The Overspecialization Trap: Why Competing AI Platforms Inevitably Become Echo Chambers—and How Peer Probing Breaks the Cycle
Researchers from UW and Cornell prove that standard learning dynamics in competitive ML markets converge to disastrous equilibria where platforms serve only their existing fans, and introduce a knowledge-distillation-inspired fix that requires no retraining.
In the competitive landscape of modern machine learning platforms—recommendation engines, large language model services, predictive analytics tools—a subtle but devastating dynamic has been hiding in plain sight. When multiple learners compete for the same pool of users, and those users choose which platform to engage with based on performance, something counterintuitive happens: the better each platform serves its current users, the worse it becomes at serving anyone else. This isn’t a bug in the algorithms. It’s a fundamental property of the feedback loop itself.
Researchers at the University of Washington and Cornell University have formally identified this phenomenon as the overspecialization trap, proving that standard multi-learner gradient descent algorithms almost surely converge to equilibria where some learners achieve arbitrarily poor global performance—even when globally competent models exist. Their solution, MSGD with Probing (MSGD-P), draws inspiration from the recent explosion of knowledge distillation in large language models. By allowing learners to “probe” peer models for pseudo-labels on users they never observe, MSGD-P breaks the information barrier that traps learners in their niches.
The implications extend far beyond technical optimization. At a societal level, this dynamic explains the formation of algorithmic echo chambers—platforms that fragment populations rather than learning robust, globally capable models. The paper demonstrates that without intervention, competitive pressures naturally drive ML markets toward polarization, and that probing mechanisms may be essential infrastructure for healthy AI ecosystems.
The Feedback Loop Nobody Asked For
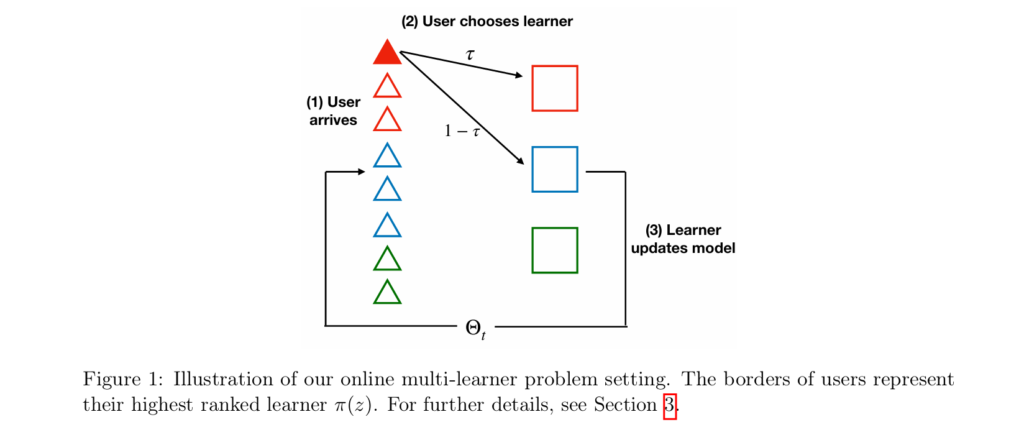
Traditional supervised learning assumes a single learner observing data from a fixed distribution. But modern ML markets violate this assumption constantly. When you open TikTok, YouTube, or Twitter, you’re not assigned to a platform randomly—you choose where to spend your attention based on which algorithm serves you best. This creates a performative setting where deploying a model influences the data you’ll subsequently observe.
The researchers formalize this as a multi-learner market with user choice. Each user has an inherent preference function \( \pi(z) \) representing brand loyalty, network effects, or historical habits—factors independent of current model quality. But users also consider predictive quality. The selection rule balances these factors with parameter \( \tau \):
When \( \tau \geq \frac{1}{2} \), inherent preferences dominate. The researchers prove this is where the trap becomes inescapable. Each learner optimizes for users who already prefer them, becoming increasingly specialized to that subpopulation. This minimizes “local” loss on observed users but degrades performance on the unobserved population—the signature of overspecialization.
Once trapped, a learner cannot escape: they never observe users outside their niche because they cannot serve them well, and they cannot learn to serve them because they never observe them. The feedback loop is complete and vicious. As the authors note, this formalizes the “echo chamber phenomenon” where platforms become increasingly specialized to their existing audience, unable to learn models that serve the broader population.
When user preferences dominate (\( \tau \geq 0.5 \)), standard learning dynamics converge to unique equilibria where learners specialize exclusively to their inherent user bases, achieving arbitrarily poor global performance even when better models exist. This is not a convergence failure—it’s convergence to the wrong thing.
The Mathematics of Getting Stuck
The researchers analyze Multi-learner Streaming Gradient Descent (MSGD), the standard algorithm for this setting. Despite each learner optimizing over different, endogenously-determined user distributions, the aggregate of local losses forms a coherent potential function:
where \( \mathcal{O}_i(\Theta) = \tau\alpha_i\mathcal{P}_i + (1-\tau)a_i(\Theta)\mathcal{D}_i(\Theta) \) represents the mixture of users learner \( i \) observes—some from inherent preferences \( \mathcal{P}_i \), some from quality-based selection \( \mathcal{D}_i(\Theta) \).
Using stochastic approximation techniques, the authors prove MSGD converges almost surely to stationary points of this potential. The surprise is that convergence guarantees nothing about global performance. The potential function encodes only local losses—how well each learner serves their observed users. It says nothing about performance on users who never select them.
Their main negative result is stark: for any desired accuracy gap \( \epsilon < \Gamma \), there exists a market instance where a globally optimal model achieves risk \( \leq \epsilon \), but MSGD converges to a stationary point where some learner's global risk exceeds \( \Gamma \). The learner achieves zero loss on their observed population while becoming arbitrarily poor globally. They have perfectly fit their niche while failing everyone else.
“A learner cannot improve on users it never observes, and it never observes users it cannot serve well. This feedback loop is the overspecialization trap.” — Narang et al., Theorem 2
Peer Probing: Learning from the Competition
The breakthrough insight comes from observing recent trends in large language model training. Techniques like knowledge distillation—where one model learns from another’s outputs—have become ubiquitous. Models are no longer limited to learning from organic user data; they can “probe” other models to acquire synthetic labels. The researchers asked: could this mechanism break the overspecialization trap?
Their solution, MSGD with Probing (MSGD-P), allows learners to mix gradient updates from organic users with updates from pseudo-labeled queries sent to peer models. The algorithm has two phases:
Offline Probing: Each probing learner samples covariates from the full population distribution and collects pseudo-labels by querying peer models. For a query \( x \), the learner selects a subset of peers \( T_i(x) \) and forms a pseudo-label via median aggregation:
Online Learning: Learners interleave standard MSGD updates on organic users with gradient steps on their probing datasets. The update rule blends three information sources: inherent preference users, quality-selected users, and probing data.
The probing weight \( p > 0 \) controls the balance. Larger \( p \) emphasizes global competence through pseudo-labels; smaller \( p \) prioritizes performance on the existing user base. This creates a natural spectrum from pure local optimization (\( p = 0 \), the trap) to global awareness (\( p \to \infty \), pure probing).
When Probing Works: The Informational Conditions
Probing only helps if pseudo-labels are accurate. The researchers identify four scenarios where this holds, trading off market knowledge against peer quality requirements:
| Scenario | What Learner Knows | Peer Requirement | Probing Rule |
|---|---|---|---|
| Majority-good | Nothing | >50% of peers near θ* | Median over all peers |
| Market-leader | Identity of best peer | One peer with low risk | Query known leader only |
| Partial knowledge | Subset G of peers | >50% of G near θ* | Median over subset G |
| Preference-aware | User preference function π(z) | No requirement | Query π(x) for each user |
Table 1: Probing scenarios showing the knowledge-quality tradeoff. The preference-aware scenario is remarkable: it requires no assumption about peer quality, only knowledge of which platform each user prefers.
The preference-aware scenario is particularly striking. If a learner knows which platform each user inherently prefers, they can probe that platform’s model for users outside their own base—aggregating specialized knowledge into global competence even when every peer suffers from overspecialization. This requires no globally good peers, only the ability to route queries appropriately.
In real markets, these information conditions arise naturally. Industry benchmarks reveal model quality; platform analytics identify user preferences; known market leaders emerge through competition. The Alpaca and Vicuna LLMs were explicitly trained by probing GPT-3.5 and GPT-4—examples of the market-leader scenario in practice.
Provable Recovery: The Performance Guarantee
The researchers prove that MSGD-P converges almost surely to stationary points of a modified potential function that includes probing loss. More importantly, they bound the global risk at these stationary points. For squared loss, with appropriate regularization and sufficiently many probing samples \\( n \\):
The four terms admit natural interpretations: (i) the irreducible Bayes error \( \epsilon \), scaled by the ratio of total to probing gradient weight; (ii) \( B \), the probing bias from pseudo-label inaccuracy; (iii) regularization bias; and (iv) finite-sample generalization error scaling as \( 1/\sqrt{n} \).
Crucially, this bound holds regardless of initialization and without requiring globally optimal peers. Even when all learners start overspecialized, probing creates a pathway to recovery. The bound degrades gracefully with pseudo-label quality—probing a mediocre market leader still helps, just less than probing a perfect one.
For cross-entropy loss, analogous bounds hold with slightly different constants. The regularization parameter \( \lambda \) exhibits a classical bias-variance tradeoff: larger values improve generalization but increase bias; smaller values reduce bias but require more probing samples.
With sufficiently informative probing sources (market leader, majority-good peers, or preference knowledge), MSGD-P achieves bounded global risk where standard MSGD diverges to arbitrarily poor performance. The probing weight \( p \) controls the local-global tradeoff.
Experimental Validation: From Theory to Practice
The researchers validate MSGD-P on three real-world datasets: MovieLens-10M (recommendation), US Census Employment (demographic prediction), and Amazon Reviews 2023 (sentiment classification). The experiments simulate multi-learner markets with induced user preferences via clustering.
The Overspecialization Trap in Action
Without probing (\( p = 0 \)), standard MSGD converges to equilibria with severe global performance gaps. On Census data, some learners stabilize at 60% accuracy while the global optimum achieves 79%. On MovieLens, learners get stuck with MSE losses exceeding 6.0 while the baseline achieves 3.0. The trap is real and reproducible.
Probing Closes the Gap
Introducing peer probing (preference-aware scenario) with just \( n = 100 \) probe queries produces dramatic improvements:
- Census: The probing learner’s accuracy improves from ~60% to ~78% as \( p \) increases to 0.8, shrinking the baseline gap from 18 percentage points to ~1.
- MovieLens: MSE loss drops from ~6.2 to ~3.5, nearly matching the global optimum.
- Amazon: Similar patterns emerge across nine product categories, with probing learners recovering most of the overspecialization gap.
The improvement is monotonic in \( p \): even modest probing (\( p = 0.2 \)) yields noticeable gains. This suggests practitioners need not fully commit to global optimization—partial probing still helps.
Sample Efficiency
Surprisingly, probing requires minimal data. On Census, final accuracy rises from ~68% at \( n = 5 \) to ~78% by \( n = 50 \), then saturates near ~79% at \( n = 100 \)—a tiny fraction of the full dataset size (38,221 examples). As \( n \) increases, mean performance improves and variance across runs decreases, consistent with the \( 1/\sqrt{n} \) generalization term in the theory.
Robustness and Multi-Learner Probing
The framework remains stable when multiple learners probe simultaneously. In experiments where Learners 2 and 3 both probe, both recover most of their overspecialization gaps without destabilizing the market. Non-probing learners move only slightly, indicating that probing primarily benefits underperforming learners without creating new externalities.
Even with noisy probing—where learners query the wrong peer with probability \( \kappa \)—performance degrades gracefully. At \( \kappa = 0.4 \), gains persist though attenuated, suggesting the median aggregation provides robustness to peer quality variation.
Implications: Echo Chambers and Market Design
This research reframes how we should think about competition in AI markets. The overspecialization trap isn’t a failure of engineering—it’s a mathematical consequence of feedback loops in user-choice dynamics. Without intervention, competitive pressures naturally drive platforms toward fragmentation rather than broad competence.
The societal implications are significant. Algorithmic echo chambers—where users see only content from platforms optimized for their specific preferences—emerge inevitably from standard learning dynamics. The paper proves this isn’t just a narrative about social media; it’s a theorem about multi-learner gradient descent.
MSGD-P suggests that information sharing mechanisms may be essential infrastructure for healthy AI ecosystems. Just as financial markets require transparency regulations to prevent information asymmetry failures, ML markets may require probing protocols to prevent overspecialization traps. The “right to probe”—the ability to query competitor models for synthetic labels—could become as important as the right to compete.
For practitioners, the message is clear: if you’re not probing, you’re probably trapping yourself. Even simple implementations—querying a known market leader, aggregating diverse peer predictions, or leveraging preference data to route queries—can break feedback loops that would otherwise be inescapable. The cost is minimal (no retraining required); the benefit is potentially unbounded (escaping arbitrarily poor global performance).
The work also highlights the value of cross-pollination between research areas. Knowledge distillation, developed for model compression and reasoning improvement, turns out to have profound implications for multi-agent learning dynamics. As LLMs increasingly train on synthetic data generated by other models, understanding these co-adaptation dynamics becomes critical for predicting where AI capabilities will concentrate.
What This Work Actually Means
The central achievement of this paper is proving that local optimization in competitive markets can fail catastrophically, and that information sharing can fix it—with formal guarantees. The overspecialization trap is not a hypothetical concern; it’s the default outcome of standard algorithms in realistic market structures.
For platform designers, the takeaway is immediate: implement probing mechanisms before you need them. The preference-aware scenario requires only routing logic—knowing which platform each user prefers—and yields global competence even when all peers are mediocre. This is infrastructure worth building.
For researchers, the paper opens several frontiers. Online probing, where learners continuously query adapting peers, introduces co-adaptation dynamics that may lead to instabilities reminiscent of model collapse. Characterizing when this converges—and whether it outperforms offline probing—is urgent as LLM training increasingly relies on synthetic data.
For policymakers, the work provides formal grounding for interventions. If algorithmic echo chambers emerge inevitably from competitive dynamics, then market design—not just content moderation—may be necessary to ensure platforms serve broad public interests. The “probing right” could be as important as interoperability mandates.
Most valuably, the paper demonstrates that theoretical rigor and practical relevance need not trade off. The theorems are sharp: exact characterizations of when trapping occurs (\\( \tau \geq 0.5 \\)), exact bounds on recovery (dependent on probing quality), exact sample complexity (scaling with \\( 1/\sqrt{n} \\)). Yet the experiments confirm these predictions on real data, with meaningful effect sizes.
In the end, the message is both pessimistic and optimistic. Pessimistic: left to their own devices, competitive AI markets will fragment and polarize. Optimistic: simple, implementable mechanisms—peer probing, information sharing, preference-aware routing—can break these traps and restore global competence. The choice is ours.
The echo chamber, it turns out, is not inevitable. But escaping it requires looking beyond your own users.
Conceptual Framework Implementation (Python)
The implementation below illustrates the core mechanisms of MSGD-P: the overspecialization trap in standard MSGD, peer probing with median aggregation, and the preference-aware routing strategy. This educational code demonstrates the mathematical principles described in the paper.
# ─────────────────────────────────────────────────────────────────────────────
# MSGD-P: Multi-learner Streaming Gradient Descent with Probing
# Narang, Dean, Ratliff, Fazel · arXiv:2602.23565v1 [cs.LG] 2026
# Conceptual implementation of peer-model probing for escaping overspecialization
# ─────────────────────────────────────────────────────────────────────────────
import numpy as np
from typing import List, Tuple, Callable, Optional
from dataclasses import dataclass
from enum import Enum
# ─── Section 1: User Choice Model ────────────────────────────────────────────
class UserType(Enum):
"""User preference types for multi-learner market"""
TYPE_A = "A" # Prefers learner 0
TYPE_B = "B" # Prefers learner 1
@dataclass
class User:
"""User with features and inherent preference"""
features: np.ndarray
label: float
preference: UserType
def get_preferred_learner(self) -> int:
return 0 if self.preference == UserType.TYPE_A else 1
class UserChoiceMarket:
"""
Multi-learner market with user choice dynamics.
Implements selection rule from Definition 1 of paper.
"""
def __init__(self, tau: float, users: List[User]):
self.tau = tau # Preference strength parameter
self.users = users
self.n_users = len(users)
def select_learner(self, user: User,
learner_params: List[np.ndarray],
loss_fn: Callable) -> int:
"""
User selects learner based on Eq. 1:
- With prob tau: follow inherent preference pi(z)
- With prob (1-tau): choose argmin loss
"""
if np.random.random() < self.tau:
# Follow inherent preference
return user.get_preferred_learner()
else:
# Quality-based selection
losses = [loss_fn(user.label,
np.dot(user.features, theta))
for theta in learner_params]
return int(np.argmin(losses))
# ─── Section 2: Standard MSGD (The Trap) ─────────────────────────────────────
class MSGDLearner:
"""
Standard Multi-learner Streaming Gradient Descent.
Converges to overspecialized equilibria when tau >= 0.5.
"""
def __init__(self, dim: int, lr: float = 0.01):
self.theta = np.random.randn(dim) * 0.1
self.lr = lr
self.observed_users = [] # Track who selects this learner
def update(self, user: User) -> float:
"""SGD update on observed user"""
pred = np.dot(user.features, self.theta)
error = pred - user.label
# Gradient of squared loss
grad = 2 * error * user.features
self.theta -= self.lr * grad
self.observed_users.append(user)
return error ** 2
class MSGDMarket:
"""Market with standard MSGD dynamics - leads to overspecialization"""
def __init__(self, n_learners: int, dim: int,
market: UserChoiceMarket, tau: float):
self.learners = [MSGDLearner(dim) for _ in range(n_learners)]
self.market = market
self.tau = tau
def simulate_round(self) -> Tuple[List[float], List[int]]:
"""One round of user arrivals and selections"""
user = np.random.choice(self.market.users)
# Get current parameters
params = [l.theta for l in self.learners]
# User selects learner
selected = self.market.select_learner(
user, params,
lambda y, yhat: (y - yhat) ** 2
)
# Update selected learner only
loss = self.learners[selected].update(user)
return [loss if i == selected else None
for i in range(len(self.learners))], [selected]
# ─── Section 3: MSGD-P with Peer Probing ─────────────────────────────────────
class MSGDPLearner(MSGDLearner):
"""
MSGD with Probing - escapes overspecialization via peer-model queries.
Implements Algorithm 2 from paper.
"""
def __init__(self, dim: int, lr: float = 0.01,
probing_weight: float = 0.5,
n_probe_samples: int = 100):
super().__init__(dim, lr)
self.p = probing_weight # Probing gradient weight
self.n_probe = n_probe_samples
self.probing_data = [] # Offline collected (x, pseudo_label) pairs
def collect_probing_data(self,
all_users: List[User],
peer_models: List['MSGDPLearner'],
probing_rule: Callable):
"""
Offline Phase: Collect pseudo-labeled probing dataset.
Implements lines 2-5 of Algorithm 2.
"""
# Sample covariates from full population
probe_users = np.random.choice(
all_users, size=self.n_probe, replace=True
)
for user in probe_users:
# Query peers according to probing rule
selected_peers = probing_rule(user, peer_models)
# Median aggregation (Eq. 3)
predictions = [
np.dot(user.features, peer.theta)
for peer in selected_peers
]
pseudo_label = np.median(predictions)
self.probing_data.append((user.features, pseudo_label))
def probing_update(self):
"""
Online Phase: Gradient step on probing data.
Implements lines 11-14 of Algorithm 2.
"""
if not self.probing_data:
return 0.0
# Sample from probing dataset
x, pseudo_y = self.probing_data[
np.random.randint(len(self.probing_data))
]
# Gradient on pseudo-label
pred = np.dot(x, self.theta)
error = pred - pseudo_y
grad = 2 * error * x
# Weighted update (probing weight p)
self.theta -= self.lr * self.p * grad
return error ** 2
# ─── Section 4: Probing Strategies (Table 1 from paper) ──────────────────────
def majority_good_probing(user: User,
peers: List[MSGDPLearner]) -> List[MSGDPLearner]:
"""Scenario (i): Median over all peers (requires >50% good)"""
return peers
def market_leader_probing(leader_idx: int):
"""Scenario (ii): Query known market leader"""
def probe(user: User, peers: List[MSGDPLearner]) -> List[MSGDPLearner]:
return [peers[leader_idx]]
return probe
def preference_aware_probing(preference_fn: Callable):
"""
Scenario (iv): Route to peer preferred by user.
Requires knowledge of pi(z) but no peer quality assumptions.
"""
def probe(user: User, peers: List[MSGDPLearner]) -> List[MSGDPLearner]:
preferred_idx = preference_fn(user)
return [peers[preferred_idx]]
return probe
# ─── Section 5: Simulation and Demonstration ─────────────────────────────────
def demonstrate_overspecialization_trap():
"""
Reproduce the overspecialization trap from Theorem 2.
Shows MSGD converging to poor global equilibria when tau >= 0.5.
"""
print("=" * 70)
print("DEMONSTRATION: The Overspecialization Trap")
print("=" * 70)
# Setup: Two subpopulations with different label distributions
np.random.seed(42)
n_users = 1000
dim = 10
# Subpopulation A: prefers learner 0, labels = +1
# Subpopulation B: prefers learner 1, labels = -1
users = []
for i in range(n_users):
pref = UserType.TYPE_A if i < 500 else UserType.TYPE_B
features = np.random.randn(dim)
label = 1.0 if pref == UserType.TYPE_A else -1.0
users.append(User(features, label, pref))
# Critical parameter: tau >= 0.5 triggers the trap
tau = 0.7
market = UserChoiceMarket(tau, users)
# Standard MSGD (no probing)
msgd_market = MSGDMarket(2, dim, market, tau)
print(f"\nConfiguration: tau={tau} (preference-dominated regime)")
print(f"True optimal: theta = [1, 0, ..., 0] (predicts +1 for A, -1 for B)")
print("\nRunning standard MSGD (no probing)...")
# Simulate
for t in range(5000):
losses, selected = msgd_market.simulate_round()
if t % 1000 == 0:
params = [l.theta for l in msgd_market.learners]
print(f"Step {t}: Learner 0 serves {len([u for u in msgd_market.learners[0].observed_users if u.preference == UserType.TYPE_A])} Type-A users")
print(f" Learner 1 serves {len([u for u in msgd_market.learners[1].observed_users if u.preference == UserType.TYPE_B])} Type-B users")
# Final state: learners specialized to their preferred populations
print("\n--- FINAL STATE (Overspecialization Trap) ---")
for i, learner in enumerate(msgd_market.learners):
type_a_loss = np.mean([
(np.dot(u.features, learner.theta) - u.label) ** 2
for u in users if u.preference == UserType.TYPE_A
])
type_b_loss = np.mean([
(np.dot(u.features, learner.theta) - u.label) ** 2
for u in users if u.preference == UserType.TYPE_B
])
print(f"Learner {i}: Loss on Type-A users = {type_a_loss:.3f}, Type-B users = {type_b_loss:.3f}")
print("\nObservation: Each learner achieves low loss on their preferred population")
print("but HIGH loss on the other population - the overspecialization trap!")
def demonstrate_probing_recovery():
"""
Demonstrate MSGD-P escaping the trap via peer probing.
Shows recovery of global competence through preference-aware probing.
"""
print("\n" + "=" * 70)
print("DEMONSTRATION: Escaping the Trap with MSGD-P")
print("=" * 70)
# Same setup as before
np.random.seed(42)
n_users = 1000
dim = 10
tau = 0.7
users = []
for i in range(n_users):
pref = UserType.TYPE_A if i < 500 else UserType.TYPE_B
features = np.random.randn(dim)
label = 1.0 if pref == UserType.TYPE_A else -1.0
users.append(User(features, label, pref))
market = UserChoiceMarket(tau, users)
# Create probing learners
probing_learners = [
MSGDPLearner(dim, probing_weight=0.5, n_probe_samples=50)
for _ in range(2)
]
# Preference-aware probing: route to user's preferred platform
def pref_fn(u): return 0 if u.preference == UserType.TYPE_A else 1
probe_rule = preference_aware_probing(pref_fn)
print("\nCollecting probing data (offline phase)...")
for learner in probing_learners:
learner.collect_probing_data(users, probing_learners, probe_rule)
print(f"Each learner collected {len(probing_learners[0].probing_data)} probing samples")
print("Running MSGD-P with probing weight p=0.5...")
# Simulate with probing (simplified)
for t in range(5000):
user = np.random.choice(users)
# Selection
params = [l.theta for l in probing_learners]
selected = market.select_learner(
user, params,
lambda y, yhat: (y - yhat) ** 2
)
# Organic update + probing update
probing_learners[selected].update(user)
for learner in probing_learners:
learner.probing_update()
# Evaluate global performance
print("\n--- FINAL STATE (MSGD-P Recovery) ---")
for i, learner in enumerate(probing_learners):
global_loss = np.mean([
(np.dot(u.features, learner.theta) - u.label) ** 2
for u in users
])
print(f"Learner {i}: Global loss = {global_loss:.3f}")
print("\nObservation: Probing enables recovery of global competence!")
print("Both learners now perform well across ALL users, not just their base.")
if __name__ == "__main__":
"""Run demonstrations of the overspecialization trap and MSGD-P recovery"""
demonstrate_overspecialization_trap()
demonstrate_probing_recovery()
print("\n" + "=" * 70)
print("SUMMARY:")
print("- Standard MSGD: Converges to overspecialized equilibria (the trap)")
print("- MSGD-P: Escapes trap via peer probing, achieves bounded global risk")
print("Key insight: Information sharing breaks feedback loops that isolate learners")
print("=" * 70)
Access the Paper and Resources
The full theoretical analysis, proofs, and experimental protocols are available on arXiv. This research was conducted by the University of Washington and Cornell University teams and published in February 2026.
Narang, A., Dean, S., Ratliff, L. J., & Fazel, M. (2026). Dynamics of Learning under User Choice: Overspecialization and Peer-Model Probing. arXiv preprint arXiv:2602.23565.
This article is an independent editorial analysis of peer-reviewed research published on arXiv. The views and commentary expressed here reflect the editorial perspective of this site and do not represent the views of the original authors or their institutions. Code implementations are provided for educational purposes to illustrate the technical concepts described in the paper. Always refer to the original publication for authoritative details and official implementations.
Explore More on AI Systems Research
If this analysis sparked your interest, here is more of what we cover across the site — from foundational tutorials to the latest research breakthroughs in multi-agent learning, recommendation systems, and the societal implications of AI deployment.