K2-Agent: The Cognitive Architecture That Taught AI to Think Like Humans About Mobile Tasks
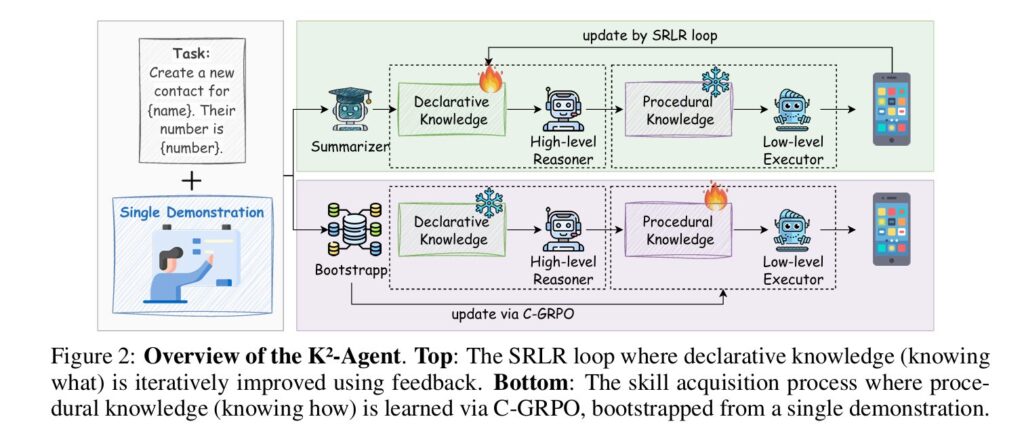
A hierarchical framework separates “knowing what” from “knowing how” — enabling co-evolution of declarative planning knowledge and procedural execution skills for mobile device control, achieving 76.1% success rate on AndroidWorld using only raw screenshots.
Mobile device control agents have long struggled with a fundamental cognitive gap: they either excel at high-level planning but fail at precise execution, or master individual actions but lose sight of the broader task objective. This dichotomy mirrors a well-established principle in cognitive neuroscience — the distinction between declarative knowledge (“knowing what”) and procedural knowledge (“knowing how”). Humans navigate this effortlessly; when we learn to use a new app, we simultaneously build explicit understanding of task logic and implicit muscle memory for interface interactions.
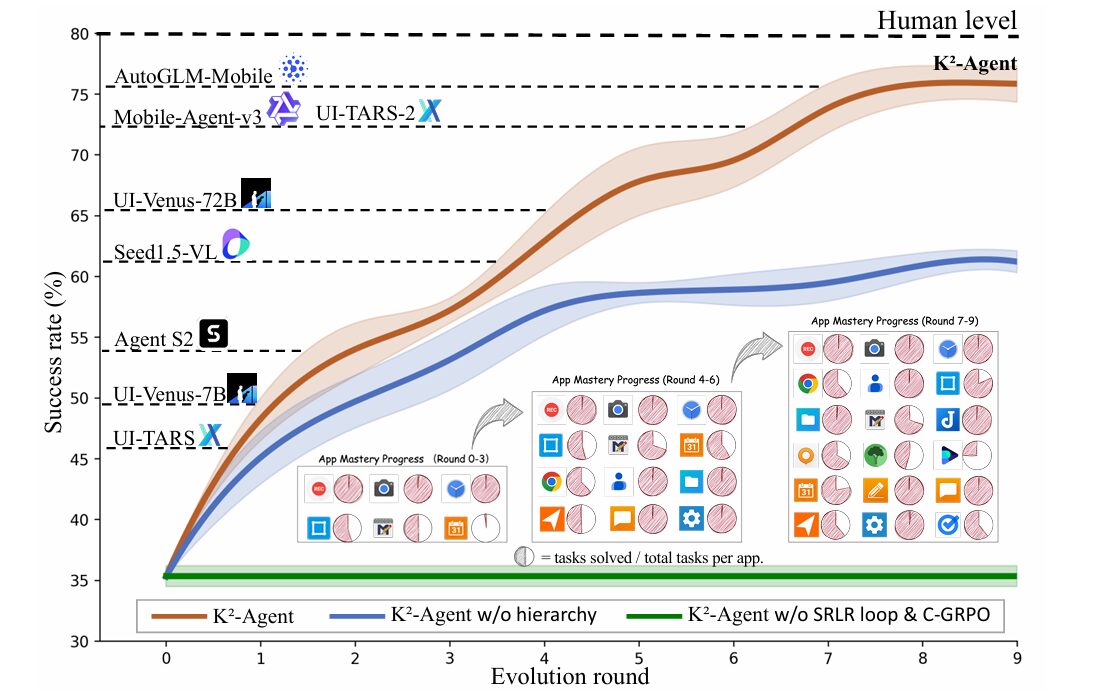
Researchers from Tsinghua University, Huawei Noah’s Ark Lab, and the Institute of Automation at the Chinese Academy of Sciences have proposed a radical reimagining of agent architecture inspired by this cognitive science foundation. Their framework, K2-Agent, explicitly decouples these two knowledge types into a hierarchical planner-executor system that co-evolves through continuous interaction. The high-level planner maintains and refines declarative task knowledge through a self-improvement loop, while the low-level executor acquires procedural skills via curriculum-guided reinforcement learning. On the challenging AndroidWorld benchmark, this approach achieves a 76.1% success rate — ranking first among all methods using only raw screenshots and open-source backbones.
What makes this work particularly significant is not just the performance metric, but the dual generalization capability it demonstrates: the high-level declarative knowledge transfers across different backbone models, while the low-level procedural skills generalize to entirely unseen tasks on different benchmarks. This suggests that the framework has captured something fundamental about how intelligent agents should structure their learning.
The Cognitive Science Foundation: Why Know-What and Know-How Must Separate
Human intelligence relies on two distinct memory systems that operate in parallel during complex tasks. Declarative knowledge consists of explicit facts and concepts that can be consciously recalled and articulated — the understanding that clicking a trash icon means delete, or that you must open an app before using its features. Procedural knowledge encompasses implicit skills acquired through repeated practice — the automatic hand-eye coordination required to precisely tap a small button, or the intuitive sense of how far to swipe to scroll a list.
These systems are supported by distinct neural circuits. Declarative memory involves the hippocampus and medial temporal lobe, enabling rapid learning from single experiences and flexible generalization. Procedural memory engages the basal ganglia and motor cortex, requiring extensive repetition to form automatic “muscle memory” that operates below conscious awareness. Critically, these systems co-activate during complex tasks: declarative knowledge guides what to do, while procedural knowledge determines how to execute.
Existing mobile control agents largely fail to respect this architectural principle. Training-free agents encode task knowledge into prompts or in-context examples, but their performance is capped by foundation model capabilities and they cannot learn from experience. Learning-based agents train monolithic policies that conflate high-level strategy and low-level execution, struggling with long-horizon credit assignment and poor task generalization. Even hierarchical approaches typically treat both layers identically — either both are training-free or both trained with standard supervised fine-tuning or reinforcement learning.
K2-Agent’s core insight is that know-what and know-how naturally match a hierarchical design but should follow fundamentally different update rules. Declarative knowledge should be explicit, symbolic, and refined through reflection; procedural knowledge should be implicit, parametric, and acquired through practice.
The practical manifestation of this insight is a two-layer architecture where each layer is initialized by a vision-language model but evolves through distinct mechanisms. The high-level planner operates in a training-free mode, maintaining an updatable declarative knowledge base that is iteratively refined through execution feedback. The low-level executor is a trainable policy that acquires procedural skills via a novel curriculum-guided reinforcement learning algorithm. These modules form a closed-loop system where improved planning provides better structure for execution learning, while execution feedback enables knowledge base refinement.
The SRLR Loop: Self-Evolving Declarative Knowledge from Single Demonstrations
The high-level planner’s declarative knowledge base is bootstrapped from a single expert demonstration per task — a dramatic reduction from the thousands of samples typically required by learning-based approaches. This initial knowledge captures the core logic for completing the task, key UI elements, and their functions in a structured, language-based format. But the true innovation lies in how this knowledge evolves.
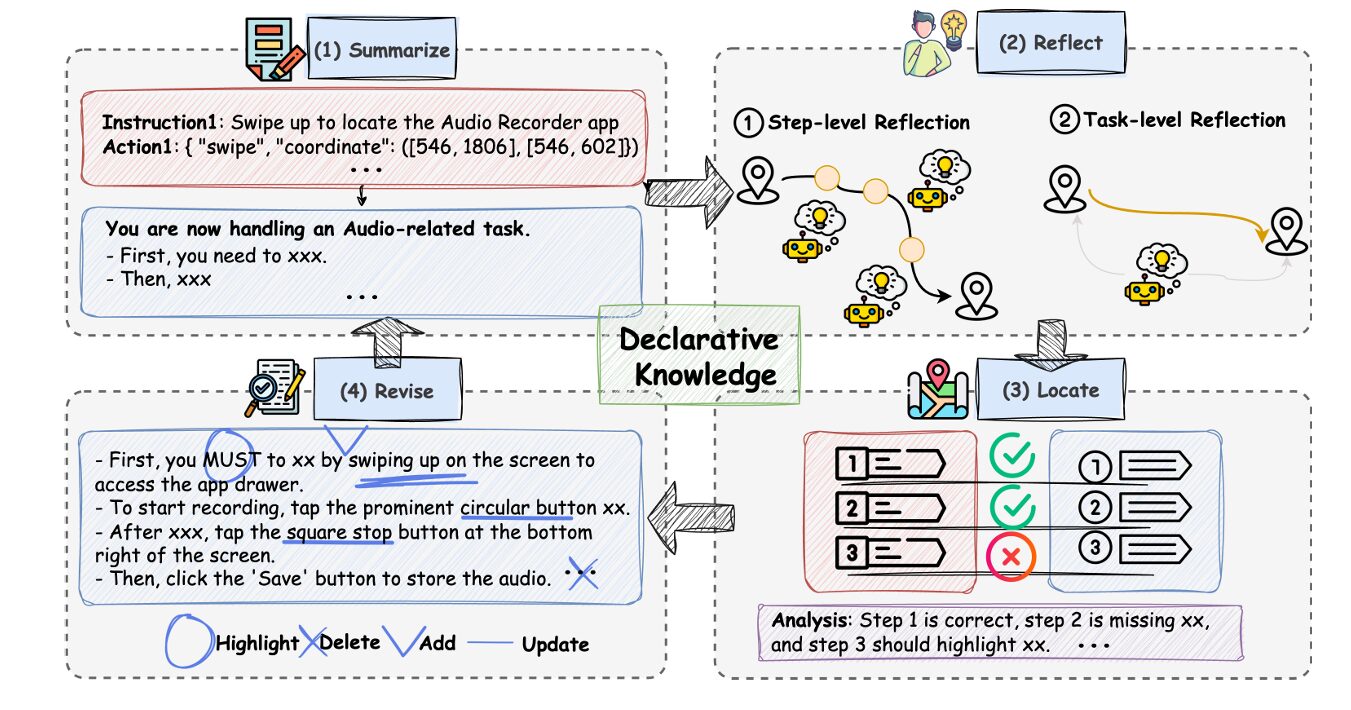
The planner runs a Summarize–Reflect–Locate–Revise (SRLR) loop that continuously incorporates execution feedback to refine the knowledge base. Each stage serves a distinct function in the self-improvement process:
Summarize: Given a single demonstration trajectory and task goal, the planner performs one-pass distillation to produce an initial structured knowledge base. This captures step ordering, UI layout invariants, parameter constraints, and recovery strategies in an explicit, revisable format.
Reflect: Upon trajectory completion, the reflection module analyzes execution at two granularities. Step-level reflection continuously verifies whether each action’s outcome aligns with expectations in the knowledge base. Task-level reflection, activated on failure, generates a structured root-cause explanation such as “failed to identify the Rename button” or “incorrect step sequence.”
Locate: To enable precise revision, the locate module aligns the executed trajectory with the task knowledge and identifies the first decision point yielding an unexpected outcome. This pinpoints exactly where the plan diverged from reality.
Revise: Given the failure explanation and location, the system performs local surgery on the knowledge base using four atomic operators: Add inserts missing steps; Delete removes erroneous instructions; Update revises existing instructions; and Highlight emphasizes critical constraints. These operations yield a revised knowledge base for the next iteration.
“The SRLR loop enables the knowledge base to improve over time through self-evolution. By iterating this cycle, the declarative knowledge becomes increasingly robust, enabling higher-quality planning.” — Wu et al., ICLR 2026
A concrete example illustrates this evolution. In an Audio Recorder task, the initial knowledge from Summarize might include a hard-coded filename from the demonstration. After execution failure on a new task instance with different parameters, Reflect identifies the generalization failure, Locate traces it to the specific filename, and Revise replaces it with a placeholder instruction. Further iterations may add logical structuring, verification steps, and recovery strategies — transforming a literal transcript into a robust, reusable plan.
C-GRPO: Curriculum-Guided Acquisition of Procedural Skills
While the high-level planner evolves explicit knowledge, the low-level executor must acquire implicit procedural skills — the precise motor control required to execute sub-goals on a touchscreen. Training this executor presents two fundamental challenges: sample imbalance and inefficient exploration.
Sample imbalance arises because training data is naturally biased toward common operations. Click actions appear far more frequently than long-press or swipe operations, causing standard training to underfit rare but critical skills. Inefficient exploration stems from the vast action space in long-horizon tasks — the agent must discover successful trajectories through trial and error in a space where rewards are sparse and failures are common.
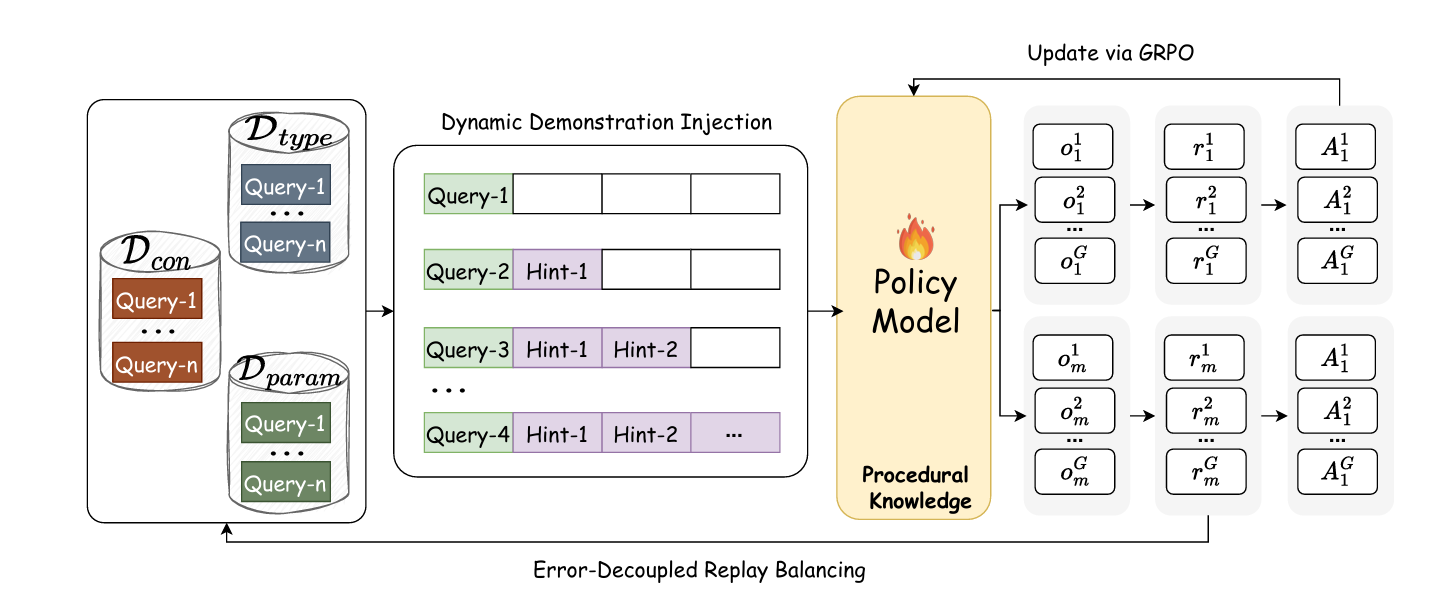
The proposed Curriculum-Guided Group Relative Policy Optimization (C-GRPO) addresses both challenges through two complementary mechanisms:
Error-Decoupled Replay Balancing
The key insight is that execution errors can be decoupled into type errors (predicting swipe instead of click) and parameter errors (clicking with inaccurate coordinates). For each training input, the model generates multiple candidate actions, enabling estimation of error rates:
Based on these error rates, each sample is dynamically assigned to one of three replay buffers: the conventional pool \(\mathcal{D}_{\text{con}}\), the type-exploration pool \(\mathcal{D}_{\text{type}}\), or the precision-optimization pool \(\mathcal{D}_{\text{param}}\). Training mini-batches are constructed by sampling from these buffers with preset ratios, ensuring balanced progress on different weaknesses.
Dynamic Demonstration Injection
Replay balancing alone cannot solve the exploration problem in vast action spaces. C-GRPO introduces a curriculum mechanism that prepends variable-length expert action prefixes to guide exploration. The injected length is scheduled by:
Where \(L\) is the total demonstration length, \(\sigma(k) = \max(0, 1 – k/K_{\max})\) is a linear annealing scheduler, and \(f_{\text{gate}}(d_i) = \tanh(d_i/T)\) is a difficulty-gating function controlled by temperature \(T\). The sample difficulty \(d_i = \eta_{\text{type}}(i) + \eta_{\text{param}}(i)\) ensures more guidance for challenging samples. As training progresses, the model is gradually weaned off demonstrations, enabling autonomous generation of successful trajectories.
C-GRPO’s curriculum design provides adaptive guidance — more extensive support for difficult samples early in training, with gradual withdrawal as competence develops. This mirrors human skill acquisition: initial heavy scaffolding that fades as muscle memory forms.
Closed-Loop Co-Evolution: How Thinking and Practice Reinforce Each Other
The two modules form a synergistic closed-loop system. Forward communication occurs via sub-goals — the high-level planner decomposes global tasks into immediate objectives that guide the low-level executor. The feedback loop consists of execution outcomes — successes, failures, and error patterns — that inform the planner’s knowledge revision.
This coupling creates virtuous cycles. A more accurate knowledge base enables the planner to generate more feasible sub-goals, providing the executor with structured exploration problems and more effective learning signals. As the executor’s procedural skills improve, the planner receives more reliable execution feedback, enabling more precise knowledge refinement. The co-evolution is implemented via an efficient alternating update mechanism: the planner first refines its knowledge base over several SRLR iterations before the executor undergoes intensive C-GRPO training.
The practical efficiency is striking. The high-level planner requires only one demonstration per task — compared to the 10,000+ samples and hundreds of GPUs required by comparable learning-based approaches. The low-level executor trains on a single server with 8× NVIDIA A100 80GB GPUs. Yet this minimal resource investment achieves state-of-the-art performance, suggesting that architectural design can substitute for raw computational scale.
Experimental Validation: AndroidWorld and Beyond
The primary evaluation platform is AndroidWorld, a standardized benchmark featuring 116 hand-crafted tasks across 20 diverse applications. Each task is dynamically instantiated with randomized parameters per episode, preventing solution memorization. Human experts achieve approximately 80% average success on this platform.
Performance Against Baselines
K2-Agent achieves a 76.1% success rate, establishing a new state-of-the-art. This surpasses the strongest open-source learning-based methods (UI-TARS-2 and Mobile-Agent-v3 at 73.3%) and outperforms all closed-source models restricted to screenshot inputs. Critically, this performance is achieved using only raw screenshots — unlike many high-ranked methods that exploit accessibility trees.
| Agent | Type | Input | Success Rate (%) |
|---|---|---|---|
| M3A | Training-free | Screenshot + A11y | 30.6 |
| Agent S2 | Training-free | Screenshot | 54.3 |
| UI-TARS | Learning-based | Screenshot | 46.6 |
| UI-Venus | Learning-based | Screenshot | 65.9 |
| Mobile-Agent-v3 | Learning-based | Screenshot | 73.3 |
| UI-TARS-2 | Learning-based | Screenshot | 73.3 |
| AutoGLM-Mobile | Learning-based | Screenshot + A11y | 75.8 |
| K2-Agent (Ours) | Hierarchical | Screenshot | 76.1 ± 1.0 |
Table 1: Comparison of K2-Agent and baselines on AndroidWorld. K2-Agent achieves state-of-the-art performance using only raw screenshots without accessibility tree access.
Dual Generalization: The True Test of Understanding
Beyond raw performance, K2-Agent demonstrates powerful dual generalization that supports the core architectural hypothesis:
Declarative Knowledge Transfer: The SRLR-produced knowledge base is language-based and explicit. When transferred to different VLM backbones (Gemini-2.5-Pro, GPT-4o) without retraining, all backbones show substantial performance improvements. This confirms that the distilled declarative knowledge is model-agnostic and broadly reusable. The knowledge provides the correct high-level plan, while the backbone’s intrinsic capabilities enable execution.
Procedural Skill Transfer: The low-level executor, trained only on AndroidWorld, achieves 91.3% overall accuracy on ScreenSpot-v2 in a zero-shot setting — competitive with specialized GUI grounding models trained on massive-scale datasets. On Android-in-the-Wild (AitW), it achieves 86.5% on the General subset and 68.3% on WebShopping, surpassing existing RL and SFT-based approaches. This demonstrates that the learned skills are fundamental and platform-agnostic rather than memorized patterns.
Ablation Studies: Isolating Component Contributions
Systematic ablations quantify the contribution of each architectural decision:
| Configuration | Success Rate (%) |
|---|---|
| No Hierarchy (flat end-to-end) | 35.3 |
| No Hierarchy + SRLR | 58.6 |
| Hierarchical (SRLR + SFT-Low) | 62.0 |
| Hierarchical (SRLR + GRPO-Low) | 68.9 |
| K2-Agent (Full: SRLR + C-GRPO) | 76.1 |
Table 2: Ablation study on AndroidWorld. Each component contributes meaningfully to final performance, with the full hierarchical co-evolution system achieving the highest success rate.
The progression reveals important insights. The flat architecture performs poorly, confirming that conflating planning and execution hinders both. Simply adding SRLR knowledge to a flat model provides a notable boost, demonstrating the value of explicit declarative knowledge. The structural benefit of hierarchy appears in the leap to 62.0% — isolating know-what from know-how enables each to develop appropriately. Replacing SFT with vanilla GRPO improves to 68.9%, showing the value of interactive learning. Finally, the full C-GRPO with curriculum guidance achieves 76.1%, with training curves showing higher and more stable rewards throughout optimization.
Ablating C-GRPO components confirms their individual importance. Removing Dynamic Demonstration Injection causes severe degradation — the policy attains substantially lower rewards with pronounced oscillations, indicating that expert-prefixed trajectories are crucial for bootstrapping exploration. Removing Error-Decoupled Replay Balancing results in slower convergence and inferior final performance, as the optimizer becomes biased toward frequent, easier operations.
Comparative Advantages: Why K2-Agent Differs from Prior Art
K2-Agent represents a distinct evolution from existing approaches across multiple dimensions:
vs. Training-Free Agents: While methods like M3A and Agent S2 leverage foundation model capabilities through careful prompt engineering, they cannot parametrically improve from experience. Their self-improvement is limited to non-parametric memory editing. K2-Agent introduces a hybrid approach: non-parametric SRLR for declarative knowledge evolution combined with parametric C-GRPO for procedural skill acquisition.
vs. Monolithic Learning-Based Agents: Approaches like UI-TARS and UI-Venus train single policies that handle both planning and execution. This conflation forces a single update rule on fundamentally different knowledge types. K2-Agent’s explicit decoupling enables more targeted, data-efficient learning for both.
vs. Existing Hierarchies: Recent work increasingly separates reasoning from action or adopts planner-executor hierarchies. However, most maintain identical training paradigms for both layers — either both training-free or both trained with standard SFT/RL. K2-Agent’s key distinction is matching know-what and know-how to their natural update rules: explicit symbolic refinement for declarative knowledge, implicit parametric practice for procedural skills.
Implications and Future Directions
K2-Agent’s architectural principles suggest broader implications for agent design:
Cognitive Plausibility: By grounding the architecture in established cognitive neuroscience — the declarative/procedural distinction supported by distinct neural circuits — the framework achieves human-like learning efficiency. Single-demonstration bootstrapping and curriculum-guided skill acquisition mirror how humans learn complex tasks.
Resource Efficiency: The minimal data requirements (one demonstration per task) and modest computational footprint (single server training) demonstrate that architectural innovation can substitute for scale. This is particularly important for democratizing capable agent systems.
Generalization as Evidence: The dual generalization results — declarative knowledge across models, procedural skills across benchmarks — provide strong evidence that the framework captures fundamental principles rather than dataset-specific optimizations.
Several directions for future work emerge:
- Multi-Modal Extension: Extending the framework to handle audio, haptic, and other modalities beyond vision and text.
- Lifelong Learning: Enabling continuous knowledge accumulation across diverse tasks without catastrophic forgetting.
- Human-Agent Collaboration: Leveraging the explicit declarative knowledge base for interpretable human oversight and intervention.
- Theoretical Analysis: Formal characterization of the co-evolution dynamics and convergence properties.
What This Work Actually Means
The central achievement of K2-Agent is not merely a technical performance improvement, but a conceptual reorientation of how intelligent agents should structure their learning. By explicitly modeling the cognitive distinction between declarative and procedural knowledge — and providing appropriate mechanisms for each to evolve — the framework achieves both human-like learning efficiency and robust generalization.
The SRLR loop demonstrates that explicit, symbolic knowledge can be effectively maintained and refined through reflection, even in the context of neural foundation models. This challenges the assumption that end-to-end differentiable learning is always optimal, suggesting instead a hybrid architecture where different knowledge types receive appropriate treatment.
The C-GRPO algorithm shows that curriculum design — specifically, adaptive demonstration injection and error-decoupled experience balancing — can dramatically improve exploration efficiency in vast action spaces. The procedural skills acquired through this process are not merely memorized trajectories but fundamental visual-grounding capabilities that transfer across platforms.
Perhaps most significantly, the closed-loop co-evolution demonstrates that planning and execution can productively shape each other’s development. Improved planning provides structure for execution learning; improved execution enables more reliable feedback for knowledge refinement. This synergy suggests that the dichotomy between “thinking” and “acting” in AI systems may be artificial — what matters is ensuring each operates at the appropriate level of abstraction with appropriate learning mechanisms.
For practitioners, K2-Agent provides a blueprint for building capable mobile control agents without massive data collection or computational resources. The hierarchical design naturally separates concerns: task experts can maintain declarative knowledge bases, while ML engineers optimize procedural skill acquisition. The dual generalization properties provide confidence that investments in either component will yield returns across deployment contexts.
As mobile AI becomes increasingly central to human-computer interaction, the ability to efficiently teach agents complex multi-step tasks — and to trust that they will generalize appropriately — becomes critical. K2-Agent suggests that looking to cognitive science for architectural inspiration may be more productive than simply scaling existing approaches. The human mind’s separation of know-what and know-how, evolved over millennia, may offer a blueprint for artificial minds as well.
The hardware of cognition, it turns out, may be as important as the software.
Conceptual Framework Implementation (Python)
The implementation below illustrates the core mechanisms of K2-Agent: the SRLR loop for declarative knowledge evolution, the C-GRPO algorithm for procedural skill acquisition, and the closed-loop co-evolution system. This educational code demonstrates the key architectural concepts described in the paper.
# ─────────────────────────────────────────────────────────────────────────────
# K2-Agent: Co-Evolving Know-What and Know-How for Hierarchical Mobile Control
# Wu, Mo, Lu, Xing et al. · ICLR 2026
# Conceptual implementation of SRLR loop and C-GRPO components
# ─────────────────────────────────────────────────────────────────────────────
import torch
import torch.nn as nn
import torch.nn.functional as F
from typing import List, Dict, Tuple, Optional
from dataclasses import dataclass
from enum import Enum
import numpy as np
# ─── Section 1: Declarative Knowledge Representation ─────────────────────────
class KnowledgeType(Enum):
"""Types of declarative knowledge extracted from demonstrations."""
STEP_ORDERING = "step_ordering"
UI_LAYOUT = "ui_layout"
PARAMETER_CONSTRAINT = "parameter_constraint"
RECOVERY_STRATEGY = "recovery_strategy"
@dataclass
class KnowledgeItem:
"""Single item in the declarative knowledge base."""
knowledge_type: KnowledgeType
description: str
priority: int = 0 # For highlighting critical constraints
verified: bool = False
class DeclarativeKnowledgeBase:
"""
Maintains explicit, language-based task knowledge.
Evolves through SRLR loop iterations.
"""
def __init__(self):
self.items: List[KnowledgeItem] = []
self.revision_history: List[Dict] = []
def summarize_from_demonstration(self,
trajectory: List[Dict],
task_goal: str,
vlm_model) -> None:
"""
Stage 1 of SRLR: Initialize knowledge from single demonstration.
Args:
trajectory: List of (state, action, instruction) tuples
task_goal: Natural language task description
vlm_model: Vision-language model for distillation
"""
# Use VLM to extract structured knowledge from trajectory
prompt = self._construct_summarize_prompt(trajectory, task_goal)
distilled = vlm_model.generate(prompt)
# Parse into structured knowledge items
self.items = self._parse_knowledge(distilled)
self.revision_history.append({
"stage": "summarize",
"item_count": len(self.items)
})
def reflect(self,
executed_trajectory: List[Dict],
success: bool,
vlm_model) -> Optional[str]:
"""
Stage 2 of SRLR: Analyze execution for deviations.
Returns:
failure_explanation: Root cause analysis if failed, None if success
"""
if success:
# Mark verified items
for item in self.items:
item.verified = True
return None
# Task-level reflection: identify root cause
prompt = self._construct_reflect_prompt(executed_trajectory)
failure_explanation = vlm_model.generate(prompt)
# Step-level reflection: verify each action outcome
for i, step in enumerate(executed_trajectory):
expected = self._get_expected_outcome(i)
actual = step['outcome']
if not self._verify_outcome(expected, actual):
self.revision_history.append({
"stage": "reflect",
"step": i,
"deviation": True
})
return failure_explanation
def locate(self,
executed_trajectory: List[Dict],
failure_explanation: str,
vlm_model) -> Optional[int]:
"""
Stage 3 of SRLR: Pinpoint first failure point.
Returns:
failure_step: Index of first failed step, or None
"""
for t, step in enumerate(executed_trajectory):
if not self._verify_step(step, t, vlm_model):
self.revision_history.append({
"stage": "locate",
"failure_step": t
})
return t
return None
def revise(self,
failure_step: int,
failure_explanation: str,
executed_trajectory: List[Dict],
vlm_model) -> None:
"""
Stage 4 of SRLR: Apply atomic edits to knowledge base.
Atomic operators: Add, Delete, Update, Highlight
"""
# Generate revision plan
prompt = self._construct_revise_prompt(
failure_step, failure_explanation, self.items
)
revision_plan = vlm_model.generate(prompt)
# Apply atomic edits
edits = self._parse_revision_plan(revision_plan)
for edit in edits:
if edit['operation'] == 'ADD':
self.items.insert(edit['position'], edit['item'])
elif edit['operation'] == 'DELETE':
del self.items[edit['index']]
elif edit['operation'] == 'UPDATE':
self.items[edit['index']].description = edit['new_description']
elif edit['operation'] == 'HIGHLIGHT':
self.items[edit['index']].priority = 1
self.revision_history.append({
"stage": "revise",
"edits_applied": len(edits)
})
def generate_subgoal(self,
current_state,
task_goal: str,
vlm_model) -> str:
"""Generate immediate sub-goal for low-level executor."""
context = self._construct_knowledge_context()
prompt = f"Task: {task_goal}\nKnowledge: {context}\nCurrent State: {current_state}\nNext sub-goal:"
return vlm_model.generate(prompt)
# ─── Section 2: Error-Decoupled Replay Buffers ───────────────────────────────
class ReplayBuffer:
"""Experience pool with error-type categorization."""
def __init__(self, buffer_type: str, capacity: int = 10000):
self.buffer_type = buffer_type # 'conventional', 'type', 'param'
self.capacity = capacity
self.buffer = []
self.error_rates = []
def add(self, sample: Dict, error_rate: float) -> None:
"""Add sample with associated error rate."""
self.buffer.append(sample)
self.error_rates.append(error_rate)
if len(self.buffer) > self.capacity:
self.buffer.pop(0)
self.error_rates.pop(0)
def sample(self, batch_size: int) -> List[Dict]:
"""Sample batch from buffer."""
if len(self.buffer) <= batch_size:
return self.buffer
indices = np.random.choice(len(self.buffer), batch_size, replace=False)
return [self.buffer[i] for i in indices]
class ErrorDecoupledReplayManager:
"""
Manages three replay pools for balanced sampling.
Implements error-decoupled replay balancing from C-GRPO.
"""
def __init__(self,
beta_con: float = 0.5,
beta_type: float = 0.25,
beta_param: float = 0.25):
self.buffers = {
'conventional': ReplayBuffer('conventional'),
'type': ReplayBuffer('type'),
'param': ReplayBuffer('param')
}
self.ratios = {
'conventional': beta_con,
'type': beta_type,
'param': beta_param
}
def assign_sample(self,
sample: Dict,
eta_type: float,
eta_param: float) -> None:
"""
Assign sample to appropriate buffer based on error rates.
Args:
sample: Training sample (state, action, reward)
eta_type: Type error rate
eta_param: Parameter error rate
"""
if eta_type > 0.1: # Threshold for type errors
self.buffers['type'].add(sample, eta_type)
elif eta_param > 0.1: # Threshold for parameter errors
self.buffers['param'].add(sample, eta_param)
else:
self.buffers['conventional'].add(sample, 0.0)
def sample_balanced_batch(self, total_batch_size: int) -> List[Dict]:
"""Construct balanced mini-batch according to preset ratios."""
batch = []
for buffer_name, ratio in self.ratios.items():
sub_batch_size = int(total_batch_size * ratio)
sub_batch = self.buffers[buffer_name].sample(sub_batch_size)
batch.extend(sub_batch)
return batch
# ─── Section 3: Dynamic Demonstration Injection ──────────────────────────────
class CurriculumScheduler:
"""
Implements dynamic demonstration injection for C-GRPO.
Schedules prefix length based on training progress and sample difficulty.
"""
def __init__(self,
max_steps: int = 1000,
temperature: float = 0.5,
full_demo_length: int = 10):
self.K_max = max_steps
self.T = temperature
self.L = full_demo_length
self.current_step = 0
def sigma(self, k: int) -> float:
"""Linear annealing scheduler."""
return max(0.0, 1.0 - k / self.K_max)
def f_gate(self, difficulty: float) -> float:
"""Difficulty-gating function."""
return np.tanh(difficulty / self.T)
def compute_injection_length(self,
sample_difficulty: float) -> int:
"""
Calculate number of expert actions to inject.
l = L * sigma(k) * f_gate(d_i)
"""
l = self.L * self.sigma(self.current_step) * self.f_gate(sample_difficulty)
return int(l)
def get_demo_prefix(self,
full_demonstration: List[Dict],
sample_difficulty: float) -> List[Dict]:
"""Extract prefix of expert actions for injection."""
length = self.compute_injection_length(sample_difficulty)
return full_demonstration[:length]
def step(self) -> None:
"""Advance training step counter."""
self.current_step += 1
# ─── Section 4: C-GRPO Training ──────────────────────────────────────────────
class CGRPOTrainer:
"""
Curriculum-Guided Group Relative Policy Optimization.
Trains low-level executor with error-decoupled replay and dynamic injection.
"""
def __init__(self,
policy_model: nn.Module,
replay_manager: ErrorDecoupledReplayManager,
curriculum_scheduler: CurriculumScheduler,
G: int = 8, # Number of rollouts per sample
epsilon_clip: float = 0.2,
kl_weight: float = 0.04):
self.policy = policy_model
self.replay_manager = replay_manager
self.scheduler = curriculum_scheduler
self.G = G
self.epsilon_clip = epsilon_clip
self.kl_weight = kl_weight
self.old_policy = None
def estimate_error_rates(self,
state,
expert_action,
device) -> Tuple[float, float]:
"""
Estimate type and parameter error rates via multiple rollouts.
Returns:
eta_type: Fraction of samples with wrong action type
eta_param: Fraction with correct type but wrong parameters
"""
type_errors = 0
param_errors = 0
with torch.no_grad():
for _ in range(self.G):
action = self.policy.sample_action(state)
# Check type match
if action['type'] != expert_action['type']:
type_errors += 1
else:
# Check parameter accuracy
coord_diff = torch.norm(
torch.tensor(action['coordinate']) -
torch.tensor(expert_action['coordinate'])
)
if coord_diff >= 10: # epsilon threshold
param_errors += 1
eta_type = type_errors / self.G
eta_param = param_errors / self.G
return eta_type, eta_param
def compute_grpo_loss(self,
batch: List[Dict],
optimizer) -> float:
"""
Compute C-GRPO objective with group-relative advantages.
J_CGRPO = E[min(r_t * A_t, clip(r_t) * A_t)]
"""
total_loss = 0.0
for sample in batch:
state = sample['state']
action = sample['action']
reward = sample['reward']
# Generate G rollouts for group-relative baseline
rollout_rewards = []
log_probs = []
for _ in range(self.G):
pred_action, log_prob = self.policy(state)
r = self._compute_reward(pred_action, action)
rollout_rewards.append(r)
log_probs.append(log_prob)
# Compute advantage as deviation from group mean
mean_reward = np.mean(rollout_rewards)
std_reward = np.std(rollout_rewards) + 1e-8
advantage = (reward - mean_reward) / std_reward
# Compute importance ratio and clipped objective
old_log_prob = self.old_policy.get_log_prob(state, action)
ratio = torch.exp(log_prob - old_log_prob)
clipped_ratio = torch.clamp(ratio,
1 - self.epsilon_clip,
1 + self.epsilon_clip)
loss = -torch.min(ratio * advantage, clipped_ratio * advantage)
total_loss += loss
optimizer.zero_grad()
total_loss.backward()
optimizer.step()
return total_loss.item()
def train_step(self, optimizer) -> float:
"""Single C-GRPO training step."""
# Sample balanced batch
batch = self.replay_manager.sample_balanced_batch(batch_size=32)
# Augment with dynamic demonstration injection
augmented_batch = []
for sample in batch:
difficulty = sample.get('eta_type', 0) + sample.get('eta_param', 0)
prefix = self.scheduler.get_demo_prefix(
sample['demonstration'], difficulty
)
sample['injected_prefix'] = prefix
augmented_batch.append(sample)
# Update policy
loss = self.compute_grpo_loss(augmented_batch, optimizer)
# Advance curriculum
self.scheduler.step()
return loss
# ─── Section 5: K2-Agent Integration ─────────────────────────────────────────
class K2Agent:
"""
Complete K2-Agent integrating high-level planner and low-level executor.
Implements closed-loop co-evolution of declarative and procedural knowledge.
"""
def __init__(self,
high_level_vlm, # Qwen-2.5-VL-72B for planner
low_level_vlm, # Qwen-2.5-VL-7B for executor
n_srlr_iterations: int = 3):
self.planner = DeclarativeKnowledgeBase()
self.high_level_vlm = high_level_vlm
self.low_level_executor = low_level_vlm
self.n_srlr = n_srlr_iterations
# Initialize C-GRPO components
self.replay_manager = ErrorDecoupledReplayManager()
self.scheduler = CurriculumScheduler()
self.trainer = CGRPOTrainer(
low_level_vlm, self.replay_manager, self.scheduler
)
def bootstrap_from_demonstration(self,
demonstration: List[Dict],
task_goal: str) -> None:
"""
Initialize agent from single demonstration.
Summarize stage of SRLR loop.
"""
self.planner.summarize_from_demonstration(
demonstration, task_goal, self.high_level_vlm
)
self.demonstration = demonstration
def execute_with_feedback(self,
task_goal: str,
environment,
max_steps: int = 50) -> Tuple[List[Dict], bool]:
"""
Execute task with closed-loop feedback.
Returns:
trajectory: Executed steps
success: Whether task completed successfully
"""
trajectory = []
state = environment.reset()
for step in range(max_steps):
# High-level planner generates sub-goal
subgoal = self.planner.generate_subgoal(
state, task_goal, self.high_level_vlm
)
# Low-level executor performs action
action = self.low_level_executor.predict(state, subgoal)
# Execute in environment
next_state, reward, done, info = environment.step(action)
trajectory.append({
'state': state,
'subgoal': subgoal,
'action': action,
'reward': reward,
'next_state': next_state
})
if done:
return trajectory, True
state = next_state
return trajectory, False
def srlr_iteration(self,
trajectory: List[Dict],
success: bool,
task_goal: str) -> None:
"""
Run one SRLR iteration to refine declarative knowledge.
"""
# Reflect
failure_exp = self.planner.reflect(
trajectory, success, self.high_level_vlm
)
if not success and failure_exp:
# Locate
failure_step = self.planner.locate(
trajectory, failure_exp, self.high_level_vlm
)
# Revise
if failure_step is not None:
self.planner.revise(
failure_step, failure_exp, trajectory, self.high_level_vlm
)
def co_evolve(self,
task_goal: str,
environment,
n_cycles: int = 10) -> None:
"""
Run closed-loop co-evolution.
Pattern: (SRLR_H)^n -> C-GRPO_L
"""
for cycle in range(n_cycles):
print(f"=== Co-evolution Cycle {cycle + 1}/{n_cycles} ===")
# Phase 1: SRLR iterations on high-level planner
for i in range(self.n_srlr):
trajectory, success = self.execute_with_feedback(
task_goal, environment
)
self.srlr_iteration(trajectory, success, task_goal)
if success:
print(f" Task succeeded at SRLR iteration {i+1}")
break
# Phase 2: C-GRPO training on low-level executor
print(" Training low-level executor with C-GRPO...")
# Collect experiences and train...
def evaluate(self, task_goal: str, environment) -> bool:
"""Evaluate agent on task."""
trajectory, success = self.execute_with_feedback(task_goal, environment)
return success
# ─── Section 6: Demonstration ────────────────────────────────────────────────
if __name__ == "__main__":
"""
Demonstration of K2-Agent framework.
Shows initialization, co-evolution, and evaluation.
"""
print("=" * 70)
print("K2-Agent: Co-Evolving Know-What and Know-How")
print("ICLR 2026 - Wu, Mo, Lu, Xing et al.")
print("=" * 70)
# Configuration
TASK_GOAL = "Create a new contact with name 'John' and phone '1234567890'"
# Mock VLM models (replace with actual Qwen-2.5-VL implementations)
class MockVLM:
def generate(self, prompt: str) -> str:
return "Mock response"
def sample_action(self, state):
return {'type': 'click', 'coordinate': [100, 200]}
def predict(self, state, subgoal):
return {'type': 'click', 'coordinate': [100, 200]}
def get_log_prob(self, state, action):
return torch.tensor(0.0)
# Initialize agent
print("\n[1] Initializing K2-Agent...")
high_level_vlm = MockVLM() # Qwen-2.5-VL-72B
low_level_vlm = MockVLM() # Qwen-2.5-VL-7B
agent = K2Agent(high_level_vlm, low_level_vlm, n_srlr_iterations=3)
# Mock demonstration
demonstration = [
{'instruction': 'Swipe up to open app drawer',
'action': {'type': 'swipe', 'coordinate': [500, 1500]}},
{'instruction': 'Tap Contacts app',
'action': {'type': 'click', 'coordinate': [300, 800]}},
{'instruction': 'Tap add contact button',
'action': {'type': 'click', 'coordinate': [900, 400]}},
]
# Bootstrap from single demonstration
print("[2] Bootstrapping from single demonstration...")
agent.bootstrap_from_demonstration(demonstration, TASK_GOAL)
print(f" Knowledge base initialized with {len(agent.planner.items)} items")
# Mock environment
class MockEnvironment:
def reset(self):
return "initial_screen"
def step(self, action):
return "next_screen", 0.5, False, {}
env = MockEnvironment()
# Run co-evolution
print("\n[3] Running co-evolution...")
# agent.co_evolve(TASK_GOAL, env, n_cycles=5)
# Show architecture summary
print("\n[4] K2-Agent Architecture Summary:")
print(" High-Level Planner (π_H):")
print(" - Model: Qwen-2.5-VL-72B (training-free)")
print(" - Knowledge: Declarative, symbolic, self-evolving via SRLR")
print(" - Input: Task goal + current state")
print(" - Output: Sub-goals for executor")
print(" Low-Level Executor (π_L):")
print(" - Model: Qwen-2.5-VL-7B (trainable)")
print(" - Knowledge: Procedural, parametric, learned via C-GRPO")
print(" - Input: Observation + sub-goal")
print(" - Output: Atomic UI actions (click, swipe, type)")
print(" Co-Evolution: Closed-loop feedback between layers")
print("\n" + "=" * 70)
print("K2-Agent enables human-like cognitive architecture for")
print("mobile device control through co-evolution of know-what and know-how.")
print("=" * 70)
Access the Paper and Resources
The full K2-Agent framework details and experimental protocols are available in the ICLR 2026 proceedings. Implementation resources and extended evaluations will be made available by the authors.
Wu, Z., Mo, D., Lu, H., Xing, J., Liu, J., Jing, Y., Li, K., Shao, K., Hao, J., & Shi, Y. (2026). K2-Agent: Co-Evolving Know-What and Know-How for Hierarchical Mobile Device Control. In Proceedings of the International Conference on Learning Representations (ICLR ’26).
This article is an independent editorial analysis of peer-reviewed research presented at ICLR 2026. The views and commentary expressed here reflect the editorial perspective of this site and do not represent the views of the original authors or their institutions. Code implementations are provided for educational purposes to illustrate the technical concepts described in the paper. Always refer to the original publication for authoritative details and official implementations.
Explore More on AI Agent Research
If this analysis sparked your interest, here is more of what we cover across the site — from foundational tutorials to the latest research breakthroughs in agent systems, hierarchical learning, and trustworthy AI.