AgentDropoutV2: Teaching Multi-Agent Systems to Self-Correct Through Test-Time Rectify-or-Reject Pruning
A novel test-time framework that intercepts and iteratively rectifies erroneous agent outputs using retrieval-augmented adversarial indicators, achieving 6.3% accuracy improvement on mathematical reasoning benchmarks without model retraining.
Multi-agent systems have demonstrated remarkable capabilities in complex reasoning tasks, from software development to scientific discovery. Yet these systems harbor a critical vulnerability: the cascading propagation of errors. When one agent generates hallucinated or incorrect information, that corruption flows downstream through the entire agent network, compounding until the final output bears little resemblance to reality. Current solutions rely on rigid structural engineering—pre-determining which agents can communicate—or expensive fine-tuning on failure trajectories, sacrificing the very adaptability that makes multi-agent architectures powerful.
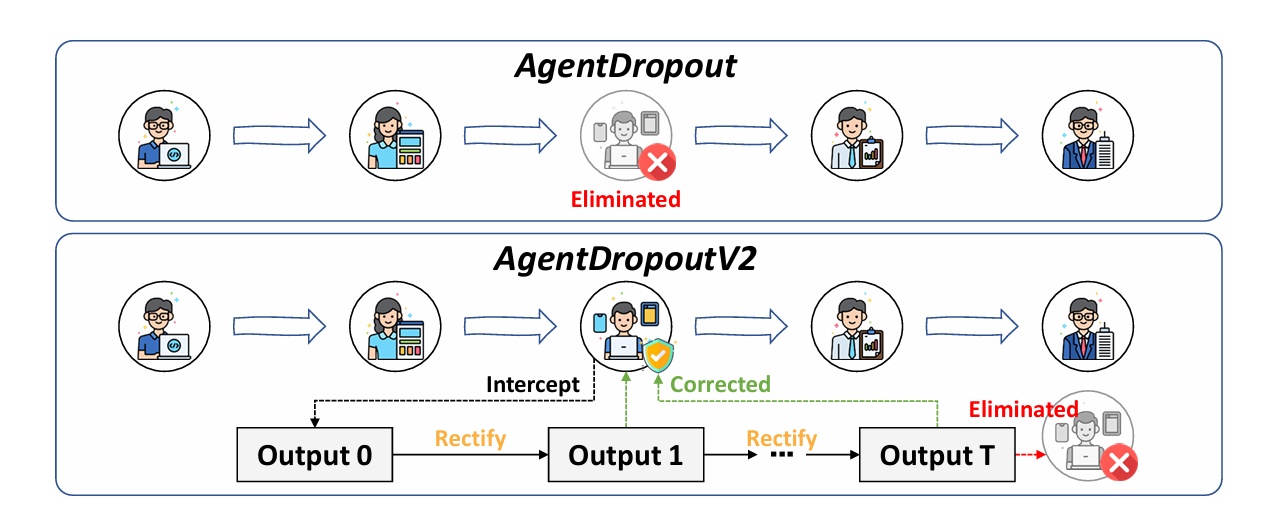
Researchers from Harbin Institute of Technology and Alibaba Group propose a fundamental reimagining of how we safeguard multi-agent information flow. Their framework, AgentDropoutV2, operates as an active firewall that intercepts agent outputs during execution, subjects them to adversarial scrutiny using retrieved failure patterns, and either rectifies errors through iterative refinement or rejects irreparable outputs entirely. Unlike static approaches that permanently prune “problematic” agents, this test-time methodology attempts rehabilitation before elimination, preserving potentially valuable contributions while strictly preventing error propagation.
What distinguishes this work is its explicit handling of the quality of error detection and the dynamic nature of rectification. Rather than applying generic verification logic, AgentDropoutV2 constructs a structured indicator pool by mining historical failure trajectories—distilling specific error patterns into retrievable knowledge. During inference, context-aware indicators are dynamically retrieved based on semantic similarity to the current task scenario, enabling precise error identification. The result is a 6.3 percentage point average accuracy gain across nine mathematical benchmarks, with particular strength on complex Olympiad-level problems where error propagation is most devastating.
The Error Propagation Crisis: Why Multi-Agent Systems Fail
The architectural premise of multi-agent systems is compelling: distribute complex reasoning across specialized agents, each contributing expertise to a collective solution. Frameworks like AutoGen enable dynamic agent selection and transparent communication, creating emergent capabilities exceeding any single model. Yet this same connectivity creates systemic fragility. A single agent’s hallucination—misinterpreting a mathematical constraint, generating non-existent citations, or proposing logically inconsistent steps—propagates through the network, contaminating downstream reasoning.
This vulnerability manifests acutely in mathematical reasoning. When an early agent miscalculates an intermediate result, subsequent agents build upon this corrupted foundation, producing elaborate derivations that are confidently wrong. The problem is not merely individual agent error rates but the structural amplification of these errors through information flow topology. Current mitigation strategies fall into two inadequate categories:
Structural optimization approaches attempt to constrain error pathways by engineering robust communication topologies—optimizing directed acyclic graphs or introducing sparse connectivity. These methods enforce static connectivity graphs derived from training statistics, permanently excluding certain agents without attempting to rehabilitate their outputs. The rigidity prevents dynamic adaptation: an agent that fails on one problem type might excel on another, yet structural methods cannot distinguish these contexts.
Parameter internalization methods fine-tune agents on failure trajectories or utilize process-supervision data to enhance intrinsic reasoning. While effective, these approaches require expensive retraining and frozen weights that cannot adapt to novel error patterns encountered during deployment. They internalize past failures but remain blind to future ones, lacking the test-time adaptivity that distinguishes robust intelligent systems.
AgentDropoutV2 addresses these limitations through test-time rectify-or-reject pruning—actively intercepting and iteratively correcting agent outputs using retrieved adversarial indicators—combined with failure-driven indicator pool construction that transforms historical mistakes into structured prior knowledge for precise error identification.
The practical manifestation is an intervention layer that operates between agent generation and information propagation. Each output undergoes multi-round rectification guided by specific, verifiable error patterns. If correction succeeds within a budget of iterations, the refined output flows downstream; if errors persist, the output is pruned entirely, acting as a semantic circuit breaker. This transforms error handling from a structural constraint into an active, intelligent process.
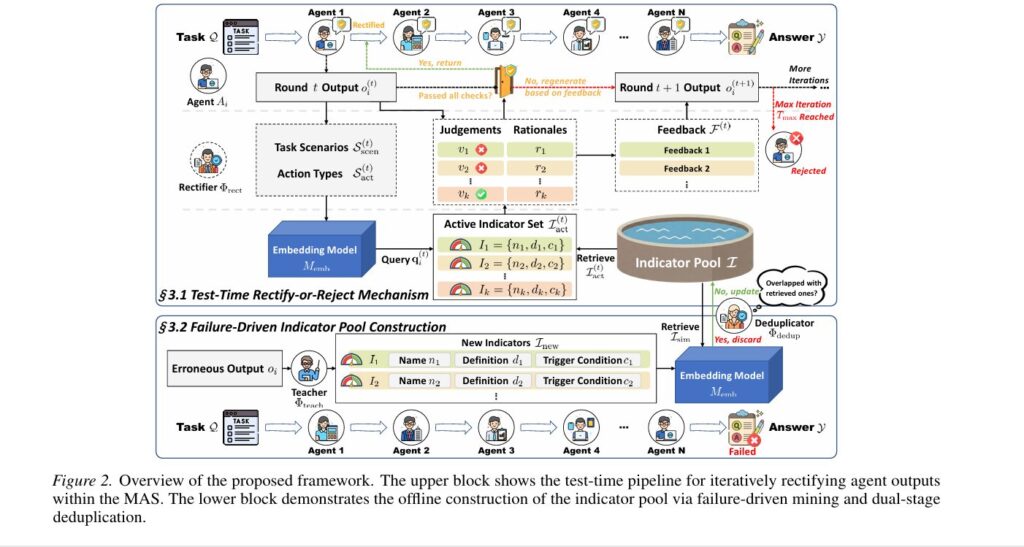
Test-Time Rectify-or-Reject Mechanism: Active Error Interception
The core insight of AgentDropoutV2’s rectification module is that effective error correction requires specific, actionable feedback rather than generic “check your work” prompts. Blindly prompting an agent to self-correct often proves counterproductive; without direction on what went wrong, agents may introduce new hallucinations or simply rephrase original errors. The framework formalizes this through a tri-state gating mechanism driven by adversarial indicator evaluation.
For an active agent \(A_i\) producing output \(o_i^{(t)}\) at iteration \(t\), the rectifier first extracts semantic keywords summarizing the task scenario \(\mathcal{S}_{\text{scen}}^{(t)}\) (e.g., geometric coordinates, algebraic operations) and specific action types \(\mathcal{S}_{\text{act}}^{(t)}\) proposed by the agent. These form a query vector:
From the pre-constructed indicator pool \(\mathcal{I}\), the system retrieves the top-\(K_{\text{act}}\) most relevant indicators based on trigger condition similarity:
Each retrieved indicator \(I_k = (n_k, d_k, c_k)\) comprises a name, error definition, and trigger condition. The rectifier evaluates the output against each indicator, generating binary violation flags \(v_k^{(t)} \in \{0,1\}\) and diagnostic rationales \(r_k^{(t)}\). A strict zero-tolerance policy activates the global error state if any indicator detects violation:
The tri-state gating mechanism then determines the trajectory:
- Pass (\(E^{(t)} = 0\)): Output accepted immediately, \(o_i = o_i^{(t)}\)
- Retry (\(E^{(t)} = 1, t < T_{\max}\)): Regenerate with feedback, \(o_i^{(t+1)} = \Phi_i(x_i, \mathcal{R}_i, \mathcal{K}_i, \mathcal{F}^{(t)})\)
- Reject (\(E^{(T_{\max})} = 1\)): Discard output, \(o_i = \emptyset\) (semantic circuit breaker)
This formulation ensures that outputs reaching downstream agents have either passed rigorous multi-indicator verification or been eliminated entirely, preventing error propagation while maximizing the salvage rate of correctable mistakes.
“Unlike rigid structural designs, our approach serves as a model-agnostic, plug-and-play module adaptable to diverse frameworks. We advance error monitoring from passive detection to active rectification, ensuring real-time stability via feedback-driven reflection.” — Wang et al., arXiv:2602.23258v1
Failure-Driven Indicator Pool: Learning from Historical Mistakes
While the rectification mechanism provides the means to correct errors, the indicator pool provides the necessary guidance to accurately pinpoint issues. AgentDropoutV2 constructs this pool through systematic mining of failed multi-agent trajectories, transforming raw execution failures into structured, retrievable knowledge.
The construction process operates on a source dataset \(\mathcal{D}_{\text{src}} = \{\mathcal{Q}, \mathcal{Y}^*\}\) of queries and ground-truth answers. For each instance, the system conducts full MAS inference to obtain trajectories \(\mathcal{T} = (\mathcal{Q}, A_{1:N}, o_{1:N}, \mathcal{Y})\). Failed cases where \(\mathcal{Y} \neq \mathcal{Y}^*\) are collected into \(\mathcal{D}_{\text{fail}}\). A teacher model \(\Phi_{\text{teach}}\) then scrutinizes individual agent outputs:
Each generated indicator captures a specific error pattern with structured fields: a unique name \(n\), detailed definition \(d\) describing the erroneous behavior, and trigger condition \(c\) specifying when the error likely occurs. This structure enables precise, context-aware retrieval during test-time operation.
To prevent repository bloating from redundant error patterns, a dual-stage deduplication process ensures pool diversity. For each candidate indicator \(I_{\text{new}}\), the system computes semantic vector \(\mathbf{v}_{\text{new}} = M_{\text{emb}}(d_{\text{new}} \oplus c_{\text{new}})\) and retrieves similar existing indicators \(\mathcal{I}_{\text{sim}}\). A deduplication model \(\Phi_{\text{dedup}}\) verifies novelty:
This compact, high-entropy pool ensures that retrieved top-\(K\) indicators cover diverse error dimensions rather than clustering around similar failure modes. The result is comprehensive safety checking without overwhelming the rectifier with redundant constraints.
Global Fallback and Structural Integrity
While aggressive pruning ensures information purity, excessive filtering risks structural collapse—analogous to the “critical mass” principle in collaborative dynamics. If remaining message counts fall below safety threshold \(\gamma\), the system loses reasoning integrity. AgentDropoutV2 addresses this through a global fallback mechanism.
When valid output count \(N_{\text{valid}} = |\{o \in \mathcal{O} \mid o \neq \emptyset\}| < \gamma\), the framework triggers a system-wide reset, discarding current progress and re-initializing execution from scratch with fresh agents. This guarantees that final solutions emerge from sufficiently robust consensus rather than fragmented, sparse reasoning. The threshold \(\gamma\) is typically set to 1, ensuring at least one valid message propagates through each critical pathway.
For zero-shot scenarios where domain-specific training data is unavailable, the framework provides a universal fallback: initializing \(\mathcal{I}_{\text{act}}\) with a general indicator \(I_{\text{gen}} = (\text{“General Logic Check”}, d_{\text{gen}}, c_{\text{gen}})\) that prompts logical consistency and hallucination detection. This ensures rectify-or-reject pruning remains functional even without prior failure pattern mining.
The global fallback mechanism ensures that structural integrity is preserved even under aggressive pruning, preventing the system from forcing conclusions from sparse, degraded contexts. Combined with zero-shot general indicators, this makes AgentDropoutV2 deployable across diverse domains without extensive pre-training.
Experimental Validation: Robustness Across Complexity Levels
AgentDropoutV2 is evaluated on nine mathematical reasoning benchmarks spanning diverse difficulty levels, from elementary GSM8K to Olympiad-level AIME problems. The framework integrates with AutoGen’s SelectorGroupChat architecture using GPT-4.1-mini for routing and Qwen3-8B/Qwen3-4B for agent reasoning.
Overall Performance: Consistent Gains Across Difficulty Spectrum
Compared to single-agent baselines and standard AutoGen configurations, AgentDropoutV2 demonstrates substantial improvements:
| System | GSM8K | MATH-500 | AQuA | AMC23 | OlymB | AIME24 | AIME25 | Average |
|---|---|---|---|---|---|---|---|---|
| Single Agent | 87.64 | 74.80 | 84.19 | 62.50 | 47.56 | 13.33 | 20.00 | 47.34 |
| AutoGen (Baseline) | 91.36 | 76.80 | 85.03 | 62.50 | 48.89 | 26.67 | 13.33 | 48.95 |
| w/ Generic Indicators | 90.52 | 77.40 | 84.98 | 72.50 | 50.37 | 33.33 | 23.33 | 52.16 |
| w/ Retrieved Indicators | 91.74 | 78.40 | 87.01 | 75.00 | 51.11 | 40.00 | 30.00 | 55.25 |
Table 1: Performance comparison across mathematical benchmarks. AgentDropoutV2 with retrieved indicators achieves 6.3 percentage point average improvement over AutoGen baseline, with particularly strong gains on complex tasks (AIME24/25).
Ablation Studies: Isolating Component Contributions
Systematic ablation reveals the necessity of each architectural choice:
Impact of rectification iterations: Setting \(T_{\max} = 0\) (no rectification) causes sharp performance drops, especially on complex tasks like AIME24 (23.33% vs. 40.00%), confirming that initial outputs often contain errors requiring active correction. However, \(T_{\max} = 4\) yields no further gains over \(T_{\max} = 3\), suggesting over-correction risks.
Retrieval mechanism sensitivity: Replacing retrieved indicators with random sampling degrades performance to 50.21%—below even the zero-iteration baseline. This proves that semantic relevance is strictly necessary for locating specific error patterns; random constraints distract rather than aid reasoning.
Pool deduplication necessity: Removing dual-stage deduplication causes average accuracy decrease, as retrieved indicators become dominated by redundant variations of similar error patterns, crowding out diverse constraints needed for comprehensive evaluation.
Iteration Dynamics: Adaptive Resource Allocation
Analysis of rectification depth reveals strong correlation with task complexity. Simple datasets (GSM8K) exhibit 60.1% first-pass acceptance, while complex tasks (AIME24/25) require multiple rounds with rejection rates exceeding 60%. This demonstrates dynamic modulation of intervention intensity—conserving resources on simple queries while allocating sustained effort to challenging scenarios.
This correlation enables AgentDropoutV2 to function as a potential task difficulty evaluator, where aggregate rectification depth and rejection rate serve as quantifiable proxies for dataset complexity.
Cross-Model Transferability and Domain Generalization
Beyond raw performance, AgentDropoutV2 demonstrates remarkable transferability. When the indicator pool constructed using Qwen3-8B is directly applied to Qwen3-4B (a smaller model), robust gains persist across most benchmarks. This “build once, deploy anywhere” paradigm enables capable models to construct offline knowledge bases that effectively supervise resource-constrained edge models without redundant mining.
Extension to code generation—testing on MBPP, HumanEval, CodeContests, and LiveCodeBench—yields consistent improvements (48.65% vs. 46.44% for AutoGen), with pronounced gains on complex benchmarks like CodeContests (6.06% → 9.26%). This confirms that adversarial rectification principles generalize beyond mathematics to any domain requiring rigorous logical consistency.
Implications and Future Directions
AgentDropoutV2’s architectural principles suggest broader implications for reliable AI system design:
Test-time optimization as default. The substantial gains from test-time intervention—without any model retraining—suggest that deployment-time computation can substitute for training-time optimization. Future systems may allocate increasing compute budgets to inference-time verification rather than scaling model parameters.
Failure-driven knowledge construction. The transformation of execution failures into structured, retrievable indicators provides a template for continual learning in deployed systems. Rather than discarding failed trajectories, systems can mine them for adversarial knowledge, creating self-improving safety mechanisms.
Dynamic difficulty evaluation. The observed correlation between rectification depth and task complexity suggests that similar mechanisms could automatically assess problem difficulty, enabling adaptive resource allocation in educational systems or automated theorem proving.
Several directions for future work emerge:
- Theoretical analysis: Formal guarantees on error propagation bounds and convergence properties under rectification.
- Multi-modal extension: Applying adversarial rectification to vision-language agents where errors span modalities.
- Hierarchical indicator pools: Structured taxonomies of error patterns enabling more efficient retrieval and composition.
- Active indicator learning: Online refinement of the indicator pool based on deployment feedback, creating truly self-improving systems.
What This Work Actually Means
The central achievement of AgentDropoutV2 is demonstrating that error handling in multi-agent systems need not be a binary choice between rigid structural constraints and expensive retraining. By intervening at test time with context-aware, adversarial verification, the framework achieves substantial robustness gains while preserving the adaptability that makes multi-agent architectures valuable.
The failure-driven indicator pool shows that historical mistakes, properly structured, become assets rather than liabilities. Each failed trajectory contributes to a growing handbook of prohibitions that guides future reasoning away from known pitfalls. This transforms error analysis from diagnostic hindsight into predictive foresight.
The rectify-or-reject mechanism embodies a philosophy of optimistic verification: assume agents are correct until evidence proves otherwise, but verify rigorously and without mercy. The tri-state gating—pass, retry, reject—creates a graduated response that maximizes information salvage while maintaining strict quality standards. This balances the trade-off between robustness and utility that plagues simpler approaches.
For practitioners, AgentDropoutV2 provides a deployable framework that integrates with existing MAS infrastructure (specifically AutoGen) without architectural overhaul. The 6.3% accuracy improvements translate directly to reliability gains in production systems—fewer cascading failures, higher user trust, more consistent performance across task types.
As multi-agent systems become increasingly central to complex reasoning tasks—from scientific discovery to software engineering—their vulnerability to error propagation becomes a critical bottleneck. AgentDropoutV2 suggests that the path forward lies not in preventing all errors (an impossible goal) but in detecting and containing them before they cascade. The best defense against systemic failure, it turns out, is to teach the system to recognize and correct its own vulnerabilities—at the very moment they appear.
The errors, it turns out, can be filtered—but only by a system that has learned to recognize their specific signatures.
Conceptual Framework Implementation (Python)
The implementation below illustrates the core mechanisms of AgentDropoutV2: failure-driven indicator pool construction, semantic retrieval, tri-state rectification gating, and global fallback protection. This educational code demonstrates the key architectural concepts described in the paper.
# ─────────────────────────────────────────────────────────────────────────────
# AgentDropoutV2: Test-Time Rectify-or-Reject Pruning for Multi-Agent Systems
# Wang, Xiong, Liu, et al. · arXiv:2602.23258v1 [cs.AI] 2026
# Conceptual implementation of retrieval-augmented rectification
# ─────────────────────────────────────────────────────────────────────────────
import torch
import torch.nn as nn
import torch.nn.functional as F
from typing import List, Tuple, Optional, Dict
from dataclasses import dataclass
from enum import Enum
# ─── Section 1: Data Structures ─────────────────────────────────────────────
class RectificationState(Enum):
"""Tri-state gating outcomes for rectify-or-reject pruning"""
PASS = "pass" # Output accepted, propagate to successors
RETRY = "retry" # Errors detected, regenerate with feedback
REJECT = "reject" # Max iterations exceeded, discard output
@dataclass
class Indicator:
"""
Structured error pattern from failure-driven mining.
name: Unique identifier (e.g., "INTEGER_CONDITION_MISMANAGEMENT")
definition: Detailed description of erroneous behavior
trigger_condition: Context where error likely occurs
"""
name: str
definition: str
trigger_condition: str
def to_embedding(self, embed_model) -> torch.Tensor:
"""Compute semantic vector for retrieval matching"""
text = self.definition + " " + self.trigger_condition
return embed_model.encode(text)
# ─── Section 2: Failure-Driven Indicator Pool Construction ───────────────────
class IndicatorPoolConstructor:
"""
Mines failed MAS trajectories to construct structured indicator pool.
Implements dual-stage deduplication for high-entropy repository.
"""
def __init__(self,
teacher_model,
dedup_model,
embed_model,
K_dedup: int = 20):
self.teacher = teacher_model
self.dedup = dedup_model
self.embed = embed_model
self.K_dedup = K_dedup
self.pool: List[Indicator] = []
def mine_from_failures(self,
failed_trajectories: List[Dict],
ground_truths: List[str]) -> List[Indicator]:
"""
Algorithm 2: Failure-Driven Indicator Pool Construction.
Args:
failed_trajectories: MAS executions where final answer != ground truth
ground_truths: Correct answers for comparison
Returns:
Optimized indicator pool with redundancy eliminated
"""
for traj, gt in zip(failed_trajectories, ground_truths):
# Teacher scrutinizes each agent in failed trajectory
for agent_output, role in zip(traj['outputs'], traj['roles']):
# Generate candidate indicators
candidates = self._generate_indicators(
traj, gt, role, agent_output
)
# Dual-stage deduplication
for candidate in candidates:
if self._is_novel(candidate):
self.pool.append(candidate)
return self.pool
def _generate_indicators(self,
trajectory: Dict,
ground_truth: str,
agent_role: str,
agent_output: str) -> List[Indicator]:
"""Use teacher model to distill error patterns from failures"""
prompt = self._build_teacher_prompt(
trajectory, ground_truth, agent_role, agent_output
)
response = self.teacher.generate(prompt)
return self._parse_indicators(response)
def _is_novel(self, candidate: Indicator) -> bool:
"""
Verify indicator novelty via semantic similarity and LLM judgment.
Prevents repository bloating from redundant error patterns.
"""
if len(self.pool) == 0:
return True
# Retrieve top-K similar indicators
cand_emb = candidate.to_embedding(self.embed)
pool_embs = torch.stack([ind.to_embedding(self.embed)
for ind in self.pool])
similarities = F.cosine_similarity(cand_emb.unsqueeze(0), pool_embs)
top_k_indices = torch.topk(similarities, min(self.K_dedup, len(self.pool))).indices
similar_indicators = [self.pool[i] for i in top_k_indices]
# LLM verifies if candidate represents distinct error pattern
return self.dedup.verify_novelty(candidate, similar_indicators)
# ─── Section 3: Test-Time Rectifier ──────────────────────────────────────────
class Rectifier:
"""
Active firewall implementing rectify-or-reject pruning.
Intercepts agent outputs, retrieves indicators, evaluates violations.
"""
def __init__(self,
rectifier_model,
embed_model,
indicator_pool: List[Indicator],
K_act: int = 5,
T_max: int = 3):
self.model = rectifier_model
self.embed = embed_model
self.pool = indicator_pool
self.K_act = K_act
self.T_max = T_max
def rectify_or_reject(self,
agent_output: str,
agent_input: str,
agent_role: str,
agent: 'Agent') -> Tuple[Optional[str], RectificationState]:
"""
Algorithm 1: Test-Time Rectify-or-Reject Pruning.
Returns:
(final_output, state): Qualified output or None if rejected,
along with final state determination
"""
current_output = agent_output
for t in range(self.T_max + 1):
# Step 1: Retrieve relevant indicators
active_indicators = self._retrieve_indicators(
current_output, agent_input, agent_role
)
# Step 2: Evaluate against each indicator
violations = []
feedback = []
for indicator in active_indicators:
v_k, r_k = self._evaluate_indicator(
current_output, agent_input, agent_role, indicator
)
if v_k == 1:
violations.append(indicator.name)
feedback.append(r_k)
# Step 3: Tri-state gating decision
E_t = 1 if len(violations) > 0 else 0
if E_t == 0:
# Pass: No violations detected
return current_output, RectificationState.PASS
elif t < self.T_max:
# Retry: Regenerate with feedback
current_output = agent.regenerate(
agent_input, feedback, iteration=t+1
)
else:
# Reject: Max iterations exceeded, semantic circuit breaker
return None, RectificationState.REJECT
return None, RectificationState.REJECT
def _retrieve_indicators(self,
output: str,
task_input: str,
role: str) -> List[Indicator]:
"""
Semantic retrieval based on task scenario and action types.
Extracts keywords, computes query vector, retrieves top-K.
"""
# Extract semantic essence via rectifier model
scen, act = self._extract_keywords(output, task_input, role)
# Compute query vector
query_text = scen + " " + act
q_i = self.embed.encode(query_text)
# Retrieve top-K by cosine similarity to trigger conditions
pool_embs = torch.stack([ind.to_embedding(self.embed)
for ind in self.pool])
similarities = F.cosine_similarity(q_i.unsqueeze(0), pool_embs)
top_k = torch.topk(similarities, min(self.K_act, len(self.pool))).indices
return [self.pool[i] for i in top_k]
def _evaluate_indicator(self,
output: str,
task_input: str,
role: str,
indicator: Indicator) -> Tuple[int, str]:
"""
Generate binary violation flag and diagnostic rationale.
Returns (1, rationale) if violation detected, (0, "N/A") otherwise.
"""
prompt = self._build_rectifier_prompt(
output, task_input, role, indicator
)
response = self.model.generate(prompt)
# Parse JSON response for violation flag and rationale
parsed = self._parse_evaluation(response)
return parsed['is_flawed'], parsed['suggestion']
# ─── Section 4: Multi-Agent System Integration ───────────────────────────────
class AgentDropoutV2:
"""
Complete MAS framework with rectify-or-reject pruning integration.
Implements global fallback against structural degeneration.
"""
def __init__(self,
agents: List['Agent'],
rectifier: Rectifier,
gamma: int = 1):
self.agents = agents
self.rectifier = rectifier
self.gamma = gamma # Safety threshold for valid message count
def execute(self, task: str) -> str:
"""
Execute MAS workflow with active error interception.
Implements global fallback if structural integrity compromised.
"""
valid_outputs = []
for agent in self.agents:
# Agent generates initial output
raw_output = agent.generate(task)
# Rectify-or-reject pruning
qualified_output, state = self.rectifier.rectify_or_reject(
raw_output, task, agent.role, agent
)
# Track valid outputs
if qualified_output is not None:
valid_outputs.append(qualified_output)
self._propagate_to_successors(agent, qualified_output)
# Global fallback check
if len(valid_outputs) < self.gamma:
return self._global_fallback(task)
# Final answer from terminal agent
return self.agents[-1].generate_final_answer(task)
def _global_fallback(self, task: str) -> str:
"""
Trigger system-wide reset when message count below safety threshold.
Guarantees solutions emerge from robust consensus, not sparse fragments.
"""
# Re-initialize with fresh agents
for agent in self.agents:
agent.reset()
# Re-execute from scratch
return self.execute(task)
def _propagate_to_successors(self, agent: 'Agent', output: str):
">Update knowledge bases of successor agents"""
for successor in agent.successors:
successor.knowledge_base.append({
'role': agent.role,
'output': output
})
# ─── Section 5: Demonstration ────────────────────────────────────────────────
if __name__ == "__main__":
"""
Demonstration of AgentDropoutV2 training and inference pipeline.
Shows indicator pool construction, test-time rectification, and MAS execution.
"""
print("=" * 70)
print("AgentDropoutV2: Test-Time Rectify-or-Reject Pruning")
print("arXiv:2602.23258v1 [cs.AI] 2026")
print("=" * 70)
# Phase 1: Offline Indicator Pool Construction
print("\n[1] Constructing failure-driven indicator pool...")
# Simulate failed trajectories from training data
failed_trajs = [
{
'outputs': ['Let n be positive integer...', 'Final answer: 10'],
'roles': ['Math Solver', 'Verifier'],
'final_answer': '10'
}
]
ground_truths = ['11'] # Correct answer includes n=0
# Initialize constructor (models would be loaded here)
constructor = IndicatorPoolConstructor(
teacher_model=None, # GPT-4o or similar
dedup_model=None,
embed_model=None # Qwen3-Embedding-8B
)
# Mine indicators from failures
# In practice, this generates indicators like:
# - "INTEGER_CONDITION_MISMANAGEMENT": Excludes zero from valid integers
# - "SQUARE_ROOT_MANIPULATION_CHECK": Violates non-negativity constraints
indicator_pool = [] # Populated by constructor.mine_from_failures()
print(f" Pool size: {len(indicator_pool)} indicators")
print(" Example: INTEGER_CONDITION_MISMANAGEMENT")
print(" Definition: Excludes valid integer values (e.g., zero) from solution sets")
print(" Trigger: When agent defines integer ranges for equation solutions")
# Phase 2: Test-Time Execution with Rectification
print("\n[2] Initializing AgentDropoutV2 framework...")
# Create rectifier with constructed pool
rectifier = Rectifier(
rectifier_model=None, # Qwen3-8B with thinking disabled
embed_model=None,
indicator_pool=indicator_pool,
K_act=5, # Retrieve top-5 relevant indicators
T_max=3 # Max 3 rectification iterations
)
# Initialize MAS
mas = AgentDropoutV2(
agents=[], # Would contain AutoGen SelectorGroupChat agents
rectifier=rectifier,
gamma=1 # Safety threshold for valid messages
)
# Phase 3: Example Rectification Trajectory
print("\n[3] Simulating rectification on math problem...")
print(" Task: For how many real x is sqrt(120 - sqrt(x)) an integer?")
print(" Ground truth: 11 (n ∈ {0,1,...,10})")
print("\n Round 0 (Initial):")
print(" Agent output: 'n ∈ {1,...,10}, answer = 10'")
print(" Retrieved indicators: [INTEGER_CONDITION_MISMANAGEMENT, ...]")
print(" Evaluation: FAILED - excludes n=0")
print(" Feedback: 'Allow n to be zero, sqrt(...) can be zero and still be integer'")
print("\n Round 1 (Retry):")
print(" Agent output: 'n ∈ {-10,...,10}, answer = 21'")
print(" Retrieved indicators: [SQUARE_ROOT_MANIPULATION_CHECK, ...]")
print(" Evaluation: FAILED - includes negative integers")
print(" Feedback: 'Restrict n to non-negative integers, sqrt yields non-negative results'")
print("\n Round 2 (Retry):")
print(" Agent output: 'n ∈ {0,1,...,10}, answer = 11'")
print(" Retrieved indicators: [all checks pass]")
print(" Evaluation: PASSED - no violations detected")
print(" State: PASS - propagating to downstream agents")
# Architecture Summary
print("\n[4] AgentDropoutV2 Architecture Summary:")
print(" Base Framework: AutoGen SelectorGroupChat")
print(" Backbone Models: Qwen3-8B/Qwen3-4B (reasoning), GPT-4.1-mini (routing)")
print(" Rectification Component:")
print(" - Indicator Retrieval: Semantic similarity (K_act=5)")
print(" - Evaluation: Binary violation detection with rationale generation")
print(" - Gating: Tri-state (Pass/Retry/Reject), T_max=3 iterations")
print(" Pool Construction:")
print(" - Mining: Teacher model analysis of failed trajectories")
print(" - Deduplication: Dual-stage semantic + LLM novelty verification")
print(" Safety: Global fallback at gamma=1 valid message threshold")
print("\n" + "=" * 70)
print("AgentDropoutV2 enhances MAS reliability through test-time")
print("adversarial rectification and failure-driven indicator retrieval.")
print("=" * 70)
Access the Paper and Resources
The full AgentDropoutV2 framework details and experimental protocols are available on arXiv. Implementation resources and code will be released by the authors.
Wang, Y., Xiong, S., Liu, X., Zhou, W., Ding, L., Zhang, M., & Zhang, M. (2026). AgentDropoutV2: Optimizing information flow in multi-agent systems via test-time rectify-or-reject pruning. arXiv preprint arXiv:2602.23258.
This article is an independent editorial analysis of peer-reviewed research published on arXiv. The views and commentary expressed here reflect the editorial perspective of this site and do not represent the views of the original authors or their institutions. Code implementations are provided for educational purposes to illustrate the technical concepts described in the paper. Always refer to the original publication for authoritative details and official implementations.
Explore More on AI Security Research
If this analysis sparked your interest, here is more of what we cover across the site — from foundational tutorials to the latest research breakthroughs in secure machine learning, adversarial robustness, and trustworthy AI.
365okgame has a surprisingly good selection of live dealer games. If you’re into feeling like you’re actually at the table, give it a whirl. Good and fun at 365okgame.