RideJudge: Teaching an 8B Model to Out-Think 32B Rivals on the Hardest Calls in Ride-Hailing
Researchers from Nanjing University and Didi Chuxing built a multimodal LLM framework that reads GPS maps like a detective, consults platform regulations like a lawyer, and delivers transparent verdicts on driver-passenger disputes — hitting 88.41% accuracy while a 32B-scale baseline manages just 65.55%.
Every time a ride gets cancelled mid-trip, someone is at fault — and someone else is upset about it. The driver says the passenger was unreachable. The passenger says the driver never showed up. Both have app timestamps. Both have GPS records. Both have a complaint filed. On a platform that handles millions of trips a day, a human reviewer reading each case carefully is simply not possible. What you need is an AI that can look at the map, read the rules, weigh the evidence, and write down exactly why it reached a verdict — not just what the verdict was. That is what RideJudge does, and it does it better than models four times its size.
Why Generic MLLMs Cannot Simply Be Asked to Judge
The instinct when you see a new reasoning task is to reach for a capable general-purpose model and try prompting it. The RideJudge paper documents precisely why this does not work for ride-hailing adjudication — and the failures are specific enough to be instructive for anyone building specialized AI systems.
The first failure is perceptual. Vision encoders in general models are pre-trained on natural image-caption pairs — photographs, documents, diagrams. A rendered GPS trajectory map is none of these things. It is a schematic with two overlapping coloured lines on a road network, where the meaningful information is the difference between the lines and where that difference begins. A model that has learned to describe what is in a photograph cannot reliably distinguish a two-hundred-metre intentional detour from normal GPS drift. The perceptual categories that matter — route deviation, abnormal stop, reverse driving — simply do not exist in its pre-trained vocabulary.
The second failure is logical. Adjudication is not a generative task where fluency matters. It is a deductive task where the conclusion must follow from premises by explicit rules. LLM generation is probabilistic — next-token prediction softly weighted across possibilities. Legal deduction is deterministic — rule R applies to fact F, therefore conclusion C. When a model hallucinates a “plausible” verdict that is not actually entailed by the rules, that is not a minor quality issue; in a quasi-judicial context, it is a systemic fairness failure.
The third failure is scale. A real platform has hundreds of liability rules covering dozens of scenario types, each with sub-clauses and exceptions. Platform regulations evolve. Historical precedents matter. Cramming all of this into a prompt exceeds context windows, introduces irrelevant noise, and makes the reasoning process unfocused. General models have no way to decide which subset of a massive rule corpus is relevant to any specific dispute.
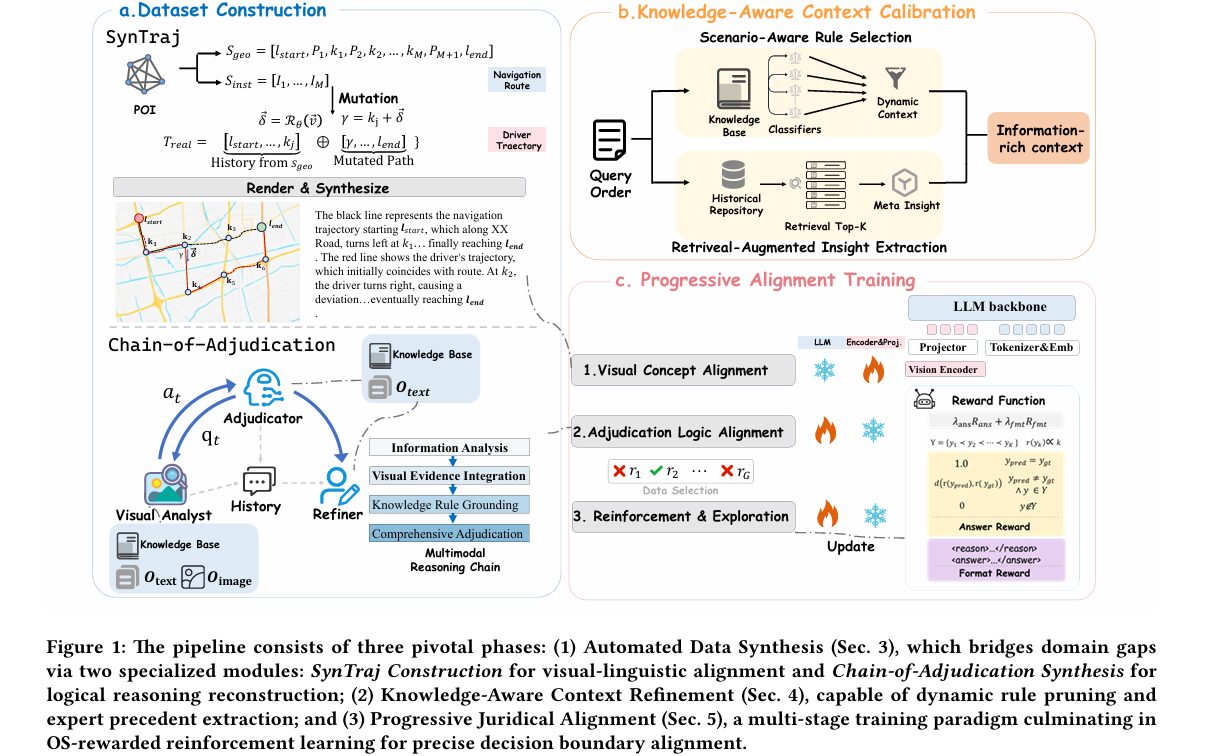
RideJudge identifies and addresses three structural disconnects: (1) General visual perception vs. domain-specific trajectory grounding — solved by SynTraj synthetic data; (2) Probabilistic generation vs. deterministic logical deduction — solved by Chain-of-Adjudication structured reasoning; (3) Fixed context window vs. open-world rule scaling — solved by Adaptive Context Optimization with scenario-aware rule pruning and RAG-based precedent retrieval.
SynTraj: Building a Training Set from Programmatic Physics
The most fundamental problem with training a domain-specific model is that you need domain-specific training data. Real dispute records from a ride-hailing platform are private, legally sensitive, and annotation-expensive. RideJudge’s first contribution is an engine that sidesteps this entirely by generating synthetic trajectory data programmatically.
SynTraj starts by sampling pairs of real Points of Interest from major Chinese cities and querying a navigation API to get the actual road-network route between them. This gives a geometric sequence of GPS coordinates and a paired instruction sequence describing each turn and road segment. From this ground-truth compliant route, the engine then applies mutation strategies to inject specific liability semantics.
The mutations are physically grounded. For an “Unintentional Deviation,” the engine picks an intersection node k_j from the planned route, computes the intended direction vector, rotates it by a randomised angle to get a deviation vector δ, calculates the mutated anchor point γ = k_j + δ, then queries the API for a new path from γ to the destination and stitches it with the historical compliant segment. The result is a trajectory that looks like a real driver who turned the wrong way at an intersection and rerouted. For “Reverse Driving,” the rotation angle is pushed into [150°, 210°] to create motion flowing against the lane direction. For “Arrival-then-Leave,” a departure vector is appended after the driver reaches the destination, simulating someone who reported arrival and immediately left.
Each synthesised trajectory is rendered as an image showing both the planned navigation route and the driver’s actual path superimposed on a road map — the same visual format used in real disputes. A natural language caption is generated from the instruction sequence metadata, describing the trajectory behaviour in adjudication terminology. This process yields 12,585 high-quality image-caption pairs where the visual anomaly and the textual description are perfectly aligned by construction, with no annotation noise.
SynTraj PIPELINE
══════════════════════════════════════════════════════
POI Sampling → Navigation API → S_geo (geometric sequence)
+ S_inst (instruction sequence)
│
┌──────────────────────┼───────────────────────┐
│ │ │
┌───────▼──────┐ ┌──────────▼─────┐ ┌────────────▼──────┐
│ GPS Drift │ │ Unintentional │ │ Reverse Driving │
│ noise ε~N(0,σ)│ │ Deviation │ │ φ ∈ [150°, 210°] │
│ σ≈10-15m │ │ θ ∈ {90°, 270°} │ │ truncated to δ_max│
└───────┬──────┘ └──────────┬─────┘ └────────────┬──────┘
│ │ │
│ ┌────────────▼──────────┐ │
│ │ Arrival-then-Leave │ │
│ │ escape to w_esc > τ │ │
│ └────────────┬──────────┘ │
└──────────────────────┼────────────────────── ┘
│
┌────────────▼──────────────┐
│ Render: T_real + S_geo │
│ onto road map → O_image │
│ Generate caption from │
│ S_inst → textual label │
└────────────┬──────────────┘
│
12,585 image-caption pairs
(perfect visual-textual alignment)
Chain-of-Adjudication: Making the Model Think Like a Judge
Having visual grounding data is necessary but not sufficient. The model also needs to learn how to reason about disputes in a structured, evidentiary way rather than producing fluent-but-vague verdict text. The Chain-of-Adjudication (CoA) framework addresses this by generating structured reasoning chains that mirror how human adjudicators actually work.
The CoA framework uses three specialised agents during training data construction. The Adjudicator is an LLM (QwQ-32B) that processes the textual order context and retrieves applicable rules from the knowledge base. Crucially, the Adjudicator is deliberately isolated from the visual map — it cannot directly see the trajectory image. Instead, when it needs visual evidence to apply a rule (say, confirming that the driver actually deviated at a specific intersection), it must formulate a precise question and send it to the Visual Analyst. This constraint forces the model to do what a real judge does: identify what factual questions the rules require answers to, then seek specific evidence for each.
The Visual Analyst (Qwen3-VL-32B-Instruct) receives these targeted queries and examines the trajectory map to provide objective, fact-based answers. The interaction continues for up to eight turns — the Adjudicator queries, the Analyst responds, and the reasoning gradually builds an evidentiary chain from visual facts to legal conclusions.
A Reasoning Refiner (again QwQ-32B) then distills this dialogue into a clean four-stage format that becomes the training target: (1) Information Analysis — what do we know about this order? (2) Visual Evidence Integration — what does the map actually show? (3) Rule Grounding — which rules apply given these facts? (4) Comprehensive Adjudication — what is the verdict and why? After filtering out cases where the synthesised verdict disagrees with human annotation, 14,582 high-confidence reasoning trajectories remain for training.
“The CoA framework improves the Recall on Malicious tasks by over 20%, indicating that decomposed reasoning steps help the model uncover subtle fraud patterns that end-to-end learning overlooks.” — Wu, Cheng, Meng et al., arXiv:2603.17328 (2026)
Adaptive Context Optimization: Handling an Entire Legal Corpus
Even with good training data and a structured reasoning format, there is the practical problem of the rule base. A real platform has hundreds of liability rules covering every imaginable dispute scenario. Feeding all of them into the model’s context window at once is wasteful at best and actively harmful at worst — the model gets confused by regulations that do not apply to the current case.
RideJudge addresses this with a two-part context refinement strategy. The first part is scenario-aware rule calibration: an ensemble of binary classifiers (one per rule) trained on order metadata decides which rules are applicable to each specific case. Each classifier takes order features — time of day, location coordinates, cancellation reason codes, semantic embeddings of driver and passenger complaints — and outputs a binary relevance score. Only rules predicted as applicable are passed to the reasoning model. The ensemble uses XGBoost, LightGBM, and CatBoost with model selection optimised for recall (missing a relevant rule is more costly than including a marginally irrelevant one).
The second part is retrieval-augmented precedent extraction. A vector store of historical resolved disputes is maintained with strict temporal partitioning — only cases resolved before the current query’s timestamp are accessible, preventing data leakage. The top-K most semantically similar historical cases are retrieved and passed to a Summary Agent (QwQ-32B), which synthesises a Meta-Insight from the retrieved cases — a concise description of how similar disputes have been resolved previously. This synthesised insight, rather than raw case text, is what enters the reasoning model’s context. The ablation results are stark: removing KACR causes a 21.30% accuracy drop on the Appeal benchmark, the largest single component contribution in the study.
Three-Stage Progressive Training
The training paradigm is staged deliberately, with each stage building on the previous one in a way that reflects how the model needs to progressively master different competencies.
Stage 1 trains the vision encoder and projector on SynTraj data while keeping the language model frozen. The goal is purely perceptual grounding — teaching the visual components to translate trajectory map patterns into concepts like “deviation at intersection,” “abnormal stop,” or “reverse motion,” without disturbing the language model’s pre-trained reasoning capabilities. This stage delivers only a +1.42% accuracy gain on its own, which is expected: visual grounding without reasoning capability cannot produce verdicts.
Stage 2 fine-tunes the language model backbone on the CoA reasoning chains while freezing the vision components. This is where the dramatic improvement happens — accuracy jumps to 68.81%, a gain of +22.90% from Stage 1. The model learns the four-stage adjudication format, how to formulate evidence-anchored reasoning, and how to map factual findings to specific liability clauses.
Stage 3 applies reinforcement learning using DAPO (Divergence-Aware Policy Optimization) to push the model through its remaining ambiguous cases. Before RL training, the Stage 2 model is used to generate 10 rollouts per training sample. Only instances where the model is correct 2–8 times out of 10 are retained — approximately 2,000 samples where the model is genuinely uncertain. This focuses the RL signal exactly where it will do the most good.
The Ordinal-Sensitive Reward: Why Binary Feedback Breaks Here
Standard RLHF and GRPO use binary rewards — the answer is right (1) or wrong (0). For adjudication with a hierarchical liability space (No Fault < Normal Fault < Malicious Fault), binary rewards are problematic: they treat "No Fault when the answer is Normal Fault" as equally wrong as "No Fault when the answer is Malicious Fault," even though the second error is far more consequential and systematically different in kind.
The Ordinal-Sensitive Reward fixes this by assigning graded signals based on how far the prediction is from the ground truth in the ordinal hierarchy:
Here d(·) is a semantic distance function over the ordinal rank mapping — a prediction adjacent to the correct label gets partial credit, while a prediction at the opposite end of the hierarchy gets a larger penalty. The ablation confirms the importance of this design: removing the ordinal sensitivity and falling back to standard binary rewards causes a 21.35% accuracy drop, tied with KACR removal as the most impactful ablation in the study.
Results: The 8B Model That Humbles 32B Baselines
RideJudge is evaluated on three real-world benchmarks drawn from Didi Chuxing’s dispute records: an Appeal set (1,007 cases where drivers formally appealed the platform’s initial verdict), a Driver-Cancel set (453 hard cases of driver-initiated cancellations), and a Passenger-Cancel set (1,249 hard cases of passenger-initiated cancellations).
| Model | Scale | Visual? | Appeal Acc. | Driver-C Acc. | Pass-C Acc. | Overall Acc. |
|---|---|---|---|---|---|---|
| DeepSeek-V3.1 | Large | No | 57.89% | 84.21% | 88.57% | 75.25% |
| Qwen3-VL-32B-Instruct | 32B | Yes | 43.20% | 57.90% | 84.60% | 65.55% |
| Qwen3-VL-32B-Thinking | 32B | Yes | 49.75% | 27.59% | 51.69% | 45.94% |
| Qwen3-VL-8B-Instruct | 8B | Yes | 39.82% | 71.00% | 92.90% | 60.61% |
| RideJudge-4B | 4B | Yes | 90.86% | 80.95% | 84.50% | 87.25% |
| RideJudge-8B | 8B | Yes | 91.86% | 83.55% | 89.76% | 88.41% |
Table 1 (abridged): RideJudge-8B vs selected baselines. The overall accuracy gap vs Qwen3-VL-32B-Instruct (+22.86%) is striking given the 4× size advantage of the baseline. Qwen3-VL-32B-Thinking actually scores lower on some benchmarks than its non-thinking counterpart, suggesting that generic extended reasoning can hurt on rule-bound structured tasks.
Several patterns in the results deserve attention beyond the headline numbers. Text-only models generally outperform general-purpose MLLMs — DeepSeek-V3.1 beats Qwen3-VL-32B-Instruct by 9.7 points despite having no access to the visual map. This confirms the paper’s premise: without domain-specific visual grounding, adding a vision encoder to the model can actually hurt, because the model hallucinates visual details rather than correctly interpreting the trajectory. RideJudge closes this gap by giving the visual encoder actual adjudication knowledge to work with.
The Malicious category results are particularly revealing. Multiple general MLLM baselines score zero precision and zero recall on malicious cases — they simply never predict “Malicious Fault” because they lack the specific pattern recognition to identify intentional fraud from trajectory data. RideJudge-8B achieves 91.52% precision and 91.93% recall on malicious cases in the Appeal benchmark — a genuinely difficult task that requires reading the visual trajectory, consulting the relevant platform rules, and making a high-stakes fraud determination. The +20% Malicious Recall improvement from CoA training specifically shows that structured evidence-gathering is what enables the model to catch subtle fraud patterns.
| Component | Removed | Accuracy Drop | Malicious Recall Drop |
|---|---|---|---|
| Chain-of-Adjudication | SFT w/o CoA | −5.06% | −20.63% |
| Knowledge-Aware Context Refinement (KACR) | w/o KACR | −21.30% | −23.77% |
| Ordinal-Sensitive Reward | DAPO w/o OS Reward | −21.35% | −35.43% |
| Reinforcement Learning (Stage 3) | Only Stage 1+2 | −23.05% | −34.53% |
Table 2: Ablation impact. KACR and Ordinal-Sensitive Reward are tied for largest contribution. Removing RL entirely yields the biggest degradation — Stage 2 SFT alone tops out at 68.81%.
An 88.41% accuracy on genuinely hard, real-world dispute cases — where drivers have formally appealed and the initial verdict was already contested — is meaningfully different from accuracy on held-out samples from the same distribution. These are the cases humans would spend the most time on. Getting them right at this rate, with transparent reasoning chains, is the bar that makes AI adjudication practically deployable.
Complete End-to-End RideJudge Implementation (PyTorch)
The implementation below covers all major components of the RideJudge framework: the SynTraj trajectory mutation engine (GPS drift, unintentional deviation, reverse driving, arrival-then-leave), the Chain-of-Adjudication multi-agent reasoning pipeline, the scenario-aware rule calibration classifier ensemble, the RAG-based precedent retrieval and meta-insight synthesis, the ordinal-sensitive reward function, the three-stage progressive training loop, and a complete smoke test. A mock MLLM interface is provided so all components can be validated without real model checkpoints.
# ==============================================================================
# RideJudge: A Progressive Visual-Logic-Aligned Framework
# for Ride-Hailing Adjudication
# Paper: arXiv:2603.17328 (2026)
# Authors: Weiming Wu, Zi-Jian Cheng, Jie Meng, Peng Zhen, Shan Huang,
# Qun Li, Guobin Wu, Lan-Zhe Guo
# Affiliations: Nanjing University & Didi Chuxing Co. Ltd
# ==============================================================================
# Sections:
# 1. Imports & Configuration
# 2. SynTraj: Trajectory Synthesis Engine
# 3. Trajectory Rendering (visual representation)
# 4. Chain-of-Adjudication (CoA) Reasoning Pipeline
# 5. Scenario-Aware Rule Calibration
# 6. Retrieval-Augmented Insight Extraction
# 7. Ordinal-Sensitive Reward
# 8. Progressive Training Framework
# 9. Evaluation & Inference
# 10. Dataset Helpers
# 11. Smoke Test
# ==============================================================================
from __future__ import annotations
import math
import random
import warnings
from dataclasses import dataclass, field
from typing import List, Dict, Optional, Tuple
import numpy as np
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch import Tensor
warnings.filterwarnings("ignore")
# ─── SECTION 1: Configuration ─────────────────────────────────────────────────
class RideJudgeConfig:
"""
Configuration for the RideJudge framework.
Attributes
----------
label_space : ordered liability labels (ordinal hierarchy)
n_rules : number of platform regulations in the knowledge base
top_k_retrieval : number of historical cases to retrieve per query
max_coa_turns : maximum interaction turns in CoA between Adjudicator/Analyst
embed_dim : embedding dimension for semantic retrieval
lambda_ans : weight for answer reward in total reward
lambda_fmt : weight for format reward in total reward
rl_min_consistency: min rollout consistency for RL data selection
rl_max_consistency: max rollout consistency for RL data selection
rl_n_rollouts : number of stochastic rollouts for difficulty assessment
"""
label_space: List[str] = None
n_rules: int = 100
top_k_retrieval: int = 4
max_coa_turns: int = 8
embed_dim: int = 256
lambda_ans: float = 0.8
lambda_fmt: float = 0.2
rl_min_consistency: float = 0.2
rl_max_consistency: float = 0.8
rl_n_rollouts: int = 10
def __init__(self, **kwargs):
self.label_space = ["No Fault", "Normal Fault", "Malicious Fault"]
for k, v in kwargs.items():
setattr(self, k, v)
def rank(self, label: str) -> int:
"""Return ordinal rank of a label (0 = least severe)."""
return self.label_space.index(label)
# ─── SECTION 2: SynTraj — Trajectory Synthesis Engine ────────────────────────
@dataclass
class GPSPoint:
"""Geographic coordinate point."""
lat: float
lon: float
def to_array(self) -> np.ndarray:
return np.array([self.lat, self.lon])
@classmethod
def from_array(cls, arr: np.ndarray) -> "GPSPoint":
return cls(lat=arr[0], lon=arr[1])
@dataclass
class NavigationRoute:
"""
A planned navigation route between two POIs.
S_geo: geometric sequence of GPS waypoints
S_inst: instruction sequence (turn-by-turn directions)
"""
start: GPSPoint
end: GPSPoint
waypoints: List[GPSPoint] # dense GPS sequence
intersections: List[GPSPoint] # critical intersection nodes k_m
instructions: List[str] # navigation instructions per segment
@dataclass
class SyntheticTrajectory:
"""A synthesised driver trajectory with its liability label."""
points: List[GPSPoint] # T_real: executed GPS track
nav_route: NavigationRoute # S_geo: planned route
violation_type: str # e.g. 'compliant', 'deviation', 'reverse'
liability_label: str # 'No Fault', 'Normal Fault', 'Malicious Fault'
description: str # natural language description of behaviour
class SynTraj:
"""
SynTraj: Automated Synthetic Trajectory Generation Engine (Section 3.1).
Simulates driver behaviours ranging from full compliance to specific
liability violations by applying programmatic mutations to a planned
navigation route. Supports four mutation types from Appendix B.1:
- GPS Drift : Gaussian noise on coordinates (compliant, sensor error)
- Unintentional Deviation: route deviation at intersection, recovers to dest
- Reverse Driving: anti-direction motion at a node
- Arrival-then-Leave: arrives at destination then departs
All trajectories are geometrically consistent and grounded in actual
road network structure (simulated here; use a real navigation API in production).
"""
def __init__(self, gps_sigma_m: float = 12.0, seed: int = 42):
self.gps_sigma = gps_sigma_m / 111_000 # degrees, ~111km per degree lat
random.seed(seed)
np.random.seed(seed)
def _rotation_matrix(self, theta_deg: float) -> np.ndarray:
"""2D rotation matrix R_θ."""
t = math.radians(theta_deg)
return np.array([[math.cos(t), -math.sin(t)],
[math.sin(t), math.cos(t)]])
def _simulate_route(self, start: GPSPoint, end: GPSPoint,
n_waypoints: int = 20) -> NavigationRoute:
"""
Generate a plausible navigation route (mock for the navigation API call).
In production, replace with: requests.get(AMAP_API, params=...)
"""
lats = np.linspace(start.lat, end.lat, n_waypoints)
lons = np.linspace(start.lon, end.lon, n_waypoints)
waypoints = [GPSPoint(lat=lats[i], lon=lons[i]) for i in range(n_waypoints)]
# Simulate intersection nodes at 1/4, 1/2, 3/4 along route
idx = [n_waypoints // 4, n_waypoints // 2, (3 * n_waypoints) // 4]
intersections = [waypoints[i] for i in idx]
instructions = ["Go straight", "Turn left", "Turn right", "Continue"]
return NavigationRoute(
start=start, end=end, waypoints=waypoints,
intersections=intersections, instructions=instructions
)
def _apply_gps_drift(self, points: List[GPSPoint]) -> List[GPSPoint]:
"""
GPS Drift Mutation (Appendix B.1.1, Eq. 12).
Applies Gaussian noise ε ~ N(0, σ²I) to each coordinate.
σ ≈ 10–15m (urban canyon GPS uncertainty).
"""
result = []
for p in points:
noise = np.random.normal(0, self.gps_sigma, 2)
result.append(GPSPoint(lat=p.lat + noise[0], lon=p.lon + noise[1]))
return result
def _apply_deviation(self, route: NavigationRoute,
theta_deg: float = 90.0,
lam: float = 0.002) -> List[GPSPoint]:
"""
Unintentional Deviation Mutation (Appendix B.1.2, Eqs. 13-14).
Selects split node p_t, rotates intended heading vector by θ ∈ {90°, 270°}
to generate off-route waypoint w_dev, then stitches:
T_yaw = S_geo[1:t] ⊕ Ψ(p_t, w_dev) ⊕ Ψ(w_dev, l_e)
"""
waypoints = route.waypoints
if len(waypoints) < 4:
return waypoints
# Select split node (not first or last)
t = random.randint(2, len(waypoints) - 3)
p_t = waypoints[t].to_array()
p_next = waypoints[t + 1].to_array()
# Compute intended heading and rotate (Eq. 13)
v_intended = p_next - p_t
R = self._rotation_matrix(theta_deg)
v_rotated = R @ v_intended
w_dev = GPSPoint.from_array(p_t + lam * v_rotated / (np.linalg.norm(v_rotated) + 1e-8))
# Stitch: history ⊕ deviation ⊕ recovery (Eq. 14)
history = waypoints[:t + 1]
deviation = [w_dev] # simplified; real impl uses navigation API
recovery = self._simulate_route(w_dev, route.end, n_waypoints=5).waypoints
return history + deviation + recovery
def _apply_reverse(self, route: NavigationRoute,
delta_max: int = 3,
phi_deg: float = 180.0) -> List[GPSPoint]:
"""
Reverse Driving Mutation (Appendix B.1.3, Eqs. 15-16).
Rotates heading by φ ∈ [150°, 210°] at node p_t to create retrograde
motion, then truncates to distance δ_max to simulate violation onset.
T_rev = S_geo[1:t] ⊕ Trunc(Ψ(p_t, w_rev), δ)
"""
waypoints = route.waypoints
t = random.randint(2, len(waypoints) - 2)
p_t = waypoints[t].to_array()
p_next = waypoints[t + 1].to_array()
v_intended = p_next - p_t
phi = random.uniform(150.0, 210.0) # obtuse rotation → against traffic
R = self._rotation_matrix(phi)
v_rev = R @ v_intended
lam = 0.001
w_rev = GPSPoint.from_array(p_t + lam * v_rev / (np.linalg.norm(v_rev) + 1e-8))
# Truncate reverse segment to delta_max steps
history = waypoints[:t + 1]
reverse_seg = [w_rev] * min(delta_max, 3)
return history + reverse_seg
def _apply_arrival_leave(self, route: NavigationRoute,
escape_dist: float = 0.003) -> List[GPSPoint]:
"""
Arrival-then-Leave Mutation (Appendix B.1.4, Eq. 17).
After full completion of S_geo, driver departs destination:
T_leave = S_geo ⊕ Ψ(l_e, w_esc)
where d(l_e, w_esc) > τ_thresh (unauthorised departure).
"""
waypoints = route.waypoints[:] # complete arrival
end = route.end.to_array()
# Generate escape target at random bearing, distance > threshold
bearing = random.uniform(0, 360)
R = self._rotation_matrix(bearing)
escape_dir = R @ np.array([1.0, 0.0])
w_esc = GPSPoint.from_array(end + escape_dist * escape_dir)
departure = self._simulate_route(route.end, w_esc, n_waypoints=5).waypoints
return waypoints + departure
def generate(self, start: GPSPoint, end: GPSPoint,
violation: str = "compliant") -> SyntheticTrajectory:
"""
Generate a synthetic trajectory with specified violation type.
Parameters
----------
start, end : POI pair (GPS coordinates)
violation : one of 'compliant' | 'drift' | 'deviation' |
'reverse' | 'arrival_leave'
Returns
-------
SyntheticTrajectory with points, nav_route, label, and description
"""
route = self._simulate_route(start, end)
violation_configs = {
"compliant": ("No Fault", "Driver followed navigation route faithfully."),
"drift": ("No Fault", "GPS noise observed; route compliance maintained."),
"deviation": ("Normal Fault", "Driver deviated from planned route at intersection."),
"reverse": ("Malicious Fault", "Driver exhibited reverse/retrograde motion."),
"arrival_leave": ("Malicious Fault", "Driver arrived then unauthorisedly departed pickup area."),
}
label, description = violation_configs.get(violation, ("No Fault", "Unknown"))
if violation == "compliant":
points = self._apply_gps_drift(route.waypoints)
elif violation == "drift":
points = self._apply_gps_drift(route.waypoints)
elif violation == "deviation":
theta = random.choice([90.0, 270.0])
points = self._apply_deviation(route, theta_deg=theta)
elif violation == "reverse":
points = self._apply_reverse(route)
elif violation == "arrival_leave":
points = self._apply_arrival_leave(route)
else:
points = route.waypoints
return SyntheticTrajectory(
points=points, nav_route=route,
violation_type=violation, liability_label=label,
description=description,
)
def generate_dataset(
self, n_samples: int = 100,
city_bbox: Tuple[float, float, float, float] = (31.0, 121.0, 31.5, 121.5),
) -> List[SyntheticTrajectory]:
"""
Generate a balanced dataset of synthetic trajectories.
Parameters
----------
n_samples : total trajectories to generate
city_bbox : (lat_min, lon_min, lat_max, lon_max) sampling region
Returns
-------
List of SyntheticTrajectory objects
"""
lat_min, lon_min, lat_max, lon_max = city_bbox
violations = ["compliant", "drift", "deviation", "reverse", "arrival_leave"]
dataset = []
for _ in range(n_samples):
start = GPSPoint(
lat=random.uniform(lat_min, lat_max),
lon=random.uniform(lon_min, lon_max),
)
end = GPSPoint(
lat=random.uniform(lat_min, lat_max),
lon=random.uniform(lon_min, lon_max),
)
violation = random.choice(violations)
dataset.append(self.generate(start, end, violation))
print(f"Generated {len(dataset)} trajectories.")
return dataset
# ─── SECTION 3: Trajectory Rendering ─────────────────────────────────────────
def render_trajectory_image(
traj: SyntheticTrajectory,
img_size: int = 256,
) -> Tensor:
"""
Render the trajectory into a visual image tensor (Section 2.1, O_image).
Renders both the planned navigation route S_geo (black/blue channel)
and the actual driver trajectory T_real (red channel) onto a grid.
The visual difference between the two encodes the liability signal.
In production, use PIL/OpenCV to render onto actual map tiles.
This implementation renders onto a synthetic grid for smoke testing.
Returns
-------
image : (3, img_size, img_size) float tensor in [0, 1]
"""
img = torch.zeros(3, img_size, img_size)
def to_pixel(pt: GPSPoint, route: NavigationRoute, sz: int) -> Tuple[int, int]:
"""Map GPS coordinate to pixel grid position."""
all_pts = route.waypoints + [route.start, route.end]
lats = [p.lat for p in all_pts]
lons = [p.lon for p in all_pts]
lat_range = max(lats) - min(lats) + 1e-8
lon_range = max(lons) - min(lons) + 1e-8
row = int((pt.lat - min(lats)) / lat_range * (sz - 1))
col = int((pt.lon - min(lons)) / lon_range * (sz - 1))
return min(max(row, 0), sz - 1), min(max(col, 0), sz - 1)
route = traj.nav_route
# Blue channel: planned navigation route (S_geo)
for pt in route.waypoints:
r, c = to_pixel(pt, route, img_size)
img[2, r, c] = 1.0
# Red channel: actual driver trajectory (T_real)
for pt in traj.points:
r, c = to_pixel(pt, route, img_size)
img[0, r, c] = 1.0
return img
# ─── SECTION 4: Chain-of-Adjudication ────────────────────────────────────────
@dataclass
class AdjudicationQuery:
"""A query from the Adjudicator to the Visual Analyst."""
question: str
context: str # which rule this query is verifying
@dataclass
class AdjudicationStep:
"""One step in the multi-turn CoA dialogue."""
query: AdjudicationQuery
answer: str
@dataclass
class AdjudicationChain:
"""
Final structured reasoning chain produced by the Reasoning Refiner.
Four-stage format from Section 3.2:
1. Information Analysis
2. Visual Evidence Integration
3. Rule Grounding
4. Comprehensive Adjudication
"""
information_analysis: str
visual_evidence: str
rule_grounding: str
comprehensive_adjudication: str
verdict: str
judge_scenario: str
steps: List[AdjudicationStep] = field(default_factory=list)
def to_formatted_string(self) -> str:
"""Format chain as model training target."""
return (
f"<reason>\n"
f"(1) Information Analysis: {self.information_analysis}\n"
f"(2) Visual Evidence Integration: {self.visual_evidence}\n"
f"(3) Rule Grounding: {self.rule_grounding}\n"
f"(4) Comprehensive Adjudication: {self.comprehensive_adjudication}\n"
f"</reason>\n"
f"<judge>{self.judge_scenario}</judge>\n"
f"<result>{self.verdict}</result>"
)
class MockAdjudicator:
"""
Mock implementation of the Adjudicator LLM agent (Section 3.2).
In production, this is instantiated from QwQ-32B or DeepSeek-V3.1.
The Adjudicator reads O_text + retrieved rules and formulates
evidence queries WITHOUT direct visual access.
"""
def formulate_query(self, order_text: str, rules: List[str]) -> AdjudicationQuery:
"""Generate an evidence query for the Visual Analyst."""
return AdjudicationQuery(
question="Does the driver's trajectory show deviation from the planned route?",
context=rules[0] if rules else "General route compliance check",
)
def derive_verdict(self, order_text: str, rules: List[str],
visual_evidence: str) -> Tuple[str, str]:
"""Derive final verdict from accumulated evidence (mock)."""
if "malicious" in visual_evidence.lower() or "reverse" in visual_evidence.lower():
return "Malicious Fault", "Intentional deviation or reverse driving"
elif "deviation" in visual_evidence.lower():
return "Normal Fault", "Unintentional route deviation"
else:
return "No Fault", "Compliant behaviour confirmed"
class MockVisualAnalyst:
"""
Mock Visual Analyst that examines trajectory images (Section 3.2).
In production, this is Qwen3-VL-32B-Instruct receiving O_image.
"""
def answer_query(self, image: Tensor, query: AdjudicationQuery,
traj: SyntheticTrajectory) -> str:
"""Produce a visual observation based on the trajectory."""
descriptions = {
"deviation": "Map shows significant deviation from planned route at mid-journey.",
"reverse": "Trajectory shows retrograde/reverse motion at a critical node.",
"arrival_leave": "Driver arrived at destination then exhibits malicious departure.",
"compliant": "Trajectories closely aligned. No violation pattern detected.",
"drift": "Minor GPS noise observed. Route compliance maintained throughout.",
}
return descriptions.get(traj.violation_type, "Trajectory analysis complete.")
class ChainOfAdjudication:
"""
Chain-of-Adjudication (CoA) Framework (Section 3.2).
Orchestrates the multi-turn dialogue between:
- Adjudicator (LLM): reads text + rules, formulates evidence queries
- Visual Analyst (MLLM): examines trajectory image, answers queries
- Reasoning Refiner (LLM): distills dialogue into 4-stage structured chain
Maximum interaction turns: cfg.max_coa_turns (default 8)
"""
def __init__(self, cfg: RideJudgeConfig):
self.cfg = cfg
self.adjudicator = MockAdjudicator()
self.analyst = MockVisualAnalyst()
def synthesise(
self,
traj: SyntheticTrajectory,
image: Tensor,
order_text: str,
applicable_rules: List[str],
) -> AdjudicationChain:
"""
Run the full CoA dialogue and produce a structured reasoning chain.
Parameters
----------
traj : SyntheticTrajectory with label and metadata
image : (3, H, W) rendered trajectory image
order_text : textual order metadata O_text
applicable_rules: pre-filtered rules from KACR module
Returns
-------
AdjudicationChain — 4-stage structured reasoning chain
"""
steps = []
# Multi-turn evidence gathering (limited to max_coa_turns)
for turn in range(self.cfg.max_coa_turns):
query = self.adjudicator.formulate_query(order_text, applicable_rules)
answer = self.analyst.answer_query(image, query, traj)
steps.append(AdjudicationStep(query=query, answer=answer))
# In production: check if Adjudicator has enough evidence to conclude
if turn >= 1: # mock: stop after 2 turns for efficiency
break
# Derive verdict from accumulated evidence
visual_evidence_summary = " | ".join([s.answer for s in steps])
verdict, judge_scenario = self.adjudicator.derive_verdict(
order_text, applicable_rules, visual_evidence_summary
)
# Reasoning Refiner: distill into 4-stage structure
chain = AdjudicationChain(
information_analysis=f"Order: {order_text[:100]}... Dispute type: {traj.violation_type}",
visual_evidence=visual_evidence_summary,
rule_grounding=f"Applied rules: {'; '.join(applicable_rules[:2])}",
comprehensive_adjudication=(
f"Based on trajectory analysis and rule grounding, verdict: {verdict}. "
f"Scenario: {judge_scenario}"
),
verdict=verdict,
judge_scenario=judge_scenario,
steps=steps,
)
return chain
def filter_corpus(
self, chains: List[AdjudicationChain],
ground_truths: List[str],
) -> List[AdjudicationChain]:
"""
Data Selection (Section 3.2): Filter out instances where
synthesised verdict diverges from human-annotated ground truth.
Ensures corpus contains only high-confidence evidence-supported chains.
"""
filtered = [
c for c, gt in zip(chains, ground_truths)
if c.verdict == gt
]
print(f"CoA filtering: {len(chains)} → {len(filtered)} high-confidence chains")
return filtered
# ─── SECTION 5: Scenario-Aware Rule Calibration ───────────────────────────────
class RuleClassifier(nn.Module):
"""
Binary classifier for a single platform rule (Eq. 6).
Each rule r_i has a dedicated binary classifier f_i that determines
whether the rule is applicable to a given order.
In production, replace with XGBoost/LightGBM/CatBoost using hybrid
tabular + semantic features (bge-large-zh-v1.5 embeddings).
This PyTorch implementation serves as an interface-compatible mock.
"""
def __init__(self, input_dim: int = 128):
super().__init__()
self.net = nn.Sequential(
nn.Linear(input_dim, 64),
nn.ReLU(),
nn.Linear(64, 1),
)
def forward(self, x: Tensor) -> Tensor:
return torch.sigmoid(self.net(x)) # (B, 1) probability of rule applicability
class DecomposedEnsembleCalibrator:
"""
Decomposed Ensemble Calibrator for Scenario-Aware Rule Calibration (Eq. 6-7).
Trains N independent binary classifiers, one per platform rule.
During inference, filters the rule base to retain only applicable rules,
preventing context overload and hallucination on irrelevant regulations.
Model selection prioritises Recall over Accuracy (Section B.3.1) —
missing a relevant rule is more costly than including a marginal one.
"""
def __init__(self, n_rules: int, input_dim: int = 128):
self.n_rules = n_rules
self.classifiers = nn.ModuleList([
RuleClassifier(input_dim) for _ in range(n_rules)
])
self.rule_names = [f"Rule_{i}" for i in range(n_rules)]
def train_classifiers(
self, order_features: Tensor, rule_labels: Tensor,
epochs: int = 5, lr: float = 1e-3
):
"""
Train each binary classifier on rule applicability annotations.
order_features : (N_samples, input_dim)
rule_labels : (N_samples, n_rules) binary applicability matrix
"""
optimizer = torch.optim.Adam(
[p for clf in self.classifiers for p in clf.parameters()], lr=lr
)
for ep in range(epochs):
total_loss = 0.0
for i, clf in enumerate(self.classifiers):
optimizer.zero_grad()
pred = clf(order_features).squeeze(-1)
loss = F.binary_cross_entropy(pred, rule_labels[:, i].float())
loss.backward()
optimizer.step()
total_loss += loss.item()
if ep % 2 == 0:
print(f" [RuleCalib] Ep {ep}/{epochs} avg_loss={total_loss/self.n_rules:.4f}")
@torch.no_grad()
def filter_rules(self, order_features: Tensor, threshold: float = 0.4) -> List[str]:
"""
Apply trained classifiers to select applicable rules (Eq. 7).
K' = {r_i ∈ K | f_i(O_query) = 1}
Returns list of applicable rule names (lower threshold → higher recall).
"""
applicable = []
for i, clf in enumerate(self.classifiers):
prob = clf(order_features.unsqueeze(0)).item()
if prob >= threshold:
applicable.append(self.rule_names[i])
return applicable if applicable else [self.rule_names[0]] # fallback
# ─── SECTION 6: Retrieval-Augmented Insight Extraction ───────────────────────
class HistoricalRepository:
"""
Historical precedent repository with temporal partitioning (Section 4.2).
Maintains a chronologically ordered collection of resolved disputes.
Strictly enforces that only cases resolved BEFORE the query timestamp
are accessible (Eq. 19), preventing data leakage.
"""
def __init__(self, embed_dim: int = 256):
self.embed_dim = embed_dim
self.cases: List[Dict] = []
self.embeddings: List[Tensor] = []
self.embedder = nn.Linear(embed_dim, embed_dim, bias=False)
def _embed(self, text_features: Tensor) -> Tensor:
"""Mock text embedding (replace with bge-large-zh-v1.5 in production)."""
with torch.no_grad():
emb = self.embedder(text_features)
return F.normalize(emb, dim=-1)
def add_case(self, order_text: str, verdict: str,
timestamp: int, features: Tensor):
"""Add a resolved case to the repository."""
self.cases.append({"text": order_text, "verdict": verdict, "ts": timestamp})
self.embeddings.append(self._embed(features))
def retrieve_top_k(self, query_features: Tensor,
query_timestamp: int, k: int = 4) -> List[Dict]:
"""
Retrieve top-K semantically similar precedents (Eq. 8).
Enforces temporal partitioning: only cases with ts < query_timestamp
are eligible for retrieval.
"""
if not self.cases:
return []
q_emb = self._embed(query_features)
# Compute cosine similarities only for temporally valid cases
valid_idx = [i for i, c in enumerate(self.cases) if c["ts"] < query_timestamp]
if not valid_idx:
return []
sim_scores = []
for i in valid_idx:
cos_sim = (q_emb * self.embeddings[i]).sum().item()
sim_scores.append((i, cos_sim))
sim_scores.sort(key=lambda x: x[1], reverse=True)
top_k_idx = [i for i, _ in sim_scores[:min(k, len(sim_scores))]]
return [self.cases[i] for i in top_k_idx]
def synthesise_meta_insight(self, cases: List[Dict]) -> str:
"""
Meta-Insight Abstraction (Eq. 9, Section 4.2).
Summarises retrieved cases into a concise insight for the reasoning model.
In production, this uses QwQ-32B as the Summary Agent.
"""
if not cases:
return "No relevant historical precedents found."
verdict_counts = {}
for c in cases:
verdict_counts[c["verdict"]] = verdict_counts.get(c["verdict"], 0) + 1
most_common = max(verdict_counts, key=verdict_counts.get)
return (
f"Retrieved {len(cases)} similar historical cases. "
f"Most common outcome: {most_common} ({verdict_counts[most_common]}/{len(cases)} cases). "
f"Historical patterns suggest reviewing route deviation evidence carefully."
)
# ─── SECTION 7: Ordinal-Sensitive Reward ────────────────────────────────────
class OrdinalSensitiveReward:
"""
Ordinal-Sensitive Reward mechanism (Section 5, Eq. 10-11).
Replaces binary answer rewards with graded signals based on ordinal
proximity between predicted and true liability labels.
R_ans(y_pred, y_gt) =
1.0 if y_pred == y_gt
d(r(y_pred), r(y_gt)) if y_pred ≠ y_gt and y_pred ∈ Y
0 if y_pred ∉ Y
where d(·) is a semantic distance function over the ordinal rank mapping.
Adjacent labels receive partial credit; distant labels receive low credit.
R_total = λ_ans * R_ans + λ_fmt * R_fmt
"""
def __init__(self, cfg: RideJudgeConfig):
self.cfg = cfg
self.n_labels = len(cfg.label_space)
def _ordinal_distance(self, rank_pred: int, rank_gt: int) -> float:
"""
Semantic distance function d(r(y_pred), r(y_gt)).
Returns a partial reward in (0, 1) inversely proportional to the
ordinal rank distance. Adjacent labels receive ~0.5 credit,
maximally distant labels receive credit approaching 0.
"""
dist = abs(rank_pred - rank_gt)
max_dist = self.n_labels - 1
# Exponential decay: closer labels get more credit
return math.exp(-dist / max_dist) * (1.0 - 1.0 / self.n_labels)
def answer_reward(self, y_pred: str, y_gt: str) -> float:
"""Compute ordinal-sensitive answer reward R_ans."""
if y_pred not in self.cfg.label_space:
return 0.0 # invalid prediction → zero reward
if y_pred == y_gt:
return 1.0 # exact match → full reward
rank_pred = self.cfg.rank(y_pred)
rank_gt = self.cfg.rank(y_gt)
return self._ordinal_distance(rank_pred, rank_gt)
def format_reward(self, output: str) -> float:
"""
Format compliance reward R_fmt.
Checks that output contains required XML-style tags.
"""
required_tags = ["<reason>", "</reason>", "<judge>", "<result>"]
present = sum(1 for tag in required_tags if tag in output)
return present / len(required_tags)
def total_reward(self, y_pred: str, y_gt: str, output: str) -> float:
"""
R_total = λ_ans * R_ans + λ_fmt * R_fmt (Eq. 11)
Balancing coefficients: λ_ans=0.8, λ_fmt=0.2
"""
r_ans = self.answer_reward(y_pred, y_gt)
r_fmt = self.format_reward(output)
return self.cfg.lambda_ans * r_ans + self.cfg.lambda_fmt * r_fmt
# ─── SECTION 8: Progressive Training Framework ────────────────────────────────
class MockRideJudgeModel(nn.Module):
"""
Mock RideJudge MLLM for interface validation.
In production, initialise from:
Qwen3-VL-8B-Instruct → RideJudge-8B
Qwen3-VL-4B-Instruct → RideJudge-4B
Architecture:
Vision Encoder → trajectory map features
Projector → cross-modal alignment
LLM Backbone → adjudication reasoning + verdict generation
"""
def __init__(self, visual_dim: int = 64, text_dim: int = 128, n_labels: int = 3):
super().__init__()
# Vision encoder (Stage 1: unfrozen)
self.vision_encoder = nn.Sequential(
nn.Conv2d(3, 16, 3, padding=1),
nn.ReLU(),
nn.AdaptiveAvgPool2d((4, 4)),
nn.Flatten(),
nn.Linear(16 * 4 * 4, visual_dim),
)
# Projector (Stage 1: unfrozen)
self.projector = nn.Linear(visual_dim, text_dim)
# LLM backbone (Stage 2: unfrozen; Stage 1: frozen)
self.llm_backbone = nn.Sequential(
nn.Linear(text_dim * 2, 256),
nn.ReLU(),
nn.Linear(256, n_labels),
)
self.text_encoder = nn.Linear(text_dim, text_dim)
def forward(self, image: Tensor, text_features: Tensor) -> Tensor:
"""
Returns (B, n_labels) logits for adjudication verdict prediction.
"""
vis_feat = self.projector(self.vision_encoder(image))
text_feat = self.text_encoder(text_features)
fused = torch.cat([vis_feat, text_feat], dim=-1)
return self.llm_backbone(fused)
class ProgressiveTrainer:
"""
Three-Stage Progressive Alignment Training (Section 5).
Stage 1 — Visual Concept Alignment:
Freezes LLM backbone. Trains vision encoder + projector on SynTraj data.
Goal: perceptual grounding of trajectory patterns.
Stage 2 — Adjudication Logic Alignment:
Freezes vision encoder. Fine-tunes LLM backbone on CoA reasoning chains.
Goal: learn 4-stage evidence-anchored adjudication format.
Stage 3 — Reinforcement & Exploration (DAPO + OS Reward):
Filters ambiguous samples (0.2 ≤ S_avg ≤ 0.8 rollout consistency).
Applies Ordinal-Sensitive Reward for RL optimisation.
Goal: explore decision boundaries, consolidate robustness.
"""
def __init__(self, model: MockRideJudgeModel, cfg: RideJudgeConfig):
self.model = model
self.cfg = cfg
self.os_reward = OrdinalSensitiveReward(cfg)
def stage1_visual_alignment(
self, syntraj_images: Tensor, syntraj_labels: Tensor,
epochs: int = 4, lr: float = 5e-6,
):
"""
Stage 1: Train vision encoder + projector; freeze LLM backbone.
Uses SynTraj dataset: 12,585 image-caption pairs.
"""
print("\n[Stage 1] Visual Concept Alignment...")
# Freeze LLM backbone
for p in self.model.llm_backbone.parameters(): p.requires_grad = False
for p in self.model.text_encoder.parameters(): p.requires_grad = False
opt = torch.optim.AdamW(
filter(lambda p: p.requires_grad, self.model.parameters()),
lr=lr, weight_decay=1e-4
)
self.model.train()
for ep in range(epochs):
self.model.text_encoder.weight.requires_grad = False
vis = self.model.vision_encoder(syntraj_images)
proj = self.model.projector(vis)
# Simple contrastive-style loss on visual features
normed = F.normalize(proj, dim=-1)
labels_flat = syntraj_labels.view(-1)
loss = F.cross_entropy(normed @ normed.T, labels_flat.clamp(0, proj.shape[0] - 1))
opt.zero_grad(); loss.backward(); opt.step()
print(f" Ep {ep+1}/{epochs} loss={loss.item():.4f}")
def stage2_logic_alignment(
self, images: Tensor, text_features: Tensor, labels: Tensor,
epochs: int = 8, lr: float = 5e-6,
):
"""
Stage 2: Freeze vision encoder; fine-tune LLM on CoA reasoning chains.
Uses Chain-of-Adjudication corpus: 14,582 high-confidence samples.
"""
print("\n[Stage 2] Adjudication Logic Alignment...")
# Freeze vision components
for p in self.model.vision_encoder.parameters(): p.requires_grad = False
for p in self.model.projector.parameters(): p.requires_grad = False
# Unfreeze LLM backbone
for p in self.model.llm_backbone.parameters(): p.requires_grad = True
for p in self.model.text_encoder.parameters(): p.requires_grad = True
opt = torch.optim.AdamW(
filter(lambda p: p.requires_grad, self.model.parameters()),
lr=lr, weight_decay=1e-4
)
self.model.train()
for ep in range(epochs):
logits = self.model(images, text_features)
loss = F.cross_entropy(logits, labels.long())
opt.zero_grad(); loss.backward(); opt.step()
acc = (logits.argmax(1) == labels.long()).float().mean().item()
print(f" Ep {ep+1}/{epochs} CE={loss.item():.4f} Acc={acc:.3f}")
def _select_rl_samples(
self, images: Tensor, text_features: Tensor, labels: Tensor,
) -> Tuple[Tensor, Tensor, Tensor]:
"""
Divergence-Aware Data Selection (Section 5).
Perform N=10 stochastic rollouts per sample, compute consistency
score S_avg, retain only 0.2 ≤ S_avg ≤ 0.8 (ambiguous samples).
These are the samples where the model currently exhibits genuine
uncertainty — RL signal has maximum impact here.
"""
self.model.eval()
B = images.shape[0]
consistency_scores = torch.zeros(B)
with torch.no_grad():
for _ in range(self.cfg.rl_n_rollouts):
logits = self.model(images, text_features)
preds = logits.argmax(1)
consistency_scores += (preds == labels.long()).float()
consistency_scores /= self.cfg.rl_n_rollouts # S_avg
mask = (
(consistency_scores >= self.cfg.rl_min_consistency) &
(consistency_scores <= self.cfg.rl_max_consistency)
)
n_selected = mask.sum().item()
print(f" RL Data Selection: {n_selected}/{B} ambiguous samples retained")
return images[mask], text_features[mask], labels[mask]
def stage3_rl_exploration(
self, images: Tensor, text_features: Tensor, labels: Tensor,
label_names: List[str], epochs: int = 3, lr: float = 1e-6,
):
"""
Stage 3: DAPO-based Reinforcement Learning with Ordinal-Sensitive Reward.
Selects ambiguous training samples, then optimises using
R_total = λ_ans * R_ans + λ_fmt * R_fmt.
"""
print("\n[Stage 3] Reinforcement Learning Exploration (DAPO + OS Reward)...")
rl_images, rl_text, rl_labels = self._select_rl_samples(images, text_features, labels)
if rl_images.shape[0] == 0:
print(" No ambiguous samples found — skipping RL stage.")
return
opt = torch.optim.AdamW(self.model.parameters(), lr=lr, weight_decay=1e-2)
self.model.train()
for ep in range(epochs):
logits = self.model(rl_images, rl_text)
preds_idx = logits.argmax(1)
# Compute ordinal-sensitive rewards for each sample
rewards = torch.tensor([
self.os_reward.total_reward(
label_names[preds_idx[i].item()],
label_names[rl_labels[i].long().item()],
output="<reason></reason><judge></judge><result></result>" # mock full format
)
for i in range(rl_images.shape[0])
])
# Policy gradient: maximise expected reward
log_probs = F.log_softmax(logits, dim=-1)
selected_lp = log_probs.gather(1, preds_idx.unsqueeze(1)).squeeze(1)
loss = -(rewards * selected_lp).mean() # REINFORCE objective
opt.zero_grad(); loss.backward(); opt.step()
avg_reward = rewards.mean().item()
print(f" Ep {ep+1}/{epochs} PG_loss={loss.item():.4f} Avg_reward={avg_reward:.3f}")
# ─── SECTION 9: Evaluation & Inference ───────────────────────────────────────
@torch.no_grad()
def evaluate_ridejudge(
model: MockRideJudgeModel,
images: Tensor,
text_features: Tensor,
labels: Tensor,
cfg: RideJudgeConfig,
) -> Dict[str, float]:
"""
Evaluate RideJudge on a test set.
Reports Accuracy, per-class Precision and Recall (Normal/Malicious),
matching the evaluation protocol from Section 6.1.
"""
model.eval()
logits = model(images, text_features)
preds = logits.argmax(1)
gt = labels.long()
acc = (preds == gt).float().mean().item() * 100
results = {"Accuracy (%)": acc}
for cls_idx, cls_name in enumerate(cfg.label_space):
tp = ((preds == cls_idx) & (gt == cls_idx)).sum().item()
fp = ((preds == cls_idx) & (gt != cls_idx)).sum().item()
fn = ((preds != cls_idx) & (gt == cls_idx)).sum().item()
prec = tp / (tp + fp + 1e-8) * 100
recall = tp / (tp + fn + 1e-8) * 100
results[f"{cls_name} P (%)"] = prec
results[f"{cls_name} R (%)"] = recall
return results
# ─── SECTION 10: Dataset Helpers ─────────────────────────────────────────────
def make_dummy_ridehailing_batch(
B: int = 8, img_size: int = 64,
text_dim: int = 128, n_labels: int = 3,
) -> Tuple[Tensor, Tensor, Tensor]:
"""
Generate a dummy batch for smoke testing.
Returns
-------
images : (B, 3, img_size, img_size) trajectory map tensors
text_features : (B, text_dim) order metadata embeddings
labels : (B,) ordinal liability labels [0, n_labels)
"""
images = torch.randn(B, 3, img_size, img_size)
text_features = torch.randn(B, text_dim)
labels = torch.randint(0, n_labels, (B,)).float()
return images, text_features, labels
# ─── SECTION 11: Smoke Test ──────────────────────────────────────────────────
if __name__ == "__main__":
print("=" * 60)
print("RideJudge — Full Framework Smoke Test")
print("=" * 60)
torch.manual_seed(42)
random.seed(42)
cfg = RideJudgeConfig()
# ── 1. SynTraj trajectory generation ─────────────────────────────────────
print("\n[1/6] SynTraj: Generating synthetic trajectories...")
engine = SynTraj()
dataset = engine.generate_dataset(n_samples=10)
sample = dataset[0]
print(f" Sample — Type: {sample.violation_type} | Label: {sample.liability_label}")
print(f" Trajectory points: {len(sample.points)}")
# ── 2. Trajectory rendering ──────────────────────────────────────────────
print("\n[2/6] Rendering trajectory to image...")
img_tensor = render_trajectory_image(sample, img_size=64)
assert img_tensor.shape == (3, 64, 64)
print(f" ✓ Image tensor: {tuple(img_tensor.shape)}")
# ── 3. Chain-of-Adjudication ─────────────────────────────────────────────
print("\n[3/6] Chain-of-Adjudication reasoning...")
coa = ChainOfAdjudication(cfg)
chain = coa.synthesise(
traj=sample,
image=img_tensor.unsqueeze(0),
order_text="Order started at 10:30, driver cancelled at 10:45. Driver claims pickup unreachable.",
applicable_rules=["Rule_deviation_fault", "Rule_malicious_detour"],
)
print(f" ✓ Verdict: {chain.verdict} | Scenario: {chain.judge_scenario}")
print(" Formatted output preview:")
print(" " + chain.to_formatted_string().split("\n")[0][:80])
# ── 4. Ordinal-Sensitive Reward ──────────────────────────────────────────
print("\n[4/6] Ordinal-Sensitive Reward validation...")
os_rew = OrdinalSensitiveReward(cfg)
tests = [
("No Fault", "No Fault", 1.0), # exact match
("Normal Fault", "No Fault", None), # partial credit
("Malicious Fault", "No Fault", None), # larger penalty
("INVALID", "Normal Fault", 0.0), # out-of-space → 0
]
for y_pred, y_gt, expected in tests:
r = os_rew.answer_reward(y_pred, y_gt)
check = f"== {expected}" if expected is not None else f"∈ (0, 1)"
print(f" '{y_pred}' vs '{y_gt}' → R_ans={r:.4f} [{check}]")
assert os_rew.answer_reward("No Fault", "No Fault") == 1.0
assert os_rew.answer_reward("INVALID", "Normal Fault") == 0.0
r_adj = os_rew.answer_reward("Normal Fault", "No Fault")
r_far = os_rew.answer_reward("Malicious Fault", "No Fault")
assert r_adj > r_far, "Adjacent label should receive more reward than distant label"
print(" ✓ Ordinal gradient confirmed: adjacent > distant partial credit")
# ── 5. Progressive Training ──────────────────────────────────────────────
print("\n[5/6] Progressive Training (2 epochs per stage, tiny batch)...")
images, text_feats, labels = make_dummy_ridehailing_batch(B=8, img_size=64)
model = MockRideJudgeModel(visual_dim=64, text_dim=128, n_labels=3)
trainer = ProgressiveTrainer(model, cfg)
trainer.stage1_visual_alignment(images, labels, epochs=2)
trainer.stage2_logic_alignment(images, text_feats, labels, epochs=2)
trainer.stage3_rl_exploration(images, text_feats, labels,
cfg.label_space, epochs=2)
# ── 6. Evaluation ───────────────────────────────────────────────────────
print("\n[6/6] Evaluation on test batch...")
results = evaluate_ridejudge(model, images, text_feats, labels, cfg)
for k, v in results.items():
print(f" {k}: {v:.2f}")
print("\n" + "=" * 60)
print("✓ All checks passed. RideJudge framework is ready.")
print("=" * 60)
print("""
Next steps:
1. Replace MockRideJudgeModel with Qwen3-VL-8B-Instruct:
Use LLaMA-Factory for SFT stages (Stage 1 & 2)
Use EasyR1 for RL stage (Stage 3)
https://github.com/hiyouga/LLaMA-Factory
https://github.com/hiyouga/EasyR1
2. Use a real navigation API for SynTraj (replace _simulate_route):
https://lbs.amap.com (Amap/Gaode Maps Open Platform)
3. Replace MockVisualAnalyst with Qwen3-VL-32B-Instruct
and MockAdjudicator with QwQ-32B for CoA data synthesis.
4. Replace RuleClassifier with XGBoost/LightGBM/CatBoost ensemble
using hybrid tabular + bge-large-zh-v1.5 semantic features.
5. Paper preprint: https://arxiv.org/abs/2603.17328
""")
Read the Full Paper
The complete paper — including full ablation tables, city-by-city stability results, PetFinder generalisation experiments, detailed agent prompts, and hyperparameter configurations — is available on arXiv.
Wu, W., Cheng, Z.-J., Meng, J., Zhen, P., Huang, S., Li, Q., Wu, G., & Guo, L.-Z. (2026). A Progressive Visual-Logic-Aligned Framework for Ride-Hailing Adjudication. arXiv:2603.17328.
This article is an independent editorial analysis of pre-print research. The PyTorch implementation is an educational adaptation using mock models; the original authors trained on 8 × NVIDIA H200 GPUs using LLaMA-Factory and EasyR1 with Qwen3-VL-8B-Instruct as the backbone. Refer to the arXiv paper for exact hyperparameters and the SynTraj dataset upon public release.