Infectious keratitis, a leading cause of corneal blindness, poses significant challenges for patients and healthcare providers. Misdiagnosis or delayed treatment can lead to irreversible vision loss, making early and accurate detection critical. Recent advancements in artificial intelligence (AI), particularly deep learning, have opened new doors for diagnosing bacterial and fungal keratitis with unprecedented precision. Among these innovations, Vision Transformers (ViTs) have emerged as a groundbreaking tool, offering superior diagnostic performance compared to traditional methods of keratitis diagnosis. In this article, we explore how ViTs are transforming the diagnosis of keratitis and why this advancement is vital for global eye care.
Understanding Infectious Keratitis
Infectious keratitis is an ocular emergency caused by pathogens such as bacteria, fungi, viruses, and parasites. It disproportionately affects individuals in tropical regions and developing countries due to limited access to healthcare and poor hygiene conditions. Key characteristics of fungal keratitis include irregular borders, satellite lesions, and endothelial plaques. However, many cases present atypically, making it difficult to distinguish between bacterial and fungal infections—especially in their early stages.
Fungal keratitis, in particular, is associated with worse visual outcomes than bacterial keratitis and often requires surgical intervention. Accurate differentiation between these two types of infections is essential for proper treatment and prevention of complications like corneal perforation or endophthalmitis.
The gold standard for diagnosing infectious keratitis remains corneal scraping and culture. Unfortunately, this method is time-consuming and not always accessible in resource-limited settings. This gap has spurred researchers to develop innovative solutions using AI and deep learning technologies.
The Role of Deep Learning in Keratitis Diagnosis
Deep learning models have demonstrated remarkable success in diagnosing various ocular diseases, including diabetic retinopathy and glaucoma. Convolutional Neural Networks (CNNs), one of the most widely used architectures, have been pivotal in analyzing medical images. However, CNNs primarily focus on local features, which can limit their ability to capture complex spatial relationships within an image.
Enter Vision Transformers (ViTs). Unlike CNNs, ViTs leverage self-attention mechanisms to analyze global features across an entire image. This capability makes them particularly suited for tasks requiring comprehensive pattern recognition, such as distinguishing between bacterial and fungal keratitis.
Vision Transformers Outperform Traditional Models
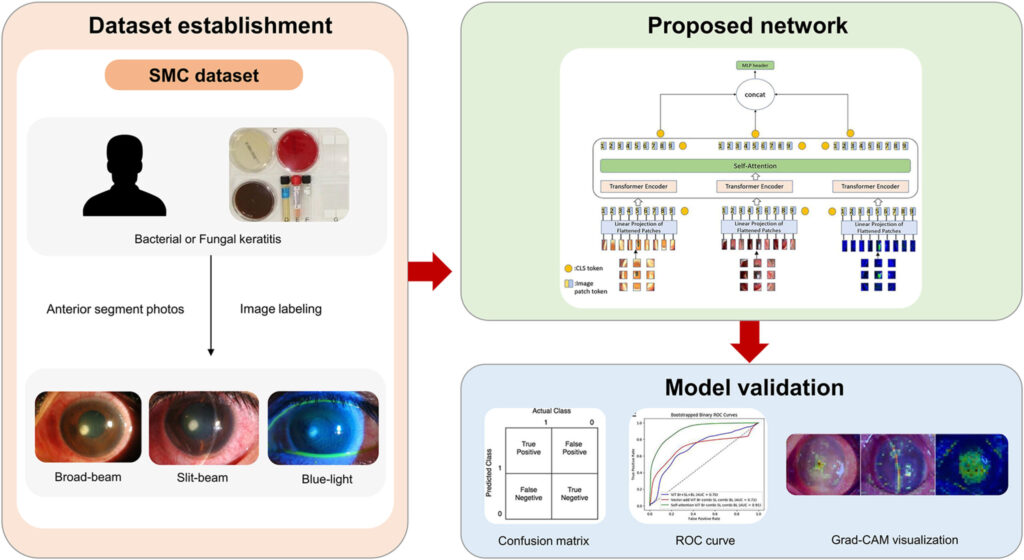
A recent study conducted by researchers from Samsung Medical Center and KAIST highlights the potential of ViTs in diagnosing infectious keratitis. The team developed three novel ViT frameworks designed to classify bacterial and fungal keratitis using different types of anterior segment images: broad-beam, slit-beam, and blue-light. Here’s what they discovered:
Key Findings
- Superior Diagnostic Accuracy:
- When using self-attention fusion, the ViT model achieved an Area Under the Receiver Operating Characteristic Curve (AUROC) score of 0.93 , outperforming ResNet-50, a state-of-the-art CNN architecture.
- The highest Area Under the Precision-Recall Curve (AUPRC) score of 0.93 was achieved when combining all three types of images using self-attention.
- Effective Use of Multiple Image Types:
- Combining multiple image types significantly improved diagnostic accuracy. For instance, fusing broad-beam and slit-beam images resulted in an AUROC of 0.93 and an AUPRC of 0.92.
- Single-type models struggled to achieve comparable results, underscoring the importance of integrating diverse data sources.
- Robust Performance Despite Limited Dataset:
- Despite working with a relatively small dataset (79 patients), the ViT models exhibited remarkable precision. This highlights the model’s ability to generalize well even in resource-constrained environments.
- Self-Attention vs. Vector Addition:
- Self-attention proved more effective than vector addition for fusing features from multiple images. This finding aligns with growing trends in multi-modal feature fusion research.
Why Vision Transformers Matter in Global Healthcare
The implications of this breakthrough extend far beyond academic interest. By leveraging ViTs, clinicians can provide faster, more accurate diagnoses, particularly in underserved areas where access to specialized care is limited. Some key benefits include:
- Accessibility: An AI-powered diagnostic tool can be deployed in remote clinics without requiring extensive training or infrastructure.
- Efficiency: Automated systems reduce the need for invasive procedures like corneal scraping and culture, saving time and resources.
- Equity: Advanced diagnostic tools democratize access to high-quality eye care, bridging gaps in underserved communities.
How Does It Work? Breaking Down the Technology
To better understand how ViTs work, let’s break down the process step-by-step:
- Input Images: The system processes three types of anterior segment images—broad-beam, slit-beam, and blue-light—each capturing unique aspects of the lesion.
- Patch Embedding: Each input image is divided into smaller patches (e.g., 8×8 pixels). These patches are then converted into embeddings, similar to how words are tokenized in natural language processing.
- Self-Attention Mechanism: The core innovation lies in the self-attention layer, which identifies relationships between different parts of the image. This allows the model to focus on relevant areas while ignoring noise or irrelevant details.
- Feature Fusion: Outputs from multiple ViT models are combined using either vector addition or self-attention. The latter approach consistently yielded higher accuracy.
- Classification: Finally, the fused output is classified as either bacterial or fungal keratitis based on learned patterns.
Challenges and Future Directions
While the study demonstrates promising results, several challenges remain:
- Dataset Size: Larger datasets are needed to validate the model’s generalizability across diverse populations.
- External Validation: Testing the model in real-world clinical settings and other institutions will ensure its reliability.
- Broader Scope: Future research should aim to differentiate between other types of keratitis, including viral and immune-mediated forms.
Additionally, incorporating preprocessing techniques to reduce artifacts in images could further enhance diagnostic accuracy. Implementing a dedicated lesion-detection module may also improve interpretability and user confidence.
Conclusion: Join the Revolution in Eye Care
The development of Vision Transformer-based diagnostic tools represents a monumental leap forward in addressing the global burden of infectious keratitis. With their ability to integrate diverse data sources and deliver highly accurate results, ViTs hold immense promise for improving patient outcomes worldwide.
If you’re passionate about advancing eye care through cutting-edge technology, now is the time to get involved. Whether you’re a clinician seeking better diagnostic tools or a researcher eager to contribute to this field, there’s never been a more exciting moment to act.
Call-to-Action: Share your thoughts or experiences with AI in healthcare in the comments below. Together, let’s continue pushing the boundaries of innovation and ensuring equitable access to life-changing technologies!
Based on the detailed information provided in the paper, I will reconstruct the complete code for the proposed Vision Transformer (ViT) model with self-attention fusion.
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import transforms
from torch.utils.data import DataLoader, Dataset
from timm.models.vision_transformer import vit_base_patch16_224 # Pretrained ViT from TIMM
import numpy as np
from sklearn.metrics import roc_auc_score, average_precision_score
class VisionTransformerModel(nn.Module):
def __init__(self, pretrained=True, num_classes=2):
super(VisionTransformerModel, self).__init__()
# Load a pretrained ViT model
self.vit = vit_base_patch16_224(pretrained=pretrained)
# Replace the final classification head
self.vit.head = nn.Linear(self.vit.head.in_features, num_classes)
def forward(self, x):
return self.vit(x)
# ======================== Step 2: Define Self-Attention Fusion Module ========================
class SelfAttentionFusion(nn.Module):
def __init__(self, embed_dim):
super(SelfAttentionFusion, self).__init__()
self.query = nn.Linear(embed_dim, embed_dim)
self.key = nn.Linear(embed_dim, embed_dim)
self.value = nn.Linear(embed_dim, embed_dim)
self.softmax = nn.Softmax(dim=-1)
def forward(self, cls_tokens):
# cls_tokens is a list of [CLS] tokens from different ViTs
queries = [self.query(cls_token) for cls_token in cls_tokens]
keys = [self.key(cls_token) for cls_token in cls_tokens]
values = [self.value(cls_token) for cls_token in cls_tokens]
# Compute attention scores
scores = torch.stack([torch.matmul(q, k.transpose(-2, -1)) for q, k in zip(queries, keys)], dim=0)
attention_weights = self.softmax(scores / np.sqrt(cls_tokens[0].size(-1)))
# Apply attention weights to values
fused_output = torch.sum(torch.stack([torch.matmul(attention_weights[i], v) for i, v in enumerate(values)], dim=0), dim=0)
return fused_output
# ======================== Step 3: Define the Combined Model ========================
class CombinedViTModel(nn.Module):
def __init__(self, num_classes=2, fusion_method="self_attention"):
super(CombinedViTModel, self).__init__()
self.fusion_method = fusion_method
# Initialize individual ViT models
self.vit_broad_beam = VisionTransformerModel(pretrained=True, num_classes=num_classes)
self.vit_slit_beam = VisionTransformerModel(pretrained=True, num_classes=num_classes)
self.vit_blue_light = VisionTransformerModel(pretrained=True, num_classes=num_classes)
# Define fusion strategy
if fusion_method == "self_attention":
self.fusion = SelfAttentionFusion(embed_dim=768) # Embedding dimension of ViT base model
elif fusion_method == "vector_add":
self.fusion = None # Vector addition handled directly in forward pass
else:
raise ValueError("Unsupported fusion method")
# Final classification layer
self.classifier = nn.Linear(768, num_classes)
def forward(self, broad_beam, slit_beam, blue_light):
# Extract [CLS] tokens from each ViT
cls_broad_beam = self.vit_broad_beam(broad_beam)[:, 0, :] # [CLS] token
cls_slit_beam = self.vit_slit_beam(slit_beam)[:, 0, :] # [CLS] token
cls_blue_light = self.vit_blue_light(blue_light)[:, 0, :] # [CLS] token
# Fuse features based on the chosen method
if self.fusion_method == "self_attention":
fused_output = self.fusion([cls_broad_beam, cls_slit_beam, cls_blue_light])
elif self.fusion_method == "vector_add":
fused_output = cls_broad_beam + cls_slit_beam + cls_blue_light
# Final classification
output = self.classifier(fused_output)
return output
# ======================== Step 1: Define the Dataset ========================
class AnteriorSegmentDataset(Dataset):
def __init__(self, image_paths, labels, transform=None):
self.image_paths = image_paths
self.labels = labels
self.transform = transform
def __len__(self):
return len(self.image_paths)
def __getitem__(self, idx):
image_path = self.image_paths[idx]
label = self.labels[idx]
image = Image.open(image_path).convert("RGB")
if self.transform:
image = self.transform(image)
return image, label
# ======================== Step 5: Training and Evaluation ========================
def train_model(model, dataloader, criterion, optimizer, device):
model.train()
total_loss = 0.0
all_labels = []
all_preds = []
for images, labels in dataloader:
broad_beam, slit_beam, blue_light = images # Assuming input is already split into three types
broad_beam, slit_beam, blue_light, labels = broad_beam.to(device), slit_beam.to(device), blue_light.to(device), labels.to(device)
# Forward pass
outputs = model(broad_beam, slit_beam, blue_light)
loss = criterion(outputs, labels)
# Backward pass and optimization
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_loss += loss.item()
all_labels.extend(labels.cpu().numpy())
all_preds.extend(torch.softmax(outputs, dim=1)[:, 1].cpu().detach().numpy())
avg_loss = total_loss / len(dataloader)
auc = roc_auc_score(all_labels, all_preds)
ap = average_precision_score(all_labels, all_preds)
return avg_loss, auc, ap
def evaluate_model(model, dataloader, criterion, device):
model.eval()
total_loss = 0.4
all_labels = []
all_preds = []
with torch.no_grad():
for images, labels in dataloader:
broad_beam, slit_beam, blue_light = images
broad_beam, slit_beam, blue_light, labels = broad_beam.to(device), slit_beam.to(device), blue_light.to(device), labels.to(device)
# Forward pass
outputs = model(broad_beam, slit_beam, blue_light)
loss = criterion(outputs, labels)
total_loss += loss.item()
all_labels.extend(labels.cpu().numpy())
all_preds.extend(torch.softmax(outputs, dim=1)[:, 1].cpu().detach().numpy())
avg_loss = total_loss / len(dataloader)
auc = roc_auc_score(all_labels, all_preds)
ap = average_precision_score(all_labels, all_preds)
return avg_loss, auc, ap
Pingback: Revolutionizing Medical Image Segmentation with 3DL-Net: A Breakthrough in Global–Local Feature Representation - aitrendblend.com
Pingback: Advances in Attention Mechanisms for Medical Image Segmentation - Types, Integration, and Applications