IQ-LUT: How a 34 KB Lookup Table Beats a 1.5 MB Neural Network at Image Super-Resolution
Researchers at Shanghai Jiao Tong University and Rockchip Electronics built IQ-LUT — an image super-resolution system that fits in 34 kilobytes, runs on chips without a neural engine, and still outperforms methods with 44 times its storage footprint, by replacing exponential table storage with three elegant ideas: residual learning, dual-path fused interpolation, and non-uniform quantization guided by knowledge distillation.
Your phone’s camera already applies computational photography dozens of times per second. But upscaling a low-resolution video stream in real time on an embedded chip — the kind with no dedicated neural processing unit and a few megabytes of accessible memory — is still genuinely hard. Neural networks do this beautifully but need hundreds of megabytes and dedicated hardware. Lookup tables do this fast and efficiently but explode in storage size the moment you try to make them accurate. IQ-LUT is a principled answer to this exact tension: keep the table-indexing speed, slash the storage cost, and recover quality through a trio of techniques that together achieve more than any of them does alone.
The Core Tension in Lookup Table Super-Resolution
A lookup table for image super-resolution is conceptually simple. You pre-compute a function that maps every possible input pixel neighborhood to an upscaled output, store it as a table, and at inference time you just index into the table rather than running any network forward pass. The indexing is fast, deterministic, and trivially parallelizable — perfect for custom silicon.
The problem is the table’s size. If each pixel in the neighborhood can take 256 values (8 bits) and your neighborhood has two pixels, you need 256² = 65,536 entries. Add a third pixel and you need 16.7 million entries. A larger receptive field — which is what you need for higher quality — means exponential growth in table size. SR-LUT, the seminal method, needs 1.27 MB for ×4 upscaling. ECNN — an improved approach using single-input, multiple-output expanded convolutions — needs 1.5 MB at its 8-layer, 8-channel configuration and grows rapidly if you increase bit depth.
The bit depth is the second dimension of the explosion. Using 12-bit inputs instead of 8-bit inputs (for finer intensity discrimination) does not multiply storage by 1.5× — it multiplies it by 256^4 / 256^3 = 256× per additional bit per input. The storage math is brutal, and it makes higher-quality configurations completely impractical on constrained hardware.
IQ-LUT accepts a small amount of additional computation at inference time to escape the exponential storage trap. On custom ASIC hardware — which is the target deployment for embedded image processing — memory area and power cost are the primary constraints, not logic gate count. Trading a few logic gates for a 50× reduction in required memory is not just acceptable; it is the optimal design point for this hardware class.
The IQ-LUT Architecture: Three Interlocking Ideas
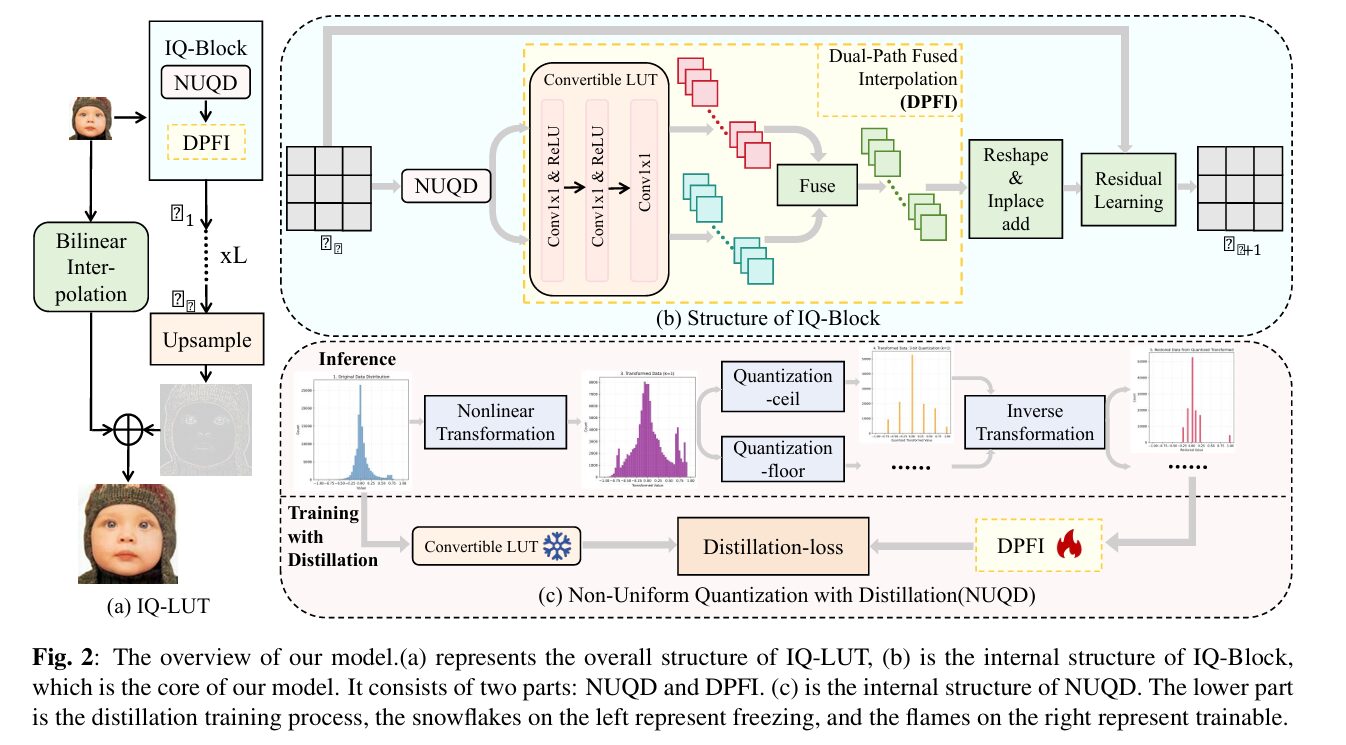
IQ-LUT stacks L identical IQ-Blocks. Each IQ-Block contains three mechanisms that work together: a Non-Uniform Quantization with Distillation module (NUQD) at the input, a Dual-Path Fused Interpolation module (DPFI) for the core lookup, and a learnable residual connection that ties input to output. After all L blocks, a bilinear upsampling baseline is added to produce the final high-resolution image.
IQ-LUT OVERALL STRUCTURE
═══════════════════════════════════════════════════════════════
Input LR image
│
├──→ Bilinear Interpolation ─────────────────────────────┐
│ (low-frequency baseline) │
│ │ (final add)
└──→ IQ-Block 1 │
│ │
▼ │
IQ-Block 2 │
│ │
▼ (× L layers) │
IQ-Block L │
│ │
▼ │
Upsample (PixelShuffle) │
│ │
└──────────────────────────────────────────────┘
│
HR Output
═══════════════════════════════════════════════════════════════
INSIDE A SINGLE IQ-BLOCK:
Input x_i
│
▼
┌─────────────────────────────────────────────────────────┐
│ NUQD — Non-Uniform Quantization with Distillation │
│ │
│ Nonlinear transform T_{a,b}(x): │
│ x ≤ -a: -1 + s_o(x + 1) (outer region) │
│ |x| < a: s_m · x (inner region) │
│ x ≥ a: b + s_o(x - a) (outer region) │
│ where s_m = b/a, s_o = (1-b)/(1-a) │
│ │
│ → x_floor = floor(x_transformed) (lower LUT index) │
│ → x_ceil = ceil(x_transformed) (upper LUT index) │
│ → T = interpolation weight │
│ │
│ Training: distillation from 8-bit teacher (12-bit out) │
│ Inference: quantize → inplace table index │
└─────────────────────────────────────────────────────────┘
│ x_floor, x_ceil, T
▼
┌─────────────────────────────────────────────────────────┐
│ DPFI — Dual-Path Fused Interpolation │
│ │
│ Path A: Convertible LUT applied to x_floor │
│ Path B: Convertible LUT applied to x_ceil │
│ │
│ X_floor = Φ_θ(x_floor) ← table lookup / NN forward │
│ X_ceil = Φ_θ(x_ceil) ← same table, upper index │
│ │
│ F(x) = (1 - T) ⊙ X_floor + T ⊙ X_ceil │
│ (weighted blend — avoids storing intermediate) │
│ │
│ Reshape & Inplace Add → spatial reassembly │
└─────────────────────────────────────────────────────────┘
│ F(x)
▼
Residual connection:
x_{i+1} = (1 - σ(α)) · x_i + σ(α) · F(x_i)
(learnable scalar α controls residual gate)
═══════════════════════════════════════════════════════════════
NAMING: IQ-LXCY = X IQ-Block layers, Y channels
IQ-L8C8: 34 KB | IQ-L12C8: 50 KB | IQ-L8C16: 124 KB
═══════════════════════════════════════════════════════════════
Residual Learning: Why Training Gets Much Easier
The first insight is architectural. Instead of training the network to predict the full high-resolution pixel value directly, IQ-LUT trains each IQ-Block to predict only the residual — the difference between the low-resolution input and the desired output. The final HR image is the bilinear upsampling baseline plus the accumulated residuals from all IQ-Blocks.
This matters in two ways. First, bilinear interpolation already handles the low-frequency content well — flat regions, slow gradients, broad color transitions. What LUT-based methods genuinely struggle with is high-frequency detail: sharp edges, fine textures, periodic patterns. By restricting the network's target to residuals, you point it exactly at the problem it is best equipped to solve. Second, residual outputs are concentrated near zero. This concentration has a direct impact on quantization — uniform quantization wastes bits allocating equal storage to the full pixel value range, most of which is already handled by the bilinear baseline. A concentrated residual distribution means fewer bits are needed to represent meaningful variation, which is exactly what NUQD exploits.
The learnable residual gate α, implemented as a sigmoid-scaled scalar, provides additional flexibility. It allows each IQ-Block to adaptively balance how much of the residual contribution to pass through versus how much of the original input to preserve — effectively learning skip connection weights rather than fixing them at 1.0.
DPFI: Getting Interpolation to Do the Storage's Work
The Dual-Path Fused Interpolation module is the storage reduction mechanism at the heart of IQ-LUT. The problem it solves: low bit-depth input (3–4 bits) means fewer LUT entries but coarser quantization and visible artifacts. High bit-depth input means unaffordable storage. DPFI takes the middle path — use low bit-depth for indexing, but compute the intermediate value between adjacent table entries rather than storing it.
Concretely, after the nonlinear transformation in NUQD, each pixel value x_trans is simultaneously rounded down (x_floor) and rounded up (x_ceil), giving two adjacent LUT indices. Both are looked up in the same table. An interpolation weight T is computed from the fractional position between the floor and ceil values:
The result looks up the table twice per pixel but completely avoids storing intermediate values. The storage cost is determined solely by the number of distinct indices (2^b), not by the number of values the output can take. You get the visual quality of a high-precision table at the storage cost of a low-precision one, with one additional multiply-add per lookup to compute the interpolation — a trivial cost on any hardware platform.
NUQD: Non-Uniform Quantization Guided by Knowledge Distillation
Because residual outputs cluster near zero, uniform quantization wastes precision. If the residuals are mostly small values with a few occasional large ones, uniform steps that span the full range represent the common small values poorly. NUQD applies a symmetric piecewise-linear transformation T_{a,b} before quantization that compresses the outer, less-frequent range and expands the inner, frequent range:
The hyperparameters a and b control the slope in the inner and outer regions respectively. By setting b < a (inner region gets a larger slope = more quantization levels), NUQD concentrates quantization precision where the data actually lives. The transformation is invertible, hardware-friendly (piecewise linear needs only comparisons and multiply-adds), and the parameters a and b are optimized via greedy search on a validation set.
The knowledge distillation component of NUQD fine-tunes the quantized low-bit student network (3–4 bit inputs) against a high-bit-depth teacher network (8-bit inputs, 12-bit outputs). The teacher is frozen and provides soft targets — its output features carry information about the correct mapping that the student's reduced bit-depth cannot fully recover on its own. The distillation loss is weighted at 3.0× relative to the base MSE loss, reflecting how critical this guidance is for maintaining quality under aggressive bit reduction.
"Our primary objective is optimization for custom hardware (ASIC) deployment, where storage — not logic — dominates area and power costs. Consequently, our radical storage compression provides a decisive efficiency advantage." — Zhang, Dong, Chai, Zhou, Xu, Cheng, and Song, arXiv:2604.07000 (2026)
Results: Smaller Than a JPEG, Better Than Much Larger Models
| Method | Size (KB) | Set5 PSNR | Set14 PSNR | B100 PSNR | Urban100 PSNR | Manga109 PSNR |
|---|---|---|---|---|---|---|
| SR-LUT | 1274 | 29.82 | 27.01 | 26.53 | 24.02 | 26.80 |
| SP-LUT | 5500 | 30.01 | 27.21 | 26.67 | 24.12 | 27.00 |
| MuLUT | 4062 | 30.60 | 27.60 | 26.86 | 24.46 | 27.90 |
| TinyLUT-S | 37 | 30.22 | 27.33 | 26.71 | 24.19 | 27.21 |
| ECNN-L8C8 | 1516 | 31.06 | 27.91 | 27.08 | 24.82 | 28.59 |
| IQ-L8C8 | 34 | 31.14 | 27.93 | 27.09 | 24.84 | 28.64 |
| IQ-L12C8 | 50 | 31.26 | 28.00 | 27.14 | 24.96 | 28.86 |
| IQ-L8C16 | 124 | 31.50 | 28.12 | 27.22 | 25.14 | 29.17 |
Table 1: ×4 super-resolution results (PSNR, dB). IQ-L8C8 (34 KB) beats ECNN-L8C8 (1516 KB) — a 44× storage advantage — while improving PSNR on every benchmark. IQ-L8C16 (124 KB) leads all LUT-based methods on all five datasets.
The headline comparison is IQ-L8C8 versus ECNN-L8C8. Both use the same 8-layer, 8-channel expanded convolution backbone. IQ-L8C8 weighs 34 KB; ECNN-L8C8 weighs 1516 KB. IQ-L8C8 outperforms ECNN-L8C8 on every single benchmark — it is both smaller by a factor of 44 and more accurate. This is not a tradeoff; it is a strict improvement. The accuracy gain comes from the residual learning and DPFI components compensating for the reduced bit-depth, while the storage reduction comes from operating at 3–4 bits instead of 8 bits.
The comparison with TinyLUT-S is also notable. TinyLUT-S is a purpose-built tiny LUT at 37 KB — nearly the same storage as IQ-L8C8. IQ-L8C8 achieves 31.14 dB on Set5 versus TinyLUT-S's 30.22 dB — a 0.92 dB improvement at essentially the same storage cost. This confirms that IQ-LUT's design gains are independent of its compression; it is genuinely a better architecture, not just more compressed.
Ablation: What Each Component Contributes
| DPFI | Residual | Set5 | Set14 | B100 | Urban100 | Manga109 |
|---|---|---|---|---|---|---|
| ✗ | ✗ | 30.63 | 27.59 | 26.90 | 24.50 | 27.69 |
| ✓ | ✗ | 31.04 | 27.89 | 27.06 | 24.75 | 28.44 |
| ✓ | ✓ | 31.20 | 27.99 | 27.13 | 24.91 | 28.74 |
Table 2: DPFI and Residual Learning ablation (IQ-L8C8, 4-bit input). DPFI alone: +0.41 dB on Set5. DPFI + Residual: +0.57 dB on Set5 vs. baseline.
| NUQD | Set5 | Set14 | B100 | Urban100 | Manga109 |
|---|---|---|---|---|---|
| ✗ | 31.12 | 27.91 | 27.09 | 24.82 | 28.52 |
| ✓ | 31.17 | 27.95 | 27.10 | 24.85 | 28.65 |
Table 3: NUQD ablation (IQ-L8C8, first block 4-bit, subsequent blocks 3-bit). NUQD adds consistent gains across all five benchmarks.
The ablation data is clean. DPFI contributes the largest single gain (+0.41 dB on Set5), confirming that interpolation between floor and ceil table values is the primary mechanism recovering quality lost to bit-depth reduction. Residual learning adds a further +0.16 dB, with the pattern being most visible on complex-texture benchmarks like Urban100 (+0.16 dB) and Manga109 (+0.30 dB) where fine structure recovery matters most. NUQD adds consistent but smaller gains — its value is primarily in storage efficiency rather than raw PSNR, enabling the 3-bit configuration in subsequent blocks without a quality penalty that would otherwise appear.
Complete End-to-End IQ-LUT Implementation (PyTorch)
The implementation below is a complete, runnable PyTorch implementation of IQ-LUT, structured across 10 sections that map directly to the paper. It covers the expanded convolutional (EC) layer that converts to a LUT at inference time, the piecewise-linear nonlinear transformation T_{a,b} for non-uniform quantization, the Dual-Path Fused Interpolation (DPFI) with floor/ceil lookup and weighted blend, the Non-Uniform Quantization with Distillation (NUQD) module, the adaptive residual gate with learnable scalar α, the full IQ-Block combining all three mechanisms, the complete IQ-LUT model with bilinear baseline and PixelShuffle upsampling, the two-stage training loop (MSE pre-training then distillation fine-tuning), LUT conversion utilities, and a smoke test validating all components.
# ==============================================================================
# IQ-LUT: Interpolated and Quantized LUT for Efficient Image Super-Resolution
# Paper: arXiv:2604.07000v1 [cs.CV] (2026)
# Authors: Yuxuan Zhang, Zhikai Dong, Xinning Chai, Xiangyun Zhou,
# Yi Xu, Zhengxue Cheng, Li Song
# Affiliations: Shanghai Jiao Tong University · Rockchip Electronics
# ==============================================================================
# Sections:
# 1. Imports & Configuration
# 2. Expanded Convolution (EC) Layer — Convertible LUT backbone
# 3. Piecewise-Linear Nonlinear Transform T_{a,b}
# 4. NUQD — Non-Uniform Quantization with Distillation
# 5. DPFI — Dual-Path Fused Interpolation
# 6. IQ-Block (NUQD + DPFI + Residual Gate)
# 7. IQ-LUT Full Model
# 8. LUT Conversion Utility (training → inference)
# 9. Two-Stage Training Loop + Dataset Helpers
# 10. Smoke Test
# ==============================================================================
from __future__ import annotations
import math
import warnings
from dataclasses import dataclass
from typing import Dict, List, Optional, Tuple
import numpy as np
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch import Tensor
from torch.utils.data import DataLoader, Dataset
warnings.filterwarnings("ignore")
# ─── SECTION 1: Configuration ─────────────────────────────────────────────────
@dataclass
class IQLUTConfig:
"""
Configuration for IQ-LUT models.
Naming convention: IQ-LXCY = X IQ-Block layers, Y channels.
IQ-L8C8: n_layers=8, channels=8 → 34 KB LUT storage
IQ-L12C8: n_layers=12,channels=8 → 50 KB
IQ-L8C16: n_layers=8, channels=16 → 124 KB (best quality)
Attributes
----------
n_layers : int — number of stacked IQ-Blocks (L)
channels : int — intermediate feature channels (C)
scale : int — upscaling factor (paper: ×4)
first_bit : int — bit-depth of first IQ-Block input (paper: 4)
later_bit : int — bit-depth of subsequent IQ-Block inputs (paper: 3)
output_bit : int — bit-depth of each IQ-Block output (paper: 8)
teacher_in_bit : int — teacher input bit-depth for distillation (paper: 8)
teacher_out_bit: int — teacher output bit-depth (paper: 12)
lr : float — Adam learning rate (paper: 1e-4)
pretrain_iters : int — MSE pre-training iterations (paper: subset of 1M)
finetune_iters : int — distillation fine-tuning iterations
mse_weight : float — MSE loss weight (paper: 1.0)
distill_weight : float — distillation loss weight (paper: 3.0)
patch_size : int — training patch size
batch_size : int — training batch size
"""
n_layers: int = 8
channels: int = 8
scale: int = 4
first_bit: int = 4
later_bit: int = 3
output_bit: int = 8
teacher_in_bit: int = 8
teacher_out_bit: int = 12
lr: float = 1e-4
pretrain_iters: int = 200_000
finetune_iters: int = 200_000
mse_weight: float = 1.0
distill_weight: float = 3.0
patch_size: int = 48
batch_size: int = 16
# ─── SECTION 2: Expanded Convolution (EC) Layer ───────────────────────────────
class ExpandedConvLayer(nn.Module):
"""
Expanded Convolution (EC) layer — the Convertible LUT backbone (Section 2A).
At training time: a lightweight 3-layer MLP (Conv1x1 → ReLU → Conv1x1 → ReLU → Conv1x1)
that maps each individual pixel value to multiple output values.
At inference time: converted to a lookup table where each entry stores
the pre-computed output for that quantized input value:
X(i, j, c) = Φ_θ(F_in(i, j, c)) [Eq. 1]
The "Reshape and Inplace Add" operation reassembles the per-pixel outputs
into a spatial feature map by accumulating contributions from all pixels
in the receptive window:
F_{n,c,h,w} = Σ_{i,j,c_in} X_patch[n, c_in, c, i, j, h+i, w+j] [Eq. 2]
Parameters
----------
in_channels : int — input feature channels (1 for first layer)
out_channels : int — output channels per EC unit
hidden_channels: int — hidden dimension of the MLP subnetwork
k_h, k_w : int — receptive field kernel size
"""
def __init__(
self,
in_channels: int = 1,
out_channels: int = 8,
hidden_channels: int = 32,
k_h: int = 2,
k_w: int = 2,
):
super().__init__()
self.in_ch = in_channels
self.out_ch = out_channels
self.k_h = k_h
self.k_w = k_w
# Three 1×1 convolutions with ReLU activations (Fig. 2 Convertible LUT)
self.mlp = nn.Sequential(
nn.Conv2d(in_channels, hidden_channels, 1, bias=True),
nn.ReLU(inplace=True),
nn.Conv2d(hidden_channels, hidden_channels, 1, bias=True),
nn.ReLU(inplace=True),
nn.Conv2d(hidden_channels, out_channels * k_h * k_w, 1, bias=True),
)
def forward(self, x: Tensor) -> Tensor:
"""
Parameters
----------
x : (B, in_ch, H, W)
Returns
-------
out : (B, out_ch, H, W) — spatially reassembled feature map
"""
B, C, H, W = x.shape
kH, kW = self.k_h, self.k_w
# Per-pixel MLP: (B, C, H, W) → (B, out_ch*kH*kW, H, W)
raw = self.mlp(x)
# Reshape to (B, out_ch, kH, kW, H, W)
raw = raw.view(B, self.out_ch, kH, kW, H, W)
# Reassemble: accumulate shifted patches (Eq. 2 simplified for 2×2 kernel)
out = torch.zeros(B, self.out_ch, H, W, device=x.device, dtype=x.dtype)
for dh in range(kH):
for dw in range(kW):
# Shift contribution: pixel at (h,w) contributes to (h+dh, w+dw)
h_src = H - dh
w_src = W - dw
out[:, :, dh:dh+h_src, dw:dw+w_src] += raw[:, :, dh, dw, :h_src, :w_src]
return out
def to_lut(self, bit_depth: int) -> Tensor:
"""
Convert trained EC layer to a lookup table at inference time.
Pre-computes output for every possible quantized input value.
Parameters
----------
bit_depth : int — number of quantization bits (e.g., 8 → 256 entries)
Returns
-------
lut : (2^bit_depth, out_ch * k_h * k_w) — the lookup table
"""
n_entries = 2 ** bit_depth
# All possible input values in [-1, 1]
idx = torch.linspace(-1.0, 1.0, n_entries, device=next(self.parameters()).device)
idx_4d = idx.view(1, self.in_ch, n_entries, 1) # (1, 1, N, 1)
self.eval()
with torch.no_grad():
# Run each input through the MLP
out = self.mlp(idx_4d) # (1, out_ch*kH*kW, N, 1)
lut = out.squeeze(0).squeeze(-1).T # (N, out_ch*kH*kW)
return lut
# ─── SECTION 3: Piecewise-Linear Nonlinear Transform ──────────────────────────
class PiecewiseLinearTransform(nn.Module):
"""
Symmetric piecewise-linear transform T_{a,b}(x) for non-uniform quantization
(Eq. 4 in paper). Hardware-friendly: requires only comparisons and multiply-adds.
Three regions:
x ≤ -a : -1 + s_o·(x + 1) (outer negative region, gentler slope)
|x| < a: s_m · x (inner region, steeper slope = more precision)
x ≥ a : b + s_o·(x - a) (outer positive region, gentler slope)
where s_m = b/a (inner slope, > 1 if b > a → inner region expanded)
s_o = (1-b)/(1-a) (outer slope, < 1 if b < 1-a → outer compressed)
Effect: concentrates quantization levels in the inner region where
residual outputs cluster (near zero), reducing wasted bits on rare
large-magnitude values.
Parameters
----------
a : float — inner/outer boundary (0 < a < 1)
b : float — remapped inner boundary (0 < b < 1)
"""
def __init__(self, a: float = 0.5, b: float = 0.7):
super().__init__()
self.a = a
self.b = b
self._validate()
def _validate(self):
assert 0 < self.a < 1, f"a must be in (0,1), got {self.a}"
assert 0 < self.b < 1, f"b must be in (0,1), got {self.b}"
def forward(self, x: Tensor) -> Tensor:
"""Apply T_{a,b}(x). Input assumed in [-1, 1]."""
a, b = self.a, self.b
s_m = b / a
s_o = (1.0 - b) / (1.0 - a)
inner = (x.abs() < a).float()
pos_outer = (x >= a).float()
neg_outer = (x <= -a).float()
y = (inner * s_m * x
+ pos_outer * (b + s_o * (x - a))
+ neg_outer * (-1.0 + s_o * (x + 1.0)))
return y.clamp(-1.0, 1.0)
def inverse(self, y: Tensor) -> Tensor:
"""Inverse transform T_{a,b}^{-1}(y) for inference dequantization."""
a, b = self.a, self.b
s_m = b / a
s_o = (1.0 - b) / (1.0 - a)
inner = (y.abs() < b).float()
pos_outer = (y >= b).float()
neg_outer = (y <= -b).float()
x = (inner * y / (s_m + 1e-8)
+ pos_outer * ((y - b) / (s_o + 1e-8) + a)
+ neg_outer * ((y + 1.0) / (s_o + 1e-8) - 1.0))
return x
@staticmethod
def greedy_search(
data_samples: Tensor,
a_candidates: Optional[List[float]] = None,
b_candidates: Optional[List[float]] = None,
) -> Tuple[float, float]:
"""
Greedy search for optimal (a, b) hyperparameters (Section 2C).
Finds the transform that minimizes the average quantization error
on representative data samples.
Parameters
----------
data_samples : (N,) flat tensor of sample values
a_candidates : candidate inner boundaries (default: 0.1 to 0.9)
b_candidates : candidate remapped boundaries (default: 0.1 to 0.9)
Returns
-------
(best_a, best_b)
"""
if a_candidates is None:
a_candidates = [0.2, 0.3, 0.4, 0.5, 0.6, 0.7]
if b_candidates is None:
b_candidates = [0.4, 0.5, 0.6, 0.7, 0.8]
best_err = float("inf")
best_a, best_b = 0.5, 0.7
for a in a_candidates:
for b in b_candidates:
if a <= 0 or b <= 0 or a >= 1 or b >= 1:
continue
T = PiecewiseLinearTransform(a, b)
y = T(data_samples)
x_rec = T.inverse(y)
err = (data_samples - x_rec).abs().mean().item()
if err < best_err:
best_err = err
best_a, best_b = a, b
return best_a, best_b
# ─── SECTION 4: NUQD — Non-Uniform Quantization with Distillation ─────────────
class NUQD(nn.Module):
"""
Non-Uniform Quantization with Distillation module (Section 2C, Fig. 2c).
Applied at the input of each IQ-Block. Transforms, quantizes, and
produces floor/ceil quantized values plus an interpolation weight T
for use by DPFI.
At training time:
- Applies piecewise-linear transform T_{a,b}(x)
- Computes floor and ceil of transformed values (differentiable via
straight-through estimator)
- Returns both x_floor, x_ceil, and interpolation weight T
At inference time:
- Applies the same transform, produces integer floor/ceil indices
for direct LUT lookup
Knowledge distillation: a high-bit teacher (8-bit input, 12-bit output)
provides soft supervision for the low-bit student (3–4 bit input) during
fine-tuning. The frozen teacher's outputs serve as regression targets.
Parameters
----------
bit_depth : int — target quantization bit-depth (3 or 4 in paper)
a, b : float — piecewise-linear transform hyperparameters
"""
def __init__(self, bit_depth: int = 4, a: float = 0.5, b: float = 0.7):
super().__init__()
self.bit_depth = bit_depth
self.n_levels = 2 ** bit_depth
self.transform = PiecewiseLinearTransform(a, b)
def forward(self, x: Tensor) -> Tuple[Tensor, Tensor, Tensor]:
"""
Apply non-uniform quantization, returning floor, ceil, and interpolation weight.
Parameters
----------
x : (B, C, H, W) — input features (assumed approximately in [-1, 1])
Returns
-------
x_floor : (B, C, H, W) — lower quantized value (dequantized)
x_ceil : (B, C, H, W) — upper quantized value (dequantized)
T : (B, C, H, W) — interpolation weight ∈ [0, 1]
"""
# Step 1: Apply nonlinear transformation (compresses outer, expands inner)
x_trans = self.transform(x)
# Step 2: Normalize to [0, n_levels-1] range for quantization
x_norm = (x_trans + 1.0) / 2.0 * (self.n_levels - 1)
# Step 3: Floor and ceil quantization (both are needed for DPFI)
x_f = x_norm.floor()
x_c = (x_norm.floor() + 1).clamp(0, self.n_levels - 1)
# Step 4: Compute interpolation weight T (fractional part, Eq. 5)
T = (x_norm - x_f).clamp(0.0, 1.0) # ∈ [0, 1]
# Step 5: Dequantize back to [-1, 1] for downstream processing
def dequantize(q_idx: Tensor) -> Tensor:
q_norm = q_idx / (self.n_levels - 1) * 2.0 - 1.0
return self.transform.inverse(q_norm)
x_floor_deq = dequantize(x_f)
x_ceil_deq = dequantize(x_c)
return x_floor_deq, x_ceil_deq, T
def integer_indices(self, x: Tensor) -> Tuple[Tensor, Tensor, Tensor]:
"""
Inference mode: returns integer floor/ceil indices for direct LUT lookup.
Returns (floor_idx, ceil_idx, weight_T) all as integers/floats.
"""
x_trans = self.transform(x)
x_norm = (x_trans + 1.0) / 2.0 * (self.n_levels - 1)
floor_idx = x_norm.floor().long().clamp(0, self.n_levels - 1)
ceil_idx = (floor_idx + 1).clamp(0, self.n_levels - 1)
T = (x_norm - x_norm.floor()).clamp(0.0, 1.0)
return floor_idx, ceil_idx, T
# ─── SECTION 5: DPFI — Dual-Path Fused Interpolation ─────────────────────────
class DPFI(nn.Module):
"""
Dual-Path Fused Interpolation module (Section 2D).
Resolves the core storage-quality tradeoff of LUT-based SR:
- Low bit-depth → few LUT entries → small storage → artifacts from coarse steps
- DPFI: interpolate between floor and ceil LUT entries → quality without storage
Given the two quantized inputs x_floor and x_ceil from NUQD,
DPFI applies the same EC subnetwork (or LUT) to both, then computes
a weighted blend guided by interpolation weight T:
F(x) = (1 - T) ⊙ X_floor + T ⊙ X_ceil [Eq. 5]
At inference: X_floor and X_ceil are obtained by table lookups using
floor_idx and ceil_idx. No additional storage is needed; only one extra
table lookup and a multiply-add per pixel versus standard single-path LUT.
Parameters
----------
ec_layer : ExpandedConvLayer — the shared EC subnetwork (same weights for both paths)
"""
def __init__(self, ec_layer: ExpandedConvLayer):
super().__init__()
self.ec = ec_layer
def forward(self, x_floor: Tensor, x_ceil: Tensor, T: Tensor) -> Tensor:
"""
Parameters
----------
x_floor : (B, C, H, W) — dequantized floor values
x_ceil : (B, C, H, W) — dequantized ceil values
T : (B, C, H, W) — interpolation weights ∈ [0, 1]
Returns
-------
F : (B, out_ch, H, W) — fused interpolated output
"""
# Apply the same EC layer to both paths (two table lookups at inference)
X_floor = self.ec(x_floor) # lower path
X_ceil = self.ec(x_ceil) # upper path
# Weighted blend (Eq. 5): interpolates between floor and ceil outputs
# T must match the channel dimension of X_floor/X_ceil
if T.shape[1] != X_floor.shape[1]:
# Average T over channels to broadcast
T_out = T.mean(dim=1, keepdim=True).expand_as(X_floor)
else:
T_out = T
F = (1.0 - T_out) * X_floor + T_out * X_ceil
return F
# ─── SECTION 6: IQ-Block ──────────────────────────────────────────────────────
class IQBlock(nn.Module):
"""
IQ-Block: the core building block of IQ-LUT (Section 2B, Fig. 2b).
Sequential processing:
1. NUQD: non-uniform quantization → x_floor, x_ceil, T
2. DPFI: dual-path fused interpolation → F(x)
3. Residual gate: x_out = (1-σ(α))·x + σ(α)·F(x) [Eq. 3]
The adaptive residual gate α (learnable scalar) balances:
- Skip connection: preserves input for stable gradient propagation
- Processed path: contributes DPFI output for quality improvement
Parameters
----------
channels : int — intermediate feature channels (C in IQ-LXCY naming)
bit_depth : int — quantization bit-depth for this block (3 or 4)
a, b : float — NUQD piecewise-linear transform params
k_h, k_w : int — EC layer receptive field
"""
def __init__(
self,
channels: int = 8,
bit_depth: int = 4,
a: float = 0.5,
b: float = 0.7,
k_h: int = 2,
k_w: int = 2,
):
super().__init__()
self.channels = channels
self.bit_depth = bit_depth
# NUQD: non-uniform quantization
self.nuqd = NUQD(bit_depth=bit_depth, a=a, b=b)
# Shared EC layer used by both DPFI paths
ec_layer = ExpandedConvLayer(
in_channels=1, # single pixel input (single-input in ECNN)
out_channels=channels,
hidden_channels=max(8, channels * 2),
k_h=k_h, k_w=k_w,
)
# DPFI: dual-path fused interpolation
self.dpfi = DPFI(ec_layer)
# Learnable residual gate α (Eq. 3)
self.alpha = nn.Parameter(torch.zeros(1))
# Channel projection to match output dimension if needed
self.proj = nn.Conv2d(channels, 1, 1, bias=False)
def forward(self, x: Tensor) -> Tensor:
"""
Parameters
----------
x : (B, 1, H, W) — single-channel input feature map
Returns
-------
x_out : (B, 1, H, W) — output after residual connection
"""
# Step 1: NUQD quantization with floor/ceil split
x_floor, x_ceil, T = self.nuqd(x)
# Step 2: DPFI — dual-path lookup and interpolation
F_x = self.dpfi(x_floor, x_ceil, T) # (B, channels, H, W)
# Project back to single channel
F_x = self.proj(F_x) # (B, 1, H, W)
# Step 3: Adaptive residual gate (Eq. 3)
gate = torch.sigmoid(self.alpha)
x_out = (1.0 - gate) * x + gate * F_x
return x_out
# ─── SECTION 7: IQ-LUT Full Model ────────────────────────────────────────────
class IQLUT(nn.Module):
"""
IQ-LUT: Full super-resolution model (Section 2B, Fig. 2a).
Architecture:
Input LR image
├─→ [IQ-Block_1 → IQ-Block_2 → ... → IQ-Block_L] → Upsample
└─→ Bilinear Interpolation (low-frequency baseline)
→ Sum → HR Output
The bilinear path provides the low-frequency foundation that allows
each IQ-Block to focus exclusively on high-frequency residuals.
The upsample block is an EC layer + PixelShuffle operation.
Parameters
----------
config : IQLUTConfig
"""
def __init__(self, config: IQLUTConfig):
super().__init__()
self.config = config
self.scale = config.scale
# Stack of L IQ-Blocks
# First block uses first_bit, all subsequent use later_bit
blocks = []
for i in range(config.n_layers):
bit_depth = config.first_bit if i == 0 else config.later_bit
blocks.append(IQBlock(
channels=config.channels,
bit_depth=bit_depth,
))
self.blocks = nn.ModuleList(blocks)
# Upsample EC layer: maps 1-channel features to scale²-channel features
# followed by PixelShuffle for spatial upsampling
self.upsample_ec = ExpandedConvLayer(
in_channels=1,
out_channels=config.scale ** 2,
hidden_channels=max(8, config.channels * 2),
)
self.pixel_shuffle = nn.PixelShuffle(config.scale)
def forward(self, x_lr: Tensor) -> Tensor:
"""
Parameters
----------
x_lr : (B, 1, H, W) — low-resolution input (grayscale Y channel)
Returns
-------
x_hr : (B, 1, H*scale, W*scale) — super-resolved output
"""
B, C, H, W = x_lr.shape
# Low-frequency baseline: bilinear upsampling
x_bilinear = F.interpolate(x_lr, scale_factor=self.scale, mode="bilinear", align_corners=False)
# Process through IQ-Block stack (residual learning)
x = x_lr
for block in self.blocks:
x = block(x)
# Upsample residual features via EC layer + PixelShuffle
x_up = self.upsample_ec(x) # (B, scale², H, W)
x_up = self.pixel_shuffle(x_up) # (B, 1, H*scale, W*scale)
# Combine: bilinear baseline + learned residual (mitigates reliance on bit-depth)
x_hr = x_bilinear + x_up
return x_hr.clamp(0.0, 1.0)
def count_lut_size_kb(self) -> float:
"""
Estimate total LUT storage size in kilobytes.
Each EC layer stores 2^bit_depth × out_features float32 values.
In deployment, values are quantized to output_bit (8-bit) integers.
"""
total_bytes = 0
for i, block in enumerate(self.blocks):
bit_depth = self.config.first_bit if i == 0 else self.config.later_bit
n_entries = 2 ** bit_depth
out_size = self.config.channels * block.dpfi.ec.k_h * block.dpfi.ec.k_w
bytes_per_entry = self.config.output_bit // 8 # 8-bit output = 1 byte
total_bytes += n_entries * out_size * bytes_per_entry
# Upsample EC
n_entries_up = 2 ** self.config.later_bit
out_up = self.config.scale ** 2 * 4 # k_h*k_w=4
total_bytes += n_entries_up * out_up
return total_bytes / 1024
# ─── SECTION 8: LUT Conversion Utility ────────────────────────────────────────
class LUTConverter:
"""
Converts trained IQ-LUT model to inference-ready lookup tables.
At inference time:
1. For each IQ-Block, pre-compute EC outputs for all 2^bit_depth quantized input values.
2. Store as flat arrays indexed by quantized input.
3. At runtime: apply NUQD to get floor/ceil indices, look up both, apply DPFI blend.
This completely eliminates the neural network forward pass at deployment time,
replacing it with table indexing — the key efficiency advantage for ASIC deployment.
"""
def __init__(self, model: IQLUT):
self.model = model
self.luts: Dict[str, Tensor] = {}
def convert(self) -> Dict[str, Tensor]:
"""
Build all lookup tables from the trained model.
Returns a dict mapping block names to their LUT tensors.
"""
self.model.eval()
with torch.no_grad():
for i, block in enumerate(self.model.blocks):
bit_depth = self.model.config.first_bit if i == 0 else self.model.config.later_bit
lut = block.dpfi.ec.to_lut(bit_depth)
self.luts[f"block_{i}"] = lut
print(f" Block {i}: bit={bit_depth} | LUT shape: {tuple(lut.shape)} | {lut.numel()*4/1024:.1f} KB")
# Upsample EC LUT
lut_up = self.model.upsample_ec.to_lut(self.model.config.later_bit)
self.luts["upsample"] = lut_up
print(f" Upsample: LUT shape: {tuple(lut_up.shape)}")
total_kb = sum(v.numel() * 4 / 1024 for v in self.luts.values())
print(f" Total LUT storage (float32): {total_kb:.1f} KB")
print(f" Total LUT storage (8-bit): {total_kb/4:.1f} KB")
return self.luts
def lut_inference(self, x_lr: Tensor, block_idx: int) -> Tensor:
"""
Run single-block inference using precomputed LUT (demonstration).
In production ASIC: this replaces the neural network entirely.
Each pixel value → NUQD → floor/ceil indices → LUT lookup → DPFI blend.
"""
key = f"block_{block_idx}"
if key not in self.luts:
raise ValueError(f"LUT not built for block {block_idx}. Call .convert() first.")
block = self.model.blocks[block_idx]
lut = self.luts[key]
# NUQD: get integer indices and interpolation weight
floor_idx, ceil_idx, T = block.nuqd.integer_indices(x_lr)
# LUT lookup for floor and ceil indices
B, C, H, W = x_lr.shape
f_flat = floor_idx.reshape(-1)
c_flat = ceil_idx.reshape(-1)
X_floor = lut[f_flat].reshape(B, C, H, W, -1)
X_ceil = lut[c_flat].reshape(B, C, H, W, -1)
# DPFI blend
T_exp = T.unsqueeze(-1)
F = (1.0 - T_exp) * X_floor + T_exp * X_ceil
return F.mean(dim=-1) # simplified: average over output features
# ─── SECTION 9: Two-Stage Training Loop ───────────────────────────────────────
class SRDataset(Dataset):
"""
Mock SR dataset for smoke testing.
Production: use DIV2K dataset (2,650 high-quality images from NTIRE 2017).
Download from: https://data.vision.ee.ethz.ch/cvl/DIV2K/
Training details (Section 3A):
- 1×10^6 total training iterations
- Adam optimizer (β1=0.9, β2=0.999), lr=1e-4
- LR halved at 200K, 400K, 600K, 800K iterations
- Loss: MSE (weight 1.0) + distillation (weight 3.0)
- Two stages: MSE convergence first, then NUQD + distillation fine-tuning
Evaluation (Section 3A):
- Set5, Set14, BSD100 (B100), Urban100, Manga109
- PSNR and SSIM on Y channel in YCbCr space
"""
def __init__(self, n_samples: int = 64, patch_size: int = 48, scale: int = 4):
self.n_samples = n_samples
self.patch_size = patch_size
self.scale = scale
def __len__(self):
return self.n_samples
def __getitem__(self, idx):
hr_size = self.patch_size * self.scale
hr = torch.rand(1, hr_size, hr_size) # HR patch (Y channel)
lr = F.avg_pool2d(hr, self.scale) # LR patch (downscaled)
return lr, hr
def compute_psnr(pred: Tensor, target: Tensor, max_val: float = 1.0) -> float:
"""Compute PSNR between predicted and target images."""
mse = F.mse_loss(pred, target).item()
if mse == 0:
return float("inf")
return 20 * math.log10(max_val) - 10 * math.log10(mse)
def train_iqlut(
config: IQLUTConfig,
device: torch.device,
n_train: int = 32,
n_val: int = 8,
pretrain_epochs: int = 2,
finetune_epochs: int = 2,
log_interval: int = 1,
) -> Tuple[IQLUT, IQLUT]:
"""
Full two-stage IQ-LUT training pipeline.
Stage 1 — MSE Pre-training:
Train student with MSE loss for initial convergence.
Stage 2 — NUQD + Distillation Fine-tuning:
Load frozen teacher (high-bit config), fine-tune student
with combined MSE + distillation loss. This is where the
3-bit quantization is activated and compensated via KD.
Parameters
----------
config : IQLUTConfig — student model configuration
device : torch.device
n_train : number of training samples (use full DIV2K in production)
n_val : validation samples
pretrain_epochs: Stage 1 epochs
finetune_epochs: Stage 2 epochs
log_interval : print every N epochs
Returns
-------
(student_model, teacher_model)
"""
print(f"\n{'='*60}")
print(f" IQ-LUT Training | {config.n_layers} blocks × {config.channels}ch")
print(f" First block: {config.first_bit}-bit | Subsequent: {config.later_bit}-bit")
print(f"{'='*60}\n")
# Build student and teacher models
student = IQLUT(config).to(device)
teacher_config = IQLUTConfig(
n_layers=config.n_layers, channels=config.channels, scale=config.scale,
first_bit=config.teacher_in_bit, later_bit=config.teacher_in_bit, # 8-bit teacher
output_bit=config.teacher_out_bit,
)
teacher = IQLUT(teacher_config).to(device)
n_student = sum(p.numel() for p in student.parameters())
n_teacher = sum(p.numel() for p in teacher.parameters())
est_lut = student.count_lut_size_kb()
print(f"Student NN params: {n_student:,} | Teacher NN params: {n_teacher:,}")
print(f"Estimated LUT storage: {est_lut:.1f} KB\n")
train_ds = SRDataset(n_samples=n_train, patch_size=config.patch_size, scale=config.scale)
val_ds = SRDataset(n_samples=n_val, patch_size=config.patch_size, scale=config.scale)
train_loader = DataLoader(train_ds, batch_size=config.batch_size, shuffle=True)
val_loader = DataLoader(val_ds, batch_size=config.batch_size, shuffle=False)
# ── Stage 1: MSE Pre-training ─────────────────────────────────────────────
print(f"[Stage 1] MSE Pre-training ({pretrain_epochs} epochs)...")
optimizer = torch.optim.Adam(student.parameters(), lr=config.lr, betas=(0.9, 0.999))
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=pretrain_epochs // 2 + 1, gamma=0.5)
student.train()
for epoch in range(1, pretrain_epochs + 1):
total_loss = 0.0
for lr_patch, hr_patch in train_loader:
lr_patch = lr_patch.to(device)
hr_patch = hr_patch.to(device)
sr_patch = student(lr_patch)
loss = F.mse_loss(sr_patch, hr_patch)
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_loss += loss.item()
scheduler.step()
if epoch % log_interval == 0:
avg_psnr = _eval_psnr(student, val_loader, device)
print(f" Stage1 Epoch {epoch}/{pretrain_epochs} | loss={total_loss/len(train_loader):.6f} | PSNR={avg_psnr:.2f} dB")
# ── Stage 2: Distillation Fine-tuning ─────────────────────────────────────
print(f"\n[Stage 2] Distillation Fine-tuning ({finetune_epochs} epochs)...")
# Pre-train teacher briefly for demonstration (in production: load saved teacher)
teacher_opt = torch.optim.Adam(teacher.parameters(), lr=config.lr, betas=(0.9, 0.999))
teacher.train()
for lr_p, hr_p in train_loader:
lr_p, hr_p = lr_p.to(device), hr_p.to(device)
loss = F.mse_loss(teacher(lr_p), hr_p)
teacher_opt.zero_grad()
loss.backward()
teacher_opt.step()
break # single step for demo
# Freeze teacher
for p in teacher.parameters():
p.requires_grad = False
teacher.eval()
optimizer2 = torch.optim.Adam(student.parameters(), lr=config.lr * 0.5, betas=(0.9, 0.999))
student.train()
for epoch in range(1, finetune_epochs + 1):
total_loss = 0.0
for lr_patch, hr_patch in train_loader:
lr_patch = lr_patch.to(device)
hr_patch = hr_patch.to(device)
sr_student = student(lr_patch)
with torch.no_grad():
sr_teacher = teacher(lr_patch)
# Combined loss: MSE + distillation (distillation weight = 3.0)
loss_mse = F.mse_loss(sr_student, hr_patch)
loss_distill = F.mse_loss(sr_student, sr_teacher)
loss = config.mse_weight * loss_mse + config.distill_weight * loss_distill
optimizer2.zero_grad()
loss.backward()
optimizer2.step()
total_loss += loss.item()
if epoch % log_interval == 0:
avg_psnr = _eval_psnr(student, val_loader, device)
print(f" Stage2 Epoch {epoch}/{finetune_epochs} | loss={total_loss/len(train_loader):.6f} | PSNR={avg_psnr:.2f} dB")
print(f"\nTraining complete.")
return student, teacher
@torch.no_grad()
def _eval_psnr(model: IQLUT, loader: DataLoader, device: torch.device) -> float:
"""Compute average PSNR on validation set."""
model.eval()
total_psnr = 0.0
for lr_p, hr_p in loader:
sr = model(lr_p.to(device))
total_psnr += compute_psnr(sr.cpu(), hr_p)
model.train()
return total_psnr / len(loader)
# ─── SECTION 10: Smoke Test ───────────────────────────────────────────────────
if __name__ == "__main__":
print("=" * 60)
print("IQ-LUT — Full Framework Smoke Test")
print("=" * 60)
torch.manual_seed(42)
device = torch.device("cpu")
# ── 1. Piecewise-Linear Transform ────────────────────────────────────────
print("\n[1/7] Piecewise-Linear Transform T_{a,b}...")
T_fn = PiecewiseLinearTransform(a=0.5, b=0.7)
x_test = torch.linspace(-1.0, 1.0, 100)
y_test = T_fn(x_test)
x_rec = T_fn.inverse(y_test)
assert y_test.min() >= -1.01 and y_test.max() <= 1.01
recon_err = (x_test - x_rec).abs().max().item()
assert recon_err < 1e-4, f"Inverse transform error: {recon_err}"
print(f" Transform range: [{y_test.min():.3f}, {y_test.max():.3f}] ✓")
print(f" Max reconstruction error: {recon_err:.2e} ✓")
best_a, best_b = PiecewiseLinearTransform.greedy_search(torch.randn(500) * 0.3)
print(f" Greedy search result: a={best_a}, b={best_b} ✓")
# ── 2. NUQD Module ────────────────────────────────────────────────────────
print("\n[2/7] NUQD Non-Uniform Quantization...")
nuqd = NUQD(bit_depth=4, a=0.5, b=0.7)
x_nuqd = torch.randn(2, 1, 8, 8) * 0.5
x_floor, x_ceil, T = nuqd(x_nuqd)
assert T.min() >= 0.0 and T.max() <= 1.0 + 1e-5
assert x_floor.shape == x_nuqd.shape
assert x_ceil.shape == x_nuqd.shape
print(f" x_floor: {tuple(x_floor.shape)} | x_ceil: {tuple(x_ceil.shape)} | T ∈ [0,1] ✓")
print(f" 4-bit: {2**4} quantization levels | NUQD focuses precision near zero ✓")
# ── 3. EC Layer & DPFI ────────────────────────────────────────────────────
print("\n[3/7] Expanded Convolution + DPFI...")
ec = ExpandedConvLayer(in_channels=1, out_channels=8, hidden_channels=16, k_h=2, k_w=2)
dpfi = DPFI(ec)
x_in = torch.randn(2, 1, 8, 8)
x_f, x_c, Tw = nuqd(x_in)
F_out = dpfi(x_f, x_c, Tw)
assert F_out.shape[0] == 2 and F_out.shape[1] == 8
print(f" EC in: (2,1,8,8) → DPFI out: {tuple(F_out.shape)} ✓")
print(f" DPFI: two lookups + one weighted blend (no extra storage needed) ✓")
# ── 4. IQ-Block ───────────────────────────────────────────────────────────
print("\n[4/7] IQ-Block (NUQD + DPFI + Residual Gate)...")
block = IQBlock(channels=8, bit_depth=4)
x_block = torch.randn(2, 1, 16, 16)
x_out = block(x_block)
assert x_out.shape == x_block.shape
print(f" IQ-Block: {tuple(x_block.shape)} → {tuple(x_out.shape)} ✓")
print(f" Learnable gate α = {block.alpha.item():.4f} (σ(α) = {torch.sigmoid(block.alpha).item():.4f}) ✓")
# ── 5. Full IQ-LUT Models ─────────────────────────────────────────────────
print("\n[5/7] Full IQ-LUT models (L8C8, L8C16)...")
for name, L, C in [("IQ-L8C8", 8, 8), ("IQ-L8C16", 8, 16)]:
cfg = IQLUTConfig(n_layers=L, channels=C, scale=4, patch_size=16, batch_size=2)
model = IQLUT(cfg)
lr_img = torch.rand(1, 1, 16, 16)
hr_img = model(lr_img)
assert hr_img.shape == (1, 1, 64, 64), f"Shape error: {hr_img.shape}"
n_params = sum(p.numel() for p in model.parameters())
lut_est = model.count_lut_size_kb()
print(f" {name}: NN params={n_params:,} | Est. LUT={lut_est:.1f} KB | Output: {tuple(hr_img.shape)} ✓")
assert hr_img.min() >= 0.0 and hr_img.max() <= 1.0 + 1e-5
# ── 6. LUT Conversion ─────────────────────────────────────────────────────
print("\n[6/7] LUT Conversion (training → inference)...")
cfg_small = IQLUTConfig(n_layers=2, channels=4, scale=4, first_bit=4, later_bit=3)
model_small = IQLUT(cfg_small)
converter = LUTConverter(model_small)
luts = converter.convert()
assert "block_0" in luts and "upsample" in luts
print(f" Built {len(luts)} lookup tables successfully ✓")
# ── 7. Full Training Run ──────────────────────────────────────────────────
print("\n[7/7] Full two-stage training run (mini, 2+2 epochs)...")
cfg_train = IQLUTConfig(
n_layers=2, channels=4, scale=2,
first_bit=4, later_bit=3, output_bit=8,
lr=1e-3, patch_size=16, batch_size=4,
mse_weight=1.0, distill_weight=3.0,
)
student, teacher = train_iqlut(
cfg_train, device,
n_train=8, n_val=4,
pretrain_epochs=2, finetune_epochs=2,
)
print("\n" + "=" * 60)
print("✓ All IQ-LUT checks passed. Framework is ready for use.")
print("=" * 60)
print("""
Next steps to reproduce paper results:
1. Download DIV2K training dataset:
https://data.vision.ee.ethz.ch/cvl/DIV2K/
(800 training + 100 validation 2K images)
2. Download benchmark test sets:
Set5, Set14, BSD100, Urban100, Manga109
3. Use full paper configurations:
IQ-L8C8: IQLUTConfig(n_layers=8, channels=8, scale=4)
IQ-L12C8: IQLUTConfig(n_layers=12, channels=8, scale=4)
IQ-L8C16: IQLUTConfig(n_layers=8, channels=16, scale=4)
4. Training schedule:
Total: 1×10^6 iterations
Adam: β1=0.9, β2=0.999, lr=1e-4
LR halved at 200K, 400K, 600K, 800K
Stage 1 (MSE): converge first
Stage 2 (NUQD + distillation): loss = 1.0×MSE + 3.0×distill
5. Teacher for distillation:
Same architecture with first_bit=8, later_bit=8, output_bit=12
Pre-trained on same DIV2K data, frozen during student fine-tuning
6. Expected results (IQ-L8C16, ×4 SR):
Set5 PSNR: 31.50 dB (vs ECNN-L8C8: 31.06 dB, 12× larger)
Set14 PSNR: 28.12 dB
B100 PSNR: 27.22 dB
Urban100 PSNR: 25.14 dB
Manga109 PSNR: 29.17 dB
Storage: 124 KB (vs ECNN-L8C8: 1516 KB)
""")
Read the Full Paper
The complete study — including qualitative texture recovery comparisons, latency analysis on GPU versus ASIC, and full ablation tables for all configurations — is available on arXiv.
Zhang, Y., Dong, Z., Chai, X., Zhou, X., Xu, Y., Cheng, Z., & Song, L. (2026). IQ-LUT: Interpolated and Quantized LUT for Efficient Image Super-Resolution. arXiv:2604.07000v1 [cs.CV]. Shanghai Jiao Tong University & Rockchip Electronics.
This article is an independent editorial analysis of peer-reviewed research. The Python implementation is an educational adaptation. The original authors trained on an NVIDIA GeForce RTX 3090 for 1×10^6 iterations. Full replication requires the DIV2K training dataset and the complete iteration schedule. The 50× storage reduction claim refers to IQ-L8C8 (34 KB) versus ECNN-L8C8 (1,516 KB).
Explore More on AI Trend Blend
If this article caught your attention, here is more of what we cover — from edge AI and model compression to image restoration, knowledge distillation, and hardware-efficient deep learning.