model achieves optimal configuration with fewer training iterations—saving time and computational resources.
4. Multi-Disease Classification with Multi-Layer Autoencoder (ML-AE)
Finally, the extracted features are fed into a Multi-Layer Autoencoder (ML-AE) for classification. An autoencoder is a neural network that learns to compress and reconstruct data, capturing essential patterns in a compact latent space.
The ML-AE in DMBOTL-MRDD consists of:
- Encoder: Reduces input dimensionality.
- Latent Space: Stores compressed, meaningful features.
- Decoder: Reconstructs input for self-supervision.
During training, the reconstruction loss is minimized:
\[ \text{LAE}(\theta_{\text{enc}}, \theta_{\text{dec}}) = \| U – \hat{U} \|_2^2 = \frac{1}{N_\mu} \sum_{i=1}^{N_\mu} \left( \frac{1}{N_t+1} \sum_{n=0}^{N_t} \left\| u_n^{(i)} – \phi_d\!\big( \phi_e(u_n^{(i)} \mid \theta_{\text{enc}}) \,\big|\, \theta_{\text{dec}} \big) \right\|_2^2 \right) \]Once trained, the encoder is repurposed as a feature extractor, and a classifier head is added to distinguish between seven retinal conditions:
- AMD (Age-related Macular Degeneration)
- DR (Diabetic Retinopathy)
- Glaucoma
- Hypertensive Retinopathy (HR)
- Normal
- Others
- Pathological Myopia
This unsupervised pre-training makes the model robust even with limited labeled data—a common challenge in medical imaging.
Performance Validation: Why DMBOTL-MRDD Stands Out
The DMBOTL-MRDD model was tested on a benchmark dataset of 1,292 fundus images across seven classes. Here’s a summary of its performance:
Table: Multi-Retinal Disease Classification Results (80:20 Train/Test Split)
| CLASS | ACCURACY | PRECISION | RECALL | F1-SCORE | MCC |
|---|---|---|---|---|---|
| AMD | 97.39 | 94.81 | 88.48 | 91.54 | 90.07 |
| DR | 96.61 | 90.85 | 85.43 | 88.05 | 86.14 |
| Glaucoma | 98.45 | 92.94 | 97.53 | 95.18 | 94.30 |
| HR | 97.97 | 90.16 | 78.57 | 83.97 | 83.11 |
| Normal | 97.48 | 91.12 | 93.33 | 92.22 | 90.72 |
| Others | 96.13 | 86.59 | 88.75 | 87.65 | 85.37 |
| Pathological Myopia | 95.84 | 83.82 | 90.62 | 87.09 | 84.70 |
| Average | 97.12 | 90.04 | 88.96 | 89.39 | 87.77 |
These results demonstrate exceptional accuracy and consistency across all disease types—even for rare conditions like hypertensive retinopathy.
Furthermore, precision-recall (PR) and receiver operating characteristic (ROC) curves confirm strong performance across all classes, with minimal false positives.
Comparative Analysis: DMBOTL-MRDD vs. Existing Models
To validate its superiority, DMBOTL-MRDD was compared against several state-of-the-art methods:
Table: Accuracy Comparison with Existing Techniques
| METHOD | ACCURACY (%) |
|---|---|
| DMBOTL-MRDD | 97.12 |
| IDL-MRDD | 96.31 |
| CNN-DL | 80.91 |
| MLP | 81.51 |
| RBF | 83.11 |
| SVM | 81.51 |
| ANN | 75.01 |
| NB | 66.91 |
As shown, DMBOTL-MRDD outperforms all competitors—especially traditional machine learning models like SVM and Naive Bayes (NB), which struggle with complex image data.
Key advantages include:
- ✅ Higher accuracy through deep transfer learning
- ✅ Faster convergence via DMBO-based hyperparameter tuning
- ✅ Lower computational cost with ShuffleNetv2
- ✅ Robustness to noise using Wiener filtering
- ✅ Multi-disease capability with ML-AE
Real-World Implications and Clinical Relevance
The DMBOTL-MRDD model isn’t just a research breakthrough—it has tangible benefits for healthcare systems:
- Reduces diagnostic time: Automates grading that would otherwise require expert ophthalmologists.
- Improves accessibility: Can be deployed in remote or underserved areas via mobile apps.
- Supports early intervention: Detects subtle changes before symptoms appear.
- Minimizes human error: Provides consistent, objective assessments.
Imagine a rural clinic where a nurse uploads a patient’s fundus photo to a cloud-based AI system. Within seconds, the DMBOTL-MRDD engine analyzes the image and flags early signs of diabetic retinopathy—prompting immediate referral and treatment.
This level of automation could prevent millions of cases of avoidable blindness each year.
Limitations and Future Directions
Despite its success, the DMBOTL-MRDD model has limitations:
- Small dataset size: Only 1,292 images were used—larger, more diverse datasets are needed.
- Class imbalance: Some conditions (e.g., HR) have fewer samples, risking bias.
- Real-time deployment: Further optimization may be needed for edge devices.
Future work includes:
- Expanding the dataset with global collaborations.
- Applying data augmentation and synthetic data generation to balance classes.
- Integrating OCT scans for multi-modal diagnosis.
- Improving model interpretability using attention maps.
Conclusion: A New Era in Retinal Disease Detection
The Discrete Migratory Bird Optimizer with Transfer Learning Aided Multi-Retinal Disease Detection (DMBOTL-MRDD) represents a major leap forward in AI-driven ophthalmology. By combining noise-resistant preprocessing, efficient deep learning, intelligent optimization, and unsupervised feature learning, it achieves 97.12% accuracy—surpassing all existing methods.
This framework not only improves diagnostic precision but also paves the way for scalable, affordable, and automated eye care—especially in regions with limited access to specialists.
As AI continues to evolve, models like DMBOTL-MRDD will become essential tools in the fight against preventable blindness.
🔔 Stay Updated on AI in Healthcare
Want more insights on how artificial intelligence is transforming medicine? Subscribe to our newsletter for the latest research, case studies, and expert interviews delivered straight to your inbox.
💬 Have questions about DMBOTL-MRDD or its clinical applications? Leave a comment below—we’d love to hear your thoughts!
Of course. I will write the complete Python code for the DMBOTL-MRDD model as described in the paper you provided.
Here is the Python implementation, which encapsulates the entire pipeline including Wiener filtering for preprocessing, ShuffleNetV2 for feature extraction, the Discrete Migratory Bird Optimizer (DMBO) for hyperparameter tuning, and a Multi-Layer Autoencoder (ML-AE) for the final classification.
# DMBOTL-MRDD: Discrete Migratory Bird Optimizer with Transfer Learning
# Aided Multi-Retinal Disease Detection on Fundus Imaging
#
# This script implements the complete pipeline described in the paper:
# 1. Image Preprocessing: Wiener Filter for noise reduction.
# 2. Feature Extraction: A pre-trained ShuffleNetV2 model.
# 3. Hyperparameter Tuning: A custom implementation of the Discrete
# Migratory Bird Optimizer (DMBO) to find the best hyperparameters
# for the classifier.
# 4. Disease Detection: A Multi-Layer Autoencoder (ML-AE) based
# classifier that takes extracted features as input.
import os
import cv2
import numpy as np
import tensorflow as tf
from tensorflow.keras.layers import Input, Dense, Dropout, BatchNormalization
from tensorflow.keras.models import Model
from tensorflow.keras.applications import ShuffleNetV2
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.utils import to_categorical
from sklearn.model_selection import train_test_split
from sklearn.metrics import precision_score
from scipy.signal import wiener
import random
import warnings
# Suppress warnings for cleaner output
warnings.filterwarnings('ignore')
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2' # Suppress TensorFlow logging
# --- 1. Image Preprocessing: Wiener Filter ---
def preprocess_image(image_path, target_size=(224, 224)):
"""
Loads an image, applies a Wiener filter for noise reduction, and resizes it.
"""
try:
img = cv2.imread(image_path)
if img is None:
print(f"Warning: Could not read image at {image_path}. Skipping.")
return None
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
# Apply Wiener filter to each channel separately
filtered_img = np.zeros_like(img, dtype=np.uint8)
for i in range(3):
# The wiener function expects float values between 0 and 1
channel = img[:, :, i].astype(np.float64) / 255.0
filtered_channel = wiener(channel, (5, 5))
filtered_img[:, :, i] = (np.clip(filtered_channel, 0, 1) * 255).astype(np.uint8)
# Resize image to the target size required by ShuffleNetV2
resized_img = cv2.resize(filtered_img, target_size)
return resized_img
except Exception as e:
print(f"Error processing image {image_path}: {e}")
return None
# --- 2. Feature Extractor: ShuffleNetV2 ---
def create_feature_extractor(input_shape=(224, 224, 3)):
"""
Creates the ShuffleNetV2 model for feature extraction.
We use pre-trained weights from ImageNet and freeze the layers.
"""
base_model = ShuffleNetV2(
include_top=False,
weights='imagenet',
input_shape=input_shape,
pooling='avg'
)
base_model.trainable = False # Freeze layers for feature extraction
return base_model
# --- 4. Classifier: Multi-Layer Autoencoder (ML-AE) based model ---
def create_classifier(input_dim, num_classes, learning_rate=0.001, dropout_rate=0.5):
"""
Creates the classifier model. The paper refers to it as a Multi-Layer
Autoencoder, but for a classification task, this architecture functions as
a standard Multi-Layer Perceptron (MLP) or a Dense Neural Network.
"""
input_layer = Input(shape=(input_dim,))
# Encoder part (as per AE terminology)
x = Dense(256, activation='relu')(input_layer)
x = BatchNormalization()(x)
x = Dropout(dropout_rate)(x)
x = Dense(128, activation='relu')(x)
x = BatchNormalization()(x)
x = Dropout(dropout_rate)(x)
# Output layer
output_layer = Dense(num_classes, activation='softmax')(x)
model = Model(inputs=input_layer, outputs=output_layer)
optimizer = Adam(learning_rate=learning_rate)
model.compile(
optimizer=optimizer,
loss='categorical_crossentropy',
metrics=['accuracy', tf.keras.metrics.Precision(name='precision')]
)
return model
# --- 3. Hyperparameter Tuner: Discrete Migratory Bird Optimizer (DMBO) ---
class DiscreteMigratoryBirdOptimizer:
"""
Implementation of the DMBO to find optimal hyperparameters for the classifier.
Each 'bird' represents a set of hyperparameters.
"""
def __init__(self, hyperparameter_space, fitness_function, n_birds=10, n_iterations=5, k_leader_neighbors=3, j_follower_neighbors=2):
self.hyperparameter_space = hyperparameter_space
self.fitness_function = fitness_function
self.n_birds = n_birds
self.n_iterations = n_iterations
self.k_leader_neighbors = k_leader_neighbors
self.j_follower_neighbors = j_follower_neighbors
self.population = []
self.fitness_scores = []
self.best_solution = None
self.best_fitness = -1
def _initialize_population(self):
"""Creates the initial flock of birds (solutions)."""
print("DMBO: Initializing population...")
self.population = []
for _ in range(self.n_birds):
solution = {key: random.choice(values) for key, values in self.hyperparameter_space.items()}
self.population.append(solution)
def _get_neighbors(self, solution, n_neighbors):
"""Generates neighboring solutions by mutating one hyperparameter."""
neighbors = []
for _ in range(n_neighbors):
neighbor = solution.copy()
# Mutate one random parameter
param_to_mutate = random.choice(list(self.hyperparameter_space.keys()))
current_value = neighbor[param_to_mutate]
possible_values = [v for v in self.hyperparameter_space[param_to_mutate] if v != current_value]
if possible_values:
neighbor[param_to_mutate] = random.choice(possible_values)
neighbors.append(neighbor)
return neighbors
def optimize(self):
"""Runs the main optimization loop."""
self._initialize_population()
for i in range(self.n_iterations):
print(f"\n--- DMBO Iteration {i + 1}/{self.n_iterations} ---")
# Evaluate fitness of the current population
self.fitness_scores = [self.fitness_function(sol) for sol in self.population]
# Find the leader (best bird)
leader_index = np.argmax(self.fitness_scores)
leader_solution = self.population[leader_index]
leader_fitness = self.fitness_scores[leader_index]
print(f"Current Leader Fitness: {leader_fitness:.4f} with params: {leader_solution}")
if leader_fitness > self.best_fitness:
self.best_fitness = leader_fitness
self.best_solution = leader_solution
print(f"New Global Best Found! Fitness: {self.best_fitness:.4f}")
# Evolve the population
new_population = []
# 1. Leader Evolution
leader_neighbors = self._get_neighbors(leader_solution, self.k_leader_neighbors)
best_leader_neighbor = leader_solution
best_leader_fitness = leader_fitness
for neighbor in leader_neighbors:
fitness = self.fitness_function(neighbor)
if fitness > best_leader_fitness:
best_leader_fitness = fitness
best_leader_neighbor = neighbor
new_population.append(best_leader_neighbor)
# 2. Follower Evolution
# The paper's V-shape formation is complex; we simplify by having followers
# learn from the leader and their own exploration.
for j in range(self.n_birds):
if j == leader_index:
continue
follower_solution = self.population[j]
follower_fitness = self.fitness_scores[j]
# Generate neighbors and also consider a solution "shared" by the leader
follower_neighbors = self._get_neighbors(follower_solution, self.j_follower_neighbors)
# Learning from leader: create a hybrid solution
hybrid_solution = follower_solution.copy()
param_to_inherit = random.choice(list(self.hyperparameter_space.keys()))
hybrid_solution[param_to_inherit] = leader_solution[param_to_inherit]
all_candidates = follower_neighbors + [hybrid_solution]
best_follower_neighbor = follower_solution
best_follower_fitness = follower_fitness
for candidate in all_candidates:
fitness = self.fitness_function(candidate)
if fitness > best_follower_fitness:
best_follower_fitness = fitness
best_follower_neighbor = candidate
new_population.append(best_follower_neighbor)
self.population = new_population
print("\nDMBO optimization finished.")
print(f"Best hyperparameters found: {self.best_solution}")
print(f"Best validation precision: {self.best_fitness:.4f}")
return self.best_solution
# --- Main DMBOTL-MRDD Model Class ---
class DMBOTL_MRDD:
def __init__(self, data_path, num_classes, class_labels):
self.data_path = data_path
self.num_classes = num_classes
self.class_labels = class_labels
self.target_size = (224, 224)
self.feature_extractor = create_feature_extractor(self.target_size + (3,))
self.classifier = None
self.best_hyperparams = None
def load_and_prepare_data(self):
print("Loading and preparing data...")
image_paths = []
labels = []
for class_index, class_name in enumerate(self.class_labels):
class_dir = os.path.join(self.data_path, class_name)
if not os.path.isdir(class_dir):
print(f"Warning: Directory not found for class '{class_name}'.")
continue
for fname in os.listdir(class_dir):
image_paths.append(os.path.join(class_dir, fname))
labels.append(class_index)
# Preprocess images
# Using a smaller subset for demonstration to speed up the process
# For a full run, use all data.
num_samples = len(image_paths)
print(f"Found {num_samples} images.")
# Using a smaller subset for quick demo
if num_samples > 500:
print("Using a subset of 500 images for this demonstration.")
subset_indices = np.random.choice(num_samples, 500, replace=False)
image_paths = [image_paths[i] for i in subset_indices]
labels = [labels[i] for i in subset_indices]
images = [preprocess_image(p, self.target_size) for p in image_paths]
# Filter out None values from failed preprocessing
valid_indices = [i for i, img in enumerate(images) if img is not None]
images = [images[i] for i in valid_indices]
labels = [labels[i] for i in valid_indices]
X = np.array(images)
y = to_categorical(np.array(labels), num_classes=self.num_classes)
# Extract features
print("Extracting features using ShuffleNetV2...")
features = self.feature_extractor.predict(X, verbose=1)
# Split data
self.X_train, self.X_test, self.y_train, self.y_test = train_test_split(
features, y, test_size=0.2, random_state=42, stratify=y
)
# Further split training data for hyperparameter tuning
self.X_train_opt, self.X_val_opt, self.y_train_opt, self.y_val_opt = train_test_split(
self.X_train, self.y_train, test_size=0.25, random_state=42
)
print(f"Data prepared: ")
print(f" - DMBO Training set: {self.X_train_opt.shape[0]} samples")
print(f" - DMBO Validation set: {self.X_val_opt.shape[0]} samples")
print(f" - Final Training set: {self.X_train.shape[0]} samples")
print(f" - Final Test set: {self.X_test.shape[0]} samples")
def _fitness_function(self, params):
"""
Trains a classifier with given params and returns validation precision.
This is the core evaluation function for the DMBO.
"""
print(f" - Evaluating params: {params}")
model = create_classifier(
input_dim=self.X_train_opt.shape[1],
num_classes=self.num_classes,
learning_rate=params['learning_rate'],
dropout_rate=params['dropout_rate']
)
# Train for a small number of epochs for speed during optimization
model.fit(
self.X_train_opt, self.y_train_opt,
epochs=params['epochs'],
batch_size=params['batch_size'],
validation_data=(self.X_val_opt, self.y_val_opt),
verbose=0 # Suppress logs during fitness evaluation
)
y_pred = model.predict(self.X_val_opt)
y_pred_classes = np.argmax(y_pred, axis=1)
y_true_classes = np.argmax(self.y_val_opt, axis=1)
# Using macro precision as the fitness score, as cited in the paper
precision = precision_score(y_true_classes, y_pred_classes, average='macro', zero_division=0)
print(f" - Achieved Precision: {precision:.4f}")
return precision
def tune_hyperparameters(self):
"""
Uses DMBO to find the best hyperparameters for the classifier.
"""
print("\n--- Starting Hyperparameter Tuning with DMBO ---")
hyperparameter_space = {
'learning_rate': [1e-2, 1e-3, 1e-4],
'dropout_rate': [0.3, 0.5, 0.7],
'batch_size': [16, 32, 64],
'epochs': [10, 15] # Epochs for fitness evaluation
}
dmbo = DiscreteMigratoryBirdOptimizer(
hyperparameter_space=hyperparameter_space,
fitness_function=self._fitness_function,
n_birds=5, # Reduced for speed
n_iterations=3 # Reduced for speed
)
self.best_hyperparams = dmbo.optimize()
def train_final_model(self, epochs=50):
"""
Trains the final classifier on the full training data using the
best hyperparameters found by DMBO.
"""
if not self.best_hyperparams:
print("Warning: Best hyperparameters not found. Using defaults.")
self.best_hyperparams = {
'learning_rate': 0.001,
'dropout_rate': 0.5,
'batch_size': 32,
}
print("\n--- Training Final Model ---")
self.classifier = create_classifier(
input_dim=self.X_train.shape[1],
num_classes=self.num_classes,
learning_rate=self.best_hyperparams['learning_rate'],
dropout_rate=self.best_hyperparams['dropout_rate']
)
history = self.classifier.fit(
self.X_train, self.y_train,
epochs=epochs,
batch_size=self.best_hyperparams['batch_size'],
validation_data=(self.X_test, self.y_test),
verbose=1
)
return history
def evaluate(self):
"""Evaluates the final model on the test set."""
print("\n--- Evaluating Final Model ---")
if not self.classifier:
print("Model has not been trained yet.")
return
loss, accuracy, precision = self.classifier.evaluate(self.X_test, self.y_test, verbose=0)
print(f"Test Loss: {loss:.4f}")
print(f"Test Accuracy: {accuracy*100:.2f}%")
print(f"Test Precision: {precision*100:.2f}%")
def main():
"""
Main function to run the DMBOTL-MRDD pipeline.
NOTE: You need to organize your data into subdirectories for this to work.
Example structure:
/path/to/dataset/
├── AMD/
│ ├── img1.png
│ └── ...
├── DR/
│ ├── img2.png
│ └── ...
└── Normal/
├── img3.png
└── ...
"""
# IMPORTANT: Update this path to your dataset directory
DATASET_PATH = 'multi_retinal_disease_dataset'
if not os.path.exists(DATASET_PATH):
print(f"Error: Dataset path '{DATASET_PATH}' does not exist.")
print("Please create a dummy dataset directory with subfolders for each class to run this script.")
# Create a dummy structure for demonstration
print("Creating a dummy dataset structure for demonstration purposes...")
CLASS_LABELS_DEMO = ['AMD', 'DR', 'Normal']
for label in CLASS_LABELS_DEMO:
os.makedirs(os.path.join(DATASET_PATH, label), exist_ok=True)
# Create a dummy image
dummy_img = np.random.randint(0, 255, size=(100, 100, 3), dtype=np.uint8)
cv2.imwrite(os.path.join(DATASET_PATH, label, f'dummy_{label}.png'), dummy_img)
print("Dummy dataset created. You can now run the script.")
# The paper mentions 7 classes: AMD, DR, Glaucoma, HR, Normal, Others, Pathological Myopia
# We will use a subset for this example. Adjust as needed.
CLASS_LABELS = sorted([d for d in os.listdir(DATASET_PATH) if os.path.isdir(os.path.join(DATASET_PATH, d))])
if not CLASS_LABELS:
print("No class subdirectories found in the dataset path. Exiting.")
return
NUM_CLASSES = len(CLASS_LABELS)
print(f"Detected {NUM_CLASSES} classes: {CLASS_LABELS}")
# Initialize and run the model pipeline
model_pipeline = DMBOTL_MRDD(DATASET_PATH, NUM_CLASSES, CLASS_LABELS)
model_pipeline.load_and_prepare_data()
model_pipeline.tune_hyperparameters()
model_pipeline.train_final_model(epochs=50) # Train for more epochs for final model
model_pipeline.evaluate()
if __name__ == '__main__':
main()
References:
[1] Al-Kahtani, N. et al. (2025). Discrete migratory bird optimizer with deep transfer learning aided multi-retinal disease detection on fundus imaging. Results in Engineering, 26, 104574. https://doi.org/10.1016/j.rineng.2025.104574
[2] Vaiyapuri, T. et al. (2022). Intelligent Deep Learning Based Multi-Retinal Disease Diagnosis. Computers, Materials & Continua.
[3] Qureshi, I. et al. (2021). Diabetic retinopathy detection using active deep learning. Multimedia Tools and Applications.
Related posts, You May like to read
- 7 Shocking Truths About Knowledge Distillation: The Good, The Bad, and The Breakthrough (SAKD)
- 7 Revolutionary Breakthroughs in Medical Image Translation (And 1 Fatal Flaw That Could Derail Your AI Model)
- DeepSPV: Revolutionizing 3D Spleen Volume Estimation from 2D Ultrasound with AI
- ACAM-KD: Adaptive and Cooperative Attention Masking for Knowledge Distillation
- GeoSAM2 3D Part Segmentation — Prompt-Controllable, Geometry-Aware Masks for Precision 3D Editing
- Probabilistic Smooth Attention for Deep Multiple Instance Learning in Medical Imaging
- A Knowledge Distillation-Based Approach to Enhance Transparency of Classifier Models
- Towards Trustworthy Breast Tumor Segmentation in Ultrasound Using AI Uncertainty
Pingback: Modifying Final Splits of Classification Trees (MDFS) for Subpopulation Targeting - aitrendblend.com
Pingback: UniForCE: A Robust Method for Discovering Clusters and Estimating Their Number Using Local Unimodality - aitrendblend.com
Pingback: Stabilizing Uncertain Stochastic Systems: A Deep Learning Approach to Inverse Optimal Control - aitrendblend.com
Pingback: SegTrans: The Breakthrough Framework That Makes AI Segmentation Models Vulnerable to Transfer Attacks - aitrendblend.com