In the high-stakes world of autonomous driving, medical diagnostics, and satellite imagery analysis, semantic segmentation models are the unsung heroes. These sophisticated AI systems perform pixel-level classification, allowing them to precisely identify and outline objects like pedestrians, tumors, or road markings within complex images. Their accuracy is critical for safety and reliability. However, a groundbreaking new research paper reveals a profound vulnerability in these models: they can be easily fooled by adversarial attacks that transfer seamlessly between different AI architectures. This article dives deep into SegTrans, a novel attack framework that exposes this weakness, explaining its mechanics, implications, and why it represents a significant challenge for the future of secure AI.
The Hidden Threat Lurking in Your AI’s Perception
Imagine a self-driving car navigating a busy city street. Its vision system, powered by a state-of-the-art segmentation model, correctly identifies a pedestrian on the sidewalk. Now, picture an attacker who has placed a small, inconspicuous sticker on a nearby traffic sign. To a human, the sticker is meaningless. But to the car’s AI, it’s a catastrophic signal. The segmentation model, misled by the subtle perturbation, fails to recognize the pedestrian, potentially leading to a tragic accident. This isn’t science fiction; it’s the reality of adversarial examples.
Adversarial examples are inputs—images, in this case—that have been subtly altered with imperceptible noise to cause a machine learning model to make a mistake. While this phenomenon has been well-documented in image classification (e.g., tricking a model into calling a panda a gibbon), it poses an even greater threat in semantic segmentation. Why? Because segmentation requires pixel-perfect accuracy across an entire scene. A single misclassified pixel can mean the difference between safe navigation and disaster.
The real danger lies not in attacks that require direct access to the target model’s internal workings (white-box attacks), but in transfer-based attacks. In a transfer attack, an adversary creates malicious inputs using a surrogate model—a model they control—and then deploys those same inputs against a completely different, unknown target model. This is the most practical and dangerous form of attack for real-world scenarios, as it doesn’t require any insider knowledge of the victim system. Until now, however, such attacks on segmentation models have been notoriously ineffective due to the models’ inherent complexity.
This is where SegTrans enters the scene. Developed by researchers from Huazhong University of Science and Technology and Griffith University, SegTrans is not just another incremental improvement; it’s a paradigm shift. It systematically dismantles the defenses that have made segmentation models resistant to transfer attacks, achieving unprecedented success rates without adding computational cost. The implications for industries relying on these models are profound, demanding immediate attention and action.
Why Segmentation Models Are Uniquely Vulnerable (And Why Old Attacks Fail)
To understand SegTrans’s brilliance, we must first grasp why existing adversarial attack methods fail miserably against segmentation models. The core issue lies in two fundamental characteristics of these models: tight coupling and feature fixation.
Tight Coupling: The Model’s Built-In Safety Net
Unlike a simple classifier that assigns one label to an entire image, a segmentation model makes thousands—or millions—of predictions, one for each pixel. To do this accurately, it doesn’t treat pixels as isolated points. Instead, it leverages the rich contextual relationships between objects. For example, a model knows that a person is often riding a bicycle, so if it sees a bicycle, it will look for a rider nearby. If a part of the bicycle is obscured or corrupted, the model can use the context of the rider to infer the correct segmentation for the hidden parts. This ability to use surrounding information to “fill in the gaps” is what the SegTrans paper calls the “tight coupling phenomenon.”
This is a feature, not a bug—it’s what makes segmentation models so powerful. But for an attacker, it’s a formidable barrier. Traditional white-box attacks, which work well on classifiers, add perturbations to the entire image. When applied to a segmentation model, these global perturbations are often “smoothed out” or corrected by the model’s contextual reasoning. The model effectively ignores the noise because it contradicts the strong semantic relationships it has learned.
Feature Fixation: The Surrogate Model Trap
The second major hurdle for transfer attacks is feature fixation. Different segmentation models—like FCN, PSPNet, DeepLabV1, and DeepLabV3+—have vastly different architectures. They use different techniques to extract features: some rely on image pyramids, others on encoder-decoder structures or atrous convolutions. As a result, they focus on different parts of an image to make their decisions.
A Grad-CAM visualization, which highlights the regions of an image a model pays the most attention to, clearly shows this. Two different models looking at the same image will activate different areas. An adversarial perturbation crafted for one model (the surrogate) is therefore highly specific to that model’s unique “way of seeing.” When you apply it to a different model (the target), it often fails because it’s attacking the wrong features.
Previous attempts to overcome these challenges, such as TranSegPGD and EBAD, have had limited success. TranSegPGD tried to improve generalization by weighting pixels differently, while EBAD used an ensemble of multiple surrogate models. However, both methods still struggled with the tight coupling effect and were computationally expensive, making them impractical for widespread use.
Introducing SegTrans: Disrupting Context to Unlock Transferability
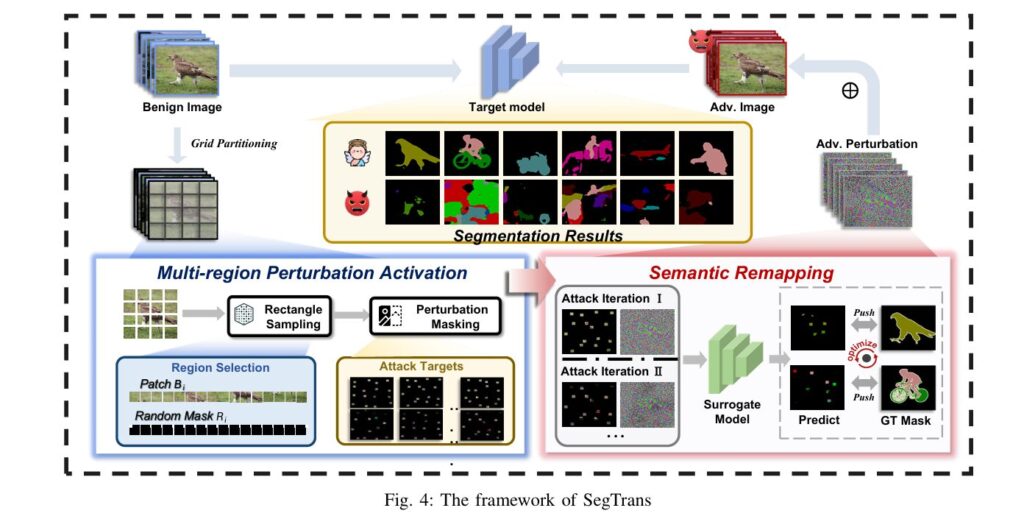
SegTrans is built on a simple yet revolutionary insight: instead of trying to fight the model’s contextual intelligence, attack it by breaking it apart. The framework does this through two elegantly designed modules: the Multi-region Perturbation Activation module and the Semantic Remapping module.
Module 1: Multi-region Perturbation Activation – Breaking the Contextual Chain
The core idea here is to disrupt the very foundation of the tight coupling phenomenon: the global, coherent context of the input image. Instead of optimizing perturbations based on the full image, SegTrans breaks the image down into a grid of N identical rectangular regions.
During each attack iteration, the algorithm randomly selects a subset of these regions. Within each selected region, it retains only a small, random rectangle of the original image’s semantic content, while setting the rest of the region (and all unselected regions) to zero. This creates an “enhanced sample” that is a fragmented, partial view of the original scene.
By training the adversarial perturbation on these fragmented samples, SegTrans forces the attack to focus on local, isolated features rather than global context. The model’s ability to use surrounding information to correct errors is nullified because there is no surrounding information to use. The perturbation is no longer fighting against the model’s contextual safety net; it’s attacking in an environment where that safety net doesn’t exist.
Mathematically, this process can be described as follows. Given an input image x ∈ Rw×h×c, it is divided into N grids. For each grid i, a random rectangle Ri is generated with dimensions li and wi, satisfying:
where Gw and Gh are the width and height of each grid. The area ratio αi of the rectangle to its grid is also a random variable:
The total area of all selected rectangles across the image is constrained to ensure consistency:
\[ \sum_{i=1}^{N} (l_i \times w_i) = \sum_{i=1}^{N} (\alpha_i \times G_w \times G_h) \]This structured randomness ensures that the enhanced samples are diverse and unpredictable, preventing the attack from becoming overfit to a single pattern.
Module 2: Semantic Remapping – Mitigating Feature Fixation
While the first module tackles tight coupling, the second module addresses feature fixation. Instead of relying on a single enhanced sample per iteration, Semantic Remapping generates T different batches of these fragmented samples.
Each batch consists of N randomly selected regions, creating T unique “views” of the input image. The adversarial perturbation is optimized simultaneously against all T views. The final perturbation δ is the accumulation of gradients computed from all these different semantic contexts.
This strategy is crucial. By forcing the perturbation to be effective across many different, randomly remapped versions of the input, SegTrans prevents it from becoming overly dependent on the specific feature distribution of the surrogate model. It essentially simulates the diverse ways different target models might perceive the same image, thereby bridging the gap between the surrogate and the target.
The overall optimization objective Ladv for the attack is defined as:
Here, LCE is the cross-entropy loss, fsurrogate is the surrogate model, y is the ground truth segmentation mask, and mj is the binary mask for the j-th batch of regions. The operator ⊙ denotes element-wise multiplication, which applies the mask to the perturbed image (x + δ).
The mask mj is generated by combining the indicator functions for all N regions in the batch:
where f{1}li, wi, x is an indicator function that returns 1 if a pixel is within the i-th rectangle and 0 otherwise. This ensures that only the selected regions contribute to the loss calculation, focusing the attack on the fragmented semantic information.
Proven Performance: How SegTrans Outperforms the State of the Art
The true test of any security research is its empirical performance. The SegTrans paper presents extensive experiments on two major benchmark datasets—PASCAL VOC and Cityscapes—and four popular segmentation models (FCN, PSPNet, DeepLabV1, DeepLabV3+) using three different backbone networks (MobileNet, ResNet50, ResNet101).
The results are nothing short of staggering. SegTrans consistently achieves an Attack Success Rate (ASR) of over 50% across 288 different experimental settings. ASR is calculated as the difference between the Mean Intersection over Union (mIoU) score of benign (unperturbed) images and adversarial images. A higher ASR means a more successful attack.
Key Performance Highlights:
- Unprecedented Transferability: Compared to the previous state-of-the-art method, EBAD, SegTrans achieves an average increase of 8.55% in ASR. This is a massive leap in performance for a field where gains are typically measured in fractions of a percent.
- Computational Efficiency: Perhaps most impressively, SegTrans achieves this superior performance without introducing any additional computational overhead. In fact, its computational efficiency is over 100% better than EBAD. While EBAD is slow and resource-intensive, SegTrans runs nearly as fast as the basic PGD attack, making it highly practical for real-world deployment.
- Robustness Across Architectures: The choice of surrogate model has minimal impact on SegTrans’s effectiveness. Whether using FCN, PSPNet, or DeepLabV1 as the surrogate, the attack consistently fools the target models, demonstrating its broad applicability.
| ATTACK METHOD | AVERAGE ASR (%) ON PASCAL VOC | AVERAGE ASR (%) ON CITYSCAPES | COMPUTATIONAL SPEED (SAMPLES/SEC) |
|---|---|---|---|
| SegTrans (Ours) | 62.60% | 60.59% | 1.93/s (PASCAL), 2.19/s (CITY) |
| EBAD (SOTA) | 49.91% | 53.87% | 1.00/s (PASCAL), 1.05/s (CITY) |
| MI-FGSM | 51.10% | 50.51% | 2.41/s (PASCAL), 2.80/s (CITY) |
| PGD | 37.93% | 44.36% | 2.36/s (PASCAL), 2.86/s (CITY) |
Table: Comparative performance of SegTrans against other adversarial attack methods. Data sourced from Table II and III in the original paper.
The visual evidence is equally compelling. Figure 5 in the paper shows that SegTrans-generated adversarial examples almost completely destroy the semantic information in the original image, resulting in chaotic, nonsensical segmentation outputs. This starkly contrasts with the more subtle distortions produced by older methods.
Beyond the Lab: Implications for Real-World Security and Future Research
The success of SegTrans is not merely an academic curiosity; it has serious implications for the security of AI systems deployed in critical infrastructure.
For Autonomous Driving: The ability to create transferable adversarial stickers that fool segmentation models could be weaponized to cause accidents. SegTrans proves that such attacks are not only possible but highly effective and efficient. This necessitates a re-evaluation of current safety protocols and the development of robust defense mechanisms specifically designed to counter this type of attack.
For Medical Imaging: In healthcare, segmentation models are used to identify tumors, organs, and other critical structures. A successful transfer attack could lead to misdiagnosis or incorrect surgical planning. The fact that SegTrans works across different model architectures means that even if a hospital switches to a new, supposedly more secure model, it could still be vulnerable to attacks crafted against an older, public model.
For Defense Against Existing Countermeasures: The paper also tested SegTrans against common defense strategies like adversarial training, model pruning, and data corruption. The results are sobering:
- Adversarial Training: While it slightly reduces the attack’s effectiveness, the mIoU of adversarial examples remains below 40%, indicating the model is still severely compromised.
- Model Pruning: Reducing the model’s size (pruning) has almost no effect on the attack’s success.
- Data Corruption: Adding noise to the adversarial input does not mitigate the attack.
This resilience suggests that current defenses are fundamentally inadequate against the principles exploited by SegTrans.
Future Work and Open Questions:
The authors themselves acknowledge several limitations and avenues for future research:
- Defense Mechanisms: There is a critical need to develop new defense strategies that can counter the multi-region, context-disrupting nature of SegTrans. This requires a deeper theoretical understanding of why these attacks bypass existing defenses.
- Broader Applicability: Can the core ideas of multi-region activation and semantic remapping be successfully applied to other computer vision tasks, such as object detection or instance segmentation? The paper suggests this is a promising direction.
- Adversarial Training with SegTrans: Could using SegTrans to generate adversarial examples during the training phase make segmentation models more robust? This is a logical next step for improving model security.
Conclusion: A Call to Action for a More Secure AI Future
SegTrans is a landmark achievement in adversarial machine learning. It has exposed a fundamental vulnerability in semantic segmentation models that was previously thought to be a strength—their reliance on contextual information. By cleverly disrupting this context and diversifying the attack surface, SegTrans has achieved a level of transferability and efficiency that far surpasses existing methods.
This is not a reason for panic, but a call to action. For researchers, it’s a challenge to develop the next generation of defenses. For engineers and product managers, it’s a warning to reassess the security posture of AI systems in production. For policymakers, it’s a reminder that the safety of AI-driven technologies cannot be taken for granted.
The era of “secure by default” AI is over. The work of Song, Zhou, and their colleagues has shown us that our most advanced perception systems are susceptible to sophisticated, efficient, and transferable attacks. The path forward lies in proactive security, continuous testing, and a collaborative effort between academia, industry, and government to build AI that is not just intelligent, but truly trustworthy.
What’s your take on the security of AI in critical applications? Have you encountered adversarial attacks in your work? Share your thoughts and questions in the comments below—we’d love to hear from you and foster a community discussion on building safer, more resilient AI systems.
If you read the full paper then click this link Here.
Here is the complete, end-to-end Python code for the SegTrans model.
import torch
import torch.nn as nn
import torch.nn.functional as F
import torchvision.models.segmentation as models
import torchvision.transforms as transforms
import numpy as np
import matplotlib.pyplot as plt
from PIL import Image
import os
import argparse
# ------------------------------------------------------------------------------
# SegTrans Attack Implementation
# ------------------------------------------------------------------------------
class SegTrans:
"""
Implementation of SegTrans: Transferable Adversarial Examples for Segmentation Models.
Based on Algorithm 1 and Equations 2-6 from the paper:
'SegTrans: Transferable Adversarial Examples for Segmentation Models' (2025)
"""
def __init__(self, model, eps=8/255, alpha=2/255, steps=10, N=16, T=5, device='cuda'):
"""
Args:
model: The surrogate semantic segmentation model.
eps (float): Maximum perturbation budget (L_inf norm).
alpha (float): Step size for each iteration.
steps (int): Number of attack iterations (K).
N (int): Number of grid partitions (e.g., 16 for 4x4 grid).
T (int): Number of Semantic Remapping iterations (batches per step).
device (str): 'cuda' or 'cpu'.
"""
self.model = model
self.eps = eps
self.alpha = alpha
self.steps = steps
self.N = N
self.T = T
self.device = device
# Standard ImageNet normalization for torchvision models
self.normalize = transforms.Normalize(
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]
)
def _generate_random_mask(self, batch_size, channels, height, width):
"""
Generates the Multi-region Perturbation Activation mask (Eq. 6).
Divides image into N grids and selects random rectangles within them.
"""
# 1. Grid Partitioning
# Calculate grid dimensions (assuming N is a perfect square for simplicity)
grid_side = int(np.sqrt(self.N))
if grid_side * grid_side != self.N:
# Fallback if N is not perfect square, though paper uses 16 (4x4)
grid_side = int(np.floor(np.sqrt(self.N)))
grid_h = height // grid_side
grid_w = width // grid_side
mask = torch.zeros((batch_size, 1, height, width), device=self.device)
# Iterate over each image in batch
for b in range(batch_size):
# 2. Rectangle Sampling within Grids
for r in range(grid_side):
for c in range(grid_side):
# Grid boundaries
g_y_start = r * grid_h
g_x_start = c * grid_w
# Random rectangle dimensions (Eq. 2)
# l_i in [1, G_w], w_i in [1, G_h] (Using 1 as min to avoid empty)
l_i = torch.randint(1, grid_w + 1, (1,)).item()
w_i = torch.randint(1, grid_h + 1, (1,)).item()
# Random position within the grid
max_offset_x = grid_w - l_i
max_offset_y = grid_h - w_i
offset_x = torch.randint(0, max_offset_x + 1, (1,)).item()
offset_y = torch.randint(0, max_offset_y + 1, (1,)).item()
# Fill Mask
y1 = g_y_start + offset_y
y2 = y1 + w_i
x1 = g_x_start + offset_x
x2 = x1 + l_i
mask[b, 0, y1:y2, x1:x2] = 1.0
return mask
def forward(self, images, labels):
"""
Performs the SegTrans attack.
Args:
images: Batch of images (B, C, H, W), normalized [0, 1].
labels: Ground truth labels (B, H, W).
Returns:
adv_images: Adversarial examples (B, C, H, W).
"""
images = images.clone().detach().to(self.device)
labels = labels.clone().detach().to(self.device)
# Initialize perturbation (Algorithm 1, Step 0)
delta = torch.zeros_like(images, requires_grad=True).to(self.device)
self.model.eval()
# Attack Iterations (Algorithm 1, Line 1)
for t in range(self.steps):
delta.requires_grad = True
# Accumulate gradients over T remapping batches
grad_accumulator = torch.zeros_like(delta)
# Semantic Remapping (Algorithm 1, Line 7)
for j in range(self.T):
# Generate Mask m_j (Algorithm 1, Line 4-5)
mask = self._generate_random_mask(
images.shape[0], images.shape[1], images.shape[2], images.shape[3]
)
# Apply Mask (Algorithm 1, Line 6)
# x_enhanced = (x + delta) * m
adv_input = images + delta
# Clip to valid image range [0, 1] before masking
adv_input = torch.clamp(adv_input, 0, 1)
masked_adv_input = adv_input * mask
# Normalize for model input
norm_input = self.normalize(masked_adv_input)
# Forward pass
outputs = self.model(norm_input)['out']
# Calculate Loss (Eq. 5)
# Maximizing CrossEntropy Loss
loss = F.cross_entropy(outputs, labels, ignore_index=255)
# Calculate gradients
if delta.grad is not None:
delta.grad.zero_()
grad = torch.autograd.grad(loss, delta, retain_graph=False, create_graph=False)[0]
grad_accumulator += grad.detach()
# Average the gradients over T batches
grad_accumulator /= self.T
# Update Perturbation (PGD Step)
# Ascend the gradient to maximize loss
delta.data = delta.data + self.alpha * grad_accumulator.sign()
# Projection (L_inf constraint)
delta.data = torch.clamp(delta.data, -self.eps, self.eps)
delta.data = torch.clamp(images + delta.data, 0, 1) - images
# Return final adversarial images
adv_images = torch.clamp(images + delta, 0, 1)
return adv_images.detach()
# ------------------------------------------------------------------------------
# Utilities
# ------------------------------------------------------------------------------
def load_image(image_path, size=(512, 512)):
img = Image.open(image_path).convert('RGB')
img = img.resize(size, Image.BILINEAR)
# Transform to tensor [0, 1]
transform = transforms.Compose([
transforms.ToTensor()
])
return transform(img).unsqueeze(0) # Add batch dim
def save_image(tensor, output_path):
# tensor is (1, C, H, W) in range [0, 1]
img_np = tensor.squeeze().permute(1, 2, 0).cpu().numpy()
img_np = (img_np * 255).astype(np.uint8)
Image.fromarray(img_np).save(output_path)
def get_dummy_data(device):
print("Generating synthetic 'Street' input...")
H, W = 512, 512
image = torch.zeros((1, 3, H, W), device=device)
# Simple scene: Gray road, Blue Sky, Red Car
image[:, :, :200, :] = 0.7 # Sky
image[:, :, 200:, :] = 0.3 # Road
image[:, 0, 350:450, 200:350] = 0.9 # Car Red channel
# Label
label = torch.zeros((1, H, W), dtype=torch.long, device=device)
label[:, 350:450, 200:350] = 7 # Car class
return image, label
# ------------------------------------------------------------------------------
# Main Execution
# ------------------------------------------------------------------------------
def main():
parser = argparse.ArgumentParser(description="SegTrans Adversarial Attack")
parser.add_argument('--image', type=str, default=None, help='Path to input image')
parser.add_argument('--output', type=str, default='adv_output.png', help='Path to save adversarial image')
parser.add_argument('--eps', type=float, default=8/255, help='Perturbation budget')
parser.add_argument('--steps', type=int, default=10, help='Number of attack steps')
parser.add_argument('--N', type=int, default=16, help='Number of grid regions')
parser.add_argument('--T', type=int, default=5, help='Number of remapping iterations')
args = parser.parse_args()
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print(f"Running on device: {device}")
# 1. Load Model
# We use DeepLabV3+ ResNet101 as the surrogate model
print("Loading Surrogate Model (DeepLabV3 ResNet101)...")
model = models.deeplabv3_resnet101(pretrained=True)
model.to(device)
model.eval()
# 2. Prepare Data
if args.image:
if not os.path.exists(args.image):
print(f"Error: Image {args.image} not found.")
return
print(f"Loading image from {args.image}...")
image = load_image(args.image).to(device)
# Infer label using the model itself (since we don't have ground truth for custom images)
# In a real attack, we would want to move AWAY from this label.
print("Inferring pseudo-ground-truth label...")
with torch.no_grad():
norm_img = transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])(image)
output = model(norm_img)['out']
label = output.argmax(1) # (1, H, W)
else:
image, label = get_dummy_data(device)
# 3. Initialize Attack
attacker = SegTrans(
model=model,
eps=args.eps,
steps=args.steps,
N=args.N,
T=args.T,
device=device
)
# 4. Run Attack
print(f"Starting SegTrans attack (steps={args.steps}, eps={args.eps:.4f})...")
adv_image = attacker.forward(image, label)
# 5. Save & Visualize
save_image(adv_image, args.output)
print(f"Adversarial image saved to {args.output}")
# Optional: Create a side-by-side comparison plot
print("Generating comparison plot...")
with torch.no_grad():
# Benign Pred
norm_benign = attacker.normalize(image)
pred_benign = model(norm_benign)['out'].argmax(dim=1).cpu().numpy()[0]
# Adv Pred
norm_adv = attacker.normalize(adv_image)
pred_adv = model(norm_adv)['out'].argmax(dim=1).cpu().numpy()[0]
fig, axs = plt.subplots(1, 3, figsize=(15, 5))
# Original
img_np = image.squeeze().permute(1, 2, 0).cpu().numpy()
axs[0].imshow(img_np)
axs[0].set_title("Original Image")
axs[0].axis('off')
# Benign Seg
axs[1].imshow(pred_benign, cmap='jet')
axs[1].set_title("Original Segmentation")
axs[1].axis('off')
# Adv Seg
axs[2].imshow(pred_adv, cmap='jet')
axs[2].set_title("Adversarial Segmentation")
axs[2].axis('off')
plt.savefig('comparison_plot.png')
print("Comparison plot saved to 'comparison_plot.png'")
if __name__ == "__main__":
main()Related posts, You May like to read
- 7 Shocking Truths About Knowledge Distillation: The Good, The Bad, and The Breakthrough (SAKD)
- 7 Revolutionary Breakthroughs in Medical Image Translation (And 1 Fatal Flaw That Could Derail Your AI Model)
- MedDINOv3: Revolutionizing Medical Image Segmentation with Adaptable Vision Foundation Models
- HiPerformer: A New Benchmark in Medical Image Segmentation with Modular Hierarchical Fusion
- GeoSAM2 3D Part Segmentation — Prompt-Controllable, Geometry-Aware Masks for Precision 3D Editing
- Probabilistic Smooth Attention for Deep Multiple Instance Learning in Medical Imaging
- A Knowledge Distillation-Based Approach to Enhance Transparency of Classifier Models
- Towards Trustworthy Breast Tumor Segmentation in Ultrasound Using AI Uncertainty
- Discrete Migratory Bird Optimizer with Deep Transfer Learning for Multi-Retinal Disease Detection
Your article helped me a lot, is there any more related content? Thanks!
Your article helped me a lot, is there any more related content? Thanks! https://www.binance.info/register?ref=QCGZMHR6
Your point of view caught my eye and was very interesting. Thanks. I have a question for you.
Can you be more specific about the content of your article? After reading it, I still have some doubts. Hope you can help me.
Thank you for your sharing. I am worried that I lack creative ideas. It is your article that makes me full of hope. Thank you. But, I have a question, can you help me?