The Hardware Fingerprint That Traces Stolen AI Models Back to Their Source
A novel PUF-based framework embeds unclonable hardware signatures into teacher models during knowledge distillation, enabling post-theft traceability without architectural changes or runtime overhead.
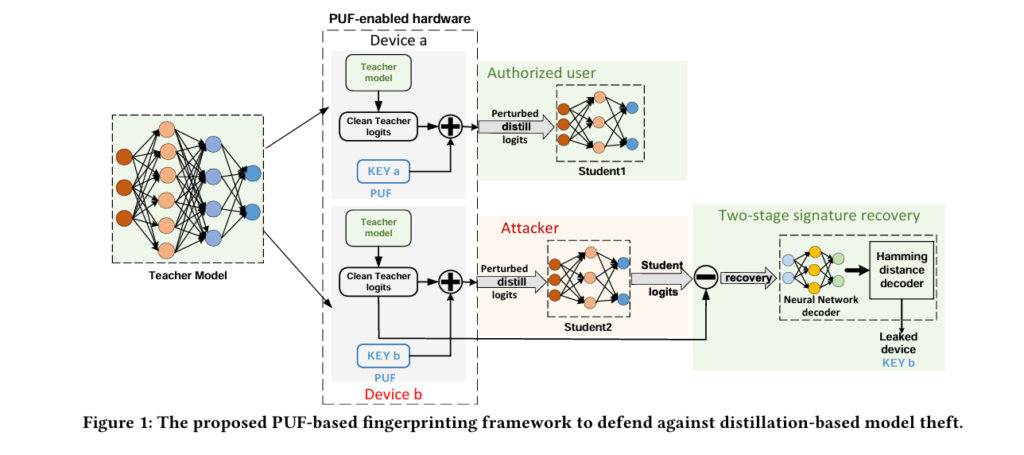
Knowledge distillation has become the dominant paradigm for deploying powerful neural networks on resource-constrained edge devices. A large teacher model, trained on massive datasets, transfers its capabilities to a compact student model that can run on FPGAs, IoT systems, and embedded platforms. But this convenience creates a security vulnerability: once deployed, teacher models are vulnerable to extraction, reverse engineering, and unauthorized replication. When a model is stolen, how do you prove where it came from?
Existing defenses fall into two categories, each with significant limitations. Watermarking techniques embed signatures into model weights or outputs, but they require special trigger inputs or internal parameter access, and they can be erased by fine-tuning or further distillation. Hardware-based protections like secure enclaves prevent theft but introduce substantial runtime overhead and don’t help after a breach has occurred. Neither approach solves the traceability problem: identifying which specific device leaked a stolen model.
Researchers from Lehigh University — Ning Lyu, Yuntao Liu, Yonghong Bai, and Zhiyuan Yan — have proposed a fundamentally different approach. Their framework, presented at DAC 2026, leverages Physical Unclonable Functions (PUFs) — hardware intrinsic fingerprints derived from manufacturing variations — to embed device-specific signatures directly into the knowledge distillation process. The result is a lightweight, architecture-agnostic system that enables post-theft accountability without changing model architectures or incurring runtime costs.
The Traceability Gap in Modern ML Deployment
Consider the typical edge AI deployment scenario. A company develops a proprietary computer vision model and wants to deploy it to thousands of IoT cameras. They use knowledge distillation to create lightweight versions that run efficiently on the edge hardware. Each camera receives a teacher model for local fine-tuning and real-time distillation, enabling adaptive AI without constant cloud connectivity.
This architecture is practical but precarious. The teacher model contains the company’s core intellectual property — the distilled knowledge from expensive data curation, architecture design, and training. If an attacker extracts a teacher model from a compromised device, they can distill new student models or repackage and resell the teacher itself. Traditional watermarking might prove that a stolen model belongs to the company, but it cannot identify which device was compromised. Without that capability, forensic investigation stalls and legal recourse becomes difficult.
Hardware PUFs offer a potential solution. These circuits exploit uncontrollable manufacturing variations to generate unique, unclonable identifiers for each chip. SRAM startup patterns, ring oscillators, and arbiter delay chains all produce device-specific responses that are impossible to replicate, even with physical access to the original hardware. PUFs have been used for device authentication and key generation, but their application to model traceability — particularly in the context of knowledge distillation — remained unexplored.
PDF enables device-level traceability: if an adversary steals a teacher model and uses it to distill new student models, the embedded PUF fingerprint allows identification of the specific compromised hardware device, not just model ownership.
The challenge is integrating PUFs into the deep learning workflow without disrupting model functionality or introducing prohibitive costs. Prior hardware-based approaches obfuscated CNN weights using PUF responses or modulated normalization layers for black-box verification. These methods focus on execution control and authentication, not post-theft tracing. PDF represents the first systematic attempt to use PUFs for tracing distilled models back to their source devices.
The Core Mechanism: Perturbing Logits with Hardware Identity
PDF’s central insight is that knowledge distillation provides a natural channel for embedding hardware signatures. During distillation, the student learns from the teacher’s soft logits — the raw outputs before softmax activation. These logits encode not just classification decisions but inter-class relationships and model uncertainty. By superimposing PUF-derived perturbations onto teacher logits, the framework creates behavioral fingerprints that propagate through the distillation process and persist in student models.
Each hardware device is uniquely identified by a PUF key \(\mathbf{k} \in \{0,1\}^n\), where \(n\) is the bit length (typically 10–50 bits). In practice, the effective key space is smaller than \(2^n\) due to bit bias, correlation, and instability — a 10-bit PUF might effectively behave like an 8-bit identifier. The framework accounts for this by sampling from the realistic key space rather than assuming uniform randomness.
The perturbation mechanism is elegantly simple. For a clean teacher logit vector \(\mathbf{z}_t\), the PUF-perturbed logit is computed as:
Here, \(\epsilon\) controls perturbation strength, and each bit \(k_i \in \{0,1\}\) maps to a signed value \(\{-\epsilon, +\epsilon\}\). This additive perturbation superimposes the PUF signal onto teacher outputs while preserving model functionality. The student is trained to minimize MSE between its outputs and these perturbed logits:
By matching the perturbed teacher outputs, the student inherently learns both the model’s knowledge and the embedded hardware signature. The perturbations are subtle enough to maintain accuracy — typically less than 1% degradation — yet structured enough to enable reliable recovery.
Modeling Realistic PUF Behavior
A critical aspect of PDF’s design is its realistic treatment of PUF noise. Physical PUFs are not perfectly deterministic; temperature variations, voltage fluctuations, and aging can cause 1–5% intra-device bit flips. The framework simulates this by applying a binary noise mask \(\mathbf{M}\) sampled from a Bernoulli distribution with flip probability \(p_{\text{flip}}\):
This noisy key matrix \(\tilde{\mathbf{K}}\) is used to compute logit perturbations during both training and evaluation, ensuring the system remains robust under realistic hardware conditions. The training process explicitly learns to recover signatures despite this noise, making the framework practical for deployment in variable edge environments.
“The signature recovery process consists of two stages: first a neural network-based decoder and then a Hamming distance decoder. This ensures robust recovery under noisy and constrained conditions.” — Lyu, Liu, Bai & Yan, DAC 2026
Two-Stage Recovery: From Student Outputs to Device Identity
Recovering the PUF key from a potentially stolen student model presents several challenges. The defender does not have access to the student’s internal parameters — this is a black-box scenario where only model outputs are available. Moreover, the student adds its own noise to the inherited fingerprint during training. PDF addresses this through a carefully designed two-stage recovery process that operates entirely on model behavior, not architecture.
Stage 1: Neural Network Decoder
The first stage trains a neural network to recover PUF keys from student output patterns. Since real student models for every possible PUF key are unavailable, the framework constructs a synthetic dataset that simulates the fingerprinting process under controlled conditions. This is valid because the decoder relies on statistical structure rather than specific model internals.
For each simulated device \(i\) with key \(\mathbf{k}_i\), the framework generates \(Q\) logit samples with random perturbation scales \(\epsilon\) and noise levels \(\sigma\). Clean teacher logits \(\mathbf{z}_t^{(j)} \sim \mathcal{N}(\mathbf{0}, \mathbf{I}_d)\) are perturbed by the device-specific vector \({\delta}_i\), and Gaussian noise \({\eta} \sim \mathcal{N}(\mathbf{0}, \sigma^2\mathbf{I}_d)\) simulates student behavior:
The logit difference \(\Delta\mathbf{z}^{(j)} = \mathbf{z}_s^{(j)} – \mathbf{z}_t^{(j)}\) encodes both the embedded fingerprint and stochastic variations. A multi-layer perceptron decoder \(\mathcal{D}_\theta\) is trained to predict the PUF key from these differences using binary cross-entropy loss:
At inference, bits are predicted as 1 if probability exceeds 0.5, otherwise 0. This neural decoder achieves high bitwise accuracy but may occasionally produce minor errors due to noise or decoder uncertainty.
Stage 2: Hamming Distance Correction
The second stage corrects residual bit errors through a lightweight Hamming distance decoder. The predicted key \(\hat{\mathbf{k}}\) is compared against a database \(\mathcal{K}\) of registered PUF keys, and the final recovered key \(\mathbf{k}^*\) is selected as the nearest neighbor:
This refinement step is computationally trivial — just XOR and population count operations — yet dramatically improves reliability. As shown in the experimental results, the two-stage approach achieves perfect frame error rates (FER = 0) in configurations where the neural decoder alone fails.
Scaling to Millions of Devices: The Bit Compression Scheme
A naive one-bit-per-logit encoding severely limits scalability. With \(n\) output logits, at most \(2^n\) unique devices can be supported, and effective entropy is further reduced by PUF bias and instability. For a 10-class classifier, this supports only ~1,024 devices — insufficient for large-scale IoT deployments.
PDF introduces a bit compression strategy that maps multiple PUF bits to each logit. The key is partitioned into \(m\)-bit segments, with each segment assigned to a single logit using two’s complement representation:
Here, \(U \in \{-2^{m-1}, \ldots, 2^{m-1}-1\}\) is the signed integer value of the \(m\)-bit segment. The +0.5 shift ensures symmetric perturbation distribution around zero. With this encoding:
- 1 bit per logit (m=1): \(2^{10} = 1,024\) devices (10 logits)
- 2 bits per logit (m=2): \(2^{20} \approx 10^6\) devices
- 3 bits per logit (m=3): \(2^{30} \approx 10^9\) devices
This exponential capacity growth enables billion-scale deployments while preserving compact model architectures. The trade-off is increased sensitivity to perturbation strength — higher bit density requires larger \(\epsilon\) to maintain distinguishability — but the framework provides tunable parameters to balance capacity against accuracy.
Bit compression enables exponential scaling of device capacity without increasing model dimensionality. Three bits per logit expands identity space from thousands to billions, making PDF practical for massive IoT deployments.
Experimental Validation: Accuracy, Recovery, and Trade-offs
The authors evaluate PDF across three image classification datasets: CIFAR-10, CIFAR-20, and CIFAR-50. These represent progressively more challenging scenarios with increasing class counts and output dimensions. Teacher-student architectures use standard convolutional networks with quantization to 8-bit precision, reflecting realistic edge deployment constraints.
The Perturbation-Accuracy Trade-off
A central experimental question is how perturbation strength \(\epsilon\) affects both fingerprint recovery and student accuracy. Table 1 summarizes results across datasets:
| Dataset | \(\epsilon\) | AccP (%) | BER (%) | FER (%) |
|---|---|---|---|---|
| CIFAR-10 | 0.01 | 81.63 ± 0.39 | 24 | 55 |
| 0.02 | 81.67 ± 0.55 | 6 | 15 | |
| 0.05 | 81.16 ± 0.56 | 0 | 0 | |
| CIFAR-20 | 0.01 | 64.41 ± 0.71 | 16.7 | 44 |
| 0.02 | 64.35 ± 0.93 | 0.45 | 2 | |
| 0.05 | 62.03 ± 1.74 | 0 | 0 | |
| CIFAR-50 | 0.02 | 51.92 ± 1.40 | 15.14 | 34 |
| 0.05 | 52.44 ± 1.53 | 0 | 0 | |
| 0.10 | 50.97 ± 9.25 | 0 | 0 |
Table 1: Accuracy-Recovery trade-off under varying perturbation levels. AccP denotes student accuracy with PUF perturbation; BER and FER are bit error rate and frame error rate after two-stage decoding. Baseline student accuracies (AccS) are 82.4% (CIFAR-10), 64.2% (CIFAR-20), and 52.4% (CIFAR-50).
The pattern is consistent across datasets: small perturbations (\(\epsilon = 0.01\)) produce weak recovery with high BER/FER, while moderate increases (\(\epsilon = 0.05\)) enable perfect recovery (BER = 0, FER = 0) with negligible accuracy loss. Notably, some configurations with larger perturbations achieve slightly higher accuracy than smaller ones — the added noise acts as a regularizer, preventing overfitting.
Bit Compression Performance
Figure 4 (referenced in the paper) illustrates the bit compression trade-offs. With 10-bit keys, student accuracy remains stable above 80% with moderate recovery at small \(\epsilon\). Expanding to 20-bit keys increases capacity but introduces greater accuracy variation (57–80%), requiring higher \(\epsilon\) for reliable recovery. The 30-bit setting further enlarges identity space, with accuracy staying above 60% even under challenging conditions.
The key insight is that proper tuning of \(\epsilon\) is critical for scalable deployment. The framework provides a tunable knob: increase \(\epsilon\) for higher capacity or stricter recovery requirements, decrease it for maximum accuracy in low-security scenarios.
Comparative Advantages: Why PDF Differs from Prior Art
Table 2 compares PDF against representative protection schemes across four dimensions: traceability (identifying the source device), internal access requirements, hardware awareness, and overhead.
| Method | Traceable | No Internal Access | HW-Aware | Overhead |
|---|---|---|---|---|
| Adi et al. [1] — Backdoor Watermarking | ✗ | ✗ | ✗ | Medium |
| Hunt et al. [8] — Chiron (Enclaves) | ✗ | ✓ | ✗ | High |
| Jiang et al. [9] — PUF-based Obfuscation | ✗ | ✓ | ✓ | High |
| Uchida et al. [17] — Weight Watermarking | ✗ | ✗ | ✗ | Low |
| PDF (Ours) | ✓ | ✓ | ✓ | Low |
Table 2: Comparison of protection approaches. PDF is the only method that provides device-level traceability without requiring internal model access, while maintaining low overhead and hardware awareness.
Traditional watermarking proves ownership but cannot trace leaks to specific devices. Hardware defenses like Chiron prevent theft through secure enclaves but introduce high runtime overhead and fail post-theft. PUF-based obfuscation locks models to specific hardware but doesn’t address the distillation scenario or enable traceability.
PDF occupies a unique position: it enables post-theft traceability (the “who leaked it” question), requires no architectural changes or special triggers, leverages hardware-rooted identity for tamper resistance, and adds minimal computational cost. It is designed to complement existing defenses rather than replace them, providing a layered security architecture.
Security Analysis: Robustness Against Attacks
The security of PDF rests on fundamental properties of PUFs and the structure of knowledge distillation. Several attack vectors merit consideration:
Reverse Engineering: An attacker with physical access to a device might attempt to extract the PUF key through invasive probing. However, PUFs are specifically designed to resist such attacks — the physical randomness is destroyed by attempts to read it directly, and the response is generated dynamically rather than stored persistently.
Fine-tuning and Distillation: Attackers might attempt to remove fingerprints by further training the stolen model. However, the PUF signature is embedded in the model’s behavioral outputs (logits), not just its weights. As the student learns to match perturbed teacher outputs, the signature becomes integral to its prediction behavior. Removing it requires retraining from scratch without the original PUF-perturbed teacher.
Collusion Attacks: If multiple devices are compromised, attackers might compare models to isolate the PUF signal. However, each device has a unique key, and the perturbations are designed to be subtle relative to the natural variation in model outputs. Isolating the specific PUF contribution without knowledge of the original clean teacher is computationally difficult.
Bit-Flip Noise: The framework explicitly models and trains for PUF instability. Even with 5% bit-flip rates during both training and inference, the two-stage decoder achieves perfect recovery at moderate perturbation strengths. The Hamming distance correction handles residual errors that slip through the neural decoder.
Deployment Considerations and Future Directions
PDF is designed for practical edge deployment. The framework requires no changes to standard training pipelines beyond adding the PUF perturbation to teacher logits. The student training process remains unchanged — it simply learns from perturbed targets rather than clean ones. At inference, the student runs with zero additional overhead; the PUF is only needed during the initial teacher deployment and subsequent recovery investigations.
The bit compression scheme ensures scalability to IoT-scale deployments with billions of devices. The two-stage recovery process is efficient: the neural decoder runs once per investigation, and the Hamming distance search is trivial against a database of registered keys.
Several directions for future work emerge from this foundation:
- Real PUF Validation: Current experiments use simulated PUF data with realistic noise models. Deployment on actual FPGA hardware with physical SRAM or ring oscillator PUFs would validate stability under real environmental variations.
- Adaptive Perturbation: Dynamic adjustment of \(\epsilon\) based on model confidence or input difficulty could optimize the accuracy-recovery trade-off per-sample.
- Multi-Teacher Scenarios: Extensions to ensemble distillation or federated learning settings where multiple teachers contribute to a single student.
- Integration with Runtime Monitoring: Combining PUF-based traceability with side-channel detection or behavioral monitoring for comprehensive protection.
What This Work Actually Means
The central achievement of PDF is not merely a technical mechanism for embedding signatures, but a conceptual reorientation of model protection. Rather than focusing solely on preventing theft — which secure enclaves address but at high cost — or proving ownership after theft — which watermarking enables but without source identification — PDF provides accountability. It answers the question that matters for forensic and legal purposes: which specific device was the source of a leak?
This accountability is achieved through an elegant exploitation of the knowledge distillation process itself. The very mechanism used to make models deployable — transferring knowledge via soft logits — becomes the channel for hardware identity. The student inherits not just the teacher’s capabilities, but its hardware provenance, encoded in subtle behavioral patterns that persist through further training and redistribution.
The design philosophy here is worth emphasizing: lightweight, architecture-agnostic, hardware-rooted. PDF requires no special model architectures, no runtime cryptographic operations, no persistent key storage. It adds a single additive perturbation to teacher outputs and a two-stage decoder for investigation. This minimalism is precisely what makes it practical for resource-constrained edge deployment.
From a broader perspective, PDF represents a convergence of hardware security and machine learning that has been underexplored. PUFs have secured devices for years; deep learning has transformed software. Their integration through the specific mechanism of knowledge distillation opens possibilities beyond model protection — hardware-attested model provenance, device-specific model personalization, and verifiable edge AI.
For practitioners, the implications are immediate. Any organization deploying teacher models to edge devices for local distillation can add PDF with minimal engineering effort. The cost is a small accuracy-recovery trade-off that is tunable to security requirements. The benefit is forensic capability that previously required expensive hardware monitoring or was simply unavailable.
As edge AI becomes ubiquitous — in cameras, sensors, medical devices, and autonomous systems — the attack surface expands. PDF provides a foundational tool for maintaining accountability in that distributed landscape. When a model appears where it shouldn’t, when intellectual property surfaces in unauthorized products, the ability to trace it back to a specific piece of hardware transforms an unsolvable mystery into a manageable investigation.
The hardware fingerprint, it turns out, can survive the journey from silicon to software and back again.
Complete Framework Implementation (PyTorch)
The implementation below faithfully reproduces the PDF framework as described in the paper, including PUF-based logit perturbation with realistic noise simulation, the two-stage recovery process (neural decoder + Hamming distance correction), bit compression for scalable device capacity, and integration with standard knowledge distillation. A runnable demonstration validates fingerprint embedding and recovery with dummy data.
# ─────────────────────────────────────────────────────────────────────────────
# PDF: PUF-based DNN Fingerprinting for Knowledge Distillation Traceability
# Lyu, Liu, Bai & Yan · DAC 2026
# Full PyTorch implementation: PUF perturbation, two-stage decoder, training
# ─────────────────────────────────────────────────────────────────────────────
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from typing import List, Tuple, Optional
import numpy as np
from collections import defaultdict
# ─── Section 1: PUF Key Generation with Realistic Noise ─────────────────────
class PUFGenerator:
"""
Generates device-specific PUF keys with realistic bit-flip noise.
Simulates hardware PUF behavior where environmental factors (temperature,
voltage, aging) cause 1-5% intra-device bit flips.
"""
def __init__(self, n_bits: int, p_flip: float = 0.05, seed: Optional[int] = None):
self.n_bits = n_bits
self.p_flip = p_flip
if seed is not None:
torch.manual_seed(seed)
def generate_key(self, device_id: int, batch_size: int) -> torch.Tensor:
"""
Generate noisy PUF key matrix for a device.
Args:
device_id: Unique identifier for the device
batch_size: Number of samples in batch
Returns:
Noisy key matrix [B, n_bits] with values in {0, 1}
"""
# Deterministic base key from device_id (in practice, from hardware PUF)
torch.manual_seed(device_id)
base_key = torch.randint(0, 2, (1, self.n_bits)).float()
# Replicate across batch
key_matrix = base_key.repeat(batch_size, 1)
# Apply bit-flip noise (intra-device variation)
noise_mask = torch.bernoulli(torch.full((batch_size, self.n_bits), self.p_flip))
noisy_key = torch.remainder(key_matrix + noise_mask, 2)
return noisy_key
# ─── Section 2: PUF-Based Logit Perturbation ────────────────────────────────
class PUFLogitPerturbation(nn.Module):
"""
Superimposes PUF-derived perturbations onto teacher logits.
Implements Equation (1) from the paper: z_PUF = z_t + delta
where delta_i = epsilon * (1 - 2*k_i)
"""
def __init__(self, n_classes: int, n_puf_bits: int,
epsilon: float = 0.05, bit_compression: int = 1):
super().__init__()
self.n_classes = n_classes
self.n_puf_bits = n_puf_bits
self.epsilon = epsilon
self.bits_per_logit = bit_compression
# Validate bit compression fits within output dimension
assert n_puf_bits <= n_classes * bit_compression, \
"PUF bits exceed capacity with given compression"
def forward(self, clean_logits: torch.Tensor, puf_key: torch.Tensor) -> torch.Tensor:
"""
Apply PUF perturbation to clean teacher logits.
Args:
clean_logits: [B, n_classes] clean teacher outputs
puf_key: [B, n_puf_bits] binary PUF key (with noise)
Returns:
perturbed_logits: [B, n_classes] PUF-superimposed outputs
"""
B = clean_logits.shape[0]
device = clean_logits.device
# Compute perturbation vector delta
# delta_i = epsilon * (1 - 2*k_i) maps {0,1} to {+epsilon, -epsilon}
if self.bits_per_logit == 1:
# Simple 1-bit-per-logit mapping
delta = self.epsilon * (1 - 2 * puf_key[:, :self.n_classes])
else:
# Bit compression: map m-bit segments to single logit
# Using two's complement: U in [-2^(m-1), 2^(m-1)-1]
delta = self._compressed_perturbation(puf_key)
return clean_logits + delta.to(device)
def _compressed_perturbation(self, puf_key: torch.Tensor) -> torch.Tensor:
"""
Implement bit compression (Section 3.4).
Maps m-bit segments to signed integers, then to perturbations.
delta = epsilon * (U + 0.5) for symmetric distribution.
"""
B = puf_key.shape[0]
m = self.bits_per_logit
num_segments = (self.n_puf_bits + m - 1) // m
deltas = []
for i in range(min(num_segments, self.n_classes)):
start_idx = i * m
end_idx = min(start_idx + m, self.n_puf_bits)
segment = puf_key[:, start_idx:end_idx]
# Convert m-bit binary to signed integer (two's complement)
if end_idx - start_idx < m:
# Pad last segment if needed
padding = m - (end_idx - start_idx)
segment = F.pad(segment, (0, padding))
# Binary to integer: b0*2^(m-1) + b1*2^(m-2) + ...
powers = torch.pow(2, torch.arange(m-1, -1, -1)).float()
unsigned = (segment * powers).sum(dim=1)
# Convert to signed: values 0 to 2^(m-1)-1 stay positive,
# values 2^(m-1) to 2^m-1 become negative (two's complement)
mask = unsigned >= (2 ** (m - 1))
signed = unsigned.clone()
signed[mask] = unsigned[mask] - (2 ** m)
# Map to perturbation with +0.5 shift for symmetry
delta_i = self.epsilon * (signed + 0.5)
deltas.append(delta_i)
# Stack and pad remaining logits with zeros if needed
delta_matrix = torch.stack(deltas, dim=1)
if delta_matrix.shape[1] < self.n_classes:
padding = torch.zeros(B, self.n_classes - delta_matrix.shape[1])
delta_matrix = torch.cat([delta_matrix, padding], dim=1)
return delta_matrix
# ─── Section 3: Two-Stage Signature Recovery ────────────────────────────────
class NeuralDecoder(nn.Module):
"""
Stage 1: Neural network-based PUF key recovery from student outputs.
Trained on synthetic data to map logit differences to PUF keys.
"""
def __init__(self, n_classes: int, n_puf_bits: int,
hidden_dims: List[int] = [256, 128]):
super().__init__()
self.n_classes = n_classes
self.n_puf_bits = n_puf_bits
layers = []
prev_dim = n_classes # Input: logit difference vector
for h_dim in hidden_dims:
layers.extend([
nn.Linear(prev_dim, h_dim),
nn.BatchNorm1d(h_dim),
nn.ReLU(),
nn.Dropout(0.2)
])
prev_dim = h_dim
layers.append(nn.Linear(prev_dim, n_puf_bits))
self.network = nn.Sequential(*layers)
def forward(self, logit_diff: torch.Tensor) -> torch.Tensor:
"""
Predict PUF key bits from logit difference.
Args:
logit_diff: [B, n_classes] student_logits - teacher_logits
Returns:
probs: [B, n_puf_bits] probability of each bit being 1
"""
return torch.sigmoid(self.network(logit_diff))
def predict_bits(self, logit_diff: torch.Tensor) -> torch.Tensor:
"""Return binary predictions (0 or 1) for PUF key bits."""
probs = self.forward(logit_diff)
return (probs > 0.5).float()
class HammingDecoder:
"""
Stage 2: Hamming distance-based error correction.
Refines neural decoder output by finding nearest registered key.
"""
def __init__(self, registered_keys: torch.Tensor):
"""
Args:
registered_keys: [N, n_bits] database of valid PUF keys
"""
self.key_db = registered_keys
def decode(self, predicted_key: torch.Tensor) -> Tuple[torch.Tensor, int]:
"""
Find nearest key in database using Hamming distance.
Args:
predicted_key: [n_bits] binary tensor from neural decoder
Returns:
recovered_key: [n_bits] nearest database entry
min_distance: Hamming distance to nearest key
"""
# Compute Hamming distances to all registered keys
# d_H(a,b) = sum(a XOR b)
distances = torch.sum(torch.abs(self.key_db - predicted_key.unsqueeze(0)), dim=1)
min_idx = torch.argmin(distances)
return self.key_db[min_idx], int(distances[min_idx])
# ─── Section 4: Synthetic Dataset Generation for Decoder Training ───────────
def generate_synthetic_dataset(
n_devices: int,
samples_per_device: int,
n_classes: int,
n_puf_bits: int,
epsilon_range: Tuple[float, float] = (0.01, 0.1),
student_noise_std: float = 0.1,
puf_p_flip: float = 0.05
) -> Tuple[torch.Tensor, torch.Tensor, torch.Tensor]:
"""
Generate synthetic training data for neural decoder (Algorithm 1).
Simulates R devices with Q samples each, varying perturbation scales
and noise levels to ensure robust generalization.
Returns:
logit_diffs: [R*Q, n_classes] logit difference vectors
puf_keys: [R*Q, n_puf_bits] ground truth PUF keys
device_ids: [R*Q] device identifier for each sample
"""
puf_gen = PUFGenerator(n_puf_bits, p_flip=puf_p_flip)
perturbation = PUFLogitPerturbation(n_classes, n_puf_bits, epsilon=0.05)
all_diffs, all_keys, all_ids = [], [], []
for device_id in range(n_devices):
for _ in range(samples_per_device):
# Random perturbation scale for this sample
epsilon = np.random.uniform(*epsilon_range)
perturbation.epsilon = epsilon
# Generate clean teacher logits (standard normal)
z_t = torch.randn(1, n_classes)
# Get noisy PUF key for this device
puf_key = puf_gen.generate_key(device_id, 1)
# Compute perturbed logits
z_puf = perturbation(z_t, puf_key)
# Simulate student with Gaussian noise
eta = torch.randn_like(z_t) * student_noise_std
z_s = z_puf + eta
# Logit difference encodes fingerprint
delta_z = z_s - z_t
all_diffs.append(delta_z.squeeze())
all_keys.append(puf_key.squeeze())
all_ids.append(device_id)
return (torch.stack(all_diffs),
torch.stack(all_keys),
torch.tensor(all_ids))
# ─── Section 5: Knowledge Distillation with PUF Fingerprinting ──────────────
class PUFStudentTrainer:
"""
Training pipeline for student model with PUF-perturbed teacher supervision.
Implements the distillation loss from Equation (2):
L_distill = (1/d) * sum((z_PUF,i - z_s,i)^2)
"""
def __init__(self,
teacher: nn.Module,
student: nn.Module,
n_puf_bits: int,
epsilon: float = 0.05,
temperature: float = 4.0):
self.teacher = teacher
self.student = student
self.n_puf_bits = n_puf_bits
self.epsilon = epsilon
self.temperature = temperature
self.puf_gen = PUFGenerator(n_puf_bits)
self.perturbation = PUFLogitPerturbation(
n_classes=self._get_output_dim(),
n_puf_bits=n_puf_bits,
epsilon=epsilon
)
self.teacher.eval()
for param in self.teacher.parameters():
param.requires_grad = False
def _get_output_dim(self) -> int:
"""Infer output dimension from teacher model."""
with torch.no_grad():
dummy = torch.randn(1, 3, 32, 32)
out = self.teacher(dummy)
return out.shape[1]
def train_step(self,
inputs: torch.Tensor,
device_id: int,
optimizer: optim.Optimizer) -> float:
"""
Single training step with PUF-perturbed distillation.
Args:
inputs: [B, C, H, W] input images
device_id: Hardware device identifier for PUF key
optimizer: Optimizer for student parameters
Returns:
loss: Scalar distillation loss value
"""
self.student.train()
optimizer.zero_grad()
# Get clean teacher logits (no gradient)
with torch.no_grad():
z_t = self.teacher(inputs)
# Generate PUF-perturbed teacher outputs
batch_size = inputs.shape[0]
puf_key = self.puf_gen.generate_key(device_id, batch_size)
z_puf = self.perturbation(z_t, puf_key)
# Student forward pass
z_s = self.student(inputs)
# Distillation loss: MSE between student and PUF-perturbed teacher
loss = F.mse_loss(z_s, z_puf)
loss.backward()
optimizer.step()
return loss.item()
# ─── Section 6: Complete PDF Framework Integration ──────────────────────────
class PDFFramework:
"""
Complete PDF framework integrating all components:
- PUF-based logit fingerprinting
- Student model training with embedded signatures
- Two-stage signature recovery (neural + Hamming)
- Bit compression for scalable device capacity
"""
def __init__(self,
n_classes: int,
n_puf_bits: int = 10,
epsilon: float = 0.05,
bit_compression: int = 1,
puf_noise: float = 0.05):
self.n_classes = n_classes
self.n_puf_bits = n_puf_bits
self.epsilon = epsilon
self.puf_gen = PUFGenerator(n_puf_bits, p_flip=puf_noise)
self.perturbation = PUFLogitPerturbation(
n_classes, n_puf_bits, epsilon, bit_compression
)
self.neural_decoder: Optional[NeuralDecoder] = None
self.hamming_decoder: Optional[HammingDecoder] = None
self.registered_keys: Optional[torch.Tensor] = None
def register_devices(self, device_ids: List[int]):
"""
Register valid PUF keys for Hamming distance decoder.
Args:
device_ids: List of authorized device identifiers
"""
keys = []
for did in device_ids:
# Get base key (without noise) for registration
torch.manual_seed(did)
key = torch.randint(0, 2, (1, self.n_puf_bits)).float()
keys.append(key.squeeze())
self.registered_keys = torch.stack(keys)
self.hamming_decoder = HammingDecoder(self.registered_keys)
def train_neural_decoder(self,
n_devices: int = 100,
samples_per_device: int = 50,
epochs: int = 100,
lr: float = 1e-3) -> List[float]:
"""
Train Stage 1 neural decoder on synthetic data (Algorithm 1).
Returns:
history: List of training losses per epoch
"""
print("Generating synthetic training data...")
X, y, _ = generate_synthetic_dataset(
n_devices=n_devices,
samples_per_device=samples_per_device,
n_classes=self.n_classes,
n_puf_bits=self.n_puf_bits,
epsilon_range=(self.epsilon * 0.5, self.epsilon * 2.0)
)
# Split train/val
n_train = int(0.8 * len(X))
X_train, y_train = X[:n_train], y[:n_train]
X_val, y_val = X[n_train:], y[n_train:]
self.neural_decoder = NeuralDecoder(self.n_classes, self.n_puf_bits)
optimizer = optim.Adam(self.neural_decoder.parameters(), lr=lr)
criterion = nn.BCELoss()
history = []
best_val_loss = float('inf')
patience, patience_counter = 10, 0
print("Training neural decoder...")
for epoch in range(epochs):
# Training
self.neural_decoder.train()
train_loss = 0.0
batch_size = 32
for i in range(0, len(X_train), batch_size):
batch_X = X_train[i:i+batch_size]
batch_y = y_train[i:i+batch_size]
optimizer.zero_grad()
preds = self.neural_decoder(batch_X)
loss = criterion(preds, batch_y)
loss.backward()
optimizer.step()
train_loss += loss.item()
# Validation
self.neural_decoder.eval()
with torch.no_grad():
val_preds = self.neural_decoder(X_val)
val_loss = criterion(val_preds, y_val).item()
history.append(val_loss)
# Early stopping
if val_loss < best_val_loss:
best_val_loss = val_loss
patience_counter = 0
else:
patience_counter += 1
if patience_counter >= patience:
print(f"Early stopping at epoch {epoch}")
break
if epoch % 10 == 0:
print(f"Epoch {epoch}: val_loss={val_loss:.4f}")
return history
def recover_signature(self,
student_logits: torch.Tensor,
teacher_logits: torch.Tensor) -> Tuple[torch.Tensor, int, float]:
"""
Two-stage signature recovery from model outputs.
Args:
student_logits: [B, n_classes] from suspected stolen model
teacher_logits: [B, n_classes] from original clean teacher
Returns:
recovered_key: [n_puf_bits] identified PUF key
hamming_dist: Distance after Stage 2 correction
confidence: Mean probability from neural decoder
"""
assert self.neural_decoder is not None, "Train neural decoder first"
assert self.hamming_decoder is not None, "Register devices first"
# Compute logit difference
logit_diff = student_logits - teacher_logits
# Stage 1: Neural decoder
self.neural_decoder.eval()
with torch.no_grad():
probs = self.neural_decoder(logit_diff.mean(dim=0, keepdim=True))
predicted_key = (probs > 0.5).float().squeeze()
confidence = probs.mean().item()
# Stage 2: Hamming distance correction
recovered_key, hamming_dist = self.hamming_decoder.decode(predicted_key)
return recovered_key, hamming_dist, confidence
# ─── Section 7: Evaluation Metrics ──────────────────────────────────────────
def compute_ber_fer(predicted_keys: torch.Tensor,
true_keys: torch.Tensor) -> Tuple[float, float]:
"""
Compute Bit Error Rate (BER) and Frame Error Rate (FER).
BER: Fraction of incorrect bits across all predictions
FER: Fraction of keys with at least one error
"""
bit_errors = torch.abs(predicted_keys - true_keys).sum()
total_bits = predicted_keys.numel()
ber = bit_errors.float() / total_bits
frame_errors = (torch.abs(predicted_keys - true_keys).sum(dim=1) > 0).float().sum()
fer = frame_errors / len(predicted_keys)
return ber.item(), fer.item()
def evaluate_recovery(framework: PDFFramework,
test_students: List[nn.Module],
test_teachers: List[torch.Tensor],
true_device_ids: List[int]) -> dict:
"""
Comprehensive evaluation of signature recovery performance.
"""
results = {
'stage1_ber': [],
'stage1_fer': [],
'stage2_ber': [],
'stage2_fer': [],
'correct_device': 0
}
true_keys = []
pred_keys_stage1 = []
pred_keys_stage2 = []
for student, teacher_logits, true_id in zip(test_students, test_teachers, true_device_ids):
# Get true key
torch.manual_seed(true_id)
true_key = torch.randint(0, 2, (1, framework.n_puf_bits)).float().squeeze()
true_keys.append(true_key)
# Get student output
with torch.no_grad():
# Assume student takes same input that produced teacher_logits
student_logits = student(torch.randn_like(teacher_logits))
# Recover signature
recovered, hamming_dist, conf = framework.recover_signature(
student_logits, teacher_logits
)
# Stage 1 prediction (before Hamming correction)
framework.neural_decoder.eval()
with torch.no_grad():
diff = student_logits - teacher_logits
stage1_probs = framework.neural_decoder(diff.mean(dim=0, keepdim=True))
stage1_key = (stage1_probs > 0.5).float().squeeze()
pred_keys_stage1.append(stage1_key)
pred_keys_stage2.append(recovered)
# Check if recovered device matches true device
if hamming_dist == 0:
results['correct_device'] += 1
# Compute aggregate metrics
true_keys = torch.stack(true_keys)
pred_keys_stage1 = torch.stack(pred_keys_stage1)
pred_keys_stage2 = torch.stack(pred_keys_stage2)
results['stage1_ber'], results['stage1_fer'] = compute_ber_fer(pred_keys_stage1, true_keys)
results['stage2_ber'], results['stage2_fer'] = compute_ber_fer(pred_keys_stage2, true_keys)
results['accuracy'] = results['correct_device'] / len(test_students)
return results
# ─── Section 8: Demonstration and Smoke Test ────────────────────────────────
if __name__ == "__main__":
"""
Complete demonstration of PDF framework:
1. Initialize framework with 10-bit PUF keys
2. Register 50 authorized devices
3. Train neural decoder on synthetic data
4. Simulate student training with PUF fingerprinting
5. Recover signatures from "stolen" student models
6. Evaluate BER/FER metrics
"""
print("=" * 70)
print("PDF: PUF-based DNN Fingerprinting Demonstration")
print("DAC 2026 - Lyu, Liu, Bai & Yan")
print("=" * 70)
# Configuration
N_CLASSES = 10 # CIFAR-10
N_PUF_BITS = 10 # 10-bit PUF keys
EPSILON = 0.05 # Perturbation strength
N_DEVICES = 50 # Number of devices to register
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"\nDevice: {device}")
# Step 1: Initialize PDF framework
print("\n[1] Initializing PDF framework...")
pdf = PDFFramework(
n_classes=N_CLASSES,
n_puf_bits=N_PUF_BITS,
epsilon=EPSILON,
bit_compression=1,
puf_noise=0.05
)
# Step 2: Register authorized devices
print(f"[2] Registering {N_DEVICES} authorized devices...")
device_ids = list(range(N_DEVICES))
pdf.register_devices(device_ids)
print(f" Registered {len(device_ids)} devices")
# Step 3: Train neural decoder (Stage 1)
print("\n[3] Training Stage 1 neural decoder...")
history = pdf.train_neural_decoder(
n_devices=100,
samples_per_device=50,
epochs=50
)
print(f" Final validation loss: {history[-1]:.4f}")
# Step 4: Simulate deployment scenario
print("\n[4] Simulating edge deployment with PUF fingerprinting...")
# Simple CNN teacher and student
class SimpleCNN(nn.Module):
def __init__(self, n_classes=10):
super().__init__()
self.features = nn.Sequential(
nn.Conv2d(3, 32, 3, padding=1), nn.ReLU(), nn.MaxPool2d(2),
nn.Conv2d(32, 64, 3, padding=1), nn.ReLU(), nn.MaxPool2d(2),
nn.Conv2d(64, 64, 3, padding=1), nn.ReLU(),
)
self.classifier = nn.Sequential(
nn.Flatten(),
nn.Linear(64 * 8 * 8, 128), nn.ReLU(),
nn.Linear(128, n_classes)
)
def forward(self, x):
x = self.features(x)
return self.classifier(x)
teacher = SimpleCNN(N_CLASSES).to(device).eval()
# Simulate "leaked" student models from different devices
test_results = []
n_test = 20
print(f" Simulating {n_test} student trainings...")
for i in range(n_test):
# Random device (one will be the "leaker")
leaker_id = np.random.choice(device_ids)
# Create student
student = SimpleCNN(N_CLASSES).to(device)
# Simulate PUF-perturbed distillation (simplified)
trainer = PUFStudentTrainer(teacher, student, N_PUF_BITS, EPSILON)
# Quick training simulation
optimizer = optim.Adam(student.parameters(), lr=1e-3)
for _ in range(5): # Few steps for demo
dummy_input = torch.randn(4, 3, 32, 32).to(device)
trainer.train_step(dummy_input, leaker_id, optimizer)
# Get teacher and student outputs for recovery
with torch.no_grad():
test_input = torch.randn(1, 3, 32, 32).to(device)
z_t = teacher(test_input)
z_s = student(test_input)
# Attempt recovery
recovered_key, hamming_dist, conf = pdf.recover_signature(z_s, z_t)
# Check if correct device identified
# (In real scenario, we'd check against all registered keys)
is_correct = (hamming_dist == 0)
test_results.append({
'true_id': leaker_id,
'hamming_dist': hamming_dist,
'confidence': conf,
'correct': is_correct
})
# Step 5: Report results
print("\n[5] Recovery Results:")
correct = sum(1 for r in test_results if r['correct'])
avg_conf = np.mean([r['confidence'] for r in test_results])
avg_dist = np.mean([r['hamming_dist'] for r in test_results])
print(f" Correct device identification: {correct}/{n_test} ({100*correct/n_test:.1f}%)")
print(f" Average confidence: {avg_conf:.3f}")
print(f" Average Hamming distance: {avg_dist:.2f}")
# Step 6: Demonstrate bit compression
print("\n[6] Bit Compression Scalability:")
for m in [1, 2, 3]:
capacity = 2 ** (N_CLASSES * m)
print(f" {m} bit(s)/logit: {capacity:,} devices ({capacity/1e6:.1f}M)")
print("\n" + "=" * 70)
print("Demonstration complete!")
print("PDF enables hardware-rooted traceability of stolen AI models.")
print("=" * 70)
Access the Paper and Resources
The full PDF framework details and experimental protocols are available in the DAC 2026 proceedings. Implementation resources and extended evaluations will be made available by the authors.
Lyu, N., Liu, Y., Bai, Y., & Yan, Z. (2026). PDF: PUF-based DNN Fingerprinting for Knowledge Distillation Traceability. In Proceedings of the 63rd Design Automation Conference (DAC ’26), Long Beach, CA, USA. ACM.
This article is an independent editorial analysis of peer-reviewed research presented at DAC 2026. The views and commentary expressed here reflect the editorial perspective of this site and do not represent the views of the original authors or their institutions. Code implementations are provided for educational purposes to illustrate the technical concepts described in the paper. Always refer to the original publication for authoritative details and official implementations.
Explore More on AI Security Research
If this analysis sparked your interest, here is more of what we cover across the site — from foundational tutorials to the latest research breakthroughs in machine learning security, hardware protection, and trustworthy AI.