DisC2o-HD: How Researchers Are Solving the Privacy-Accuracy Trade-off in Multi-Hospital Causal Inference
A team from the University of Pennsylvania, Columbia University, and Cornell University has built a distributed algorithm that estimates causal treatment effects from high-dimensional electronic health records spread across multiple clinical sites — without ever sharing a single patient record — while also handling the thorny problem of population differences between hospitals.
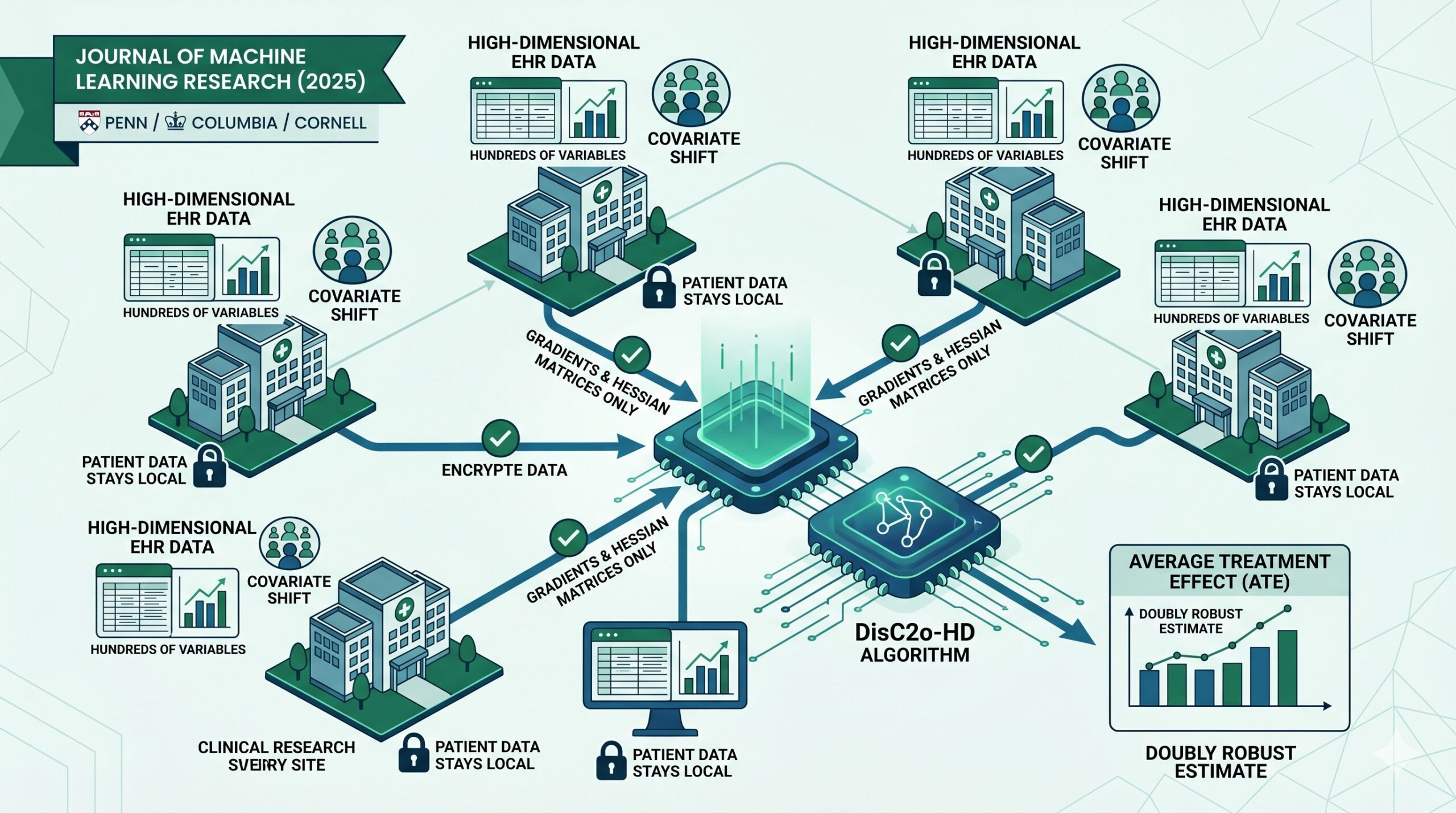
Imagine you want to know whether a particular drug genuinely reduces long-COVID symptoms in children. You have access to data from six hospitals, but you can’t legally move patient records between institutions. Each hospital also serves a different demographic — different racial compositions, different chronic disease burdens, different prescribing habits. And each hospital has hundreds of variables per patient, far more than any classical statistical method was designed to handle. This is exactly the situation DisC2o-HD was designed for.
The Problem No Single Previous Method Could Fully Solve
Real-world healthcare data from distributed research networks like the OHDSI consortium and PCORnet is enormously valuable for understanding how treatments actually work in diverse populations. But using this data for rigorous causal inference requires overcoming three distinct challenges simultaneously — and until now, no single method addressed all three at once.
Privacy & Data Sharing
Patient-level data cannot leave the institution that collected it. Privacy regulations, logistical complexity, and policy restrictions make pooling records infeasible in most real-world research networks.
High Dimensionality
Electronic health records contain hundreds to thousands of variables per patient — diagnoses, medications, labs, demographics, procedures. Standard causal methods break down when covariates vastly outnumber patients.
Covariate Shift
Hospitals serve different populations. A Mayo Clinic patient looks different from a Vanderbilt patient in terms of race, comorbidities, and medication history. Ignoring these distributional differences produces biased treatment effect estimates.
Existing distributed learning approaches — like simple divide-and-conquer or the surrogate likelihood method of Jordan et al. (2018) — handle the first challenge reasonably well. High-dimensional causal inference methods from Belloni, Chernozhukov, Tan, and Ning address the second. But combining both while also accounting for covariate shift across sites is an unsolved problem. That is the gap DisC2o-HD fills.
When patient populations differ across sites, the global Hessian matrix (the second derivative of the objective function) cannot be approximated by the local Hessian at any single site. This seemingly technical point has practical consequences: previous surrogate likelihood methods that only transfer first-order gradients introduce a constant bias term under covariate shift, making their error bounds worse than simply using local data alone. DisC2o-HD fixes this by also collecting Hessian matrices from all sites.
The Setup: What DisC2o-HD Is Trying to Estimate
The problem is formally set up as follows. Patient data from K clinical sites cannot be shared. Each site has n patients, for a total pooled sample size of N = Kn. For every patient, we observe a binary treatment assignment (treated or not), an outcome variable, and a high-dimensional vector of pre-treatment covariates — the confounders that need to be controlled for.
The target quantity is the average treatment effect (ATE) across all K populations:
where Yₖᵢ(1) and Yₖᵢ(0) are the potential outcomes under treatment and control for the i-th patient at site k. The “covariate shift” is the fact that the distribution of Xₖᵢ can differ substantially from site to site — the mean and covariance of patient characteristics are different hospitals, even though the underlying causal model relating treatment to outcome is assumed to be the same across sites.
The method models the treatment assignment probability via a logistic propensity score model and the expected outcome via a linear outcome model. Importantly, the method is designed to remain valid even when one of these two models is incorrectly specified — a property called double robustness.
The Technical Heart: Why Sharing Hessians Matters
To understand DisC2o-HD’s key insight, it helps to understand what goes wrong with simpler approaches under covariate shift.
The standard surrogate likelihood method works by having the lead site maintain a local version of the objective function, while other sites contribute only their first-order gradient information. This works well when all sites have similar data distributions, because in that case the local Hessian at the lead site is a good approximation of the global average Hessian. The condition needed is:
But when covariate shift is present — meaning the patient populations genuinely differ between hospitals — this assumption breaks down entirely:
DisC2o-HD solves this by asking every collaborating site to also transmit its Hessian matrix. The global Hessian is then reconstructed as the average of all site-level Hessians:
This is the foundational observation that makes the whole approach work. By averaging Hessians across sites rather than relying on the lead site’s local Hessian alone, the method reconstructs the global second-order information exactly, regardless of how different the site populations are.
The Surrogate Objective Functions
With this insight in hand, DisC2o-HD constructs a second-order surrogate of the global propensity score objective function. Rather than minimizing the true global objective QN(θ) — which would require pooling all patient data — the method minimizes a surrogate built from the lead site’s local data plus aggregated gradient and Hessian information from all sites:
Here, θ̄ is an initial estimator (for example, a lasso estimator fit on the lead site’s local data). The terms ∇Qₙ and ∇²Qₙ are constructed by averaging the gradient and Hessian contributions from all K sites — they never require sharing patient-level data, only summary statistics. Once this surrogate is built, the penalized propensity score estimator is obtained by minimizing Q̃ plus an ℓ₁ penalty, just like a standard lasso.
A parallel surrogate is constructed for the outcome model:
The outcome model is fitted using a weighted least squares loss that is specifically designed to achieve the doubly robust property — the final ATE estimate will be consistent as long as either the propensity score model or the outcome model is correctly specified, not both.
The Three-Algorithm Procedure
DisC2o-HD runs in three coordinated steps. To achieve the theoretical guarantees — particularly the independence needed for the final AIPW estimator to have clean variance bounds — the K clinical sites are randomly split into three sets K₁, K₂, and K₃ of roughly equal size. The paper shows this site-splitting strategy outperforms splitting patients within each site, both theoretically and in simulations.
Algorithm 1 — Distributed Propensity Score Estimation on K₁: The lead site (site 1 within K₁) fits an initial lasso propensity score estimator on its local data and broadcasts the coefficients to all sites in K₁. Each other site in K₁ computes and sends back its gradient vector and Hessian matrix. The lead site constructs the surrogate objective, fits the penalized surrogate, and obtains θ̃ₖ₁. The same procedure is applied on K₂ and K₃ independently.
Algorithm 2 — Distributed Outcome Model on K₁: Using the propensity score estimate θ̃ₖ₂ from K₂ (a separate fold, for independence), the outcome model is fitted via a parallel surrogate construction on K₁. Each site contributes gradient and Hessian information for the weighted least squares objective. This yields β̃ₖ₁. Same for the other two splits.
Algorithm 3 — AIPW Aggregation: Each site in K₃ computes its local augmented inverse propensity weighted (AIPW) estimator using θ̃ₖ₁ and β̃ₖ₂. These are averaged across all sites in K₃ to get τ̃₁,K₃. The process is repeated for K₁ and K₂. The final ATE estimate is the average of the three: τ̃₁ = (τ̃₁,K₁ + τ̃₁,K₂ + τ̃₁,K₃)/3.
The total communication overhead is modest: each participating site needs to send one gradient vector and one Hessian matrix per model — a single round of communication for each model fitting step. This makes the method practical for large research networks where communication costs are a real constraint.
“By collecting the Hessian matrices from collaborating sites, the proposed method can address the issue of covariate shifts across different sites. This incorporation of Hessians shows that the presence of covariate shift does not affect the estimation of the ATE when using high-dimensional data.” — Tong, Hu, Hripcsak, Ning, Chen · JMLR 26 (2025)
The Theoretical Guarantees
The paper’s theoretical results establish four main properties of DisC2o-HD, all proved under standard assumptions: unconfoundedness, overlap, a well-conditioned design matrix, sub-Gaussian noise, and sparsity conditions on the true propensity score and outcome model coefficients.
Convergence Rates Match the Pooled Gold Standard
The propensity score estimator θ̃ achieves an ℓ₂ error bound of:
The first term is the classical lasso rate for a dataset of size Kn — the same rate you would achieve if all data were pooled together. The second term represents the approximation cost of the distributed approach, and it vanishes faster than the first term as n grows. The outcome model estimator β̃ achieves the pooled rate √(s₂ log(p ∨ Kn) / Kn) exactly — a lossless result that holds because the outcome model’s weighted least squares structure is preserved perfectly by the surrogate.
Distributed ATE Error Bounds
The ATE estimator τ̃₁ satisfies:
When K = o(n) — meaning the number of sites grows slower than the sample size at each site — the second term is dominated by the first, and the distributed estimator achieves the same error bound as the pooled estimator. In other words, distributing the analysis across K hospitals costs essentially nothing in terms of accuracy, as long as the network is reasonably sized.
Asymptotic Normality and Semiparametric Efficiency
Theorem 6 establishes a Berry-Esseen bound showing that √(Kn)(τ̃₁ − τ*₁)/√V̂ converges to a standard normal distribution. This means you can construct valid confidence intervals and p-values for the treatment effect using the normal approximation — the standard statistical inference machinery applies. Moreover, the paper proves that the asymptotic variance V̂ consistently estimates the semiparametric efficiency bound first derived by Hahn (1998), which means DisC2o-HD achieves the best possible variance for any regular estimator of the ATE under the assumed model.
Double Robustness
Even when one of the two working models is wrong, the method remains consistent. Propositions 8 and 9 formalize this: if the propensity score model is misspecified but the outcome model is correct, or vice versa, the distributed estimator still converges to the true ATE at essentially the same rate.
The theoretical guarantees require that the sparsity of the true models (how many variables actually matter) grows slowly relative to the sample size. Specifically, letting s = max(s₁, s₂), the condition is roughly s/√n = o(1) — or in words, the number of truly relevant variables must be much smaller than the square root of the per-site sample size. This is the same condition required by the best existing non-distributed high-dimensional causal inference methods, confirming that DisC2o-HD pays no extra price for the distributed structure.
Simulation Results: Seven Scenarios, One Clear Winner
The paper tests DisC2o-HD-2 (the second-order surrogate version) against three competitors across seven increasingly challenging simulation scenarios: the pooled method (the gold standard requiring data sharing), the simple average method (naive divide-and-conquer), and DisC2o-HD-1 (first-order only surrogate).
| Scenario | Setting | Best Distributed Method | Key Finding |
|---|---|---|---|
| (I) | p < n, homogeneous | DisC2o-HD-2 | Matches pooled as K grows; simple average degrades |
| (II) | p < n, covariate shift | DisC2o-HD-2 | Only method that improves consistently with more sites |
| (III) | p > n, homogeneous | DisC2o-HD-2 | Large RMSE gap over DisC2o-HD-1 and simple average |
| (IV) | p > n, covariate shift | DisC2o-HD-2 | First-order method visibly worse; second-order holds |
| (V) | Misspecified PS model | DisC2o-HD-2 | Doubly robust — correct OM compensates for wrong PS |
| (VI) | Misspecified OM | DisC2o-HD-2 | Doubly robust — correct PS compensates for wrong OM |
| (VII) | Both models wrong | All degrade | Expected failure; confirms theoretical boundary |
Across all correctly-specified scenarios, DisC2o-HD-2 consistently produces smaller RMSE, bias, and variance than either the simple average method or the first-order DisC2o-HD-1. Crucially, its performance improves as the number of sites K increases — a property that the other distributed methods do not share. As K grows from 10 to 60 sites in the simulations, DisC2o-HD-2 converges visibly toward the pooled gold standard, while the first-order method stagnates and the simple average actually worsens in some scenarios.
The covariate shift scenarios (II and IV) are particularly telling. In these cases, the simple average method and even DisC2o-HD-1 show higher bias and RMSE than in the homogeneous settings, reflecting the damage that unaccounted distributional differences do to naive aggregation. DisC2o-HD-2’s performance barely changes between the homogeneous and heterogeneous settings — exactly what theory predicts, since the Hessian aggregation removes covariate shift from the error bound entirely.
DisC2o-HD-1 (First-Order Only)
Transfers only gradient vectors from each site. Works well when populations are homogeneous, but fails to correct for covariate shift. Under heterogeneous settings, the error can exceed what a purely local analysis would achieve.
DisC2o-HD-2 (Second-Order, Proposed)
Transfers both gradient vectors and Hessian matrices. Exactly cancels the covariate shift bias. Performance converges to the pooled gold standard as K grows, in both homogeneous and heterogeneous settings.
Real-World Application: COVID-19 Vaccination and Long-COVID in Children
The paper applies DisC2o-HD to a practically important and timely question: does COVID-19 vaccination reduce Post-Acute Sequelae of SARS-CoV-2 (PASC) — commonly called long-COVID — in children aged 5 to 11 during the Omicron period?
Because actual multi-site EHR data cannot be shared publicly, the study uses a simulated dataset generated from summary statistics derived from real EHR studies on pediatric PASC. The simulated data includes six clinical sites totaling 1,158 children, with approximately 193 patients per site. The 248 confounders include demographic variables, a Pediatric Medical Complexity Algorithm score, emergency department visit counts, inpatient and outpatient visit counts, unique medication counts, and indicator variables for 205 chronic condition clusters — a genuinely high-dimensional set of covariates.
The results are clinically meaningful. The proposed DisC2o-HD-2 method produces an ATE estimate of −0.26 (95% CI: [−0.44, −0.08]), indicating a reduction in the count of PASC features following vaccination. The pooled gold standard — which has access to all patient records simultaneously — estimates −0.24 (95% CI: [−0.38, −0.14]). The two estimates are numerically close, and both confidence intervals suggest a genuine protective effect of vaccination against PASC. This finding is directionally consistent with adult studies on the same question.
The simple average method and DisC2o-HD-1 produce estimates that deviate more substantially from the pooled reference. DisC2o-HD-2 achieves the best approximation of the gold standard while respecting the constraint that no patient record crosses institutional boundaries — which is precisely the setting that motivated the method’s development.
“The proposed method exhibits a loss in efficiency, resulting in a wider confidence interval for the estimate. The results of this study by examining the impact of COVID-19 vaccination on children aged 5 to 11 showed consistent findings with previous studies conducted on adults.” — Tong, Hu, Hripcsak, Ning, Chen · JMLR 26 (2025)
Limitations and Future Directions
The authors are upfront about the current method’s limitations. First, DisC2o-HD requires that all participating sites observe the same set of covariates — a condition called structural completeness. In practice, some sites may be missing certain variable types entirely (for example, a site that does not routinely collect certain lab values). Handling this kind of structural missingness is a planned extension.
Second, the method assumes that the true model coefficients are homogeneous across sites — the same propensity score and outcome model hold everywhere. In reality, complex multi-site EHR data often shows site-specific patterns. Extending the framework to allow for heterogeneous coefficients, along the lines of Duan et al.’s (2022) density ratio tilting approach, is identified as a key future direction.
Third, the current framework focuses on estimating the population-average treatment effect. Estimating site-specific treatment effects — which would allow understanding of why some hospitals see larger treatment benefits than others — is another important extension that the authors flag for future work.
Despite these limitations, DisC2o-HD represents a meaningful practical advance. It is the first method that simultaneously addresses all three core challenges of distributed healthcare causal inference — privacy, high dimensionality, and covariate shift — with provable statistical guarantees. The communication requirements are light enough to be practical in real networks, and the simulation evidence shows robust performance across a wide range of scenarios including model misspecification.
What Makes DisC2o-HD Practically Useful
Beyond the theoretical contributions, the paper emphasizes practical deployability. Several design choices make the method genuinely usable in large-scale distributed research networks.
The communication protocol is simple and one-shot per model: each participating site computes a gradient vector and a Hessian matrix from its local data, sends both to the lead site, and receives back the final model parameters. There are no iterative rounds of back-and-forth communication between sites. For a research network with 30 or 60 hospitals, coordinating a single exchange per model is feasible within the administrative structures that already exist for collaborative research.
The regularization parameters are selected via cross-validation, which is a standard procedure that requires no additional coordination between sites. The sample splitting into K₁, K₂, K₃ is a coordination cost, but the paper shows in supplementary simulations that the method also works well without splitting — the theoretical guarantees weaken slightly, but empirical performance is nearly identical when K is large.
The variance estimator needed for confidence intervals can be computed in a fully distributed manner, requiring only one additional round of communication to aggregate the squared residuals. This means the entire inference procedure — point estimates, confidence intervals, and p-values — can be completed without any site ever sharing patient-level data.
If you are running a multi-site observational study from EHR data with hundreds of covariates and different patient populations at each site, DisC2o-HD gives you a principled, privacy-preserving way to estimate treatment effects that is theoretically guaranteed to match what you would get from pooling all the data together. The cost is sharing gradient vectors and Hessian matrices — a manageable burden for any properly-governed research network.
Read the Full Paper
DisC2o-HD is published open-access in the Journal of Machine Learning Research. The full paper includes complete proofs, extended simulation results, and the COVID-19 vaccination data application.
Jiayi Tong, Jie Hu, George Hripcsak, Yang Ning, Yong Chen. DisC2o-HD: Distributed causal inference with covariates shift for analyzing real-world high-dimensional data. Journal of Machine Learning Research, 26 (2025) 1–50. http://jmlr.org/papers/v26/23-1254.html
This work was supported in part by the National Institutes of Health and the Patient-Centered Outcomes Research Institute (PCORI). The first two authors (Tong and Hu) contributed equally. Corresponding author: Yong Chen, University of Pennsylvania. This article is an independent editorial analysis of a peer-reviewed open-access paper. All statements and interpretations are those of the editorial authors and do not represent the views of PCORI, NIH, or the original paper’s authors.