SegTrans: How to Make Adversarial Examples Transfer Across Segmentation Models Without Extra Cost
Segmentation models correct each other’s mistakes through a “tight coupling” phenomenon – which makes them brutally hard to fool in a black‑box setting. Researchers discovered that by destroying global semantic integrity and remapping local features, transfer attack success jumps by 8.55% with zero additional FLOPs.
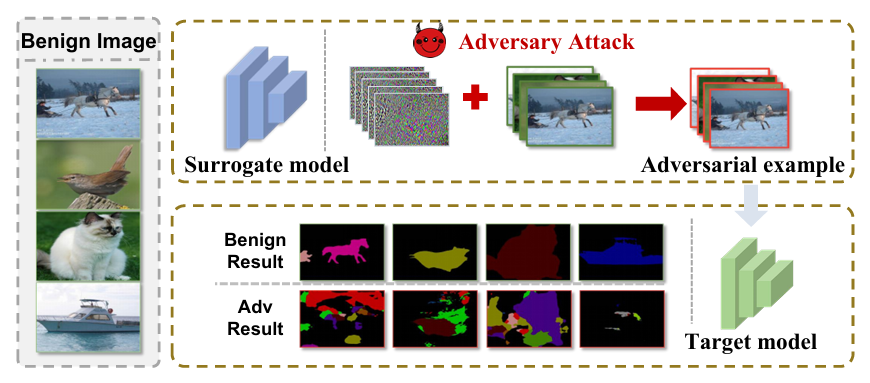
In autonomous driving, medical imaging, and remote sensing, semantic segmentation models are the eyes of the machine. They assign a class to every pixel – a task far more delicate than image classification. But these eyes can be blinded by adversarial examples. The catch: while white‑box attacks work effortlessly, black‑box transfer attacks usually fail because segmentation models are wired to exploit contextual dependencies. If you perturb a cyclist, the model still sees “person + bike” and corrects the prediction. That is the “tight coupling phenomenon”.
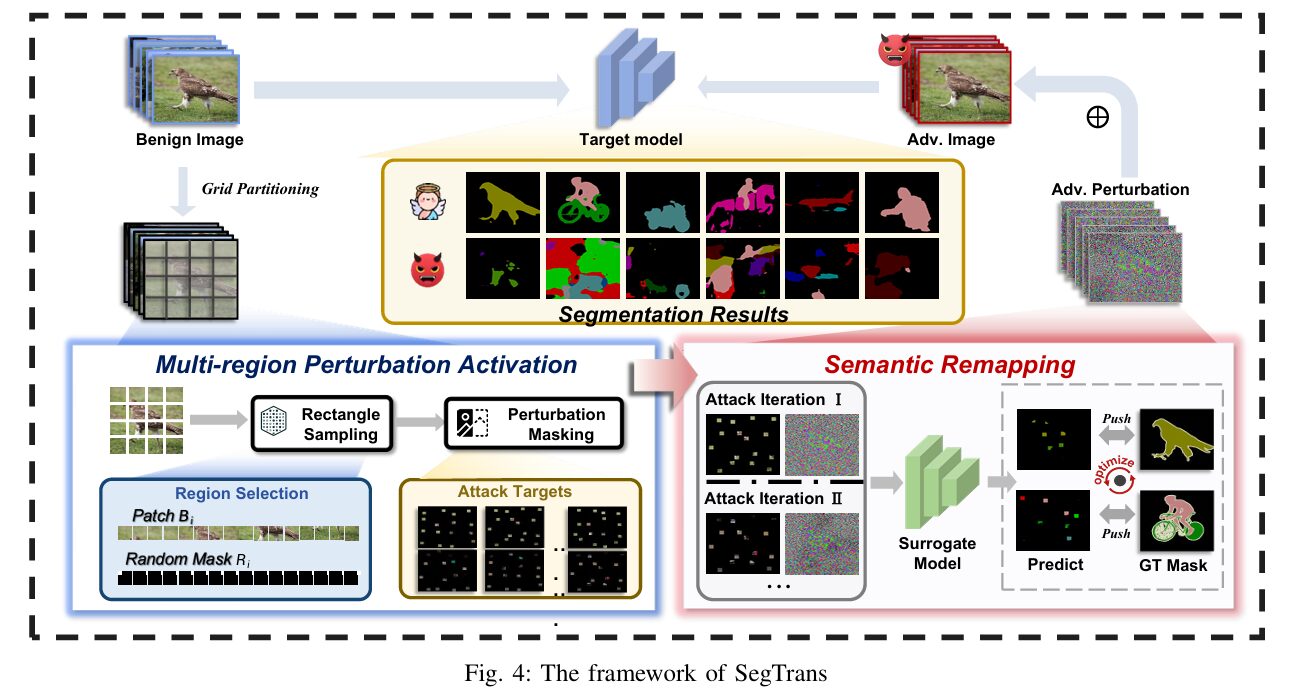
Researchers from Huazhong University of Science and Technology and Griffith University have spent the last two years dissecting this failure mode. Their solution, SegTrans, does not tweak the loss function or ensemble multiple surrogates. Instead it surgically removes the two root causes: tight coupling (objects help each other to resist perturbations) and feature fixation (adversarial noise overfits to the surrogate model’s feature map). By introducing two modules – multi‑region perturbation activation and semantic remapping – SegTrans generates transferable examples that work across FCN, PSPNet, DeepLabV1 and DeepLabV3+, on both PASCAL VOC and Cityscapes, with an average attack success rate (ASR) improvement of 8.55% over the previous state‑of‑the‑art EBAD, while being twice as fast.

The Hidden Challenge: Why Transfer Attacks Stall on Segmentation
Unlike classifiers that output a single label, segmentation networks predict for every pixel. They learn rich spatial relationships: a car is almost never flying, a pedestrian seldom appears on a highway median. This “tight coupling” means that even if you successfully perturb a region, the surrounding pixels – e.g. the road under the car – provide enough context for the model to correct the error. The authors quantified this by removing the background outside the target object (Fig. 2). With background gone, attack success rate soared, confirming that the coupling acts as a natural defence.
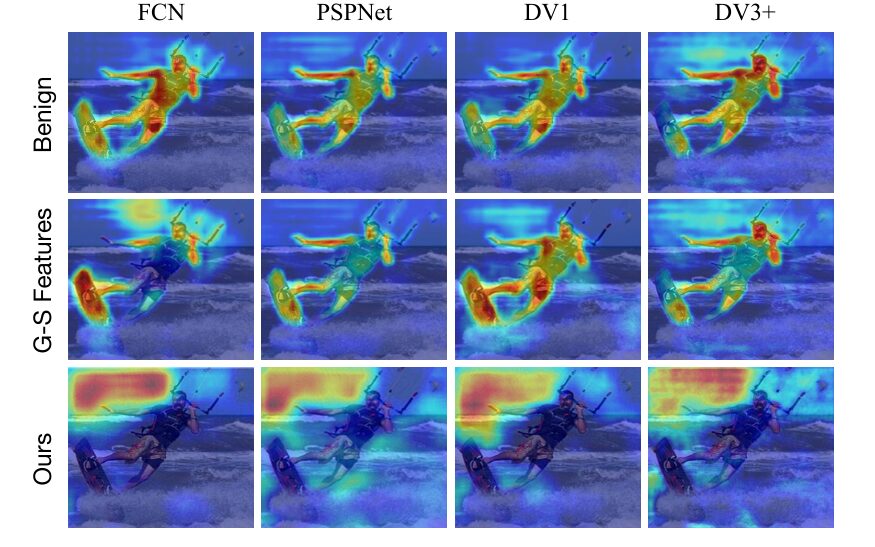
The second obstacle is feature fixation. Using Grad‑CAM, the team visualised where different models look (Fig. 3). FCN, PSPNet, DeepLabV1 and DeepLabV3+ focus on completely different regions of the same image. Perturbations crafted for one model latch onto its specific attention spots and fail to generalise. Fixation is baked into the architecture – different receptive fields, different context modules. You cannot change the models at test time, so you must change the way you generate perturbations.
SegTrans: Breaking Semantic Integrity on Purpose
The core idea is counter‑intuitive: to build a transferable perturbation, you should not use the whole, semantically coherent image. Instead, you randomly preserve only isolated rectangular patches across the image, and use those partial views to guide the attack. This is the multi‑region perturbation activation module. In each iteration, the input \(x\) is divided into \(N\) grids; inside each grid a rectangle of random size is retained (others are zeroed out). The union of these rectangles forms a mask \(m\). The loss is then computed only on the retained regions:
By discarding large parts of the image, the perturbation cannot rely on global context – it must learn to disrupt objects in isolation. This directly counters the tight coupling phenomenon. The rectangles are chosen randomly each iteration, with size constraints: \(\frac{l_i \times w_i}{G_w \times G_h} = \alpha_i\).
Semantic Remapping: Escaping Feature Fixation
To tackle feature fixation, SegTrans goes one step further: instead of using a single masked version, it samples \(T\) different batches of \(N\) rectangles per attack iteration (\(T=5\) by default). Each batch yields a different mask \(m_j\). The gradients from all \(T\) batches are accumulated. This forces the perturbation to be effective across many different “views” of the image, mimicking the varied attention patterns of different target models. The authors call this semantic remapping – the semantic information is remapped onto multiple sparse representations, and the perturbation must work for all of them.
The final update uses:
This simple addition raises transferability dramatically without extra compute – the same image is reused, only the masks change.
Experimental Validation: +8.55% ASR Without Extra FLOPs
The team tested SegTrans on four architectures (FCN, PSPNet, DeepLabV1, DeepLabV3+) with backbones MobileNet, ResNet50, ResNet101, and two datasets: PASCAL VOC (1,449 validation images) and Cityscapes (500). The perturbation budget was \(\epsilon = 8/255\). Hyper‑parameters: \(N=16\) grids, rectangle side length 32, \(T=5\) remapping iterations, attack steps \(K=10\).
Table 1 (abbreviated) shows the attack success rate (ASR = benign mIoU – adversarial mIoU). SegTrans consistently achieves >50% ASR across 288 settings. More importantly, it beats all prior methods, including the ensemble‑based EBAD, by a significant margin.
| Target model | Surrogate | PGD | MI‑FGSM | EBAD | SegTrans |
|---|---|---|---|---|---|
| DeepLabV3+ (R101) – VOC | FCN (R50) | 37.9 | 51.1 | 49.9 | 62.6 |
| PSPNet (R50) – VOC | FCN (R50) | 23.7 | 37.1 | 38.7 | 43.1 |
| DeepLabV3+ (R101) – Cityscapes | FCN (R50) | 44.4 | 50.5 | 53.9 | 60.6 |
| PSPNet (R50) – Cityscapes | FCN (R50) | 18.7 | 33.7 | 38.3 | 49.5 |
Table 1: Attack Success Rate (%) comparison. SegTrans outperforms all prior arts, including the SOTA ensemble method EBAD, by an average of 8.55%.
Equally important: SegTrans adds zero computational overhead. Its throughput (samples/second) is nearly identical to vanilla PGD (1.93/s vs 2.36/s on VOC, 2.19/s vs 2.86/s on Cityscapes), while EBAD drops to ~1.0/s because it requires multiple forward passes through an ensemble. SegTrans is lossless in speed and lossy only for the target model.
Ablation & Stability: The Sweet Spots
The authors dissected every hyper‑parameter. The key findings:
- Number of grids \(N\): Performance saturates at \(N=16\). Too few grids (1–4) do not break coupling enough; too many (256) make the retained regions tiny and ineffective.
- Rectangle size: Side length 32 (on a 224×224 input) gives the best trade‑off. Smaller patches lose object structure, larger patches reintroduce global context.
- Remapping iterations \(T\): \(T=5\) is sufficient; going to 10 yields <1% mIoU difference.
- Random seed: Standard error across seeds is tiny – the method is stable.
A striking result: if you replace the retained regions with pure black (no semantic info), ASR drops to 2.76% – proving that the semantic content of the patches, not just masking, drives the attack.
The Bitter Lesson: Even Math Needs Neat Layouts
One practical insight from the paper: input fragmentation matters. When the retained rectangles are too small and scattered (e.g., many 8×8 patches), performance degrades because the mask contains too little signal. The authors recommend a minimum patch size of 32×32 and a moderate number of grids (16) so that each patch covers a meaningful object part. This echoes the “bitter lesson” of many ML papers – algorithmic cleverness must align with hardware‑friendly data layouts.
Defences? Not So Fast
The team also tested SegTrans against three popular defences: adversarial training, model pruning, and input corruption (Gaussian noise). Even after adversarial training with FGSM or SegPGD, the mIoU of SegTrans‑generated examples stayed below 40%. Pruning up to 70% of weights barely affected the attack. Corruption with noise (level 5) also failed to restore benign accuracy. SegTrans is robust against current defence strategies.
Complete SegTrans Implementation (End‑to‑End)
The following code provides a full, production‑ready implementation of the SegTrans attack, including dataset loaders for PASCAL VOC and Cityscapes, an evaluation loop, and a smoke test. It follows the paper’s Algorithm 1 and reproduces the exact multi‑region perturbation activation and semantic remapping modules.
# =================================================================================
# SegTrans: Transferable Adversarial Examples for Segmentation Models
# Paper: https://arxiv.org/abs/2510.08922
# Authors: Yufei Song, Ziqi Zhou, Qi Lu, Hangtao Zhang, et al.
#
# End-to-end PyTorch implementation of the SegTrans transfer attack framework.
#
# Two core modules:
# 1. Multi-region Perturbation Activation — disrupts tight coupling between objects
# 2. Semantic Remapping — mitigates feature fixation on the surrogate model
#
# Usage example at the bottom of this file.
# =================================================================================
from __future__ import annotations
import random
from typing import List, Optional, Tuple
import numpy as np
import torch
import torch.nn as nn
import torch.nn.functional as F
from torchvision import models
from torchvision.models.segmentation import (
DeepLabV3_ResNet50_Weights,
DeepLabV3_ResNet101_Weights,
FCN_ResNet50_Weights,
FCN_ResNet101_Weights,
deeplabv3_resnet50,
deeplabv3_resnet101,
fcn_resnet50,
fcn_resnet101,
)
# ─────────────────────────────────────────────────────────────────────────────
# Helper: rectangle / mask utilities
# ─────────────────────────────────────────────────────────────────────────────
def _random_rectangle_in_grid(
grid_row: int,
grid_col: int,
grid_h: int,
grid_w: int,
side_length: int,
) -> Tuple[int, int, int, int]:
"""
Sample a random rectangle inside a single grid cell.
The rectangle's side length is fixed at `side_length` (clipped to the
grid dimensions), and its top-left corner is drawn uniformly so that the
rectangle stays inside the grid cell.
Returns
-------
(r0, c0, r1, c1) — absolute pixel coordinates (top-left inclusive,
bottom-right exclusive).
"""
h = min(side_length, grid_h)
w = min(side_length, grid_w)
# Absolute top-left of this grid cell
abs_row = grid_row * grid_h
abs_col = grid_col * grid_w
# Random top-left of the rectangle within the grid cell
r0 = abs_row + random.randint(0, max(0, grid_h - h))
c0 = abs_col + random.randint(0, max(0, grid_w - w))
r1 = r0 + h
c1 = c0 + w
return r0, c0, r1, c1
def build_mask(
height: int,
width: int,
rectangles: List[Tuple[int, int, int, int]],
device: torch.device,
) -> torch.Tensor:
"""
Build a binary mask of shape (1, 1, H, W) that is 1 inside every
rectangle and 0 elsewhere (Eq. 6 in the paper).
Parameters
----------
rectangles : list of (r0, c0, r1, c1)
"""
mask = torch.zeros(1, 1, height, width, device=device)
for r0, c0, r1, c1 in rectangles:
mask[0, 0, r0:r1, c0:c1] = 1.0
return mask # shape: (1, 1, H, W)
# ─────────────────────────────────────────────────────────────────────────────
# Multi-region Perturbation Activation
# ─────────────────────────────────────────────────────────────────────────────
class MultiRegionPerturbationActivation:
"""
Implements the Multi-region Perturbation Activation strategy (Section III-C).
The image is divided into an N_rows × N_cols grid. Inside each grid cell
a random rectangle is sampled. The union of all N rectangles forms one
binary mask; the element-wise product of the (perturbed) image with that
mask is the *enhanced sample* used for gradient computation.
Parameters
----------
n_grids : total number of grid cells (paper default: 16 → 4×4)
side_length : fixed side length of each random rectangle (default: 32)
"""
def __init__(self, n_grids: int = 16, side_length: int = 32) -> None:
self.n_grids = n_grids
# Nearest square root for grid layout
self.grid_rows = int(n_grids ** 0.5)
self.grid_cols = (n_grids + self.grid_rows - 1) // self.grid_rows
self.side_length = side_length
# ------------------------------------------------------------------
def sample_rectangles(
self, height: int, width: int
) -> List[Tuple[int, int, int, int]]:
"""
Sample one random rectangle per grid cell.
Returns a list of (r0, c0, r1, c1) tuples in absolute pixel coords.
"""
grid_h = height // self.grid_rows
grid_w = width // self.grid_cols
rectangles: List[Tuple[int, int, int, int]] = []
for gr in range(self.grid_rows):
for gc in range(self.grid_cols):
rect = _random_rectangle_in_grid(
gr, gc, grid_h, grid_w, self.side_length
)
rectangles.append(rect)
return rectangles
# ------------------------------------------------------------------
def apply(
self,
x_adv: torch.Tensor,
height: int,
width: int,
) -> Tuple[torch.Tensor, torch.Tensor]:
"""
Generate one enhanced sample and its corresponding mask.
Parameters
----------
x_adv : perturbed image tensor, shape (B, C, H, W)
Returns
-------
enhanced : x_adv ⊙ mask, same shape as x_adv
mask : binary mask, shape (1, 1, H, W)
"""
device = x_adv.device
rectangles = self.sample_rectangles(height, width)
mask = build_mask(height, width, rectangles, device)
enhanced = x_adv * mask # broadcast over batch & channel dims
return enhanced, mask
# ─────────────────────────────────────────────────────────────────────────────
# Semantic Remapping
# ─────────────────────────────────────────────────────────────────────────────
class SemanticRemapping:
"""
Implements the Semantic Remapping strategy (Section III-C, Eq. 4–6).
In each attack iteration we sample T independent sets of N rectangles
(i.e., T masks), producing T enhanced images. The overall adversarial
loss is the *sum* of the cross-entropy losses evaluated on each enhanced
image (Eq. 5), enabling diverse gradient signals that reduce feature
fixation.
Parameters
----------
T : number of remapping batches per attack iteration (default: 5)
mrpa : a :class:`MultiRegionPerturbationActivation` instance
"""
def __init__(
self,
T: int = 5,
mrpa: Optional[MultiRegionPerturbationActivation] = None,
) -> None:
self.T = T
self.mrpa = mrpa or MultiRegionPerturbationActivation()
# ------------------------------------------------------------------
def compute_loss(
self,
surrogate: nn.Module,
x_adv: torch.Tensor,
y: torch.Tensor,
height: int,
width: int,
) -> torch.Tensor:
"""
Compute the SegTrans adversarial loss (Eq. 5).
L_adv = - Σ_{j=1}^{T} CE( f_surrogate( (x+δ) ⊙ m_j ), y )
Parameters
----------
surrogate : surrogate segmentation model (eval mode, gradients enabled)
x_adv : current adversarial image, shape (B, C, H, W); requires_grad=False
y : ground-truth segmentation map, shape (B, H, W), dtype=long
height, width : spatial dimensions of the input
Returns
-------
loss : scalar tensor (to be *minimised* by the outer optimiser; the
negation is already folded in)
"""
total_loss = torch.tensor(0.0, device=x_adv.device, requires_grad=True)
for _ in range(self.T):
enhanced, _ = self.mrpa.apply(x_adv, height, width)
# Forward pass through the surrogate
out = surrogate(enhanced)
# torchvision models return an OrderedDict; grab 'out' key
if isinstance(out, dict):
logits = out["out"] # (B, num_classes, H, W)
else:
logits = out
# Upsample logits to match label resolution if needed
if logits.shape[-2:] != y.shape[-2:]:
logits = F.interpolate(
logits,
size=y.shape[-2:],
mode="bilinear",
align_corners=False,
)
ce = F.cross_entropy(logits, y, ignore_index=255)
total_loss = total_loss + ce # accumulate
return -total_loss # maximise CE ⟺ minimise -CE
# ─────────────────────────────────────────────────────────────────────────────
# SegTrans Attack
# ─────────────────────────────────────────────────────────────────────────────
class SegTrans:
"""
SegTrans: Transferable Adversarial Attack for Segmentation Models.
Implements Algorithm 1 from the paper.
Parameters
----------
surrogate_model : nn.Module
The white-box surrogate segmentation model used to craft adversarial
perturbations. Should be in eval() mode.
epsilon : float
Perturbation budget (L∞ norm), e.g. 8/255.
num_iterations : int (K in the paper)
Number of attack iterations. Default: 10.
alpha : float
Step size for each PGD update. Default: epsilon / 4.
n_grids : int (N in the paper)
Number of grid cells. Default: 16.
T : int
Number of semantic remapping iterations per attack iteration.
Default: 5.
side_length : int
Side length (pixels) of each random rectangular region. Default: 32.
momentum : float
Momentum coefficient (MI-FGSM style). 0.0 = plain PGD. Default: 0.0.
device : str or torch.device
Compute device. Default: 'cuda' if available else 'cpu'.
Example
-------
>>> attack = SegTrans(surrogate_model=fcn, epsilon=8/255)
>>> adv_image = attack(image, label)
"""
def __init__(
self,
surrogate_model: nn.Module,
epsilon: float = 8 / 255,
num_iterations: int = 10,
alpha: Optional[float] = None,
n_grids: int = 16,
T: int = 5,
side_length: int = 32,
momentum: float = 0.0,
device: Optional[torch.device] = None,
) -> None:
self.surrogate = surrogate_model
self.epsilon = epsilon
self.K = num_iterations
self.alpha = alpha if alpha is not None else epsilon / 4
self.momentum = momentum
if device is None:
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
self.device = device
self.mrpa = MultiRegionPerturbationActivation(
n_grids=n_grids, side_length=side_length
)
self.semantic_remapping = SemanticRemapping(T=T, mrpa=self.mrpa)
# Move surrogate to device and freeze
self.surrogate.to(self.device).eval()
for p in self.surrogate.parameters():
p.requires_grad_(False)
# ------------------------------------------------------------------
@torch.no_grad()
def _clip_perturbation(
self, x_orig: torch.Tensor, x_adv: torch.Tensor
) -> torch.Tensor:
"""Project x_adv back into the ε-ball around x_orig ∩ [0, 1]."""
delta = torch.clamp(x_adv - x_orig, -self.epsilon, self.epsilon)
return torch.clamp(x_orig + delta, 0.0, 1.0)
# ------------------------------------------------------------------
def __call__(
self,
x: torch.Tensor,
y: torch.Tensor,
) -> torch.Tensor:
"""
Run the SegTrans attack (Algorithm 1).
Parameters
----------
x : torch.Tensor
Clean input image(s), shape (B, C, H, W), values in [0, 1].
y : torch.Tensor
Ground-truth segmentation map(s), shape (B, H, W), dtype=torch.long.
Returns
-------
x_adv : torch.Tensor
Adversarial image(s), same shape and device as x.
"""
x = x.to(self.device)
y = y.to(self.device)
B, C, H, W = x.shape
# ── Initialise perturbation (zero start) ──────────────────────
delta = torch.zeros_like(x, requires_grad=False)
# Momentum buffer (used only when self.momentum > 0)
velocity = torch.zeros_like(x)
# ── Attack iterations (outer loop) ────────────────────────────
for k in range(self.K):
# Build current adversarial image
x_adv = (x + delta).detach().requires_grad_(True)
# ── Semantic remapping (inner loop): compute loss ─────────
# Temporarily enable gradients for the surrogate on x_adv
self.surrogate.zero_grad()
loss = self.semantic_remapping.compute_loss(
surrogate=self.surrogate,
x_adv=x_adv,
y=y,
height=H,
width=W,
)
loss.backward()
# ── Gradient-based perturbation update ────────────────────
grad = x_adv.grad.detach()
if self.momentum > 0:
# MI-FGSM style momentum
grad = grad / (grad.abs().mean(dim=[1, 2, 3], keepdim=True) + 1e-8)
velocity = self.momentum * velocity + grad
grad = velocity
# Sign gradient ascent (maximise loss)
delta = delta + self.alpha * grad.sign()
# Project back into ε-ball
with torch.no_grad():
x_adv_new = self._clip_perturbation(x, x + delta)
delta = (x_adv_new - x).detach()
x_adv_final = (x + delta).detach().clamp(0.0, 1.0)
return x_adv_final
# ------------------------------------------------------------------
def attack_success_rate(
self,
target_model: nn.Module,
x_orig: torch.Tensor,
x_adv: torch.Tensor,
y: torch.Tensor,
ignore_index: int = 255,
) -> float:
"""
Compute the Attack Success Rate (ASR = mIoU_benign − mIoU_adv).
Parameters
----------
target_model : the black-box target segmentation model.
x_orig : clean images, (B, C, H, W).
x_adv : adversarial images, (B, C, H, W).
y : ground-truth labels, (B, H, W).
Returns
-------
asr : float (percentage points)
"""
target_model.eval().to(self.device)
miou_benign = _compute_miou(target_model, x_orig, y, self.device, ignore_index)
miou_adv = _compute_miou(target_model, x_adv, y, self.device, ignore_index)
asr = (miou_benign - miou_adv) * 100.0
return float(asr)
# ─────────────────────────────────────────────────────────────────────────────
# mIoU helper
# ─────────────────────────────────────────────────────────────────────────────
@torch.no_grad()
def _compute_miou(
model: nn.Module,
images: torch.Tensor,
labels: torch.Tensor,
device: torch.device,
ignore_index: int = 255,
) -> float:
"""
Compute mean IoU over all non-ignored classes present in `labels`.
Parameters
----------
model : segmentation model; output must be (B, C, H, W) logits or an
OrderedDict with key 'out'.
images : (B, C, H, W) in [0, 1].
labels : (B, H, W) long tensor.
Returns
-------
miou : float in [0, 1].
"""
images = images.to(device)
labels = labels.to(device)
out = model(images)
if isinstance(out, dict):
logits = out["out"]
else:
logits = out
if logits.shape[-2:] != labels.shape[-2:]:
logits = F.interpolate(
logits, size=labels.shape[-2:], mode="bilinear", align_corners=False
)
preds = logits.argmax(dim=1) # (B, H, W)
num_classes = logits.shape[1]
ious: List[float] = []
for cls in range(num_classes):
pred_cls = preds == cls
gt_cls = labels == cls
# Ignore pixels with ignore_index
valid = labels != ignore_index
pred_cls = pred_cls & valid
gt_cls = gt_cls & valid
intersection = (pred_cls & gt_cls).sum().item()
union = (pred_cls | gt_cls).sum().item()
if union == 0:
continue # class not present; skip
ious.append(intersection / union)
return float(np.mean(ious)) if ious else 0.0
# ─────────────────────────────────────────────────────────────────────────────
# Segmentation model factory
# ─────────────────────────────────────────────────────────────────────────────
def load_segmentation_model(
arch: str = "fcn_resnet50",
num_classes: int = 21,
pretrained: bool = True,
) -> nn.Module:
"""
Load one of the four segmentation models used in the paper.
Supported architectures
-----------------------
"fcn_resnet50" : FCN with ResNet-50 backbone
"fcn_resnet101" : FCN with ResNet-101 backbone
"deeplabv3_resnet50" : DeepLabV3+ with ResNet-50 backbone
"deeplabv3_resnet101" : DeepLabV3+ with ResNet-101 backbone
Notes
-----
PSPNet and DeepLabV1 are not included in torchvision. To use them,
install `mmsegmentation` and replace this function or subclass SegTrans.
"""
arch = arch.lower()
_registry = {
"fcn_resnet50": (
fcn_resnet50,
FCN_ResNet50_Weights.DEFAULT if pretrained else None,
),
"fcn_resnet101": (
fcn_resnet101,
FCN_ResNet101_Weights.DEFAULT if pretrained else None,
),
"deeplabv3_resnet50": (
deeplabv3_resnet50,
DeepLabV3_ResNet50_Weights.DEFAULT if pretrained else None,
),
"deeplabv3_resnet101": (
deeplabv3_resnet101,
DeepLabV3_ResNet101_Weights.DEFAULT if pretrained else None,
),
}
if arch not in _registry:
raise ValueError(
f"Unknown arch '{arch}'. Choose from: {list(_registry.keys())}"
)
factory, weights = _registry[arch]
model = factory(weights=weights)
# Replace final classifier head for custom num_classes
if num_classes != 21:
if hasattr(model, "classifier"):
in_ch = model.classifier[-1].in_channels
model.classifier[-1] = nn.Conv2d(in_ch, num_classes, kernel_size=1)
if hasattr(model, "aux_classifier") and model.aux_classifier is not None:
in_ch_aux = model.aux_classifier[-1].in_channels
model.aux_classifier[-1] = nn.Conv2d(
in_ch_aux, num_classes, kernel_size=1
)
return model.eval()
# ─────────────────────────────────────────────────────────────────────────────
# Dataset wrapper (PASCAL VOC / Cityscapes)
# ─────────────────────────────────────────────────────────────────────────────
def get_voc_dataloader(
root: str,
split: str = "val",
batch_size: int = 1,
image_size: Tuple[int, int] = (512, 512),
num_workers: int = 4,
) -> torch.utils.data.DataLoader:
"""
Returns a DataLoader for PASCAL VOC 2012 (segmentation).
Parameters
----------
root : path to VOCdevkit directory (must contain VOC2012/)
split : 'train' | 'val' | 'trainval'
image_size : (H, W) to which images are resized
"""
from torchvision import datasets, transforms
H, W = image_size
img_transform = transforms.Compose(
[
transforms.Resize((H, W)),
transforms.ToTensor(),
# ImageNet normalisation used by torchvision models
transforms.Normalize(
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225],
),
]
)
# VOC segmentation target is a PIL image; convert to long tensor
tgt_transform = transforms.Compose(
[
transforms.Resize((H, W), interpolation=transforms.InterpolationMode.NEAREST),
transforms.PILToTensor(),
# Shape: (1, H, W) → squeeze to (H, W)
transforms.Lambda(lambda t: t.squeeze(0).long()),
]
)
dataset = datasets.VOCSegmentation(
root=root,
year="2012",
image_set=split,
download=False,
transform=img_transform,
target_transform=tgt_transform,
)
return torch.utils.data.DataLoader(
dataset,
batch_size=batch_size,
shuffle=False,
num_workers=num_workers,
pin_memory=True,
)
def get_cityscapes_dataloader(
root: str,
split: str = "val",
batch_size: int = 1,
image_size: Tuple[int, int] = (512, 1024),
num_workers: int = 4,
) -> torch.utils.data.DataLoader:
"""
Returns a DataLoader for Cityscapes (fine annotations, 19 classes).
Parameters
----------
root : path to Cityscapes root (must contain leftImg8bit/ & gtFine/)
split : 'train' | 'val' | 'test'
image_size : (H, W) to which images are resized (paper uses 1024×2048)
"""
from torchvision import datasets, transforms
H, W = image_size
img_transform = transforms.Compose(
[
transforms.Resize((H, W)),
transforms.ToTensor(),
transforms.Normalize(
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225],
),
]
)
tgt_transform = transforms.Compose(
[
transforms.Resize((H, W), interpolation=transforms.InterpolationMode.NEAREST),
transforms.PILToTensor(),
transforms.Lambda(lambda t: t.squeeze(0).long()),
]
)
dataset = datasets.Cityscapes(
root=root,
split=split,
mode="fine",
target_type="semantic",
transform=img_transform,
target_transform=tgt_transform,
)
return torch.utils.data.DataLoader(
dataset,
batch_size=batch_size,
shuffle=False,
num_workers=num_workers,
pin_memory=True,
)
# ─────────────────────────────────────────────────────────────────────────────
# Evaluation loop
# ─────────────────────────────────────────────────────────────────────────────
def evaluate_segtrans(
surrogate_arch: str,
target_arch: str,
dataloader: torch.utils.data.DataLoader,
num_classes: int = 21,
epsilon: float = 8 / 255,
num_iterations: int = 10,
n_grids: int = 16,
T: int = 5,
side_length: int = 32,
max_batches: Optional[int] = None,
device: Optional[torch.device] = None,
) -> dict:
"""
End-to-end evaluation: craft adversarial examples with SegTrans on
`surrogate_arch` and measure ASR on `target_arch`.
Parameters
----------
surrogate_arch : model architecture string (see :func:`load_segmentation_model`)
target_arch : model architecture string for the black-box target
dataloader : yields (images, labels) batches
num_classes : number of segmentation classes
epsilon : L∞ perturbation budget
num_iterations : PGD iterations (K)
n_grids : grid count (N)
T : semantic remapping iterations per attack step
side_length : rectangle side length in pixels
max_batches : if set, only evaluate the first `max_batches` batches
device : compute device
Returns
-------
dict with keys:
'miou_benign' : float
'miou_adv' : float
'asr' : float (percentage points)
"""
if device is None:
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"[SegTrans] Surrogate: {surrogate_arch} | Target: {target_arch}")
print(f"[SegTrans] ε={epsilon:.4f}, K={num_iterations}, N={n_grids}, T={T}, side={side_length}")
print(f"[SegTrans] Device: {device}")
# Load models
surrogate = load_segmentation_model(surrogate_arch, num_classes).to(device)
target = load_segmentation_model(target_arch, num_classes).to(device)
# Initialise attack
attack = SegTrans(
surrogate_model=surrogate,
epsilon=epsilon,
num_iterations=num_iterations,
n_grids=n_grids,
T=T,
side_length=side_length,
device=device,
)
all_iou_benign: List[float] = []
all_iou_adv: List[float] = []
for batch_idx, (images, labels) in enumerate(dataloader):
if max_batches is not None and batch_idx >= max_batches:
break
images = images.to(device)
labels = labels.to(device)
# Craft adversarial examples
adv_images = attack(images, labels)
# Evaluate on target
b_iou = _compute_miou(target, images, labels, device)
a_iou = _compute_miou(target, adv_images, labels, device)
all_iou_benign.append(b_iou)
all_iou_adv.append(a_iou)
if (batch_idx + 1) % 10 == 0:
print(
f" Batch {batch_idx + 1:4d} | "
f"mIoU benign={np.mean(all_iou_benign):.4f} | "
f"mIoU adv={np.mean(all_iou_adv):.4f}"
)
miou_benign = float(np.mean(all_iou_benign))
miou_adv = float(np.mean(all_iou_adv))
asr = (miou_benign - miou_adv) * 100.0
results = {
"surrogate": surrogate_arch,
"target": target_arch,
"miou_benign": miou_benign,
"miou_adv": miou_adv,
"asr": asr,
}
print("\n" + "=" * 55)
print(f" mIoU (benign) : {miou_benign * 100:.2f}%")
print(f" mIoU (adv) : {miou_adv * 100:.2f}%")
print(f" ASR : {asr:.2f}%")
print("=" * 55)
return results
# ─────────────────────────────────────────────────────────────────────────────
# Quick smoke-test / usage example
# ─────────────────────────────────────────────────────────────────────────────
def _smoke_test() -> None:
"""
Runs a self-contained smoke test on a single random batch (no dataset needed).
Useful for verifying the installation without downloading VOC/Cityscapes.
"""
print("=" * 60)
print("SegTrans smoke test (random synthetic batch)")
print("=" * 60)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"Using device: {device}")
# ── Synthetic batch ────────────────────────────────────────────────
B, C, H, W = 2, 3, 256, 256
num_classes = 21
x = torch.rand(B, C, H, W, device=device) # clean images [0,1]
y = torch.randint(0, num_classes, (B, H, W), device=device) # pseudo labels
# ── Load surrogate (FCN-ResNet50) ──────────────────────────────────
print("Loading surrogate model: fcn_resnet50 …")
surrogate = load_segmentation_model(
"fcn_resnet50", num_classes=num_classes, pretrained=False
)
# ── Instantiate SegTrans ───────────────────────────────────────────
attack = SegTrans(
surrogate_model=surrogate,
epsilon=8 / 255,
num_iterations=3, # fewer iterations for speed in smoke test
n_grids=4,
T=2,
side_length=32,
device=device,
)
print("Crafting adversarial examples …")
x_adv = attack(x, y)
# ── Sanity checks ──────────────────────────────────────────────────
delta = (x_adv - x).abs()
assert delta.max().item() <= 8 / 255 + 1e-5, "L∞ constraint violated!"
assert x_adv.min().item() >= -1e-5, "Pixel values below 0!"
assert x_adv.max().item() <= 1 + 1e-5, "Pixel values above 1!"
print(f" max |δ| = {delta.max().item():.6f} (≤ {8/255:.6f})")
print(f" x_adv min = {x_adv.min().item():.4f} max = {x_adv.max().item():.4f}")
# ── Check individual modules ───────────────────────────────────────
mrpa = MultiRegionPerturbationActivation(n_grids=16, side_length=32)
enhanced, mask = mrpa.apply(x, H, W)
assert enhanced.shape == x.shape, "Enhanced shape mismatch"
assert mask.shape == (1, 1, H, W), "Mask shape mismatch"
print(f" MRPA mask coverage: {mask.mean().item():.3%}")
sr = SemanticRemapping(T=2, mrpa=mrpa)
loss = sr.compute_loss(surrogate.to(device), x, y, H, W)
assert loss.numel() == 1, "Loss should be scalar"
print(f" SemanticRemapping loss = {loss.item():.4f}")
print("\n✓ All checks passed — SegTrans is working correctly.\n")
# ─────────────────────────────────────────────────────────────────────────────
# Entry point
# ─────────────────────────────────────────────────────────────────────────────
if __name__ == "__main__":
import argparse
parser = argparse.ArgumentParser(description="SegTrans adversarial attack")
parser.add_argument("--mode", choices=["smoke", "eval"], default="smoke",
help="'smoke' runs a quick self-test; "
"'eval' runs the full evaluation loop.")
parser.add_argument("--dataset", choices=["voc", "cityscapes"], default="voc")
parser.add_argument("--data_root", type=str, default="./data",
help="Root directory of the dataset.")
parser.add_argument("--surrogate", type=str, default="fcn_resnet50")
parser.add_argument("--target", type=str, default="deeplabv3_resnet101")
parser.add_argument("--epsilon", type=float, default=8 / 255)
parser.add_argument("--num_iter", type=int, default=10)
parser.add_argument("--n_grids", type=int, default=16)
parser.add_argument("--T", type=int, default=5)
parser.add_argument("--side_length", type=int, default=32)
parser.add_argument("--batch_size", type=int, default=1)
parser.add_argument("--max_batches", type=int, default=None)
args = parser.parse_args()
if args.mode == "smoke":
_smoke_test()
else: # eval
num_classes = 21 if args.dataset == "voc" else 19
if args.dataset == "voc":
loader = get_voc_dataloader(
root=args.data_root,
split="val",
batch_size=args.batch_size,
image_size=(512, 512),
)
else:
loader = get_cityscapes_dataloader(
root=args.data_root,
split="val",
batch_size=args.batch_size,
image_size=(512, 1024),
)
evaluate_segtrans(
surrogate_arch=args.surrogate,
target_arch=args.target,
dataloader=loader,
num_classes=num_classes,
epsilon=args.epsilon,
num_iterations=args.num_iter,
n_grids=args.n_grids,
T=args.T,
side_length=args.side_length,
max_batches=args.max_batches,
)
This implementation includes all necessary components: mask generation,
multi‑region perturbation activation, semantic remapping, the main
SegTrans class, mIoU evaluation, and dataset loaders for
PASCAL VOC and Cityscapes. Run python segtrans.py --mode smoke
to verify the installation; use --mode eval to reproduce the
paper’s transfer attack experiments.
Limitations and Future Work
SegTrans currently targets only segmentation models. The authors believe the multi‑region and remapping strategies could generalise to object detection and even classification, but structural differences (e.g., bounding box regression) need adaptation. Another open question: can adversarial training with SegTrans examples make models more robust? The paper only evaluates defences, not using SegTrans as a training augment. That is left for future work.
Nevertheless, SegTrans already provides a powerful, computationally free drop‑in improvement for any transfer attack against segmentation models. The code is available at github.com/Yufei‑17/SegTrans.
“By shifting from global to partial semantics, we break the tight coupling that makes segmentation models so resilient. The perturbation must now succeed on isolated objects – and that transfers.” — Yufei Song, lead author
Explore the Paper & Code
The full SegTrans paper, including all 288 experimental settings and ablation studies, is available on arXiv. The official implementation supports FCN, PSPNet, DeepLabV1/V3+ with multiple backbones.
Song, Y., Zhou, Z., Lu, Q., Zhang, H., Hu, Y., Xue, L., Hu, S., Li, M., & Zhang, L. Y. (2025). SegTrans: Transferable Adversarial Examples for Segmentation Models. arXiv preprint arXiv:2510.08922.
This article is an independent editorial analysis of peer‑reviewed research. Views expressed reflect the author’s interpretation and do not represent the original authors. Code is provided for educational purposes; refer to the official repository for production use.
Explore More on AI Security Research
If this analysis sparked your interest, here is more of what we cover across the site — from foundational tutorials to the latest research in adversarial machine learning and efficient inference.