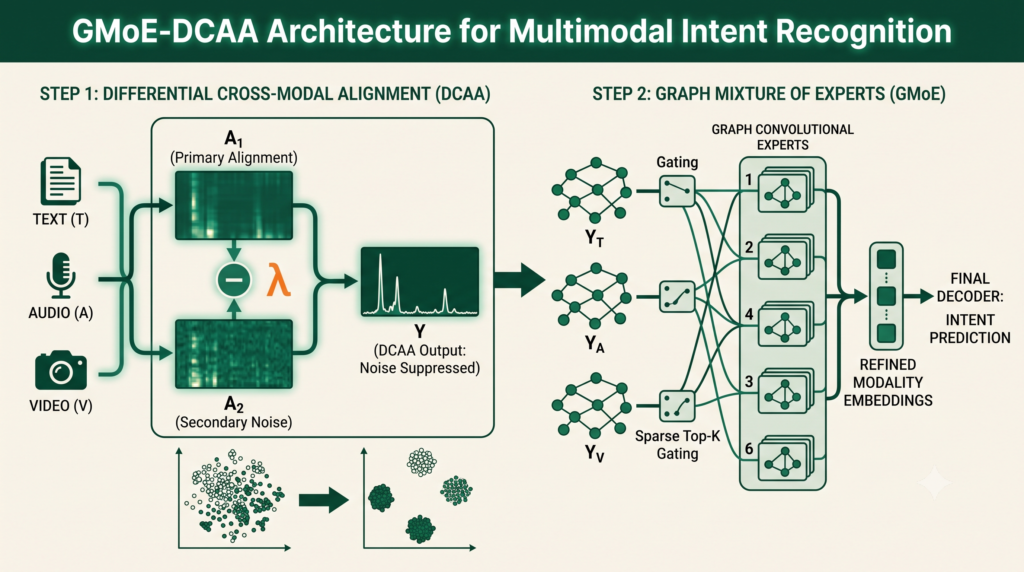
GMoE-DCAA Teaches Modalities To Cancel Out Each Other’s Noise
Analysis by the aitrendblend editorial team · Multimodal Fusion and Attention Mechanisms · 16 min read Multimodal Fusion Differential Attention Mixture Of Experts Graph Neural Networks Intent Recognition A conceptual illustration of differential cross modal attention and expert routing, not an original figure from the paper. Someone on a video call says “you knocked over […]
GMoE-DCAA Teaches Modalities To Cancel Out Each Other’s Noise Read More »