DySL-VLA: How Researchers Finally Taught Robots to Think Fast Without Thinking Less
A team at Peking University discovered something that sounds almost too obvious once you hear it—not every robot movement deserves the same amount of brainpower. What they built around that insight cuts inference latency by 3.75× and actually makes the robot better.
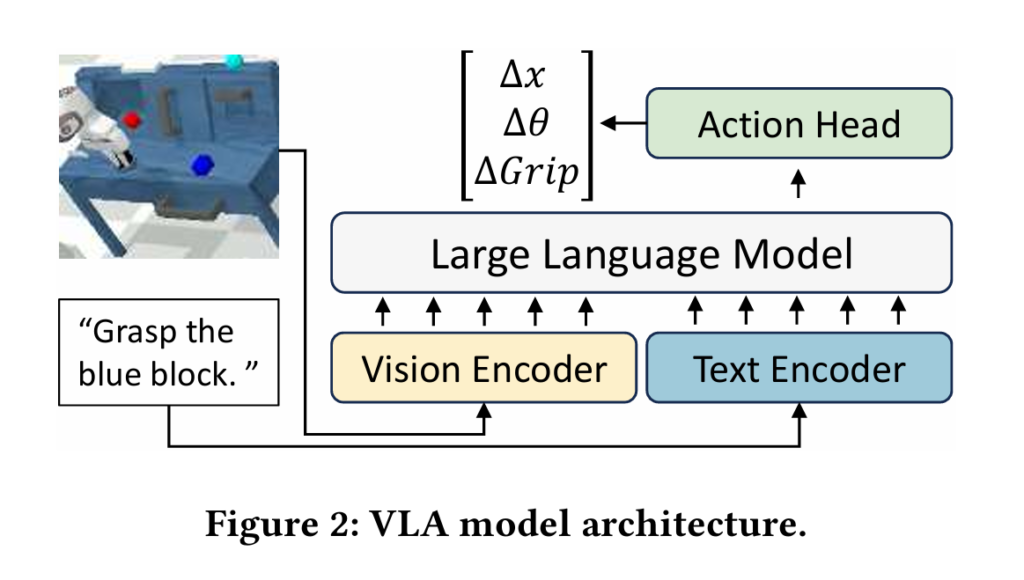
Robots are getting smarter, but the intelligence is costly. Today’s best Vision-Language-Action (VLA) models can understand a scene, follow a language instruction, and generate the next motor command—but they do it painfully slowly. RT-2 runs at 1–3 Hz. OpenVLA tops out around 5 Hz. Real-time robot control typically demands 20–50 Hz or more. The gap isn’t a little math problem; it’s the difference between a robot that works in a lab demo and one that works in the real world.
A team from Peking University’s Institute for Artificial Intelligence recently published a framework called DySL-VLA (Dynamic-Static Layer-Skipping for Vision-Language-Action models) that attacks this gap from an angle most prior work missed entirely. The key observation is disarmingly simple: not every robotic action is equally important. The moment a robot’s hand closes around an object is absolutely critical. The arm swinging through open air to get there? Much less so.
DySL-VLA exploits this asymmetry directly. By categorizing model layers into “static” ones that always run and “dynamic” ones that can be skipped, and by using trajectory continuity to guess when a critical action is coming, the framework delivers a 3.75× latency reduction over the RoboFlamingo baseline—while actually improving task success rates compared to competing acceleration methods. The entire system requires only 14 million trainable parameters and a training budget of about 7 GPU-hours.
The Problem: Uniform Computation in a Non-Uniform World
Every current VLA acceleration technique—quantization, pruning, early exit, mixture-of-layers—shares a quiet assumption: all action predictions deserve roughly the same computational resources. You compress the whole model uniformly, run it at a fixed depth, and hope the performance holds.
That assumption is wrong, and the paper proves it empirically in a striking way. The researchers injected noise of varying magnitudes into model weights at different points during a manipulation task. The result was dramatic: when noise hit during a grasping or releasing step, task completion rates cratered even at low noise magnitudes. When noise hit during pre-grasp approach movements, the robot shrugged it off. The same model, the same noise level, completely different impact depending on when in the trajectory it was applied.
This matters because existing methods waste their acceleration budget. They shave compute from actions that didn’t need full precision to begin with—but they also shave compute from the exact moments where the robot really cannot afford to make a mistake. The result is modest speedups paired with real accuracy penalties. DeeR-VLA, the strongest existing baseline, actually needs 1.2 billion trainable parameters and 112 GPU-hours of training just to recover accuracy after its early-exit compression. DySL-VLA gets better numbers with 14 million parameters and 7 GPU-hours.
The act of grasping an object is far more sensitive to model accuracy than the arm’s approach through free space. DySL-VLA is the first VLA acceleration framework built explicitly around this asymmetry—allocating full computation to critical actions and aggressively skipping on routine ones.
What DySL-VLA Actually Does: Two Types of Layers, One Smart Controller
The framework rests on a core empirical finding about VLA model internals. The team measured the average cosine similarity between the input and output activations of every layer across both a 3B and 9B parameter version of RoboFlamingo. What they found was that most layers only slightly transform the activation—the input and output look nearly identical. But a handful of layers cause the activation distribution to shift dramatically. These are the layers that actually matter.
DySL-VLA draws a hard line between these two types. Static layers are the small set of “informative” layers—identified by their low input-output cosine similarity—that always execute, no matter what. Dynamic layers are everything else: they can be skipped, but their skipping is controlled by lightweight decision mechanisms rather than left to chance.
When a dynamic layer gets skipped, the model doesn’t just drop that computation on the floor. A small adapter network—a simple feedforward layer trained to summarize what the skipped layers would have contributed—bridges the gap between the last dynamic layer and the next static layer. Because skipped layers don’t change the activation distribution much, this summarization is well within the adapter’s capacity. The end result is a model that maintains the information flow of the most critical pathway while cutting out the redundant processing that surrounds it.
Compared to early-exit methods that cut off all remaining layers past a certain depth, this approach has a crucial advantage: the informative layers scattered throughout the network are never missed. Compared to uniform layer-skipping approaches that just skip every other layer, it’s far more precise. And unlike DeeR-VLA, which retrains the full LLM backbone to compensate for accuracy loss, DySL-VLA never touches the backbone at all.
“Not all VLA layers contribute equally to action prediction. By statically keeping informative layers and dynamically skipping others, we achieve high speedup with low information loss—without retraining the LLM backbone.” — Yang, Qi, Xie et al., arXiv:2602.22896v2
The Continuity Signal: Knowing When to Be Careful
Deciding when to skip is the other half of the problem. The team tried the obvious approach first: just use a standard feedforward “skipping controller” before each dynamic layer to predict whether that layer needs to run. It didn’t work well. The controllers consistently predicted skipping for almost all actions because the training loss penalizes computation, and they had no way to distinguish the routine arm-swinging phase from the delicate grasping phase.
The breakthrough came from an observation about robot trajectory data: during non-critical motions, consecutive actions are highly similar—the robot moves at a smooth, uniform pace. The continuity of the trajectory is high. But when the robot transitions to a fine manipulation step like grasping or releasing, that continuity breaks down. Movements become hesitant, micro-corrective, disjointed.
DySL-VLA formalizes this as a trajectory continuity score:
Here, \(A_j\) is the action at step \(j\), and the score averages over the last \(k\) steps (the paper uses \(k=5\)). A less negative \(C_t\)—meaning actions are changing a lot—signals that something important may be happening soon.
This score drives a prior-post skipping guidance system with two components. The pre-skip prediction uses continuity change to move a “skipping-allow point” forward or backward through the dynamic layers. When continuity drops sharply (critical action incoming), the allow-point shifts forward rapidly, forcing more layers to execute. When continuity improves, it gradually relaxes back, enabling more skipping. An adaptive moving stride ensures the system responds faster to danger than it recovers from it—a hysteresis-like design that errs on the side of caution.
The post-skip verification handles a subtlety: because we can only detect continuity decreasing after the first critical action has already been predicted, we can’t retroactively protect that first action. So when a continuity drop is first detected, the system re-runs the inference for the current step with no skipping at all. This re-prediction ensures the initial critical action is computed at full precision, and its output is used to update the continuity estimate, improving detection for subsequent steps.
Trajectory continuity is a free, real-time signal for action importance. When adjacent actions start diverging in magnitude or direction, it’s a reliable warning that something precise and critical is about to happen. DySL-VLA uses this signal to pre-emptively allocate more computation before the critical moment arrives—not after.
Training It Efficiently: The Two-Stage Trick
Even with the framework designed, training it naively creates a chicken-and-egg problem. The adapters (which summarize skipped layers) and the controllers (which decide whether to skip) are both randomly initialized. If you train them together from scratch, the controllers start refusing to skip anything—because the untrained adapters produce garbage outputs when skipping does happen. The adapters never get meaningful training signal because skipping barely occurs. Neither component learns well.
The solution is a skip-aware two-stage knowledge distillation approach. In the first stage, skipping is forced to happen everywhere, and only the adapters are trained. Their loss function measures how well each adapter’s output approximates the result of actually running all the dynamic layers up to the next static layer:
Once the adapters can faithfully summarize their respective layer groups, the second stage trains both adapters and controllers together. Rather than letting the controllers choose freely (which still risks them collapsing to “never skip”), the training randomly selects one dynamic layer per forward pass to practice with, weighted toward earlier layers that have the hardest summarization job. This systematic coverage ensures every controller gets trained, and every adapter keeps improving.
The result is a training process that costs just 14 million parameters and 7 GPU-hours—against DeeR-VLA’s 1.2 billion parameters and 112 GPU-hours. Critically, the LLM backbone is never touched, which also means DySL-VLA preserves the generalization capabilities that make VLM-based robots useful in the first place.
Experimental Results: What 3.75× Faster Actually Looks Like
The team evaluated DySL-VLA on two standard robotic manipulation benchmarks: CALVIN (using RoboFlamingo 3B and 9B models) and LIBERO (using OpenVLA-OFT 7B). Both measure task success rate and latency independently, giving a clear picture of the accuracy-speed tradeoff.
Calvin Benchmark Results
| Method | Fine-tuned Parameters | Training (GPU hrs) | D→D Avg Length | ABC→D Avg Length | Latency (RTX 4090) |
|---|---|---|---|---|---|
| RoboFlamingo 3B (baseline) | — | — | 2.92 | 2.85 | 51.0 ms |
| DeeR-VLA 3B | 1.2B | 112 | 2.83 | 2.82 | 19.3 ms |
| FlexiDepth | 19M | 7 | 1.87 | 1.65 | 27.6 ms |
| Random Skip | — | — | 0.38 | 0.45 | 22.6 ms |
| DySL-VLA 3B | 14M | 7 | 2.89 | 2.83 | 13.6 ms |
Table 1: Calvin D→D and ABC→D evaluation. DySL-VLA matches or exceeds DeeR-VLA’s accuracy with 85.7× fewer trainable parameters and 16× less training cost, while being nearly 1.5× faster at inference.
The numbers here are striking on their own, but the context makes them remarkable. DeeR-VLA achieves its 19.3 ms latency by fine-tuning 1.2 billion parameters for 112 GPU-hours. DySL-VLA achieves 13.6 ms—faster—with 14 million parameters and 7 GPU-hours. At the same time, FlexiDepth, which uses a similar parameter budget, collapses to an average task length of 1.87 (versus 2.89 for DySL-VLA), because it skips without discriminating between important and unimportant layers.
LIBERO Benchmark Results
| Method | Fine-tuned Params | Avg SR (%) | A6000 Latency | Jetson Orin Latency |
|---|---|---|---|---|
| OpenVLA-OFT 7B (baseline) | — | 97.1 | 53.0 ms | 676 ms |
| DeeR-VLA 7B | 7.1B | 95.3 | 40.2 ms | 495 ms |
| FlexiDepth | 390M | 55.2 | 42.2 ms | 502 ms |
| DySL-VLA 7B | 226M | 96.5 | 27.4 ms | 345 ms |
Table 2: LIBERO benchmark results. DySL-VLA 7B achieves 96.5% average success rate—narrowly behind the full baseline—while running nearly 2× faster on both server-class hardware (A6000) and the Jetson Orin edge platform used in real robots.
The Jetson Orin result deserves special mention. This is the kind of compute platform that actually ships on real robots—not a data center GPU. On it, DySL-VLA runs at a latency of 345 ms per full-precision inference, but because OpenVLA-OFT uses action chunking (predicting 8 actions per inference), the effective control frequency reaches 23.2 Hz—pushing right into the real-time control range.
Ablations: Which Pieces Actually Matter?
The ablation study in the paper is refreshingly honest about what each component contributes. Every piece of DySL-VLA turns out to carry real weight.
Removing post-skip verification drops the average task length from 2.89 to 2.79—a small but consistent penalty from the occasional missed first critical action. Removing pre-skip prediction is far more damaging, dropping to 2.42, because without the continuity-based guard the controllers skip too aggressively during important transitions. Removing dynamic-static layer skipping (reverting to uniform skipping with controllers only) collapses performance to 1.87—the same as FlexiDepth—confirming that distinguishing informative from redundant layers is the core technical contribution. And removing skip-aware two-stage distillation causes a peculiar failure mode: the controllers never learn to skip at all, and average latency balloons to 74 ms, worse than the unmodified model, because the skipping infrastructure adds overhead without ever activating.
The team also explored how sensitive the framework is to the choice of static layer ratio—what fraction of layers to treat as always-on. Values between 10% and 30% all produce acceptable results, with 20% hitting the best balance. This suggests the method is robust to this hyperparameter in practice, which is good news for anyone adapting it to a new architecture.
What This Means for Robotics Research
DySL-VLA makes several points that are worth sitting with carefully, because they affect how we should think about VLA model deployment going forward.
First, it establishes that action-importance awareness is not a luxury but a necessity for VLA acceleration. FlexiDepth and similar approaches that skip layers uniformly without caring about action importance achieve 1.87 average task length versus DySL-VLA’s 2.89. That gap—roughly 55%—is entirely attributable to the framework knowing when skipping is safe and when it isn’t. Efficiency methods that ignore this will systematically underperform.
Second, the work shows that you don’t need to touch the LLM backbone. DeeR-VLA’s approach of fine-tuning 1.2 billion parameters is expensive and potentially harmful to generalization. DySL-VLA’s adapters and controllers are tiny by comparison, which means they can be trained quickly and discarded if needed without disturbing the model’s foundational capabilities. For practitioners deploying VLA models across multiple robot platforms or task domains, this is a significant practical advantage.
Third, the Jetson Orin results matter for the field. Much VLA acceleration research benchmarks only on high-end server GPUs, which obscures whether the method is actually useful for real robots. Running at 23.2 Hz effective control frequency on consumer-grade edge hardware closes an important gap between research and deployment.
Fourth, the continuity-based skipping guidance points to a broader principle: robot manipulation datasets contain implicit importance signals that haven’t been fully exploited. The training data itself encodes, through trajectory statistics, which types of actions are delicate and which are coarse. Tapping those signals for inference-time decisions—rather than just for learning action distributions—is a relatively unexplored direction.
The Bigger Picture
There’s something philosophically satisfying about DySL-VLA’s approach. It treats the robot’s own motion history as a real-time signal about what kind of cognitive effort the current moment demands—and it builds that intuition directly into the inference pipeline. The model doesn’t just predict actions; it dynamically adjusts how hard it thinks about each one.
That’s closer to how skilled humans work than most AI systems are. An experienced surgeon doesn’t apply the same level of conscious focus to repositioning their arm as they do to the next incision. A pianist doesn’t expend equal attention on every note. Expertise involves knowing when full attention is required and when it’s safe to coast on learned habits. DySL-VLA gives robots a rudimentary version of that capacity.
The 3.75× speedup is the headline number, but the more interesting result might be that the framework is better than the heavily trained DeeR-VLA baseline with a fraction of the resources. It suggests that the bottleneck in VLA deployment isn’t raw model capacity—it’s the structural mismatch between uniform computation and non-uniform task demands. Fix the structure, and the efficiency follows almost automatically.
Whether this principle generalizes beyond manipulation to navigation, dexterous grasping, or whole-body control tasks remains to be seen. But the basic argument—that not all robotic actions are equally important, and inference systems should respect that—seems durable enough to build on.
The layers were never the problem. The assumption that they all mattered equally was.
Conceptual Framework Implementation (Python)
The code below illustrates the core mechanisms of DySL-VLA: the dynamic-static layer classification, trajectory continuity computation, prior-post skipping guidance, and the two-stage knowledge distillation training loop. This is educational pseudocode capturing the paper’s architectural ideas.
# ─────────────────────────────────────────────────────────────────────────────
# DySL-VLA: Dynamic-Static Layer-Skipping for VLA Model Inference
# Yang, Qi, Xie, Yu, Liu, Li · arXiv:2602.22896v2 [cs.RO] 2026
# Conceptual implementation of core components
# ─────────────────────────────────────────────────────────────────────────────
import torch
import torch.nn as nn
import torch.nn.functional as F
from typing import List, Tuple, Optional, Deque
from collections import deque
import math
# ─── Section 1: Layer Classification ─────────────────────────────────────────
def classify_vla_layers(
model: nn.Module,
calibration_data: torch.Tensor,
static_ratio: float = 0.20
) -> Tuple[List[int], List[int]]:
"""
Identify static (informative) vs dynamic layers using cosine similarity.
A layer is 'informative' if its output activation differs significantly
from its input (low cosine similarity between input and output).
Args:
model: VLA model (LLM backbone portion)
calibration_data: Sample activations for measurement
static_ratio: Fraction of layers to designate as static (paper: 20%)
Returns:
static_layers: Indices of always-executed layers
dynamic_layers: Indices of potentially-skippable layers
"""
similarities = []
hooks = []
layer_io = {}
# Register forward hooks to capture input/output for each layer
for i, layer in enumerate(model.layers):
def make_hook(idx):
def hook(module, input, output):
inp = input[0].detach()
out = output[0].detach() if isinstance(output, tuple) else output.detach()
layer_io[idx] = (inp, out)
return hook
hooks.append(layer.register_forward_hook(make_hook(i)))
# Run calibration forward pass
with torch.no_grad():
model(calibration_data)
# Compute average cosine similarity per layer
for i in range(len(model.layers)):
inp, out = layer_io[i]
inp_flat = inp.view(inp.shape[0], -1)
out_flat = out.view(out.shape[0], -1)
cos_sim = F.cosine_similarity(inp_flat, out_flat, dim=1).mean().item()
similarities.append(cos_sim)
# Remove hooks
for h in hooks:
h.remove()
# Layers with lowest cosine similarity → most informative → static
n_static = max(1, int(len(model.layers) * static_ratio))
sorted_by_info = sorted(range(len(similarities)), key=lambda i: similarities[i])
static_layers = sorted(sorted_by_info[:n_static])
dynamic_layers = [i for i in range(len(model.layers)) if i not in static_layers]
return static_layers, dynamic_layers
# ─── Section 2: Trajectory Continuity Signal ─────────────────────────────────
class TrajectoryContinuityMonitor:
"""
Tracks trajectory continuity C_t = -(1/k) * sum_{j=t-k+1}^{t} ||A_j - A_{j-1}||_2
A value close to 0 indicates smooth, uniform motion (safe to skip).
A large negative value indicates high action variation (critical phase).
"""
def __init__(self, k: int = 5, eta: float = 1e-3):
"""
Args:
k: Trajectory window length (paper default: 5)
eta: Threshold for detecting continuity changes
"""
self.k = k
self.eta = eta
self.action_history: Deque = deque(maxlen=k + 1)
self.continuity_history: Deque = deque(maxlen=3)
def update(self, action: torch.Tensor) -> float:
"""Add new action and compute current continuity score."""
self.action_history.append(action.detach())
if len(self.action_history) < 2:
self.continuity_history.append(0.0)
return 0.0
history = list(self.action_history)
diffs = [torch.norm(history[j] - history[j - 1]).item()
for j in range(max(1, len(history) - self.k), len(history))]
C_t = -(sum(diffs) / len(diffs)) if diffs else 0.0
self.continuity_history.append(C_t)
return C_t
def continuity_change(self) -> float:
"""Return delta_C_t = C_t - C_{t-1}."""
if len(self.continuity_history) < 2:
return 0.0
hist = list(self.continuity_history)
return hist[-1] - hist[-2]
def is_critical_transition(self) -> bool:
"""
Detect first moment of continuity decrease (Eq. delta_C_t < -eta and delta_C_{t-1} > eta).
This triggers post-skip verification.
"""
if len(self.continuity_history) < 3:
return False
hist = list(self.continuity_history)
delta_t = hist[-1] - hist[-2]
delta_tm1 = hist[-2] - hist[-3]
return delta_t < -self.eta and delta_tm1 > self.eta
# ─── Section 3: Skipping-Allow Point Manager ─────────────────────────────────
class SkippingAllowPoint:
"""
Manages the skipping-allow point l_i between two adjacent static layers.
The allow point determines where between two static layers the skipping
controller becomes active. Before the point, layers are forced to execute.
Moves FORWARD (restricting more skipping) when continuity drops.
Moves BACKWARD (allowing more skipping) when continuity improves.
"""
def __init__(self, s_prev: int, s_next: int, eta: float = 1e-3):
self.s_prev = s_prev # Index of preceding static layer
self.s_next = s_next # Index of next static layer
self.eta = eta
self.l_i = s_prev + 1 # Initially allow skipping from first dynamic layer
def update(self, delta_C: float):
"""
Move allow point based on continuity change (Eq. 2 and 3 from paper).
Args:
delta_C: Change in continuity score (C_t - C_{t-1})
"""
if delta_C < -self.eta and self.l_i < self.s_next:
# Continuity dropping → move forward (less skipping)
delta_l = math.ceil(abs(delta_C) / self.eta)
self.l_i = min(self.l_i + delta_l, self.s_next)
elif delta_C > self.eta and self.l_i > self.s_prev + 1:
# Continuity improving → move backward by 1 (restore skipping gradually)
self.l_i -= 1
def layer_is_active(self, layer_idx: int) -> bool:
"""Returns True if this layer must execute (before allow point)."""
return layer_idx < self.l_i
# ─── Section 4: DySL-VLA Inference Engine ────────────────────────────────────
class DySLVLAInference:
"""
Production inference engine implementing DySL-VLA's dynamic-static
layer skipping with prior-post skipping guidance.
"""
def __init__(
self,
vla_backbone: nn.Module,
static_layers: List[int],
dynamic_layers: List[int],
adapters: nn.ModuleList,
controllers: nn.ModuleList,
eta: float = 1e-3,
k: int = 5
):
self.backbone = vla_backbone
self.static_layers = set(static_layers)
self.dynamic_layers = dynamic_layers
self.adapters = adapters
self.controllers = controllers
self.continuity = TrajectoryContinuityMonitor(k=k, eta=eta)
self.allow_points = self._init_allow_points(static_layers)
self.eta = eta
def _init_allow_points(self, static_layers: List[int]) -> List[SkippingAllowPoint]:
"""Create a SkippingAllowPoint manager between each pair of adjacent static layers."""
points = []
for i in range(len(static_layers) - 1):
points.append(SkippingAllowPoint(
s_prev=static_layers[i],
s_next=static_layers[i + 1],
eta=self.eta
))
return points
def predict_action(
self,
observation: torch.Tensor,
instruction_tokens: torch.Tensor
) -> torch.Tensor:
"""
Full inference step with dynamic-static skipping and prior-post guidance.
Args:
observation: Current image observation
instruction_tokens: Tokenized language instruction
Returns:
action: Predicted robot action
"""
# Update allow points from latest continuity reading
delta_C = self.continuity.continuity_change()
for ap in self.allow_points:
ap.update(delta_C)
# Check if post-skip verification is needed
needs_verification = self.continuity.is_critical_transition()
if needs_verification:
# Post-skip verification: re-run with ALL layers (no skipping)
action = self._run_full_model(observation, instruction_tokens)
verified_C = self.continuity.update(action)
# Recompute delta with verified action for better future estimates
delta_C_verified = self.continuity.continuity_change()
for ap in self.allow_points:
ap.update(delta_C_verified)
else:
action = self._run_with_skipping(observation, instruction_tokens)
self.continuity.update(action)
return action
def _run_with_skipping(
self,
observation: torch.Tensor,
instruction_tokens: torch.Tensor
) -> torch.Tensor:
"""Execute backbone with dynamic-static layer skipping."""
x = self.backbone.embed(observation, instruction_tokens)
i = 0
allow_point_idx = 0
while i < len(self.backbone.layers):
layer = self.backbone.layers[i]
if i in self.static_layers:
# Static layer: always execute
x = layer(x)
i += 1
allow_point_idx = min(allow_point_idx + 1, len(self.allow_points) - 1)
else:
# Dynamic layer: check if before allow point
ap = self.allow_points[min(allow_point_idx, len(self.allow_points) - 1)]
if ap.layer_is_active(i):
# Before allow point: force execution
x = layer(x)
i += 1
else:
# After allow point: consult controller
controller_idx = self.dynamic_layers.index(i)
skip_prob = self.controllers[controller_idx](x).sigmoid().item()
if skip_prob > 0.5:
# Skip to next static layer using adapter
adapter_idx = controller_idx
x = self.adapters[adapter_idx](x)
# Jump to next static layer
next_static = next((s for s in self.static_layers if s > i), i + 1)
i = next_static
else:
x = layer(x)
i += 1
return self.backbone.action_head(x)
def _run_full_model(
self,
observation: torch.Tensor,
instruction_tokens: torch.Tensor
) -> torch.Tensor:
"""Execute all layers with no skipping (for post-skip verification)."""
with torch.no_grad():
x = self.backbone.embed(observation, instruction_tokens)
for layer in self.backbone.layers:
x = layer(x)
return self.backbone.action_head(x)
# ─── Section 5: Two-Stage Knowledge Distillation ─────────────────────────────
class SkipAwareDistillation:
"""
Implements the two-stage training protocol for DySL-VLA.
Stage 1: Train adapters in isolation with forced skipping.
Stage 2: Joint adapter + controller training with harmonic layer selection.
"""
def __init__(self, model: DySLVLAInference, lambda_norm: float = 0.01):
self.model = model
self.lambda_norm = lambda_norm
def stage1_adapter_loss(
self,
x_i: torch.Tensor,
layer_idx: int,
next_static_idx: int
) -> torch.Tensor:
"""
Stage 1 loss: adapter output should match running all dynamic layers.
(Eq. 4 from paper)
"""
adapter_idx = self.model.dynamic_layers.index(layer_idx)
adapter_out = self.model.adapters[adapter_idx](x_i)
# Target: run all dynamic layers up to next static layer
target = x_i.clone()
with torch.no_grad():
for j in range(layer_idx, next_static_idx):
target = self.model.backbone.layers[j](target)
return torch.norm(adapter_out - target, p='fro')
def stage2_joint_loss(
self,
x_i: torch.Tensor,
selected_layer_idx: int,
next_static_idx: int,
task_loss: torch.Tensor
) -> torch.Tensor:
"""
Stage 2 loss: task loss + normalization loss encouraging skipping.
(Eq. 5 and 6 from paper)
"""
adapter_idx = self.model.dynamic_layers.index(selected_layer_idx)
controller_prob = self.model.controllers[adapter_idx](x_i).sigmoid()
adapter_out = self.model.adapters[adapter_idx](x_i)
# Full path: run all dynamic layers up to next static
full_path = x_i.clone()
for j in range(selected_layer_idx, next_static_idx):
full_path = self.model.backbone.layers[j](full_path)
# Soft combination (differentiable forward, Eq. 5)
x_next_static = controller_prob * adapter_out + (1 - controller_prob) * full_path
# Normalization loss: encourage controller to skip more
layers_to_skip = next_static_idx - selected_layer_idx
norm_loss = (1 - controller_prob) * layers_to_skip
return task_loss + self.lambda_norm * norm_loss.mean()
def harmonic_layer_selection(
self,
dynamic_layers_between: List[int]
) -> int:
"""
Select a dynamic layer for training using harmonic decay probability.
Earlier layers are selected more often (they summarize more layers).
"""
n = len(dynamic_layers_between)
weights = [1.0 / (i + 1) for i in range(n)] # Harmonic weights
total = sum(weights)
probs = [w / total for w in weights]
return torch.multinomial(torch.tensor(probs), 1).item()
# ─── Section 6: Demo ─────────────────────────────────────────────────────────
if __name__ == "__main__":
print("=" * 70)
print("DySL-VLA: Dynamic-Static Layer Skipping for VLA Models")
print("arXiv:2602.22896v2 [cs.RO] 2026")
print("=" * 70)
# Demonstrate trajectory continuity monitor
print("\n[1] Trajectory Continuity Monitor Demo")
monitor = TrajectoryContinuityMonitor(k=5, eta=1e-3)
# Simulate smooth approach actions (low variance)
print(" Approach phase (smooth motion):")
for t in range(8):
action = torch.tensor([0.1, 0.1, 0.02]) + torch.randn(3) * 0.001
C = monitor.update(action)
print(f" Step {t}: C_t = {C:.5f}")
# Simulate grasp onset (high variance)
print("\n Grasp phase (variable, critical):")
for t in range(4):
action = torch.tensor([0.1, 0.1, 0.02]) + torch.randn(3) * 0.05
C = monitor.update(action)
critical = monitor.is_critical_transition()
print(f" Step {t+8}: C_t = {C:.5f} → critical={critical}")
print("\n[2] Key Results Summary")
print(" Calvin D→D: DySL-VLA 2.89 vs DeeR-VLA 2.83 vs baseline 2.92")
print(" Latency: 13.6ms (DySL-VLA) vs 51.0ms (RoboFlamingo) → 3.75×")
print(" Training: 14M params, 7 GPU-hours vs DeeR-VLA 1.2B, 112 hrs")
print(" Jetson Orin: 23.2 Hz effective control frequency")
print("\n[3] Component Importance (Ablation)")
components = [
("Full DySL-VLA", 2.89, "13.6ms"),
("w/o Post-skip Verification", 2.79, "13.4ms"),
("w/o Pre-skip Prediction", 2.42, "20.1ms"),
("w/o Skip-aware KD", 2.82, "74.0ms"),
("w/o Dynamic-static Skipping", 1.87, "27.6ms"),
]
for name, avg_len, latency in components:
print(f" {name:<40s} AvgLen={avg_len} Latency={latency}")
print("\n" + "=" * 70)
print("DySL-VLA achieves efficient VLA inference by respecting the fact")
print("that not all robot actions demand the same computational attention.")
print("=" * 70)
Access the Paper and Code
The full DySL-VLA framework, training code, and evaluation scripts are available on GitHub and arXiv. The work was conducted at Peking University’s Institute for Artificial Intelligence and published in February 2026.
Yang, Z., Qi, Y., Xie, T., Yu, B., Liu, S., & Li, M. (2026). DySL-VLA: Efficient Vision-Language-Action Model Inference via Dynamic-Static Layer-Skipping for Robot Manipulation. arXiv preprint arXiv:2602.22896.
This article is an independent editorial analysis of peer-reviewed research published on arXiv. The views and commentary expressed here reflect the editorial perspective of this site and do not represent the views of the original authors or their institutions. Code implementations are provided for educational purposes to illustrate the technical concepts described in the paper. Always refer to the original publication for authoritative details and official implementations.
Explore More on AI Systems Research
If this analysis sparked your interest, here is more of what we cover across the site — from foundational tutorials to the latest research breakthroughs in efficient machine learning, robotics, and industrial AI deployment.