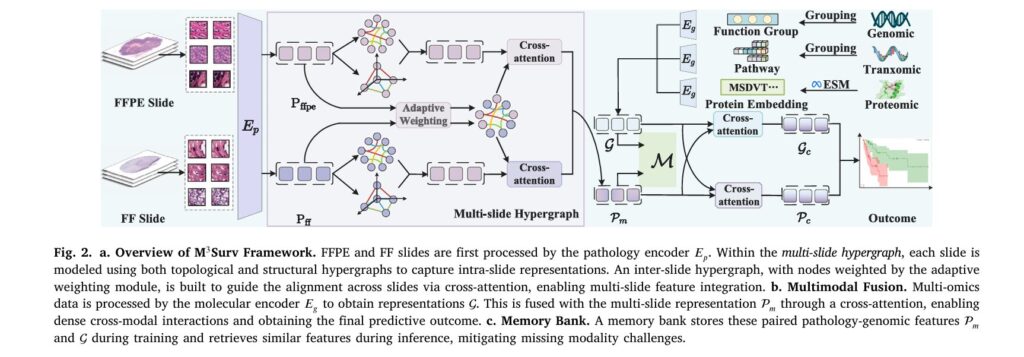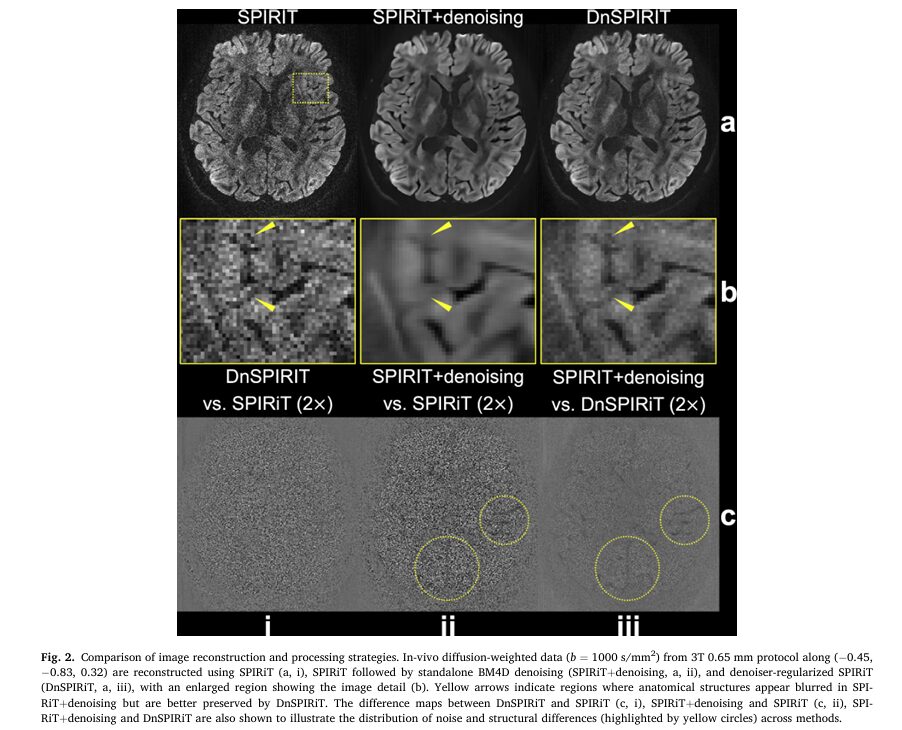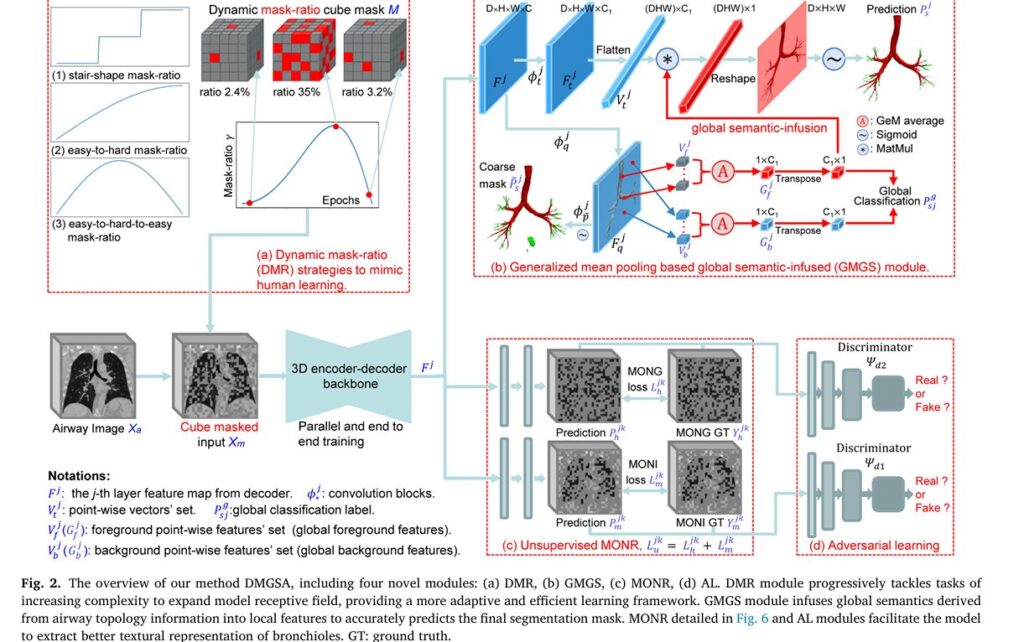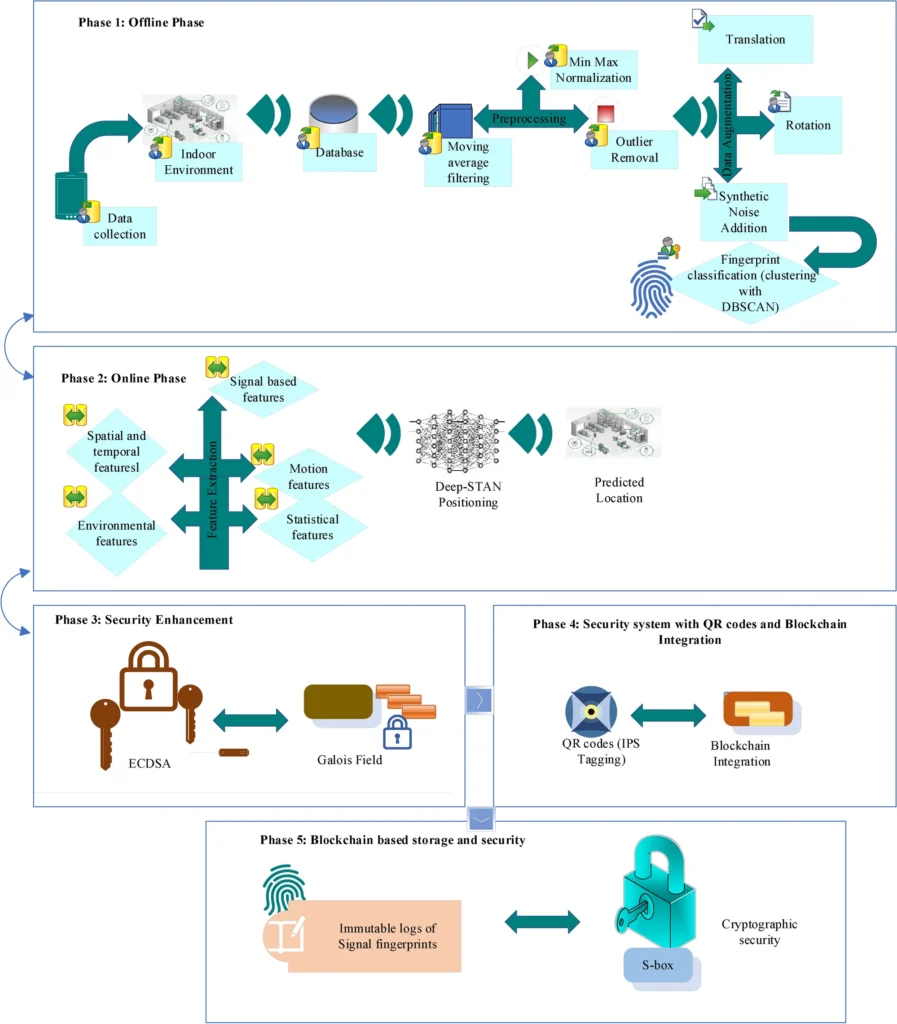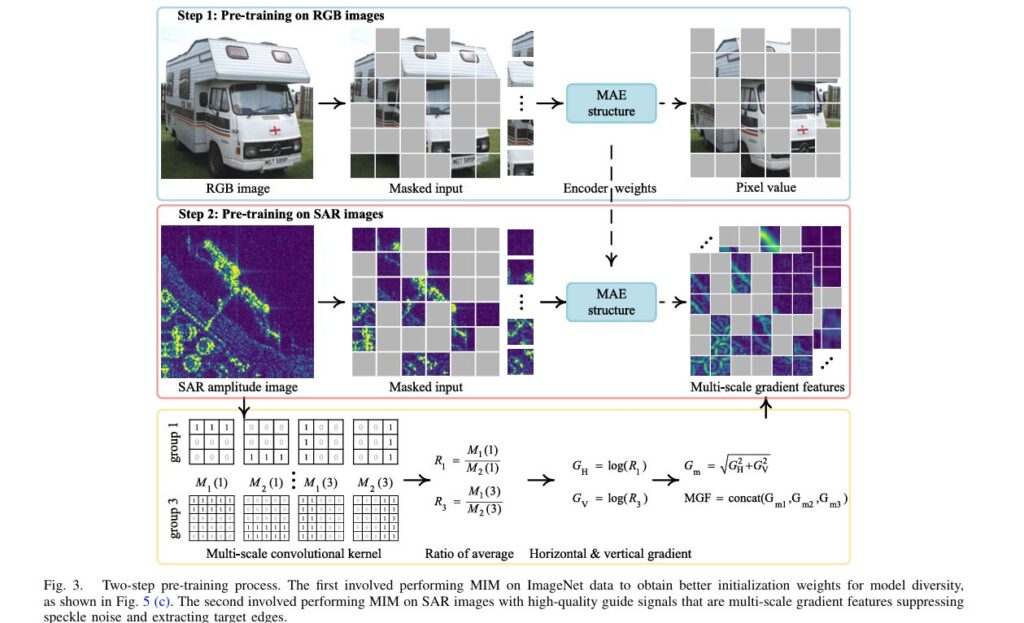
SARATR-X: Revolutionary Foundation Model Transforms SAR Target Recognition with Self-Supervised Learning
Introduction: Breaking New Ground in Radar Image Analysis Imagine a technology that can see through clouds, darkness, and adverse weather conditions to identify vehicles, ships, and aircraft with remarkable precision. This is the power of Synthetic Aperture Radar (SAR), and now, researchers have developed SARATR-X—the first foundation model specifically designed to revolutionize how machines understand […]