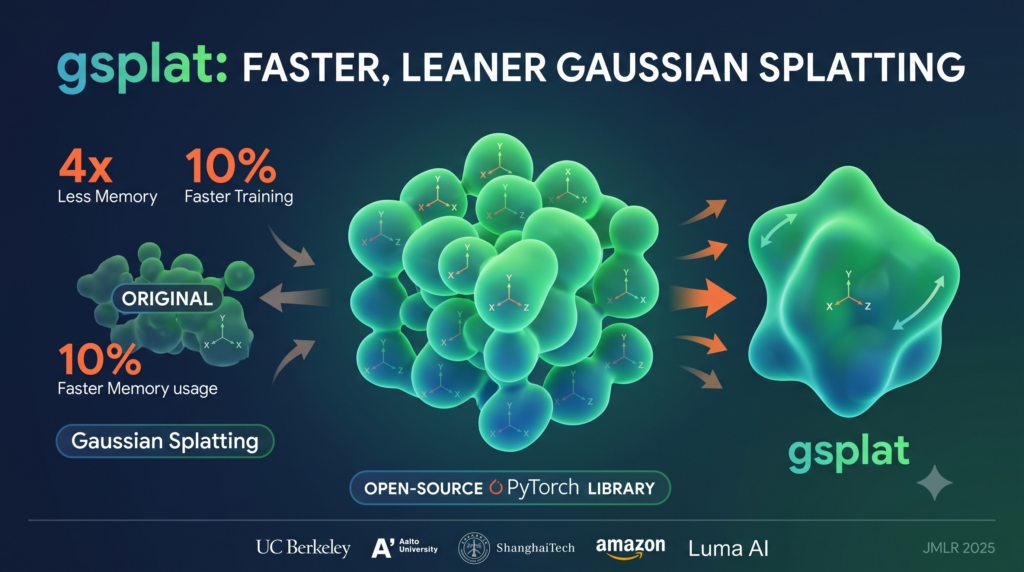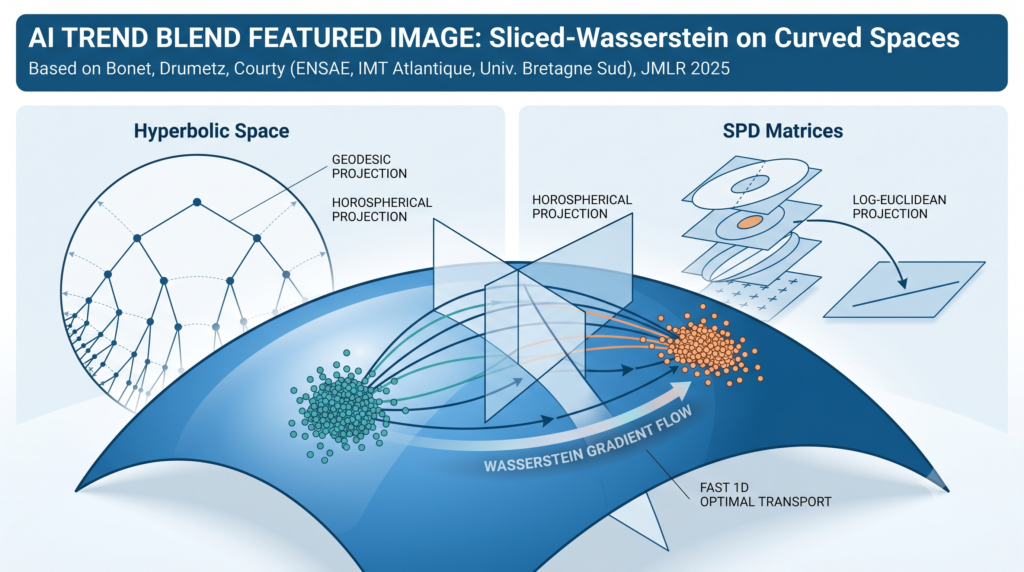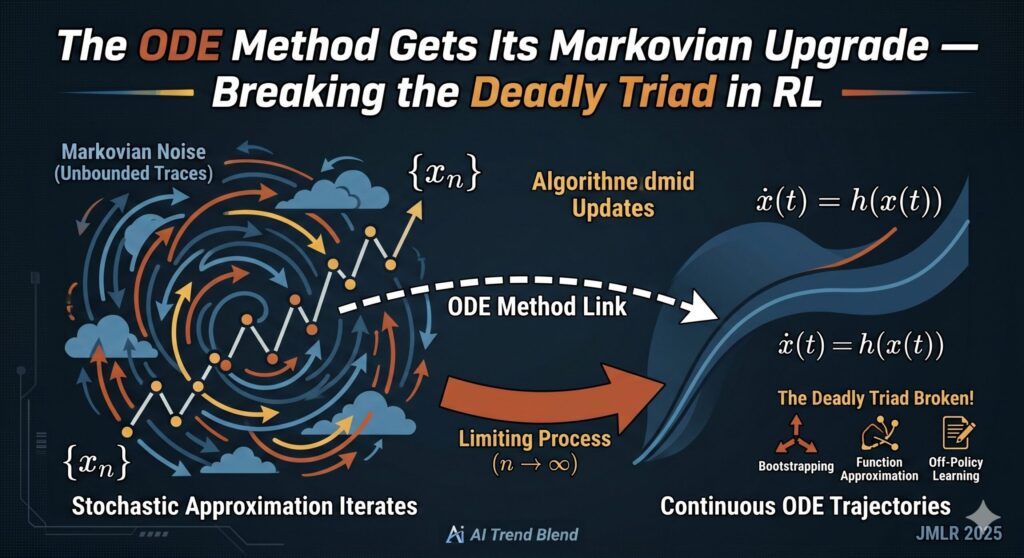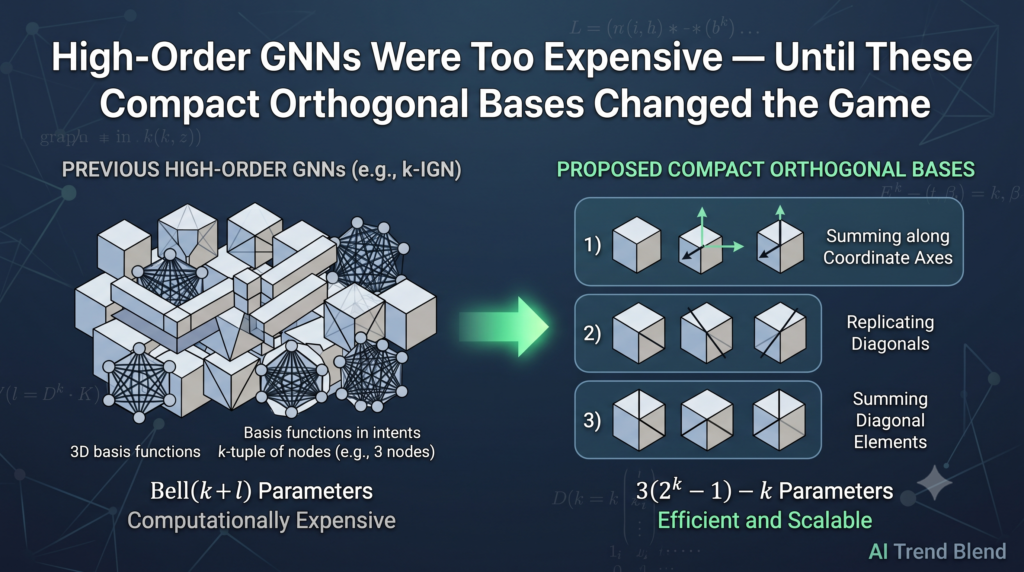
Chaos in the p-adic Ising Model — When Prime Numbers Decide Phase Transitions
Chaos in the p-adic Ising Model — When Prime Numbers Decide Phase Transitions | AI Trend Blend AITrendBlend Machine Learnings Mathematics About Statistical Mechanics · Journal of Mathematical Analysis and Applications 560 (2026) · UAE University & Uzbekistan Academy of Sciences · 14 min read When the Prime Number Decides Everything — Chaos and Phase […]
Chaos in the p-adic Ising Model — When Prime Numbers Decide Phase Transitions Read More »