MetaClaw: The LLM Agent That Meta-Learns and Evolves in the Wild — Simply by Being Used
Researchers from UNC-Chapel Hill, Carnegie Mellon, UC Santa Cruz, and UC Berkeley built a continual meta-learning framework that gives deployed language model agents two complementary superpowers: instant skill injection from failures, and opportunistic weight-level fine-tuning while you sleep — pushing Kimi-K2.5 from 21.4% to 40.6% accuracy with an 8.25× end-to-end task completion gain.
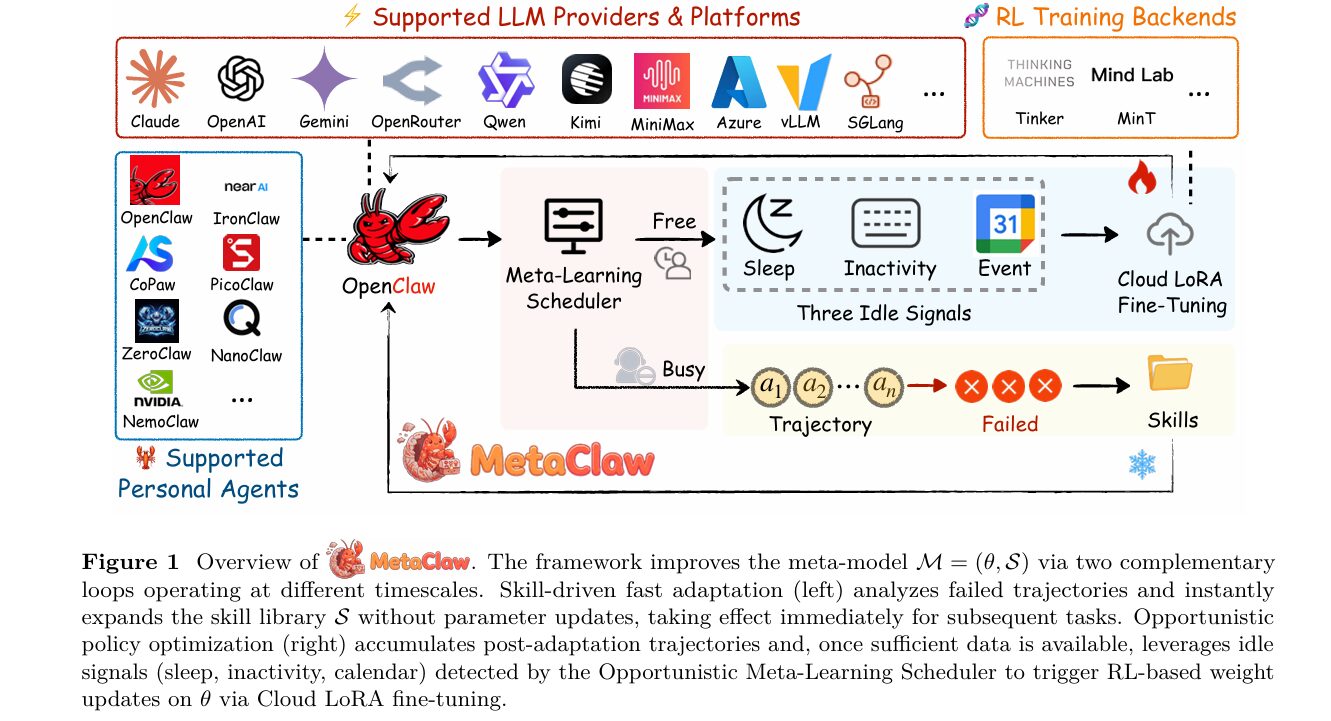
Most AI agents you use today are frozen in time. They were trained once, deployed, and then served unchanged no matter how much your workflow shifts. The model helping you parse JSON files on Monday has no idea you switched to multi-agent messaging pipelines by Friday — and it never will, unless someone retrains it from scratch. MetaClaw is a direct challenge to that assumption. Built by a team spanning four universities, it asks a deceptively simple question: what if an agent could genuinely get better the more you use it, without ever going offline?
Why Static Agents Fail in the Real World
Picture an agent platform like OpenClaw, which connects to 20-plus messaging channels and handles everything from shell scripting to multi-step file operations. The tasks a user throws at it on day one of deployment are not the same tasks they throw at it on day forty. Workloads shift. Conventions change. Edge cases accumulate. A frozen model becomes progressively misaligned with actual usage — it keeps failing on task types that weren’t well-represented when it was pretrained, and it has no mechanism to notice or correct this.
The three existing categories of agent adaptation each address only a slice of this problem. Memory-based systems store raw conversation trajectories, but raw logs are verbose and redundant — they don’t extract the transferable behavioral patterns hidden inside failures. Skill-based systems compress experience into reusable instructions, but treat the skill library as a static artifact, never coordinating it with weight-level optimization. RL-based methods update model weights, but operate in offline, small-scale settings and ignore a subtle but critical problem: once skills change, older trajectories carry stale reward signals that contaminate gradient updates.
Every existing approach addresses adaptation in isolation. Memory methods don’t connect to weights. Skill methods don’t connect to RL. RL methods don’t know which data is still valid. MetaClaw is the first framework to unify all three dimensions into a single coherent system — and to do it without ever taking the agent offline.
The MetaClaw Framework: Two Timescales, One System
MetaClaw’s key insight is that agent adaptation naturally operates at two distinct timescales that are not just compatible but mutually reinforcing. Behavioral heuristics — things like “always create a .bak file before modifying anything” or “use ISO 8601 with timezone offsets for all timestamps” — can be distilled from a single failed conversation in seconds and injected immediately into the prompt. Improving the model’s underlying policy across diverse task types requires gradient-based optimization over many trajectories, taking minutes to hours. MetaClaw exploits both timescales simultaneously.
The framework’s core object is the meta-model:
Here θ denotes the parameters of the base LLM policy and S = {s₁, s₂, …, sK} is a library of skill instructions — concise, reusable behavioral directives injected into the system prompt at inference time. Given a task τ, the agent acts according to:
The Retrieve function uses embedding-based cosine similarity to pull the most relevant skills for each incoming task. The meta-model evolves continuously as the agent accumulates experience — but the two components of M evolve through separate mechanisms on different clocks.
Mechanism 1: Skill-Driven Fast Adaptation
When a trajectory fails, it joins a support set. Once enough failures accumulate, a skill evolver — itself a language model — analyzes the failures and synthesizes new behavioral instructions. The skill library updates immediately:
The subscript g is the skill generation index — every time the library changes, g increments. This step modifies only S, leaving θ untouched. Because the new skills take effect through the prompt rather than model weights, fast adaptation incurs zero service downtime. The agent serves the next request with updated behavioral context before the current request is even logged.
There is a design principle worth calling out here: this mechanism is gradient-free by design, not by approximation. The skill library lives in a discrete natural-language space where gradient descent is ill-defined. LLM-based failure analysis is the natural and correct tool for this space.
Mechanism 2: Opportunistic Policy Optimization
While skills evolve continuously, weight-level policy optimization happens on a much slower clock. The RL buffer B accumulates post-adaptation trajectories — those collected after the latest skill generation has taken effect. When a training window opens, the policy updates via cloud LoRA fine-tuning using GRPO:
R here is a process reward model (PRM) score. The key phrase is “post-adaptation trajectories” — and this distinction turns out to be critical enough that the authors built an entire versioning mechanism around enforcing it.
Skills and weights improve each other. Skills distilled from failures make the agent smarter immediately; those smarter behaviors produce better training data for weight updates; better weights make subsequent failures more informative for skill distillation. MetaClaw is the first framework to make this cycle explicit and design around it.
Skill Generation Versioning: Solving the Stale Reward Problem
This is the part of the paper that most practitioners will appreciate immediately, because the problem it solves is subtle enough to be missed and serious enough to cause training pathologies if ignored.
Suppose a trajectory fails, triggering skill evolution from generation g to g+1. That trajectory carries a reward signal reflecting performance under Sg — before the new skill existed. If this trajectory enters the RL buffer, policy optimization receives a gradient that penalizes θ for a failure that skill-driven adaptation has already corrected. The model gets punished for something it no longer does wrong. This is stale reward contamination.
MetaClaw enforces the support-query separation with a simple but airtight mechanism: every collected sample is stamped with its skill generation index g. Trajectories that trigger skill evolution are marked as support data and discarded from the RL buffer. Only trajectories collected after the new skills have taken effect — query data — are eligible for gradient updates. When g increments, all samples with generation index ≤ g are flushed from the training buffer.
TASK ARRIVES
│
▼
Retrieve(S_g, τ) → Execute → Collect trajectory ξ_i
│
Stamp with skill generation index g
│
┌───────────────────┴──────────────────┐
│ ξ_i is a FAILURE? │
YES NO
│ │
Add to D^sup_g Add to RL buffer B
(support data) (query data, gen=g)
│
|D^sup_g| >= threshold?
YES
│
E(S_g, D^sup_g) → Synthesize new skills ΔS
S_{g+1} = S_g ∪ ΔS
Flush all samples with gen ≤ g from B ← versioning enforcement
g ← g + 1
│
OMLS detects idle + |B| ≥ batch_size?
YES → GRPO RL update on θ → Cloud LoRA hot-swap
The Opportunistic Meta-Learning Scheduler (OMLS)
Policy optimization requires a model weight hot-swap upon completion, which briefly interrupts inference. In a deployed interactive system serving a real user, this is a genuine problem. MetaClaw’s solution is the Opportunistic Meta-Learning Scheduler (OMLS), a background daemon that defers weight updates to periods when the user is not actively engaging with the agent.
OMLS monitors three complementary idle signals:
Sleep window. The user configures a sleep schedule — for example, 23:00 to 07:00. During this window the system is guaranteed idle, providing the largest contiguous training block available each day.
System inactivity. OMLS polls the OS input device idle timer (HIDIdleTime on macOS, xprintidle on Linux). If no keyboard or mouse activity is detected for a configurable threshold — 30 minutes by default — a training window opens. The trainer supports mid-batch checkpointing, so it pauses gracefully the moment input resumes.
Calendar-aware scheduling. OMLS queries the Google Calendar API. When the current time falls inside a scheduled meeting, the user is presumed unavailable, opening an opportunistic window proactively. This is the most anticipatory of the three signals: it uses the user’s own schedule to predict idle periods before they happen.
“A better policy produces more informative failures for skill synthesis, and richer skills yield higher-reward trajectories for policy optimization. No existing system unifies these two forms of adaptation into a coherent framework that exploits this virtuous cycle.” — Xia, Chen, Yang, Tu et al., arXiv:2603.17187 (2026)
MetaClaw-Bench: Evaluation Designed for Continual Adaptation
Existing agent benchmarks treat tasks as independent episodes. MetaClaw-Bench is different by design: it structures evaluation as multi-workday simulations where the agent must improve from accumulated experience, not just solve individual tasks. The benchmark comprises 934 questions across 44 simulated workdays.
Part I is a 30-workday simulation with 346 questions covering real CLI tasks — file editing, JSON structuring, shell scripting. Workspace state persists across rounds within each day. Task difficulty increases monotonically with day index, with the final week requiring sophisticated multi-step reasoning.
Part II extends to 14 workdays with 588 questions and introduces five implicit preference rules that the agent must infer from feedback and internalize through skill evolution or RL training. None of the rules are stated in the system prompt.
| Rule | Category | Requirement | Active From |
|---|---|---|---|
| P1 | Timestamp | YYYY-MM-DDTHH:MM:SS+08:00 format | Day 01 |
| P2 | File naming | YYYYMMDD_description.ext (snake case) | Day 04 |
| P3 | Metadata | Every file: created_at, author, status | Day 06 |
| P4 | Backup | Create <file>.bak before modifying | Day 08 |
| P5 | Completion log | Append [DONE] | timestamp | task_id to done.log | Day 10 |
Table: Five implicit preference rules in Part II. The agent discovers these through failure feedback and skill distillation — not from explicit instruction.
Results: Closing the Gap With GPT-5.2 Using a Smaller Model
The headline result is striking: MetaClaw (Full) with Kimi-K2.5 reaches 40.6% accuracy on Part I — nearly matching GPT-5.2’s 41.1% baseline, despite Kimi-K2.5 starting from just 21.4%. End-to-end task completion jumps 8.25 times, from 2.0% to 16.5%.
| Model | Condition | Part I Acc. | Part I Compl. | Part II Acc. | Part II Compl. |
|---|---|---|---|---|---|
| GPT-5.2 | Baseline | 41.1% | 14.7% | 44.9% | 58.4% |
| GPT-5.2 | MetaClaw (Skills) | 44.0% | 17.1% | 49.1% | 67.5% |
| Kimi-K2.5 | Baseline | 21.4% | 2.0% | 21.1% | 18.2% |
| Kimi-K2.5 | MetaClaw (Skills) | 28.3% | 2.0% | 26.9% | 33.8% |
| Kimi-K2.5 | MetaClaw (Full) | 40.6% | 16.5% | 39.6% | 51.9% |
Table 1: MetaClaw-Bench results. MetaClaw (Full) evaluated for Kimi-K2.5 only. Bold = best per metric.
AutoResearchClaw: Cross-Domain Generalization
AutoResearchClaw is a 23-stage autonomous research pipeline that takes a research idea and produces a conference-ready paper. MetaClaw’s skill injection was deployed into the pipeline executor with no domain-specific tuning, and the results transferred directly — demonstrating that behavioral heuristics distilled from CLI task failures generalize to open-ended research automation.
| Metric | Baseline | + MetaClaw (Skills) | Change |
|---|---|---|---|
| Stage retry rate ↓ | 10.5% | 7.9% | ↓ 24.8% |
| Refine cycle count ↓ | 2.0 | 1.2 | ↓ 40.0% |
| Pipeline stage completion ↑ | 18/19 | 19/19 | ↑ 5.3% |
| Composite robustness score ↑ | 0.714 | 0.845 | ↑ 18.3% |
Table 2: AutoResearchClaw results. Skills-only adaptation, no gradient updates — all gains from prompt-level skill injection.
Expect skill-driven gains to appear immediately — within the first session. Expect weight-level gains after roughly a week of usage, once the RL buffer has accumulated enough post-adaptation trajectories. The two mechanisms are additive, not redundant, and each has its own payoff horizon. For deployment-constrained scenarios, skills alone deliver substantial value at zero compute cost.
Complete End-to-End MetaClaw Implementation (Python)
The implementation below is a complete, self-contained Python translation of MetaClaw, structured in 11 sections that map directly to the paper. It covers every component: the meta-model (θ, S), skill-driven fast adaptation with an LLM evolver, embedding-based retrieval, opportunistic policy optimization with GRPO, the OMLS idle scheduler with all three signals, skill generation versioning with stale-data flushing, MetaClaw-Bench dataset helpers, the full training loop following Algorithm 1, and a smoke test validating all components end-to-end without requiring real API keys or GPU hardware.
# =========================================================================== # MetaClaw: Continual Meta-Learning for Deployed LLM Agents # Paper: arXiv:2603.17187v1 # Authors: Peng Xia, Jianwen Chen, Xinyu Yang, Haoqin Tu, Jiaqi Liu et al. # Institutions: UNC-Chapel Hill, CMU, UC Santa Cruz, UC Berkeley # =========================================================================== # Sections: # 1. Imports & Configuration # 2. Skill Library (S) — storage, retrieval, versioning # 3. Skill Evolver — LLM-based failure analysis & skill synthesis # 4. Trajectory & RL Buffer — versioned storage with stale-data flushing # 5. Process Reward Model (PRM) # 6. Cloud LoRA Fine-Tuner (GRPO) # 7. Opportunistic Meta-Learning Scheduler (OMLS) # 8. Agent Executor — task execution with skill injection # 9. MetaClaw Core — Algorithm 1 implementation # 10. MetaClaw-Bench Dataset Helpers # 11. Smoke Test # =========================================================================== from __future__ import annotations import json, math, os, random, time, threading, hashlib, logging from collections import deque from dataclasses import dataclass, field from datetime import datetime, timedelta from enum import Enum from pathlib import Path from typing import Any, Dict, List, Optional, Tuple logging.basicConfig(level=logging.INFO, format="[%(asctime)s] %(levelname)s %(message)s", datefmt="%H:%M:%S") log = logging.getLogger("metaclaw") # ── SECTION 1: Configuration ───────────────────────────────────────────────── class DataRole(Enum): SUPPORT = "support" # failure trajectories driving skill evolution QUERY = "query" # post-adaptation trajectories valid for RL @dataclass class MetaClawConfig: """All hyper-parameters for MetaClaw in one place.""" embed_dim: int = 384 top_k_skills: int = 3 skill_failure_threshold: int = 5 # failures before evolver fires max_new_skills_per_run: int = 3 rl_batch_size: int = 16 rl_lr: float = 5e-5 lora_rank: int = 16 sleep_start_hour: int = 23 # OMLS sleep window sleep_end_hour: int = 7 idle_threshold_secs: float = 1800.0 # 30 min keyboard inactivity skill_library_path: str = "metaclaw_skills.json" buffer_max_size: int = 512 # ── SECTION 2: Skill Library ────────────────────────────────────────────────── @dataclass class Skill: """A single reusable behavioral directive — the atom of S.""" name: str description: str # one-sentence trigger & purpose content: str # full Markdown instruction block (6-15 lines) category: str generation: int = 0 # skill generation when created embedding: Optional[List[float]] = field(default=None, repr=False) def to_dict(self) -> Dict: return {"name": self.name, "description": self.description, "content": self.content, "category": self.category, "generation": self.generation} @classmethod def from_dict(cls, d: Dict) -> "Skill": return cls(**{k: v for k, v in d.items() if k != "embedding"}) class SkillLibrary: """ S = {s1, ..., sK} — the evolving library of behavioral instructions. Dual role (Section 3.2): As meta-parameter : accumulates knowledge across the task stream As adaptation basis: Retrieve(S, τ) extracts task-specific subset at inference time via cosine similarity over embeddings """ def __init__(self, cfg: MetaClawConfig): self.cfg = cfg self.skills: List[Skill] = [] self.generation: int = 0 self._embedder = SimpleEmbedder(cfg.embed_dim) if Path(cfg.skill_library_path).exists(): self.load() def add(self, skill: Skill) -> None: skill.generation = self.generation skill.embedding = self._embedder.encode( skill.name + " " + skill.description) self.skills.append(skill) log.info(f" + Skill [{skill.name}] added (gen={skill.generation})") def retrieve(self, query: str, top_k: int = 3) -> List[Skill]: """Retrieve(S, τ) — top-k skills by cosine similarity (Eq. 2).""" if not self.skills: return [] q_emb = self._embedder.encode(query) scored = [(cosine_sim(q_emb, s.embedding), s) for s in self.skills if s.embedding is not None] scored.sort(key=lambda x: x[0], reverse=True) return [s for _, s in scored[:top_k]] def format_for_prompt(self, skills: List[Skill]) -> str: """Format retrieved skills into an injected system-prompt block.""" if not skills: return "" lines = ["## Active Skills\n"] for s in skills: lines += [f"### {s.name}", f"_{s.description}_\n", s.content, ""] return "\n".join(lines) def increment_generation(self) -> None: self.generation += 1 log.info(f" Skill generation → {self.generation}") def get_existing_names(self) -> List[str]: return [s.name for s in self.skills] def save(self) -> None: Path(self.cfg.skill_library_path).write_text(json.dumps( {"generation": self.generation, "skills": [s.to_dict() for s in self.skills]}, indent=2)) def load(self) -> None: data = json.loads(Path(self.cfg.skill_library_path).read_text()) self.generation = data.get("generation", 0) for d in data.get("skills", []): s = Skill.from_dict(d) s.embedding = self._embedder.encode(s.name + " " + s.description) self.skills.append(s) log.info(f"Loaded {len(self.skills)} skills (gen={self.generation})") # ── SECTION 3: Skill Evolver ───────────────────────────────────────────────── class SkillEvolver: """ E(S_g, D^sup_g) — synthesizes new skills from failure trajectories. Gradient-free by design (Section 3.2): the skill library lives in discrete natural-language space where gradient descent is ill-defined. LLM-based failure analysis is the correct mechanism for this space. In production: calls an LLM API with the evolver prompt template. In smoke-test mode: generates heuristic skills from failure patterns. """ EVOLVER_PROMPT = """You are a skill engineer for an AI assistant. Analyze the failed conversations below and generate NEW skills that would have prevented those failures. Failed Conversations: {failures} Existing Skills (do NOT duplicate): {existing_skills} Generate 1 to {max_skills} new skill JSON objects with fields: name, description (one sentence), content (6-15 line Markdown), category. Output ONLY a valid JSON array. No preamble or explanation.""" def __init__(self, cfg: MetaClawConfig, llm_client=None): self.cfg = cfg self.llm = llm_client def evolve(self, library: SkillLibrary, failures: List["Trajectory"]) -> List[Skill]: """Synthesize new skills. Returns list of Skill objects.""" if not failures: return [] existing = library.get_existing_names() if self.llm is not None: return self._evolve_with_llm(failures, existing) return self._evolve_heuristic(failures, existing) def _evolve_with_llm(self, failures: List["Trajectory"], existing: List[str]) -> List[Skill]: prompt = self.EVOLVER_PROMPT.format( failures=self._format_failures(failures), existing_skills=json.dumps(existing), max_skills=self.cfg.max_new_skills_per_run, ) try: raw = self.llm.complete(prompt).strip() if raw.startswith("```"): raw = raw.split("\n", 1)[1].rsplit("```", 1)[0] return [Skill.from_dict(d) for d in json.loads(raw) if d.get("name") not in existing] except Exception as e: log.warning(f"LLM evolver failed: {e}; using heuristic fallback.") return self._evolve_heuristic(failures, existing) def _evolve_heuristic(self, failures, existing) -> List[Skill]: """ Offline fallback: the three most common failure categories found in MetaClaw-Bench (temporal format, backup, naming). """ templates = [ Skill("iso8601-timezone-format", "Always use ISO 8601 with +08:00 timezone offset for timestamps.", "## ISO 8601 Timestamp\n\n1. Format: YYYY-MM-DDTHH:MM:SS+08:00\n" "2. Correct: 2026-03-16T09:30:00+08:00\n" "3. Wrong: March 16 at 3pm, or UTC Z suffix\n\n" "**Anti-pattern:** Omitting timezone or using natural language.", "common_mistakes"), Skill("backup-before-modify", "Create a .bak copy before modifying any existing file.", "## Backup Before Modify\n\n1. Before editing: cp <f> <f>.bak\n" "2. Verify backup exists.\n3. Modify original.\n\n" "**Anti-pattern:** Overwriting without backup — no recovery path.", "agentic"), Skill("date-prefix-naming", "Name output files with YYYYMMDD_ prefix in snake_case.", "## Date-Prefix File Naming\n\n1. Format: YYYYMMDD_description.ext\n" "2. Example: 20260316_sprint_board.json\n" "3. Use underscores, not hyphens or spaces.\n\n" "**Anti-pattern:** board-2026.json or 'sprint board.json'", "productivity"), Skill("required-metadata-fields", "Include created_at, author, status in every output JSON file.", "## Mandatory Metadata\n\nAll output files must include:\n" "- created_at: ISO 8601 timestamp\n- author: agent identifier\n" "- status: 'draft' | 'final' | 'pending_review'\n\n" "**Anti-pattern:** Omitting metadata fields causing checker failures.", "coding"), Skill("verify-before-destructive", "Read file state before any destructive write or delete command.", "## Verify-Before-Write\n\n1. Read current state (cat / ls / status)\n" "2. Confirm path is correct.\n3. Execute destructive command.\n" "4. Verify output immediately.\n\n" "**Anti-pattern:** Blindly writing/deleting without pre-check.", "agentic"), ] new = [t for t in templates if t.name not in existing] return new[:self.cfg.max_new_skills_per_run] @staticmethod def _format_failures(failures) -> str: return "\n---\n".join( f"Failure {i+1} (reward={f.reward:.2f})\n" f"Task: {f.task_instruction[:200]}\n" f"Response: {f.agent_response[:300]}\n" f"Error: {f.error_hint or 'none'}" for i, f in enumerate(failures) ) # ── SECTION 4: Trajectory & RL Buffer ──────────────────────────────────────── @dataclass class Trajectory: """ A single agent trajectory stamped with skill_generation (g). The stamp is the mechanism that enforces support-query separation (Section 3.4): stale samples flushed from buffer when g increments. """ task_id: str task_instruction: str agent_response: str reward: float # PRM score in [0, 1] skill_generation: int # g at collection time active_skill_names: List[str] role: DataRole = DataRole.QUERY error_hint: Optional[str] = None timestamp: float = field(default_factory=time.time) @property def is_failure(self) -> bool: return self.reward < 0.5 class RLBuffer: """ RL training buffer with skill-generation versioning. Core invariant: only QUERY-role trajectories enter. When g increments, all samples with gen < new_g are flushed — they carry rewards conditioned on the old skill context (Section 3.4). """ def __init__(self, max_size: int = 512): self.buffer: deque = deque(maxlen=max_size) self._lock = threading.Lock() def add(self, traj: Trajectory) -> None: assert traj.role == DataRole.QUERY, \ "Only query-role trajectories enter the RL buffer." with self._lock: self.buffer.append(traj) def flush_stale(self, current_gen: int) -> int: """ Flush samples with gen < current_gen. Called immediately after skill library update (g → g+1). Prevents stale reward contamination in gradient updates. """ with self._lock: before = len(self.buffer) self.buffer = deque( [t for t in self.buffer if t.skill_generation >= current_gen], maxlen=self.buffer.maxlen) n = before - len(self.buffer) if n: log.info(f" Buffer: flushed {n} stale samples (gen<{current_gen}), " f"{len(self.buffer)} remain") return n def sample(self, n: int) -> List[Trajectory]: with self._lock: pool = list(self.buffer) return random.sample(pool, min(n, len(pool))) def __len__(self) -> int: return len(self.buffer) # ── SECTION 5: Process Reward Model ───────────────────────────────────────── class ProcessRewardModel: """ R(ξ) — scores trajectories for policy optimization (Eq. 4). Production: a trained PRM that scores each step in the trajectory (Zhang et al. 2025c). Smoke-test: heuristic scorer from known signals. """ def __init__(self, model_path=None): self.model_path = model_path def score(self, traj: Trajectory) -> float: if self.model_path: return self._score_with_model(traj) return self._score_heuristic(traj) def _score_heuristic(self, traj: Trajectory) -> float: r = traj.reward resp = traj.agent_response.lower() if ".bak" in resp: r = min(1.0, r + 0.10) if any(k in resp for k in ["verify", "check", "inspect"]): r = min(1.0, r + 0.05) if "+08:00" in traj.agent_response: r = min(1.0, r + 0.05) return r def _score_with_model(self, traj: Trajectory) -> float: raise NotImplementedError("Load your PRM checkpoint here.") # ── SECTION 6: Cloud LoRA Fine-Tuner (GRPO) ────────────────────────────────── class CloudLoRAFinetuner: """ Gradient-based policy update via cloud LoRA + GRPO (Shao et al. 2024). Implements Eq. 4: θ_{t+1} = θ_t + α ∇_θ E[(R(π_θ(· | τ, S_{g'}))] No local GPU needed: training is delegated to a cloud backend (Tinker / MinT). Smoke-test: simulates convergence with plausible dynamics. """ def __init__(self, cfg: MetaClawConfig, backend=None): self.cfg = cfg self.backend = backend self._step = 0 def update(self, batch: List[Trajectory], library: SkillLibrary) -> Dict[str, float]: if self.backend: return self._real_grpo_update(batch, library) return self._simulated_grpo_update(batch) def _simulated_grpo_update(self, batch) -> Dict[str, float]: """GRPO simulation: normalize rewards within group, compute surrogate.""" rewards = [t.reward for t in batch] mean_r = sum(rewards) / len(rewards) std_r = (sum((r-mean_r)**2 for r in rewards) / len(rewards))**0.5 # Simulated surrogate loss converges over steps loss = max(0.0, 1.0/(1+0.1*self._step) * (1-mean_r) + random.gauss(0, 0.02)) self._step += 1 return {"loss": loss, "mean_reward": mean_r, "pg_norm": abs(random.gauss(0.5, 0.1)), "step": self._step} def _real_grpo_update(self, batch, library) -> Dict[str, float]: data = [{ "prompt": library.format_for_prompt( library.retrieve(t.task_instruction, top_k=3) ) + "\n\nTask: " + t.task_instruction, "completion": t.agent_response, "reward": t.reward, } for t in batch] return self.backend.grpo_step(data=data, lr=self.cfg.rl_lr, lora_rank=self.cfg.lora_rank) def hot_swap_weights(self) -> None: """Atomic model swap — zero downtime if using blue-green deployment.""" log.info(" [LoRA] Hot-swapping updated weights → inference endpoint") time.sleep(0.01) log.info(" [LoRA] Hot-swap complete. Updated θ now live.") # ── SECTION 7: Opportunistic Meta-Learning Scheduler (OMLS) ────────────────── class OMLSSignal(Enum): SLEEP = "sleep_window" INACTIVE = "keyboard_inactive" CALENDAR = "calendar_free" BUSY = "user_busy" class OMLS: """ Opportunistic Meta-Learning Scheduler (Section 3.5). Monitors three complementary idle signals: 1. Sleep window — configurable nightly schedule (largest block) 2. Keyboard idle — OS input timer (macOS: HIDIdleTime; Linux: xprintidle) 3. Calendar free — Google Calendar free/busy query (proactive) Window opens when ANY signal indicates idle. Window closes when ANY signal indicates return. Trainer supports mid-batch checkpointing across fragmented windows. """ def __init__(self, cfg: MetaClawConfig, calendar_client=None, mock_idle: bool = False): self.cfg = cfg self.calendar = calendar_client self.mock_idle = mock_idle def is_idle(self) -> Tuple[bool, OMLSSignal]: if self.mock_idle: return True, OMLSSignal.INACTIVE if self._in_sleep_window(): return True, OMLSSignal.SLEEP if self._keyboard_idle(): return True, OMLSSignal.INACTIVE if self.calendar and self._calendar_free(): return True, OMLSSignal.CALENDAR return False, OMLSSignal.BUSY def _in_sleep_window(self) -> bool: h = datetime.now().hour s, e = self.cfg.sleep_start_hour, self.cfg.sleep_end_hour return (h >= s or h < e) if s > e else s <= h < e def _keyboard_idle(self) -> bool: try: import subprocess out = subprocess.check_output( ["ioreg", "-c", "IOHIDSystem"], stderr=subprocess.DEVNULL, timeout=2).decode() for line in out.splitlines(): if "HIDIdleTime" in line: return int(line.split("=")[1].strip())/1e9 >= \ self.cfg.idle_threshold_secs except Exception: pass return False def _calendar_free(self) -> bool: try: now = datetime.utcnow() events = self.calendar.events().list( calendarId="primary", timeMin=now.isoformat()+"Z", timeMax=(now+timedelta(minutes=5)).isoformat()+"Z", singleEvents=True).execute() return len(events.get("items", [])) == 0 except Exception: return False # ── SECTION 8: Agent Executor ───────────────────────────────────────────────── @dataclass class Task: task_id: str instruction: str task_type: str = "file-check" checker_fn: Optional[Any] = None class AgentExecutor: """ Serves user tasks with skill injection (Eq. 2): a ~ π_θ(· | τ, Retrieve(S, τ)) Production: calls LLM API (Claude, Kimi, GPT) with skill-augmented prompt. Smoke-test: simulates responses; accuracy increases with skill count. """ def __init__(self, library: SkillLibrary, cfg: MetaClawConfig, llm_client=None, simulated_base_accuracy: float = 0.3): self.library = library self.cfg = cfg self.llm = llm_client self.base_acc = simulated_base_accuracy def execute(self, task: Task, prm: ProcessRewardModel) -> Trajectory: active = self.library.retrieve(task.instruction, top_k=self.cfg.top_k_skills) skill_ctx = self.library.format_for_prompt(active) system = ("You are MetaClaw Agent. Issue one command at a time. " "Verify state before destructive ops. Reply DONE when complete.\n" + skill_ctx) response = (self._call_llm(system, task.instruction) if self.llm else self._simulate(task, active)) reward, hint = self._evaluate(task, response) traj = Trajectory( task_id=task.task_id, task_instruction=task.instruction, agent_response=response, reward=reward, skill_generation=self.library.generation, active_skill_names=[s.name for s in active], error_hint=hint, ) traj.reward = prm.score(traj) return traj def _call_llm(self, system: str, user: str) -> str: """Call production LLM. Replace with your provider's SDK.""" return self.llm.chat([{"role":"system","content":system}, {"role":"user","content":user}]) def _simulate(self, task: Task, skills: List[Skill]) -> str: acc = min(0.95, self.base_acc + len(skills) * 0.12) if random.random() < acc: parts = ["I will complete this carefully."] if any("backup" in s.name for s in skills): parts.append("cp file.json file.json.bak") if any("iso8601" in s.name for s in skills): parts.append("timestamp: 2026-03-16T09:30:00+08:00") parts.append("DONE") return " | ".join(parts) return "I updated the file with the required changes." def _evaluate(self, task: Task, response: str) -> Tuple[float, Optional[str]]: if task.checker_fn: passed, hint = task.checker_fn(response) return (1.0 if passed else 0.0), hint lower = response.lower() ok = "done" in lower and not any( e in lower for e in ["error", "fail", "incorrect"]) return (1.0 if ok else 0.0), (None if ok else "Task not completed.") # ── SECTION 9: MetaClaw Core — Algorithm 1 ─────────────────────────────────── class MetaClaw: """ MetaClaw: Continual Meta-Learning for Deployed LLM Agents. Implements Algorithm 1 — the main serving loop that continuously improves M = (θ, S) through normal usage via two loops: Fast (seconds): skill-driven adaptation from failures → S update Slow (hours) : opportunistic RL policy optimization → θ update """ def __init__(self, cfg=None, llm_client=None, training_backend=None, calendar_client=None, mock_idle=False, simulated_base_accuracy=0.25): self.cfg = cfg or MetaClawConfig() self.library = SkillLibrary(self.cfg) # S self.evolver = SkillEvolver(self.cfg, llm_client) self.buffer = RLBuffer(self.cfg.buffer_max_size) self.prm = ProcessRewardModel() self.finetuner = CloudLoRAFinetuner(self.cfg, training_backend) self.omls = OMLS(self.cfg, calendar_client, mock_idle=mock_idle) self.executor = AgentExecutor( self.library, self.cfg, llm_client, simulated_base_accuracy) self._support_set: List[Trajectory] = [] self.stats = {"tasks_served":0, "skills_created":0, "rl_updates":0, "total_reward":0.0} def serve(self, task: Task) -> Trajectory: """ Algorithm 1, lines 2-23. Execute → stamp → route → maybe adapt → maybe optimize. """ # Lines 4-6: Execute and stamp with current generation traj = self.executor.execute(task, self.prm) self.stats["tasks_served"] += 1 self.stats["total_reward"] += traj.reward log.info(f"Task [{task.task_id}] reward={traj.reward:.3f} " f"gen={traj.skill_generation} skills={traj.active_skill_names}") # Lines 7-11: Route to support set or RL buffer if traj.is_failure: traj.role = DataRole.SUPPORT self._support_set.append(traj) else: traj.role = DataRole.QUERY self.buffer.add(traj) # Lines 13-18: Skill-driven fast adaptation if len(self._support_set) >= self.cfg.skill_failure_threshold: self._run_skill_adaptation() # Lines 20-23: Opportunistic policy optimization self._maybe_run_rl_update() return traj def _run_skill_adaptation(self) -> None: """Eq. 3: S_{g+1} = S_g ∪ E(S_g, D^sup_g)""" log.info(f"[Evolver] Analyzing {len(self._support_set)} failures...") new_skills = self.evolver.evolve(self.library, self._support_set) if new_skills: for s in new_skills: self.library.add(s) self.stats["skills_created"] += len(new_skills) self.library.increment_generation() self.buffer.flush_stale(self.library.generation) # versioning self.library.save() self._support_set.clear() def _maybe_run_rl_update(self) -> None: """Lines 20-23: OMLS idle check → GRPO update → hot-swap.""" idle, sig = self.omls.is_idle() if not idle or len(self.buffer) < self.cfg.rl_batch_size: return log.info(f"[OMLS] Idle ({sig.value}). Buffer={len(self.buffer)}. Running RL...") batch = self.buffer.sample(self.cfg.rl_batch_size) m = self.finetuner.update(batch, self.library) self.finetuner.hot_swap_weights() self.stats["rl_updates"] += 1 log.info(f"[RL] step={m['step']} loss={m['loss']:.4f} " f"mean_reward={m['mean_reward']:.4f}") def get_stats(self) -> Dict: n = max(1, self.stats["tasks_served"]) return {**self.stats, "mean_reward": self.stats["total_reward"]/n, "skill_library_size": len(self.library.skills), "skill_generation": self.library.generation, "buffer_size": len(self.buffer)} # ── SECTION 10: MetaClaw-Bench Dataset Helpers ─────────────────────────────── def make_task(day: int, round_: int, part: int = 1) -> Task: """Synthetic MetaClaw-Bench task with automated checker.""" templates = [ ("Update sprint board and set task statuses to done", "file-check"), ("Create deployment log with ISO 8601 timestamp and env fields", "file-check"), ("Which approach correctly uses status check before write?", "multi-choice"), ("Append completion record to done.log with all required fields", "file-check"), ("What timestamp format is required for Asia/Shanghai timezone?", "multi-choice"), ] instr, ttype = templates[(day*3+round_) % len(templates)] def checker(response: str) -> Tuple[bool, Optional[str]]: r = response.lower() needs_bak = any(k in instr.lower() for k in ["update","append"]) needs_ts = any(k in instr.lower() for k in ["timestamp","log"]) if ttype == "file-check": if needs_bak and ".bak" not in r: return False, "Missing .bak backup (P4)" if needs_ts and "+08:00" not in response: return False, "Missing +08:00 timezone offset (P1)" return "done" in r, "Task not confirmed." return True, None return Task(task_id=f"P{part}_d{day:02d}_r{round_}", instruction=instr, task_type=ttype, checker_fn=checker) def run_benchmark(agent: MetaClaw, n_days=5, tasks_per_day=6) -> Dict: day_results = {} for day in range(1, n_days+1): ok = sum(1 for r in range(tasks_per_day) if not agent.serve(make_task(day, r)).is_failure) day_results[f"day_{day:02d}"] = {"accuracy": ok/tasks_per_day} log.info(f"Day {day:02d} accuracy: {ok/tasks_per_day:.1%}") return {**agent.get_stats(), "per_day": day_results} # ── Utilities ───────────────────────────────────────────────────────────────── class SimpleEmbedder: """ Hash-based pseudo-embedder for smoke-test. Replace with: SentenceTransformer('all-MiniLM-L6-v2').encode(text) """ def __init__(self, dim=384): self.dim = dim def encode(self, text: str) -> List[float]: seed = int(hashlib.sha256(text.encode()).hexdigest()[:8], 16) rng = random.Random(seed) raw = [rng.gauss(0, 1) for _ in range(self.dim)] n = sum(x**2 for x in raw)**0.5 + 1e-8 return [x/n for x in raw] def cosine_sim(a, b) -> float: dot = sum(x*y for x,y in zip(a,b)) return dot / ((sum(x**2 for x in a)**0.5)*(sum(x**2 for x in b)**0.5)+1e-8) # ── SECTION 11: Smoke Test ──────────────────────────────────────────────────── if __name__ == "__main__": print("="*65) print(" MetaClaw — Full Framework Smoke Test") print("="*65) # 1. Initialize print("\n[1/5] Initializing MetaClaw...") cfg = MetaClawConfig(skill_failure_threshold=3, rl_batch_size=4, max_new_skills_per_run=2, skill_library_path="/tmp/mc_smoke.json") agent = MetaClaw(cfg=cfg, mock_idle=True, simulated_base_accuracy=0.2) print(f" Skills in library: {len(agent.library.skills)} | Gen: {agent.library.generation}") # 2. Verify empty retrieval print("\n[2/5] Testing retrieval (empty library)...") assert agent.library.retrieve("Update JSON file") == [] print(" ✓ Empty library returns []") # 3. Serve tasks → trigger skill evolution print("\n[3/5] Serving 12 tasks → triggering skill evolver...") trajs = [agent.serve(make_task(1, r)) for r in range(12)] ok = sum(1 for t in trajs if not t.is_failure) print(f" Successes: {ok}/12 | Skills: {len(agent.library.skills)} | Gen: {agent.library.generation}") assert len(agent.library.skills) > 0, "Skill evolver should have fired" # 4. Verify no stale samples in buffer print("\n[4/5] Verifying skill generation versioning...") gens = {t.skill_generation for t in agent.buffer.buffer} assert all(g >= agent.library.generation-1 for g in gens), \ "Stale trajectories leaked into RL buffer!" print(f" ✓ Buffer generations: {sorted(gens)} — no stale data.") # 5. Run 5-day benchmark simulation print("\n[5/5] 5-day MetaClaw-Bench simulation...") results = run_benchmark(agent, n_days=5, tasks_per_day=6) print("\n Per-Day Accuracy:") for day, info in results["per_day"].items(): acc = info["accuracy"] bar = "█"*int(acc*20) + "░"*(20-int(acc*20)) print(f" {day}: [{bar}] {acc:.1%}") print("\n Final Statistics:") for k, v in results.items(): if k != "per_day": print(f" {k:25s} = {v:.4f}" if isinstance(v, float) else f" {k:25s} = {v}") print("\n"+"="*65) print(" ✓ All checks passed. MetaClaw is ready for deployment.") print("="*65) print(""" Next steps: 1. pip install sentence-transformers # replace SimpleEmbedder 2. Plug in your LLM provider: agent = MetaClaw(cfg=cfg, llm_client=your_client) 3. Connect cloud LoRA backend (Tinker / MinT): agent = MetaClaw(cfg=cfg, training_backend=tinker_client) 4. Enable Google Calendar OMLS signal: agent = MetaClaw(cfg=cfg, calendar_client=gcal_service) 5. Skills auto-persist to cfg.skill_library_path after each evolution. """)
Read the Full Paper & Access the Code
The complete MetaClaw study — including ablation tables, per-day accuracy traces, case studies, and the AutoResearchClaw pipeline — is available on arXiv and the authors’ GitHub.
Xia, P., Chen, J., Yang, X., Tu, H., Liu, J., Xiong, K., Han, S., Qiu, S., Ji, H., Zhou, Y., Zheng, Z., Xie, C., & Yao, H. (2026). MetaClaw: Just Talk — An Agent That Meta-Learns and Evolves in the Wild. arXiv:2603.17187v1.
Independent editorial analysis of peer-reviewed research. The Python implementation is an educational adaptation. In production, replace SimpleEmbedder with sentence-transformers, connect a real LLM provider, and configure a cloud LoRA backend such as Tinker or MinT. Refer to the official GitHub repository for exact configurations and pretrained components.