Segment Anything for Video: Why SAM2 Is the Most Important Architecture Shift in Object Tracking Since Transformers
A sweeping new survey from UT Southwestern and UPenn maps the full landscape of SAM/SAM2-based Video Object Segmentation and Tracking — covering how models remember the past, understand the present, and predict the future of any moving object.
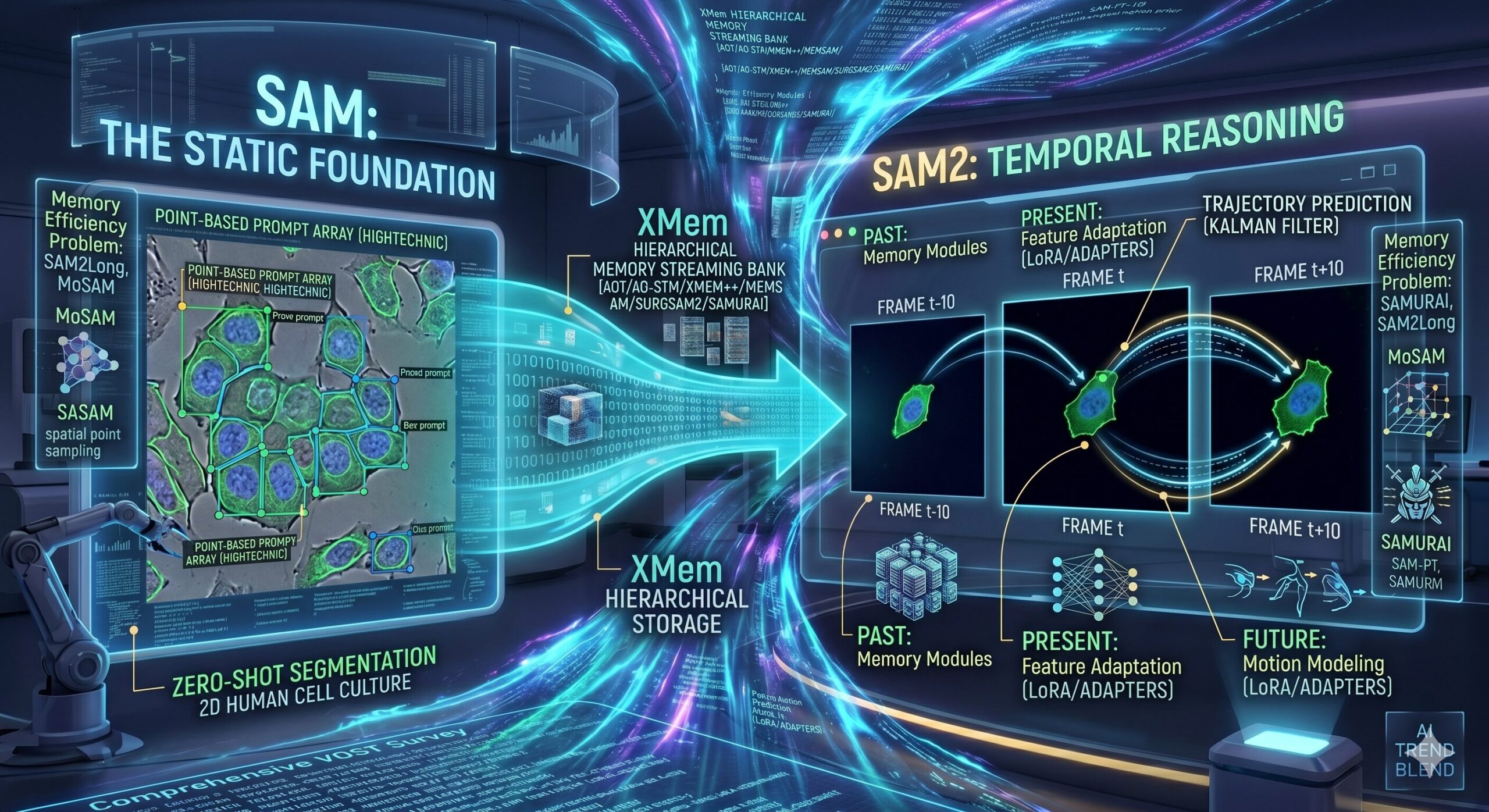
Every time a self-driving car watches a cyclist weave through traffic, every time a surgical robot tracks a scalpel blade through tissue, every time a radiologist’s software follows a tumor across MRI frames — the same fundamental problem is being solved: how do you keep pixel-perfect track of an object across time? Video Object Segmentation and Tracking (VOST) has been wrestling with this for years. The arrival of SAM2 — Meta’s streaming-memory successor to the Segment Anything Model — didn’t just move the needle. It changed what the question even looks like.
Why VOST Is Harder Than It Looks
On the surface, tracking an object in video sounds like it should be an extension of detecting it in a single image. Just run your image segmentation model on every frame, right? If only. The real challenge is everything that happens between frames: objects blur, shrink, occlude each other, deform, temporarily disappear, and come back looking slightly different. Handling all of that while maintaining consistent pixel-level identity across hundreds or thousands of frames is genuinely hard.
Traditional approaches built their way toward a solution using encoder-decoder architectures where information from previous frames — stored as features, masks, or embeddings — is fed back into the network to guide segmentation of the current frame. A landmark paper in this lineage was STM (Space-Time Memory Networks), which introduced the idea of a memory bank that stores features from all past frames alongside their predicted masks. Instead of just looking at the immediately previous frame, STM could draw on the entire history. That sounds expensive, and it was, but it also unlocked a new level of temporal coherence.
Following STM, the field produced a steady stream of refinements: STCN fixed the shared encoder design, XMem introduced hierarchical multi-timescale memory management, and various other works tackled temporal correspondence, multi-scale features, and memory overflow prevention. Each paper chipped away at specific weaknesses while the overall framework grew more capable.
Then, in 2023, Segment Anything Model (SAM) arrived and scrambled the whole conversation.
VOST requires solving two problems simultaneously: precise pixel-wise segmentation of objects in each frame, and consistent identity tracking of those objects across frames despite motion blur, occlusion, deformation, scale changes, and background confusion. Neither problem is easy alone. Together, they’re the central unsolved challenge of video understanding.
SAM Changed the Rules. SAM2 Changed the Game.
SAM was trained on over 1 billion masks across 11 million images — a dataset scale that made every previous segmentation model look like a prototype. The result was a model with genuinely remarkable zero-shot generalization: you could describe a target object using points, bounding boxes, or masks, and SAM would segment it accurately without ever having seen that specific object category before. This wasn’t just a performance improvement. It was a new paradigm: foundation model meets interactive segmentation.
The architecture behind this capability is a three-part system — a heavyweight image encoder pretrained with masked autoencoders, a lightweight prompt encoder that handles sparse and dense input types, and a mask decoder that runs cross-attention between prompt and image embeddings to produce high-resolution segmentation outputs. The design is deliberately modular, which made it easy for the broader research community to grab the image encoder and build on top of it.
But SAM had an obvious limitation: it was designed for static images. Apply it frame-by-frame to a video and you get good per-frame masks with zero temporal consistency — the model doesn’t know (or care) that the person in frame 47 is the same person it segmented in frame 23. Early work-arounds integrated SAM with external tracking modules like XMem (TAM), DeAOT (SAM-Track), and point trackers (SAM-PT). These hybrid pipelines worked, but they were awkward — two systems loosely coupled rather than one system that actually understands video.
SAM2, released in 2024, addressed this directly. It added a streaming memory mechanism — three new components called the memory encoder, memory bank, and memory attention module — that allow SAM2 to maintain a running record of what it has seen and use that history to condition its understanding of the current frame. Trained on SA-V (35.5 million masks across 50,900 videos), SAM2 is simultaneously a better image segmenter (6× faster than original SAM) and the first version of Segment Anything that actually thinks about time.
“SAM2 extends this capability to video object segmentation and tracking, offering improved inference speed while maintaining competitive segmentation accuracy — representing a paradigm shift from training task-specific models to fine-tuning a powerful pre-trained foundation model through interactive prompting.” — Xu, Udupa, Yu, Shao et al., UT Southwestern / UPenn Survey, 2025
A Framework for Thinking About VOST: Past, Present, Future
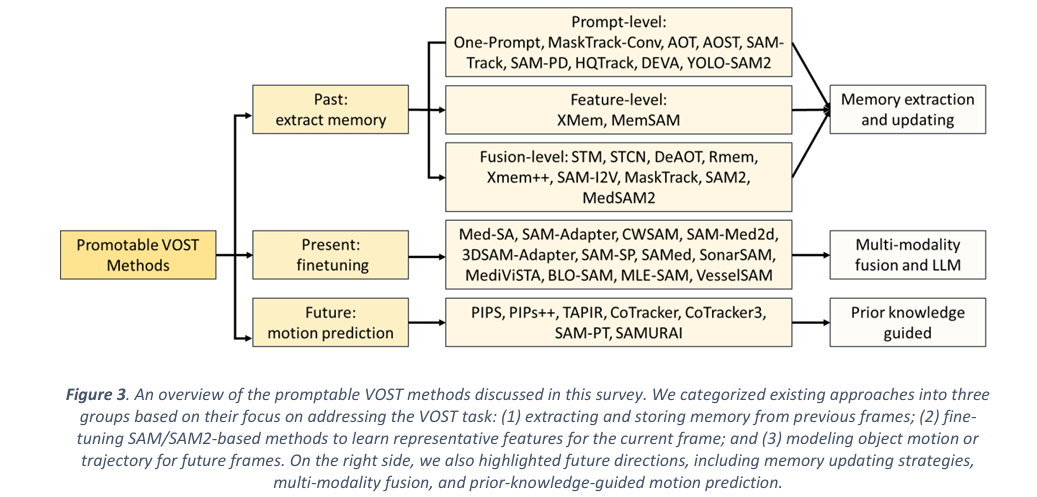
The survey structures the entire field around a beautifully simple three-part lens. Any VOST system has to handle three temporal dimensions simultaneously:
How does the model store and selectively retrieve information from previous frames? Which features are worth keeping? How do you prevent error accumulation as memory grows?
How does the model extract discriminative features from the current frame efficiently — especially when you’re adapting a foundation model to a new domain like medical imaging?
How does the model predict where objects are going next? Trajectory estimation, motion modeling, and point tracking all feed into this question.
This framework is useful precisely because it separates concerns that are often tangled together in the literature. A method might be groundbreaking in memory management while using standard feature extraction, or excellent at motion prediction while inheriting SAM2’s off-the-shelf feature encoder. Thinking in these three dimensions helps clarify what each paper actually contributes.
The Past: How Models Remember (and Forget)
Memory is the beating heart of VOST. Without it, you’re just doing image segmentation on individual frames. With good memory, you can maintain object identity through occlusions, recover after tracking failures, and leverage the full temporal context of a video sequence. The survey identifies three distinct levels at which memory can operate, each with different strengths and failure modes.
Prompt-Level Memory: Teaching the Model Where to Look
The simplest form of memory propagation passes information forward as a prompt — specifically, the predicted mask from the previous frame becomes an additional input signal to the current frame. MaskTrack ConvNet pioneered this idea: concatenate the previous mask as an extra input channel and let the network figure out how to use it. It’s elegant and surprisingly effective for short sequences where objects move predictably.
The problem is that this approach creates a fragile chain. If frame N’s mask is slightly wrong, frame N+1’s mask will be based on a flawed prompt, and the error compounds. Extended to long videos or fast-moving objects, it degrades badly. Optical flow variants (using motion fields instead of masks) partially address the temporal alignment issue but add their own failure modes when motion estimation is unreliable.
More sophisticated prompt-level methods use identification mechanisms to propagate multi-object mask embeddings across frames. AOT and AOST introduced an ID mechanism that encodes object-specific information into a Long Short-Term Transformer (LSTT) module, enabling much more robust long-term tracking because each object gets its own identity representation rather than just a binary foreground mask.
When SAM entered this space, it brought dramatically better mask quality — but temporal coherence remained the problem. SAM-Track chains SAM with GroundingDINO for text-based object specification, then hands off to DeAOT for temporal propagation. SAM-PD (Prompt Denoising) extracts bounding boxes from each prediction and passes them forward as prompts to the next frame, using multi-prompt strategies and point-based refinement to compensate for the inevitable quality drift. These are smart engineering solutions to a fundamental incompatibility between a static-image model and a temporal task.
Feature-Level Memory: Storing the Right Information
A step deeper than prompt propagation, feature-level memory approaches store intermediate representations — the actual neural network activations, not just the output masks. The landmark system here is XMem, which drew inspiration from the Atkinson-Shiffrin psychological model of human memory to organize features into three distinct timescales: a rapidly updated sensory memory for very recent frames, a high-resolution working memory for medium-term context, and a compact long-term memory for persistent object characteristics.
Managing transitions between these memory types requires careful engineering. XMem introduced a prototype selection algorithm and a memory potential mechanism that decides when working memory features are informative enough to be consolidated into long-term storage. This hierarchical design allows XMem to handle videos of arbitrary length without running out of memory or losing track of objects that temporarily disappear.
MemSAM extends this approach into the SAM era, wrapping SAM’s feature extraction with a space-time memory module that captures both spatial and temporal cues. A Memory Reinforcement module actively suppresses the propagation of noisy features — instead of blindly storing everything SAM produces, it filters for what’s genuinely useful. A Gated Recurrent Unit (GRU) handles rapid sensory memory updates. The result is a system that leverages SAM’s exceptional feature quality while adding the temporal reasoning SAM itself lacks.
Fusion-Level Memory: Bridging Image and Mask
The most sophisticated approach recognizes that image features and mask features carry complementary information that should be integrated rather than treated separately. Fusion-level methods run attention mechanisms and multi-modal fusion modules that jointly process both sources, creating richer memory representations than either alone.
Earlier works like STM and STCN incorporated previous masks directly alongside image features. Later systems like DeAOT, RMem, and XMem++ handled them in separate pipelines before merging at a later stage. SAM-I2V takes a more unified approach: it extracts image features from video frames using the original SAM, enriches them with temporal context through a temporal feature integrator, then passes the result through a memory selective associator that jointly manages both image and mask historical information. A memory prompt generator refines the output before feeding it into SAM’s segmentation pathway.
SAM2 itself represents the most tightly integrated version of this approach. Its streaming memory mechanism is baked into the architecture rather than bolted on externally — the memory encoder, memory bank, and memory attention module are designed together from the ground up to handle image-mask fusion, storage, and retrieval as a unified operation. This tight coupling is part of why SAM2 runs 6× faster than SAM-with-external-memory approaches while achieving better temporal consistency.
SAM2’s streaming memory consists of three integrated components: (1) a memory encoder that fuses current frame image features with the predicted mask, (2) a memory bank that stores these fused representations using a first-in-first-out queue, and (3) a memory attention module with L transformer blocks that uses both self-attention (to refine current features) and cross-attention (to integrate stored history) before passing to the mask decoder. This is fundamentally different from bolt-on memory modules — it’s temporal reasoning as a native capability.
The Memory Efficiency Problem: Pruning, Trees, and Spatial Selection
SAM2’s default memory design has a known weakness: it uses a fixed-size FIFO queue that discards old frames indiscriminately, regardless of how informative they were. For long videos with fast-moving or self-occluding objects, critical context can get overwritten before it’s needed. And because SAM2 treats all stored frames equally in attention, including erroneous masks from difficult frames causes error accumulation that compounds over time.
The research community has attacked this problem from multiple angles, and the solutions are creative:
SurgSAM2 introduced cosine-similarity-based frame pruning — before adding a new frame to memory, check how similar it is to what’s already stored. If it’s largely redundant, skip it. This reduces the number of stored frames while preserving diversity, which helps the memory attention module focus on actually informative temporal signals.
SAMURAI added motion awareness to the pruning decision. Rather than just measuring visual similarity, it computes three quality scores per frame — mask affinity, object occurrence score, and motion score from a Kalman Filter model — and selects memory frames based on all three. This means the system retains frames that capture important motion transitions, not just visually distinct moments. Combined with Kalman Filter motion prediction for bounding box positions, SAMURAI achieves robust zero-shot tracking without any task-specific fine-tuning.
SAM2Long takes a more radical approach: instead of a single linear memory bank, it maintains a tree structure with multiple memory pathways. For each input frame, the mask decoder generates three candidate masks conditioned on different memory branch histories. The best candidate — evaluated by cumulative quality score — is selected to continue into the next timestep. This branching allows the system to recover from segmentation errors by effectively maintaining alternative hypotheses about what has happened in the video.
MoSAM adds a spatial dimension to the pruning problem. Previous methods pruned at the temporal level (which frames to keep), but MoSAM also prunes at the spatial level — using probability segmentation maps from previous predictions to identify and discard low-confidence spatial regions within each stored frame. Only the most reliable foreground areas contribute to future segmentation decisions.
| Method | Memory Strategy | Key Innovation | Zero-Shot? |
|---|---|---|---|
| XMem | Feature-level | 3-tier Atkinson-Shiffrin memory hierarchy | No |
| MemSAM | Feature-level + SAM | Memory Reinforcement module filters noisy features | Partial |
| SAM2 (base) | Fusion-level FIFO | Streaming memory baked into architecture | Yes |
| SurgSAM2 | Pruning-based | Cosine similarity frame filtering | Yes |
| SAMURAI | Motion-aware pruning | Kalman Filter + 3-score memory selection | Yes |
| SAM2Long | Memory tree | Multi-branch constrained memory for error recovery | Yes |
| MoSAM | Spatio-temporal pruning | Spatial-level region filtering within frames | Yes |
The Present: How Models Learn to See Differently
SAM2 is a powerful generalist, but “generalist” is a double-edged sword. The same training that makes it work on natural scene videos also means it hasn’t specialized in the peculiarities of surgical video, echocardiography, MRI scans, or sonar imagery. These domains look radically different from the SA-V training data, and applying SAM2 out-of-the-box produces mediocre results.
The solution is parameter-efficient transfer learning (PETL) — methods that inject domain-specific knowledge into a frozen foundation model with a tiny number of additional trainable parameters. You keep SAM2’s enormous pretrained representations intact (they took tremendous compute to build and they generalize extremely well in the feature space) while adding small adapter modules that learn the domain-specific translation. Two approaches dominate the literature.
Adapters: Bottleneck Networks Inside Transformer Blocks
The standard Adapter design inserts a small two-layer network (MLP → nonlinearity → MLP) inside each transformer block of SAM’s image encoder. The first MLP compresses the feature dimension (reducing computational cost), the nonlinearity adds representational capacity, and the second MLP restores the original dimension. Only the adapter weights are trained; the base SAM weights stay frozen.
This surprisingly simple intervention works remarkably well. Medical SAM Adapter (Med-SA) applies adapters to both the image encoder and prompt decoder, effectively teaching SAM the vocabulary of medical imaging without forgetting its natural-image capabilities. SAM-Adapter uses the same pattern for camouflaged object segmentation, where standard SAM fails because camouflaged objects are explicitly designed to be hard to spot. CWSAM adapts this design for synthetic aperture radar (SAR) imagery, which looks almost nothing like optical photographs.
Domain-specific refinements quickly emerged. SAM-Med2D incorporated channel-wise attention into the adapter bottleneck for better local and channel-specific feature adaptation. MA-SAM and 3DSAM-Adapter introduced 3D convolutions to capture the volumetric structure of CT and MRI data — a critical upgrade since 3D medical volumes have spatial relationships across all three dimensions that 2D adapters would completely miss.
LoRA: Low-Rank Matrices as Efficient Fine-Tuning
Low-Rank Adaptation (LoRA) takes a different mathematical approach: instead of inserting new modules between existing layers, it adds pairs of small matrices in parallel with the original weight matrices. If the original weight matrix is W ∈ ℝ^(d×d), LoRA approximates the update ΔW as the product of two low-rank matrices: ΔW = BA where B ∈ ℝ^(d×r) and A ∈ ℝ^(r×d) with r ≪ d. Training only these rank-r matrices yields updates that are a fraction of the original parameter count.
SAMed, SAM-SP, SonarSAM, and MediViSTA all apply LoRA to SAM’s image encoder transformer blocks for various medical segmentation tasks. BLO-SAM applies LoRA to the mask decoder and prompt encoder instead, using a bi-level optimization strategy to prevent overfitting during semantic segmentation fine-tuning. More recently, MLE-SAM introduced a Mixture of Experts (MoE) variant within SAM2 that routes different input modalities to different LoRA experts — a neat solution to the challenge of fine-tuning a single model for multiple image types simultaneously. VesselSAM adds Atrous Spatial Pyramid Pooling inside the LoRA modules to capture multi-scale context for aortic vessel segmentation.
Adapters insert new sequential modules and are better at learning domain-specific transformations that require new computational pathways. LoRA modifies existing weight matrices in a parameter-efficient way and tends to preserve more of the original model’s capabilities. For 3D medical volumes, adapter-based approaches with 3D convolutions currently have an edge. For multi-modal tasks, LoRA-based MoE approaches are gaining traction. Both suffer from the same gap: they’ve been primarily tested on static image segmentation, and their behavior within SAM2’s streaming memory mechanism for VOST remains largely unexplored.
The Future: Predicting Where Objects Are Going
The third pillar of VOST — trajectory estimation and motion prediction — is where the field is arguably least mature. Knowing where an object is in the current frame is not the same as knowing where it will be in the next frame, especially when it’s moving fast, when it’s temporarily occluded, or when multiple similar objects are nearby and the tracker might confuse them.
Classical methods for motion estimation — optical flow and Kalman filtering — have been incorporated into deep learning pipelines since the beginning of video understanding. More recently, transformer-based point trackers like PIPs++, TAPIR, CoTracker, and CoTracker3 have demonstrated impressive performance on continuous point trajectory estimation through dynamic scenes. But these are motion-estimation tools, not segmentation tools, and combining them elegantly with SAM’s segmentation capabilities requires careful design.
SAM-PT: Points as Temporal Bridges
SAM-PT takes an elegant conceptual approach: rather than tracking masks directly, track individual points through the video and use the resulting point trajectories as dynamic prompts for SAM at each frame. The process starts by generating positive and negative query points from the first-frame annotation (indicating target and background regions), runs a point tracker (PIPS or CoTracker) to propagate these points forward across all frames, and feeds the resulting point sets and occlusion scores into SAM to generate per-frame segmentation masks. Optionally, the predicted masks can be used to reinitialize point tracking periodically.
This is a clever inversion of the usual approach: instead of tracking masks and deriving points, derive points and use them to generate masks. The weakness is the hard dependency on a separately trained, separately maintained point tracker — fine-tuning, debugging, and deploying two models is significantly more complex than one unified system.
SAMURAI: Motion as a First-Class Citizen
SAMURAI integrates motion modeling much more tightly into the SAM2 framework. Rather than treating motion as a separate module, it incorporates Kalman Filter-based bounding box prediction directly into the memory selection pipeline. When deciding which stored frames are most useful for segmenting the current frame, SAMURAI factors in motion scores alongside mask quality and object occurrence scores. Frames that capture important motion transitions get retained; frames that duplicate information already in memory get pruned.
The result is a system that simultaneously improves temporal consistency (by keeping motion-informative memory) and reduces error propagation (by pruning redundant or low-quality memory). It achieves competitive zero-shot tracking results across multiple standard benchmarks without any task-specific fine-tuning — a significant practical advantage since most real-world deployment scenarios can’t afford the time and labeled data required for task-specific training.
MOTION-AWARE TRACKING PIPELINE (SAMURAI-style)
Frame t-1 Frame t Frame t+1
│ │ │
▼ ▼ ▼
[Image Encoder] [Image Encoder]
│ │
▼ │
[Memory Encoder] │
(fuse features + mask) │
│ │
▼ │
[Memory Bank]──────────────────┤
• FIFO for recent frames │
• Scored by: ▼
- Mask Affinity [Memory Attention]
- Object Occurrence (cross-attn: current ← stored)
- Motion Score (KF) │
↓ High scorers kept ▼
↓ Low scorers pruned [Mask Decoder]
│
[Kalman Filter]────────────────┤ predicted bbox
predicts next position │
from motion history ▼
Final Mask t
Beyond Zero-Shot: Segment Any Motion in Videos
A more comprehensive approach in the survey uses two pre-trained models to generate 2D object tracks and depth maps, then runs these through a motion encoder and track decoder that decouple motion information from semantic content and filter out noise. The cleaned point prompts are fed into SAM2 to generate initial segmentation masks. Dynamic trajectories belonging to the same object are then grouped and re-fed into SAM2 for refinement. It’s a multi-pass approach that achieves high accuracy at the cost of significant computational overhead — the right trade-off for offline analysis but challenging for real-time applications.
Datasets and How to Measure Success
No survey is complete without an honest accounting of what benchmarks the field is actually optimizing for and whether those benchmarks capture what we care about. The VOST literature has a well-established set of natural scene benchmarks — SegTrack, DAVIS16/17, YouTubeVOS, MOSE — spanning short clips to long-form multi-object videos. SA-V, SAM2’s training set, adds an unprecedented scale of 4.2 million frames across 50,900 videos.
| Dataset | Videos | Frames | Key Challenge |
|---|---|---|---|
| SegTrackv2 | 14 | 976 | Early benchmark, short clips |
| DAVIS16 | 50 | 3,455 | Occlusion, fast motion, appearance change |
| DAVIS17 | 150 | 10,459 | Multi-object, complex interactions |
| LVOS-V1 | 220 | 126,280 | Long-form temporal consistency |
| LVOS-V2 | 720 | 296,401 | Scale and diversity at long form |
| YouTubeVOS | 4,453 | 120,532 | Diverse real-world objects |
| MOSE | 2,149 | — | Crowded scenes, severe occlusions |
| SA-V | 50,900 | 4,200,000 | Foundation model training scale |
Performance on these benchmarks is typically measured with the J&F score — the arithmetic mean of the Jaccard Index (IoU between predicted and ground-truth masks, measuring region overlap) and the Boundary F1 score (measuring how precisely the predicted boundary matches the ground-truth contour). J&F is now the standard composite metric for VOST because it captures both coarse localization quality (J) and fine boundary precision (F) in a single number.
Medical imaging adds its own layer of complexity. The survey covers a separate ecosystem of benchmarks spanning surgical instrument segmentation (EndoVis17/18), cardiac structure tracking (CAMUS, EchoNet-Dynamic), tumor tracking during radiotherapy (TrackRAD2025), polyp segmentation (SUN-SEG, Polyp-Gen), and cell tracking in microscopy videos. These domains impose additional metrics — Challenge IoU (CIoU) for object-centric temporal evaluation across entire videos, Dice coefficient for overlap sensitivity, and FPS for real-time viability assessment in clinical settings.
Where the Field Goes Next: Seven Honest Gaps
The survey doesn’t pretend the field is nearly done. It identifies seven specific research gaps, each worth understanding in its own right.
1. Hierarchical Memory for SAM2
SAM2’s FIFO memory is computationally convenient but theoretically limited. The natural extension — organizing memory into sensory, short-term, and long-term tiers within the SAM2 framework (the way XMem did for pre-SAM2 approaches) — hasn’t been done cleanly yet. Residual learning for memory updates, which would incrementally correct errors and focus on informative changes rather than redundantly storing similar frames, is a particularly interesting direction.
2. Language + Vision for Medical VOST
Language-guided segmentation (using text prompts like “the tumor in the upper right lobe” instead of point clicks) has started entering natural-scene VOST through SAM-Track and SAMWISE. For medical VOST, this capability could be transformative — clinicians already describe structures in language, and a system that bridges that language to pixel-level tracking would genuinely change clinical workflows. The barrier is data: there are essentially no large-scale video-and-language datasets in the medical domain. Building them is grunt work that doesn’t make for flashy papers, but it’s a precondition for meaningful progress.
3. Physics-Based Motion Priors
The best motion models in the survey (SAMURAI’s Kalman Filter) are linear first-order approximations. Real anatomical motion — cardiac cycles, respiratory dynamics, joint kinematics — has known physical structure that current models largely ignore. Incorporating periodic priors for cardiac motion, or biomechanical constraints for joint tracking, could dramatically improve both accuracy and sample efficiency in medical applications.
4. Computational Efficiency
SAM2’s image encoder (Hiera, a hierarchical vision transformer) is still heavy. At 15–30 FPS on modern GPUs, real-time deployment in resource-constrained environments — intraoperative settings, mobile devices, edge computing — requires further work. Knowledge distillation approaches (MobileSAM, EfficientSAM, RepViT-SAM) have made progress on the image segmentation side but haven’t been fully adapted for the streaming memory requirements of video tracking. Quantization, pruning, and model refactorization for SAM2-style architectures remain largely unexplored territory.
5. Clinical-Grade Medical Benchmarks
The current medical VOST benchmarks are useful but don’t reflect the full complexity of clinical deployment. Real clinical scenarios involve 2D/3D registration (e.g., fluoroscopy registered to a 3D CT scan for tumor tracking during radiotherapy), low-contrast tissue boundaries with significant noise, large 3D volumetric data, and severely limited labeled examples per patient. The CyberKnife markerless tumor tracking system demonstrates the feasibility of real-time radiotherapy tracking, but there’s no standard benchmark that would let researchers systematically evaluate and compare approaches for this class of problem. This gap actively slows clinical translation.
6. End-to-End Joint Training
Most current VOST pipelines train segmentation and tracking components separately, then combine them. This misses cross-task regularization signals — the appearance consistency constraints from tracking could regularize segmentation, and the shape constraints from segmentation could regularize tracking. BioMedParse, VisTR, and Cell-TRACTR demonstrate that joint end-to-end learning is feasible for biomedical and natural-scene applications. Extending this paradigm to SAM2-based medical VOST, where the foundation model provides strong initialization but the downstream task is highly specialized, is a natural next step.
7. Detection-Assisted Automation
Current VOST systems typically require a human to provide an initial prompt in the first frame — a click, a box, a rough mask. For population-scale screening (e.g., automatically segmenting and tracking polyps across thousands of colonoscopy videos) or for long-form clinical video where objects appear and disappear, manual initialization is a practical bottleneck. Detection-first cascades — using systems like Grounding-DINO to automatically locate candidate objects, then handing off to SAM2 for precise tracking — could close this gap and enable truly automated VOST pipelines.
Read the Full Survey
The complete paper covers all representative methods across natural and medical VOST, with detailed ablation analyses, benchmark comparisons across 10+ metrics, and architectural diagrams for every major system discussed above.
The Honest Bottom Line
SAM2 genuinely represents the most coherent architecture for VOST that the field has produced. Its streaming memory is tightly integrated rather than externally bolted on, its scale of pre-training is unprecedented, and its prompt-based interaction model makes it usable without task-specific training in most scenarios. The 6× speed improvement over the original SAM isn’t a minor optimization — it’s the difference between a research tool and a practical system.
But the survey is honest about what SAM2 doesn’t solve. Fixed FIFO memory accumulates errors over long videos. The image encoder is still too heavy for many deployment contexts. The system hasn’t been adapted systematically for 3D medical imaging. Language-guided interaction remains an open frontier. And the benchmarks the field optimizes for — particularly for clinical applications — don’t yet reflect the real complexity of the problems practitioners face.
What’s remarkable about this moment in VOST research is that the fundamental architecture problem is closer to solved than it has ever been. SAM2’s streaming memory gave researchers a common foundation to build on. The methods surveyed here — SAMURAI, SAM2Long, MoSAM, MemSAM, VesselSAM — aren’t trying to replace SAM2; they’re refining specific components of a system that has largely earned the community’s trust. That’s a different research dynamic than existed even two years ago, and it suggests the next wave of VOST breakthroughs will come from the application layer — clinical translation, domain adaptation, and efficient deployment — rather than from fundamental architecture redesign.
Xu, G., Udupa, J.K., Yu, Y., Shao, H.-C., Zhao, S., Liu, W., & Zhang, Y. (2025). Segment Anything for Video: A Comprehensive Review of Video Object Segmentation and Tracking from Past to Future. The Medical Artificial Intelligence and Automation (MAIA) Laboratory, UT Southwestern Medical Center; Medical Image Processing Group, University of Pennsylvania.
This article is an independent editorial analysis of the above peer-reviewed survey paper. All benchmark figures, architectural descriptions, and method comparisons are sourced directly from the original work. The authors’ research was supported by NIH grants R01 CA240808, R01 CA258987, R01 EB034691, and R01 CA280135.