Unlocking Retinal Health: The Power of Complete Vessel Mapping
The intricate network of blood vessels in your retina acts as a window into your overall health, offering early clues to serious conditions like diabetic retinopathy, glaucoma, and age-related macular degeneration. Accurately analyzing this microscopic vascular structure is paramount for early detection and effective disease management. However, traditional imaging methods and analysis techniques often struggle with a significant hurdle: fragmentation . Fine capillaries and even larger vessels can appear broken or disconnected in images due to low contrast, noise, or resolution limits.
This is where cutting-edge artificial intelligence steps in. A new method, Masked Vascular Structure Segmentation and Completion (MaskVSC) , promises to revolutionize how we map the retinal vasculature. As detailed in a recent paper by Zhou et al. (2025), MaskVSC isn’t just another segmentation tool; it’s specifically designed to reconstruct and complete these fragmented vascular networks, leading to a more accurate and interconnected representation crucial for diagnosis.
This article delves into the groundbreaking MaskVSC technique, exploring how it tackles the challenges of retinal image analysis, why it outperforms existing methods, and the potential impact it holds for ophthalmology and beyond.
The Challenge: Fragmented Vessels in Retinal Imaging
Retinal images, whether from fundus cameras, Optical Coherence Tomography Angiography (OCTA), or advanced techniques like two-photon fluorescence microscopy (2PFM), project a continuous, interconnected vascular network onto a 2D plane. However, the reality captured is often far from perfect:
- Low Signal-to-Noise Ratio (SNR): Fine capillaries are particularly susceptible to noise, making them appear faint or invisible.
- Limited Contrast and Resolution: Subtle differences between vessels and surrounding tissue can be lost.
- Imaging Artifacts: Various factors can introduce breaks or discontinuities in the captured image.
These issues result in fragmented vessel segments . Traditional segmentation methods, even advanced deep learning models, often struggle to connect these pieces accurately. This fragmentation directly impacts the topological integrity of the vascular network – the way vessels connect and branch – which is vital for understanding blood flow and detecting pathological changes.
Furthermore, manually correcting these segmentations is cumbersome and time-consuming , limiting the availability of large, high-quality labeled datasets needed to train robust AI models. Existing methods often rely on post-processing steps or specific loss functions that might not fully address the core issue of missing connections.
Introducing MaskVSC: A Novel Approach to Completion
MaskVSC proposes a clever and effective solution to these problems. It doesn’t just try to identify vessels; it actively learns how to complete them. Here’s how it works:
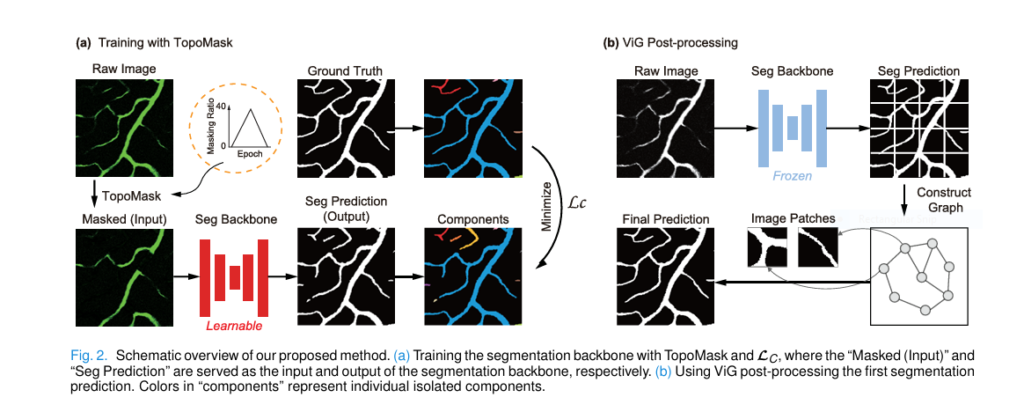
1. Topology-Aware Masking (TopoMask): Learning from Breaks
Inspired by the concept of Masked Autoencoders (MAE) used in natural image processing, MaskVSC introduces a unique Topology-Aware Mask Strategy (TopoMask) .
- Simulating Real-World Breaks: Instead of randomly masking image patches, TopoMask strategically masks portions of actual vessel segments in the training images. It does this by first identifying vessel skeletons (centerlines) from the ground truth annotations, randomly selecting parts of these skeletons, dilating them slightly, and then masking these regions.
- Realistic Noise: Crucially, the masked regions aren’t simply turned black. They are filled with zero-mean Gaussian noise, mimicking the appearance of missing or low-SNR vessel sections found in real images. The noise level is tailored to the specific imaging modality (e.g., fundus, OCTA, 2PFM).
- Dynamic Masking Ratio: The proportion of vessels masked during training isn’t fixed. It follows a dynamic schedule, starting at 0%, increasing to a peak (found to be optimal at 40%), and then decreasing back to 0% over the course of training epochs. This progressive difficulty helps the model learn robust features initially and then adapt to increasingly challenging, incomplete data.
This strategy forces the model to learn how to reconstruct missing vessel parts based on the context provided by the remaining visible structure. It effectively simulates the heterogeneous forms of vessel breaks encountered in real-world scenarios, mitigating the need for extensive manual labeling.
2. Connectivity Loss (LC): Guiding the Network to Stay Connected
Accurate segmentation isn’t enough; the resulting vessel map must reflect the true interconnected nature of the retinal vasculature. MaskVSC introduces a novel Connectivity Loss (LC ) to enforce this.
- Measuring Connected Components: LC directly penalizes predictions that have a different number of connected components compared to the ground truth. A connected component is a group of vessel pixels all linked to each other.
- Mathematical Formulation: The connectivity loss is defined as:
Where:
- Y is the model’s prediction.
- YG is the ground truth segmentation.
- #C(Y) and #C(YG) represent the number of connected components in the prediction and ground truth, respectively.
- #(YG) is the total number of pixels in the ground truth.
- Smooth Approximation: Calculating the exact number of connected components is non-differentiable. Therefore, LC uses a smoothness penalty S(⋅) as an approximation. This penalty measures the differences between adjacent pixels, capturing the notion of connectivity:
Where Y(i,j) is the pixel value at position (i,j) , and N is the total number of pixels.
- Balancing with BCE Loss: To prevent the model from simply minimizing components by over-segmenting (e.g., labeling everything as background) or under-segmenting (e.g., labeling everything as vessel), LC is combined with the standard Binary Cross-Entropy (BCE) loss (LBCE ). The total loss function (LT ) becomes:
The trade-off parameter λ is set to 1 based on experimental validation.
This connectivity loss guides the model towards predictions with fewer isolated fragments, encouraging the formation of a more complete and realistic vascular network.
3. ViG-Based Post-Processing: Refining the Topology
Even with TopoMask and LC , minor inaccuracies or false positives might persist. MaskVSC incorporates a post-processing step using a Vision GNN (ViG) to further refine the topological features of the segmented vessels.
- Graph Representation: ViG treats the initial segmented image as a graph. It divides the image into patches (nodes) and connects them based on spatial proximity (edges).
- Graph Convolution: By processing this graph structure using graph convolution operations, ViG can better capture long-range dependencies and global connectivity patterns inherent in vascular networks.
- Reducing False Positives: This graph-based approach helps correct minor errors introduced by TopoMask (like false positives) by leveraging the overall structural context, leading to a cleaner, more topologically accurate final output.
Why MaskVSC Outperforms the Competition
The effectiveness of MaskVSC isn’t just theoretical; it’s backed by rigorous testing across diverse datasets and imaging modalities.
- Superior Segmentation Accuracy: On standard metrics like Dice Coefficient and Jaccard Index, MaskVSC consistently achieves higher scores, indicating better overlap with the ground truth.
- Enhanced Topological Correctness: MaskVSC excels in metrics specifically designed to evaluate topological integrity:
- clDice: Measures the similarity of the predicted and ground truth skeletons, emphasizing connectivity. MaskVSC outperforms methods using clDice loss alone.
- Betti Number Error (βerr ): Measures differences in the number of connected components (0D) and loops/holes (1D). MaskVSC shows significantly lower βerr , indicating better preservation of the network’s fundamental topological features.
- Betti Matching Error (μerr ): Like βerr , but also considers the spatial location of components, making it a stricter measure. MaskVSC performs exceptionally well on μerr .
- CAL (Connectivity x Area x Length): A global quality metric combining fragmentation, overlap, and path similarity. MaskVSC achieves higher CAL scores.
- Robustness Across Modalities: Tested on fundus images (DRIVE, STARE, RITE, LES-AV), OCTA images (ROSE, OCTA-500), and 2PFM images, MaskVSC delivers consistent performance improvements.
- Backbone Agnostic: MaskVSC isn’t tied to a specific neural network architecture. It successfully enhances the performance of various backbones, including U-Net, CS2-Net, and Swin-Unet, demonstrating its versatility and broad applicability.
Ablation studies confirm the importance of each component: removing TopoMask, LC , or the ViG post-processing leads to measurable drops in performance, validating their synergistic contribution.
Real-World Impact: Beyond Segmentation
The benefits of MaskVSC extend beyond academic benchmarks. Its ability to generate more complete vascular maps has tangible clinical relevance:
- Improved Disease Diagnosis: Features like vascular tortuosity (twisting) are sensitive indicators of disease. In a diabetic retinopathy (DR) classification task using OCTA images, MaskVSC-segmented vessels led to a significantly better Area Under the Curve (AUC) of 0.81 compared to 0.71 without MaskVSC (p=0.0287). This demonstrates its potential to enhance diagnostic accuracy.
- Quantitative Analysis: More accurate and complete maps enable more reliable quantification of vessel parameters (diameter, density, branching angles), crucial for monitoring disease progression and treatment efficacy.
- Reduced Manual Effort: By inherently learning to complete vessels, MaskVSC reduces the dependency on large amounts of manually annotated training data, speeding up development and deployment.
If you’re Interested in 3D Medical Image Segmentation using deep learning, you may also find this article helpful: UNETR++ vs. Traditional Methods: A 3D Medical Image Segmentation Breakthrough with 71% Efficiency Boost
Conclusion: A New Era for Retinal Vessel Analysis
MaskVSC represents a significant leap forward in the field of retinal image analysis. By intelligently simulating vessel breaks (TopoMask), explicitly guiding the model towards topological integrity, and refining results with graph-based processing (ViG), it tackles the core challenge of fragmentation head-on.
Its proven superiority across multiple datasets, imaging modalities, and network backbones underscores its robustness and generalizability. The enhanced topological accuracy and demonstrated clinical relevance, particularly in improving diagnostic metrics like AUC for DR, highlight its potential to become a cornerstone technology in ophthalmic AI.
As research continues, future directions might include adapting MaskVSC for 3D vascular structures or integrating it into real-time diagnostic workflows. For now, MaskVSC stands as a powerful tool, promising more accurate, complete, and insightful analysis of the vital retinal vasculature.
Ready to explore the future of retinal diagnostics? Dive deeper into the original research paper by Zhou et al. (2025) to understand the intricate details of MaskVSC’s architecture and experiments. Share your thoughts on how AI like MaskVSC can transform eye care in the comments below!
Below is a minimal but complete PyTorch implementation of the MaskVSC pipeline described in the paper “Masked Vascular Structure Segmentation and Completion in Retinal Images”.
import torch, torch.nn as nn, torch.nn.functional as F
import numpy as np, cv2, math
from torch.cuda.amp import autocast
from kornia.morphology import thinning
from typing import Tupleclass TopoMask:
"""
Given a binary GT vessel mask, generate a topology-aware masked version.
ratio: % of skeleton pixels to mask (0–1).
noise_sd: Gaussian noise level to fill the masked regions.
"""
def __init__(self, ratio: float = .4, noise_sd: float = 20.):
self.ratio, self.noise_sd = ratio, noise_sd
def __call__(self, gt: torch.Tensor) -> torch.Tensor:
"""
gt: [1, H, W] binary mask on cpu/numpy.
returns: [1, H, W] masked image (float32).
"""
gt_np = gt.squeeze().cpu().numpy().astype(np.uint8)
# 1-pixel skeleton
ske = thinning(torch.from_numpy(gt_np).unsqueeze(0).unsqueeze(0)).squeeze().numpy()
ys, xs = np.where(ske > 0)
if len(ys) == 0:
return gt.float()
# choose random subset
n_mask = int(self.ratio * len(ys))
idx = np.random.choice(len(ys), size=n_mask, replace=False)
mask = np.zeros_like(gt_np)
for y, x in zip(ys[idx], xs[idx]):
cv2.circle(mask, (int(x), int(y)), 3, 1, -1) # dilate skeleton
# build masked image
masked = gt_np.astype(np.float32).copy()
masked[mask > 0] = 0
noise = np.random.normal(0, self.noise_sd, gt_np.shape).astype(np.float32)
masked[mask > 0] = noise[mask > 0]
return torch.from_numpy(masked).unsqueeze(0)class ConnectivityLoss(nn.Module):
"""
Penalises the difference in the number of connected components
between prediction and ground-truth.
"""
def __init__(self):
super().__init__()
def forward(self, pred: torch.Tensor, gt: torch.Tensor) -> torch.Tensor:
"""
pred, gt: [B, 1, H, W] after sigmoid.
returns scalar tensor.
"""
B = pred.size(0)
loss = 0.
for b in range(B):
p, g = pred[b, 0], gt[b, 0]
n_pred = self._cc_count((p > .5).byte())
n_gt = self._cc_count((g > .5).byte())
loss += abs(n_pred - n_gt) / max(n_gt, 1)
return loss / B
@staticmethod
@torch.no_grad()
def _cc_count(mask: torch.Tensor) -> int:
# OpenCV connected components (CPU)
mask_np = mask.cpu().numpy()
_, lbl = cv2.connectedComponents(mask_np)
return lbl.max()class Grapher(nn.Module):
"""
One ViG Grapher block (K=9 neighbours by default).
"""
def __init__(self, dim, k=9):
super().__init__()
self.k = k
self.fc1 = nn.Linear(dim, dim)
self.conv = nn.Conv1d(dim, dim, 1, groups=1)
self.fc2 = nn.Linear(dim, dim)
self.norm = nn.LayerNorm(dim)
def forward(self, x):
# x: [B, N, C]
B, N, C = x.shape
# KNN graph on-the-fly
with torch.no_grad():
dist = torch.cdist(x, x) # [B, N, N]
_, idx = dist.topk(self.k+1, dim=-1, largest=False) # [B, N, K+1]
idx = idx[:, :, 1:] # remove self
# gather neighbours
x_neigh = x.unsqueeze(2).expand(-1, -1, self.k, -1) # [B, N, K, C]
idx = idx.unsqueeze(-1).expand(-1, -1, -1, C)
x_neigh = torch.gather(x_neigh, 1, idx) # [B, N, K, C]
x_neigh = x_neigh.permute(0, 3, 1, 2).contiguous() # [B, C, N, K]
x_neigh = self.conv(x_neigh.view(B, C, -1)).view(B, C, N, self.k)
x_neigh = x_neigh.max(dim=-1)[0].permute(0, 2, 1) # [B, N, C]
x = x + F.relu(self.fc2(F.relu(self.fc1(x_neigh))))
return self.norm(x)
class ViG_Post(nn.Module):
"""
Tiny ViG (ViG-Ti) for 512×512 images.
Patch size 16×16 → 32×32 patches.
"""
def __init__(self, in_ch=1, dim=96, depth=4):
super().__init__()
self.patch_embed = nn.Conv2d(in_ch, dim, 16, 16)
blocks = []
for _ in range(depth):
blocks += [Grapher(dim), nn.Sequential(
nn.LayerNorm(dim), nn.Linear(dim, dim*4),
nn.GELU(), nn.Linear(dim*4, dim))]
self.blocks = nn.Sequential(*blocks)
self.head = nn.Sequential(
nn.LayerNorm(dim),
nn.Linear(dim, 16*16),
nn.Unfold(16, 16, 16) # unfold back to image
)
def forward(self, x):
# x: [B, 1, H, W]
B, _, H, W = x.shape
x = self.patch_embed(x) # [B, C, H/16, W/16]
x = x.flatten(2).transpose(1, 2) # [B, N, C]
x = self.blocks(x)
x = self.head(x.transpose(1, 2).view(B, -1, H//16, W//16))
x = x.view(B, 1, H, W)
return torch.sigmoid(x)class MaskVSC(nn.Module):
"""
End-to-end wrapper:
step1: segmentation backbone (e.g. U-Net) trained with TopoMask + LC
step2: frozen backbone → ViG post-processor trained
"""
def __init__(self, seg_backbone: nn.Module, vig: ViG_Post):
super().__init__()
self.seg = seg_backbone
self.vig = vig
def forward(self, x, step: int = 2):
# step=1 during first training stage, step=2 for inference
with torch.no_grad() if step == 2 else torch.enable_grad():
pred = self.seg(x)
if step == 2:
pred = self.vig(pred)
return predif __name__ == "__main__":
# Dummy data
img = torch.randn(2, 1, 512, 512).cuda()
gt = torch.randint(0, 2, (2, 1, 512, 512)).float().cuda()
# Backbone (U-Net mini)
unet = torch.hub.load('mateuszbuda/brain-segmentation-pytorch', 'unet',
in_channels=1, out_channels=1, init_features=32, pretrained=False).cuda()
topo = TopoMask(ratio=.4, noise_sd=20.)
criterion = nn.BCELoss()
conn = ConnectivityLoss()
# Stage-1 optimisation
opt = torch.optim.Adam(unet.parameters(), 2e-4)
for epoch in range(5):
opt.zero_grad()
masked = torch.stack([topo(g) for g in gt]).cuda()
out = unet(masked)
loss = criterion(out, gt) + conn(out, gt)
loss.backward()
opt.step()
print(f"epoch {epoch} loss {loss.item():.4f}")
# Freeze backbone & train ViG
vig = ViG_Post().cuda()
opt_vig = torch.optim.Adam(vig.parameters(), 2e-4)
model = MaskVSC(unet, vig).cuda()
for epoch in range(5):
opt_vig.zero_grad()
with autocast():
out = model(img, step=2)
loss = criterion(out, gt)
loss.backward()
opt_vig.step()
print(f"VIG epoch {epoch} loss {loss.item():.4f}")Repository structure suggestion
MaskVSC/
├─ maskvsc.py # file above
├─ datasets/ # your readers
├─ train_stage1.py # TopoMask + LC
├─ train_vig.py # frozen backbone → ViG
└─ README.md