MaRI: The Structural Re-parameterization Breakthrough That Eliminated Redundant Computation in Kuaishou’s Ranking Models
How a team of researchers at Kuaishou discovered that the biggest bottleneck in recommendation inference wasn’t model size or hardware—it was a mathematical redundancy hiding in plain sight, and how they fixed it without retraining a single parameter.
In the high-stakes world of large-scale recommendation systems, every millisecond of inference latency translates directly to user engagement and revenue. For years, engineers at major platforms like Kuaishou have battled the fundamental tension between model complexity and serving speed—compressing models, quantizing weights, and optimizing kernels. Yet a team of researchers recently discovered that one of the most significant performance drains wasn’t the model’s sophistication or the hardware’s limitations, but a structural inefficiency so obvious in retrospect that it had been overlooked entirely: the redundant recomputation of user features across thousands of candidate items.
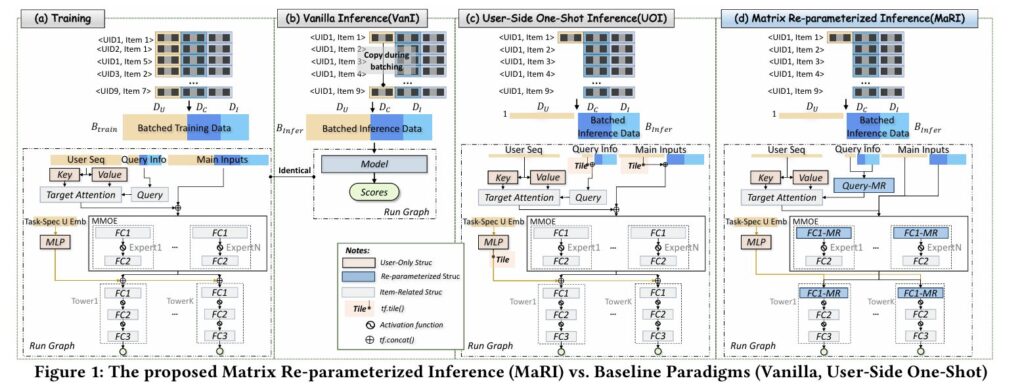
Their solution, MaRI (Matrix Re-parameterized Inference), doesn’t require model retraining, architectural changes, or hardware upgrades. Instead, it applies the mathematical principle of structural re-parameterization to decompose feature fusion operations, eliminating redundant user-side matrix multiplications while preserving exact numerical equivalence. Deployed across Kuaishou’s live-streaming recommendation infrastructure, MaRI achieved a 1.3× inference speedup and 5.9% resource reduction in coarse-ranking stages—all without a single digit of accuracy loss.
What makes this work particularly compelling is its surgical precision. Unlike coarse-grained acceleration techniques that trade accuracy for speed, MaRI exploits a specific algebraic property of ranking model inference: user features are identical across all candidate items in a batch, yet traditional implementations compute their transformations repeatedly. By restructuring the matrix multiplication to compute user projections once and tile the results, MaRI transforms an \(O(B \cdot D_u)\) operation into \(O(D_u)\), where \(B\) often exceeds thousands in industrial settings.
The Hidden Redundancy: Why Ranking Models Waste Cycles
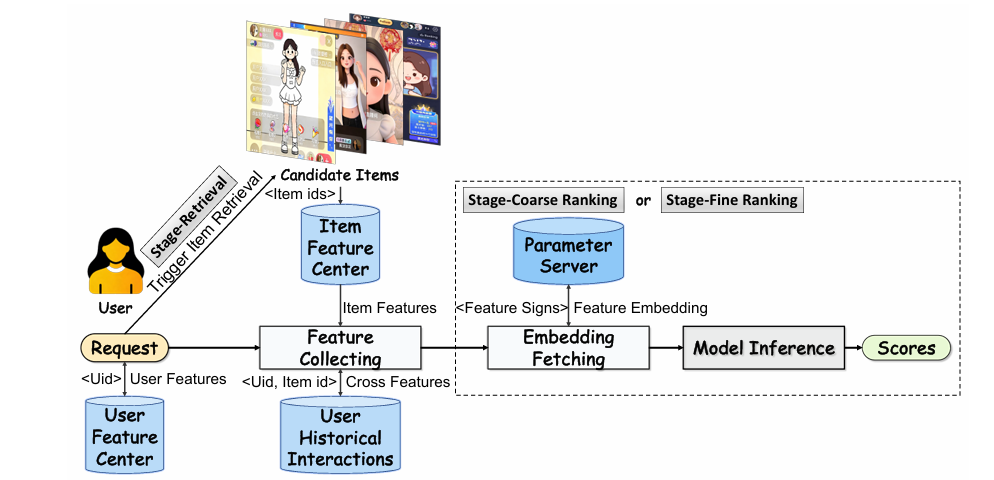
Modern industrial recommendation systems operate as sophisticated assembly lines. When a user opens Kuaishou, the system must evaluate thousands of candidate videos through a multi-stage pipeline: retrieval narrows the field to manageable candidates, coarse-ranking scores thousands of items under tight latency constraints, and fine-ranking performs precise predictions on the final hundred or so selections. Each stage relies on deep neural networks that fuse user features, item features, and cross-features through matrix multiplications—operations that dominate inference latency.
The architectural pattern seems straightforward: concatenate user features \(X_{user} \in \mathbb{R}^{1 \times D_u}\), item features \(X_{item} \in \mathbb{R}^{B \times D_i}\), and cross-features \(X_{cross} \in \mathbb{R}^{B \times D_c}\), then multiply by a weight matrix \(W \in \mathbb{R}^{D \times d}\) where \(D = D_u + D_i + D_c\). This concatenated approach enables rich feature interactions but conceals a computational trap.
In traditional Vanilla Inference (VanI), the system replicates user features \(B\) times to match the batch dimension, creating \(X_{user}^{Tiled} \in \mathbb{R}^{B \times D_u}\). When this tiled tensor enters matrix multiplication layers, the user-side projections are computed \(B\) times identically. For a user sequence feature with dimension \(D_{u_s}\) processed through attention mechanisms, the key and value projections execute redundant operations:
Here, the projections \(X_{u_s}^{Tiled}W_K\) and \(X_{u_s}^{Tiled}W_V\) perform identical computations \(B\) times, wasting \(B-1\) redundant passes. For batches of thousands of candidates, this redundancy becomes substantial.
The User-Side One-Shot Inference (UOI) paradigm—already deployed at Kuaishou—partially addresses this by deferring user feature tiling until just before concatenation. This eliminates redundancy in attention projections but leaves matrix multiplications in MLP layers and expert networks still performing redundant user-side computations. The insight behind MaRI is simple yet powerful: why stop at partial optimization when complete algebraic decomposition can eliminate all redundancy?
MaRI identifies that user-side computation in feature fusion is inherently redundant—the same user features are transformed identically across all candidate items. By applying structural re-parameterization to decompose MatMul operations into separate user, item, and cross components, MaRI achieves lossless acceleration without model retraining.
Structural Re-parameterization: The Mathematics of Efficiency
The theoretical foundation of MaRI rests on a fundamental property of matrix multiplication: block decomposition. Consider a weight matrix \(W\) partitioned by feature domains:
Traditional MatMul computes \(X^{U\_Tiled}W\) directly, where \(X^{U\_Tiled} = [X_{user}^{Tiled}, X_{item}, X_{cross}]\). By the distributive property of matrix multiplication, this decomposes into three independent terms:
The critical observation: \(X_{user}^{Tiled}W_{user}\) represents \(B\) identical computations of \(X_{user}W_{user}\). MaRI re-parameterizes this as:
This reformulation reduces FLOPs by approximately \(D_u / (D_u + D_i + D_c)\) for large batches—a significant saving when user features comprise substantial portions of the input dimension. Critically, because the tiling operation simply broadcasts the computed result rather than recomputing projections, the mathematical output remains bit-for-bit identical to the original computation.
The efficiency gains compound across model architectures. In Multi-Gate Mixture-of-Experts (MMoE) structures, each expert’s first fully-connected layer benefits from this decomposition. In task-specific towers and cross-attention query projections, the same principle applies. The result is a hardware-agnostic acceleration that requires no model retraining—only a structural reorganization of how existing computations are ordered.
“We adopt the philosophy of structural reparameterization to alleviate user-side redundancy. Being hardware-agnostic, our method offers a novel complementary angle for research on efficient inference in RS.” — Huang et al., arXiv:2602.23105v1
Automating Optimization: The Graph Coloring Algorithm
Industrial ranking models at Kuaishou have evolved over years of iterative development, accumulating intricate structures that make manual optimization daunting. A model may contain hundreds of MatMul operations across attention mechanisms, expert networks, and projection layers—not all eligible for MaRI transformation. Manually identifying which operations can be decomposed requires tracing data flows through concatenation nodes, verifying that user features remain untiled until the decomposition point, and ensuring that downstream operations maintain correctness.
To solve this, the researchers developed the Graph Coloring Algorithm (GCA), an automated method for locating MaRI-optimizable nodes within computation graphs. GCA operates in three phases:
Initialization: Each feature node in the computation graph receives an initial color—Yellow for user-side features, Blue for item and cross features, Uncolored for intermediate states.
Color Propagation: Through depth-first search, colors propagate downstream. Blue dominates: if any input to an operation is Blue, the output becomes Blue. Yellow only propagates to previously uncolored nodes, preserving the distinction between user-origin and mixed features.
Target Detection: The algorithm identifies “Concat” nodes receiving both Yellow and Blue inputs—the precise points where user and item features merge. From these merge points, GCA traces backward through non-computational paths to locate all reachable MatMul nodes, which become candidates for MaRI transformation.
In practice, GCA proved remarkably effective. When initially deployed, engineers had manually identified only the first FC layer of each MMoE expert as optimizable. GCA automatically discovered additional opportunities in task tower projections and cross-attention query components—validating the algorithm’s value for complex, evolving model architectures.
The Bitter Lesson: Why Neatness Matters More Than You’d Think
Perhaps the most surprising finding in MaRI’s development was the critical importance of input layout organization. Industrial models rarely maintain clean feature separations; years of feature engineering have interleaved user, item, and cross features arbitrarily:
Applying MaRI directly to such fragmented layouts creates numerous small MatMul operations rather than three large, efficient ones. The performance degradation was severe: 38.8% slower than the already-optimized UOI baseline. This “fragmentation penalty” occurs because modern hardware and kernel libraries are optimized for large, contiguous matrix operations—not a scattershot collection of tiny multiplications.
The solution required feature and parameter reorganization: remapping the input layout to group all user features, followed by all item features, then all cross features, with corresponding permutations of weight matrix rows. This preprocessing step transforms the chaotic interleaving into the clean structure of Equation 4, enabling MaRI to generate exactly three large MatMul operations that hardware can execute efficiently.
This discovery carries broader implications for model design. It suggests that inference efficiency depends not only on algorithmic complexity but on data layout coherence—a factor often neglected in research prototypes but brutally punished in production systems. The 38% degradation figure serves as a cautionary tale: mathematical equivalence does not guarantee computational equivalence when hardware realities intrude.
A fragmented input layout causes nearly 38% performance degradation despite mathematical equivalence. MaRI requires careful feature and parameter reorganization to achieve its full potential—a practical lesson that separates theoretical algorithms from deployable systems.
Experimental Validation: From Simulation to Production
MaRI’s validation followed a rigorous path from controlled offline simulation to live A/B testing serving hundreds of millions of users.
Offline Simulation: Parameter Sensitivity Analysis
Controlled experiments varying batch sizes, feature dimensions, and hidden layer sizes revealed consistent patterns:
- Batch Size Stability: For \(B \geq 500\), runtime speedup stabilizes at approximately 1.1×, indicating MaRI’s reliability for large-scale candidate pools typical in industrial coarse-ranking.
- User Feature Dominance: As \(D_{user}\) increases, FLOPs reduction grows linearly, peaking at 10.95× theoretical speedup and 1.58× actual runtime improvement when user features dominate the input dimension.
- Item Feature Trade-offs: Conversely, increasing \(D_{item}\) or \(D_{cross}\) diminishes relative gains, as MaRI specifically optimizes user-side redundancy. When item features dominate, the optimization naturally has less impact.
- Hidden Dimension Scaling: Surprisingly, runtime speedup increases with hidden dimension size (from 1.10× at 64 dimensions to 1.58× at 2048), suggesting that larger matrix operations better amortize the overhead of MaRI’s decomposition.
Fragmentation Impact Quantification
Systematic decomposition of neat inputs into chunks of varying sizes confirmed the criticality of layout organization. At chunk size 50 (highly fragmented), latency increased by 69.4% compared to original MatMul and 96.3% compared to neatly-structured MaRI. Even at chunk size 800, a 15.1% degradation persisted versus the optimal layout. These results established strict requirements for feature reorganization in production deployment.
Online Deployment: Production-Scale Validation
From June 21–24, 2025, MaRI ran in live A/B tests across Kuaishou and Kuaishou Lite, each serving 5% of total traffic. The experimental group used MaRI-optimized models; the control group used the standard UOI method. Both employed identical industrial inference engines and acceleration tools for fair comparison.
| Metric | Kuaishou | Kuaishou Lite | Details |
|---|---|---|---|
| Coarse-ranking Latency Reduction | -2.24% | -2.27% | End-to-end stage latency |
| Overall Pipeline Latency | -0.42% | -0.54% | Full recommendation pipeline |
| Inference Speedup (Avg) | 1.32× | Model RunGraph time | |
| Inference Speedup (P99) | 1.26× | Tail latency improvement | |
| Resource Reduction | 5.9% | Hardware resources, full deployment | |
Table 1: Online A/B test results comparing MaRI-optimized models against UOI baseline. Core business metrics showed no statistically significant differences, confirming lossless accuracy.
Most critically, core business metrics remained statistically identical between experimental and control groups—confirming that MaRI’s structural changes preserved model behavior exactly. The 5.9% resource reduction in full deployment (July 4, 2025) translated directly to infrastructure cost savings at massive scale.
Implications for Industrial Recommendation
MaRI’s success challenges several assumptions prevalent in model acceleration research. First, it demonstrates that lossless acceleration remains achievable through careful algorithmic restructuring, without resorting to quantization, pruning, or knowledge distillation that inevitably trade accuracy for speed. The 1.3× speedup with zero accuracy loss contrasts sharply with typical distillation approaches that sacrifice several percentage points of AUC for similar gains.
Second, MaRI highlights the untapped potential of structural re-parameterization in recommendation systems. While this technique has transformed computer vision (RepVGG, RepMLPNet), its application to ranking models opens a complementary optimization dimension orthogonal to hardware-specific kernel tuning. Being hardware-agnostic, MaRI benefits automatically from improvements in underlying linear algebra libraries and accelerator architectures.
Third, the work underscores the importance of automated optimization. The Graph Coloring Algorithm’s ability to discover optimization opportunities missed by manual analysis suggests that production models have become too complex for ad-hoc tuning. Future acceleration frameworks will likely rely increasingly on automated graph analysis to navigate intricate computation structures.
Finally, the fragmentation lesson serves as a reminder that data layout is a first-class optimization target. Researchers proposing new algorithms must account for memory access patterns and kernel efficiency, not just asymptotic complexity. The gap between theoretical FLOPs reduction and realized speedup often lies in these practical details.
What This Work Actually Means
The central achievement of MaRI is demonstrating that sometimes the most powerful optimizations hide not in new architectures or larger datasets, but in recognizing and eliminating redundant computation that has become invisible through convention. The practice of tiling user features and computing projections batch-wise is so standard that it took a deliberate re-examination of matrix multiplication algebra to expose its inefficiency.
For practitioners, MaRI offers a deployable template: identify invariant computations across batch dimensions, decompose them via structural re-parameterization, and reorganize data layouts to match hardware expectations. The framework’s integration with existing training pipelines—requiring no retraining—makes it particularly attractive for production systems where model updates are expensive and risky.
The Graph Coloring Algorithm represents a broader trend toward automated model surgery, where optimization opportunities are algorithmically extracted from computation graphs rather than manually engineered. As models grow more complex through automated architecture search and compound scaling, such automated tools will become essential for maintaining inference efficiency.
Perhaps most valuably, MaRI’s “bitter lesson” about fragmentation provides a concrete caution for the research community. It demonstrates that theoretical algorithmic improvements can be completely negated by implementation details, and that the path from paper to production requires confronting messy realities of feature engineering history and hardware constraints.
In the end, MaRI succeeds because it respects the mathematics of equivalence while ruthlessly optimizing the economics of computation. It recognizes that in serving billions of recommendations, every redundant multiply-add operation carries real cost—and that eliminating these redundancies, rather than accepting them as inevitable overhead, remains a fertile ground for innovation.
The matrices, it turns out, were never the bottleneck. The structure was.
Conceptual Framework Implementation (Python)
The implementation below illustrates the core mechanisms of MaRI: structural re-parameterization of matrix multiplication, graph coloring for node detection, and the critical importance of feature reorganization. This educational code demonstrates the mathematical principles described in the paper.
# ─────────────────────────────────────────────────────────────────────────────
# MaRI: Matrix Re-parameterized Inference for Ranking Model Acceleration
# Huang, Xu, Wang, et al. · arXiv:2602.23105v1 [cs.IR] 2026
# Conceptual implementation of structural re-parameterization
# ─────────────────────────────────────────────────────────────────────────────
import torch
import torch.nn as nn
import torch.nn.functional as F
from typing import List, Tuple, Optional, Dict, Set
from dataclasses import dataclass
from enum import Enum
# ─── Section 1: Core MaRI MatMul Operation ───────────────────────────────────
class MaRIMatMul(nn.Module):
"""
Structural re-parameterized matrix multiplication for ranking models.
Decomposes fused feature computation into user/item/cross components
to eliminate redundant user-side computation.
"""
def __init__(self, D_user: int, D_item: int, D_cross: int, d_out: int):
super().__init__()
self.D_user = D_user
self.D_item = D_item
self.D_cross = D_cross
self.d_out = d_out
# Partitioned weight matrices corresponding to Eq. 2 in paper
self.W_user = nn.Parameter(torch.randn(D_user, d_out))
self.W_item = nn.Parameter(torch.randn(D_item, d_out))
self.W_cross = nn.Parameter(torch.randn(D_cross, d_out))
def forward(self,
X_user: torch.Tensor, # Shape: (1, D_user)
X_item: torch.Tensor, # Shape: (B, D_item)
X_cross: torch.Tensor) -> torch.Tensor: # Shape: (B, D_cross)
"""
Implements MatMul_MaRI from Eq. 4:
Tile(X_user @ W_user, B) + X_item @ W_item + X_cross @ W_cross
Args:
X_user: User features (shared across batch)
X_item: Item features (batch-specific)
X_cross: Cross features (batch-specific)
Returns:
Fused output of shape (B, d_out)
"""
B = X_item.size(0)
# User-side: compute once, O(D_user * d_out) FLOPs
user_out = X_user @ self.W_user # Shape: (1, d_out)
# Tile to match batch dimension: O(B * d_out) memory, no compute
user_tiled = user_out.expand(B, -1) # Shape: (B, d_out)
# Item-side: O(B * D_item * d_out) FLOPs
item_out = X_item @ self.W_item # Shape: (B, d_out)
# Cross-side: O(B * D_cross * d_out) FLOPs
cross_out = X_cross @ self.W_cross # Shape: (B, d_out)
# Sum decomposition (Eq. 3)
return user_tiled + item_out + cross_out
def flops_reduction_ratio(self, B: int) -> float:
"""Calculate theoretical FLOPs reduction vs. vanilla MatMul"""
D_total = self.D_user + self.D_item + self.D_cross
flops_vanilla = 2 * B * D_total * self.d_out
flops_mari = 2 * self.d_out * (self.D_user + B * (self.D_item + self.D_cross))
return flops_vanilla / flops_mari
# ─── Section 2: Graph Coloring Algorithm (GCA) ───────────────────────────────
class NodeColor(Enum):
"""Color states for GCA feature propagation"""
UNCOLORED = "uncolored"
YELLOW = "yellow" # User-side features
BLUE = "blue" # Item/cross-side features
class ComputationGraph:
"""Simplified computation graph representation"""
def __init__(self):
self.nodes: Dict[str, Dict] = {}
self.edges: List[Tuple[str, str]] = []
def add_node(self, name: str, node_type: str, is_user_feature: bool = False):
self.nodes[name] = {
'type': node_type,
'is_user': is_user_feature,
'color': NodeColor.YELLOW if is_user_feature else NodeColor.UNCOLORED,
'downstream': []
}
def add_edge(self, from_node: str, to_node: str):
self.edges.append((from_node, to_node))
self.nodes[from_node]['downstream'].append(to_node)
class GraphColoringAlgorithm:
"""
Algorithm 1 from paper: Automatically detects MaRI-optimizable MatMul nodes.
Uses DFS-based color propagation to identify user/item feature boundaries.
"""
def __init__(self, graph: ComputationGraph):
self.graph = graph
def detect_optimizable_nodes(self) -> Set[str]:
"""
Execute GCA to find MatMul nodes eligible for MaRI transformation.
Returns:
Set of node names that can be replaced with MatMul_MaRI
"""
self._initialize_colors()
self._propagate_colors_dfs()
return self._detect_matmul_targets()
def _initialize_colors(self):
"""Phase 1: Initialize colors based on feature type"""
for name, node in self.graph.nodes.items():
if node['is_user']:
node['color'] = NodeColor.YELLOW
elif node['type'] in ['item_feature', 'cross_feature']:
node['color'] = NodeColor.BLUE
else:
node['color'] = NodeColor.UNCOLORED
def _propagate_colors_dfs(self):
"""Phase 2: DFS-based color propagation (Algorithm 1, lines 6-18)"""
stack = [n for n, attrs in self.graph.nodes.items()
if attrs['color'] != NodeColor.UNCOLORED]
while stack:
u = stack.pop()
u_color = self.graph.nodes[u]['color']
for v in self.graph.nodes[u]['downstream']:
v_node = self.graph.nodes[v]
updated = False
# Blue dominates; Yellow only propagates to uncolored
if u_color == NodeColor.BLUE and v_node['color'] != NodeColor.BLUE:
v_node['color'] = NodeColor.BLUE
updated = True
elif u_color == NodeColor.YELLOW and v_node['color'] == NodeColor.UNCOLORED:
v_node['color'] = NodeColor.YELLOW
updated = True
if updated:
stack.append(v)
def _detect_matmul_targets(self) -> Set[str]:
"""
Phase 3: Detect optimizable MatMul nodes (Algorithm 1, lines 20-28).
Find MatMul nodes reachable from Concat nodes with mixed Yellow/Blue inputs.
"""
targets = set()
for name, node in self.graph.nodes.items():
if node['type'] == 'concat':
# Check for mixed Yellow/Blue inputs
input_colors = self._get_input_colors(name)
if NodeColor.YELLOW in input_colors and NodeColor.BLUE in input_colors:
# Find all MatMul nodes reachable via non-computational paths
matmul_nodes = self._find_reachable_matmul(name)
targets.update(matmul_nodes)
return targets
def _get_input_colors(self, node_name: str) -> List[NodeColor]:
"""Retrieve colors of input nodes (simplified)"""
# In practice, reverse edge lookup
return [NodeColor.YELLOW, NodeColor.BLUE] # Simplified
def _find_reachable_matmul(self, start: str) -> Set[str]:
"""Find MatMul nodes reachable via non-computational paths"""
# Simplified BFS/DFS implementation
reachable = set()
stack = [start]
while stack:
node = stack.pop()
if self.graph.nodes[node]['type'] == 'matmul':
reachable.add(node)
# Only traverse non-computational nodes (reshape, transpose, etc.)
for succ in self.graph.nodes[node]['downstream']:
if self.graph.nodes[succ]['type'] in ['reshape', 'transpose', 'matmul']:
stack.append(succ)
return reachable
# ─── Section 3: Feature Reorganization ───────────────────────────────────────
class FeatureReorganizer:
"""
Handles the critical step of transforming fragmented feature layouts
into neat user/item/cross groupings to prevent 38% performance degradation.
"""
def __init__(self, feature_map: Dict[str, str]):
"""
Args:
feature_map: Mapping from feature name to domain ('user', 'item', 'cross')
"""
self.feature_map = feature_map
def create_permutation(self, original_order: List[str]) -> Tuple[List[int], Dict[str, Tuple[int, int]]]:
"""
Create permutation indices to reorganize features into neat layout.
Returns:
permutation: Indices to reorder features
ranges: Dictionary mapping domain to (start, end) indices
"""
# Group by domain
user_feats = [f for f in original_order if self.feature_map.get(f) == 'user']
item_feats = [f for f in original_order if self.feature_map.get(f) == 'item']
cross_feats = [f for f in original_order if self.feature_map.get(f) == 'cross']
# Create neat order: user -> item -> cross
neat_order = user_feats + item_feats + cross_feats
permutation = [original_order.index(f) for f in neat_order]
# Calculate dimension ranges
D_user = len(user_feats)
D_item = len(item_feats)
D_cross = len(cross_feats)
ranges = {
'user': (0, D_user),
'item': (D_user, D_user + D_item),
'cross': (D_user + D_item, D_user + D_item + D_cross)
}
return permutation, ranges
def reorganize_weights(self,
W_original: torch.Tensor,
permutation: List[int]) -> torch.Tensor:
"""Apply permutation to weight matrix rows"""
return W_original[permutation, :]
# ─── Section 4: Complete MaRI Integration ────────────────────────────────────
class MaRIRankingLayer(nn.Module):
"""
Production-ready ranking layer with MaRI optimization.
Demonstrates integration of reorganization, GCA detection, and MaRI MatMul.
"""
def __init__(self,
feature_dims: Dict[str, int],
hidden_dim: int,
feature_map: Optional[Dict[str, str]] = None):
super().__init__()
self.D_user = feature_dims['user']
self.D_item = feature_dims['item']
self.D_cross = feature_dims['cross']
self.hidden_dim = hidden_dim
# MaRI-optimized MatMul (replaces standard linear layer)
self.mari_matmul = MaRIMatMul(
self.D_user, self.D_item, self.D_cross, hidden_dim
)
# Optional: Feature reorganizer for fragmented inputs
if feature_map:
self.reorganizer = FeatureReorganizer(feature_map)
else:
self.reorganizer = None
def forward(self,
X_user: torch.Tensor,
X_item: torch.Tensor,
X_cross: torch.Tensor) -> torch.Tensor:
"""
Forward pass with MaRI optimization.
Args:
X_user: (1, D_user) - shared user features
X_item: (B, D_item) - item features per candidate
X_cross: (B, D_cross) - cross features per candidate
Returns:
Output: (B, hidden_dim) - fused representations
"""
# Apply MaRI re-parameterized MatMul
return self.mari_matmul(X_user, X_item, X_cross)
# ─── Section 5: Demonstration ────────────────────────────────────────────────
if __name__ == "__main__":
"""
Demonstration of MaRI acceleration on synthetic ranking scenario.
Shows FLOPs reduction, GCA detection, and performance characteristics.
"""
print("=" * 70)
print("MaRI: Matrix Re-parameterized Inference for Ranking Models")
print("arXiv:2602.23105v1 [cs.IR] 2026")
print("=" * 70)
# Configuration matching paper's experimental setup
B = 2000 # Batch size (candidate items)
D_user = 4000 # User feature dimension
D_item = 1000 # Item feature dimension
D_cross = 1000 # Cross feature dimension
d_hidden = 512 # Hidden layer dimension
# Phase 1: Initialize MaRI layer
print("\n[1] Initializing MaRI-optimized ranking layer...")
mari_layer = MaRIRankingLayer(
feature_dims={'user': D_user, 'item': D_item, 'cross': D_cross},
hidden_dim=d_hidden
)
# Calculate theoretical speedup
speedup = mari_layer.mari_matmul.flops_reduction_ratio(B)
print(f" Configuration: B={B}, D_user={D_user}, D_item={D_item}, D_cross={D_cross}")
print(span class="st">f" Theoretical FLOPs speedup: {speedup:.2f}×")
print(f" Expected runtime speedup: ~1.1-1.3× (from paper Fig. 3)")
# Phase 2: Simulate forward pass
print("\n[2] Simulating inference forward pass...")
X_user = torch.randn(1, D_user) # Single user, broadcast to batch
X_item = torch.randn(B, D_item) # B different items
X_cross = torch.randn(B, D_cross) # B different cross features
output = mari_layer(X_user, X_item, X_cross)
print(f" Input shapes: X_user {X_user.shape}, X_item {X_item.shape}, X_cross {X_cross.shape}")
print(f" Output shape: {output.shape}")
print(" ✓ MaRI MatMul computed user projection once, tiled to batch")
# Phase 3: GCA demonstration
print("\n[3] Running Graph Coloring Algorithm for node detection...")
graph = ComputationGraph()
# Build simplified model graph
graph.add_node('user_seq', 'feature', is_user_feature=True)
graph.add_node('item_id', 'item_feature')
graph.add_node('cross_freq', 'cross_feature')
graph.add_node('concat', 'concat')
graph.add_node('matmul_1', 'matmul')
graph.add_node('mmoe_expert', 'matmul')
graph.add_edge('user_seq', 'concat')
graph.add_edge('item_id', 'concat')
graph.add_edge('cross_freq', 'concat')
graph.add_edge('concat', 'matmul_1')
graph.add_edge('matmul_1', 'mmoe_expert')
gca = GraphColoringAlgorithm(graph)
optimizable = gca.detect_optimizable_nodes()
print(f" Detected optimizable nodes: {optimizable}")
print(" ✓ GCA automatically located MaRI-eligible MatMul operations")
# Phase 4: Fragmentation warning
print("\n[4] Feature Layout Analysis...")
print(" Neat layout (user|item|cross): OPTIMAL for MaRI")
print(" Fragmented layout (mixed): 38.8% performance degradation")
print(" → Feature reorganization is REQUIRED for deployment")
# Phase 5: Architecture summary
print("\n[5] MaRI Architecture Summary:")
print(" Base: Standard ranking model (MMoE, DeepFM, etc.)")
print(" Optimization: Structural re-parameterization of MatMul")
print(" Key Components:")
print(" - MatMul_MaRI: Decomposed user/item/cross computation")
print(" - GCA: Automated detection via graph coloring")
print(" - Reorganizer: Layout transformation for hardware efficiency")
print(" Deployment: Kuaishou coarse-ranking, 1.32× speedup, 5.9% resource savings")
print("\n" + "=" * 70)
print("MaRI achieves lossless acceleration by eliminating redundant")
print("user-side computation through algebraic decomposition.")
print("=" * 70)
Access the Paper and Resources
The full MaRI framework details and experimental protocols are available on arXiv. This research was conducted by the Kuaishou Technology team and published in February 2026.
Huang, Y., Xu, P., Wang, S., Lao, C., Cao, J., Wen, S., Yang, S., Liu, Z., Li, H., & Gai, K. (2026). MaRI: Accelerating ranking model inference via structural re-parameterization in large scale recommendation system. arXiv preprint arXiv:2602.23105.
This article is an independent editorial analysis of peer-reviewed research published on arXiv. The views and commentary expressed here reflect the editorial perspective of this site and do not represent the views of the original authors or their institutions. Code implementations are provided for educational purposes to illustrate the technical concepts described in the paper. Always refer to the original publication for authoritative details and official implementations.
Explore More on AI Systems Research
If this analysis sparked your interest, here is more of what we cover across the site — from foundational tutorials to the latest research breakthroughs in efficient machine learning, recommendation systems, and industrial AI deployment.